



داده کاوی (Data Mining) – از صفر تا صد
در این مطلب به مباحث «داده کاوی» (Data Mining) از صفر تا صد پرداخته شده است. با پیشرفت سریع «فناوری اطلاعات» (Information Technology)، بشر شاهد یک رشد انفجاری در تولید «داده» (Data) و ظرفیتهای گردآوری و ذخیرهسازی آن در دامنههای گوناگون بوده است. در جهان کسبوکار، «پایگاهدادههای» (Databases) بسیار بزرگی برای تراکنشهای تجاری وجود دارند که توسط خردهفروشان و یا در «تجارت الکترونیک» (E-commerce) ساخته شدهاند. از سوی دیگر، همه روزه حجم عظیمی از دادههای علمی در زمینههای گوناگون تولید میشوند.




از جمله دادههای علمی میتوان به پروژه «ژنوم انسان» (Human Genome) اشاره کرد که چندین گیگابایت داده را از کد ژنتیکی انسان تجمیع کرده است. «وب جهان گستر» (World Wide Web) مثال دیگری از منابع داده است که میلیاردها صفحه وب شامل اطلاعات متنی و چند رسانهای را دربرمیگیرد. این صفحات توسط میلیونها نفر بازدید میشوند. در چنین شرایطی، تحلیل بدنه بزرگ دادهها به شکل قابل درک و کاربردی، یک مساله چالش برانگیز است.
«دادهکاوی» (Data Mining) این مساله را با فراهم کردن روشها و نرمافزارهایی برای خودکارسازی تحلیلها و اکتشاف مجموعه دادههای بزرگ و پیچیده حل میکند. پژوهشها در زمینه دادهکاوی در گستره وسیعی از موضوعات شامل آمار، علوم کامپیوتر، «یادگیری ماشین» (Machine Learning)، «مدیریت پایگاه داده» (Database Management) و «بصریسازی دادهها» (Data Visualization) دنبال میشود. روشهای دادهکاوی و یادگیری، در زمینههایی غیر از آمار نیز توسعه داده شدهاند، که از جمله آنها میتوان به یادگیری ماشین و «پردازش سیگنال» (signal processing) اشاره کرد.
داده کاوی چیست؟
به مجموعهای از روشهای قابل اعمال بر پایگاه دادههای بزرگ و پیچیده به منظور کشف الگوهای پنهان و جالب توجه نهفته در میان دادهها، دادهکاوی گفته میشود. روشهای دادهکاوی تقریبا همیشه به لحاظ محاسباتی پر هزینه هستند. علم میانرشتهای دادهکاوی، پیرامون ابزارها، متدولوژیها و تئوریهایی است که برای آشکارسازی الگوهای موجود در دادهها مورد استفاده قرار میگیرند و گامی اساسی در راستای کشف دانش محسوب میشود.
دلایل گوناگونی پیرامون چرایی مبدل شدن دادهکاوی به چنین حوزه مهمی از مطالعات وجود دارد. برخی از این موارد در ادامه بیان شدهاند.

۱. رشد انفجاری دادهها در گستره وسیعی از زمینهها در صنعت و دانشگاه که توسط موارد زیر پشتیبانی میشود:
- دستگاههای ذخیرهسازی نسبت به گذشته ارزانتر و با ظرفیت نامحدود، مانند فضاهای ذخیرهسازی ابری
- ارتباطات سریعتر با سرعت اتصال بیشتر
- سیستمهای مدیریت پایگاه داده و پشتیبانی نرمافزاری بهتر
۲. قدرت پردازش کامپیوتری به سرعت در حال افزایش
با چنین حجم بالا و متنوعی از دادههای موجود، روشهای دادهکاوی به استخراج اطلاعات از دادهها کمک میکنند. «ژیاوی هان» (Jiawei Han)، دانشمند داده و نویسنده کتاب «دادهکاوی، مفاهیم و روشها» (Data Mining: Concepts and Techniques) در این رابطه میگوید:
«... در نتیجه، دادههای گردآوری شده در مخازن داده به گورهای داده مبدل شدهاند، ...، شکاف در حال افزایش میان داده و اطلاعات، توسعه سیستماتیک ابزارهای دادهکاوی را میطلبد که میتوانند گورهای داده را به شمشهایی از طلا مبدل کنند.»
روشهای دادهکاوی دارای انواع گوناگونی هستند و از رگرسیون گرفته تا روشهای تشخیص الگوی پیچیده و دارای هزینه محاسباتی بالا که ریشه در علوم کامپیوتر دارند را شامل میشوند. هدف اصلی روشهای یادگیری (دادهکاوی) انجام پیشبینی است، ولی این تنها هدف دادهکاوی نیست.
پیش از ادامه این مبحث لازم است یادآور شویم که میتوانید داده کاوی را با استفاده از مجموعه آموزش داده کاوی، مقدماتی تا پیشرفته فرادرس یاد بگیرید.
تاریخچه دادهکاوی
در سال ۱۹۶۰، کارشناسان آمار از اصطلاحات «صید داده» (Data Fishing) و «لایروبی داده» (Data Dredging) برای ارجاع به فعالیتهای «تحلیل داده» (Data Analytics) استفاده میکردند. اصطلاح «دادهکاوی» در حدود سال ۱۹۹۰ در جامعه پایگاهداده مورد استفاده قرار گرفت و به محبوبیت قابل توجهی دست پیدا کرد. عنوان مناسبتر برای فرآیند دادهکاوی، «کشف دانش از داده» (Knowledge Discovery From Data) است.
در حال حاضر، یادگیری آماری، «تحلیل داده» و «علم داده» (Data Science) از دیگر عباراتی هستند که با معنای مشابه دادهکاوی مورد استفاده قرار میگیرند، حال آنکه گاه تفاوتهای ظریفی میان این موارد وجود دارد. برای آشنایی با این تفاوتها، مطالعه مطلب «علم داده، تحلیل داده، دادهکاوی و یادگیری ماشین ــ تفاوتها و شباهتها» توصیه میشود. همچنین، برای مطالعه همراه با جزئیات بیشتر پیرامون تاریخچه دادهکاوی، مطلب «دادهکاوی چیست؟ بخش اول: مبانی» پیشنهاد میشود.

