



دسته بندی متن با پایتون و کرس (Keras) – راهنمای جامع
روزی، مساله فهمیدن حال افراد از طریق اینترنت بیشتر شبیه به موضوع یک فیلم تخیلی بود تا واقعیتی امکانپذیر، اما امروزه این کار در ابعاد خاصی قابل انجام است. پس از مطالعه این راهنما که در آن چگونگی دستهبندی متن با «زبان برنامهنویسی پایتون» (Python Programming Language) و کتابخانه متنباز کِرَس (Keras) آموزش داده شده، مخاطبان قادر به انجام چنین کاری خواهند بود. با مطالعه این راهنمای جامع و کاربردی، ضمن فراگیری روش دستهبندی متن، میتوان درک خوبی از پیشرفتهای شبکههای عصبی (عمیق) و چگونگی اعمال آنها روی متن به دست آورد. خواندن احوال از روی متن با بهرهگیری از «یادگیری ماشین» (Machine Learning)، «تحلیل احساسات» (Sentiment Analysis) نامیده میشود و یکی از مباحث برجسته دستهبندی متن است. این زمینه در اغلب پژوهشهای حوزه «پردازش زبان طبیعی» ( Natural Language Processing | NLP) نیز کاربرد دارد. از دیگر کاربردهای متداول دستهبندی متن میتوان به «تشخیص هرزنامه» (Detection of Spam)، تگ زدن خودکار کوئریهای مشتریان و دستهبندی متن در دستههای از پیش تعریف شده اشاره کرد. اما چگونه میتوان متنها را دستهبندی کرد؟




انتخاب مجموعه داده
پیش از آغاز کار، باید نگاهی به دادههای موجود انداخت. دادههای مورد استفاده در این مطلب، متعلق به «مجموعه داده جملات برچسبگذاری شده احساسات» (+) هستند که از مخزن یادگیری ماشین UC (یا UCI Machine Learning Repository) دریافت شده است.
این مخزن منبع فوقالعادهای برای دادههای یادگیری ماشین است که میتوان از آنها برای آزمودن الگوریتمها استفاده کرد. مجموعه داده مذکور شامل نقد و بررسیهای برچسبگذاری شده از وبسایتهای IMDB، «آمازون» (Amazon) و «یلپ» (Yelp) است. هر نقد و بررسی امتیازی از ۰ (برای عواطف منفی) تا ۱ (برای عواطف مثبت) دارد. اکنون باید پوشه موجود را در پوشه data استخراج و در ادامه، دادهها را با بهرهگیری از کتابخانه Pandas بارگذاری کرد.
نتیجه قطعه کد بالا به صورت زیر خواهد بود.
sentence Wow... Loved this place. label 1 source yelp Name: 0, dtype: object
با این مجموعه داده، میتوان مدلی را آموزش داد که عواطف یک جمله را پیشبینی کند. در این راستا، باید زمانی را به فکر کردن پیرامون اینکه چگونه میتوان مدل پیشبینی دادهها را ساخت اختصاص داد. یک راه برای انجام این کار شمارش تکرار هر «کلمه» (Word) در هر جمله و مرتبط ساختن این مقدار با کل مجموعه کلمات موجود در مجموعه داده است. این کار با دریافت داده و ساخت یک «واژه» (Vocabulary) از همه کلمات موجود در کلیه جملات آغاز میشود. مجموعه متن در پردازش زبان طبیعی «پیکره» (Corpus) نیز نامیده میشود. «واژه» (Vocabulary) در این شرایط لیستی از کلمات است که در متن به وقوع پیوستهاند و هر کلمه دارای اندیس خودش است. این امر کاربر را قادر به ساخت بردار برای یک جمله میسازد.
سپس، جملهای که هدف، برداریسازی آن است دریافت میشود و میتوان وقوع هر کلمه در واژه را شمارش کرد. بردار حاصل طولی به اندازه واژه و یک شمارش برای هر کلمه در واژه دارد. به این بردار، «بردار ویژگی» (Feature Vector) میگویند. در بردار ویژگی، هر بُعد میتواند ویژگی «عددی» (Numeric) یا «دستهای» (Categorical) باشد، برای مثال، ارتفاع یک ساختمان، قیمت سهام یا در این مثال تعداد کلمات در واژه انواع گوناگونی از ویژگیها هستند. این بردارهای ویژگی بخش حیاتی از «علم داده» (Data Science) و یادگیری ماشین هستند زیرا مدلی که قرار است «آموزش» (Train) داده شود، به این ویژگیها بستگی دارد. اکنون، آنچه بیان شد به تصویر کشیده میشود. دو جمله زیر مفروض هستند.
سپس، میتوان از CountVectorizer که توسط کتابخانه scikit-learn برای برداریسازی جملات فراهم شده استفاده کرد. این پیادهسازی کلمات هر جمله را دریافت کرده و یک واژه از همه کلمات یکتای موجود در جمله میسازد. این واژه را میتوان برای ساخت یک بردار ویژگی از شمارشهای کلمات، مورد استفاده قرار داد.
این واژه به عنوان اندیس هر کلمه نیز به کار میرود. اکنون، میتوان هر جمله را دریافت کرد و وقوع کلمات را بر اساس واژه پیشین به دست آورد. واژه شامل همه ۵ کلمه موجود در جمله میشود و هر یک از آنها نمایانگر یک کلمه در واژه هستند. هنگامی که دو جمله پیشین دریافت و توسط کاربر با CountVectorizer «تبدیل» (transform) میشوند، میتوان یک بردار دریافت کرد که نمایانگر شمارش هر کلمه از جمله است.
اکنون، میتوان بردارهای ویژگی حاصل شده برای هر جمله برپایه واژه پیشین را مشاهده کرد. خروجی حاصل به عنوان مدل «کیسه کلمات» (Bag-of-words | BOW) در نظر گرفته میشود که یک روش متداول در «پردازش زبان طبیعی» (Natural Language Processing) برای ساخت بردارها از متن است. هر سند به صورت یک بردار نمایش داده میشود. این بردارها به عنوان بردارهای ویژگی برای مدل یادگیری ماشین قابل استفاده هستند. انجام وظایف بیان شده، کار را به بخش بعدی یعنی تعریف مدل مبنا هدایت میکند.
تعریف مدل مبنا
هنگام انجام کار یادگیری ماشین، یک گام مهم تعریف مدل مبنا است. مدل مبنا معمولا شامل یک مدل ساده میشود که بعدا برای مقایسه با مدل پیشرفتهتری که قصد آزمودن آن وجود دارد مورد استفاده قرار میگیرد. در این شرایط، از مدل مبنا برای مقایسه آن با متدهای پیشرفتهتری از جمله شبکههای عصبی (عمیق) بهرهبرداری میشود.

