



روش های بهینه سازی در یادگیری ماشین – راهنمای کاربردی
در این مطلب، فهرستی از محبوبترین و پرکاربردترین روش های بهینه سازی در یادگیری ماشین به همراه منابع آموزش روش های بهینه سازی ارائه شده است.



روش های بهینه سازی در یادگیری ماشین
«پودیا پریل» (Judea Pearl)، از جمله دانشمندان علوم کامپیوتری است که نسبت به «هوش مصنوعی» (Artificial Intelligence) و «شبکههای بیزی» (Bayesian Network) دیدگاه و رویکرد آماری دارد. او درباره «یادگیری عمیق» (Deep Learning) چنین میگوید:
همه دستاوردهای تاثیرگذار یادگیری عمیق در برازش منحنی خلاصه میشوند.
تقلیل یافتهترین شکل «یادگیری ماشین» (Machine Learning) را میتوان برازش منحنی دانست. از جهاتی میتوان گفت که داشتن چنین رویکردی درست است. مدلهای یادگیری ماشین معمولا بر اساس اصول «همگرایی» (Convergence) و در واقع، «برازش» (Fitting) دادهها در مدل بنا نهاده شدهاند. اگرچه، این رویکرد منجر به «هوش عمومی مصنوعی» (Artificial General Intelligence | AGI) میشود که همچنان موضوعی مورد بحث است. این در حالی است که در حال حاضر، «شبکههای عصبی عمیق» (Deep Neural Networks) از بهترین راهکارها برای مسائل یادگیری ماشین محسوب میشوند و از «روشهای بهینهسازی» (Optimization) برای رسیدن به هدف استفاده میکنند.
روشهای بهینهسازی پایهای معمولا به سه دسته روشهای «مرتبه اول» (First Order)، «مرتبه بالا» (High Order) و «روشهای بهینهسازی فاقد مشتق» (Derivative-Free Optimisation Methods) تقسیم میشوند. به طور معمول، روشهای بهینهسازی موجود، در دسته بهینه سازی مرتبه اول قرار میگیرند؛ از جمله این روشها میتوان به «گرادیان کاهشی» (Gradient Descent) و انواع آن اشاره کرد. برای مطالعه بیشتر پیرامون بهینهسازی، مطالب زیر پیشنهاد میشوند.
- بهینه سازی (ریاضیاتی) چیست؟ — راهنمای جامع
- بهینه سازی چند هدفه چیست؟ — راهنمای جامع
- مقدمهای بر بهینه سازی به کمک الگوریتمهای فراابتکاری و محاسبات تکاملی
همچنین، پیشتر، برخی از الگوریتم های بهینه سازی در یادگیری ماشین در مجله فرادرس به طور جامع، کامل و کاربردی، همراه با مثالهای فراوان و ارائه کدهای پیادهسازی در زبانهای برنامهنویسی گوناگون مورد بررسی قرار گرفتند.