از روشهای دادهکاوی در فرآیند طویل پژوهش و توسعه محصول استفاده میشود. از همین رو، تکامل دادهکاوی نیز از هنگامی آغاز شد که دادههای کسبوکارها روی کامپیوترها ذخیره شدند. دادهکاوی به کاربران امکان حرکت در میان دادهها را در زمان واقعی میدهد. از دادهکاوی در جامعه کسبوکار بدین دلیل استفاده میشود که از سه فناوری بلوغ یافته استفاده میکند، این فناوریها عبارتند از:
- گردآوری داده انبوه
- کامپیوترهای چند پردازندهای قدرتمند
- الگوریتمهای دادهکاوی
چرا دادهکاوی؟
با رشد و افزایش توجهات به دادهکاوی، پرسش «چرا دادهکاوی؟» همواره مطرح میشود. در پاسخ به این پرسش باید گفت، دادهکاوی دارای کاربردهای زیادی است. بدین ترتیب، زمینهای جوان و آیندهدار برای نسل کنونی محسوب میشود. این زمینه توانسته توجهات زیادی را به صنایع و جوامع اطلاعاتی جلب کند. با وجود گستره وسیع دادهها، نیاز حتمی به تبدیل چنین دادههایی به اطلاعات و دانش وجود دارد.
بنابراین، بشر از اطلاعات و دانش برای گستره وسیعی از کاربردها، از تحلیل بازار گرفته تا تشخیص بیماریها، کشف کلاهبرداری و پیشبینی قیمت سهام استفاده میکند. در مجموع باید گفت، ضربالمثل انگلیسی «نیاز، مادر همه ابداعات بشر است»، پاسخی کوتاه و گویا به پرسش مطرح شده است. در ادامه، برخی از استفادههای دادهکاوی مورد بررسی قرار گرفتهاند.
پیشبینی خودکار گرایشها و رفتارها
از دادهکاوی برای خودکارسازی فرآیندها و انجام پیشبینی در پایگاهدادههای بزرگ استفاده میشود. پرسشهایی که پاسخگویی به آنها نیازمند تحلیلهای گسترده است، اکنون و با استفاده از تحلیل دادهها قابل پاسخگویی هستند. بازاریابی هدفمند مثالی از بازاریابی پیشبین است. همچنین، از دادهکاوی برای ارسال ایمیلهای تبلیغاتی هدفمند و بهینه استفاده میشود.

در واقع، دادهکاوی به منظور بیشینهسازی «بازگشت سرمایه» (Return On Investment) در ارسال ایمیلهای تبلیغاتی مورد استفاده قرار میگیرد. از دیگر مسائل پیشبینی میتوان به پیشبینی ورشکستگی، اشاره کرد. شناسایی بخشهایی از جامعه که احتمال دارد به یک رویداد واکنشهای مشابهی نشان دهند نیز از دیگر قابلیتهای دادهکاوی به شمار میآید.

کشف خودکار الگوهای پیشتر ناشناخته
از ابزارهای دادهکاوی برای بررسی پایگاههای داده استفاده میشود. همچنین، برای شناسایی الگوهای از پیش ناشناخته نیز قابل بهرهبرداری است. یک مثال خیلی خوب از کاوش الگوها، تحلیل دادههای فروش خردهفروشیها است. این کار با هدف شناسایی محصولات غیر مرتبطی که معمولا با هم خریداری میشوند انجام میشود. همچنین، مسائل کاوش الگوی دیگری نیز وجود دارند که از جمله آنها میتوان به شناسایی تراکنشهای کلاهبرداری در کارتهای اعتباری اشاره کرد. در چنین مواردی، الگوهای داده ناشناخته و جدید، میتوانند خبر از وقوع سرقت اطلاعات کارت اعتباری و دیگر انواع کلاهبرداری بدهند.
انواع منابع داده
در این بخش، انواع منابع دادهای که همه روزه حجم انبوهی از دادهها را تولید و یا ذخیره میکنند، مورد بررسی قرار گرفتهاند. در همین راستا، مطالعه مطلب «مجموعه دادههای رایگان و قابل دانلود برای علم داده و یادگیری ماشین» به علاقمندان توصیه میشود.
تراکنشهای کسبوکار
در کسبوکارهای کنونی، اغلب تراکنشها تا ابد نگهداری میشوند. بسیاری از این تراکنشها دارای زمان هستند و شامل معاملات درون کسبوکاری مانند خریدها، مبادلات بانکداری، سهام و دیگر موارد هستند.
دادههای علمی
در سراسر جهان، جوامع گوناگون در حال گردآوری حجم انبوهی از دادههای علمی هستند. این دادههای علمی نیاز به تحلیل دارند. این در حالی است که همواره نیاز به ثبت دادههای جدید بیشتر با سرعت بالاتری وجود دارد. دادهکاوی در زمینههای علمی گوناگون برای کمک به تحلیل دادهها و کشف دانش از آنها کمک شایان توجهی میکند.
دادههای شخصی و پزشکی
دادهها، از شخصی گرفته تا عمومی و از فردی گرفته تا دولتی را میتوان با اهداف گوناگونی گردآوری کرد و مورد تحلیل قرار داد. این دادهها برای افراد و گروههای مختلف مورد نیاز هستند و هنگامی که گردآوری شدند، کشف اطلاعات از آنها میتواند پرده از مسائل مهمی بردارد. از جمله دادههای شخصی، میتوان به اطلاعات تراکنشهای بانکی فرد و یا اسناد پزشکی ایشان اشاره کرد. دادهکاوی در دادههای پزشکی نقش قابل توجهی در پیشگیری، کشف و حتی درمان بیماریها دارد.

تصاویر و ویدئوهای نظارتی
با کاهش قیمت دوربینهای عکاسی و فیلمبرداری و وجود دوربین در گوشیهای هوشمند، در هر لحظه حجم زیادی از دادههای چندرسانهای تولید میشود. از سوی دیگر، حجم زیادی از تصاویر و ویدئوها نیز توسط دوربینهای نظارتی گردآوری میشوند. این دادهها برای انواع تحلیلهای داده قابل بهرهبرداری هستند.

رقابتهای ورزشی
حجم زیادی از دادهها و آمارها پیرامون رقابتهای ورزشی وجود دارد که قابل گردآوری و تحلیل محسوب میشوند. از جمله این موارد میتوان به اطلاعات بازی و بازیکنان اشاره کرد.
رسانههای دیجیتال
دلایل زیادی منجر به انفجار مخازن دادههای دیجیتال شده است. از جمله این موارد میتوان به اسکنرهای ارزان، دوربینهای ویدئویی دسکتاپ و دوربینهای دیجیتال اشاره کرد. از سوی دیگر، شرکتهای بزرگی مانند NHL و NBA در حال حاضر کار تبدیل مجموعههای خود به دادههای دیجیتال را آغاز کردهاند و انجام چنین کارهایی نیز نیاز به تحلیل حجم انبوه دادهها را برجستهتر میسازد.

