



آموزش مدل های رگرسیون با استفاده از الگوریتم گرادیان کاهشی
مدلهای یادگیری ماشین، انواع مختلفی دارند. نوع نظارت شده (Supervised) این مدلها، پس از ایجاد، به صورت خام هستند. به این معنی که مدل (Model) میتواند با دریافت یک ورودی (Input یا x)، خروجی (Output یا y) مربوط به آن را تولید کند اما این پیشبینی (Prediction) انجام شده بدون یادگیری مجموعه داده (Dataset) است. در طول فرآیند آموزش (Training)، مدل اطلاعات و علم موجود در مجموعه داده را کشف میکند. پس از یادگیری، پیشبینیهای مدل به واقعیت موجود در مجموعه داده نزدیک خواهد بود. مدلهای رگرسیون نیز جزئی از این مدلها هستند که میتوانند ویژگیهای عددی پیوسته را پیشبینی کنند. در این مطلب قصد داریم مدل های رگرسیون ساده را ایجاد کنیم و سپس با استفاده از الگوریتم گرادیان کاهشی (Gradient Descent) و مشتق عددی (Numerical Differentiation) آنها را آموزش دهیم.
- ساختار و منطق الگوریتم گرادیان کاهشی را در آموزش مدلها میآموزید.
- یاد خواهید گرفت چگونه برای مدلسازی، داده مصنوعی با توزیع نرمال تولید کنید.
- یاد میگیرید گرادیان عددی را با تکنیکهای تفاضلی برای پارامترها محاسبه کنید.
- خواهید توانست با کدنویسی پایتون، مدل خطی یا غیرخطی بسازید و آموزش دهید.
- میآموزید با استفاده از نمودارها روند کاهش خطا و همگرایی مدل را تحلیل کنید.
- روشهای ارزیابی دقت مدل از جمله معیار «MSE» و «R2» را به کار میگیرید.


الگوریتم گرادیان کاهشی چیست؟
یک الگوریتم بهینهسازی (Optimization) است. با توجه به اینکه این الگوریتم برای بهینهسازی تنها از گرادیان استفاده میکند، از مرتبه اول (First Order) است. این الگوریتم در چندین تکرار فرآیند بهینهسازی را کامل میکند، بنابراین تکرارشونده (Iterative) نیز است.
اگر تابع هدف F را در نظر داشته باشیم و قصد کمینهسازی (Minimization) آن را داشته باشیم، یک حدس اولیه برای ورودی آن خواهیم داشت که با نام x_0 میشناسیم. در نکته x_0، گرادیان تابع F به شکل زیر خواهد بود:
در این شرایط، الگوریتم گرادیان کاهشی، تغییرات زیر را توصیه میکند:
به این ترتیب، با داشتن مقدار حدس اولیه و گرادیان تابع در نقطه حدس اولیه، میتوانیم حدس بعدی را داشته باشیم. این روند میتواند تا تعداد مشخصی از مراحل انجام شود. در نهایت به رابطه عمومی زیر میتوان رسید:
متغیر α عددی کوچک است که اغلب در بازه [0.1,0.0001] قرار میگیرد. این ضریب با نام نرخ یادگیری (Learning Rate) شناخته میشود و تنظیم آن بسیار حائز اهمیت است. به ازای یک مقدار مناسب از α و یک تخمین دقیق از گرادیان، خواهیم داشت:
بنابراین یک روند یکنوای کاهشی خواهیم داشت. از این الگوریتم میتوانیم برای کمینهسازی تابع هزینه (Cost Function) یا تابع خطا (Loss Function) استفاده کنیم. معیارهای مختلفی از دقت و خطا در رگرسیون وجود دارد که با مراجعه به مطلب «ارزیابی رگرسیون در پایتون» میتوانید در این باره مطالعه نمایید.
یکی از معیارهای خطای پرکاربرد در رگرسیون، میانگین مربعات خطا (Mean Squared Error یا MSE) است. این معیار میتواند به عنوان تابع هدف کمینه شود. اگر آرایه Y شامل مقادیر واقعی هدف (True Value یا Target Values) و شامل مقادیر پیشبینی مدل (Predicted Values) باشد، میانگین مربعات خطا به شکل زیر تعریف میشود:
با توجه به اینکه مقادیر Y جزء مجوعه داده هستند، نمیتوان آنها را تغییر داد، بنابراین باید کمینهسازی MSE با استفاده از صورت گیرد. مقادیر تحت تأثیر تو مجموعه از اعداد قرار دارد:
- ورودیهای مدل (X)
- پارامترهای مدل (W)
از بین این دو مورد، تنها پارامترهای مدل قابل تغییر و تنظیم هستند. به این ترتیب میتوان گفت که کمینهسازی MSE تنها با تنظیم مقادیر پارامترها یا آرایه W امکانپذیر است. اگر تابع هزینه را با نام J بشناسیم، در ورودی بردار (Vector) W را دریافت خواهد کرد و در خروجی یک عدد غیرمنفی خواهیم داشت:
در عبارت فوق، مدل استفاده شده را معادل تابع M در نظر گرفتهایم. این مدل میتواند انواع مختلفی از جمله خطی (Linear)، درجه دوم (Quadratic)، نمایی (Exponential) و ... داشته باشد. میتوانیم با قرار دادن ضابطه تابع M در رابطه نوشته شده، نسبت به هر پارامتر مشتق بگیریم و بردار گرادیان حاصل شود. این روش با استفاده از تعریف دقیق مشتق و به کارگیری روابط مشتقگیری کار میکند.

