



رگرسیون خطی چندگانه (Multiple Linear Regression) – به زبان ساده
یکی از روشهای مرسوم در تحلیل چند متغیره، تکنیک «رگرسیون خطی چندگانه» (Multiple Linear Regression) است. بر اساس تحلیل رگرسیونی، یک رابطه خطی بین «متغیر پاسخ» (Response Variable) با یک یا چند «متغیر توصیفی» (Explanatory Variable) برقرار میشود. البته گاهی به متغیر پاسخ، «متغیر وابسته» (Dependent Variable) و به متغیرهای توصیفی، «متغیرهای مستقل» (Independent Variables) نیز میگویند.

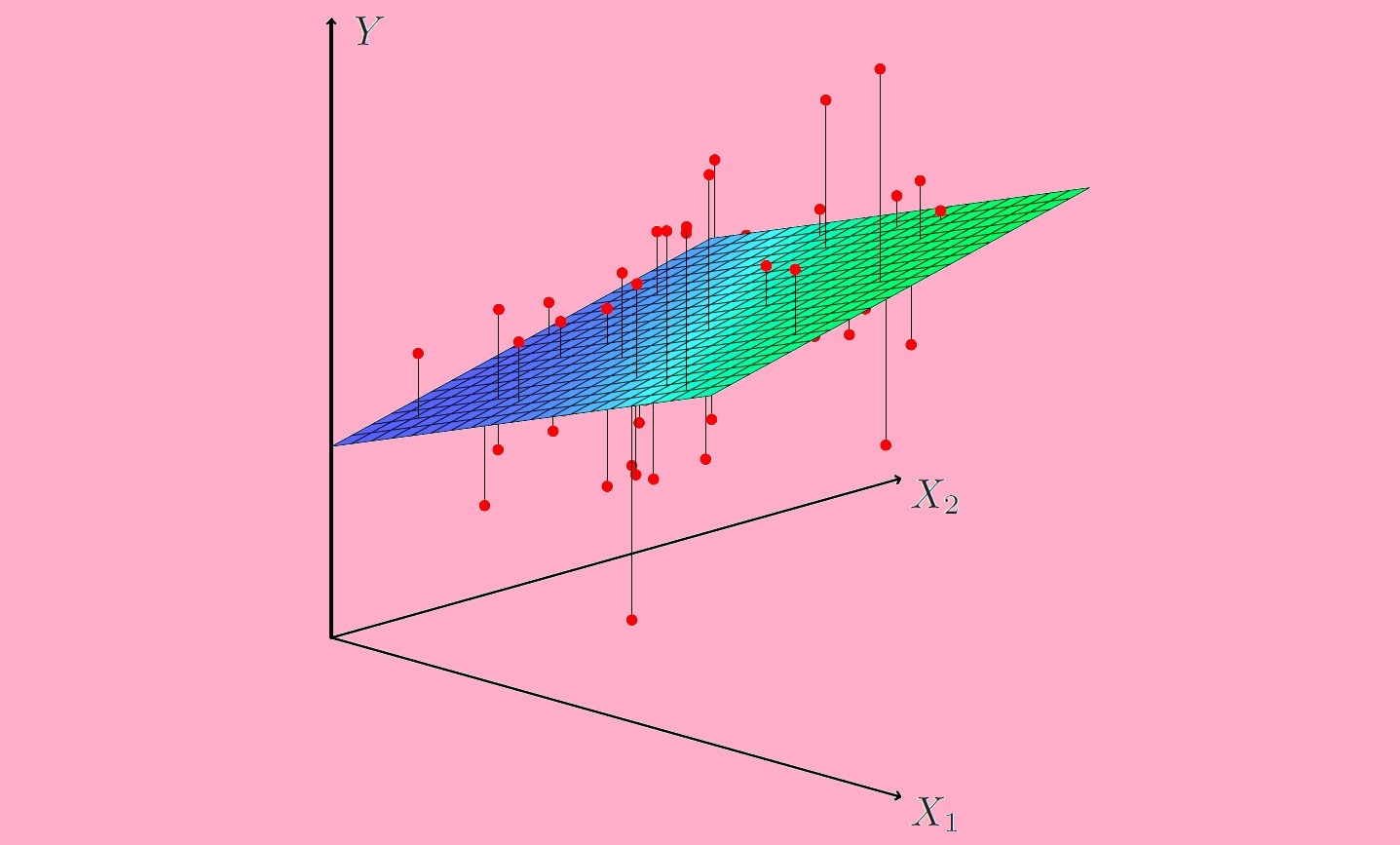


اگر رابطه خطی بین یک متغیر پاسخ و یک متغیر مستقل برقرار شود، تکنیک رگرسیون را رگرسیون خطی ساده (Simple Linear Regression) مینامند. ولی در صورت به کارگیری چندین متغیر توصیفی یا مستقل در مدل رگرسیونی، روش رگرسیونی را «چند گانه» (Multiple Linear Regression) میگویند. البته روش رگرسیونی دیگری براساس چند متغیر پاسخ و مستقل نیز به کار گرفته میشود که به آن «رگرسیون چند متغیره» (Multivariate Regression) گفته شده و بیش از یک متغیر پاسخ مورد تحلیل و مدلسازی قرار میگیرد.
