



انواع روش های ماشین لرنینگ چیست؟ – توضیح کامل به زبان ساده
«یادگیری ماشین» (Machine Learning) یکی از شاخههای «هوش مصنوعی» (Artificial Intelligence | AI) محسوب میشود که شامل طیف گستردهای از الگوریتمهایی است که با کمک آنها میتوان به طراحی برنامهها، سیستمها و ابزارهای هوشمندی پرداخت که میتوانند همانند انسان یک سری امور را انجام دهند و عملکرد خود را به طور مداوم بهبود بخشند. رویکردهای مختلفی برای یادگیری الگوریتم های یادگیری ماشین و الگوریتم های یادگیری عمیق وجود دارند که هر کدام از آنها دارای نقاط قوت و ضعف و کاربردهای متمایزی هستند. در این مطلب از مجله فرادرس، قصد داریم به انواع روش های ماشین لرنینگ بپردازیم و ویژگیها و کاربردهای هر یک از آنها را به زبان ساده توضیح دهیم.
- میآموزید ماشین لرنینگ چگونه از برنامهنویسی سنتی متمایز است.
- یاد میگیرید مدلهای ML با دادههای آموزشی چگونه شکل میگیرند.
- میآموزید از چه مسیر و منابعی یادگیری ML را شروع کنید.
- با رویکردهای اصلی یادگیری ماشین و کاربردهای آنها آشنا میشوید.
- یاد خواهید گرفت یادگیری نظارتشده بر چه اساسی عمل میکند.
- کاربرد دستهبندی، رگرسیون و الگوریتمهای کلیدی را خواهید شناخت.




در ابتدای مطلب حاضر، به توضیح مختصری از مفهوم یادگیری ماشین میپردازیم و به تفاوت آن با برنامه نویسی سنتی اشاره خواهیم کرد. سپس، ۱۴ روش یادگیری ماشین را معرفی میکنیم و کاربردها و ویژگیهای آنها را به همراه مثال ملموس از دنیای واقعی شرح خواهیم داد.
تفاوت برنامه نویسی یادگیری ماشین با برنامه نویسی سنتی
یادگیری ماشین یا ماشین لرنینگ یکی از زیر شاخه های هوش مصنوعی است که بر توسعه الگوریتمهایی تمرکز دارد که بتوانند به طور خودکار از طریق تجربه و با استفاده از دادهها وظیفهای خاص را یاد بگیرند و عملکرد خود را در انجام آن وظیفه بهبود بخشند. به عبارت ساده، یادگیری ماشین به رایانهها امکان میدهد تا از دادههای آموزشی یاد بگیرند و تصمیمات یا پیشبینیهایی را به طور خودکار انجام دهند بدون آن که صریحاً برای انجام آنها برنامهریزی شده باشند. هر چقدر دادههای آموزشی مدلهای یادگیری ماشین بیشتر باشند، یادگیری مدل بهتر میشود و مدل با دقت بیشتری میتواند وظیفه مشخص شده را انجام دهد.
در برنامه نویسی سنتی، یک کامپیوتر با پیروی از مجموعهای از دستورالعملهای از پیش تعریف شده توسط برنامه نویس، وظیفهای خاص را انجام میداد. به عنوان مثال، اگر بخواهیم کامپیوتر مجموعهای از تصاویر مربوط به گربه و سگ را از هم تفکیک کند، برنامه نویس باید یک سری ویژگیها را در قالب دستورات شرطی برای کامپیوتر مشخص کند.

در یادگیری ماشین، مجموعهای از دادهها به الگوریتمهای ریاضیاتی داده میشود و کامپیوتر بر اساس دادهها و نوع الگوریتمی که در اختیار دارد، یاد میگیرد چطور مسئلهای را حل کند. به عنوان مثال، برای فیلتر کردن تصاویر گربه و سگ، باید هزاران عکس مرتبط با آن دو حیوان را تهیه کنیم و آنها را در اختیار الگوریتمهای یادگیری ماشین قرار دهیم تا بر اساس الگوها و ویژگیهای مشترک، تصاویر مرتبط به هر حیوان را از هم تفکیک کنند. با جمعآوری تصاویر بیشتر از این دو حیوان، میتوان عملکرد الگوریتم را بهبود بخشید تا در زمان تست، مدل بتواند به خوبی درباره تصاویر جدید تصمیم بگیرد.
افزایش میزان توانایی الگوریتمهای ماشین لرنینگ در یادگیری از دادهها و بهبود عملکردشان در انجام کار در طول زمان باعث میشود برای انجام امور مختلف بسیار قدرتمند عمل کنند و بتوان از آنها در زمینههای مختلفی نظیر طراحی دستیارهای صوتی، سیستمهای توصیهگر، ساخت مترجم هوشمند، طراحی خودروهای خودران، طراحی دستیار پزشک هوشمند و هزاران مورد دیگر استفاده کرد.
چگونه ماشین لرنینگ را با فرادرس یاد بگیریم؟

برای شروع، ابتدا باید مفهوم یادگیری ماشین و کاربردهای آن را درک کنید. یادگیری ماشین یک شاخه از هوش مصنوعی است که به ماشینها امکان میدهد بدون نیاز به برنامهریزی صریح، از دادهها یاد بگیرند و الگوهایی را شناسایی کنند. پس از درک مفهوم، میتوانید با مطالعه اصول و مفاهیم اساسی یادگیری ماشین آشنا شوید. این اصول شامل مفاهیمی مانند مدلهای پیشبینی، الگوریتمهای طبقهبندی و رگرسیون، و معیارهای ارزیابی عملکرد مدلها است. بعد از آشنایی با مفاهیم اولیه، میتوانید به مطالعه الگوریتمهای مختلف یادگیری ماشین مانند درخت تصمیم، ماشین بردار پشتیبان (SVM)، شبکههای عصبی، و روشهای یادگیری تقویتی پرداخته و نحوه کارکرد هرکدام را درک کنید. سپس، میتوانید با مطالعه مطالب پیشرفتهتری مانند انتخاب ویژگی و تکنیکهای بهینهسازی مدلها، مهارتهای لازم برای ایجاد مدلهای یادگیری ماشین با کارایی بالا را به دست آورید.
و در نهایت، با مشاهده فیلمهای آموزشی فرادرس که مرتبط با روشهای یادگیری ماشین هستند و انجام تمرینهای عملی، میتوانید تواناییهای خود را در استفاده از این روشها در پروژههای واقعی تقویت کنید و بهترین روشهای یادگیری ماشین را برای مسائل خاص شناسایی کنید. در زیر، فیلمهای آموزشی فرادرس در رابطه با یادگیری ماشین آورده شده است.