در مقابل روش گفته شده، مشتق عددی قرار دارد. این روش از روابط تقریبی برای تخمین مشتق هر تابع نسبت به هر ورودی استفاده میکند. اگر تابع F را با ورودی x متصور باشیم، مشتق عددی این تابع میتواند به دو روش زیر محاسبه شود:
این دو روش به ترتیب با اسمهای زیر شناخته میشوند:
- تفاضل رو به جلو (Forward Difference)
- تفاضل رو به عقب (Backward Difference)
مقدار h آورده شده در روابط، عددی کوچک است. با توجه به اینکه میانگین بازه هر دو روش بر روی نقطه x قرار نمیگیرد، میانگین این دو روش به شکل زیر محاسبه میشود:
به این ترتیب، فرمول مربوط به تفاضل مرکزی (Central Difference) حاصل میشود. برای آشنایی بیشتر با مشتق عددی، میتوانیم به مطلب «مشتق گیری عددی – به زبان ساده» مراجعه نمایید.
فرمول آورده شده، برای تابعی با تنها یک ورودی بود. با توجه به اینکه تابع هزینه تعریف شده، یک بردار ورودی به نام W دریافت میکند و شامل پارامترهای مختلفی است، بنابراین برای هر پارامتر میتوان این عملیات را تکرار و مقدار گرادیان را با روش عددی تخمین زد.
دانلود کد الگوریتم گرادیان کاهشی
با توجه به پیچیده و طولانی بودن روند کدنویسی الگوریتم، احتمال اشتباه در پیادهسازی کدها وجود دارد، به همین جهت کدهای نهایی حاصل بر روی سایت آپلود شده است.
- برای دریافت کدهای الگوریتم گرادیان کاهشی، + اینجا کلیک کنید.
فراخوانی کتابخانههای مورد نیاز برای آموزش مدل رگرسیون با گرادیان کاهشی
برای انجام محاسبات برداری (Vectorized Computation) و رسم نمودارهای مورد نیاز، دو کتابخانه Numpy و Matplotlib را فراخوانی میکنیم:
در طول کدنویسی از اعداد تصادفی (Random Numbers) برای تولید مجموعه داده مصنوعی (Synthetic Dataset) استفاده خواهیم کرد، بنابراین با هربار اجرا مجموعه داده ایجاد شده متفاوت با سایرین است. برای جلوگیری از این امر، قطعه کد زیر را استفاده میکنیم:
برای بهتر کردن ظاهر نمودارها نیز، با استفاده از قطعه کد زیر، یک Style برای نمودارها تعریف میشود:
در اولین مرحله، قصد داریم یک مدل خطی ایجاد و آموزش دهیم. به همین یک مجموعه داده با ضابطه زیر ایجاد میکنیم که با یک مدل خطی قابل برازش باشد:
بخش x یک متغیر مستقل (Independent Variable) را نشان میدهد که دارای توزیع نرمال (Normal Distribution) است. بخش y متغیری وابسته (Dependent Variable) است که باید ارتباط آن با x کشف شود. بخش e استفاده شده در عبارت، نشاندهنده یک نویز (Noise) با توزیع تصادفی نرمال است تا مجموعه داده ایجاد شده طبیعی باشد.
ایجاد مجموعه داده مصنوعی برای آموزش مدل رگرسیون با گرادیان کاهشی
به منظور ایجاد این مجوعه داده، ابتدا تعداد داده را تعیین میکنیم:
به افزایش این عدد، دادههای بیشتری تولید میشود و مدل خواهد توانست با دقت بیشتری به ضابطه آورده شده همگرا (Converge) شود. حال میتوانیم مقادیر متغیر مستقل (x) را برای 200 داده انتخاب کنیم:
توجه داشته باشید که ورودی loc محل مرکز توزیع را نشان میدهد. با توجه به اینکه مقدار 1 برای این ورودی تعیین شده است، انتظار داریم میانگین مقادیر X عددی نزدیک به 1 باشد.
ورودی scale انحراف معیار توزیع را نشان میدهد. با افزایش این عدد، پراکندگی مقادیر X حول 1 افزایش مییابد اما همچنان میانگین مقادیر X نزدیک به 1 خواهد بود.
ورودی size تعداد اعداد تصادفی تولید شده یا ابعاد آن را نشان میدهد. با توجه به اینکه تنها یک متغیر مستقل داریم، آرایه (Array) X را به شکل یکبُعدی ایجاد کردیم. در یک آرایه نیز باید مقادیر نویز را ایجاد کنیم. مشابه X برای این آرایه نیز خواهیم داشت:
مقادیر نویز اغلب نسبت به متغیرهای مستقل شدت کمتری دارند و به همین دلیل ویژگی هدف (Target Feature) یا متغیر وابسته قابل پیشبینی است.
حال میتوانیم آرایه Y را ایجاد کنیم:
توجه داشته باشید که دو متغیر X و E آرایه هستند اما به دلیل امکانات موجود در کتابخانه Numpy میتوانیم آنها را با عبارات ساده ریاضی وارد رابطه کنیم.
ابعاد نهایی این 3 آرایه به شکل زیر قابل بررسی هست:
که خواهیم داشت:
به این ترتیب مشاهده میکنیم که ابعاد هر 3 آرایه صحیح است. میتوانیم توزیع مقادیر این 3 آرایه را نیز بررسی کنیم:
قطعه کد بالا، برای آرایه X نوشته شده است. میتوان مشابه این کد را برای آرایههای E و Y نیز بنویسیم و نمودارهای زیر حاصل شود.