از رگرسیون خطی چندگانه در بسیاری از شاخههای علوم بخصوص فیزیک و شیمی استفاده میشود. همچنین برای پیشگویی روند دادههای مالی از رگرسیون چندگانه بهره میگیرند.
البته در این نوشتار به بررسی رگرسیون چندگانه میپردازیم. برای اطلاع از مبانی و تاریخچه رگرسیون بهتر است مطلب رگرسیون خطی — مفهوم و محاسبات به زبان ساده را بخوانید. همچنین خواندن نوشتار ضریبهای همبستگی (Correlation Coefficients) و شیوه محاسبه آنها — به زبان ساده و هم خطی در مدل رگرسیونی — به زبان ساده نیز خالی از لطف نیست.
رگرسیون خطی چندگانه (Multiple Linear Regression)
در رگرسیون خطی چندگانه، پارامترهای یک مدل خطی به کمک یه تابع هدف و مقدارهای متغیرها، برآورد میشوند. در رگرسیون خطی، مدل در نظر گرفته شده، یک رابطه خطی برحسب پارامترهای مدل است.
به این ترتیب اگر مشاهده از متغیر مستقل بعدی داشته باشیم و بخواهیم یک رابطه خطی با متغیر پاسخ برقرار کنیم، میتوانیم از مدل رگرسیون خطی زیر استفاده کنیم.
از آنجایی که متغیر مستقل دارای بعد است، مقدار آن را در هر بعد با یک متغیر مستقل یک بعدی جایگزین کردهایم. مشخص است که اندیس نیز شماره مشاهده را نشان میدهد. در انتها نیز جمله خطای مدل رگرسیونی محسوب میشود.
نکته: باید توجه داشت که در مدل رگرسیون خطی، رابطه بین پارامترها خطی است. به این ترتیب مدلی به صورت نیز یک مدل خطی برحسب پارامترها است. در حالیکه رابطه دیگر یک رابطه خطی براساس پارامترها محسوب نخواهد شد.
در رگرسیون خطی ساده، رابطه بین متغیر مستقل و وابسته به صورت معادله یک خط بیان میشود. در رگرسیون چندگانه، اگر دو متغیر مستقل با یک متغیر وابسته در رابطه خطی باشند، شکل این رابطه به صورت یک صفحه (plane) در خواهد آمد. در صورتی که بیش از دو متغیر مستقل در مدل رگرسیون خطی به کار روند، مدل به شکل یک «ابرصفحه» (Hyperplane) ظاهر میشود.

مدل رگرسیون خطی
مدل رگرسیون خطی را میتوان به صورت یک رابطه برداری نیز نوشت.
در این حالت، ، یک بردار است که دارای ستون است. همچنین نیز برداری است که سطر دارد. ضمناً منظور از نیز ضرب داخلی این دو بردار است که حاصل آن یک عدد (Scalar) خواهد بود. اگر بردارهای و مشخص باشند میتوان مقدار متغیر پاسخ یعنی را با میزان خطای متوسط ، بر اساس هر مشاهده برآورد کرد.
این محاسبات را به صورت ماتریسی و برای همه مشاهدات به صورت یکجا نیز نوشتهاند. فرض کنید که بردار مشاهدات متغیر پاسخ باشد. به همین ترتیب نیز ماتریس مربوط به متغیر مستقل بعدی و نیز بردار پارامترهای مدل با سطر باشد. اگر بردار خطا را نیز بنامیم، مدل رگرسیون خطی را میتوان به زبان ماتریس و بردارها به صورت زیر بازنویسی کرد.
ماتریسها و بردارها به کار رفته در رابطه بالا در ادامه قابل مشاهدهاند.