علاقهمندان میتوانند برای آشنایی با این روش های بهینه سازی در یادگیری ماشین مطالب زیر را مطالعه کنند.
- رویکرد هوش ازدحامی با استفاده از کلونی زنبور عسل مصنوعی برای حل مسائل بهینهسازی
- حل مسائل خوشهبندی با استفاده از الگوریتم کلونی زنبور عسل مصنوعی
- الگوریتم بهینه سازی فاخته – از صفر تا صد
- الگوریتم کرم شب تاب — از صفر تا صد
- الگوریتم ژنتیک – از صفر تا صد
- گرادیان کاهشی (Gradient Descent) و پیاده سازی آن در پایتون — راهنمای کاربردی
- الگوریتم کلونی مورچگان — از صفر تا صد
- الگوریتم بهینه سازی کلونی مورچگان در جاوا — راهنمای کاربردی
- شبیه سازی تبرید (Simulated Annealing) – به زبان ساده
- بهینه سازی نسبت طلایی — از صفر تا صد (+ دانلود فیلم آموزش رایگان)
- مهمترین الگوریتمهای یادگیری ماشین (به همراه کدهای پایتون و R) — بخش یازدهم و پایانی: الگوریتمهای ارتقای گرادیان
در مطالبی از مجله فرادرس نیز به پرسشهای رایج در زمینه بهینهسازی پاسخ داده شده است. لینک دسترسی به این مطالب در ادامه آمده است.
- پاسخ سئوالات رایج در خصوص مسائل بهینهسازی
- چگونه مسائل بهینه سازی با متغیرهای مخلوط گسسته و پیوسته را حل کنیم؟
- بهینه سازی با شبکه عصبی — پادکست پرسش و پاسخ
در نهایت، در مطالبی از مجله فرادرس که طی آنها به بهینه سازی در یادگیری ماشین پرداخته شده بود، کاربردهای بهینه سازی، پیادهسازی آن روی مسائل جهانواقعی و ابزارهای پیادهسازی مورد بررسی قرار گرفته بودند.
