



آشنایی با شبکههای عصبی پیچشی (CNN)
«شبکههای عصبی پیچشی» (convolutional neural network) ردهای از شبکههای عصبی عمیق هستند که معمولاً برای انجام تحلیلهای تصویری یا گفتاری در یادگیری ماشین استفاده میشوند. برای توضیح CNN کار خود را با اساسیترین عنصر این شبکه عصبی یعنی «پرسپترون» (perceptron) آغاز میکنیم.
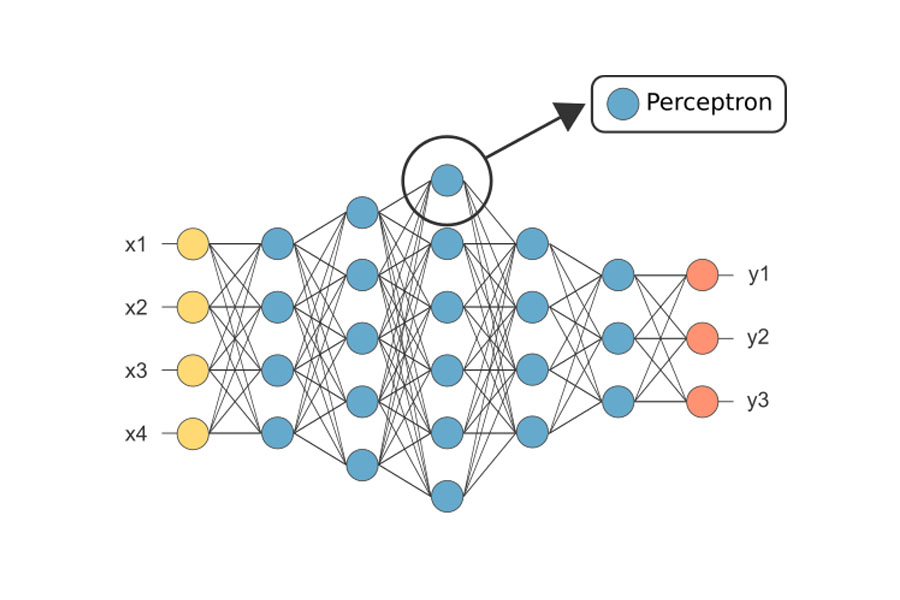


پرسپترون
پرسپترون جزء اساسی و پایهای شبکه عصبی است که میتواند یادگیری نیز داشته باشد. توسعه این جزء درنتیجه الهام از یک عنصر زیستشناختی به نام نورون بوده است. چراکه پرسپترون مانند نورون یک سیگنال ورودی را دریافت میکند، آن را پردازش میکند و یک پاسخ را شبیهسازی میکند. پرسپترون سیگنال میتواند برای تمییز مسائل قابل جداسازی خطی مورداستفاده قرار گیرد.
بردار ویژگی
وظایف یادگیری ماشینی معمولاً بدینصورت تعریف میشوند که سیستم یادگیری ماشینی چگونه باید یک نمونه را پردازش کند. معمولاً این وظایف مجموعهای از ویژگیها هستند که از برخی از اشیا یا رویدادها بهصورت کمی اندازهگیری میشوند و از سیستم یادگیری ماشینی میخواهیم که آنها را برای ما پردازش کند.
معمولاً این نمونه را بهصورت بردار x ∈ Rn نمایش میدهیم که هر مؤلفه xi خود یک بردار ویژگی است. برای مثال ویژگیهای یک تصویر معمولاً مقادیر پیکسلهایی هستند که در آن تصویر وجود دارند.