در ادامه به بررسی ماتریس و بردار مورد استفاده در رابطه بالا خواهیم پرداخت.
بردار مشاهدات متغیر پاسخ (): این بردار از مقدارهای متغیر پاسخ برای هر مشاهده یعنی ها تشکیل شده است. به این ترتیب مقدار متغیر پاسخ برای مشاهده اول و مقدار متغیر پاسخ برای مشاهده iام و در انتها نیز نیز مقدار متغیر پاسخ برای مشاهده nام است. پس یک بردار n سطری است.
ماتریس متغیرهای مستقل (): سطرهای این ماتریس، از مقدار مشاهدات متغیرهای مستقل تشکیل شده است. به این ترتیب سطر اول مربوط به مقدارهای متغیرهای مستقل برای مشاهده اول است. از آنجایی که هر مشاهده دارای متغیر مستقل است، تعداد ستونهای این ماتریس نیز است. از طرفی با توجه به مشاهده نیز مشخص است که تعداد سطرهای این ماتریس باید برابر با باشد. پس این ابعاد این ماتریس را میتوان به صورت در نظر گرفت.
نکته: همانطور که در ماتریس مشاهده میکنید، همه مقادیر مربوط به ستون اول برابر با ۱ هستند. در نتیجه این ماتریس دارای سطر و ستون است. این امر به علت آن است که برای مقدار ثابت در بردار (یعنی مقدار ) نیز امکان محاسبه وجود داشته باشد. اگر در مدل رگرسیون مقدار ثابت در نظر گرفته نشود، این ستون را حذف کرده و در بردار پارامترها نیز را در نظر نمیگیرند. گاهی به ماتریس ، «ماتریس طرح» (Design Matrix) نیز میگویند.
بردار پارامترها (): این بردار در حالت عمومی دارای سطر است که مقدار ثابت در مدل را نشان میدهد. این پارامترهای در صورت برآورد، همان «ضرایب مدل رگرسیونی» (Regression Coefficients) هستند. مقدار این ضرایب، حساسیت متغیر پاسخ را به هر یک از متغیرهای مستقل نشان میدهد. محاسبه این ضرایب به کمک کمینه سازی «مجموع مربعات خطا» (Ordinary Least Square) و براساس محاسبه «مشتقات جزئی» (partial deviation) صورت میگیرد. اگر مقدار ثابت () در مدل رگرسیون لحاظ نشود، این بردار دارای سطر خواهد بود. البته باید توجه داشت که در این حالت، ماتریس نیز دچار تغییر خواهد شد. به متن مربوط به نکته بالا توجه کنید.
بردار خطا (): این بخش از مدل رگرسیون خطی، «جمله خطا» (Error Term) نامیده میشود. مقدار این عبارت شامل همه عواملی است که ممکن است روی مقدار متغیر پاسخ تاثیر گذار بوده ولی در مدل رگرسیونی منظور نشدهاند. این بردار به تعداد مشاهدات سطر دارد. به این ترتیب بُعد آن به صورت است.
مثال
در فیزیک و قوانین حرکت خواندهایم که مسافت طی شده از مکان در طی زمان برای یک جسم با شتاب و سرعت اولیه به صورت زیر نوشته میشود.
واضح است که در این مدل یک رابطه رگرسیون خطی وجود دارد. با استفاده از دادههای اندازهگیری شده برای حرکت یک جسم با شتاب، سرعت اولیه و زمانهای مختلف، امکان برآورد این پارامترها بوجود میآید. حال میتوان مشاهدات برای چنین مدلی را به صورت زیر نشان داد.
در اینجا مشخص است که یک مدل رگرسیون دوگانه مورد نظر است. متغیرهای توصیفی در این مدل به ترتیب و هستند و هر مشاهده به صورت متناظر با نوشته میشوند. این مدل برحسب متغیر زمان، غیر خطی ولی براساس پارامترها یک مدل خطی محسوب میشود. به این ترتیب و خواهند بود. نیز تغییر مکان در زمان صفر است. (البته میتوان در چنین مدلی مقدار را صفر در نظر گرفت زیرا در زمان صفر هیچ تغییر مکانی وجود ندارد.
برآورد پارامترهای مدل رگرسیون خطی
مدل برداری و ماتریسی رگرسیون خطی را در نظر بگیرید. همانطور که بیان کردیم، یکی از روشهای برآورد پارامترهای این مدل استفاده از تکنیک OLS یا «کمینه سازی مربعات خطا» (Ordinary Least Square) است. در این قسمت به بررسی این روش به منظور برآورد پارامترهای مدل رگرسیون خطی میپردازیم.