- فیلم آموزش یادگیری ماشین فرادرس
- فیلم آموزش رایگان درخت تصمیم در یادگیری ماشین فرادرس
- مجموعه فیلمهای آموزش هوش مصنوعی با پایتون مقدماتی تا پیشرفته فرادرس
- فیلم آموزش شبکه های عصبی مصنوعی در متلب فرادرس
- فیلم آموزش رایگان یادگیری تقویتی فرادرس
- فیلم آموزش رایگان مفاهیم پایه در یادگیری تقویتی ماشین فرادرس
یادگیری ماشین و انواع روش های آن
روش های یادگیری ماشین متنوع هستند و بر اساس عوامل مختلفی نظیر نوع داده آموزشی، نحوه یادگیری الگوریتم، معماری مدلها و شیوه یادگیری از دادهها میتوان رویکردهای مختلفی را برای نحوه یادگیری الگوریتمهای ماشین لرنینگ در نظر گرفت که در ادامه به آنها اشاره شده است:

- الگوریتمهای یادگیری ماشین با رویکرد «یادگیری نظارت شده» (Supervised Learning)
- الگوریتمهای یادگیری ماشین با رویکرد «یادگیری نظارت نشده» (Unsupervised Learning)
- الگوریتمهای یادگیری ماشین با رویکرد «یادگیری نیمه نظارت شده» (Semi Supervised Learning)
- الگوریتمهای یادگیری ماشین با رویکرد «یادگیری خودآموز» (Self Supervised Learning)
- الگوریتمهای یادگیری ماشین با رویکرد «یادگیری چند نمونهای» (Multi Instance Learning)
- الگوریتمهای یادگیری ماشین با رویکرد «یادگیری استقرایی» (Inductive Learning)
- الگوریتمهای یادگیری ماشین با رویکرد «یادگیری استنتاجی» (Deductive Learning)
- الگوریتمهای یادگیری ماشین با رویکرد «یادگیری ترارسانی» (Transductive Learning)
- الگوریتمهای یادگیری ماشین با رویکرد «یادگیری تقویتی» (Reinforcement Learning)
- الگوریتمهای یادگیری ماشین با رویکرد «یادگیری چند وظیفهای» (Multi Task Learning)
- الگوریتمهای یادگیری ماشین با رویکرد «یادگیری فعال» (Active Learning)
- الگوریتمهای یادگیری ماشین با رویکرد «یادگیری آنلاین» (Online Learning)
- الگوریتمهای یادگیری ماشین با رویکرد «یادگیری انتقال» (Transfer Learning)
- الگوریتمهای یادگیری ماشین با رویکرد «یادگیری جمعی» (Ensemble Learning)
در بخشهای بعدی مطلب حاضر، به توضیح هر یک از انواع روش های ماشین لرنینگ میپردازیم و کاربردها و ویژگیهای هر یک از آنها را شرح خواهیم داد.
۱. یادگیری نظارت شده
همانطور که از نام این نوع یادگیری پیداست، روش یادگیری نظارت شده بر پایه نظارت بر مدل انجام میشود. این بدان معنا است که در این روش، برنامه نویس باید مجموعهای از دادههای آموزشی برچسبدار را برای مدل فراهم کند. برچسبهای داده، خروجی مورد انتظار از مدل را مشخص میکنند. مدلهای یادگیری نظارت شده با استفاده از دادههای ورودی و برچسب هر یک از آنها آموزش داده میشوند و سپس مدل آموزش دیده را برای دادههای جدید استفاده میکنیم. اگر میخواهید یادگیری ماشین را با پایتون یاد بگیرید، پیشنهاد میکنیم از فیلم آموزش یادگیری ماشین با پایتون فرادرس استفاده کنید که لینک آن در زیر آورده شده است.
به منظور درک بهتر روش یادگیری نظارت شده میتوانیم از یک مثال ساده کمک بگیریم. فرض کنید یک مجموعه داده ورودی از تصاویر اشکال مختلف داریم. قصد داریم مدلی را با رویکرد یادگیری نظارت شده با استفاده از این مجموعه داده آموزش دهیم تا در نهایت بتواند با دریافت تصویر جدید، شکل موجود در تصویر را تشخیص دهد.

بدین منظور، برچسبهای دادههای آموزشی مدل باید تعیین شوند که برای این مثال، هر یک از برچسبها نام اشکال موجود در تصاویر را مشخص میکنند. به عبارتی، در مثال تعریف شده، سه برچسب مربع، مثلث و شش ضلعی وجود دارد. با استفاده از اطلاعات استخراج شده از تصاویر مانند شکل و تعداد اضلاع و به همراه برچسب تصاویر میتوان مدل یادگیری ماشین را آموزش داد.
پس از اتمام آموزش، تصویر یک شکل جدید را به مدل میدهیم و از آن میخواهیم که شکل موجود در تصویر را تشخیص دهد. مدل بر اساس ویژگیهایی که در مرحله آموزش یاد گرفته است، ویژگیهای تصویر جدید را بررسی میکند و سپس خروجی را ارائه میدهد.
یادگیری نظارت شده را که جزو انواع روش های ماشین لرنینگ محسوب میشود، میتوان در حل دو نوع مسئله هوش مصنوعی به کار برد که در ادامه به آنها اشاره شده است:
- «دستهبندی | طبقه بندی» (Classification): در این نوع مسائل، مدل یادگیری ماشین بر اساس ویژگیهای دادههای آموزشی یاد میگیرد که دادههای جدید را در چه دستهای قرار دهد. به عنوان مثال، مسئله تشخیص هرزنامه را میتوان جزو مسائل دستهبندی محسوب کرد. در این مسئله مجموعهای از دادههای آموزشی را در اختیار داریم که با برچسب، هرزنامهها از غیر هرزنامهها تفکیک شدهاند. سپس، مدل با یادگیری دادههای آموزشی، درباره محتوای ایمیل جدید تصمیم میگیرد و آن را جزو یکی از دو دسته تعریف شده قرار میدهد. در مسائل دستهبندی، تعداد برچسبها محدود هستند.
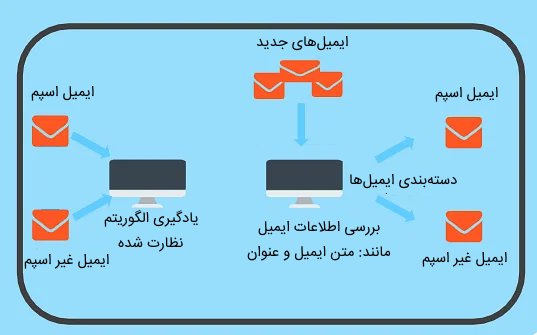
مثالی از طبقهبندی در یادگیری ماشین - رگرسیون: در مسئله رگرسیون نیز دادههای آموزشی دارای برچسب هستند اما تعداد برچسبهای تعریف شده محدود نیستند. مسئلهای نظیر پیشبینی قیمت مسکن را در نظر بگیرید. بر اساس ویژگیهایی نظیر موقعیت جغرافیایی خانه، تعداد اتاق، متراژ خانه و مواردی از این قبیل، قیمت مشخصی برای خانه تعیین شود. در این مسئله، ویژگیهای خانه، به عنوان دادههای ورودی مدل در نظر گرفته میشوند و قیمت خانه به عنوان برچسب داده تعیین میشود و مدل باید یاد بگیرد چه روابطی بین ویژگیهای خانه و قیمت آن وجود دارد تا با استفاده از این اطلاعات، درباره قیمت خانههای دیگر نیز به درستی قیمت را پیشبینی کند. تعیین میزان رطوبت نیز از دیگر مثالهای رگرسیون است. در این مسئله، با توجه به ویژگیهای مختلفی نظیر میزان دما، خشکی هوا، آفتابی بودن و موارد دیگر، مدل سعی دارد میزان رطوبت هوا را پیشبینی کند.