این مطالب در ادامه ارائه شدهاند تا علاقهمندان امکان دسترسی سریع و مطالعه آنها را داشته باشند.
- کاربرد بهینه سازی در اقتصاد — همراه با مثال
- کاربرد بهینه سازی در هندسه — به زبان ساده (+ دانلود فیلم آموزش رایگان)
- مساله تقسیم بندی در بهینه سازی — به زبان ساده
- رگرسیون خطی با گرادیان کاهشی (Gradient Descent) – پیاده سازی با پایتون
- تقلب نامه (Cheat Sheet) تولباکس بهینه سازی در متلب — راهنمای کاربردی
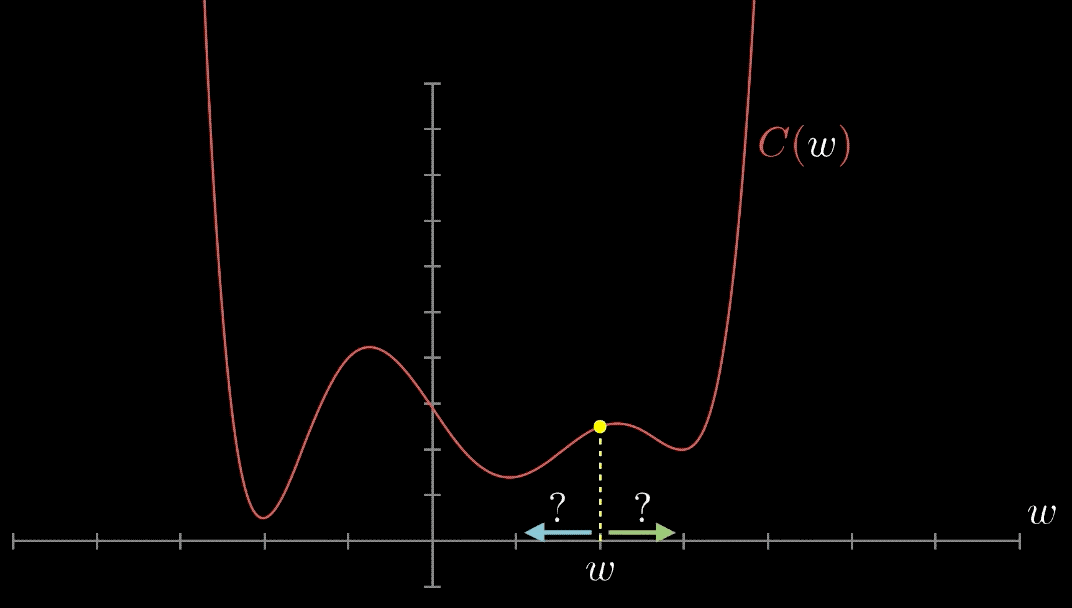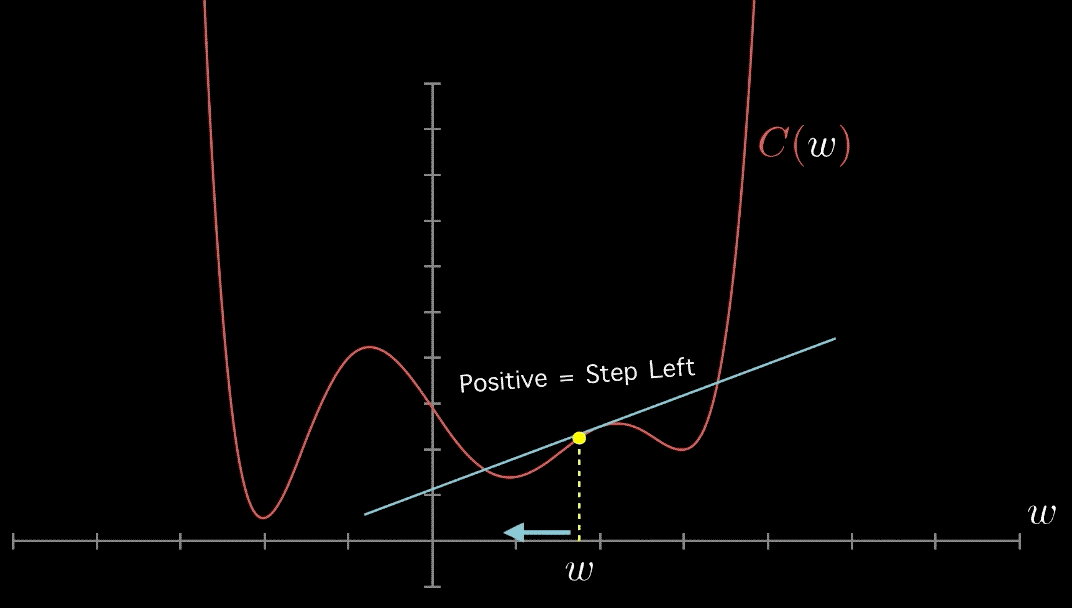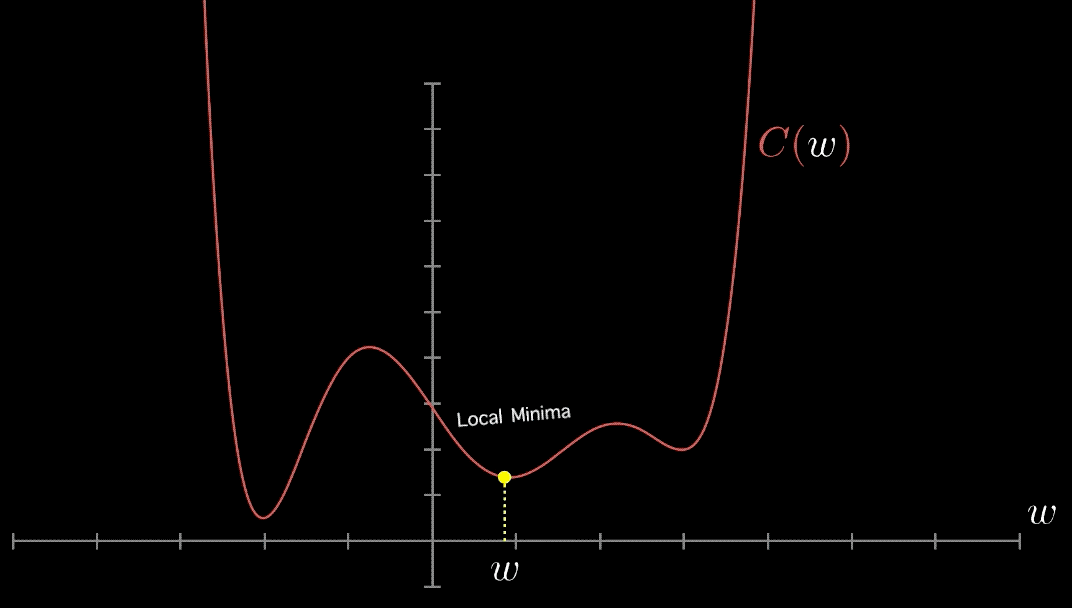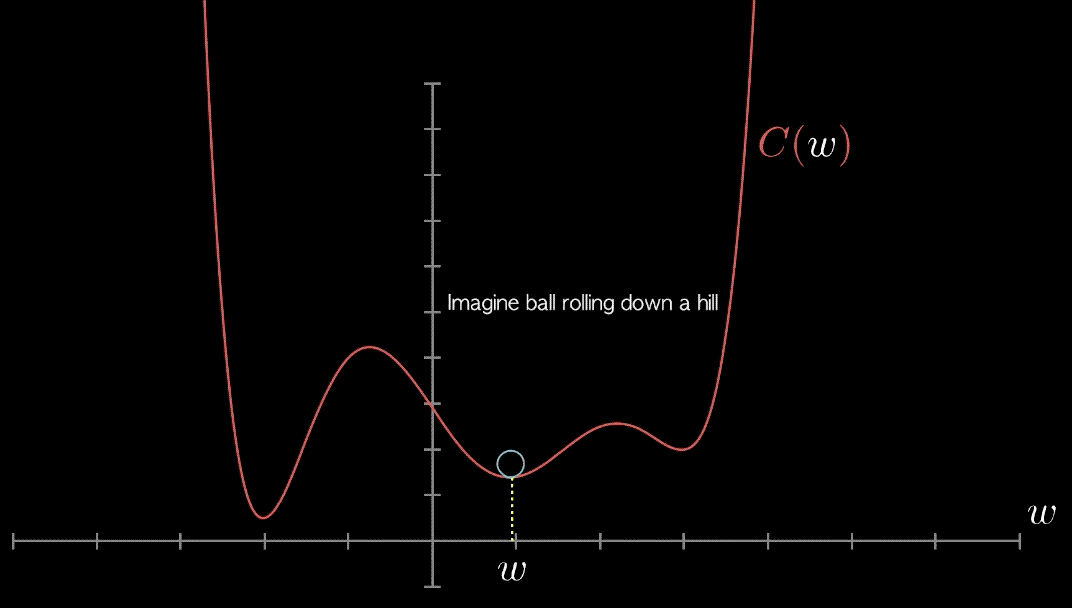
در ادامه و مطابق با بررسی موردی انجام شده با عنوان «بررسی موردی پیرامون روش های بهینه سازی از چشمانداز یادگیری ماشین» (A Survey of Optimization Methods from a Machine Learning Perspective) که توسط «شی لیانگ» و همکاران او انجام شده است، برخی از برترین روشهای بهینهسازی مورد استفاده که افراد اغلب در مجلات یادگیری ماشین با آنها مواجه میشوند معرفی شدهاند و مورد بررسی قرار گرفتهاند.
گرادیان کاهشی
«روش گرادیان کاهشی» (Gradient Descent Method) محبوبترین روش بهینهسازی محسوب میشود. ایده نهفته در پس این روش، به روز رسانی «تکرار شونده» (Iteratively) در جهت مثبت «تابع هدف» (Objective Function) است.