اگر را به صورت زیر معرفی کنیم، هدف از برآورد پارامترهای مدل رگرسیون خطی، محاسبه بردار برحسب مقدار مشاهدات است تا حداقل ممکن شود.
مشخص است که منظور از مربع فاصله یا نرم اقلیدسی است. اگر برآورد بردار پارامترها را با نشان دهیم، پارامترهای مدل، مقادیری هستند که در رابطه زیر صدق کنند.
به کمک مشتقگیری و حل معادلات ماتریسی، برآورد پارامترها به صورت زیر خواهد بود.
توجه داشته باشید که این برآورد، زمانی امکان پذیر است که ماتریس معکوس پذیر باشد. به این معنی که دترمینان آن باید مخالف صفر بوده تا نشان دهنده عدم وابستگی خطی بین سطرها یا ستونهای ماتریس باشد. به همین دلیل یکی از شرطهای اصلی در مدل رگرسیون خطی، استقلال متغیرهای توصیفی است. در غیر این صورت ماتریس معکوس پذیر نبوده و امکان برآورد پارامترها وجود ندارد. همچنین وجود شرط کم بودن تعداد متغیرها نسبت به مشاهدات () نیز به این منظور باید رعایت شود. در نوشتار رگرسیون لاسو (Lasso Regression) — به زبان ساده، مثالی وجود دارد که با توجه به بزرگ بودن بعد مسئله نسبت به مشاهدات، معکوسپذیری ماتریس از بین میرود.
توجه داشته باشید اگر فقط یک متغیر مستقل وجود داشته باشد، مدل رگرسیونی به صورت مدل رگرسیونی خطی ساده در خواهد آمد. برآورد پارامترهای چنین مدلی به سادگی به کمک مشتق از تابع مربعات خطا و حل یک دستگاه حاصل میشود. به این ترتیب «عرض از مبدا» (Intercept) و نیز «شیب خط» (Coefficient) را نشان میدهند.
نکته: اگر تعداد پارامترها بیشتر از تعداد مشاهدات باشد باید از روشهای رگرسیون دیگر مانند رگرسیون لاسو (Lasso Regression) استفاده کرد.
فرضیات مدل رگرسیون خطی در تکنیک OLS
در برآورد پارامترهای مدل رگرسیون خطی به روش OLS باید شرطهایی را در نظر گرفت تا مدل ارائه شده، معتبر باشد. در ادامه این شرطها مورد بررسی قرار میگیرند.
مدل توصیفی
در هنگام ایجاد مدل رگرسیونی باید متغیرهایی مستقلی که بیشترین میزان رابطه را با متغیر پاسخ دارند به کار گرفت. همچنین به منظور بررسی رابطه خطی بین متغیرهای پاسخ و مستقل از ضرایب همبستگی یا ترسیم نقاط در حالت سه بعدی (یا حتی زوجهای متغیرهای مستقل و پاسخ) کار ساز است.
عدم وابستگی متغیرهای مستقل با جمله خطا
جملات خطا نباید هیچ وابستگی با متغیرهای مستقل داشته باشند، از طرفی میانگین جملات خطا نیز باید صفر باشد. به این ترتیب باید شرط و همچنین بررسی و مورد تایید قرار گیرد تا مدل حاصل از OLS در رگرسیون خطی معتبر باشد. توجه دارید که منظور از امید ریاضی (میانگین) جملات خطا است.

عدم وابستگی خطی
همانطور که دیدیم، یکی از شرطها در محاسبات OLS، معکوس پذیر بودن ماتریس بود. به این ترتیب ماتریس باید پر رتبه باشد. به بیان دیگر باید رابطه زیر برای این ماتریس برقرار باشد.
این شرط بوسیله عدم وابستگی خطی بین متغیرهای مستقل تضمین میشود. به این ترتیب قبل از اجرا و انجام محاسبات رگرسیون خطی باید وجود رابطه خطی بین متغیرهای مستقل بوسیله ضریب همبستگی یا رسم نمودارهای نقطهای (Scatter Plot) مورد تایید قرار گیرد. در صورت وابستگی خطی بین متغیرهای توصیفی با مشکل «همخطی چندگانه» (Multicollinear) مواجه خواهیم شد و مقدار هر متغیر در پارامترهای متغیرهای دیگر تاثیر گذار خواهد بود. در این صورت واریانس براوردگرها بزرگ شده و اعتبار مدل از بین خواهد رفت.