ابتدا، باید دادهها به مجموعههای «آموزش» (Train) و «آزمون» (Test) تقسیم شوند تا امکان ارزیابی صحت و قابلیت تعمیم مدل فراهم شود. این یعنی بررسی اینکه آیا مدل دارای عملکرد خوبی روی دادههایی که پیشتر ندیده، است؟ روش بیان شده راهکاری برای بررسی «بیشبَرازش» (Overfitting) مدل محسوب میشود. بیشبرازش هنگامی به وقوع میپیوندد که مدل روی دادههای آموزش بیش از اندازه خوب آموزش داده شود. باید از بیشبرازش اجتناب کرد، زیرا بیشبرازش یعنی مدل تنها دادههای آموزش را به خاطر سپرده است و این امر منجر به صحت بالا برای دادههای آموزش و صحت پایین برای دادههای آزمون میشود. در اینجا کار با دریافت مجموعه داده Yelp آغاز میشود که از مجموعه دادهای که پیشتر الحاق شده بود استخراج میشود. از این مجموعه، جملات و برچسبها استخراج میشوند. «values.» به جای شی Pandas Series یک آرایه NumPy باز میگرداند که کار با آن در این زمینه راحتتر است.
سپس، مجددا از مدل BOW پیشین برای برداریسازی جملات استفاده شده است. میتوان مجددا از CountVectorizer برای این کار استفاده کرد. از آنجا که ممکن است در طول آموزش، دادههای آزمون موجود نباشند، میتوان واژه را با استفاده از دادههای آموزش ساخت. همچنین، با بهرهگیری از این واژه، میتوان بردارهای آتی را برای هر جمله از مجموعه آموزش و آزمون (تست) ایجاد کرد.
قابل مشاهده است که بردارهای ویژگی منتج شده دارای ۷۵۰ نمونه هستند. این موارد در واقع تعداد نمونههای آموزشی محسوب میشوند که پس از جداسازی دادههای آموزش-آزمون باقیماندهاند. همچنین، میتوان ملاحظه کرد که یک «ماتریس خلوت» (Sparse Matrix) حاصل شده است. ماتریس خلوت، نوع دادهای است که برای ماتریسهایی با تنها چند عنصر غیر صفر بهینه شده و صرفا عناصر غیر صفر را حفظ میکند و با این کار موجب کاهش بار حافظه می شود. CountVectorizer کار «توکنسازی» (tokenization) را انجام میدهد و به عبارت دیگر، جملات را به مجموعهای از «توکنها» (tokens) جداسازی میکند که پیشتر در واژه مشاهده شدند. علاوه بر این، نشانهگذاریها و کاراکترهای خاص را نیز حذف کرده و میتواند پیشپردازش را بر هر واژه اعمال کند. در صورت تمایل میتوان از یک «توکنساز» (tokenizer) سفارشی از کتابخانه NLTK با CountVectorizer یا هر تعداد سفارشیسازی که برای بهبود کارایی مدل قابل اکتشاف است استفاده کرد.
نکته: پارامترهای دیگری مانند افزودن ngrams نیز افزون بر ()CountVectorizer وجود دارند که از آنها در اینجا صرفنظر شده، زیرا هدف در ابتدا ساخت یک مدل مبنای ساده بوده است. خود الگوی توکن بهطور پیشفرض به صورت token_pattern=’(?u)\b\w\w+\ است و یک الگوی regex محسوب میشود که میگوید «یک کلمه ۲ یا تعداد بیشتری کاراکتر کلمه بیهمتا دارد که به وسیله مرزها احاطه شدهاند». مدل دستهبندی که قصد استفاده از آن وجود دارد «رگرسیون لجستیک» (Logistic Regression) است که یک مدل ساده ولی قدرتمند محسوب میشود و به بیان ریاضی نوعی از رگرسیون بین ۰ و ۱ برپایه بردار ویژگی ورودی است. با تعیین یک مقدار آستانه (به طور پیشفرض ۰.۵)، مدل رگرسیون برای دستهبندی مورد استفاده قرار میگیرد. میتوان از کتابخانه scikit-learn مجددا استفاده کرد که «دستهبند» (Classifier) رگرسیون لجستیک را (LogisticRegression) فراهم میکند.
قابل مشاهده است که رگرسیون لجستیک به مقدار صحت چشمگیر ۷۹.۶٪ رسیده، اما بررسی چگونگی عملکرد این مدل روی دیگر دادههای موجود نیز مفید خواهد بود. در این اسکریپت، کل فرآیند برای هر مجموعه داده موجود انجام و ارزیابی میشود.
خروجی این کار در زیر قابل مشاهده است.
بسیار عالی! به وضوح مشخص است که این مدل ساده به مقدار صحت خوبی دست یافته. بررسی اینکه آیا مدلی وجود دارد که عملکردی بهتر از این داشته باشد یا خیر، جالب توجه خواهد بود. در بخش بعدی، به مبحث شبکههای عصبی (عمیق) و چگونگی اعمال آنها برای دستهبندی متن پرداخته خواهد شد.
مقدمهای بر شبکههای عصبی (عمیق)
امروزه بسیاری از افراد هیجان و ترسهای مرتبط با «هوش مصنوعی» (Artificial Intelligence) و «یادگیری عمیق» (Deep Learning) را تجربه کردهاند. بحثهایی که در «سخنرانیهای تِد» (TED talks) پیرامون «تکینگی فناوری» (Technological Singularity) انجام میشود و صحبتهایی که برخی چهرههای شاخص دنیای علم و فناوری پیرامون حکمرانی هوش مصنوعی بر بشر دارند تصویری هراسانگیز از پیشرفتهای هوش مصنوعی ارائه میکند.
همه پژوهشگران بر این امر توافق دارند که درباره زمان دقیقی که کارایی هوش مصنوعی از سطح انسانی تجاوز میکند با یکدیگر هم عقیده نیستند. مطابق مقالهای که با عنوان «هوش مصنوعی چه هنگام از کارایی انسانی پیشی میگیرد؟» (?When Will AI Exceed Human Performance) (+) منتشر شده، همچنان زمان زیادی تا آن روز باقیمانده است.
احتمالا برای مخاطبان مطلب پیشرو که تا این بخش از آن را مطالعه کردهاند این سوال پیش آمده که با این اوصاف شبکههای عصبی چگونه کار میکنند؟ در این بخش صرفا چشماندازی از شبکههای عصبی و عملکرد داخلی آنها ارائه و در ادامه چگونگی استفاده از شبکههای عصبی با کتابخانه فوقالعاده «کِرَس» (Keras) بیان میشود. در این وهله نیازی به نگرانی پیرامون تکینگی فناوری نیست، ولی باید گفت شبکههای عصبی «عمیق» نقش اساسی در توسعههای اخیر هوش مصنوعی بازی کردهاند. این مبحث با مقاله انتشار یافته از «جفری هینتون» (Geoffrey Hinton) در سال ۲۰۱۲ (+)، آغاز شد. در این مقاله مدلی معرفی شده بود که نسبت به همه مدلهای پیشین ارائه شده در چالش ImageNet، عملکرد بهتری داشت. چالش ImageNet را میتوان برابر با جام جهانی حوزه بینایی ماشین دانست که طی آن دستهبندی مجموعه بزرگی از تصاویر بر پایه برچسبهای داده شده انجام میشود. جفری هینتون و تیم او موفق به شکست دادن مدلهای پیشین با استفاده از یک «شبکه عصبی پیچشی» (Convolutional Neural Network | CNN) شدند که چگونگی عملکرد آن در این مطلب شرح داده شده است.
از آن زمان، شبکهها عصبی در زمینههای گوناگونی از جمله «دستهبندی» (Classification)، «رگرسیون» (Regression) و حتی «مدلهای مولد» (Generative Models) مورد استفاده قرار میگیرند. مدلهای شبکههای عصبی بیشترین کاربرد را در زمینه «بینایی ماشین» (Computer Vision)، «بازشناسی صدا» (Voice Recognition) و «پردازش زبان طبیعی» (Natural Language Processing | NLP) دارند. شبکههای عصبی که گاهی به آنها «شبکه عصبی مصنوعی» (Artificial Neural Network | ANN) یا «شبکه عصبی پیشخور» (Feedforward Neural Network) نیز گفته میشود، شبکههای محاسباتی هستند که از شبکههای عصبی موجود در مغز انسان الهام گرفته شدهاند. این شبکهها «نورونهایی» (Neurons) را در بر میگیرند که به آنها «گره» (Node) نیز گفته میشود و مانند آنچه در تصویر زیر آمده به یکدیگر متصل شدهاند.

در مدل شبکه عصبی کار با یک لایه از نورونهای ورودی آغاز میشود که بردار ویژگی خوراک آن است و مقادیر بعدا به یک «لایه پنهان» (Hidden Layer) پیشخور (feeded forward) میشوند. در هر اتصال، مقدار به پیش خورانده میشود، در حالیکه با یک وزن چند برابر و یک بایاس به آن اضافه شده است. این اتفاق در هر اتصال میافتد و در پایان یک لایه خروجی با یک یا تعداد بیشتری گره حاصل میشود. برای انجام دستهبندی دودویی میتوان از یک گره استفاده کرد، اما در صورت داشتن چندین دسته باید از چندین گره برای هر دسته استفاده کرد. میتوان هر تعداد که کاربر تمایل داشته باشد، لایه پنهان در شبکه عصبی داشت. در حقیقت، یک شبکه عصبی با بیش از یک لایه پنهان به عنوان «شبکه عصبی عمیق» (Deep Neural Network) در نظر گرفته میشود. در اینجا به مسائل ریاضیاتی همراه با جزئیات ورود نمیشود. برای مطالعه دقیقتر در این رابطه مشاهده آموزشهای ویدئویی فرادرس توصیه میشود. فرمول لازم برای رفتن از یک لایه به لایه بعدی مطابق معادله زیر است.