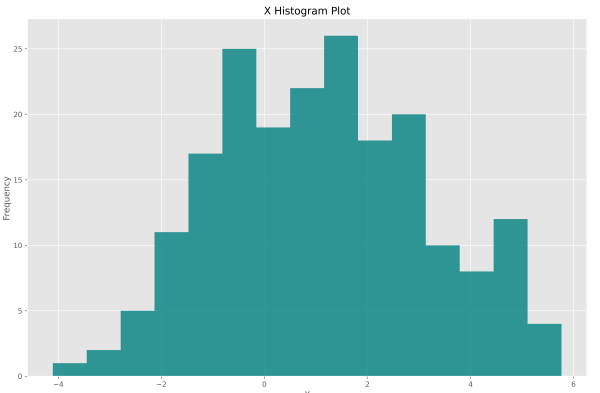
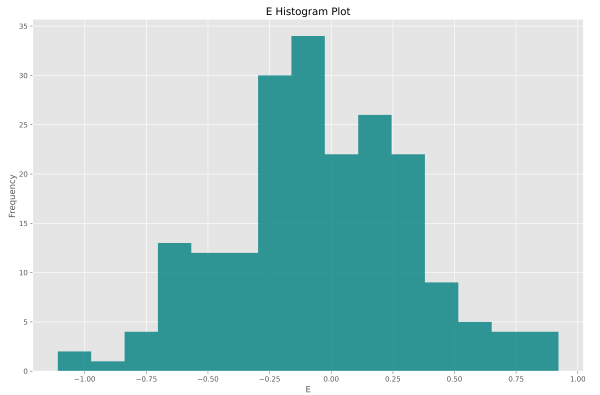
به این ترتیب میتوانیم مشاهده کنیم که دادهها از توزیع و معیارهای آماری مد نظر ما برخوردار هستند. میتوانیم از دو تابع numpy.mean و numpy.std برای محاسبه میانگین و انحراف معیار آرایهها استفاده کنیم.
در این مجموعه داده یک متغیر مستقل و یک متغیر وابسته وجود دارد. به همین جهت میتوانیم یک نمودار نقطهای (Scatter Plot) رسم کنیم تا ارتباط بین آنها را نمایش دهیم. به همین جهت از کد زیر استفاده میکنیم:
پس از اجرای کد بالا، نموداری مشابه با تصویر زیر به دست میآید.
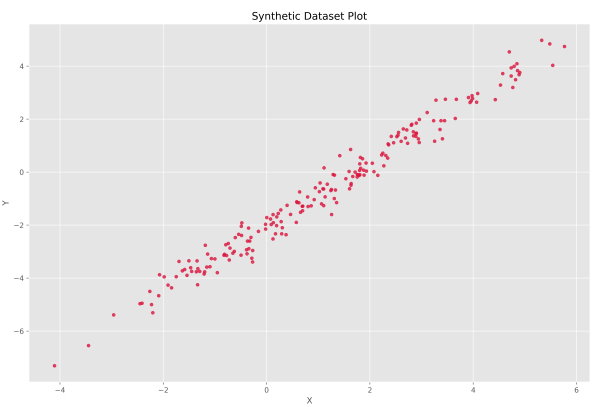
به این ترتیب مشاهده میکنیم که رابطه خطی قابل تصور است.
ایجاد تابع مدل خطی برای آموزش مدل رگرسیون با گرادیان کاهشی
با توجه به اینکه قصد داریم از یک مدل خطی برای پیشبینی استفاده کنیم، یک تابع با نام LinearModel ایجاد میکنیم که در ورودی آرایه پارامترهای مدل (W) و آرایه دادههای ورودی (X) را دریافت خواهد کرد:
با توجه به اینکه خروجی این تابع نیز آرایه پیشبینیهای انجام شده است، تکه کد را استفاده کردیم. اولین عضو آرایه W را به عنوان عرض از مبدا (Intercept) یا بایاس (Bias) و دومین عضو را به عنوان شیب (Slope) یا ضریب متغیر مستقل اول در نظر میگیریم:
حال آرایه P را در خروجی برمیگردانیم:
به این ترتیب تابع مورد نظر با ورودی و خروجیهای مد نظر ایجاد میشود.
ایجاد تابع هزینه برای آموزش مدل رگرسیون با گرادیان کاهشی
در این پروژه قصد داریم از میانگین مربعات خطر به عنوان تابع هزینه استفاده کنیم. بنابراین نیاز داریم تابعی ایجاد کنیم که با دریافت تابع مدل، آرایه پارامترهای مدل (W)، آرایه دادههای ورودی مدل (X) و آرایه دادههای هدف مدل (Y)، مقدار میانگین مربعات خطا را برگرداند:
توجه داشته باشید که مقدار میانگین مربعات خطا یک عدد اعشاری است، بنابراین از تکه کد -> float استفاده شده است. در اولین قدم، تابع مدل را با پارامترها و دادههای ورودی فراخوانی میکنیم تا مقادیر پیشبینی را بیابیم:
حال باید مقادیر پیشبینی را از مقادیر هدف کم کنیم تا آرایه خطا به دست آید. تابع numpy.subtract میتواند این عملیات را انجام دهد:
حال از آرایه خطا (E)، برای محاسبه آرایه مربعات خطا (Squared Error) استفاده میکنیم. تابع numpy.power میتواند این عملیات را انجام دهد:
حال باید از آرایه مربعات خطا (SE) میانگینگیری کنیم تا مقدار میانگین مربعات خطا حاصل شود و آن را در خروجی برگردانیم:
توجه داشته باشید که این تابع میتواند به شکل زیر نیز طراحی شود:
این دو کد به یک شکل عمل خواهند کرد.