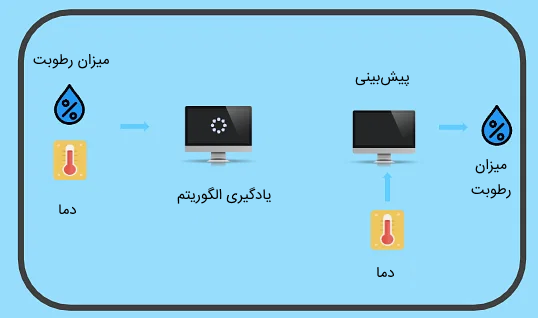
مثالی از رگرسیون در یادگیری ماشین


الگوریتم های یادگیری نظارت شده
همانطور که اشاره کردیم، یادگیری نظارت شده یکی از انواع روش های ماشین لرنینگ است که در این روش به مجموعهای از دادههای آموزشی برچسبدار نیاز داریم. الگوریتمهای مختلفی وجود دارند که با رویکرد یادگیری نظارت شده به یادگیری و حل مسئله میپردازند که در ادامه به پرکاربردترین و مهمترین آنها اشاره شده است:

- الگوریتم «رگرسیون خطی» (Linear Regression)
- الگوریتم «رگرسیون لجستیک» (Logistic Regression)
- الگوریتم «ماشین بردار پشتیبان» (Support Vector Machine | SVM)
- الگوریتم «K نزدیکترین همسایگی» (K Nearest Neighbor)
- الگوریتم «درخت تصمیم» (Decision Tree)
- الگوریتم «جنگل تصادفی» (Random Forest)
- الگوریتم «دسته بند بیز ساده» (Naive Bayes)
کاربردهای یادگیری نظارت شده
در ادامه، به برخی از مسائل رایج هوش مصنوعی اشاره میکنیم که میتوانیم آنها را با استفاده از انواع روش های ماشین لرنینگ با رویکرد یادگیری نظارت شده حل کنیم:
- تقسيمبندی تصویر: از الگوریتمهای ماشین لرنینگ با رویکرد نظارت شده میتوان در تقسیمبندی تصویر استفاده کرد. در این فرایند، طبقهبندی تصویر بر اساس برچسبهای از پیش تعریف شده انجام میشود.
- تشخيص پزشكی: از انواع روش های ماشین لرنینگ با رویکرد یادگیری نظارت شده میتوان در زمینه پزشکی برای تشخیص انواع بیماریهای مختلف استفاده کرد. مدلهای یادگیری ماشین با مجموعه زیادی از تصاویر پزشکی آموزش داده میشوند تا از مدل نهایی بتوان برای تشخیص نوع بیماری و راه درمان افراد بیمار جدید استفاده کرد.
- تشخیص کلاهبرداری: الگوریتمهای طبقهبندی با رویکرد یادگیری نظارت شده را میتوان برای تشخیص کلاهبرداری و افراد مشکوک به کار برد. روش های یادگیری ماشین با این رویکرد میتوانند بر اساس دادههای تاریخی الگوهایی را شناسایی کنند که میتوانند منجر به فعالیتهای مشکوک و کلاهبرداریهای مالی شوند.
- شناسایی هرزنامه: در شناسایی و فیلتر کردن هرزنامه نیز از الگوریتمهای طبقهبندی استفاده میشوند. این الگوریتمها بر اساس محتوای ایمیل، آدرس فرستنده، کلمات کلیدی موجود در ایمیل و مواردی از این قبیل، ایمیلهای مشکوک را به پوشه هرزنامه ارسال میکنند.
- تشخيص گفتار: هدف از تشخیص گفتار طراحی سیستمهای هوشمندی است که بتوانند صدای فرد گوینده را تشخیص دهند و بر اساس خواسته کاربر، کاری را انجام دهند. از الگوریتمهای ماشین لرنینگ با رویکرد نظارت شده میتوان در طراحی سیستمهای تشخیص گفتار استفاده کرد. این الگوریتم با دادههای صوتی آموزش داده میشوند تا بتوانند صدای گوینده را برای انجام امور مختلف مانند فعال کردن گذرواژهها، اجرای برنامهای خاص بر روی گوشی یا لپتاپ، اجرا کردن موسیقی خاص و مواردی از این قبیل تشخیص دهند. در مطالب قبلی مجله فرادرس نیز به طور کامل راجع به «تشخیص گفتار» صحبت کردهایم و پیادهسازی آن در متلب را نیز توضیح دادیم. اگر میخواهید این موضوع را بهتر و بیشتر یاد بگیرید، پیشنهاد میکنیم مطلب تشخیص گفتار در متلب را مطالعه کنید.
مزایای انواع روش های ماشین لرنینگ با رویکرد یادگیری نظارت شده
انواع روش های ماشین لرنینگ با رویکرد نظارت شده دارای مزیتهای مشترکی هستند که در ادامه به برخی از مهمترین آنها اشاره میکنیم:
- دقت بالا: مدلهای ماشین لرنینگ با رویکرد یادگیری نظارت شده میتوانند عملکرد بسیار دقیق داشته باشند، بهویژه زمانی که دادههای آموزشی آنها از کیفیت بالایی برخوردار باشند. این امر به این دلیل است که مدل بهطور صریح بر روی خروجی مورد نظر آموزش داده شده است و میتواند الگوهایی دقیقی از دادهها را شناسایی کند که برای طبقهبندی دادهها مناسب هستند.
- تفسیرپذیر بودن: روش های یادگیری ماشین با رویکرد نظارت شده تفسیرپذیر هستند که این ویژگی برای درک نحوه عملکرد مدل برای انجام وظایف مانند تشخیص تقلب یا تشخیص پزشکی مهم است.
- کاربرد گسترده: از انواع روش های ماشین لرنینگ با رویکرد یادگیری نظارت شده را میتوان برای طیف گستردهای از مسائل از جمله طبقهبندی، رگرسیون و «تشخیص داده پرت» (Outlier Detection) استفاده کرد.
معایب انواع روش های ماشین لرنینگ با رویکرد یادگیری نظارت شده
با این که روش های یادگیری ماشین با رویکرد نظارت شده دارای مزیتهای مهمی هستند و در بسیاری از مسائل میتوان از آنها استفاده کرد، دارای معایبی نیز هستند که در ادامه به آنها اشاره میکنیم:
- زمانبر بودن آمادهسازی دادههای آموزشی: روش های یادگیری ماشین با رویکرد یادگیری نظارت شده به دادههای آموزشی برچسبدار احتیاج دارند تا با استفاده از آنها یاد بگیرند مسائل را حل کنند. جمعآوری و آمادهسازی این دادهها زمانبر است زیرا نیاز است که از افراد متخصصی نظیر زبانشناسان برای برچسبزنی دادهها کمک بگیریم.
- وابستگی به داده: عملکرد مدلهای ماشین لرنینگ با رویکرد یادگیری نظارت شده به شدت به کیفیت دادههای آموزشی وابسته است. اگر دادههای آموزشی نمونهای از دادههای دنیای واقعی نباشند، عملکرد مدل کاهش مییابد. این امر میتواند در مسائلی چالشبرانگیز باشد که دادهها آموزشی کمی در اختیار داریم یا جمعآوری دادههای زیاد برای یادگیری مدل دشوار است.