اکنون به آرامی از آنچه به وقوع میپیوندد پردهبرداری خواهد شد. همانطور که مشهود است، در اینجا تنها با دو لایه کار میشود. لایه با گرههای a به عنوان ورودی برای لایهای با گرههای o عمل میکند. به منظور محاسبه مقدار برای هر گره خروجی، باید هر گره ورودی با یک وزن w چند برابر و یک بایاس b به آن اضافه شود. همه این موارد باید جمع و به تابع f پاس داده شوند. این تابع به عنوان «تابع فعالسازی» (activation function) در نظر گرفته میشود و توابع متعدد متفاوتی وجود دارند که بسته به لایه یا مساله برای این کار قابل استفاده هستند. به طور کلی، یک «واحد خطی یکسوساز» (Rectified Linear Unit | ReLU) برای لایههای پنهان، یک «تابع سیگموئید» (Sigmoid Function) برای لایه خروجی در مسائل دستهبندی دودویی، یا یک تابع «بیشینه هموار» (softmax function) برای لایه خروجی در مسائل دستهبندی چند دستهای (multi-class) مورد استفاده قرار میگیرد.
پرسشی که در این وهله امکان دارد برای بسیاری از افراد مطرح شود آن است که «وزنها» (Weights) چگونه محاسبه میشوند و این موضوع به وضوح مهمترین بخش از شبکههای عصبی و البته دشوارترین آن است. الگوریتم با مقداردهی اولیه به وزنها با مقادیر تصادفی آغاز و سپس با متدی با عنوان «بازگشت به عقب» (backpropagation) آموزش داده میشود.
این کار با استفاده از متدهای بهینهسازی (که به آنها بهینهساز نیز گفته میشود) مانند گرادیان کاهشی به منظور کاهش خطای بین خروجی محاسبه شده و مورد انتظار (به آن خروجی هدف نیز گفته میشود)، صورت میپذیرد. خطا با یک «تابع زیان» (loss function) که باید زیان آن به وسیله بهینهساز کاهش پیدا کند محاسبه میشود. کل فرآیند مفصلتر از حوصله این بحث است و بنابراین برای علاقمندان به یادگیری دقیقتر و عمیقتر مشاهده دورههای ویدئویی فرادرس پیشنهاد میشود. آنچه در این وهله باید دانست آن است که روشهای بهینهسازی متنوعی وجود دارند که میتوان از آنها استفاده کرد اما متداولترین بهینهسازی که در حال حاضر مورد استفاده قرار میگیرد «آدام» (Adam) (+) نامیده میشود و کارایی خوبی در مسائل گوناگون دارد.
همچنین، میتوان از توابع زیان گوناگونی استفاده کرد، ولی در این مطلب فقط نیاز به «تابع زیان آنتروپی متقاطع» (cross entropy loss function) یا به طور مشخصتر «آنتروپی متقاطع دودویی» (binary cross entropy) است که برای مسائل دستهبندی دودویی مورد استفاده قرار میگیرد. برخی از پژوهشگران در مقالهای که اخیرا منتشر کردهاند (+) ادعا میکنند که انتخاب بهترین متد به نوعی کیمیاگری است. دلیل این امر آن است که متدهای زیادی موجود هستند که به خوبی تشریح نشدهاند و شامل «پیچش» (tweaking) و «آزمونهای» (testing) زیادی میشوند.
معرفی کِرَس
«کِرَس» (Keras) یک API یادگیری عمیق و شبکه عصبی است که توسط «فرانکویس کولِت» (François Chollet) توسعه داده شده و قادر به اجرا بر فراز «تنسورفلو» (Tensorflow)، «ثینو» (Theano) یا CNTK (جعبهابزار شناختی مایکروسافت | Microsoft Cognitive Toolkit) است.
در کتاب «یادگیری عمیق با پایتون» (Deep Learning with Python) اثر «فرانسیس کلت» (François Chollet) در رابطه با کِرَس چنین آمده:
«کِرَس یک کتابخانه سطح مدل است که بلوکهای سطح بالایی برای توسعه مدلهای یادگیری عمیق فراهم میکند. این کتابخانه از عملیات سطح پایین مانند دستکاری و متمایزسازی تانسور پشتیبانی نمیکند. در عوض، بر کتابخانه تنسور تخصصی و به خوبی بهینهسازی شدهای تکیه دارد که بهعنوان موتور پشتیبان (بکاند) کِرَس عمل میکنند.»
این راه بسیار خوبی برای آغاز تجربه کار با شبکههای عصبی است، بدون آنکه الزامی به پیادهسازی هر لایه و بخش توسط کاربر باشد. برای مثال، تنسورفلو یک کتابخانه یادگیری ماشین بسیار خوب است، اما باید میزان زیادی کد برای داشتن یک مدل در حال اجرا پیادهسازی شوند.
نصب کِرَس
پیش از نصب کِرَس، نیاز به «تنسورفلو» (Tensorflow)، «ثینو» (Theano)، یا CNTK است. در این راهنما از تنسورفلو استفاده خواهد شد، بنابراین افرادی که این کتابخانه را نصب ندارند میتوانند از این راهنما (+) برای نصب آن استفاده کنند.
البته الزامی به استفاده از این کتابخانه وجود ندارد و افراد میتوانند از میان گزینههای قابل استفاده مورد دیگری را برگزینند. کِرَس قابل نصب با استفاده از PyPI (+) و با بهرهگیری از دستور زیر است:
کاربران میتوانند backend مورد نظر خود را با باز کردن فایل «پیکربندی» (configuration) کِرَس که از مسیر زیر در دسترس است، انتخاب کنند.
$HOME/.keras/keras.json
کاربران ویندوز باید HOME$ را با %USERPROFILE% جایگزین کنند. فایل پیکربندی باید به صورت زیر باشد:
در کد بالا میتوان فیلد backend را به theano ،tensorflow یا cntk تغییر داد و انتخاب این مورد بستگی به کتابخانه نصب شده روی سیستم کاربر دارد. برای دریافت جزئیات بیشتر در این رابطه، مطالعه سند «Keras backends» (+) توصیه میشود. چنانچه مشهود است در فایل پیکربندی از داده float32 استفاده شده. دلیل این امر استفاده از شبکههای عصبی در GPU و «تنگنای محاسباتی» (Computational Bottleneck) حافظه است. با استفاده از ۳۲ بیت، میتوان بار حافظه را کاهش داد و بدین شکل مانع از دست رفتن اطلاعات خیلی زیاد شد.
اولین مدل کِرَس
اکنون زمان آن رسیده تا تجربه ساخت مدل با کِرَس جامه عمل بپوشد. Keras از دو نوع اصلی مدلها پشتیبانی میکند. Sequential model API (+) نوع مورد استفاده در این راهنما و functional API (+) نوع قابل استفاده برای انجام کلیه امور مربوط به مدلهای ترتیبی و البته مدلهای پیشرفته با معماری شبکه پیچیدهتر است.
مدل ترتیبی یک «پشته» (stack) خطی از لایهها محسوب میشود که میتواند از انواع زیادی از لایههای موجود در کِرَس استفاده کند. متداولترین لایه، Dense است که شبکه عصبی به شدت متصل با قاعده محسوب میشود که همه وزنها و بایاسهای آن پیشتر توضیح داده شدند.
اکنون، این موضوع مورد بررسی قرار میگیرد که آیا امکام به دست آوردن بهبودهای بیشتری نسبت به مدل رگرسیون پیشین وجود دارد؟ برای پاسخ به این پرسش، میتوان از آرایههای X_train و X_test استفاده کرد که پیشتر در مثال بیان شده مورد بهرهبرداری قرار گرفتند. پیش از آنکه مدل ساخته شود، باید ابعاد ورود بردار ویژگی را دانست. این اتفاق تنها در لایه اول به وقوع میپیوندد زیرا لایههای بعدی میتوانند استنباط شکل را به صورت خودکار انجام دهند. به منظور ساخت مدل ترتیبی، میتوان لایهها را یکی یکی و به ترتیب به صورت زیر وارد کرد:
پیش از آغاز کار آموزش دادن مدل، نیاز به پیکربندی فرآیند یادگیری است. این کار با متد ()compile. انجام میشود. این متد «بهینهساز» (optimizer) و «تابع زیان» (loss function) را تعیین میکند. علاوه بر این، میتوان لیستی از سنجهها را که بعدا برای ارزیابی قابل استفاده هستند اضافه کرد، اما این موارد آموزش را تحت تاثیر قرار نمیدهند. در این مطلب از «آنتروپی متقاطع دودویی» (binary cross entropy) و بهینهساز «آدام» (Adam) استفاده میشود که پیشتر به آنها اشاره شد. کِرَس همچنین شامل یک تابع کاربردی ()summary. برای ارائه چشماندازی از مدل و تعداد پارامترهای موجود برای آموزش است.
همانطور که مشهود است، ۸۵۷۵ پارامتر برای اولین لایه وجود دارد و ۶ تای دیگر در بعدی قرار دارند. اما این موارد از کجا آمدهاند؟ در پاسخ به این سوال باید گفت که ۱۷۱۴ بُعد برای هر ویژگی و گره وجود دارد که برابر با ۱۷۱۴ * ۵ = ۸۵۷۰ پارامتر میشود، سپس پنج بایاس افزوده دیگر برای هر گره مورد نیاز است، که در نهایت ۸۵۷۵ پارامتر بر جای میماند. در گره نهایی، ۵ وزن دیگر و یک بایاس باقی میماند که ۶ پارامتر بر جای میگذارد. با توجه به آنکه آموزش در شبکه عصبی یک فرآیند تکرار شونده است، آموزش پس از پایان یافتن متوقف نمیشود. کاربر باید تعداد تکرارهایی که تمایل دارد مدل طی آن آموزش ببیند را تعیین کند. این تکرارهای کامل معمولا «دوره» (Epoch) نامیده میشوند. در اینجا مدل برای ۱۰۰ دوره اجرا میشوند تا بتوان مشاهده کرد که زیان آموزش و صحت پس از هر دوره چگونه تغییر میکند.
پارامتر دیگری که کاربر میتواند انتخاب کند «اندازه دسته» (batch size) است. اندازه دسته مسئول تعداد نمونههایی است که مقرر شده در یک دوره استفاده شوند، این یعنی چه تعداد نمونه در یک پاس رو به جلو/رو به عقب استفاده میشوند. این امر سرعت محاسبات را افزایش میدهد زیرا نیاز به دورههای بیشتری برای اجرا دارد، اما در عین حال نیاز به حافظه بیشتری نیز دارد و ممکن است مدل در مواجهه با سایز دستههای بزرگتر دچار تنزل رتبه شود. بنابراین، با توجه به اینکه در اینجا یک مجموعه آموزش کوچک وجود دارد، میتوان از سایز دسته پایین استفاده کرد:
اکنون میتوان از متد ()evaluate. برای اندازهگیری صحت مدل استفاده کرد. میتوان این کار را هم برای دادههای آموزش و هم دادههای آزمون انجام داد. انتظار میرود که دادههای آموزش نسبت به دادههای تست دارای صحت بالاتری باشند. هر چه شبکه عصبی برای مدت بیشتری آموزش داده شود، احتمال آنکه شروع به «بیشبرازش» (overfitting) کند بیشتر است. نکته قابل توجه آن است که اگر متد ()fit. باز اجرا شود، کار با وزنهای محاسبه شده از آموزش پیشین آغاز خواهد شد. بنابراین پیش از آموزش دوباره مدل، باید اطمینان حاصل کرد که مجددا کامپایل شده است. اکنون میتوان صحت مدل را ارزیابی کرد.
قابل ملاحظه است که مدل بیشبرازش شده زیرا صحت برای دادههای آموزش به ۱۰۰٪ رسیده. اما با توجه به بالا بودن تعداد دورهها برای این مدل، میتوان گفت وقوع بیشبرازش امری بدیهی محسوب میشود. اگرچه، صحت دادههای تست حتی همین حالا هم از صحت حاصل شده توسط مدل BOW با رگرسیون لجستیک، بیشتر است. برای سادهتر کردن کار، میتوان از این تابع کمککننده کوچک برای بصریسازی زیان و صحت برای دادههای آموزش و آزمون بر مبنای فراخوانی تاریخچه استفاده کرد. این فراخوانی که به طور خودکار بر هر مدل کِرَس اعمال میشود، زیان و «سنجههای» (metrics) (+) قابل اضافه کردن به متد ()fit. هستند. در این مطلب، تنها از سنجه صحت استفاده شده است. این تابع کمککننده از کتابخانه ترسیم نمودار «matplotlib» استفاده میکند.
برای استفاده از این تابع، به سادگی میتوان ()plot_history را با صحت و زیان گردآوری شده درون دیکشنری history فراخوانی کرد.