کلاسبندی
در این نوع وظایف از برنامه رایانهای خواسته میشود که مشخص کند یک مقدار ورودی به کدام یک از k دسته تعلق دارد.
برای انجام این کار یادگیری ماشینی معمولاً برای تولید یک تابع بهصورت زیر استفاده میشود.
{F: Rn → {1,..., k
که (y = f (x مدلی است که یک ورودی را که بر اساس بردار x توصیف میشود به یک دسته منتسب میکند که بر اساس کد عددی y شناسایی میشود. نسخههای دیگری از وظایف کلاسبندی هم وجود دارند. برای مثال وقتی خروجی تابع f یک توزیع احتمال بر روی کلاسها باشد. نمونه از وظیفه کلاسبندی، شناسایی اشیا است. در این وظیفه ورودی یک تصویر است (معمولاً بهصورت مجموعهای از مقادیر روشنایی پیکسل توصیفشده است) و خروجی یک کد عددی است که شیء درون تصویر را شناسایی میکند.
برای مثال ربات (Willow Garage PR2) میتواند بهعنوان یک پیشخدمت عمل کند. این ربات انواع مختلفی از نوشیدنیها را تشخیص میدهد و بر اساس سفارش افراد به آنها تحویل میدهد. شناسایی اشیا امروزه بهطور بهینهای بر اساس یادگیری عمیق صورت میگیرد. شناسایی اشیا درواقع همان فناوری پایهای است که به رایانهها اجازه میدهد چهره افراد را تشخیص دهند و بدین ترتیب برای تگ کردن خودکار افراد در مجموعه تصاویر استفاده میشود و به رایانهها اجازه میدهد به روش طبیعیتری با کاربرانشان تعامل داشته باشند.
در این مقاله میخواهیم نحوه یادگیری عملی پرسپترون را درک کنیم. برای تسهیل این امر میخواهیم الگوی پایهای این کار را یاد بگیریم.
الگوریتم تمرین
یک الگوریتم یادگیری ماشینی الگوریتمی است که توانایی یادگیری از دادهها را داشته باشد. اما منظور ما از یادگیری چیست؟ میچل (1997) تعریفی از یادگیری ارائه کرده است:
میگوییم یک برنامه رایانهای از تجربهی E با توجه به برخی کلاسهای وظیفهای T برای اندازهگیری عملکرد P یاد گرفته است، درصورتیکه عملکردهای موجود در وظایف T که بر اساس معیارهای P اندازهگیری میشوند در تجربه E بهبودیافته باشند»

شخص میتواند طیف وسیعی از تجربیات E، وظایف T و معیارهای عملکردی P را تصور کند. ما در این مقاله در پی ارائه تعریفی رسمی ازآنچه برای این گزارهها استفاده میشود نخواهیمبود. در عوض در بخشهای بعدی توصیفات شهودی و نمونههای انواع مختلف وظایف و معیارهای عملکردی و تجربیاتی که میتوان برای ساختن الگوریتمهای یادگیری ماشینی استفاده کرد را ارائه خواهیم کرد.

تمرین دادن پرسپترون
در این بخش میخواهیم هوش ریاضیاتی که قبلاً معرفی کردیم را وارد بحث بکنیم.

مبدأ (epoch)
مبدأ در زمان تمرین دادن یک مدل یادگیری ماشینی بهصورت یک گذر مشخص بر روی تمام مجموعه تمرینی تعریفشده است. در یک مبدأ منفرد همه نمونههای تمرینی بهیکباره وارد مدل میشوند. بنابراین کل تعداد مبدأها در زمان تمرین دادن یک مدل، نشاندهنده تعداد چرخههایی است که بر روی تمام مجموعه دادههای تمرینی اجرا شده است.

همانطور که در بخش الگوریتم تمرینی توضیح داده شد هدف ما افزایش عملکرد وظایف T است. در هر مبدأ ما یک پیشنگر برای پرسپترون ایجاد میکنیم تا بتوانیم خروجی مطلوب را پیشبینی کنیم. زمانی که مقدار پیشبینیشده (محاسبهشده) با مقدار مطلوب همسو نباشد، در وزنهای پرسپترون یک بهروزرسانی ایجاد میکنیم. بهروز رساندن وزنها بدین معنی است که مقادیر w باید افزایش یا کاهش یابند. این تغییرات دلتا آن چیزی است که الگوریتم تمرینی اعمال میکند تا بتوانند خطا/زیان کلی تعریفشده را به مقدار کمینه برساند.
زمانی که مشغول تمرین دادن هر مدلی هستیم همواره زیان تعریفشده داریم که وزنها بر روی آن بهینه میشوند.
تمرین دادن عملی پرسپترون
مجموعه داده
X = Np.Array([[0, 0, 1], [1, 1, 1], [1, 0, 1], [0, 1, 1]]) Y = Np.Array([0, 1, 1, 0])
کار خود را با این جدول آغاز میکنیم تا مدل پرسپترون خود را تمرین دهیم.
x: بردار ویژگی هر نمونه
y: برچسب برای هر نمونه
مدل پرسپترون خودمان را با انتساب مقادیر تصادفی برای وزنها آغاز میکنیم.
W = Np.Random.Rand(1, X.Shape[1] + 1)
همانطور که در بخش تئوری الگوریتم تمرینی توضیح دادیم هدف ما افزایش عملکرد وظایف T است. در هر مبدأ یک پیشنگر ایجاد میکنیم که خروجی مطلوب پرسپترون ما را پیشبینی میکنند. زمانی که مقدار پیشبینیشده (محاسبهشده) با مقدار مطلوب همسو نباشد یک بهروزرسانی در وزنهای پرسپترون ایجاد میکنیم. بهروزرسانی وزنهای پرسپترون بدین معنی است که مقادیر w باید کاهش یا افزایش داشته باشند.