مقداردهی اولیه پارامترها برای آموزش مدل رگرسیون با گرادیان کاهشی
با توجه به اینکه الگوریتم گرادیان کاهشی تکرار شونده است، پارامترهای به روز شده در هر مرحله، از روی پارامترهای مرحله قبلی محاسبه میشود، بنابراین در شروع کار الگوریتم، نیاز است تا پارامترها به شکل تصادفی (Random) مقداردهی شوند. به این جهت، ابتدا تعداد پارامترها را تعیین و سپس آنها را مقداردهی اولیه (Initialization) میکنیم:
مقداردهی اولیه وزنها، با توجه به مدل مورد استفاده و روشهای تجربی کشف شده، میتواند بهبود یابد تا سرعت همگرایی الگوریتم بهینهساز افزایش یابد.
تنظیمات کار الگوریتم برای آموزش مدل رگرسیون با گرادیان کاهشی
نیاز است تا تعداد مراحل کار الگوریتم، نرخ یادگیری و اپسیلون استفاده شده برای محاسبه گرادیان عددی را تعیین کنیم:
تعداد مراحل تکرار کم، ممکن است کافی نباشد و تعداد زیاد آن باعث بیشبرازش (Overfitting) شود، هرچند که احتمال این اتفاق برای مدلی خطی دارای 2 پارامتر با 200 داده کم است. نرخ یادگیری بزرگ، باعث ناپایدار شدن روند بهینهسازی و حتی واگرایی میشود، مقدار کم آن نیز سرعت همگرایی را کند و زمان اجرا را افزایش میدهد. مقدار اپسیلون باید نزدیک به صفر باشد. با شدت گرفتن مقدار آن، خطای تخمین عددی گرادیان افزایش مییابد.
بهینهسازی پارامترها برای آموزش مدل رگرسیون با گرادیان کاهشی
حال میتوانیم کد اصلی مربوط به بهینهسازی پارامترهای مدل را پیادهسازی کنیم. برای ذخیره خطای مدل در بین هر مرحله بهینهسازی، یک آرایه خالی ایجاد میکنیم. به این منظور از تابع np.zeros استفاده میکنیم:
حال حلقه مربوط به هر مرحله از بهینهسازی را ایجاد میکنیم:
در اولین قدم، خطای حاصل از پارامترهای فعلی را محاسبه میکنیم:
توجه داشته باشید که اولین ورودی تابع Loss تابع مربوط به مدل مورد استفاده است، بنابراین اگر بخواهیم مجموعه داده را با مدل دیگری برازش کنیم، تنها نیاز است که ورودی اول را تغییر دهیم. این ویژگی در برازش دادههایی با ارتباطهای غیرخطی (Non-Linear) بسیار حائز اهمیت است. پس از محاسبه مقدار خطا، آن را در آرایه MSEs ذخیره میکنیم
به ترتیب خطای قبل از هر تکرار را خواهیم داشت. برای نمایش شماره تکرار و مقدار نهایی تابع هزینه، تکه کد زیر را نیز اضافه میکنیم:
آوردن چنین پیامهایی در کدهای مربوط به بهینهسازی که تکرار میشوند، میتواند مهم باشد. مقدار خطا تا 4 رقم اعشار گرد شده است، با توجه به اینکه میانگین مربعات خطا دارای بُعد است، ممکن است برای برخی مسائل 4 رقم اعشار کافی نباشد.
حال باید تکرار مربوط به بهینهسازی را انجام دهیم. به این منظور بردار گرادیان نیاز است که محاسبه نشده است، بنابراین یک آرایه خالی به نام Gradient ایجاد میکنیم.
حال باید حلقه دیگری ایجاد کنیم و به ازای هر پارامتر، مقدار گرادیان محاسبه شود:
برای محاسبه گرادیان تابع هزینه نسبت به پارامتر شماره j به سه عدد زیر نیاز داریم:
- مقدار تابع هزینه با پارامترهای فعلی
- مقدار تابع هزینه پس از افزایش h واحدی در پارامتر شماره j
- مقدار h
مورد اول در ابتدای حلقه محاسبه شده است و در متغیر MSE0 موجود است. مورد سوم را نیز داخل کد تعیین کردهایم. باید مورد دوم محاسبه شود. به این منظور، مقدار پارامتر شماره j از آرایه W را به اندازه Epsilon افزایش میدهیم.