دنیاهای مجازی
سیستمهای «طراحی به کمک کامپیوتر» (Computer Aided Design) متعددی برای معماران وجود دارند. این سیستمها برای تولید حجم انبوهی از دادهها مورد استفاده قرار میگیرند. علاوه بر این، میتوان از دادههای «مهندسی نرمافزار» (Software Engineering) به عنوان منبعی از دادهها - همراه با کدهای فراوان برای امور گوناگون - استفاده کرد.
جهانهای مجازی
امروزه بسیاری از برنامههای کاربردی از فضاهای مجازی سهبُعدی استفاده میکنند. همچنین، این فضاها و اشیایی که در بر میگیرند باید با زبان خاصی مانند «زبان مدلسازی واقعیت مجازی» (Virtual Reality Modeling Language | VRML) توصیف شوند.
گزارشها و اسناد متنی
ارتباطات در بسیاری از شرکتها بر مبنای گزارشها و اسناد دارای قالب متنی است. این اسناد برای انجام تحلیلهای آتی قابل نگهداری هستند. از سوی دیگر، حجم انبوهی از دادههای موجود در وب نیز به صورت دادههای متنی ساختار نیافته هستند که هر روز بر حجم آنها افزوده میشود.
فرایند دادهکاوی
دادهکاوی که با عنوان «کشف دانش از داده» (Knowledge Discovery From Data | KDD) نیز شناخته شده است، فرایند استخراج اطلاعات و دانش از دادههای موجود در پایگاهداده یا انبارداده است.
فرآیند دادهکاوی شامل چندین گام است. این فرآیند از دادههای خام آغاز میشود و تا شکلدهی دانش جدید ادامه دارد. فرآیند بازگشتی دادهکاوی شامل گامهای زیر است:
- «پاکسازی داده» (Data Cleaning)
- «یکپارچهسازی داده» (Data Integration)
- «انتخاب داده» (Data Selection)
- «تبدیل داده» (Data Transformation)
- «کاوش داده» (Data Mining)
- «ارزیابی الگو» (Pattern Evaluation)
- «ارائه دانش» (Knowledge Representation)
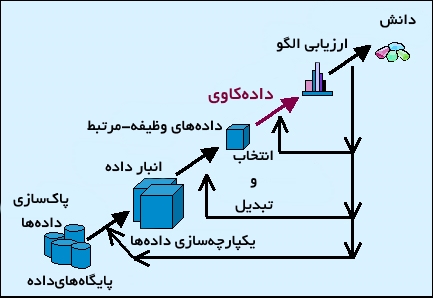

پاکسازی داده
در این فاز «نویز» (نوفه) از مجموعه حذف و تدابیری برای «دادههای ناموجود» (Missing Values) اندیشیده میشود. برای مطالعه بیشتر در این رابطه، مطلب «پاکسازی داده (Data Cleaning) در پایتون با استفاده از NumPy و Pandas — راهنمای جامع» پیشنهاد میشود.
یکپارچهسازی دادهها
در اغلب مسائل دادهکاوی، دادهها از منابع داده گوناگون باید به یکباره مورد تحلیل قرار بگیرند. مثال خوبی از این مورد پایگاه دادههای شعب مختلف یک فروشگاه زنجیرهای در شهرها و کشورهای گوناگون جهان است. برای تحلیل این دادهها باید آنها را به صورت یکپارچه در یک «انبار داده» (Data Warehouse) گردآوری کرد، این کار در فاز یکپارچهسازی انجام میشود.

انتخاب داده
در فاز انتخاب داده، باید دادههای مرتبط با تحلیل انتخاب، و از مجموعه داده برای انجام تحلیلها بازیابی شوند. در مطلب «انتخاب ویژگی (Feature Selection) در دادههای ابعاد بالا — خودآموز ساده» به این مساله همراه با جزئیات پرداخته شده است. همچنین، مطالعه «الگوریتم کاهش ابعاد t-SNE با مثالهای پایتون -- آموزش کاربردی» نیز به علاقمندان پیشنهاد میشود.
تبدیل داده
تبدیل داده یک روش تثبیت داده نیز هست. در این فاز، دادههای انتخاب شده به فرم دیگری تبدیل میشوند. این کار به سادهتر شدن، بهبود صحت و دقت فرآیند کاوش کمک میکند. برخی از روشهای محبوب و متداول استانداردسازی دادهها در مطلب «روشهای استانداردسازی دادهها» بیان شدهاند. دیگر مطالبی که مطالعه آنها در همین راستا توصیه میشود عبارتند از:
- پایتون و استخراج، تبدیل و بارگذاری دادهها (ETL) — راهنمای کامل
- استخراج (Extraction) و تبدیل (Transformation) دادهها در پایتون — راهنمای جامع
- تبدیل دادههای بدون ساختار به ساختیافته با پایتون و API نقشه گوگل — راهنمای کامل
دادهکاوی
در این فاز از روشهای هوشمندانه برای استخراج الگوهای مهم و جالب توجه از میان دادهها استفاده میشود. برخی از این روشها در مطالب جداگانه دیگری تشریح شدهاند که از آن جمله میتوان به موارد زیر اشاره کرد:
- رویکرد هوش ازدحامی با استفاده از کلونی زنبور عسل مصنوعی برای حل مسائل بهینهسازی
- پشتیبان، اطمینان، بالابری و عقیده -- مفاهیم کاربردی در کاوش قوانین انجمنی
- الگوریتم اپریوری (Apriori) به همراه کد پیادهسازی در پایتون — کاوش قوانین انجمنی در دادهکاوی
- الگوریتم اپریوری (Apriori) و کاوش الگوهای مکرر در دادهکاوی — به همراه کد پیادهسازی در R
- الگوریتم اپریوری (Apriori) — راهنمای ساده و سریع
ارزیابی الگو
در این فرآیند، الگوهای حاصل شده در گام قبل، از جنبههای گوناگونی شامل دقت، صحت و قابلیت تعمیم و دیگر موارد مورد ارزیابی قرار میگیرند. مطالعه مطالب زیر برای فراگیری بهتر پیرامون روشهای ارزیابی الگو پیشنهاد میشود:
- تحلیلها و آزمونهای آماری — مفاهیم و اصطلاحات
- روشهای بازنمونهگیری جکنایف و بوتاسترپ (Jackknife and Bootstrap) — به زبان ساده
- آزمون فرض میانگین جامعه در آمار — به زبان ساده
- اعتبار سنجی متقابل (Cross Validation) — به زبان ساده
ارائه دانش
ارائه دانش فاز نهایی فرآیند دادهکاوی است. در این فاز، دانش کشف شده به شیوه قابل درک به کاربر ارائه میشود. در این گام حیاتی و بسیار مهم، روشهای بصریسازی مورد استفاده قرار میگیرند. این کار به کاربران در درک و تفسیر نتایج دادهکاوی کمک میکند. مطالعه مطالب زیر در همین رابطه توصیه میشود:
- اینفوگرافیک چیست و چه فرقی با بصری سازی دادهها دارد؟
- هیستوگرام (Histogram) و نمودارهای چگالی — راهنمای بصری سازی دادههای تک بُعدی در پایتون
- نمودارهای متحرک در پایتون — از صفر تا صد
- انواع نمودار در ریاضیات — به زبان ساده
- ترسیم داده های جغرافیایی در پایتون — راهنمای جامع
مشکلات دادهکاوی
در این بخش از راهنمای دادهکاوی، برخی از مسائل کلی که دادهکاوی با آنها مواجه است تشریح شدهاند.
مسائل روششناسی دادهکاوی
این چالش به روشهای موجود برای دادهکاوی و محدودیتهای آنها مانند تطبیقپذیری مربوط است. در واقع، ارائه روشهایی که دارای پیچیدگی کم و قابلیت تعمیم به مسائل گوناگون باشند و در عین حال بتوانند با حجم انبوهی از دادهها کار کنند از جمله مسائل مربوط به بحث روششناسی در دادهکاوی است.