میتوان مشاهده کرد که مدل برای مدت بسیار زیادی آموزش داده شده، بنابراین به صحت ۱۰۰٪ دست پیدا کرده است. یک راه خوب برای مشاهده اینکه چه زمان مدل شروع به بیش برازش میکند هنگامی است که زیان دادههای اعتبارسنجی مجددا شروع به افزایش میکند. به نظر میرسد این نقطه خوبی برای متوقف کردن مدل باشد. این نقطه برای آموزش مثال بیان شده در حدود ۲۰-۴۰ دوره (epoch) است.
تذکر: هنگام آموزش یک شبکه عصبی، باید از مجموعه دادههای تست و اعتبارسنجی متفاوتی استفاده کرد. کاری که اغلب انجام میشود آن است که مدل با بالاترین صحت اعتبارسنجی گرفته و سپس با مجموعه تست ارزیابی میشود. چنین کاری این اطمینان را ایجاد میکند که مدل دچار بیشبرازش نشده. استفاده از مجموعه اعتبارسنجی برای انتخاب بهترین مدل، نوعی از «نشت داده» (یا تقلب) است که به منظور حصول نتایجی که بهترین امتیاز تست را از میان حالات گوناگون فراهم کردهاند انجام میشود. نشت داده هنگامی به وقوع میپیوندد که اطلاعات خارج از مجموعه داده آموزش در مدل مورد استفاده قرار بگیرند.
در این مثال، دادههای تست و اعتبارسنجی مشابه هستند، زیرا اندازه نمونه کوچک است. همانطور که پیشتر بیان شد، شبکههای عصبی (عمیق) هنگامی که میزان نمونهها خیلی زیاد باشد عملکرد خوبی دارند. در بخش بعدی، راه متفاوتی برای ارائه کلمات به صورت وکتور بیان شده. راهکار تشریح شده، بسیار هیجانانگیز و برای کار با کلمات دارای قدرت زیادی است. در ادامه، چگونگی نمایش کلمات به عنوان بردارهای چگال نیز تشریح خواهد شد.
جاسازی کلمات چیست؟
متن به عنوان شکلی از دادههای متوالی، شبیه به دادههای «سریهای زمانی» (Time Series) که در دادههای آبوهوا یا مالی وجود دارند در نظر گرفته میشود. در مدل BOW پیشین، چگونگی ارائه کل توالی کلمات به عنوان یک بردار ویژگی یکتا مشاهده شد.