- پیچیدگی محاسباتی: انواع روش های ماشین لرنینگ با رویکرد یادگیری نظارت شده به لحاظ بار محاسباتی سنگین هستند. این ویژگی در آموزش مسائلی با دادههای حجیم با ابعاد بسیار بالا مشکلساز خواهد بود.
- رخداد «بیش برازش» (Overfitting): در زمان یادگیری الگوریتمهای ماشین لرنینگ با رویکرد یادگیری نظارت شده احتمال رخداد بیش برازش وجود دارد. این وضعیت زمانی اتفاق میافتد که مدل یادگیری ماشین، دادههای آموزشی را بیش از حد، خوب یاد بگیرد و نتواند عملکرد خود را به دادههای جدید تعمیم دهد که در نتیجه منجر به عملکرد ضعیف مدل در دادههای جدید میشود.
۲. یادگیری نظارت نشده
بر خلاف انواع روش های ماشین لرنینگ با رویکرد نظارت شده، الگوریتمهای یادگیری نظارت نشده نیاز به دادههای برچسبدار ندارند. به عبارتی، این مدلها به کمک انسان برای یادگیری مسئله احتیاج ندارند و صرفاً با تجزیه و تحلیل دادههای موجود، همبستگیها و روابط بین آنها را تعیین میکنند.
به بیان دیگر، مدلهای یادگیری نظارت نشده به دنبال تشخیص الگوهای پنهان موجود در دادهها هستند و با تشخیص آنها سعی دارند دادهها را به نحوی سازماندهی کنند که دادههای مشابه در گروهها، یا به اصطلاح «خوشههای» (Clusters)، یکسان قرار بگیرند. هر چه تعداد دادههای بیشتری توسط مدلهای یادگیری نظارت نشده مورد ارزیابی قرار گیرند، توانایی و عملکرد آنها در تصمیمگیری بر اساس آن دادهها به تدریج بهبود مییابد.

برای درک بهتر رویکرد نظارت نشده، مثالی را در نظر بگیرید؛ فرض کنید یک مجموعهای از تصاویر میوه در اختیار داریم و آن را به مدل ماشین لرنینگ با رویکرد یادگیری نظارت نشده وارد میکنیم. این تصاویر برای مدل کاملاً ناشناخته هستند و وظیفه ماشین یافتن الگوها و خوشهبندی تصاویر مشابه است. مدل هوش مصنوعی الگوها و تفاوتهای تصاویر نظیر تفاوت رنگ، تفاوت شکل و مواردی از این قبیل را کشف خواهد کرد و بر اساس این اطلاعات، تصاویر متفاوت را در خوشههای مجزا قرار میدهد. سه نوع مسئله را میتوان با روشهای یادگیری نظارت نشده حل کرد که در ادامه به آنها اشاره شده است:
- «خوشهبندی» (Clustering): خوشه بندی شامل گروهبندی مجموعههای داده مشابه (بر اساس معیارهای تعریف شده) است. این روش برای بخشبندی دادهها به چندین گروه مفید است و مدلهای یادگیری نظارت نشده در هر مجموعه داده تجزیه و تحلیل انجام میدهند تا الگوهای پنهان دادهها را پیدا کنند.
- «کاهش ابعاد» (Dimension Reduction): ابعاد دادههای ورودی الگوریتم های هوش مصنوعی را میتوان با یک سری از روشهای یادگیری نظارت نشده کاهش داد که این امر میتواند در بهبود یادگیری مدل و کمتر شدن زمان آموزش تاثیرگذار باشد.
- یافتن «وابستگی» (Association) بین دادهها: یادگیری قانون وابستگی یکی دیگر از انواع یادگیری ماشین با رویکرد نظارت نشده است که بر روی یافتن روابط بین متغیرها در یک مجموعه داده بزرگ تمرکز دارد. این نوع الگوریتمها عمدتاً در تحلیل سبد خرید مشتریان و بررسی نحوه استفاده از وب کاربرد دارند.
الگوریتم های یادگیری نظارت نشده
الگوریتمهای مختلفی وجود دارند که با رویکرد یادگیری نظارت نشده به یادگیری و حل مسئله میپردازند که در ادامه به پرکاربردترین و مهمترین آنها اشاره شده است:
- الگوریتم «خوشهبندی K میانگین» (K-means Clustering)
- الگوریتم «تغییر میانگین» (Mean Shift)
- الگوریتم DBSCAN
- الگوریتم «تحلیل مولفه اساسی» (Principal Component Analysis | PCA)
- الگوریتم «تحلیل مولفههای مستقل» (Independent Component Analysis | ICA)
- الگوریتم «اپریوری» (Apriori)
- الگوریتم «رشد الگوی مکرر» (Frequently Pattern Growth)
کاربردهای یادگیری نظارت نشده
از انواع یادگیری ماشین با رویکرد نظارت نشده میتوان در حل مسائل مختلفی استفاده کرد که در ادامه به برخی از آنها اشاره میکنیم:
- تحلیل شبکههای اجتماعی: از انواع روش های ماشین لرنینگ با رویکرد نظارت نشده میتوان برای شناسایی سرقت ادبی و کپیرایت در تحلیل شبکههای اجتماعی استفاده کرد.
- سیستمهای توصیهگر: به منظور طراحی سیستمهای توصیه کننده بهطور گسترده از روشهای یادگیری ماشین با رویکرد نظارت نشده استفاده میشود که از آنها میتوان در وبسایتهای مختلف و سایتهای تجارت الکترونیکی بهرهمند شد.
- «تشخیص ناهنجاری» (Anomaly Detection): تشخیص ناهنجاری از دیگر کاربردهای محبوب الگوریتمهای یادگیری نظارت نشده است که بر شناسایی دادههای غیرعادی در مجموعه داده تمرکز دارد. از این مسئله به منظور کشف معاملات جعلی و کلاهبرداریهای اینترنتی استفاده میشود.
- تقسیمبندی مشتریان: الگوریتمهای یادگیری نظارت نشده را میتوان برای گروهبندی مشتریان بر اساس رفتار خرید، جمعیتشناسی یا سایر عوامل استفاده کرد. این امر به مشاغل و افراد فعال در حوزه کسب و کار اجازه میدهد تا کمپینهای بازاریابی و پیشنهادات محصول را برای بخشهای مشتری خاص تنظیم کنند.
- تحلیل ژنومیک: الگوریتمهای یادگیری نظارت نشده میتوانند دادههای ژنتیکی را برای شناسایی الگوها و روابط دادهها تجزیه و تحلیل کنند. این امر میتواند منجر به درک بهتر نتایج پزشکی افراد و تحقیقات ژنتیکی شود.