با هر به روز رسانی، این روش مدل را به سمت پیدا کردن هدف هدایت میکند و به تدریج به مقدار بهینه تابع هدف همگرا میشود.

گرادیان کاهشی تصادفی
«گرادیان کاهشی تصادفی» (Stochastic Gradient Descent | SGD) برای حل مشکل پیچیدگی محاسباتی موجود در هر تکرار برای دادههای کلان مقیاس در گرادیان کاهشی، معرفی شد.

معادله این روش به صورت زیر است.

دریافت مقادیر و تنظیم آنها به صورت بازگشتی روی پارامترهای گوناگون به منظور کاهش «تابع زیان» (Loss Function)، «پسانتشار» (BackPropagation | BP) نامیده میشود. در این روش، یک نمونه برای به روز رسانی گرادیان (تتا | Theta) مورد استفاده قرار میگیرد؛ به جای آنکه به طور مستقیم مقدار دقیق گرادیان محاسبه شود.
گرادیان تصادفی یک تخمین «بدون سوگیری» (Unbiased) از گرادیان حقیقی (Real Gradient) ارائه میکند. این روش بهینهسازی زمان به روز رسانی را برای سر و کار داشتن با تعداد زیادی از نمونهها کاهش میدهد و میزان خاصی از «افزونگی» (Redundancy) را حذف میکند.
روش نرخ یادگیری تطبیقی
نرخ یادگیری یکی از «فراپارامترهایی» (Hyperparameters) است که در بهینهسازی وجود دارد. نرخ یادگیری تصمیم میگیرد که مدل از بخش خاصی از دادهها پرش کند. اگر نرخ یادگیری بالا باشد، مدل ممکن است که جنبههای ظریفتر دادهها را از دست بدهد و در واقع، به آنها توجه نداشته باشد. اگر این مقدار کم باشد، برای کاربردهای جهان واقعی مطلوب است. نرخ یادگیری تاثیر قابل توجهی روی گرادیان کاهشی تصادفی (SGD) دارد. تنظیم مقدار صحیح برای نرخ یادگیری کاری چالشبرانگیز است. روشهای تطبیقی ارائه شدهاند تا این تنظیمات را به صورت خودکار انجام دهند.

انواع تطبیقی SGD به طور گسترده در شبکههای عصبی عمیق (DNN) مورد استفاده قرار گرفتهاند. روشهایی مانند «آدادِلتا» (AdaDelta)، «آراِماِسپراپ» (RMSProp) و «آدام» (Adam) از «میانگینگیری نمایی» (Exponential Averaging) برای فراهم کردن به روز رسانیهای موثر و ساده کردن محاسبات استفاده میکنند.
- Adagrad: وزنها با گرادیان بالا نرخ یادگیری پایینی خواهند داشت و بالعکس.
- RMSprop: روش Adagrad را به صورتی تنظیم میکند که نرخ یادگیری به طور یکنواخت رو به کاهش آن را کاهش دهد.
- Adam: شباهت زیادی به RMSProp دارد، با این تفاوت که تکانه دارد.
- ADMM: «روش متناوب جهت ضرب» (Alternating Direction Method of Multipliers) جایگزین دیگری برای گرادیان کاهشی تصادفی است. تفاوت بین گرادیان کاهشی تصادفی و روش متناوب جهت ضرب آن است که نرخ یادگیری دیگر ثابت نیست. این مورد با استفاده از همه گرادیانهای تاریخی تجمیع شده تا آخرین تکرار، محاسبه میشوند.
روش گرادیان مزدوج
رویکرد «گرادیان مزدوج» (Conjugate Gradient) برای حل سیستمهای معادلات خطی بزرگ و مسائل بهینهسازی غیر خطی مورد استفاده قرار میگیرند. روشهای مرتبه اول سرعت همگرایی کمتری دارند. این در حالی است که روشهای مرتبه دوم زیاد از منابع استفاده میکنند و اصطلاحا «منابع سنگین» (Resource-Heavy) هستند.
روش بهینهسازی گرادیان مزدوج یک الگوریتم میانی است که مزایای اطلاعات روشهای مرتبه اول را ضمن حصول اطمینان از سرعت همگرایی روشهای مرتبه بالا ارائه میکند.