مسائل کارایی
روشهای هوش مصنوعی و آماری زیادی وجود دارند که در دادهکاوی مورد استفاده قرار میگیرند. اغلب این روشها برای مجموعه دادههای خیلی بزرگ طراحی نشدهاند و این چالشی است که دادهکاوی این روزها با آن دست و پنجه نرم میکند. زیرا امروزه حجم دادهها از ترابایت، پتابایت و اگزابایت نیز عبور کرده است. میتوان گفت این امر موجب افزایش مسائل مرتبط با مقیاسپذیری و کارایی روشهای دادهکاوی میشود و نیاز به روشهایی را ایجاد میکند که بتوانند به طور قابل توجهی دادههای بزرگ را پردازش کنند.

در چنین شرایطی، ممکن است از نمونهبرداری به جای کل مجموعهداده استفاده شود. اگرچه، در این حالت نیز مسائلی مانند کامل بودن و روش انتخاب نمونهها بروز میکند. دیگر موضوع در بحث کارایی بهروزرسانی تدریجی و برنامهنویسی موازی است. از موازیسازی برای حل مساله اندازه استفاده میشود و طی آن اگر مجموعه داده به زیرمجموعههایی تقسیم شود، نتایج بعدا قابل ادغام شدن هستند. بهروزرسانی مداوم برای ادغام نتایج از «کاوش موازی» (Parallel Mining) بسیار حائز اهمیت است. دادههای جدید بدون نیاز به بازتحلیل کل مجموعه داده در دسترس قرار میگیرند.
مسائل منابع داده
مسائل زیادی در رابطه با منابع داده لازم/مورد استفاده برای دادهکاوی وجود دارد. برخی از این مسائل مانند تنوع دادهها کاربردی و بخشی دیگر مسائل فلسفیتری مانند مشکل انباشته شدن دادهها هستند. واضح است که در حال حاضر حجم زیادی از دادهها، بیش از آنکه قابل مدیریت باشند، وجود دارند. از سوی دیگر، بشر همچنان در حال گردآوری دادهها حتی با نرخ بالاتری است. گسترش سیستمهای مدیریت پایگاه داده یکی از عواملی بوده که به رشد گردآوری دادهها کمک شایان توجهی کرده است.

ظهور دادهکاوی قطعا منجر به برداشت دادههای بیشتری میشود. با توجه به مسائل کاربردی مرتبط با منابع داده، پایگاه دادههای موضوعی ایجاد شدهاند. بدین ترتیب، نیاز به تمرکز کردن روی انواع داده پیچیدهتر وجود دارد. انواع گوناگونی از دادهها در گستره متنوعی از مخازن ذخیرهسازی میشوند. سخت است که بشر انتظار داشته باشد یک سیستم دادهکاوی نتایج کاوش خوبی را برای همه دادهها و منابع داده کسب کند.
دادهها و منابع گوناگون داده ممکن است نیاز به الگوریتمها و متدولوژیهای متمایزی داشته باشند. در حال حاضر، تمرکز بر پایگاه دادههای رابطهای و انبارهای داده است. ابزارهای دادهکاوی نیز طیف گستردهای را برای انواع دادهها شامل میشوند. علاوه بر این، منابع داده، در سطح ساختاری و معنایی، چالشهای مهمی را به همراه دارند. این تنها به جامعه پایگاهداده مربوط نیست، بلکه به جامعه دادهکاوی نیز ارتباط دارد.
اصطلاحشناسی
در ادامه برخی از مفاهیم و اصطلاحات پر کاربرد در حوزه دادهکاوی تشریح شدهاند.
نشانهگذاری
ورودی X: X اغلب چندبُعدی است. هر بُعد از X به صورت Xj مشخص شده که به یک ویژگی، یک متغیر (پیشبین) مستقل یا یک متغیر (بسته به اینکه پژوهشگر از کدام حوزه مطالعاتی است) اشاره دارد. خروجی Y، متغیر پاسخ یا متغیر وابسته نامیده میشود. پاسخ تنها هنگامی در دسترس است که یادگیری نظارت شده باشد.
ماهیت مجموعه داده
ویژگیهای موجود در مجموعه داده انواع گوناگونی دارند. این انواع به صورت زیر دستهبندی شدهاند.
| انواع ویژگیها | ||
|
اسمی (دستهای)
| ترتیبی | عددی
|
| کمی یا کیفی | ||
«کمی» (Quantitative): اندازهگیریها یا شمارشهایی که به صورت مقادیر عددی ذخیره شدهاند، دادههای کمی هستند. از جمله این موارد میتوان به درجه حرارت و قد افراد اشاره کرد.
«کیفی» (Qualitative): گروه یا دستهها، برای مثال دسته مدارک تحصیلی (دیپلم، فوق دیپلم، لیسانس، فوق لیسانس و دکترا) یا گروه رنگها (زرد، قرمز و آبی) از این جملهاند.
«ترتیبی» (Ordinal): چنین دادههایی دارای یک ترتیب طبیعی هستند. اندازه پیراهن (XL ،L ، M ،S و XXL) و مدارج تحصیلی (دبستان، راهنمایی، دبیرستان، کارشناسی، کارشناسی ارشد و دکترا) از این جملهاند.
«اسمی» (Nominal): اسامی دستهها، مانند وضعیت تاهل، جنسیت و رنگها از انواع دادههای اسمی هستند.
«عددی» (Numeric): دادههای عددی خود به دو دسته فاصلهای و نسبتی تقسیم میشوند. دادههای فاصلهای بر اساس مقیاس واحدهایی با اندازه برابر اندازهگیری میشوند. مقادیر ویژگیهای عددی دارای ترتیب هستند و میتوانند مثبت، صفر و یا منفی باشند. یک داده نسبتی، خصیصه عددی دارای یک صفر مطلق است. اگر اندازهها نسبتی باشند، میتوان از نسبت مقادیر با یکدیگر سخن گفت. به علاوه، مقادیر قابل مرتبسازی شدن هستند و میتوان تفاضل بین آنها، میانگین، میانه و مُد را محاسبه کرد.
برای مطالعه دقیقتر پیرامون چیستی ویژگی، بردار ویژگی و انواع ویژگیها، مطالعه مطلب «انواع ویژگی ها (خصیصه ها) و مفهوم بردار ویژگی در داده کاوی» توصیه میشود.
یادگیری نظارت شده در مقایسه با یادگیری نظارت نشده
اگر Y در دادههای آموزش وجود داشته باشد، روش یادگیری «نظارت شده» (Supervised) است. اگر Y وجود نداشته باشد (یا در صورت وجود از آن چشمپوشی شود)، یادگیری «نظارت نشده» (Unsupervised) است. یادگیری نظارت شده بر دو نوع است:
- رگرسیون: پاسخ Y کمی است.
- دستهبندی: متغیر پاسخ کیفی یا اسمی است.