مزایای انواع روش های ماشین لرنینگ با رویکرد یادگیری نظارت نشده
انواع روش های ماشین لرنینگ با رویکرد نظارت نشده دارای مزیتهای مشترکی هستند که در ادامه به برخی از مهمترین آنها اشاره میکنیم:
- نیاز به مراحل کمتر برای آمادهسازی داده: در رویکرد یادگیری نظارت شده، برای آموزش مدلهای هوش مصنوعی نیاز به دادههای برچسبدار داریم. برچسب زدن داده امری زمانبر است و باید از افراد متخصص این حوزه کمک بگیریم. بنابراین، تهیه دادههای مورد نیاز مدلهای یادگیری نظارت شده هزینه مالی را نیز در پی خواهد داشت. انواع یادگیری ماشین با رویکرد نظارت نشده به دادههای برچسبدار نیاز ندارند که این روش به عنوان رویکردی کارآمدتر برای تجزیه و تحلیل مقادیر زیادی داده محسوب میشود.
- تشخیص الگوها و روابط پنهان در دادهها: الگوریتمهای یادگیری نظارت نشده میتوانند الگوها و روابطی را در دادهها شناسایی کنند که برای انسانها به راحتی قابل مشاهده نیستند. این امر میتواند منجر به اکتشافات جدیدی از دادهها شود که میتوان از آنها برای بهبود تصمیمگیری و حل مسئله استفاده کرد.
- پردازش دادههای چند بعدی: الگوریتمهای یادگیری نظارت نشده اغلب برای پردازش دادههای چند بعدی موثرتر از الگوریتمهای یادگیری نظارت شده هستند. این امر به این دلیل است که آنها نیازی به پردازش دادهها پیش از پردازش یا کاهش ابعاد ندارند.
- تجزیه و تحلیل دادههای اکتشافی: از الگوریتمهای یادگیری نظارت نشده میتوان بدون در نظر گرفتن هیچ فرضی در مورد دادهها، برای کاوش و درک ساختار آنها استفاده کرد. این ویژگی میتواند برای شناسایی ناهنجاریها، دادههای خارج از محدوده تعیین شده مفید باشد.
- فشردهسازی دادهها و کاهش ابعاد آنها: الگوریتمهای یادگیری نظارت نشده را میتوان برای فشردهسازی دادهها و کاهش ابعاد آنها استفاده کرد که این امر میتواند برای کاهش میزان فضای لازم برای ذخیرهسازی داده و کارآمدتر کردن تجزیه و تحلیل داده مفید باشد.
معایب الگوریتم ماشین لرنینگ با رویکرد یادگیری نظارت نشده
علیرغم این که روش های یادگیری ماشین با رویکرد نظارت نشده دارای مزیتهای مهمی هستند و در بسیاری از مسائل میتوان از آنها استفاده کرد، دارای معایبی نیز هستند که در ادامه به آنها اشاره میکنیم:
- تفسیرپذیری دشوار: روش های یادگیری ماشین با رویکرد یادگیری نظارت نشده اغلب نتایجی تولید میکنند که به دشواری میتوان آنها را تفسیر کرد زیرا این نوع الگوریتمها بر اساس تجزیه و تحلیل روابط دادهها و تشخیص الگوهای آنها به خوشهبندی دادهها میپردازند که ممکن است انسان به طور دقیق تمامی این اطلاعات استخراج شده را درک نکند.
- حساس بودن به نویزها: الگوریتمهای ماشین لرنینگ با رویکرد یادگیری نظارت نشده میتوانند نسبت به نویز موجود در دادههای آموزشی حساستر از الگوریتمهای یادگیری نظارت شده باشند زیرا این الگوریتمها نمیتوانند از دادههای برچسبدار برای یادگیری نحوه فیلتر کردن نویز استفاده کنند.
- احتمال رخداد بیش برازش: الگوریتمهای یادگیری نظارت نشده در مقایسه با مدلهای یادگیری نظارت شده، بیشتر مستعد رخداد بیش برازش هستند زیرا این روشها نمیتوانند از دادههای برچسبدار برای یادگیری نحوه تعمیم اطلاعات استخراج شده از دادههای آموزشی به دادههای جدید استفاده کنند.
- دشوار بودن انتخاب مناسبترین الگوریتم: انواع مختلفی از الگوریتمهای یادگیری نظارت نشده وجود دارند و انتخاب مناسبترین الگوریتم از میان آنها برای مسئله تعریف شده دشوار است زیرا هر یک از الگوریتمها ممکن است ویژگیهای خاصی از داده را در نظر بگیرند و همین امر منجر به خروجیهای متفاوت میشود.
- دشوار بودن ارزیابی الگوریتمها: ارزیابی عملکرد الگوریتمهای یادگیری نظارت نشده دشوارتر از الگوریتمهای یادگیری نظارت شده است. این امر این دلیل است که هیچ مرجع مشخصی برای مقایسه نتایج حاصل شده از الگوریتمهای نظارت نشده وجود ندارد.
۳. یادگیری نیمه نظارت شده
یکی دیگر از انواع یادگیری ماشین، یادگیری نیمه نظارت شده است که از هر دو روش یادگیری نظارت شده (با دادههای آموزشی برچسبگذاری شده) و یادگیری نظارت نشده (بدون دادههای آموزشی برچسبگذاری شده) استفاده میکند. با این که در این روش آموزشی نیز، از دادههای برچسبدار استفاده میشود، بیشتر یادگیری مدلهای هوش مصنوعی وابسته به دادههای بدون برچسب هستند. به عبارتی، میتوان گفت به منظور غلبه بر معایب روشهای یادگیری نظارت شده و روشهای نظارت نشده، مفهوم یادگیری نیمه نظارت شده معرفی شده است. در این میان، اگر بخواهید یادگیری ماشین لرنینگ را با ساخت پروژه، تکمیلتر کنید، پیشنهاد میکنیم از فیلم آموزش اصول ساخت پروژه یادگیری ماشین فرادرس استفاده کنید که لینک آن در زیر آورده شده است.

در روش یادگیری ماشین با رویکرد یادگیری نیمه نظارت شده، هدف اصلی این است که به طور موثر از تمام دادههای موجود استفاده شود. در ابتدا، دادههای مشابه با استفاده از الگوریتمهای یادگیری نظارت نشده در خوشههای یکسان قرار میگیرند و سپس به هر یک از خوشههای مشخص شده برچسبی داده میشود.

میتوانیم سه مفهوم یادگیری نظارت شده، یادگیری نظارت نشده و یادگیری نیمه نظارت شده را با یک مثال ملموس توضیح دهیم. فرض کنید دانشآموزی تحت نظارت یک استاد در خانه یا دانشگاه به یادگیری مبحث درسی میپردازد. این روش یادگیری، از نوع نظارت شده است و استاد به عنوان ناظر به دانشآموز در آموزش مبحث درسی کمک میکند. چنانچه دانش آموز مبحث درسی را بدون هیچ کمکی از استاد خود یاد بگیرد، از روش یادگیری نظارت نشده استفاده میکند. در صورتی که دانشآموز مبحث درسی را خودش یاد بگیرد و سپس با کمک استاد به مرور مطالب بپردازد، از روش یادگیری نیمه نظارت شده استفاده میکند.