بهینهسازی بدون مشتق
در برخی از مسائل بهینهسازی، میتوان از گرادیان به این دلیل استفاده کرد که مشتق (Derivative) تابع هدف وجود ندارد و یا محاسبه آن دشوار است. این مسائل نقاطی هستند که بهینهسازی بدون مشتق در آنها مطرح میشود. این روشها از «الگوریتم هیوریستیک» (Heuristic Algorithm) استفاده میکنند. الگوریتمهای هیوریستیک روشهایی را انتخاب میکند که در حال حاضر به خوبی کار کردهاند؛ به جای آنکه راهکارها را به صورت سیستماتیک به دست آورد.

بهینهسازی مرتبه صفر
بهینهسازی مرتبه صفر (Zeroth Order Optimisation) اخیرا برای حل کمبودهای بهینهسازی بدون مشتق ارائه شده است. روشهای بهینهسازی بدون مشتق مقیاس دادن به مسائل بزرگ را دشوار میکنند و از فقدان تحلیلهای نرخ همگرایی رنج میبرند. مزایای بهینهسازی مرتبه صفر عبارتند از:
- سادگی پیادهسازی با صرفا ویرایشهای ناچیزی از الگوریتمهای متداول مبتنی بر گرادیان
- تخمین بهینه بودن از نظر محاسباتی برای مشتقاتی که محاسبات آنها دشوار است
- نرخ همگرایی خوب و قابل مقایسه با الگوریتمهای مرتبه اول
یادگیری متا
بهینهسازی متا در «یادگیری متا» (Meta Learning) روش محبوبی است. هدف یادگیری متا به دست آورد یادگیری سریع است که در عوض، گرادیان کاهشی را در بهینهسازی صحیحتر میکند. خود فرایند بهینهسازی را میتوان به عنوان یک مسئله یادگیری برای یادگیری گرادیان پیشبینی به جای یک الگوریتم گرادیان کاهشی در نظر گرفت. به دلیل مشابهت بین به روز رسانی گرادیان در پسانتشار و به روز رسانی سلول در «حافظه کوتاه مدت بلند» (Long Short-Term Memory | LSTM) اغلب به عنوان یک «متا بهینهساز» (Meta-Optimiser) مورد استفاده قرار میگیرد.
در حالی که «الگوریتم یادگیری متا مدل آگنوستیک» (Model-Agnostic Meta Learning Algorithm | MAML) روش دیگری است که پارامترهای مدلهای در معرض روشهای گرادیان کاهشی را میآموزد که شامل «دستهبندی» (Classification)، «رگرسیون» (Regression) و «یادگیری تقویتی» (Reinforcement Learning) میشوند. ایده اصلی نهفته در پس الگوریتم مدل آگنوستیک آن است که چند وظیفه به طور همزمان آغاز شوند و سپس، جهت گرادیان مصنوعی وظایف گوناگون دریافت شود تا یک مدل متداول پایهای یاد گرفته شود.

اینها تنها برخی از روشهای بهینهسازی پر کاربرد هستند. صرفنظر از این موضوع، روشهای دیگری نیز برای بهینهسازی وجود دارند که پرداختن به آنها از حوصله این بحث خارج است. مسئله بهینهسازی برای یادگیری عمیق در همینجا به پایان نمیرسد، زیرا همه مسائل تحت «بهینهسازی محدب» (Convex Optimisation) مطرح نمیشوند.