اکنون چگونگی ارائه هر کلمه به صورت یک بردار مورد بررسی قرار میگیرد. راههای متعددی برای برداریسازی متن وجود دارد که از آن جمله میتوان به موارد زیر اشاره کرد.
- کلمات هر واژه به صورت یک بردار ارائه میشوند.
- کاراکترهای هر کاراکتر به صورت بردار ارائه میشوند.
- «N-گرامهای» (N-grams) کلمات/کاراکترها نمایانگر یک بردار هستند (N-gramها شامل گروههایی از کلمات/کاراکترهای متعاقب در متن میشوند).
رمزگذاری One-Hot
اولین راه برای ارائه یک کلمه به عنوان بردار، فراخوانی رمرنگاری one-hot است. این کار، به سادگی و با گرفتن یک بردار با طول واژه و دریافت ورودی برای هر کلمه در پیکره (نوشتار) انجام میشود. بدین شکل، برای هر کلمه، جایی در واژه وجود دارد، و یک بردار دارای صفر ایجاد میشود که در هر جا به جز نقطه مذکور برابر با صفر قرار داده شده است.
این کار میتواند منجر به یک بردار نسبتا بزرگ برای هر کلمه شود و هیچ اطلاعات افزودهای مانند ارتباط بین کلمات نیز به دست نمیدهد. مطابق مثال زیر، فرض میشود که لیستی از شهرها موجود هستند.
میتوان از scikit-learn و LabelEncoder برای رمزگذاری لیست شهرها در مقادیر صحیح دستهای مانند آنچه در زیر آمده استفاده کرد.
با استفاده از این ارائه، میتوان از OneHotEncoder ارائه شده توسط scikit-learn برای رمزنگاری مقادیر دستهای که پیشتر در آرایه عددی به صورت one-hot رمزنگاری شدهاند، استفاده کرد. OneHotEncoder از هر مقدار عددی انتظار دارد تا در سطر جداگانهای باشد، بنابراین نیاز به شکلدهی مجدد آرایه است، سپس کاربر میتواند رمزنگار را اعمال کند.
میتوان مشاهده کرد که مقادیر صحیح دستهای موقعیت هر آرایه را نشان میدهند که برابر با ۱ و کل آن صفر است. این امر اغلب هنگامی مورد استفاده قرار میگیرد که ویژگیهای دستهای وجود داشته باشد که کاربر نتواند آنها را به صورت مقادیر عددی نمایش دهد اما همچنان تمایل به استفاده از آن در یادگیری ماشین داشته باشد. یک بررسی کاربردی برای این رمزنگاری، کلمات داخل متن است، اما این رمزنگاری در اصل برای دستهها مورد استفاده قرار میگیرد. از جمله این دستهها میتوان به شهر و دپارتمان اشاره کرد.
جاسازی کلمات
در این روش، کلمات به صورت بردارهای کلمات متراکم ارائه میشوند (به این کار جاسازی کلمات گفته میشود) که برخلاف رمزنگاری one-hot که به صورت سخت کدنویسی شده (hardcoded)، آموزش دیده است. این یعنی جاسازی کلمات اطلاعات بیشتری را در ابعاد کمتری گردآوری میکند.
توجه به این نکته لازم است که جاسازهای کلمات، متن را به شکلی انسان میفهمد درک نمیکنند، اما ساختار آماری زبان استفاده شده در نوشتار را نسبتا درک میکنند. هدف آنها نگاشت معنایی به «فضای هندسی» (Geometric Space) است. این فضای هندسی «فضای جاسازی» (Embedding Space) نامیده میشود.
این کار کلماتی با معنای مشابه مانند اعداد یا رنگها را در فضای جاسازی نگاشت میکند. اگر جاسازی، رابطه بین کلمات را به خوبی ثبت کند، مواردی مانند «حساب برداری» (Vector Arithmetic) باید امکانپذیر باشند. یک مثال معروف در این زمینه، مطالعات توانایی نگاشت King - Man + Woman = Queen (+) است. چگونه میتوان به چنین جاسازی کلماتی دست یافت؟ دو گزینه برای این کار وجود دارد. یک راهکار آموزش دادن جاسازهای کلمات در طول آموزش شبکه عصبی است. راهکار دیگر استفاده از جاسازهای کلمات از پیش آموزش داده شده است که کاربر میتواند در مدل خود به طور مستقیم از آنها استفاده کند. بنابراین دو گزینه برای این کار وجود دارد، بدون تغییر باقی گذاشتن این جاسازهای کلمات در طول آموزش یا آموزش دادن آنها.
اکنون نیاز به «توکنسازی» (Tokenize) دادهها در قالبی است که توسط جاسازهای کلمات قابل استفاده باشند. «کِرَس» (Keras) چندین روش راحت برای «پیشپردازش متن» (Text Preprocessing) (+) و «پیشپردازش دنباله» (Sequence Preprocessing) (+) دارد که میتوان آنها را برای آمادهسازی متن به کار گرفت. این کار با استفاده از «کلاس مطلوبیت» (utility class) که Tokenizer است و میتواند نوشتار متنی را در لیستی از اعداد صحیح برداریسازی کند، قابل انجام محسوب میشود. هر عدد صحیح به یک مقدار در دیکشنری نگاشت میشود که کل نوشتار را با کلیدهایی در دیکشنری که خودشان اصطلاحات واژگان هستند رمزنگاری میکند. میتوان پارامتر num_words را اضافه کرد که مسئول تنظیم اندازه واژگان هستند. سپس، متداولترین کلمات num_words نگهداری خواهند شد. دادههای تست و آموزش برای مثال پیشین به صورت آماده موجود هستند:
«نمایهسازی» (indexing) در پی متداولترین کلمات در متن مرتبسازی شده، که با کلمه the که دارای اندیس ۱ است قابل مشاهده محسوب میشود. لازم به ذکر است که اندیس ۰ معکوس شده و به هیچ کلمهای تخصیص داده نمیشود. این اندیس (صفر) برای «لایهگذاری» (padding) مورد استفاده قرار میگیرد که در ادامه تشریح شده.
کلمات ناشناخته (کلماتی که در واژگان نیستند) در Keras با word_count + 1 تعیین شدهاند، زیرا امکان دارد اطلاعاتی را در بر داشته باشند. میتوان اندیس هر کلمه را با نگاه کردن به دیکشنری word_index شی Tokenizer مشاهده کرد.
تذکر: باید توجه زیادی به تفاوت بین این روش و X_train داشت که توسط CountVectorizer کتابخانه scikit-learn تولید شده است. کاربر با CountVectorizer، بردارهای شمارش کلمات قرار گرفته در پشته را دارد (اندازه کل واژگان نوشتار). با Tokenizer، بردارهای نتیجه شده مساوی طول هر متن هستند و اعداد شمارش را نشان نمیدهند، اما نسبتا به مقادیر کلمات دیکشنری tokenizer.word_index مرتبط هستند.
مسالهای که در این وهله وجود دارد آن است که هر توالی متن در بیشتر مواقع دارای طول کلمات متفاوتی است. برای مواجهه با این مساله، میتوان از ()pad_sequence استفاده کرد که به سادگی توالی کلمات را با صفر لایهگذاری میکند. به طور پیشفرض، این متد صفرها را به اول کاراکترها اضافه میکند (Prepend)، در حالیکه هدف در اینجا افزودن صفر به انتهای کاراکتر (Append) است. معمولا اهمیتی ندارد که صفرها prepend شدهاند یا append.
علاوه بر این، ممکن است کاربر بخواهد پارامتر maxlen را برای تعیین اینکه دنبالهها چقدر طولانی باید باشند مورد استفاده قرار دهد. این متد توالیهایی که از عدد تجاوز میکنند را میشکند. در کدی که در ادامه میآید، قابل مشاهده است که چگونه میتوان با استفاده از کِرَس توالیها را لایهگذاری کرد.
اولین مقادیر نشانگر اندیس واژگان هستند، چنانکه در مثالهای پیشین، مفهوم آن بیان شد. همچنین میتوان مشاهده کرد که بردارهای ویژگی حاصل شده اغلب شامل صفر هستند، زیرا جمله نسبتا کوتاه است. در بخش بعدی، چگونگی کار با جاسازهای کلمات در Keras آموزش داده میشود.
لایه Keras Embedding
شایان توجه است که در این نقطه، دادهها همچنان به صورت هاردکد شده هستند. در اینجا به Keras گفته نشده که یک فضای جاسازی جدید از طریق وظایف پیدرپی را بیاموزد.
اکنون میتوان از «لایه جاسازی» (Embedding Layer) کرس که اعداد صحیحی که پیشتر محاسبه شدهاند را دریافت و آنها را به یک بردار متراکم از جاساز نگاشت میکند استفاده کرد. در این راستا نیاز به پارامترهای زیر است.
- input_dim: اندازه واژگان
- output_dim: اندازه بردار متراکم
- input_length: طول دنباله
با لایه Embedding، یک جفت گزینه وجود دارد. یک راه دریافت خروجی لایه جاساز و متصل کردن آن در یک لایه Dense است. به منظور انجام این کار، نیاز به افزودن لایه Flatten در میان است که ورودی ترتیبی را برای لایه Dense آماده میکند.
خروجی به صورت زیر خواهد بود:
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= embedding_8 (Embedding) (None, 100, 50) 87350 _________________________________________________________________ flatten_3 (Flatten) (None, 5000) 0 _________________________________________________________________ dense_13 (Dense) (None, 10) 50010 _________________________________________________________________ dense_14 (Dense) (None, 1) 11 ================================================================= Total params: 137,371 Trainable params: 137,371 Non-trainable params: 0 _________________________________________________________________
اکنون میتوان مشاهده کرد که ۸۷۳۵۰ پارامتر جدید برای آموزش وجود دارد. این عدد از vocab_size در دفعات embedding_dim به دست میآید. این وزنهای لایه جاسازی با وزنهای تصادفی مقداردهی اولیه شدهاند و سپس از طریق بازگشت به عقب در طول آموزش تنظیم میشوند. این مدل، کلمات را به همان ترتیبی که در جمله میآیند به عنوان بردار ورودی دریافت میکند و میتوان آن را با استفاده از آنچه در ادامه آمده آموزش داد.
نتایج به صورت زیر هستند:
Training Accuracy: 0.5100 Testing Accuracy: 0.4600

