



الگوریتم اپریوری (Apriori) و کاوش الگوهای مکرر در دادهکاوی – به همراه کد پیادهسازی در R
اغلب الگوریتمهای یادگیری ماشین در دادهکاوی با دادههای عددی کار میکنند و در پیادهسازی و نحوه کار آنها گرایش به ریاضیات محض وجود دارد. اما، «کاوش قواعد وابستگی» (association rule mining) که از آن با عنوان «کاوش قواعد وابستگی» نیز یاد میشود، برای دادههای دستهای مناسب و محاسبات آن نسبت به بسیاری از دیگر الگوریتمها سادهتر است. این روش، یکی از راهکارهای مبتنی بر قواعد (rules)، برای کشف روابط جالب بین متغیرها در پایگاه دادههای بزرگ محسوب میشود. در کاوش قواعد وابستگی، قواعد قوی با استفاده از سنجه جذابیت (interestingness) شناسایی میشوند.




یکی از معروفترین مثالها در رابطه با قواعد وابستگی، این عبارت است: «مردهای جوان آمریکایی که بعد از ظهرهای جمعه پوشک بچه تهیه میکنند، مستعد خرید آبجو نیز هستند». این عبارت یک مثال مشهور از کاوش قواعد وابستگی عجیب از زندگی روزمره افراد است. چنین اطلاعاتی را میتوان به عنوان پایههایی برای تصمیمسازی درباره فعالیتهای بازار مانند قیمتگذاری تبلیغاتی یا تحلیل سبد خرید استفاده کرد.