خصوصیات جملات خطا
به منظور اعتبار بخشی و همچنین بررسی فرضیات برآوردهای صورت گرفته توسط روش OLS باید شرایط زیر را برای جملات خطا مورد کاوش قرار دارد.
ثابت بودن واریانس: واریانس جملات خطا باید ثابت باشد. به این معنی که با توجه به مشاهدات صورت گرفته، واریانس جمله خطا تغییر نکند. به بیان آماری این جمله را به صورت زیر بیان میکنیم.
در صورتی که واریانس ثابت نباشد، با استفاده از وزندهی به مشاهدات میتوان واریانس را ثابت کرد. این عمل در برآورد پارامترهای «رگرسیونی وزنی» (Weighted Least Squares) مورد استفاده قرار میگیرد.
عدم وابستگی جملات خطا: استقلال عبارت خطا برای مشاهدات یکی از فرضیات مهم در روش OLS محسوب میشود. با توجه به ثابت بودن واریانس عبارت خطا، عدم وابستگی بین جملات خطا را میتوان به صورت زیر نشان داد.
توزیع نرمال برای جملات خطا: هر چند این شرط، مربوط به تکنیک OLS نیست ولی گاهی اوقات برای امکان اجرای آزمون فرض در مورد پارامترهای برآورد شده این شرط ضروری به نظر میرسد. به این ترتیب توزیع احتمالی عبارت خطا به شرط متغیرهای مستقل باید نرمال باشد. با توجه به توضیحات گفته شده در این بخش، خواهیم داشت:
در ادامه به بررسی مثالی میپردازیم که در آن بوسیله رگرسیون خطی، یک تابع غیرخطی مثل را برآورد میکنیم.
تخمین تابع سینوس بوسیله رگرسیون خطی
همانطور که در مطلب سری تیلور — از صفر تا صد خواندهاید، میدانید که امکان تقریب زدن توابع مثلثاتی بوسیله چند جملهایها وجود دارد. بسط یا سری تیلور برای تابع سینوس به صورت زیر نوشته میشود.
در اینجا هم با کمی اقماض در مورد وابستگی متغیرهای مستقل، سعی میکنیم به کمک دادههای تولید شده بوسیله بسط یا سری تیلور و برآورد پارامترهای مدل رگرسیونی، تقریبی مناسب برای تابع سینوس ارائه دهیم. هر چه تعداد جملات سری تیلور بیشتر باشد دقت در محاسبه سینوس زاویه بیشتر میشود. در مدل رگرسیون خطی نیز اگر تعداد متغیرها را بیشتر در نظر بگیریم و از جملاتی بیشتر سری تیلور استفاده کنیم، دقت برآوردها بیشتر شده و به مقدار واقعی سینوس هر زاویه نزدیکتر میشویم.
مثال
جدول زیر مربوط به دادههایی است که براساس مقدار توانهای فرد (یک، سه و پنچ) از زاویههای مختلف (برحسب رادیان) و همچنین مقدار سینوس آن زوایهها ساخته شده است. قرار است، بوسیله مدل رگرسیون خطی، ضرایب مربوط به بسط یا سری تیلور را محاسبه کنیم تا با دقت مناسب مقدار سینوس هر زاویه را بدست آوریم. البته از آنجایی که سینوس هر زاویه از قبل مشخص است، میتوانیم مقدار خطا را اندازهگیری کرده و نسبت به مناسب بودن مدل (کم بودن خطای مدل) تصمیم بگیریم.
| 0 | 0 | 0 |
| 0.2 | 0.008 | 0.2 |
| 0.4 | 0.064 | 0.39 |
| 0.6 | 0.216 | 0.56 |
| 0.8 | 0.512 | 0.72 |
| 1 | 1 | 0.84 |
از آنجایی که برای برآورد مقدار تابع سینوس از متغیرهای و استفاده خواهیم کرد، لازم است ابتدا ماتریس و بردارهای و را تشکیل دهیم.
بردار بوسیله مقدارهای ستون ساخته میشود. پس داریم:
حال به ایجاد ماتریس میپردازیم. توجه داشته باشید که در این مسئله از دو متغیر توصیفی برای پیشبینی مقدار سینوسن در بسط تیلور استفاده خواهیم کرد.
نکته: از آنجایی که در این مدل، مقدار ثابت وجود ندارد ماتریس دارای ستون خواهد بود. همین موضوع را در هنگام نوشتن بردار نیز رعایت میکنیم و برای آن فقط سطر در نظر میگیریم. به این ترتیب مقدار است.