«بهینهسازی غیر محدب» (Non-Convex Optimisation) یکی از مشکلات در مسئله بهینهسازی است. یک رویکرد برای حل مسائل بهینهسازی غیر محدب، تبدیل آنها به مسائل بهینهسازی محدب است. راهکار دیگر، استفاده از روشهای خاص بهینهسازی مانند «گرادیان کاهشی پروجکشن» (Projection Gradient Descent)، «بهینهسازی متناوب» (Alternating Minimisation)، «بیشینهسازی امید ریاضی» (Expectation Maximisation | EM) و گرادیان تصادفی و انواع آن است.
منابع آموزش روش های بهینه سازی در یادگیری ماشین
در ادامه، منابع آموزش روش های بهینه سازی در یادگیری ماشین معرفی شدهاند.
- برای دسترسی به بیش از ۷,۴۱۲ دقیقه فیلم آموزشی و به زبان فارسی الگوریتم های بهینه سازی هوشمند + اینجا کلیک کنید.

آموزش مبانی محاسبات تکاملی و بهینه سازی هوشمند
طول مدت دوره آموزشی «آموزش مبانی محاسبات تکاملی و بهینه سازی هوشمند» که مدرس آن دکتر سید مصطفی کلامی هریس است، برابر با شش ساعت و دوازده دقیقه است. این آموزش در واقع به نوعی درس شماره صفر تمام دروس آموزش بهینهسازی محسوب میشود.
در این دوره آموزشی، مفهوم بهینهسازی، مباحث پایهای مربوط به مسائل بهینهسازی و الگوریتمهای مورد استفاده در این راستا مورد بحث و بررسی قرار گرفتهاند. برخی از مباحث مورد بررسی در این فیلم آموزشی در ادامه بیان شدهاند.
- مفاهیم پایه بهینهسازی
- اجزای یک مسئله بهینهسازی، تابع هدف و فضای جستجو
- اجزای یک مسئله بهینهسازی، قیدها و محدودیتها
- مبانی بهینهسازی چندهدفه
- بررسی ساختار کلی الگوریتم های بهینه سازی
- ساختار کلی و نحوه عملکرد الگوریتمهای تکاملی
- روشهای توصیف متغیرها و فضای جستجو
- روشهای برخورد با قیدها
آموزش بهینه سازی چند هدفه در متلب
طول مدت دوره آموزشی «آموزش بهینه سازی چند هدفه در متلب» که مدرس آن دکتر سید مصطفی کلامی هریس است، برابر با هجده ساعت و پنجاه و سه دقیقه است. در این دوره آموزشی، مفهوم بهینه سازی چند هدفه و تفاوت آن با مسائل بهینه سازی یک هدفه، تقسیمبندی روش های بهینه سازی چند هدفه و دیگر مباحث مرتبط با روش های بهینه سازی چند هدفه مورد بحث و بررسی قرار گرفتهاند.

برخی از مباحث مورد بررسی در این فیلم آموزشی در ادامه بیان شدهاند.
- مبانی بهینهسازی چند هدفه و بیان تفاوتهای آن با مسئله بهینهسازی یک هدفه
- تقسیمبندی روشهای بهینهسازی چندهدفه
- روش های بهینه سازی چندهدفه کلاسیک
- روش چبیشف (Chebyshev)، به عنوان حالت کلی روشهای مبتنی بر آرمان
- روش تبدیل به قید یا ε-Constrainet (بخوانید Epsilon Constraint)
- مقدمهسازی برای طرح الگوریتم های تکاملی چند هدفه

آموزش بهینهسازی مقید در متلب
طول مدت دوره آموزشی «آموزش بهینهسازی مقید در متلب» که مدرس آن دکتر سید مصطفی کلامی هریس است، برابر با نُه ساعت و بیست و شش دقیقه است. در این دوره آموزشی، مفهوم بهینهسازی مقید و دیگر مباحث مرتبط با روش های بهینه سازی مقید مورد بحث و بررسی قرار گرفتهاند.

برخی از مباحث مورد بررسی در این فیلم آموزشی در ادامه بیان شدهاند.
- مبانی بهینهسازی مقید
- بهینهسازی مقید مبتنی بر تابع جریمه
- رویکردهای مبتنی بر قابل قبول نگه داشتن جوابها برای بهینهسازی مقید
- حل مساله تخصیص منابع یا Resource Allocation
- بهینهسازی مقید با استفاده از روش های بهینه سازی چند هدفه
- بهینهسازی مقید با استفاده از روشهای همتکاملی
آموزش مقدماتی پیادهسازی مسائل بهینهسازی در پایتون
طول مدت دوره آموزشی «آموزش مقدماتی پیادهسازی مسائل بهینه سازی در پایتون)» که مدرس آن مهندس پژمان اقبالی است، برابر با چهار ساعت و سه دقیقه است. در این دوره آموزشی، مسائل معروف و شناخته شدهای مانند بهینهسازی کولهپشتی، مسئله کوتاهترین مسیر در گراف و دنباله فیبوناچی با بهینهسازی و «برنامهنویسی پویا» (Dynamic Programming) مورد بحث و بررسی قرار گرفتهاند.
برخی از مباحث مورد بررسی در این فیلم آموزشی در ادامه بیان شدهاند.
- مسائل بهینهسازی کولهپشتی
- مسائل بهینه سازی گراف
- برنامه نویسی پویا