حال مقدار تابع هزینه را در این شرایط محاسبه میکنیم:
حال باید پارامتر j را به حالت قبلی برگردانیم:
به این ترتیب، مورد دوم نیز محاسبه میشود و تنها باید این سه عدد را در رابطه قرار دهیم:
به این ترتیب، در هر تکرار از بهینهسازی، برای هر پارامتر به صورت جداگانه این فرمول استفاده میشود. در انتهای حلقه دوم، بردار گرادیان کامل شده است و میتوانیم از آن برای یک تکرار بهینهسازی استفاده کنیم:
به این ترتیب کد مربوط به هسته اصلی بهینهسازی کامل میشود. پس از اتمام حلقه مربوط به مراحل تکرار، باید بار دیگر تابع هزینه را محاسبه و مقدار آن را ذخیره و نمایش دهیم:
توجه داشته باشید که اگر 300 مرحله تکرار داشته باشیم، 301 عدد خطا خواهیم داشت که قبل و بعد هر مرحله را نشان میدهند، به همین دلیل پس از اتمام حلقه باید یک مرحله دیگر این فرآیند را تکرار کنیم. کد را اگر اجرا کنیم، خروجی زیر حاصل خواهد شد:
به ترتیب مشاهده میکنیم که خطای مدل قبل از آموزش 13.3 بوده و در اولین تکرار به مقدار 12.1 کاهش یافته که معادل 9% کاهش است. در تکرارهای 299 و 300 این کاهش به 0.3% رسیده است. بنابراین میتوان ادعا کرد که مدل همگرا شده است. برای اثبات این ادعا، میتوانیم نمودار خطا را در طول آموزش رسم کنیم. خطاهای مدل در طول آموزش، داخل آرایه MSEs ذخیره شده است، بنابراین به شکل زیر عمل میکنیم:
توجه داشته باشید که تابع matplotlib.pyplot.plot اگر در ورودی تنها یک آرایه دریافت کند، به عنوان مقادیر محور افقی، از اعداد حسابی به طول آرایه ورودی استفاده میکند. با توجه به اینکه شماره تکرارها نیز از 0 شروع میشوند، این حالت مطلوب بوده و تنها یک آرایه در ورودی این تابع وارد میشود. برای این نمودار، مقیاس (Scale) محور عمودی به لگاریتمی تغییر یافته که یک نمودار نیمهلگاریتمی (Semi-Logarithmic) ایجاد میکند. انجام این کار به جهت نمایش بهتر تغییرات تابع هزینه در مراحل انتهایی آموزش حائز اهمیت است. پس از اجرای کد، نمودار زیر حاصل میشود.
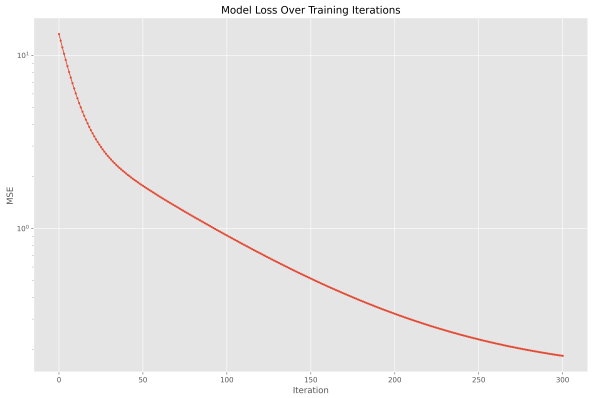
به این ترتیب مشاهده میکنیم که در کل روند آموزش تابع هزینه کاهش یافته ولی سرعت کاهش آن از تکرار 30 به بعد کاهش یافته و پس از تکرار 250 روند بسیار کندی به خود گرفته است.
انجام پیشبینی و بررسی آن برای آموزش مدل رگرسیون با گرادیان کاهشی
تابع هزینه درستی روند آموزش را نمایش میدهد. برای نمایش میزان برازندگی مدل، باید پیشبینی مدل برای مجموعه داده ورودی را دریافت کرده و آن را نمایش دهیم. به این منظور میتوانیم دو نوع نمودار زیر را رسم کنیم:
- نمودار پیشبینی در مقابل مقادیر هدف (این نمودار را با اسم Regression Plot خواهیم شناخت)
- نمودار پیشبینی و مقادیر هدف در مقابل مقادیر متغیر مستقل
مورد 1 میتواند برای تمامی مسائل رگرسیون رسم شود و قضاوت در مورد آن آسان است. مورد 2 در محور عمودی پیشبینی و مقادیر هدف را میگنجاند و در محور افقی تنها یک متغیر مستقل، بنابراین برای مسائلی از رگرسیون که تنها یک متغیر مستقل دخیل است مناسب است. در این مسئله میتوانیم هر دو مورد را رسم کنیم. قبل از رسم هر کدام از نمودارها، ابتدا با کمک پارامترهای نهایی، پیشبینی مدل برای هر داده را دریافت میکنیم:
حال میتوانیم نمودار 1 را رسم کنیم:
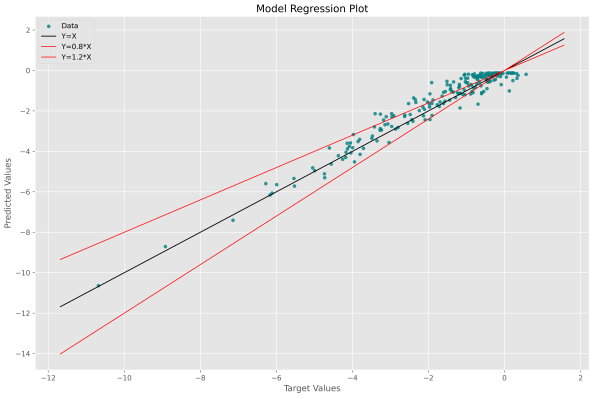
در این نمودار، محور افقی مقادیر هدف و محور عمودی مقادیر پیشبینی است. در صورتی که به یک مدل ایدهآل دست بیابیم که فاقد هرگونه خطا هست، تمامی نقاط بر روی خط y=x جمع خواهند شد، بنابراین این خط هدف است و باید در نمودار نشان دهیم. سه خط ابتدای مربوط به رسم این نمودار که شامل محاسبه دو عدد a و b است، دو نقطه ابتدا و انتهای خط y=x را تعیین میکند.

