



یادگیری نظارت نشده (Unsupervised Learning) با پایتون – راهنمای جامع و کاربردی
«یادگیری نظارت نشده» (Unsupervised Learning) یک دسته از روشهای «یادگیری ماشین» (Machine Learning) برای کشف الگوهای موجود در میان دادهها است. دادههای ارائه شده به الگوریتم نظارت نشده دارای برچسب نیستند، بدین معنا که متغیر ورودی (X) بدون هیچ متغیر خروجی متناظری داده شده است. در یادگیری نظارت نشده، الگوریتمها به حال خود رها میشوند تا ساختارهای جالب موجود در میان دادهها را کشف کنند. «یان لیوکن» (Yann LeCun)، دانشمند فرانسوی کامپیوتر و پدر بنیانگذار «شبکه عصبی پیچشی» (Convolutional Neural Networks | CNN)، یادگیری ماشین نظارت نشده را چنین تعریف کرده است: «آموزش دادن ماشینها برای یادگیری برای خودشان بدون آنکه به آنها صراحتا گفته شود کاری که انجام میدهند درست محسوب میشود یا غلط. یادگیری نظارت نشده راهی به سوی هوش مصنوعی «حقیقی» است.»




یادگیری نظارت شده و نظارت نشده
در یادگیری نظارت شده، سیستم در تلاش برای یادگیری از مثالهای قبلی است که به آن داده شده. (به عبارت دیگر، در یادگیری نظارت شده، سیستم در تلاش برای پیدا کردن الگوها از مثالهایی است که به آن داده شده.)
بنابراین، اگر مجموعه داده برچسبگذاری شده باشد، به عنوان مساله نظارت شده مطرح میشود و اگر مجموعه داده بدون برچسب باشد مساله نظارت نشده است.

تصویر سمت چپ نمونهای از یادگیری نظارت شده است، و در آن برای پیدا کردن بهترین برازش بین ویژگیها از روش رگرسیون استفاده شده است. در حالیکه در یادگیری نظارت نشده، ورودیها براساس ویژگیها و پیشبینی بر اساس آنکه به کدام خوشه تعلق دارد مجزا میشود.
مفاهیم مهم
- «ویژگی» (Feature): یک متغیر ورودی که برای انجام پیشبینیها مورد استفاده قرار میگیرد.
- «پیشبینیها» (Predictions): خروجی مدل، در هنگامی که نمونه ورودی فراهم شده است.
- «نمونه» (Example): یک سطر از مجموعه داده را گویند. یک نمونه شامل یک یا تعداد بیشتری ویژگی و احتمالا یک برچسب است.
- «برچسب» (Label): نتیجه یک ویژگی را گویند.

آمادهسازی دادهها برای یادگیری نظارت نشده
در این مطلب، از «مجموعه داده گل زنبق» (Iris flower data set) یا «مجموعه داده زنبق فیشر» (Fisher's Iris data set) برای انجام پیشبینیهای سریع استفاده میشود. مجموعه داده مذکور شامل یک مجموعه از ۱۵۰ رکورد و ۵ ویژگی (مشخصه | attribute) است. این ویژگیها «طول گلبرگ» (Petal Length)، «عرض گلبرک» (Petal Width)، «طول کاسبرگ» (Sepal Length)، «عرض کاسبرگ» (Sepal width) و برچسبها هستند.
برچسبها در این مجموعه داده در واقع تعیین میکنند که هر نمونه با طول کاسبرگ و گلبرگ خود از کدام گونه گل زنبق است. گونههای موجود در این مجموعه داده شامل «زنبق سِتوسا» (Iris Setosa)، «زنبق ویرجینیکا» (Iris Virginica) و «زنبق وِرسیکالر» (Iris Versicolor) هستند. برای الگوریتم یادگیری نظارت نشده، چهار ویژگی گل زنبق به مدل داده میشود و مدل پیشبینی میکند که هر نمونه به کدام دسته تعلق دارد. از کتابخانه sklearn در پایتون برای بارگذاری مجموعه داده Iris و کتابخانه matplotlib به منظور بصریسازی دادهها استفاده شده است. قطعه کدی که در زیر آمده به منظور کاوش مجموعه داده مورد استفاده قرار میگیرد.
['DESCR', 'data', 'feature_names', 'target', 'target_names'] ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)'] [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2] ['setosa' 'versicolor' 'virginica']
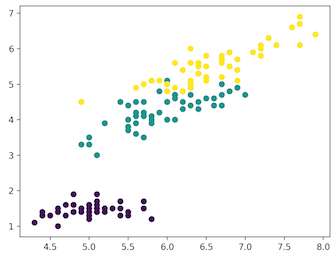

خوشهبندی
در خوشهبندی (Clustering)، دادهها به چندین گروه تقسیمبندی میشوند.