رگرسیون
- Y کمی است یا کیفی؟
- هنگامی که Y کمی یا اسمی باشد، صرفا یک برچسب است. مجموعه برچسبها را میتوان به صورت زیر تعیین کرد:
{G ∈ G = {1, 2, ... , K
- اگر Y کمی است، الگوریتم یادگیری یک مساله رگرسیون است. اگر Y کیفی باشد، الگوریتم یادگیری مساله دستهبندی است.
به طور ایدهآل، یک الگوریتم یادگیری مشخصات زیر را دارد:
- الگوریتم «برازش» (Fit) مناسبی برای دادهها ارائه میکند. از آنجا که مدل با استفاده از دادههای آموزش توسعه داده شده، انتظار میرود که به خوبی برای دادههای آموزش برازش داده شود.
- الگوریتم تا حد ممکن «مستحکم» (Robust) است. از یک الگوریتم مستحکم انتظار میرود که برای دادههای تست نیز عملکرد خوبی داشته باشد زیرا دارای قدرت پیشبینی بالا است.
یک مدل پیشبینی خوب با استفاده از دادههای آموزش توسعه داده شده و باید روی دادههای تست نیز به خوبی کار کند. چنین چیزی ممکن است به صورت پیشفرض درست به نظر برسد، اما این موضوع حقیقت ندارد! هنگام برازش دادن داده آموزش، مدل نباید بیش از اندازه به دادهها نزدیک باشد، زیرا در آینده، هنگامی که دادههای جدید مشاهده شدند، هیچ تضمینی وجود ندارد که آنها یک کپی دقیق از دادههای آموزش باشند. از این رو، نیاز به مستحکم بودن مدل وجود دارد.
بنابراین، یک مدل سادهتر، در مقایسه با یک مدل پیچیده ممکن است گرایش بیشتری به مستحکم بودن داشته باشد. یعنی قدرت پیشبینی آن بالاتر باشد. یک مدل پیچیده، ممکن است از الگوی موجود در دادهها به طور نزدیکی پیروی کند و بنابراین کارایی آن در دادههای تست بسیار بد شود. از سوی دیگر، یک مدل ساده دادههای آموزش را به صورت تهاجمی برازش نمیکند. بنابراین، همواره «موازنهای» (trade-off) وجود دارد که از طریق مفاهیمی که در بخش «خطای آموزش در مقابل خطای تست» بیان شده، نشان داده میشوند. مطالب زیر جهت مطالعه دقیقتر و همراه با جزئیات در زمینه روشهای یادگیری هستند.
یادگیری نظارت نشده
- ماشین بردار پشتیبان — به زبان ساده
- ماشین بردار پشتیبان — به همراه کدنویسی پایتون و R
- الگوریتم K-نزدیکترین همسایگی به همراه کد پایتون
- استنتاج قوانین اولیه در داده کاوی -- روش One Rule به همراه شبه کد
- برترین الگوریتم های پیش بینی در یادگیری ماشین (Machine Learning)
- ماتریس مشابهت (Similarity) و فاصله (Distance) به همراه کدهای محاسباتی در R — راهنمای گام به گام
- ساخت شبکه عصبی (Neural Network) در پایتون — به زبان ساده
- یادگیری نظارت شده (Supervised Learning) با پایتون — راهنمای جامع
یادگیری نظارت شده
- خوشهبندی و تفسیر نتایج آن
- حل مسائل خوشهبندی با استفاده از الگوریتم کلونی زنبور عسل مصنوع
- اصطلاحات کاربردی خوشهبندی -- به زبان ساده
- خوشه بندی k میانگین (k-means Clustering) — به همراه کدهای R
- خوشه بندی سلسله مراتبی (Hierarchical Clustering) — به همراه کدهای R
- یادگیری نظارت نشده (Unsupervised Learning) با پایتون — راهنمای جامع و کاربردی
روشهای آماری
تحلیل مولفه اساسی (PCA) — راهنمای عملی به همراه کد نویسی در پایتون و R
رگرسیون خطی — مفهوم و محاسبات به زبان ساده
رگرسیون خطی چندگانه (Multiple Linear Regression) برای پایگاه های داده مبتنی گراف — به زبان ساده
رگرسیون غیر خطی در R — به زبان ساده
برازش منحنی (Curve Fitting) — به زبان ساده
رگرسیون کمترین زاویه (LAR Regression) — به زبان ساده
رگرسیون لوجستیک (Logistic Regression) — مفاهیم و کاربردها
رگرسیون خطی با متغیرهای طبقه ای در SPSS — راهنمای گام به گام
خطای آموزش در مقابل خطای تست
خطای آموزش این موضوع را منعکس میکند که دادهها به خوبی برازش داده شدهاند یا نه. خطای تست نشان میدهد که پیشبین در عمل، روی دادههای جدید کار میکند یا خیر. یک مدل با کمترین خطای آموزش الزاما کمترین خطای آزمون را فراهم نمیکند.
بایاس در مقابل واریانس
«بایاس» (سوگیری | Bias) اندازهای از این است که مدل چقدر به واقعیت نزدیک شده. اگر یک مدل خطی ارائه شود، هنگامی که رابطه واقعی بین X و Y درجه دوم باشد، مدل ارائه شده دارای سوگیری است. اگر الگوریتم یادگیری مشابهی بر چندین داده آموزش مستقل اعمال شود، تخمین پیشبین متفاوتی حاصل خواهد شد. اگر میانگین این پیشبینها مشابه مقدار واقعی آمار در نظر گرفته شده باشد، پیشبینی بدون سوگیری است. هنگامی که یک مدل شامل پارامترها و روابط پیچیده بیشتر باشد، بایاس به سمت کمتر بودن گرایش دارد.
مدلهای پیچیده دارای کوک تنظیمی هستند تا مدل را به خوبی تنظیم کنند، اما پیدا کردن موقعیت درست برای کوکهای بیشتر سختتر است. بایاس بخش سیستماتیک تفاوت میان مدل و حقیقت است. از سوی دیگر، واریانس سنجهای از میزان آن است که پیشبین تفاوتها را هنگامی که دادههای آموزش مختلفی مورد استفاده قرار میگیرند تخمین بزند. پیدا کردن توازنی میان بایاس و واریانس هدف توسعه یک مدل پیشبین بهینه است، زیرا صحت مدل تحت تاثیر هر دو آنها قرار میگیرد.
برازش در مقابل بیشبرازش
یک مدل «بیشبرازش» (Overfitting) شده دادههای آموزش را از نزدیک دنبال میکند. این مدل ممکن است سوگیری کمی داشته باشد اما واریانس آن بالا خواهد بود. این نشان میدهد که پیشبین روی دادههای آموزش عملکرد خوبی دارد، اما روی دادههای تست بد کار میکند. برای درک بهتر این مبحث بسیار مهم در دادهکاوی، مطالعه مطلب «بیش برازش (Overfitting)، کم برازش (Underfitting) و برازش مناسب — مفهوم و شناسایی» توصیه میشود.
ریسک تجربی در مقابل پیچیدگی مدل
«ریسک تجربی» (Empirical Risk) نرخ خطا بر مبنای دادههای آموزش است. اگر مدل پیچیدهتر باشد، گرایش به داشتن خطای تجربی کمتری دارد، اما در عین حال از استحکام کمتری نیز برخوردار است، به عبارت دیگر واریانس بالاتری دارد. برخی از روشهای دستهبندی مانند «ماشین بردار پشتیبان» (Support Vector Machine)، مستقیما بین ریسک تجربی و پیچیدگی مدل موازنه میکنند.
نکته: توجه به این نکته لازم است که همه مفاهیم بالا در یک مفهوم واحد خلاصه میشوند که «یک الگوریتم یادگیری باید توازن خوبی بین پیچیدگی و استحکام برقرار کند تا به بهترین شکل ممکن روی دادههای آموزش و نمونههای تست عمل کنند».
در ادامه، تصویری بسیار جالب از «عناصر یادگیری آماری» ارائه شده است که در تلاش برای تشریح ایده بالا است. شایان توجه است که نمودار ایستا در تلاش برای ضبط چیزی بسیار پویا است.
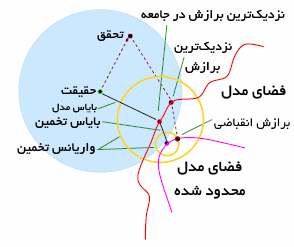
«تحقق» (Truth) در مرکز دایره آبی چیزی است که فرآیند دادهکاوی تلاش میکند به آن برسد. آنچه به پیشبینیگر ارائه میشود یک مجموعه داده نمونه است که «توزیع تجربی» (Empirical Ristribution) دارد و احتمالا در هرجای دایره آبی قرار میگیرد. یک مدل بزرگ (پیچیدهتر) با مدل کوچکتر (محدودتر) مقایسه میشود. دو دایره زرد نشانگر طیف مدلهای تخمین زده شده و به دست آمده تحت دو فضای مدل هستند. در فضای مدل بزرگتر، مدل میانگین به دست آمده با مرکز دایره زرد بزرگ نشان داده شده است.
تفاوت بین این مرکز و تحقق، بایاس برای فضای مدل بزرگتر است. به طور مشابه، تفاوت بین تحقق و مرکز دایره زرد کوچک، بایاس برای فضای مدل کوچکتر است. فضای مدل کوچکتر دارای بایاس بزرگتری است. از سوی دیگر، مدل نتیجه شده از فضای کوچکتر نسبت به فضای بزرگتر خیلی متفاوت نیست، از همین رو واریانس کوچکتر است. با اینکه فضای مدل بزرگتر به طور میانگین بهتر است (بایاس کوچکتر)، در مدل خاص احتمال بیشتری دارد که ضعیف باشد، زیرا واریانس از میانگین بالا است.
طیف یادگیری
از چشمانداز تاریخی، دو پایان برای طیف یادگیری وجود دارد. یک پایان در مدلهای سادهای که بسیار محدود هستند واقع شده است. از سوی دیگر، مدلهای بسیار پیچیدهای وجود دارند که میتوانند به شدت انعطافپذیر باشند. طی سالهای متمادی، فعالیتهای پژوهشی انجام شده در حوزه دادهکاوی موازنه میان پیچیدگی و انعطافپذیری را بهبود بخشیدهاند. از یک سو با قاعدهسازی به مدلهای پیچیده افزوده شده و از سوی دیگر افزونه مدل برای مدلهای ساده طراحی شده است.