نکته مهم دیگر، دو ورودی ابتدایی تابع matplotlib.pyplot.scatter است. مورد اول مقادیر محور افقی و مورد دوم مقادیر محور عمودی را نشان میدهد. جابهجایی این دو ورودی، ممکن است باعث اشتباه تحلیل شود. پس از اجرای این کد، نمودار زیر حاصل میشود.
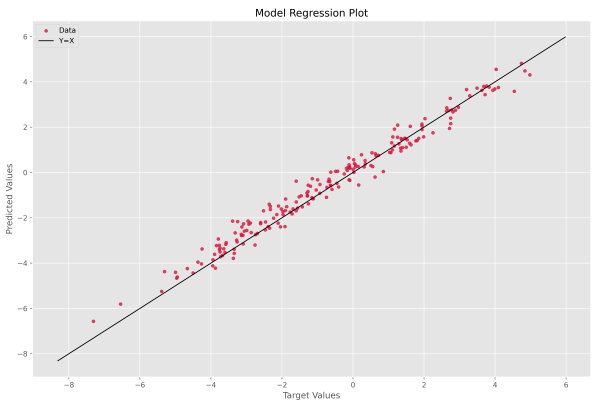
به این ترتیب برای هر داده یک نقطه داریم که هرچه به خط مشکی رنگ نزدیکتر باشد، مطلوبتر است. این نمودار همواره حول یک خط رسم میشود و این خط دارای ضابطه تابع همانی (Identity) است. خط مشکی رنگ از ابتدا و انتها به اندازه 1 واحد از نقاط فاصله دارد. این مقدار در دو سطر زیر تعیین شده است.
رعایت اندکی حاشیه برای این خط، جهت حفظ زیبایی نمودار مهم است. در برخی موارد، به جز خط y=x دو خط جانبی با ضابطه و نیز رسم میشود. این دو خط نشاندهنده خطای 20% هستند و نقاطی که بین این دو خط قرار بگیرند، دارای خطای کمتر از 20% هستند. برای این حالت میتوانیم کد را به شکل زیر تغییر دهیم.
در این شرایط، نمودار به شکل زیر خواهد بود.
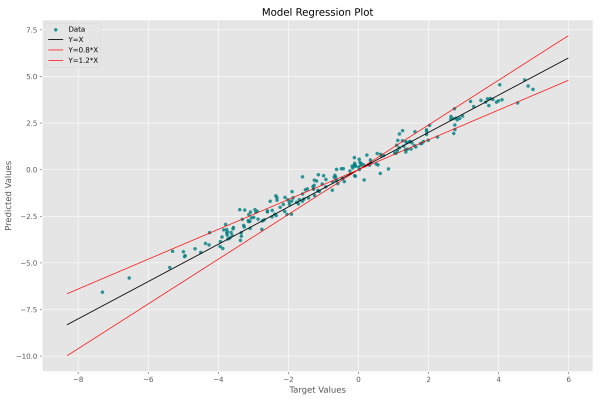
به این ترتیب میتوانیم دادههایی با خطاهای بیشتر از 20% را مشاهده کنیم. به این ترتیب رسم نمودار 1 به اتمام میرسد. برای رسم نمودار 2 به تعداد 200 نقطه با فاصله یکسان در بازه آن انتخاب میکنیم. به این منظور تابع numpy.linspace مناسب است. برای این ورودیها پیشبینی مدل را نیز محاسبه میکنیم:
حال خط مربوط به این دادهها را با نمودار نقطهای Y در مقابل X ادغام میکنیم:
پس از اجرای کد، نمودار زیر به همراه رابطه پیشبینی شده برای دادههای آن به نمایش درمیآید.
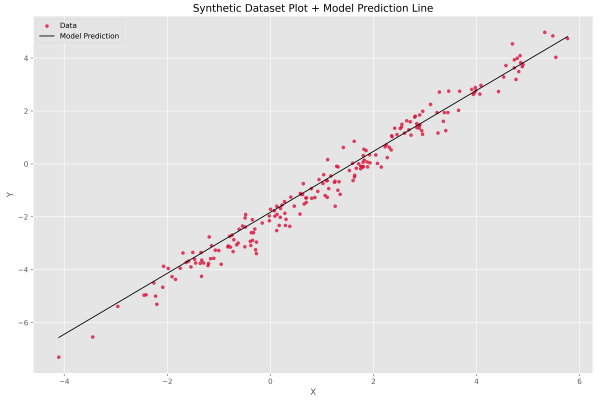
به این ترتیب مشاهده میکنیم که الگوریتم گرادیان کاهشی به خوبی توانسته خط فرضی مورد نظر ما را بیابد. شکل این نمودار بستگی به ارتباط بین متغیر مستقل و متغیر وابسته دارد. در این مورد با توجه به اینکه یک مجموعه داده با ضابطه خطی ایجاد کردیم، نمودار حاصل نیز خطی است. این مورد نباید باعث اشتباه بین نمودار 1 و 2 شود.