به بیان ساده، هدف جداسازی گروههایی با «صفات» (traits) مشترک (منظور ویژگیهای مشترک است) و تخصیص آنها به خوشهها است.

در تصویر بالا، نقاط داده موجود در نمودار سمت چپ دادههای خامی هستند که «دستهبندی» (Classification) روی آنها انجام نشده است. تصویر سمت راست دادههای خوشهبندی شده هستند (دادهها بر پایه ویژگیهایشان دستهبندی شدهاند). هنگامی که ورودی که براساس آن پیشبینی انجام میشود به مدل داده شد، برپایه ویژگیهایی که دارد خوشهای که به آن متعلق است مورد بررسی قرار میگیرد و پیشبینی انجام میشود.
خوشهبندی K-Means در پایتون
«خوشهبندی K-means» یک الگوریتم خوشهبندی محسوب میشود که هدف آن پیدا کردن بیشینه محلی است. در این الگوریتم، ابتدا تعداد خوشههای مورد نظر باید انتخاب شوند. از آنجا که برای مجموعه داده Iris سه دسته وجود دارد، در اینجا الگوریتم طوری برنامهریزی میشود تا دادهها را با پاس دادن پارامتر n_clusters به مدل KMeans در سه خوشه قرار دهد. اکنون، به طور تصادفی سه نقطه (ورودی) به سه دسته تخصیص پیدا میکنند. برپایه فاصله «مرکزوار» (Centroid) بین هر دو نقطهای، ورودی بعدی به خوشه مربوطه تخصیص پیدا میکند. اکنون مراکز دستهها مجددا برای همه خوشهها انتخاب میشوند.

هر مرکزوار از یک خوشه، مجموعهای از مقادیر ویژگیها است که گروههای نتیجه را تعیین میکند. آزمودن وزنهای ویژگی مرکزوار میتواند به طور کیفی برای تفسیر اینکه هر گروه از دادهها حاوی چه نوع زنبقی هستند مورد استفاده قرار بگیرد. در این راستا، مدل KMeans، از کتابخانه sklearn ایمپورت میشود و با برازش ویژگیها پیشبینی انجام میدهد.
کد پیادهسازی الگوریتم K-Means در پایتون
[0] [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 2 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 1 2 1 1 1 1 2 1 1 1 1 1 1 2 2 1 1 1 1 2 1 2 1 2 1 1 2 2 1 1 1 1 1 2 1 1 1 1 2 1 1 1 2 1 1 1 2 1 1 2]
خوشهبندی سلسلهمراتبی
«خوشهبندی سلسلهمراتبی» (Hierarchical Clustering)، همانطور که از نام آن بر میآید الگوریتمی است که یک سلسله مراتب از خوشهها میسازد. این الگوریتم با همه دادههایی که به خوشه خودشان تخصیص داده شدهاند آغاز به کار میکند.
سپس، دو خوشه نزدیکتر به یکدیگر در یک خوشه مشترک ملحق میشوند. در پایان، این الگوریتم با حالتی که تنها یک خوشه مجزا باقیمانده به کار خود پایان میدهد. تکمیل خوشهبندی سلسله مراتبی را میتوان با «دِندروگرام» (Dendrogram) نشان داد. اکنون میتوان یک مثال از خوشهبندی سلسلهمراتبی دادههای غلات را مشاهده کرد. مجموعه داده مربوط به این مثال از اینجا (+) در دسترس هستند.
پیادهسازی خوشهبندی سلسلهمراتبی در پایتون
تفاوت بین K-Means و خوشهبندی سلسلهمراتبی
- خوشهبندی سلسلهمراتبی نمیتواند «کلانداده» (مِهداده | Big Data) را به خوبی مدیریت کند، اما خوشهبندی K-Means توانایی انجام این کار را دارد. دلیل این امر خطی بودن پیچیدگی زمانی K Means و برابری آن با (O(n است، در حالیکه خوشهبندی سلسلهمراتبی از درجه دوم (O(n2 است.
- در خوشهبندی K-Means، با توجه به اینکه انتخاب خوشهها به صورت دلخواه انجام میشود، نتایج تولید شده طی اجراهای متعدد الگوریتم ممکن است متفاوت باشند.
- K-Means کشف شده تا هنگامی که شکل خوشه «فراکرهای» (hyper spherical) (برای مثال دایره و کره) است به خوبی کار کند.
- K-Means با دادههای دارای نویز (noisy data) نمیتواند به خوبی کار کند، در حالیکه خوشهبندی سلسلهمراتبی می تواند از یک مجموعه داده نویزی برای خوشهبندی استفاده کند.