همانطور که از کارایی مشهود است، این راه معمولا برای کار با دادههای ترتیبی خیلی قابل اعتماد نیست. هنگام کار با دادههای ترتیبی، کاربر باید روی روشهایی که به اطلاعات محلی و ترتیبی به جای اطلاعات موقعیتی مطلق نگاه میکنند متمرکز شود.
راه دیگر برای کار با جاسازها استفاده از MaxPooling1D/AveragePooling1D یا یک لایه GlobalMaxPooling1D/GlobalAveragePooling1D پس از جاسازی است. میتوان به گردآوری (pooling) لایهها به عنوان راهکاری برای downsample (راهی برای کاهش اندازه) بردار ویژگیهای ورودی اندیشید.
در شرایط گردآوری حداکثری (max pooling)، کاربر بیشینه مقدار همه ویژگیها را در pool در هر بُعد ویژگی میگیرد. در شرایط pooling متوسط، کاربر میانگین را میگیرد، اما به نظر میرسد گردآوری بیشینه به طور متداولتری مورد استفاده قرار میگیرد زیرا مقادیر بزرگ را برجسته میکند.
گردآوری بیشینه/میانگین سراسری، بیشنیه/میانگین همه ویژگیها را میگیرد، در حالیکه در شرایط دیگر نیاز به تعریف اندازه pool نیست. Keras مجددا لایه خودش را دارد که میتوان آن را به مدل ترتیبی اضافه کرد.
نتایج به شکل زیر خواهند بود:
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= embedding_9 (Embedding) (None, 100, 50) 87350 _________________________________________________________________ global_max_pooling1d_5 (Glob (None, 50) 0 _________________________________________________________________ dense_15 (Dense) (None, 10) 510 _________________________________________________________________ dense_16 (Dense) (None, 1) 11 ================================================================= Total params: 87,871 Trainable params: 87,871 Non-trainable params: 0 _________________________________________________________________
روال آموزش تغییر نمیکند:
نتایج به شکل زیر خواهند بود:
Training Accuracy: 1.0000 Testing Accuracy: 0.8050

میتوان برخی از بهبودها در مدل را مشاهده کرد. سپس، میتوان دید که چگونه میتوان جاسازهای کلمات از پیش آموزش دیده را به کار گرفت و اینکه آیت آنها به ما در کار با مدل کمک میکنند.
استفاده از جاسازی کلمات از پیش آموزش دیده
مثالی از یادگیری به طور مشترک جاسازهای کلمات گنجانده شده در مدل بزرگتر که هدف حل آن است، مشاهده شد. یک جایگزین، استفاده از فضای جاسازی از پیش محاسبه شده محسوب میشود که نوشتارهای بزرگتر را به کار میگیرد. امکان دارد که جاسازهای کلمات با آموزش آنها در نوشتارهای بزرگ متنی پیش محاسبه شوند.
در میان روشهای محبوب، Word2Vec توسط گوگل و GloVe (سرنام عبارت Global Vectors for Word Representation) توسط Stanford NLP Group توسعه داده شده است.
در این راهنما، چگونگی کار با جاسازهای کلمه GloVe از Stanford NLP Group آموزش داده شده، زیرا سایز آنها نسبت به جاسازهای کلمه Word2Vec ارائه شده توسط گوگل بیشتر قابل مدیریت است. اکنون باید 6B (آموزش دیده روی ۶ میلیارد کلمه) جاساز کلمه را از این مسیر (+) دانلود کرد (حجم آن ۸۲۲ مگابایت است).
همچنین، دیگر جاسازهای کلمه از صفحه اصلی GloVe قابل مشاهده است. میتوان جاسازهای از پیش آموزش دیده Word2Vec توسط گوگل را از اینجا (+) دانلود کرد. افرادی که قصد دارند جاسازهای کلمه خود را آموزش بدهند، میتوانند این کار را به طور موثر با بسته پایتون gensim (+) انجام دهند که از Word2Vec برای محاسبات استفاده میکنند. جزئیات بیشتر برای انجام این کار از اینجا (+) در دسترس است.
اکنون، میتوان از جاسازهای کلمه در مدل استفاده کرد. چگونگی بارگذاری ماتریس جاساز در مثال بعدی قابل مشاهده است. هر خط در فایل با کلمه آغاز میشود و با بردار جاسازی برای یک کلمه خاص دنبال میشود.
این یک فایل بزرگ با ۴۰۰۰۰۰ خط است که در آن هر خط نمایانگر یک کلمه دنبال شده توسط بردار خودش به عنوان جریانی از اعداد شناور است. برای مثال، در اینجا ۵۰ کاراکتر اول از خط اول آورده شده است:
$ head -n 1 data/glove_word_embeddings/glove.6B.50d.txt | cut -c-50 the 0.418 0.24968 -0.41242 0.1217 0.34527 -0.0444
با توجه به اینکه نیازی به همه کلمات نیست، میتوان تنها روی کلماتی که در واژگان وجود دارد تمرکز کرد. به دلیل آنکه تنها تعداد محدودی از کلمات در واژگان وجود دارند، میتوان از بیشتر ۴۰۰۰۰ کلمه را در جاسازهای کلمه پیشآموزش داده شده پرش کرد.
اکنون میتوان از این تابع برای بازیابی ماتریس جاسازی استفاده کرد.
فوقالعاده است. اکنون زمان استفاده از ماتریس جاساز در آموزش رسیده است. در ادامه این مسیر، از شبکه پیشین با با بیشینه گردآوری سراسری استفاده میشود و این موضوع مورد بررسی قرار میگیرد که آیا میتوان این مدل را بهبود بخشید. هنگامی که کاربر از جاسازهای کلمه از پیش آموزش داده شده استفاده میکند، این انتخاب را دارد که بپذیرد جاسازها در طول آموزش به روز رسانی شوند یا فقط از بردارهای جاساز نتیجه شده استفاده کنند. ابتدا، باید نگاهی سریع به تعداد بردارهای جاسازی که غیر صفر هستند داشت.
این یعنی ۹۵.۱٪ از واژگان تحت پوشش مدل از پیش آموزش داده شده قرار گرفتهاند. در ادامه نگاهی به کارایی هنگام استفاده از لایه GlobalMaxPool1D انداخته شده است.
نتایج به صورت زیر است:
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= embedding_10 (Embedding) (None, 100, 50) 87350 _________________________________________________________________ global_max_pooling1d_6 (Glob (None, 50) 0 _________________________________________________________________ dense_17 (Dense) (None, 10) 510 _________________________________________________________________ dense_18 (Dense) (None, 1) 11 ================================================================= Total params: 87,871 Trainable params: 521 Non-trainable params: 87,350 _________________________________________________________________
نتایج به صورت زیر است:
Training Accuracy: 0.7500 Testing Accuracy: 0.6950

