



الگوریتم اپریوری (Apriori) – راهنمای ساده و سریع
در این مطلب، «الگوریتم اپریوری» (Apriori Algorithm) که یکی از روشهای پر کاربرد برای کاوش مجموعه اقلام مکرر و قواعد وابستگی (association rule mining) است، مورد بررسی قرار میگیرد. پیش از آغاز بحث اصلی، مفهوم مجموعه اقلام مکرر (frequent itemset) و مجموعه اقلام کاندید (candidate itemset) شرح داده میشود.


- یک مجموعه اقلام مکرر، مجموعه اقلامی است که پشتیبان (Support) آن بیشتر از حداقل پشتیبان تعریف شده توسط کاربر باشد (با Lk علامتگذاری شده و در آن k اندازه مجموعه اقلام است).
- یک مجموعه اقلام کاندید، مجموعه اقلام مکرر بالقوه است (که با Ck علامتگذاری شده و در آن k اندازه مجموعه اقلام است).
الگوریتم اپریوری
این الگوریتم توسط اگراوال (Agrawal) و همکاران، در مرکز تحقیقات IBM Almaden کشف شد و از آن می توان برای تولید کلیه مجموعه اقلام مکرر استفاده کرد.
در ادامه، این الگوریتم مورد بررسی قرار میگیرد.
پاس ۱
- مجموعه اقلام کاندید را در C1 را تولید کن
- مجموعه اقلام مکرر را در L1 ذخیره کن
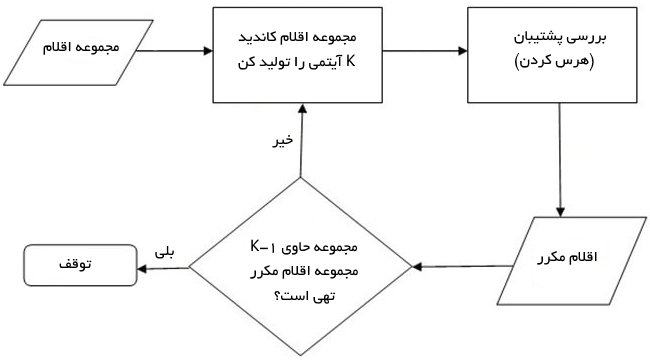
پاس k
۱. مجموعه اقلام کاندید در Ck را از مجموعه اقلام مکرر در Lk-1 تولید کن
۱. Lk-1p با Lk-1q را به صورت زیر به یکدیگر متصل کن
insert into Ck
select p.item1, p.item2, . . . , p.itemk-1, q.itemk-1
from Lk-1 p, Lk-1q
where p.item1 = q.item1, . . . p.itemk-2 = q.itemk-2, p.itemk-1 < q.itemk-1
۲. همه (k-1) زیرمجموعه از زیرمجموعههای کاندید در Ck را تولید کن
۳. همه مجموعه اقلام کاندید را در جایی که (k-1) زیر مجموعه از مجموعه اقلام کاندید، مجموعه اقلام مکرر Lk-1 نیست، از Ck هرس کن
۲. پایگاه داده تراکنشی را اسکن کن تا پشتیبان برای هر مجموعه اقلام کاندید در Ck را تعیین کنی
۳. مجموعه اقلام مکرر را در Lk ذخیره کن

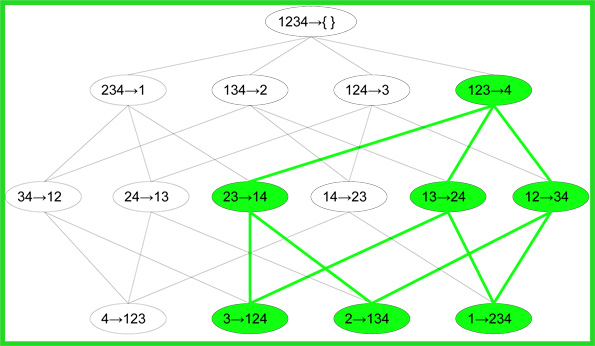
مثال اول
فرض میشود که حداقل پشتیبان تعیین شده توسط کاربر برابر با ٪۵۰ است.
ورودی: مجموعه داده تراکنشی زیر ورودی مساله است.

مجموعه اقلام کاندید: آنچه در تصویر زیر نمایش داده شده، مجموعه اقلام کاندید در C2 است.

مجموعه اقلام مکرر: در تصویر زیر، مجموعه اقلام مکرر در L2 نشان داده شده است.

مثال دوم
فرض میشود که حداقل پشتیبان تعیین شده توسط کاربر ۴۰٪ است. برای مجموعه داده تراکنشی که در ادامه آمده، همه مجموعه اقلام مکرر کاوش میشوند.
ورودی: پایگاهداده تراکنشی زیر ورودی مساله است.

پاس ۱:

پاس ۲:
C2

- تا هنگامی که همه زیرمجموعههای این مجموعه، اقلام مکرر هستند، هیچ چیز هرس نخواهد شد.

پاس ۳:
- برای ساخت C3 تنها به اقلامی توجه میشود که اولین مورد آنها مشابه است (در پاس K، اولین k-2 آیتم باید مطابقت پیدا کنند).

- هرس کردن، ABE را حذف میکند زیرا BE مکرر نیست.
- تراکنشها باید در پایگاه داده اسکن شوند.
L3

پاس ۴:
- اولین k-2 = 2 آیتم باید در پاس k = 4 مطابقت پیدا کنند.

هرس کردن
- برای ABCD مکرر بودن ACD ،ABD ،ABC و BCD چک میشود. این آیتمها در همه کیسها هستند، بنابراین ABCD هرس نمیشود.
- برای ACDE، مکرر بودن ADE ،ACE ،ACD و CDE بررسی میشود. این آیتمها در کلیه کیسها هستند پس ACDE هرس نمیشود.
- هر دو مکرر هستند
پاس ۵:
برای پاس ۵، نمیتوان هیچ کاندیدی ایجاد کرد، زیرا هیچ دو مجموعه اقلام مکرری با ۴ آیتم وجود ندارند که با ۳ آیتم مشابه آغاز شوند.

مزایا و معایب روش اپریوری
این روش دارای مزایا و معایبی است که در ادامه به برخی از آنها اشاره شده است.

مزایا:
- مصرف کمتر حافظه
- پیادهسازی آسان
- استفاده از برخی ویژگیها برای هرس کردن که موجب میشود مجموعه اقلام باقیمانده برای بررسی نهایی کمتر شوند.
معایب:
- نیازمند اسکنهای زیاد از پایگاه داده است.
- تنها یک آستانه پشتیبان حداقلی منفرد را میپذیرد.
- فقط برای پایگاه دادههای کوچک مطلوب است.
اگر نوشته بالا برای شما مفید بوده، آموزشهای زیر نیز به شما پیشنهاد میشود:
- مجموعه آموزشهای آمار، احتمالات و دادهکاوی
- مجموعه آموزشهای یادگیری ماشین و بازشناسی الگو
- آموزش برنامهنویسی R و نرمافزار R Studio
- مجموعه آموزشهای هوش محاسباتی
- مجموعه آموزشهای برنامه نویسی متلب (MATLAB)
^^