قواعد وابستگی از دیدگاه ریاضی
مساله کاوش قواعد وابستگی را میتوان به صورت ریاضی و چنانکه در ادامه میآید دید.
- {...,I = {i_1,i_2 مجموعهای از ویژگیها (خصیصههای) دودویی است که به آنها اقلام گفته میشود.
- {...,D = {t_1,t_2 مجموعهای از تراکنشها است که پایگاه داده نامیده میشود.
- هر تراکنش در «D» شامل زیرمجموعهای از اقلام موجود در «I» است.
قواعد ساده وابستگی چنانکه در ادامه میآید هستند. لازم به ذکر است که در قاعده زیر، t1 مقدم و t2 نتیجه (موخر) محسوب میشود.
- t_1 ⇒ t_2 (در اینجا، t_i به طور کلی یک مورد مجزا یا مجموعهای از اقلام است)
مثال سوپرمارکت
مجموعه داده D (تراکنشی) به صورت زیر است.
![]()
نکات کلی پیرامون مجموعه داده
- در مجموعه داده D، مقدار «۱» نشاندهنده وجود یک آیتم در یک تراکنش و «۰» نشانگر عدم وجود آن است.
- مجموعه اقلام این مجموعه داده به صورت {I = {milk, bread, butter, beer, diapers است.
- قاعده {butter, bread} ⇒ {milk}، بدین معناست که اگر کره و نان خریداری شوند، مشتری شیر نیز میخرد.
استفاده از آستانهها برای روابط
پشتیبان: نشانگر آن است که یک مجموعه اقلام چند بار در پایگاه تکرار شده. این مقدار به عنوان کسر رکوردهای شامل X∪Y بر کل تعداد رکوردها در پایگاه داده است. برای مثال اگر پشتیبان یک مورد %0.1 باشد، بدین معناست که تنها %0.1 از تراکنشها حاوی آن مورد هستند.
Support (XY) = Support count of (XY) / Total number of transaction in D
اطمینان: کسر تعداد تراکنشهای حاوی X∪Y به کل تعداد رکوردهای شامل x است. این مقدار، مقیاسی از استحکام قواعد وابستگی است. برای مثال اگر اطمینان یک قاعده وابستگی X⇒Y is 80% باشد، بدین معناست که %۸۰ از تراکنشهایی که حاوی X هستند، شامل Y نیز میشوند.
Confidence (X|Y) = Support (XY) / Support (X)
الگوریتم اپریوری (Apriori)
الگوریتم اپریوری (Apriori)، روشی قابل اعمال روی رکوردهای پایگاه داده و به ویژه پایگاه داده تراکنشی یا رکوردهای حاوی تعداد مشخصی فیلد یا آیتم است. اپریوری یکی از الگوریتمهای دارای رویکرد «پایین به بالا» است که به تدریج رکوردهای پیچیده را با یکدیگر مقایسه میکنند. این الگوریتم یکی از روشهای کارآمد برای حل مسائل پیچیده کنونی موجود در دادهکاوی و یادگیری ماشین است.
اساسا، الگوریتم اپریوری بخشهایی از یک پایگاه داده بزرگتر را دریافت کرده و به آنها «امتیازدهی» کرده و یا آن بخشها را با دیگر مجموعهها به شیوه مرتب شدهای مقایسه میکند. از نتایج خروجی، برای تولید مجموعههایی استفاده میشود که مکررا در پایگاه داده اصلی به وقوع پیوستهاند.
برای کسب درک بهتر از الگوریتم میتوان برخی کاربردهای آن مانند «تحلیل سبد خرید» را مورد بررسی قرار داد. در این کاربرد، دادهکاو به دنبال کشف آن است که کدام اقلام با یکدیگر (در یک سبد خرید) خریداری شدهاند. در دیگر مثالی که میتوان پیرامون الگوهای مکرر زد، ابزارهای تحلیل مالی هستند که با بهرهگیری از الگوریتم اپریوری چگونگی داغ شدن سهامهای گوناگون با یکدیگر را نمایش میدهند. فلوچارت الگوریتم اپریوری (Apriori) در ادامه آورده شده است.
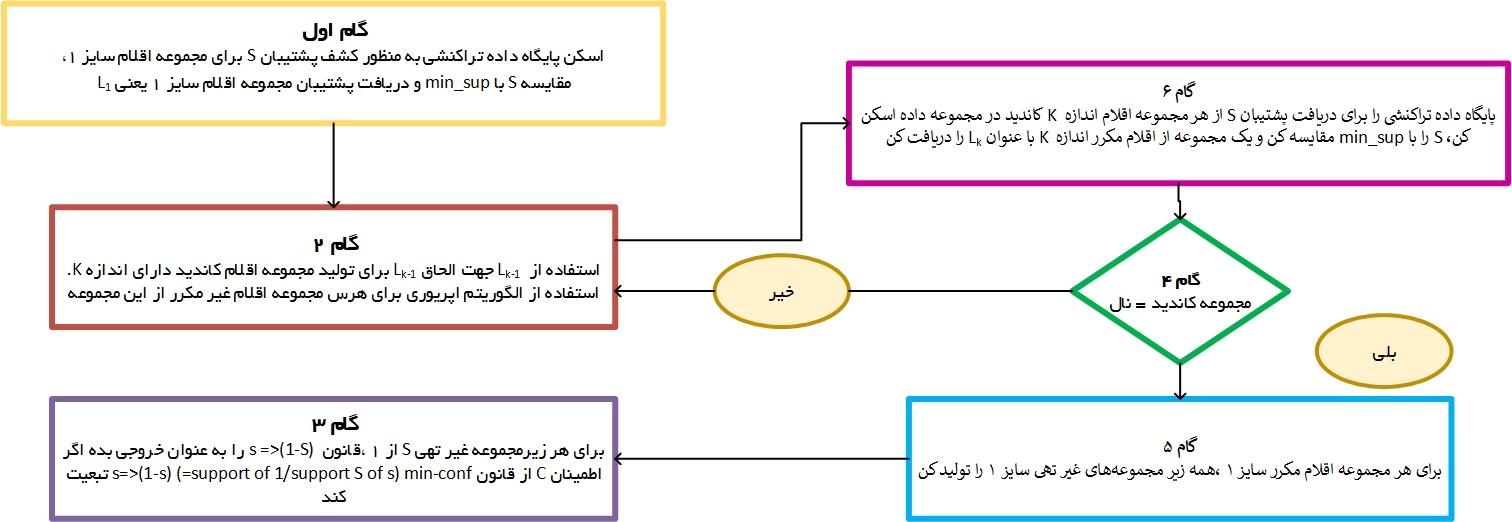
برای مشاهده تصویر بالا در ابعاد بزرگتر، اینجا کلیک کنید.
این روش، ممکن است به طور پیوسته با دیگر الگوریتمها استفاده شود تا به طور موثری دادهها را مرتبسازی و با یکدیگر مقایسه کند. اصل اپریوری میتواند تعداد اقلامی که نیاز به بررسی آنها است را کاهش دهد. این روش بیان میکند که اگر یک مجموعه اقلام فاقد تکرار است، پس همه زیرمجموعههای آن نیز نادر هستند. این امر بدین معناست که اگر {آبجو} فاقد تکرار بود، میتوان انتظار داشت که {آبجو، پیتزا} هم به همان میزان و یا حتی بیشتر، نادر باشند. بنابراین، برای یکی کردن لیست مجموعه اقلام محبوب، نیازی به در نظر گرفتن {آبجو، پیتزا} و یا هیچ یک از دیگر مجموعه اقلام حاوی آبجو، نخواهد بود.

یافتن مجموعه اقلام دارای پشتیبان بالا
با استفاده از اصل اپریوری، تعداد مجموعه اقلامی که باید بررسی شوند قابل هرس شدن هستند و لیستی از مجموعه اقلام محبوب (مکرر) با انجام مراحل زیر قابل مشاهده است.
گام ۰: آغاز با مجموعه اقلام حاوی تنها یک مورد، مانند {سیب} و {هلو}.
گام ۱: تعیین پشتیبان برای مجموعه اقلام. حفظ کردن مجموعه اقلامی که به حداقل آستانه پشتیبان میرسند و حذف مواردی که مطابقت ندارند.
گام ۲: استفاده از مجموعه اقلام گام ۱، ساخت همه پیکربندیهای مجموعه اقلام ممکن.
گام ۳: تکرار گامهای ۱ و ۲ تا هنگامی که مجموعه اقلام جدیدی وجود نداشته باشد.
این فرآیند تکرار شونده در انیمیشن زیر نمایش داده شده است.