از آنجا که جاسازهای کلمات به طور افزوده آموزش داده نشدهاند، انتظار میرود که پایینتر باشد. اما اکنون باید دید که اگر جاسازها با استفاده از trainable=True آموزش داده شوند، چگونه عمل میکند.
نتایج به صورت زیر است:
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= embedding_11 (Embedding) (None, 100, 50) 87350 _________________________________________________________________ global_max_pooling1d_7 (Glob (None, 50) 0 _________________________________________________________________ dense_19 (Dense) (None, 10) 510 _________________________________________________________________ dense_20 (Dense) (None, 1) 11 ================================================================= Total params: 87,871 Trainable params: 87,871 Non-trainable params: 0 _________________________________________________________________
نتایج به صورت زیر است:
Training Accuracy: 1.0000 Testing Accuracy: 0.8250
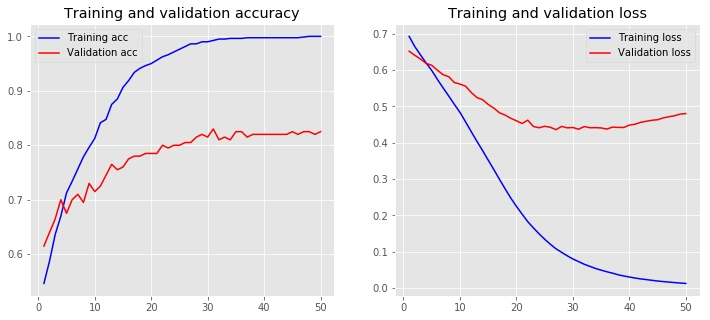

با توجه به تصویر بالا، باید گفت که تاثیرگذارترین حالت، دادن امکان آموزش دیدن به جاسازها است. هنگام کار با مجموعه دادههای بزرگ، میتواند فرآیند آموزش را برای سریعتر بودن شتاب بدهد. در این مثال، به نظر میرسید که کمک کند اما در حقیقت این اتفاق به وقوع نپیوست. اکنون، زمان تمرکز روی یک مدل شبکه عصبی پیشرفتهتر رسیده است.
شبکههای عصبی پیچشی (CNN)
«شبکههای عصبی پیچشی» (Convolutional Neural Networks | CNN) که به آنها convnets نیز گفته میشود، جالبترین توسعه در یادگیری ماشین طی سالهای اخیر به شمار میآیند.
آنها با داشتن توانایی استخراج ویژگی از تصاویر و استفاده از آنها در شبکههای عصبی موجب ایجاد انقلابی در دستهبندی تصاویر و بینایی کامپیوتر شدند. مشخصههایی که آنها را برای پردازش تصویر مناسب میسازد، این شبکههای عصبی را برای پردازش دنبالهها نیز کارآمد میسازد. میتوان یک CNN را به عنوان شبکه عصبی خاصی در نظر گرفت که قادر به شناسایی الگوهای خاصی است.
اگر شبکههای عصبی پیچشی تنها نوع دیگری از شبکههای عصبی هستند، پس چه چیزی آنها را از یکدیگر متمایز میکند؟
یک CNN دارای لایههای پنهانی است که «لایههای پیچشی» (convolutional layers) نامیده میشود. هنگامی که کاربر به تصاویر فکر میکند، کامپیوتر باید با ماتریس دو بعدی از اعداد کار کند و بنابراین نیاز به راهی برای شناسایی ویژگیها در این ماتریس است. این لایههای پیچشی قادر به شناسایی لبهها، گوشهها و دیگر انواع الگوها هستند که آنها را به ابزاری ویژه مبدل میسازد. لایه پیچشی شامل چندین فیلتر است که در سرتاسر تصویر لغزش میکنند و قادر به شناسایی ویژگیهای خاص هستند.
این هسته اصلی روش و فرآیند ریاضی که در پیچش اتفاق میافتد است. با هر لایه پیچشی، شبکه قادر به شناسایی الگوهای پیچیدهتر است. در «بصریسازی ویژگیها» (Feature Visualization) توسط «کریس اولا» (Chris Olah) میتوان بینش خوبی از اینکه این ویژگیها چطور میتوانند به نظر برسند به دست آورد.
هنگام کار با دادههای ترتیبی، مانند متن، با پیچشهای یکبُعدی کار میشود، اما ایده و کاربر مشابه میماند. کاربر همچنان میخواد الگویی در توالی را برگزیند که با هر لایه پیچشی اضافه شده پیچیدهتر میشود.
در تصویر بعدی، میتوان مشاهده کرد که چنین پیچشی چطور کار میکند. کار با دریافت یک «وصله» (Patch) از ویژگیهای ورودی با سایز کرنل فیلتر آغاز میشود. با این patch «ضرب داخلی» (Dot Product) وزنهای ضرب شده فیلتر به دست میآید. convnet یکبُعدی برای ترجمهها ثابت است، این یعنی توالیهای مشخصی ممکن است در موقعیتهای گوناگون ممکن است تشخیص داده شوند. این میتواند برای الگوهای مشخصی در متن مفید باشد.

اکنون نگاهی به چگونگی استفاده از این شبکه در Keras انداخته میشود. Keras مجددا لایههای پیچشی متنوعی را پیشنهاد میدهد که میتوان از آنها برای این کار استفاده کرد. لایهای که مورد نیاز محسوب میشود لایه Conv1D است. این لایه مجددا دارای پارامترهای گوناگونی است که میتوان از میان آنها انتخاب کرد. مواردی که برای راهنمای پیش رو جالب توجه است تعداد فیلترها، سایز کرنل و تابع فعالسازی است. میتوان این لایه را بین لایه Embedding و لایه GlobalMaxPool1D قرار داد.
نتایج به صورت زیر است:
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= embedding_13 (Embedding) (None, 100, 100) 174700 _________________________________________________________________ conv1d_2 (Conv1D) (None, 96, 128) 64128 _________________________________________________________________ global_max_pooling1d_9 (Glob (None, 128) 0 _________________________________________________________________ dense_23 (Dense) (None, 10) 1290 _________________________________________________________________ dense_24 (Dense) (None, 1) 11 ================================================================= Total params: 240,129 Trainable params: 240,129 Non-trainable params: 0 _________________________________________________________________
نتایج به صورت زیر است:
Training Accuracy: 1.0000 Testing Accuracy: 0.7700

میتوان مشاهده کرد که رسیدن به صحت ۸۰ درصد برای این مجموعه داده مانعی دشوار است و امکان دارد CNN به خوبی تجهیز نشده باشد. دلیل انجام چنین کاری میتواند از موارد زیر باشد:
- نمونههای آموزش کافی وجود ندارند.
- دادههای موجود به خوبی عمومیسازی نشدهاند.
- از دست دادن تمرکز بر پیچش هایپرپارامترها
CNN با دادههای آموزش بزرگ بهتر کار میکند، زیرا قادر است عمومیسازیهایی را پیدا کند که یک مدل ساده مانند رگرسیون لوجستیک قادر نیست.
بهینهسازی هایپرپارامترها
یک گام حیاتی در یادگیری عمیق و کار با شبکههای عصبی بهینهسازی هایپرپارامترها است. همانطور که در مدلهای مورد استفاده مشاهده شد، حتی در مدلهای ساده نیز، تعداد زیادی پارامتر برای پیچش و انتخاب از میان آنها وجود دارد. چنین پارامترهایی هایپرپارامتر نامیده میشوند.