آموزش پیادهسازی الگوریتمهای تکاملی و فراابتکاری در سیشارپ
طول مدت دوره آموزشی «آموزش پیاده سازی الگوریتم های تکاملی و فراابتکاری در سی شارپ» که مدرس آن دکتر سید مصطفی کلامی هریس است، برابر با نُه ساعت و یک دقیقه است. در این دوره آموزشی، برخی از محبوبترین الگوریتمهای بهینهسازی مورد بحث و بررسی قرار گرفتهاند و در زبان برنامهنویسی سیشارپ پیادهسازی شدهاند.

برخی از مباحث مورد بررسی در این فیلم آموزشی در ادامه بیان شدهاند.
- مرور مبانی تئوری الگوریتم بهینه سازی ازدحام ذرات یا PSO
- پیاده سازی الگوریتم PSO در سی شارپ
- تبدیل برنامه قبلی به صورت شی گرا
- افزودن رویداد و تبدیل برنامه به حالت تحت ویندوز
- بهبود برنامه تحت ویندوز با افزودن کنترل های پارامتری
- جداسازی تعریف مساله و الگوریتم با تعریف کلاس مجزا
- تعریف متغیرهای تصمیم پیوسته با بازه متفاوت
- تعریف متغیرهای تصمیم گسسته باینری و عدد صحیح
- مرور مبانی تئوری الگوریتم شبیه سازی تبرید و پیاده سازی آن
- اتصال برنامه SA به برنامه تحت ویندوز قبلی
- مرور مبانی تئوری الگوریتم های ژنتیک و نحوه کارکرد آن ها
- پیاده سازی عملی الگوریتم ژنتیک در سی شارپ
- اتصال برنامه GA به برنامه تحت ویندوز قبلی
آموزش بهینهسازی سبد سهام با روش های بهینه سازی کلاسیک و هوشمند در متلب
طول مدت دوره آموزشی «آموزش بهینهسازی سبد سهام با روشهای بهینهسازی کلاسیک و هوشمند در متلب» که مدرس آن دکتر سید مصطفی کلامی هریس است، برابر با چهار ساعت و سی و دو دقیقه است. در این دوره آموزشی، ضمن بررسی مدلهای ریاضی مسئله بهینهسازی سبد سهام، بهینهسازی سبد سهام کلاسیک با بهرهگیری از روشهای بهینهسازی کلاسیک و هوشمند انجام شده است.

برخی از مباحث مورد بررسی در این فیلم آموزشی در ادامه بیان شدهاند.
- مدل های ریاضی مساله بهینهسازی سبد سهام
- بهینهسازی سبد سهام با استفاده از روش های بهینه سازی کلاسیک
- بهینهسازی سبد سهام با استفاده از روش های بهینه سازی هوشمند و فرا ابتکاری
برای کسب اطلاعات بیشتر پیرامون فیلم آموزش بهینه سازی سبد سهام با روش های بهینه سازی کلاسیک و هوشمند در متلب و مشاهده پیشنمایشهایی از آن + اینجا کلیک کنید.
آموزش انواع الگوریتم های بهینه سازی و تکاملی الهام گرفته از طبیعت
روش های بهینه سازی یادگیری ماشین گوناگونی وجود دارند. در فرادرس، فیلمهای آموزشی و به زبان فارسی برای محبوب ترین الگوریتم های بهینه سازی ارائه شده است.
در ادامه، آموزشهای الگوریتم های بهینه سازی معرفی شدهاند.