نرخ یادگیری، تکانهای است که برای سرعت تمرین دادن تعیین میکنیم.
Eta = 0.001
در مثال ما مقدار زیان بهصورت مربع خطا تعریفشده است. همانطور که در بخشهای قبلی توضیح دادیم فرمول بهروزرسانی وزنهای دلتا بهصورت زیر است:
بنابراین زمانی که شروع به آغاز تمرین دادن یک مدل میکنیم هایپر پارامترهایی داریم که باید انتخاب کنیم.
def delta_weight(eta, true_label, predicted_label, x): """ :param eta: Learning rate :param true_label: :param predicted_label: :param x: """ lambda_param = -1 delta_w = lambda_param * eta * (predicted_label - true_label) * x return delta_w
def training_perceptron(eta, X, Y, number_of_epoch=5000):
"""
:param eta: learning rate of perceptron
:param X: the feature set for training
:param Y: the target value against feature set
"""
logging.info('Training Config:\nNumber_of_epoch: {} Eta: {}'.format(number_of_epoch, eta))
W = np.random.rand(1, X.shape[1] + 1)
loss_log = []
X = np.insert(X, 2, values=1, axis=1)
for epoch in range(number_of_epoch):
X, Y = shuffle(X, Y)
loss = 0.0
for index, (feature_row, true_label) in enumerate(zip(X, Y)):
theta = np.dot(np.array(feature_row), W.T)
# predicted_output = 1 if theta > 0 else 0
predicted_output = float(theta)
loss += (true_label - predicted_output) ** 2
delta_W = [delta_weight(eta, true_label, predicted_output, x) for x in feature_row]
logging.debug([feature_row, true_label, np.around(W, decimals=1), predicted_output, theta, delta_W])
W = np.add(W, delta_W)
if epoch % 50 == 0:
loss_log.append([epoch, loss])
logging.info('Epoch Summary : Epoch: {} Loss: {}'.format(epoch, loss))
if loss < 0.001:
break
time.sleep(0.001)
df = pd.DataFrame(loss_log, columns=['Epoch', 'Loss'])
logging.info(df)
df.to_csv('training_log.csv')
return number_of_epoch
در مثال ما هایپر پارامترها بهصورت زیر هستند:
""" eta: learning rate of the training lambda_param: to limit the maximum delta change in weights """
در نرخهای یادگیری متفاوت ممکن است نمودارهای زیان مختلفی را به دست آوریم. اگر نرخ یادگیری بالا باشد بهروزرسانی وزنها بزرگ خواهد بود، که موجب تمرین سریعتر خواهد شد.

وقتی نرخ یادگیری بهصورت eta = 0.0001 تنظیم شود یادگیری باید مبدأهای بیشتری را برای رسیدن به زیان کمینه مطلوب طی کند.

وقتی نرخ یادگیری به مقدار eta = 0.01 تنظیم شود سرعتهای یادگیری بیشتر میشود و تقریباً ده برابر خواهد بود

اگر تمایل به مطالعه بیشتر در مورد این موضوعات را داشته باشید؛ شاید آموزش های زیر نیز برای شما مفید باشند:
- مجموعه آموزشهای شبکههای عصبی مصنوعی
- آموزشهای شبکههای عصبی مصنوعی در متلب
- آموزش طبقهبندی و بازشناسی الگو با شبکه های عصبی LVQ
- آموزش شبکههای عصبی گازی به همراه پیاده سازی عملی
#