کاربردهای انواع روش یادگیری نیمه نظارت شده
یادگیری نیمه نظارت شده یکی از انواع روش های ماشین لرنینگ قدرتمند است که میتواند برای حل طیف گستردهای از مسائلی استفاده شوند که دادههای برچسبدار کمی برای آنها در اختیار داریم. در ادامه به چند نمونه از کاربردهای روش یادگیری نیمه نظارت شده اشاره شده است:
- «پردازش زبان طبیعی» (Natural Language Processing | NLP): یادگیری نیمه نظارت شده برای بهبود عملکرد وظایفی مانند تحلیل احساسات، ترجمه ماشینی و پاسخ به سؤال استفاده میشود. به عنوان مثال، میتوان از این رویکرد یادگیری برای بهبود دقت تحلیل احساسات برای توییتر استفاده کرد و یک مجموعه داده کوچک از توییتهای برچسبدار را برای تولید برچسبهای جدید برای مجموعه بزرگی از توییتهای بدون برچسب به کار برد.
- طبقهبندی تصویر: از روش یادگیری نیمه نظارت شده برای بهبود عملکرد وظایف طبقهبندی تصویر، مانند تشخیص شیء و تقسیمبندی تصویر استفاده میشود.
- سیستمهای توصیهگر: با استفاده از روش یادگیری نیمه نظارت شده میتوان عملکرد سیستمهای توصیهگر را بهبود داد.
- تشخیص ناهنجاری: با کمک روش یادگیری نیمه نظارت شده میتوان عملکرد تشخیص ناهنجاری را با استفاده از یک مجموعه کوچک از ناهنجاریهای برچسبدار برای تولید برچسبهای جدید مجموعه بزرگی از دادههای بدون برچسب بهبود بخشید. این روش میتواند به شناسایی ناهنجاریهایی کمک کند که خیلی نادر یا خیلی پیچیده هستند.
- کشف دارو: از روشهای یادگیری نیمه نظارت شده میتوان در شناسایی کاندیدهای دارویی بالقوه با استفاده از یک مجموعه کوچک از ترکیبات برچسبدار برای تولید برچسبهای جدید برای مجموعه بزرگی از ترکیبات بدون برچسب استفاده کرد. این امر میتواند به محققان کمک کند تا با سرعت بیشتر و با اطمینان بالاتر داروهای جدیدی را کشف کنند.
مزایای یادگیری نیمه نظارت شده
روش های یادگیری ماشین با رویکرد نیمه نظارت شده دارای مزیتهای مهمی هستند و در بسیاری از مسائل میتوان از آنها استفاده کرد. در ادامه، به برخی از مهمترین مزیتهای این روش میپردازیم:
- نیاز به دادههای برچسبگذاری شده کمتر: الگوریتمهای ماشین لرنینگ با رویکرد یادگیری نیمه نظارت شده میتوانند از دادههای برچسبدار کمتری برای یادگیری مسائل استفاده کنند و بیشتر بر روی دادههای بدون برچسب متکی باشند. همین امر هزینه زمانی و مالی مورد نیاز برای آمادهسازی دادههای آموزشی برچسبدار را به مراتب کاهش میدهد.
- شناسایی الگوهای پنهان در دادههای آموزشی: الگوریتمهای یادگیری نیمه نظارت شده از ویژگی روشهای یادگیری نظارت نشده برخوردار هستند و میتوانند الگوهای پنهان دادهها را تشخیص دهند.
- مقاوم بودن در مقابل دادههای نویزی: الگوریتمهایی با رویکرد یادگیری نیمه نظارت شده گاهی اوقات میتوانند در برابر نویز مقاوم باشند زیرا این مدلها قادر به یادگیری طیف گستردهتری از دادهها هستند که این ویژگی میتواند به فیلتر کردن نویز کمک کند.
معایب رویکرد یادگیری نیمه نظارت شده
با این که روش های یادگیری ماشین با رویکرد نیمه نظارت شده دارای مزیتهای مهمی هستند و در بسیاری از مسائل میتوان از آنها استفاده کرد، دارای معایبی نیز هستند که در ادامه به آنها اشاره میکنیم:
- پیچیدهتر بودن الگوریتمها: الگوریتمهای یادگیری نیمه نظارت شده اغلب پیچیدهتر از الگوریتمهای یادگیری نظارت شده هستند. این امر میتواند باعث شود که پیادهسازی و تنظیم آنها دشوارتر باشد.
- حساستر بودن به وزنهای اولیه مدل: انواع روش های ماشین لرنینگ با رویکرد یادگیری نیمه نظارت شده میتوانند نسبت به شرایط اولیه مدل حساستر باشند. این بدان معناست که انتخاب مجموعه خوبی از «فراپارامترها» (Hyperparameters) برای الگوریتم مهم است.
- دشوار بودن ارزیابی مدل: ارزیابی عملکرد الگوریتمهای یادگیری نیمه نظارت شده دشوار است زیرا هیچ مرجعی برای مقایسه نتایج وجود ندارد. این امر باعث میشود که به راحتی نتوان تشخیص داد آیا مدل واقعاً از دادههای بدون برچسب یاد میگیرد یا عملکرد آن صرفاً بر پایه حدسهای تصادفی است.
۴. انواع روش های یادگیری خودآموز
از دیگر انواع روش های ماشین لرنینگ میتوان به روش یادگیری خودآموز اشاره کرد. الگوریتمهای خودآموز در پی یادگیری روش نظارت نشده از طریق الگوریتمهای نظارت شده هستند. در این روش از یادگیری، دادههای ورودی این مدلها، خودشان به عنوان برچسب داده محسوب میشوند و دیگر نیازی به برچسبدهی دستی به دادههای آموزشی نیست.
یک کاربرد معمول از یادگیری خودآموز را میتوان در حوزه «بینایی ماشین» (Computer Vision) ملاحظه کرد. فرض کنید یک مجموعه داده از تصاویر رنگی بدون برچسب در دسترس است و میخواهیم از آن برای آموزش یک مدل یادگیری ماشین استفاده کنیم. به عنوان مثال، قصد داریم تصاویر را به رنگ خاکستری تبدیل کنیم تا مدل بازنمایی رنگ تصویر اصلی را پیشبینی کند. همچنین، میتوان بخشی از تصاویر را حذف کنیم تا مدل قسمتهای حذف شده را بازسازی کند. در چنین مثالهایی، میتوان از مدلهای ماشین لرنینگ با رویکرد یادگیری خودآموز استفاده کرد.
مدلهای «خودرمزگذار» (Autoencoders) نمونهای از الگوریتمهای یادگیری خودآموز هستند. این مدلها به عنوان یکی از انواع «شبکههای عصبی» (Neural Networks) محسوب میشوند که از آنها میتوان برای فشردهسازی دادههای ورودی استفاده کرد.

این مدلهای خودرمزگذار از دادههای آموزشی به عنوان ورودی و برچسب مدل استفاده میکنند و هدفشان این است که دادهها را به حالت فشرده درآورند به نحوی که اگر از حالت فشرده خارج شوند، بتوانند داده اصلی را بازسازی کنند. این مدل یادگیری ماشین از دو بخش رمزگذار و رمزگشا تشکیل میشود که پس از آموزش مدل، بخش رمزگشا کنار گذاشته میشود و میتوان قسمت رمزگذار را به منظور فشردهسازی دادهها به کار برد
اگرچه برای آموزش مدل خودرمزگذار از روش یادگیری نظارت شده استفاده میشود، اما این مدلها در پی فرآیند آموزش، یک مسئله با رویکرد نظارت نشده را حل میکنند و دادهها را با روش فشردهسازی به گونهای تبدیل میکنند که ابعادشان از ابعاد اصلی کمتر هستند.