ماهیت مساله دادهکاوی
روشهای کامپیوتری قدرت بیسابقهای را به دادهکاوی بخشیدهاند، اما در عین حال، شانس آنکه برخی روشها به صورت کورکورانه و بدون توجه به کاربرد آنها در مسائل مورد استفاده قرار بگیرند نیز افزایش دادهاند. بینش تحلیلی با هیچ نرمافزار کاربردی عرضه نمیشود؛ یک برنامه کاربردی بینش تحلیلی را افزایش میدهد. استفاده چشم بسته از یک نرمافزار برای حجم بالایی از رکوردها الزاما بینشی از دادهها فراهم نمیکند؛ در عوض این امکان وجود دارد که حقایقی نیز از دست بروند.
در ادامه، چشماندازی از روشهای دادهکاوی نظارت شده ارائه میشود که تمرکز آنها روی انجام پیشبینی است. مساله پیشبینی، تنها نوع مسائلی که دادهکاوی میتواند به حل آنها بپردازد نیست. دادهکاوی علمی میان رشتهای و شامل روشهایی است که با بزرگ شدن و افزایش مقیاس در دادههای ابعاد بالا، جریانهای داده سطح بالا، دادهکاوی توزیع شده، کاوش در تنظیمات شبکه و بسیای از دیگر زمینهها کاربرد دارد.
نمودار زیر چهار جنبه مهم از مدل یادگیری ماشینی را نشان میدهد. در یک مساله یادگیری (پیشبینی)، یک مجموعه از ویژگیهای X و پاسخ Y وجود دارد. X معمولا یک بردار است. در یادگیری نظارت شده Y معمولا یک عدد حقیقی است که میتواند متغیر کمی یا برچسبی برای متغیرهای دستهای باشد. «پیشبین» (Predictor) یک تابع ریاضیاتی F است که X را به Y نگاشت میکند.
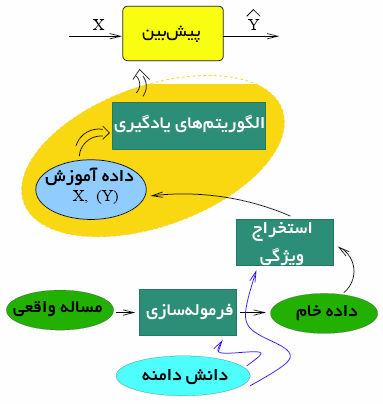
چگونه باید تابع F را پیدا کرد؟
رویکردهای مختلفی برای حل این مساله وجود دارد. برای مثال، پژوهشگران در دامنه پزشکی پیشبینیهای خود را بر مبنای تخصص فردی و دانش دامنه انجام میدهند. به عبارت دیگر، پزشکان از بیماران خود پیرامون نشانههای بیماری سوال میکنند و سپس بر اساس تخصص خود بیماری را تشخیص میدهند. نوع دیگری از رویکردها کاملا «داده محور» (data-driven) هستند. در این راستا، الگوریتمهای یادگیری پیشبینهایی را تولید میکنند.
رویکرد در نظر گرفته شده در دادهکاوی کاملا دادهمحور است. اولین گام در هر فرآیند ساخت مدل درک دادهها است که به صورت گرافیکی یا تحلیلی انجامپذیر است. هنگامی که دادهها پیچیده هستند، ادغام فرآیندهای بصری و تحلیلی بهترین نتیجه را حاصل میکند. این گام معمولا «تحلیل داده اکتشافی» (Exploratoy Data Analysis | EDA) نامیده میشود. دومین گام ساخت و ارزیابی یک مدل (مجموعهای از مدلهای کاندید) روی دادهها است. یک رویکرد استاندارد دریافت نمونه تصادفی از دادهها برای ساخت مدل و استفاده از دادهها برای ارزیابی کارایی مدل است.
بخشی از نمونه که برای ساخت مدل مورد استفاده قرار میگیرد نمونه آموزش (مجموعه آموزش یا دادههای آموزش) نامیده میشود و بخش دیگر، نمونه تست (مجموعه تست یا داده تست) است. نمونه تست برای توسعه ارتباط بین X و Y و مدل، پارامترها بر مبنای این دادهها تخمین زده میشوند. نمونه تست تنها هنگامی مورد استفاده قرار میگیرد که یک مدل در میان چند مدل کاندید قوی نهاییسازی میشود. استفاده از نمونه تست در فرآیند ساخت مدل نقش آن در ارزیابی نهایی مدل را منتفی میکند.
الگوریتمهای یادگیری مجموعه داده را اکتشاف کرده و رابطهای بین X و Y کشف میکنند. خروجی الگوریتمهای یادگیری تابعی است که X را به Y نگاشت میکنند. به چنین رویکردی «یادگیری نظارت شده» (Supervised Learning) گفته میشود. در الگوریتمهای «یادگیری نظارت نشده» (Unsupervised Learning) پاسخ Y شناخته شده نیست و در توسعه الگوریتم در نظر گرفته نشده است. در ظاهر، ساخت مدل ساده به نظر میرسد. هنگامی که دادهها موجود باشند، با کمک نرمافزار، چندین روش روی دادههای آموزش اعمال میشوند و مدل نهایی پس از بررسی کارایی در دادههای تست تعیین میشود. اگرچه، برای ایجاد یک مدل قابل اعتماد و اطمینان، درک ویژگیهای داده و اهداف مدلسازی حیاتی است. در واقع، حقیقت اغلب پیچیده است و فرمولهسازی یک مساله عملی به عنوان یک مساله دادهکاوی ممکن است چالشی اساسی باشد.
گاهی، صرفا دادههای خام برای تحلیل وجود دارند. در شرایط دیگر پژوهشگران دارای آزادی برای گردآوری دادهها هستند. گردآوری دادههای مرتبط کاری هزنیهبر و نیازمند دانش دامنه است. بین دادههای خام و ساخت مدل، یک گام سادهسازی دادهها وجود دارد که با عنوان «کاهش ابعاد» (Dimensionality Reduction) نامیده میشود. اغلب اوقات، دادههای خام به سادگی مدیریت نمیشوند و لایههایی از اطلاعات پنهان وجود دارد که باید پیش از ارسال به الگوریتم یادگیری آشکار شوند.
مزایا و معایب دادهکاوی
دادهکاوی دارای مزایا و معایب متعددی است. برخی از این موارد در ادامه بیان شدهاند.
مزایای دادهکاوی
- برای پیدا کردن کلاهبرداریهای احتمالی از دادهکاوی در بانکها و موسسات مالی استفاده میشود. این کار بر پایه تراکنشها، رفتار کاربر و الگوهای دادهها انجام میشود.
- به تبلیغکنندگان کمک میکند تا تبلیغات درستی را در اینترنت قرار دهند. این کار در صفحات وب و برپایه الگوریتمهای یادگیری ماشین انجام میشود. بدین شکل دادهکاوی هم به خریداران و هم فروشندگان محصولات و خدمات سود میرساند.
- فروشگاههای خردهفروشی و مواد غذایی از دادهکاوی برای چینش قفسههای فروشگاهی و تحلیل سبد خرید مشتریان خود استفاده میکنند. بدین شکل دادهکاوی به افزایش درآمد آنها کمک میکند.
- از دادهکاوی در زمینههای گوناگونی از جمله «بیوانفورماتیک» (bio-informatic)، پزشکی و ژنتیک با اهداف گوناگون شامل پیشگیری، تشخیص و درمان بیماریها استفاده میشود.
- دادهکاوی توسط سازمانهای قانونی برای شناسایی مظنونهای جنایی مورد استفاده قرار میگیرند.
معایب دادهکاوی
- روشهای دادهکاوی ۱۰۰٪ صحیح نیستند. بنابراین ممکن است در برخی شرایط عواقب بسیار بدی را در پی داشته باشند.
- کار با برخی سیستمها و روشهای دادهکاوی دشوار و نیازمند دانش قابل توجهی است.
- برخی از مسائل دادهکاوی حریم خصوصی و حتی امنیت کاربر را تحت تاثیر قرار میدهند.