این مهمترین بخش از یادگیری ماشین است و متاسفانه تاکنون هیچ کس راهکاری برای آن ارائه نداده که در همه موارد مناسب باشد. با نگاهی به رقابتهای Kaggle، که یکی از بزرگترین محلها برای رقابت با دیگر دانشمندان داده است میتوان مشاهده کرد که اغلب تیمها و مدلهای برنده پیچشها و آزمایشهای زیادی را انجام دادهاند تا به پیروزی دست یافتهاند. بنابراین، هنگام رسیدن به پستی و بلندیها نباید ناامید شد، بلکه باید به راههایی فکر کرد که میتوان برای بهینه کرد مدل یا دادهها مورد استفاده قرار داد.
یک روش محبوب برای بهینهسازی فراپارامترها «جستوجوی شبکهای» (Grid Search) است. آنچه این روش انجام میدهد آن است که لیست پارامترها را دریافت کرده و مدل را با هر ترکیبی از پارامترها که میتواند بیابد اجرا کند. این کاملترین راه و در عین حال سنگینترین روش محاسباتی برای انجام این کار محسوب میشود. دیگر راه متداول، «جستوجوی تصادفی» (random search) است. در ادامه از روش جستوجوی تصادفی برای ترکیب پارامترها استفاده خواهد شد.
به منظور اعمال جستوجوی تصادفی با Keras، نیاز به استفاده از KerasClassifier است که به عنوان پوشش برای رابط برنامهنویسی کاربردی scikit-learn عمل میکند. با این پوشش، کاربر قادر است از ابزارهای گوناگون موجود با scikit-learn مانند اعتبارسنجی متقابل استفاده کند. کلاسی که کاربر نیاز دارد RandomizedSearchCV است که جستوجوی تصادفی با اعتبارسنجی متقابل را پیادهسازی میکند. اعتبارسنجی متقابل راهکاری برای ارزیابی مدل و دریافت کل مجموعه داده و جداسازی آن در چندین مجموعه داده تست و آموزش است.
انواع گوناگونی از اعتبارسنجی متقابل وجود دارد. یک نوع از آن اعتبارسنجی متقابل k-fold است که در این مثال نشان داده خواهد شد. در این نوع، مجموعه داده به k سایز مساوی تقسیمبندی میشود که در آن یک مجموعه برای ارزیابی و سایر بخشها برای آموزش مورد استفاده قرار میگیرند. این امر کاربر را قادر میسازد که k اجرای مختلف را انجام دهد که طی آنها هر پارتیشن یک بار به عنوان مجموعه تست مورد استفاده قرار گرفته است. بنابراین، هر چه k بالاتر باشد، ارزیابی مدل صحیحتر و در عین حال مجموعه داده تست کوچکتر است. اولین گام برای KerasClassifier داشتن تابعی است که یک مدل Keras میسازد. در اینجا از مدل پیشین استفاده میشود اما به پارامترای گوناگون نیز اجازه داده میشود برای بهینهسازی هایپرپارامترها تنظیم شوند.
سپس، باید پارامتر grid تعریف شود که قصد استفاده از آن در آموزش وجود دارد. grid شامل یک دیکشنری با کلیه پارامترهایی است که در تابع پیشین نامگذاری شده. تعداد فضاها در شبکه 3 * 3 * 1 * 1 * 1 است، که در آن هر یک از اعداد، تعداد انتخابهای متفاوت برای پارامتر داده شده محسوب میشوند. میتوان مشاهده کرد که این کار به لحاظ محاسباتی به سرعت پرهزینه میشود، اما خوشبخانه هم جستوجوی شبکهای و هم تصادفی به شکل بدی موازی هستند و کلاسها با یک پارامتر n_jobs ارائه میشوند که امکان تست فضای شبکهای را در موازات فراهم میکنند. پارامتر grid با دیکشنری که در ادامه میآید مقداردهی اولیه میشود.
اکنون، زمان آغاز جستوجوی تصادفی رسیده است. در این مثال، تکرار در هر مجموعه داده به وقوع میپیوندد و سپس کاربر دادهها را به صورت مشابه آنچه پیشتر گفته شد پیشپردازش میکند. سپس، تابع پیشین را دریافت کرده و آن را به کلاس پوشش KerasClassifier شامل تعداد «دورهها» (epochs) اضافه میکند. نمونه حاصل شده و پارامتر grid به عنوان تخمینزنندهای در کلاس RandomSearchCV محسوب میشود. علاوه بر این، میتوان تعداد foldها در اعتبارسنجی متقابل k-fold را انتخاب کرد که در اینجا برابر با ۴ است. قابل مشاهده است که بیشتر کد موجود در این قطعه کد، در کد مربوط به مثال پیشین نیز وجود داشت. در کنار RandomSearchCV و KerasClassifier، یک بلوک کوچک از کدی که ارزیابی را مدیریت میکرد نیز اضافه شده است:
اجرای این کد کمی زمان میبرد. در ادامه خروجی کد نشان داده شده است:
جالب است! به دلایلی صحت تست بیشتر از صحت آموزش است. مثلا امکان دارد این مساله به دلیل تنوع بالا در امتیازها طی اعتبارسنجی متقابل باشد. مشاهده میشود که همچنان امکان شکست ۸۰٪ وجود دارد، به نظر میرسد این موضوع به دلیل محدودیت طبیعی موجود برای این داده و سایز آن باشد. باید به خاطر داشت که این مجموعه داده کوچک بوده و شبکههای عصبی پیچشی به داشتن بهترین اجرا برای مجموعه دادههای بزرگ گرایش دارند. دیگر روش موجود برای CV، «اعتبارسنجی متقابل تو در تو» (nested cross-validation) است که هنگامی مورد استفاده قرار میگیرد که فراپارامترها نیاز به بهینهسازی داشته باشند.دلیل استفاده از این روش آن است که مدل غیر تو در توی CV در مجموعه داده دارای سوگیری است و منجر به یک امتیاز بهینهسازی بیش از حد میشود. میتوان مشاهده کرد، هنگامی که بهینهسازی هایپرپارامترها چنانکه در مثال قبل انجام شد صورت میپذیرد، بهترین هایپرپارامترها برای مجموعه داده مشخص انتخاب میشوند اما این بدین معنا نیست که این هایپرپارامترها به خوبی تعمیم پیدا میکنند.
نتیجهگیری
در این مطلب چگونگی کار با دستهبندی متن در Keras آموزش داده شد و از یک مدل کیسه کلمات گرفته تا رگرسیون لجستیک و روشهای پیشرفتهتری مانند شبکهای عصبی پیچشی مورد بررسی قرار گرفتند. همچنین، به چیستی جاسازی کلمات، دلیل مفید بودن و چگونگی استفاده از جاسازهای از پیش آموزش داده شده برای آموزشها پرداخته شد. چگونگی کار با شبکههای عصبی و نحوه استفاده از بهینهسازی هایپرپارامترها برای گرفتن کارایی بهتر از مدل بیان شد. افراد پس از مطالعه این مطلب سنگ بنای اطلاعاتی لازم برای پردازش زبان طبیعی را دارند و میتوانند برای دستهبندی انواع متن از آن استفاده کنند. «تحلیل عواطف» برجستهترین مثال برای این مورد است. از جمله دیگر کاربردهای دستهبندی متن میتوان به موارد زیر اشاره کرد.
- تشخیص اسپم در ایمیلها
- تگگذاری خودکار متن
- دستهبندی مقالات خبری با عناوین از پیش تعریف شده
میتوان از این دانش و مدلهایی که آموزش داده شده در پروژههای پیشرفته استفاده کرد. همچنین، میتوان تحلیل عواطف یا دستهبندی متن را با «بازشناسی گفتار» (Speech Recognition) ترکیب کرد.

اگر نوشته بالا برای شما مفید بوده، آموزشهای زیر نیز به شما پیشنهاد میشوند:
- مجموعه آموزشهای هوش محاسباتی
- مجموعه آموزشهای شبکههای عصبی مصنوعی
- مجموعه آموزشهای آمار، احتمالات و دادهکاوی
- مجموعه آموزشهای برنامهنویسی پایتون
- معرفی منابع جهت آموزش یادگیری عمیق (Deep Learning) — راهنمای کامل
- معرفی منابع آموزش ویدئویی هوش مصنوعی به زبان فارسی و انگلیسی
^^









با سلام من الهه نمازی هستم یک ماه پیش مقاله Kaggle در موضوعات دیگر هم شما ارائه داده بودید ولی متاسفانه الان موضوعات دیگر در وبلاگ تون نمیبینم و برداشته شده است لطفا راهنماییم بفرمایید با تشکر
سلام، وقت شما بخیر؛
کلیه مطالبی که در مجله فرادرس در زمینه هوش مصنوعی ارائه شدهاند را میتوانید از طریق این لینک مشاهده کنید.
از اینکه با مجله فرادرس همراه هستید از شما بسیار سپاسگزاریم.
سلام و تشکّر/ عالی و خیلی با حوصله/ موفق باشید و سلامت