یکی دیگر از الگوریتمهای ماشین لرنینگ با رویکرد یادگیری خودآموز، «شبکههای مولد تخاصمی» (Generative Adversarial Networks | GANs) هستند. کاربرد رایج این مدلهای مولد این است که بر اساس دادههای تصویری آموزشی، تصاویری را تولید کنند که شباهت زیادی به تصاویر اصلی و واقعی داشته باشند.
کاربرد روش های یادگیری خودآموز
یادگیری خودآموز یکی از انواع روش های ماشین لرنینگ تلقی میشود که در سالهای اخیر به طور چشمگیر مورد توجه قرار گرفته است. این روش یادگیری مزایای متعددی دارد و از آن در حوزههایی نظیر مراقبتهای بهداشتی، پردازش زبان طبیعی و بینایی کامپیوتر استفاده میشود که آمادهسازی و تهیه دادههای برچسبدار برای آنها دشوار و هزینهبر است. در ادامه، به برخی از کاربردهای مهم الگوریتمهای ماشین لرنینگ با رویکرد یادگیری خودآموز اشاره میکنیم:
- بازسازی تصویر: از روش یادگیری خودآموز میتوان برای بازسازی تصاویر از دادههای نویزی یا ناقص به منظور بهبود کیفیت دادههای تصویری استفاده کرد.
- رنگآمیزی تصویر: مدلهای مبتنی بر یادگیری خودآموز میتوانند یاد بگیرند که رنگ اصلی تصاویر خاکستری را پیشبینی کنند.
- عنوانگذاری تصویر: مدلهای ماشین لرنینگ با رویکرد یادگیری خودآموز میتوانند یاد بگیرند که برای تصاویر عنوانهایی ایجاد کنند که توضیحاتی پیرامون محتوا و زمینه تصویر را بهطور کامل دربر میگیرد.
- پیشبینی فریم ویدیو: از الگوریتمهای یادگیری خودآموز میتوان به منظور پیشبینی فریمهای بعدی یک ویدیو در مسائلی نظیر ردیابی اشیا استفاده کرد.
- تشخیص و جداسازی شی: روشهای یادگیری خودآموز میتوانند با بازنمایی بهتری از ویژگیهای دادهها، در تشخیص و جداسازی اشیای موجود در تصاویر عملکرد بهتری داشته باشند.
- تکمیل متن: کاربرد دیگر مدلهای هوش مصنوعی با رویکرد یادگیری خودآموز را میتوان در پردازش زبان طبیعی ملاحظه کرد. این مدلها میتوانند یاد بگیرند که متنهای پرسش را تکمیل و کلمات یا عبارات حذف شده را پر کنند تا جملات منسجمی حاصل شود.
- خلاصهسازی متن: مدلهای یادگیری خودآموز میتوانند یاد بگیرند که متنهای طولانی را به خلاصههای کوتاهتر و مختصرتر تبدیل کنند تا صرفاً نکات کلیدی و اطلاعات مهم را دربر بگیرند.
- پاسخ به سوالات: الگوریتمهای یادگیری ماشین با رویکرد یادگیری خودآموز میتوانند یاد بگیرند که بر اساس اسناد متنی به سوالات پاسخی مرتبط و مفید ارائه دهند.
- تولید متن: مدلهای ماشین لرنینگ خودآموز میتوانند یاد بگیرند که فرمتهای متن خلاقانه مختلفی مانند شعر، کد قطعههای برنامه نویسی، فیلمنامه، قطعات موسیقی، محتوای ایمیل، محتوای نامه و مواردی از این قبیل تولید کنند.
- تحلیل احساسات: از روشهای یادگیری خودآموز ماشین لرنینگ میتوان در احساسات اسناد متنی استفاده کرد.
- تشخیص گفتار: به منظور ارائه بازنماییهای بهتر از زبان گفتاری و افزایش دقت سیستمهای تشخیص گفتار میتوان از الگوریتمهای یادگیری خودآموز ماشین لرنینگ بهره گرفت.
- اکتشاف دارو: کاربرد دیگر روشهای یادگیری خودآموز هوش مصنوعی را میتوان در تجزیه و تحلیل مجموعه دادههای بزرگی از دادههای مولکولی و شیمیایی ملاحظه و از طریق آنها نامزدهای دارویی بالقوه را شناسایی و خواص آنها را پیشبینی کرد.
- تشخیص کلاهبرداریهای مالی: از تکنیکهای ماشین لرنینگ خودآموز میتوان برای تجزیه و تحلیل تراکنشهای مالی و شناسایی الگوهای مشکوکی مالی استفاده کرد.
- تقسیمبندی مشتریان: مدلهای یادگیری ماشین با رویکرد یادگیری خودآموز میتوانند برای تجزیه و تحلیل دادههای مشتری و دستهبندی آنها بر اساس رفتار و سلایقشان مورد استفاده قرار گیرند.
- سیستمهای توصیهگر: روشهای ماشین لرنینگ با رویکرد یادگیری خودآموز میتوانند با درک بهتر ترجیحات و علایق کاربر، توصیههای ارائه شده توسط سیستمهای توصیهگر را بهبود بخشند.
مزایای انواع روش های ماشین لرنینگ با رویکرد یادگیری خودآموز
رویکرد یادگیری خودآموز عملکرد بسیار خوبی در حل مسائل مختلف یادگیری ماشین دارد و در موضوعات مختلف میتوان از الگوریتمهای آن بهره گرفت. در ادامه، به مهمترین ویژگیهای این رویکرد یادگیری ماشین اشاره میکنیم:
- قابلیت مقیاسپذیری: رویکرد یادگیری خودآموز در مقایسه با رویکرد یادگیری نظارت شده مقیاسپذیرتر است زیرا به دادههای آموزشی برچسبدار نیاز ندارد و این امر باعث میشود بتوان به راحتی دادههای آموزشی بیشتری را برای مدل فراهم کنیم که این موضوع میتواند منجر به عملکرد بهتر شود. به علاوه، این ویژگی در کاهش زمان لازم برای تهیه و آمادهسازی دادههای آموزشی تاثیرگذار است.
- بهبود بازنمایی از ویژگیهای داده: در مقایسه با رویکرد یادگیری نظارت شده، روشهای یادگیری خودآموز میتوانند بازنماییهای غنیتر و بهتری از دادههای آموزشی ارائه دهند زیرا این روشها برای درک ساختار زیربنایی دادهها طراحی شدهاند در حالی که در روشهای یادگیری نظارت شده دادهها توسط تحلیل انسان برچسبدهی میشوند و مدلها درکی از ساختار پنهان دادهها ندارند.
- تعمیمپذیری مدل: الگوریتمهای یادگیری خودآموز تعمیمپذیرتر از روشهای یادگیری نظارت شده هستند زیرا یادگیری آنها به صورت انتزاعیتر انجام میشود و از آنها میتوان در طیف گستردهتری از مسائل استفاده کرد.