در مجموع میتوان تاثیرات مثبت و منفی زیر را برای دادهکاوی بیان کرد.
تاثیرات مثبت
- پیشبینی گرایشهای آینده
- کمک در تصمیمگیری
- بهبود درآمد سازمانها و کاهش هزینههای آنها
- تحلیل سبد خرید
- تشخیص کلاهبرداری
اثرات منفی
- حریم خصوصی/امنیت کاربر
- حجم غافلگیرکننده دادهها
- هزینه بالا در گام پیادهسازی
- استفادههای احتمالی از اطلاعات
- عدم صحت احتمالی دادهها
کاربردهای دادهکاوی
از آنجا که دادهها اغلب بسیار ارزان و روشهای گردآوری داده تقریبا به طور کامل خودکارسازی شدهاند، در بسیاری از زمینهها، مانند کسبوکار، موفقیت بستگی به استفاده موثر و هوشمندانه از دادههای گردآوری شده دارد. در همین راستا باید گفت که تلاش ها در حوزه دادهکاوی در زمینههای گوناگونی در حال وقوع است.
مثالهایی که در ادامه میآید، تنها نشانگر برخی از حوزههای کاربرد جالب دادهکاوی (+) است. هر چه ارتباطات بیشتری میان رشتههای گوناگون به وقوع بپیوندد، دامنه کاربردها تکامل یافته و کاربردهای جدیدی ظهور میکنند. برخی از کاربردهای دادهکاوی در ادامه بیان و برای چندی از آنها توضیحاتی ارائه شده است.
- تجارت الکترونیک
- خودروهای خودران
- خطرات درمانهای جدید
- پژوهشهای فضایی
- تشخیص کلاهبرداری
- تحلیل تجارت سهام
- پیشبینی کسبوکار
- شبکههای اجتماعی
- تحلیل مشتریان
کسبوکار
- خردهفروشانی مانند «والمارت» (Walmart) اطلاعات را برای کمپینهای تبلیغاتی، پیشبینی آبوهوا، پیشبینی فروش و متعاقبا پیشبینی افزایش سهام استفاده میکنند.
- شرکتهای کارت اعتباری رکوردهای تراکنشها را برای کشف استفاده کلاهبردارانه از این کارتها بر اساس الگوری خرید مصرف کنندگان استفاده میکنند و حتی در صورت تغییر شدید الگوری خرید کاربر میتوانند دسترسی مصرفکننده را به کارت قطع کنند. (این کار به منظور حفظ امنیت کاربر اتفاق میافتد و در صورتی که محرز شود الگوی خرید مربوط به دارنده اصلی کارت است، مشکل عدم دسترسی حل خواهد شد.)