با در نظر گرفتن این موضوع، بردار هم به شکل زیر نوشته میشود.
حال با استفاده از رابطه برآورد پارامترها را محاسبه میکنیم. در گام اول بخش ابتدایی رابطه یعنی را محاسبه میکنیم. به کمک روابطی که در جبر خطی برای پیدا کردن ترانهاده ماتریسها و ضرب آنها به یاد داریم، نتیجه این محاسبه به صورتی که در ادامه قابل مشاهده است در خواهد آمد.
در گام دوم به معکوس ماتریس بالا احتیاج داریم. به این ترتیب معکوس این ماتریس مطابق با رابطه زیر خواهد بود.
در گام سوم نیز حاصل ضرب ماتریس در بردار مشاهدات متغیر پاسخ نیز به صورت زیر قابل محاسبه است.
در انتها، براساس ضرب این قسمتها، برآورد پارامترهای مدل رگرسیون دو گانه، حاصل خواهد شد.
پس مشخص است که پارامتر اول برای این مدل رگرسیونی برابر و پارامتر دوم نیز برابر با است.
نکته: همانطور که در سری یا بسط تیلور تابع سینوس دیده میشود ضرایب مربوط به هر یک از متغیرها به ترتیب به صورت و است که با برآوردهای حاصل از رگرسیون بسیار نزدیک است.
اگر بوسیله مدل بدست آمده، خطا (مقدار تفاضل واقعی سینوس از برآورد مقدار سینوس توسط مدل رگرسیونی) را اندازهگیری کنیم، مجموع مربعات خطا، حداقل ممکن را نسبت به هر رابطه خطی دیگر خواهد داشت. به جدول زیر توجه کنید.
| 0 | 0 | 0 | 0 |
| 0.1987 | 0.2 | 0.0013 | 1.69E-06 |
| 0.3893 | 0.39 | 0.0007 | 4.9E-07 |
| 0.564 | 0.56 | -0.004 | 1.6E-05 |
| 0.7147 | 0.72 | 0.0053 | 2.809E-05 |
| 0.8333 | 0.84 | 0.0067 | 4.489E-05 |
| مجموع مربعات خطا | 9.116E-05 |
همانطور که دیده میشود، مجموع مربعات خطای این مدل بسیار به صفر نزدیک است که نشانگر مناسب بودن مدل است. سنجش فرضهای مربوط به رگرسیون خطی برای چنین مدلی به علت کم بودن تعداد مشاهدات به درستی صورت نخواهد گرفت. البته به منظور ارزیابی مدل حاصل باید از روشهای دیگری مانند آنالیز واریانس و آزمون فرض استفاده کرد که در این نوشتار از آنها صرفنظر میکنیم. در دیگر نوشتارهای فرادرس با موضوع رگرسیون خطی با SPSS به بررسی و سنجش فرضیات مدل و ارزیابی آن خواهیم پرداخت.
اگر مطلب بالا برای شما مفید بوده است، آموزشهای زیر نیز به شما پیشنهاد میشوند:
- مجموعه آموزش های SPSS
- مجموعه آموزشهای داده کاوی یا Data Mining در متلب
- مجموعه آموزشهای نرمافزارهای آماری
- آموزش همبستگی و رگرسیون خطی در SPSS
- رگرسیون خطی — مفهوم و محاسبات به زبان ساده
- تحلیل واریانس (Anova) — مفاهیم و کاربردها
^^











سلام، مطلبتون عالیه، فقط از پایه میخوام مطالعه داشته باشم، جزوه ویا خلاصه دارین ومعرفی بفرماین برای دانستن بیشتر اقتصادسنجی
سلام، وقت شما بخیر؛
در رابطه با بحث اقتصادسنجی و مسیر یادگیری آن پیشنهاد میکنیم به سراغ این مطلب از مجله فرادرس با عنوان «اقتصاد سنجی چیست ؟ — به زبان ساده + معرفی فیلم های آموزشی» بروید که راهنمایی کاملی را در این زمینه ارائه کرده است.
ممنون از آقای ری بد عزیز، آموزشهای ایشان واقعا کاربردی و ساده فهم هست، امیدوارم ایشون همواره در نشر آمورشهای آماری فعال باشند.
سلام
ای کاش مانند wikipedia لینکی برای دانلود فایل وجود داشت