- فیلم آموزش بهینهسازی مبتنی بر جغرافیای زیستی یا BBO در متلب (مدرس دوره: دکتر سید مصطفی کلامی هریس، طول مدت دوره: یک ساعت و پنجاه و یک دقیقه) + اینجا کلیک کنید.
- فیلم آموزش الگوریتم چرخه آب برای حل مسائل بهینهسازی (مدرس دوره: دکتر علی سعداله، طول مدت دوره: چهار ساعت و چهار دقیقه) + اینجا کلیک کنید.
- فیلم آموزش الگوریتم بهینهسازی جهش قورباغه یا SFLA در متلب (مدرس دوره: دکتر سید مصطفی کلامی هریس، طول مدت دوره: سه ساعت و سی و پنج دقیقه) + اینجا کلیک کنید.
- فیلم آموزش الگوریتم بهینهسازی مبتنی بر آموزش و یادگیری یا TLBO (مدرس دوره: دکتر سید مصطفی کلامی هریس، طول مدت دوره: یک ساعت و پانزده دقیقه) + اینجا کلیک کنید.
- فیلم آموزش الگوریتم PSO، شامل مباحث تئوری و عملی (مدرس دوره: دکتر سید مصطفی کلامی هریس، طول مدت دوره: نه ساعت و پنجاه و سه دقیقه) + اینجا کلیک کنید.
- فیلم آموزش پیادهسازی و برنامهنویسی الگوریتم ازدحام ذرات (PSO) گسسته باینری (مدرس دوره: دکتر اسماعیل آتشپز گرگری، طول مدت دوره: یک ساعت و چهل دقیقه) + اینجا کلیک کنید.
- فیلم آموزش الگوریتم فرهنگی یا Cultural Algorithm در متلب (مدرس دوره: دکتر سید مصطفی کلامی هریس، طول مدت دوره: دو ساعت و سی و شش دقیقه) + اینجا کلیک کنید.
- فیلم آموزش الگوریتم گروه میگوها با پیادهسازی در MATLAB (مدرس دوره: دکتر بهداد آرندیان، طول مدت دوره: یک ساعت و بیست دقیقه) + اینجا کلیک کنید.
- فیلم آموزش جستجوی ممنوع یا Tabu Search در متلب (مدرس دوره: دکتر سید مصطفی کلامی هریس، طول مدت دوره: دو ساعت و سی و شش دقیقه) + اینجا کلیک کنید.
- فیلم آموزش الگوریتم بهینهسازی علف هرز مهاجم یا IWO در متلب (مدرس دوره: دکتر سید مصطفی کلامی هریس، طول مدت دوره: دو ساعت و بیست و شش دقیقه) + اینجا کلیک کنید.
- فیلم آموزش جامع کلونی زنبور مصنوعی یا Artificial Bee Colony در متلب (مدرس دوره: دکتر سید مصطفی کلامی هریس، طول مدت دوره: دو ساعت و چهل و یک دقیقه) + اینجا کلیک کنید.
- فیلم آموزش الگوریتم جستجوی هارمونی یا Harmony Search در متلب (مدرس دوره: دکتر سید مصطفی کلامی هریس، طول مدت دوره: یک ساعت و پنجاه و چهار دقیقه) + اینجا کلیک کنید.
- فیلم آموزش الگوریتم زنبورها یا Bees Algorithm در متلب (مدرس دوره: دکتر سید مصطفی کلامی هریس، طول مدت دوره: دو ساعت و یک دقیقه) + اینجا کلیک کنید.
- فیلم آموزش الگوریتم تکامل تفاضلی، شامل مباحث تئوری و عملی (مدرس دوره: دکتر سید مصطفی کلامی هریس، طول مدت دوره: یک ساعت و چهار دقیقه) + اینجا کلیک کنید.
- فیلم آموزش الگوریتم کرم شبتاب یا Firefly Algorithm در متلب (مدرس دوره: دکتر سید مصطفی کلامی هریس، طول مدت دوره: یک ساعت و دوازده دقیقه) + اینجا کلیک کنید.
- فیلم آموزش الگوریتم بهینهسازی ملخ (GOA) و پیادهسازی آن در MATLAB (مدرس دوره: مهندس حسن سعادتمند، طول مدت دوره: پنج ساعت و هفت دقیقه) + اینجا کلیک کنید.
- فیلم آموزش الگوریتم رقابت استعماری در متلب (مدرس دوره: دکتر سید مصطفی کلامی هریس، طول مدت دوره: سیزده ساعت و هشت دقیقه) + اینجا کلیک کنید.
- فیلم آموزش شبیهسازی تبرید یا Simulated Annealing در متلب (مدرس دوره: دکتر سید مصطفی کلامی هریس، طول مدت دوره: چهار ساعت و بیست و هشت دقیقه) + اینجا کلیک کنید.
- فیلم آموزش الگوریتم بهینهسازی شیرمورچه و پیادهسازی آن در متلب (مدرس دوره: دکتر بهداد آرندیان، طول مدت دوره: یک ساعت و چهل و نه دقیقه) + اینجا کلیک کنید.
- فیلم آموزش الگوریتم مورچگان در متلب (مدرس دوره: دکتر سید مصطفی کلامی هریس، طول مدت دوره: شش ساعت و چهل و هفت دقیقه) + اینجا کلیک کنید.