پژوهشهای ژنوم
- پروژه ژنوم انسان شعلههای علم داده را بالا برده و داده را برای خدمت به نوع بشر و در راستای توسعه داروهای جدید و ریشهکنی بیماریها به کار گرفته است. از اینرو نیاز به تشخیص الگو در دادهها وجود دارد که در حوزه علم «بیوانفورماتیک» (bioinformatic) انجام میشود.
- دانشمندان از دادههای «ریزآرایه» (Microarray) برای بررسی بیان ژن استفاده میکنند و روشهای پیچیده تحلیل داده را برای محاسبه نویز زمینهای و نرمالسازی دادهها به کار میگیرند.

بازیابی اطلاعات
- ترابایتها داده روی اینترنت انباشته شده است. از جمله این دادهها میتوان به دادههای تولید شده در «فیسبوک» (Facebook)، «توییتر» (Twitter)، «اینستاگرام» (Instagrams) و دیگر شبکههای اجتماعی اشاره کرد. این مخزن عظیم با اهداف گوناگونی، از تغییر و کنترل افکار عمومی جهت رای دادن به نامزد خاصی در انتخابات (استراتژی انتخاباتی) گرفته تا ارزیابی کارایی یک محصول (استراتژی بازاریابی و فروش) قابل کاوش هستند.
- دیگر جنبه رسانههای اجتماعی وجود اطلاعات چند رسانهای شامل دادههای بصری در عین وجود دادههای صوتی و دیگر انواع داده است. باید توجه کرد که کاوش دادههای غیر عددی و الفبایی کار سادهای نیست.
سیستمهای ارتباطی
«بازشناسی گفتار» حوزهای است که در آن روشهای مهم «بازشناسی الگو» (Pattern Recognition) توسعه یافتهاند و به دیگر دامنههای کاربرد انتقال داده شدهاند. تحلیل تصویر دیگر حوزه مهم از کاربردهای دادهکاوی است و روشهای «بازشناسی چهره» (Facial recognition) نوعی تمهید امنیتی محسوب میشوند.

اگر نوشته بالا برای شما مفید بوده، آموزشهای زیر نیز به شما پیشنهاد میشود:
- مجموعه آموزشهای برنامه نویسی پایتون (Python)
- مجموعه آموزشهای آمار، احتمالات و دادهکاوی
- مجموعه آموزشهای یادگیری ماشین و بازشناسی الگو
- مجموعه آموزشهای شبکههای عصبی مصنوعی
- مجموعه آموزشهای هوش محاسباتی
- آموزش برنامهنویسی R و نرمافزار R Studio
- مجموعه آموزشهای برنامه نویسی متلب (MATLAB)
^^








سلام.مطالب خیلی مفید و ارزنده بود.ممنونم
تشکر از مطلب خوب و کاملتون🙏🌹
مثل همیشه فوق العاده
سلام وقت بخیر
سپاس از زحمات بی شائبه شما
میشه سوال من رو پاسخ دهید
اگر به شما گفته شود که نتیجه دسته بندی درخت شما برای مثالهای فوق اشتباه است روشی برای تصحیح درخت بیان کنید که بدون نیاز به ساخت مجدد درخت قادر به دسته بندی صحیح نمونه های آموزشی و مثالهای فوق باشد.
از زحمات شما برای مطالب عالی و کاربردی سپاسگزارم
سلام با تشکر از اطلاعات خوبتون
ارتیاط بین داده کاوی و کاهش ابعاد چیه؟
سلام روزتون به خیر. من برای مقایسه روش پیشنهادی خودم با یکی از روشهای موجود داده کاوی نیاز به یک متخصص که تجربه کار عملی با یک یا چند روش داده کاوی دارم. ممنون میشم اگر کسی هست معرفی بفرمایید
سلام.من تعداد 100 تا ID اینستا دارم می خوام نودهای اصلی یا نودهای مهم را از طریق داده کاوی پیدا کنم.نمی دونم با چیکار کنم و از کجا شروع کنم ممنون میشم راهنمایی کنید.
با سلام متاسفانه در این حوزه بخش اصلی که همان داده و اطلاعات است مغفول مانده است در حوزه انواع تکنولوژی های داده مانند DATA PROFILING و DATA MINING اولین مرحله DATA STANDARDIZATION است که در حوزه مدیریت داده های اصلی MASTER DATA MANAGEMENT قرار می گیرد این حوزه در مورد خود هسته داده و اطلاعات بحث می کند و حوزه سمانیک وب نیز مشتق از همین تکنولوژی داده است امروزه با تولید انبوه داده ها جستجو و تحلیل در زباله های دیجیتالی انجام می گردد. در این بخش کیفیت و تضمین کیفیت داده نقش اساسی بازی می کند که امروزه استانداردهای ایزو ۸۰۰۰ با عنوان استانداردهای تضمین کیفیت داده برای همین امر توسعه پیدا کرده است. متاسفانه تمام تحلیل گران در حوزه داده و اطلاعات تمام هم و غم خود را به تحلیل های آماری، نرم افزاری و بانک های اطلاعاتی معطوف کرده اند و خود داده و اطلاعات مظلوم واقع شده است
جالب بود متشکرم
خوب است
بسیار مفید و کاربردی بود
خیلی ممنونم
خیلی خوب بود
ممنونم
سلام
من دانشجوی دکتری رشته آمار هستم و در پی پیدا کردن مطالبی راجع به این موضوع هستم.
سایت و مطالبی فوق العاده ای دارین.
خیلییی ممنونم از این بابت که این اطلاعات رو به صورت رایگان در اختیار علاقمندان قرار دادین.
امیدوارم که روزی شاهد موفقیت های شما باشیم.
عالی بود
جالب بود متشکرم