همانطور که در انیمیشن نشان داده شده، {سیب} گزینهای با پشتیبان ضعیف محسوب میشود، از اینرو حذف شد و بنابراین نیاز به بررسی دیگر مجموعه اقلامی که حاوی سیب بودند نیست. این کار، تعداد مجموعه دادههایی که باید بررسی شوند را به بیش از نیمی کاهش میدهد.
شایان توجه است که آستانه پشتیبانی که در گام یک انتخاب میشود، میتواند بر اساس تحلیلهای رسمی یا تجربیات پیشین باشد. براساس نتایج حاصل از اعمال الگوریتم اپریوری، اگر پژوهشگر متوجه شود که فروش برخی از اقلام تاثیر قابل توجهی بر سود سازمان دارد، ممکن است از آن مقادیر برای تعیین آستانه استفاده کند.
یافتن قواعد با قابلیت اطمینان یا بالابری زیاد
پیش از این بیان شد که چگونه میتوان از الگوریتم اپریوری برای شناسایی مجموعه اقلام دارای پشتیبانی بالا استفاده کرد. قاعده مشابهی برای شناسایی انجمنهای اقلام با اطمینان یا بالابری زیاد قابل استفاده است. پیدا کردن قواعد با اطمینان یا بالابری زیاد به لحاظ محاسباتی کم هزینه است.

هنگامی که اقلام با پشتیبان بالا شناسایی شدند، مقادیر بالابری با استفاده از مقادیر پشتیبان محاسبه میشود. برای مثال برای یافتن قواعد با اطمینان بالا، اگر قاعده به صورت زیر باشد
{beer, chips -> apple}
دارای اطمینان پایینی است. دیگر قواعد با اقلام تشکیل دهنده و سیب در سمت راست جهت نما نیز دارای اطمینان پایینی هستند. به ویژه قواعد
{beer -> apple, chips}
{chips -> apple, beer}
اطمینان بسیار پایینی دارند. مانند گذشته، قواعد اقلام کاندید با اطمینان یا بالابری پایین را میتوان با استفاده از الگوریتم اپریوری هرس کرد، بنابراین قواعد کاندید کمتری برای بررسی باقی میماند.
محدودیتها
هزینه محاسباتی بالا: روش اپریوری به لحاظ محاسباتی بسیار پر هزینه است. حتی اگر الگوریتم اپریوری تعداد اقلام کاندید برای بررسی را کاهش دهد، در صورتی که موجودی فروشگاه زیاد یا آستانه پشتیبان کم باشد میزان باقیمانده همچنان عدد بزرگی خواهد بود. یک راهکار جایگزین، کاهش تعداد مقایسهها با استفاده از ساختارهای پیشرفته داده مانند جدولهای هش برای مرتبسازی اقلام کاندید به شیوه موثرتر است.
انجمنهای جعلی: تحلیل صورت کالاهای بزرگ مجموعه اقلام بیشتری را در برمیگیرد و آستانه پشتیبان ممکن است برای شناسایی انجمنهای مشخصی کاهش پیدا کند. اگرچه، کاهش آستانه پشتیبان ممکن است تعداد انجمنهای جعلی کشف شده را افزایش دهد. برای حصول اطمینان از اینکه انجمنهای شناسایی شده قابل تعمیم هستند، میتوان آنها را از مجموعه داده آموزش به دست آورد، پیش از آنکه پشتیبان و اطمینان ارزیابی شده برای آنها در یک مجموعه داده جدا قرا گیرد.
پیادهسازی الگوریتم اپریوری در زبان برنامهنویسی R
بستهای که در زبان برنامهنویسی R برای پیادهسازی الگوریتم اپریوری مورد استفاده قرار میگیرد arules نام دارد.

تابعی که برای کاوش قواعد وابستگی استفاده میشود به صورت زیر است.
آرگومانهای تابع apriori به صورت زیر هستند.
داده: ساختار دادهای که قابل اعمال به تراکنشها است (برای مثال، ماتریس دودویی یا چارچوب داده).
پارامتر: یک لیست اسمی (دارای مقادیر غیر عددی) شامل مقادیر آستانه برای پشتیبان و اطمینان است. مقدار پیشفرض این آرگومان لیستی از حداقل پشتیبان ۰.۱ ، حداقل اطمینان ۰.۸، بیشینه ۱۰ آیتم (maxlen) و حداکثر زمان برای بررسی زیر مجموعهها به مدت ۵ ثانیه است (maxtime). کد کامل الگوریتم اپریوری در زبان برنامهنویسی R از این لینک در دسترس است.
اگر نوشته بالا برای شما مفید بوده، آموزشهای زیر نیز به شما پیشنهاد میشوند:
- مجموعه آموزشهای آمار، احتمالات و دادهکاوی
- مجموعه آموزشهای یادگیری ماشین و بازشناسی الگو
- مجموعه آموزشهای هوش محاسباتی
- مجموعه آموزشهای شبکههای عصبی مصنوعی
- آموزش برنامهنویسی R و نرمافزار R Studio
- الگوریتم اپریوری (Apriori) به همراه کد پیادهسازی در پایتون — کاوش قواعد وابستگی در دادهکاوی
^^