در نهایت برای تعیین عددی دقت مدل، از ضریب تعیین (Coefficient of Determination) یا همان استفاده میکنیم. این معیار به شکل زیر محاسبه میشود:
با پیادهسازی رابطه فوق خواهیم داشت:
پس از اجرا خواهیم داشت:
به این ترتیب مشاهده میکنیم که مدل به دقت بسیار خوبی دست یافته است. توجه داشته باشید که دقت مدل باید با توجه مجموعه داده آزمایش (Test Dataset) گزارش شود که در این پروژه جهت سادگی، مجموعه داده آزمایش نداریم.
مجموعه داده غیر خطی برای آموزش مدل رگرسیون با گرادیان کاهشی
به عنوان نمونه یک مجموعه داده غیرخطی نیز ایجاد میکنیم و برای آن نیز این فرآیند را تکرار میکنیم تا از عملکرد الگوریتم پیادهسازی شده اطمینان حاصل کنیم. به این جهت ضابطه زیر را برای تولید مجموعه داده استفاده میکنیم:
برای ایجاد این مجموعه داده به شکل زیر عمل میکنیم:
کدهای مربوط به مجوعه دده قبلی را برای این مجموعه داده نیز تکرار میکنیم و نمودارها به شکل زیر حاصل میشود.
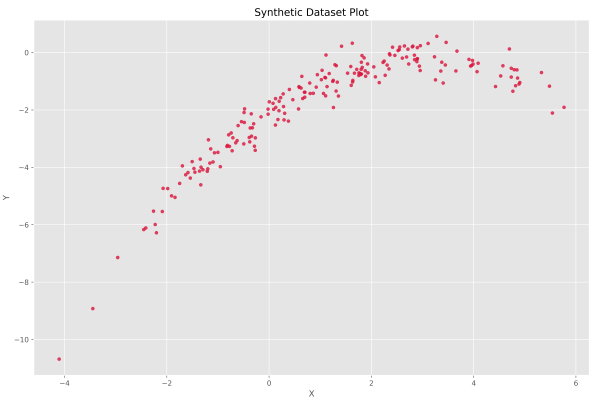
به این ترتیب مشاهده میکنیم که رابطه موجود دیگر خطی نیست و باید از یک مدل درجه دوم استفاده کنیم. به همین جهت تابع جدیدی با نام QuadraticModel ایجاد میکنیم تا نقش یک مدل درجه دوم را ایفا کند:
این مدل با 3 پارامتر کار میکند اما ورودی و خروجیهای آن مشابه تابع LinearModel است. تعداد پارامترهای مدل نیز بایستی به شکل زیر تغییر یابد:
پس از این تغییر، در سایر خطوط کد اسم تابع LinearModel را با QuadraticModel پر میکنیم. پس از اجرای کد، خطاهای زیر نمایش داده میشود:
به این ترتیب یک کاهش شدید در اولین مرحله آموزش مدل مشهود است. نمودار خطا نیز به شکل زیر درمیآید.
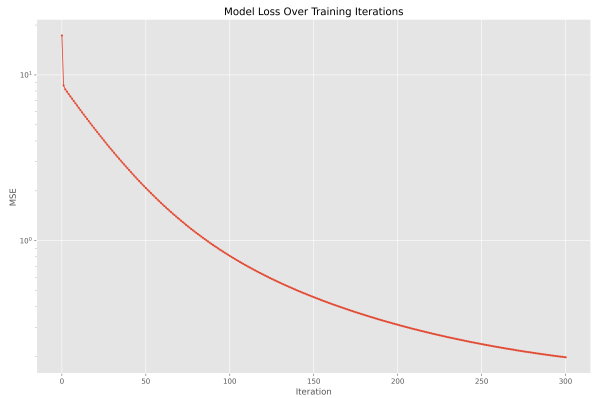
به سادگی قبل تشخیص است که اولین گام از بهروزرسانی وزنها تغییرات بسیار شدیدی ایجاد کرده. با نگاه به مراحل انتهای میتوان گفت که مدل همچنان درحال بهبود خود است و شاید بتواند بیشتر از این مقدار نیز دقیق شود. نمودار رگرسیون مدل سهمی بر روی این مجموعه داده به شکل زیر حاصل میشود.
مشاهده میکنیم که دادههای دورتر از 0 دارای خطای نسبی کمی هستند که منطقی است. دادههایی که بیرون خطوط قرمز رنگ قرار میگیرند و فاصله بیشتری دارند، خطای نسبی بیشتری نیز دارند. میتوانیم به عنوان آخرین نمودار نیز نمودار شماره 2 را بررسی کنیم.
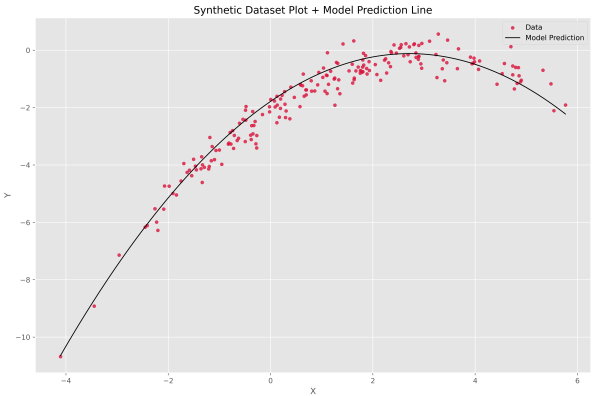
در این مورد نیز مشاهده میکنیم که الگوریتم توانسته به خوبی نمودار سهمی مد نظرمان را بیابد. در انتها دقت مدل برابر با 93.77% گزارش شده است که مناسب است. تا به اینجا پیادهسازی مدل و بررسی نتایج به اتمام رسیده است.