خوشهبندی t-SNE
t-SNE یکی از روشهای یادگیری نظارت نشده برای بصریسازی دادهها است. این کلمه در واقع سرنامی برای عبارت «t-distributed stochastic neighbor embedding» محسوب میشود. این الگوریتم دادههای ابعاد بالا را به فضای ۲ یا ۳ بُعدی نگاشت میکند که قابل بصریسازی هستند.
به طور خاص، این الگوریتم هر شی دارای ابعاد بالا را با نقاط دو یا سه بُعدی به شیوهای نگاشت میکند که اشیای مشابه با نقاط نزدیک و اشیای غیر مشابه با نقاط دور از هم با احتمال بالا نگاشت میشوند.
پیادهسازی خوشهبندی t-SNE در پایتون برای مجموعه داده Iris
در اینجا با توجه به اینکه مجموعه داده Iris دارای چهار ویژگی (4d) است، تبدیل و در یک شکل دوبُعدی نمایش داده شده. به طور مشابه، مدل t-SNE قابل اعمال بر یک مجموعه داده با n-ویژگی است.

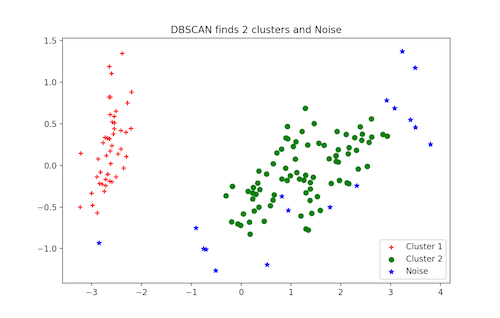
خوشهبندی DBSCAN
DBSCAN (خوشهبندی فضایی مبتنی بر چگالی کاربردهای دارای نویز) یک الگوریتم خوشهبندی محبوب است که به عنوان جایگزینی برای K-means در تحلیلهای پیشبین مورد استفاده قرار میگیرد. این روش خوشهبندی نیازمند آن نیست که کاربر تعداد خوشهها را برای اجرا به آن بدهد. اما در عوض، باید دو پارامتر دیگر توسط کاربر تنظیم شوند.
پیادهسازی scikit-learn این الگوریتم، دارای مقادیر پیشفرض برای پارامترهای eps و min_samples است. اما عموما انتظار میرود که کاربر این مقادیر را تنظیم کند. پارامتر eps بیشینه فاصله بین دو نقطه داده است که باید در یک همسایگی مشابه در نظر گرفته شود. پارامتر min_samples حداقل مقدار نقاط داده در یک همسایگی است که باید در نظر گرفته شود.
پیادهسازی خوشهبندی DBSCAN در پایتون

دیگر روشهای یادگیری نظارت نشده
- «تحلیل مولفه اساسی» (Principal Component Analysis | PCA)
- روشهای تشخیص ناهنجاری (اغلب نظارت نشده هستند، در این راستا مطالعه دو مطلب «تشخیص ناهنجاری با استفاده از داده کاوی — بررسی موردی همراه با کدهای پایتون» و «تشخیص ناهنجاری در داده کاوی — با استفاده از زبان برنامهنویسی R» توصیه میشود.)
- «خودرمزگذارها» (Autoencoders)
- «شبکه باور عمیق» (Deep Belief Network)
- «یادگیری هبیان/هبین» (Hebbian Learning)
- شبکههای تولید کننده رقابتی (Generative Adversarial Networks | GAN)
- نقشههای خودسازماندهنده (Self-Organizing maps | SOM)

اگر مطلب بالا برای شما مفید بوده، آموزشهای زیر نیز به شما پیشنهاد میشوند:
- مجموعه آموزشهای آمار، احتمالات و دادهکاوی
- مجموعه آموزشهای یادگیری ماشین و بازشناسی الگو
- مجموعه آموزشهای هوش محاسباتی
- مجموعه آموزشهای شبکههای عصبی مصنوعی
- گنجینه آموزشهای برنامه نویسی پایتون (Python)
- آموزش برنامهنویسی R و نرمافزار R Studio
- مجموعه آموزشهای برنامه نویسی متلب (MATLAB)
- علم داده، تحلیل داده، دادهکاوی و یادگیری ماشین ــ تفاوتها و شباهتها
^^









خط 3 لطفا اصلاح شود:
غلط: “در یادگیری نظارت شده، الگوریتمها به حال خود رها میشوند”
صحیح: “در یادگیری نظارت نشده، الگوریتمها به حال خود رها میشوند”
با سلام و احترام؛
صمیمانه از همراهی شما با مجله فرادرس و ارائه بازخورد سپاسگزاریم.
این مورد اصلاح شد.
برای شما آرزوی سلامتی و موفقیت داریم.