گرادیان در طول آموزش برای آموزش مدل رگرسیون با گرادیان کاهشی
به عنوان بررسی آخر، میخواهیم روند اندازه بردار گرادیان را بررسی کنیم. به زمان ساده گرادیان نشانگر شیب زمین است و پارامترها نشاندهنده مکان یک توپ. تا زمانی که مقدار شیب صفر نشود، توپ نیز باید جابهجا شود، همانطور که پارامترها باید بهروزرسانی شوند، تا زمانی که مقدار گرادیان صفر شود. همانطور که توپ پس از ازادسازی از بالای یک تپه، در یک دره یا چاله متوقف میشود، انتظار داریم پارامترها نیز پس از تعداد تکرارهای مشخصی همگرا شده و تغییر نیابند. این روند همگرایی به کمک اندازه بردار گرادیان قابل محاسبه هست. بنابراین یک نسخه کپی از کد مربوط به مدل سهمی ایجاد کرده و هسته بهینهسازی را اندکی تغییر میدهیم تا به شکل زیر برسیم:
حال یک نمودار برای آرایه Ns قابل رسم است.
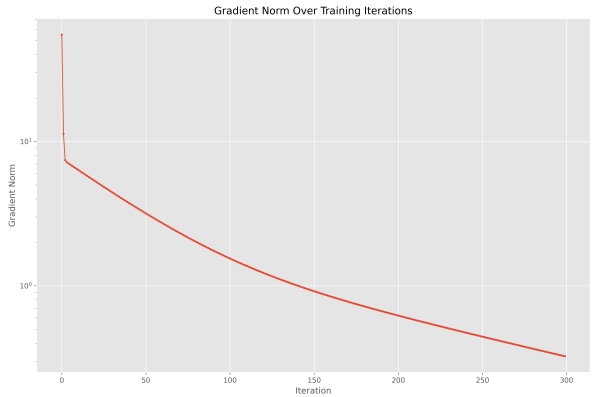
به این ترتیب مشاهده میکنیم که این نمودار رو به نزول است، بنابراین با احتمال زیادی پارامترها درحال نزدیک شدن به یک بهینه محلی (Local Minimum) یا عمومی (Global Minimum) هستند. با افزایش تعداد مراحل آموزش به 1000 مرحله، خواهیم داشت.
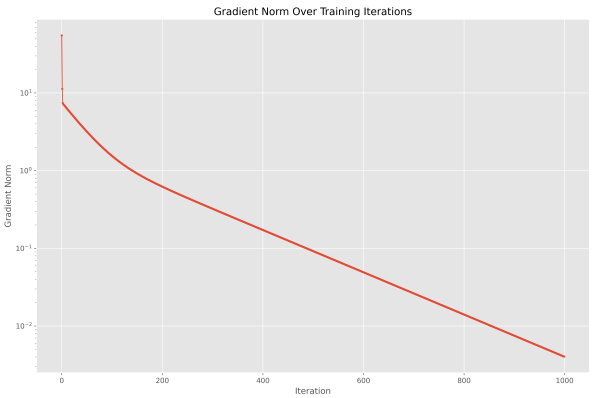
با توجه به اینکه مقیاس محور عمودی لگاریتمی است، با خطی شدن بزرگی بردار گرادیان، میتوان به این نتیجه رسید که روند آن در مقیاس واقعی لگاریتمی است. کد مربوط الگوریتم گرادیان کاهشی نیز میتواند به شکل یک تابع درآورده شود تا استفاده از آن تسهیل شود.

جمعبندی
به این ترتیب پیادهسازی الگوریتم گرادیان کاهشی برای آموزش مدلهای یادگیری ماشین به اتمام میرسد. برای مطالعه بیشتر، میتواند موارد زیر را بررسی کرد:
- کد مربوط به الگوریتم گرادیان کاهشی را به شکل تابع در آورید و در ورودی تابع مدل، تعداد پارامتر و مجموعه داده را دریافت کنید. تابع را به گونهای طراحی کنید که در خروجی آرایه پارامترها، خطا در طول آموزش، اندازه گرادیان در طول آموزش و پیشبینی نهایی مدل را برگرداند.
- تابع هزینه تعریف شده براساس میانگین مربعات خطا است. تابع هزینه دیگری براساس میانگین قدرمطلق خطا تعریف کنید.
- اگر دو متغیر مستقل در مجموعه داده وجود داشته باشد، چه تغییراتی باید در کد ایجاد شود؟
- برای بررسی قابلیت تعمیمپذیری (Generalizability) مدل، دو مجوعه داده آموزش و آزمایش ایجاد کنید و دقت مدل بر روی مجموعه داده آزمایش را گزارش کنید.
- یکی از روشها برای جلوگیری از بیشبرازش مدلها، استفاده از Regularization است. برای پیادهسازی این تکنیک، باید کدام بخش از کد اصلاح شود؟
- در تخمین گرادیان، چرا به جای روش تفاضل مرکزی، از روش تفاضل رو به جلو استفاده شد؟
- معیارهای ارزیابی همچون NRMSE, MAPE را پیادهسازی کرده و مقدار آنها را برای پیشبینی مدل گزارش کنید.