- استفاده از یادگیری خودآموز به جای روشهای یادگیری نظارت نشده: از روشهای یادگیری خودآموز میتوان برای یادگیری بازنمایی دادههای بدون برچسب استفاده کرد. به عبارتی، بازنماییهای حاصل شده را میتوان در مسائل مرتبط با یادگیری نظارت نشده مانند خوشهبندی و کاهش ابعاد به کار برد.
معایب یادگیری خودآموز
با این که روش های یادگیری ماشین با رویکرد یادگیری خودآموز دارای مزیتهای مهمی هستند و در بسیاری از مسائل میتوان از آنها استفاده کرد، دارای معایبی نیز هستند که در ادامه به آنها اشاره میکنیم:
- پیچیدگی محاسباتی: رویکرد یادگیری خودآموز ماشین لرنینگ از نظر محاسباتی در مقایسه با رویکرد یادگیری نظارت شده سنگینتر است به ویژه زمانی که با مجموعه حجیمی از دادههای آموزشی سر و کار داریم زیرا مدلهای این رویکرد اغلب به پارامترهای بیشتری نیاز دارند و عملیات پیچیدهتری را انجام میدهند.
- قابلیت تفسیرپذیری پایین: درک عملکرد مدلهای یادگیری خودآموز دشوار است که این امر باعث میشود درک نحوه تصمیمگیری آنها درباره خروجی سخت و پیچیده شود. این ویژگی میتواند کاربرد این رویکرد از یادگیری ماشین را در برخی حوزهها نظیر مسائل پزشکی محدود کند زیرا در این نوع مسائل دقیقاً باید نحوه انجام محاسبات و استنتاج و تصمیمگیری مدل مشخص باشد.
- سوگیری: روشهای یادگیری خودآموز ممکن است در حین یادگیری دادهها تحت تاثیر سوگیری قرار بگیرند.
- محدودیت کاربرد در حوزههای خاص: از الگوریتمهای یادگیری خودآموز نمیتوان در حوزههای خاصی با تنوع محدود یا دادههای ساختاریافته استفاده کرد.
۵. روش یادگیری چند نمونه ای
یادگیری چند نمونهای به عنوان یکی از حالات رویکرد یادگیری نظارت شده محسوب میشود که دادههای آموزشی آن از مجموعهای از نمونهها تشکیل شده است. به عبارتی، برای چندین داده، یک برچسب تعریف میشود که نوع کلاس دادهها را مشخص میکند اما فقط یکی از دادههای موجود در مجموعه متعلق به برچسب تعیین شده است.
هدف از این رویکرد، یادگیری مدلی است که میتواند مجموعهها را بر اساس نمونههای داخل آنها طبقهبندی کند. به منظور درک بهتر این روش از یادگیری ماشین از مثالی ساده کمک میگیریم. فرض کنید ۳ دسته کلید در اختیار داریم و به دنبال آن هستیم که دسته کلیدی را پیدا کنیم که حداقل یکی از کلیدهای آن میتواند قفل یک در را باز کند. هر دسته کلیدی که کلید سبز رنگ را شامل شود، به عنوان دسته کلید Positive در نظر گرفته میشود و سایر دسته کلیدها با برچسب Negative مشخص میشوند.

بر اساس تصور بالا دسته کلیدهای ۱ و ۲ دارای کلید سبز رنگ هستند و برچسب Positive به آنها داده میشود. با این حال شاهد این هستیم که در این دو دسته کلید، کلیدهای دیگری نیز وجود دارند که با استفاده از آنها نمیتوان قفل در مورد نظر را باز کرد. اما ما به کل دسته کلید برچسب Positive اختصاص دادیم. این مثال، یک نمونه واضح از شیوه برچسبزنی دادهها در روش یادگیری چند نمونهای است.
برای رویکرد یادگیری چند نمونهای مثال دیگری را میتوان از طبقهبندی صحنه در بینایی ماشبن ارائه کرد. فرض کنید مجموعهای تصاویر از طبیعت در اختیار دارید که هر یک از آنها نماهای مختلفی از جنگل، بیابان، ساحل و دریا را نشان میدهند. هدف مسئله طبقهبندی این تصاویر در دستههای صحنه مختلف است. با این حال، برچسبگذاری پیکسلهای هر یک از تصاویر دشوار و زمانبر است و میتوان به جای این کار، کل تصاویر را با نام یک دسته برچسبگذاری کنیم. اینجاست که میتوان از رویکرد یادگیری چند نمونهای بهره ببریم. میتوانیم با تقسیم هر تصویر به قسمتهای کوچکتر، مجموعهای از نمونهها ایجاد و سپس هر مجموعه را با نام تصویر اصلی برچسبگذاری کنیم. هدف این است که مدل هوشمندی را آموزش دهیم که میتواند مجموعههایی از قسمتهای مختلف تصاویر را در دستههای متفاوت طبقهبندی کند، حتی اگر فقط یکی از نمونههای موجود در مجموعه نشاندهنده برچسب دسته باشد.

الگوریتم های یادگیری چند نمونه ای
الگوریتمهای مختلفی وجود دارند که با رویکرد یادگیری چند نمونه ای به یادگیری و حل مسئله میپردازند که در ادامه به پرکاربردترین و مهمترین آنها اشاره شده است:
- الگوریتم «نمونهگیری تصادفی از بخشها» (Random Patch Sampling)
- الگوریتم «نمونهگیری انتخابی» (Selective Sampling)
- الگوریتم «یادگیری چند نمونهای بر پایه نمونه» (Instance-based Multi Instance Learning)
- الگوریتم «یادگیری چند نمونهای بر پایه مجموعه» (Bag-based Multi Instance Learning)
- الگوریتم «یادگیری چند نمونهای زیر فضا» (Subspace Multi Instance Learning)
- «شبکه عصبی چند نمونهای» (Multi Instance Neural Network)
کاربردهای انواع روش های ماشین لرنینگ با رویکرد چند نمونه ای
کاربرد رویکرد یادگیری چند نمونهای در یادگیری ماشین را میتوان در حوزههای مختلفی ملاحظه کرد که در ادامه به برخی از آنها اشاره میکنیم:
- طبقهبندی تصویر: یادگیری چند نمونهای میتواند برای طبقهبندی تصاویر بر اساس یادگیری مجموعهای از بخشهای تصویر استفاده شود.
- تشخیص ناهنجاری: الگوریتمهای ماشین لرنینگ با رویکرد یادگیری چند نمونهای را میتوان برای تشخیص ناهنجاریها در دادهها استفاده کرد. این مدلها با یادگیری مجموعهای از دادههای معمولی، درباره مجموعه داده جدید تصمیم میگیرند.
- کشف دارو: از روشهای یادگیری چند نمونهای میتوان برای شناسایی کاندیدای احتمالی دارو بر اساس یادگیری مجموعهای از دادههای مولکولی استفاده کرد. تنها یکی از نمونههای موجود در مجموعه دادهها با برچسب کلاس مرتبط است و نشان میدهد آیا مولکول دارای خواص مورد نظر است یا نمیتوان آن ترکیب نمونه را دارای خواص دانست.
- تشخیص تقلب: کاربرد دیگر روشهای یادگیری چند نمونهای را میتوان در تشخیص تراکنشهای جعلی در دادههای مالی ملاحظه کرد. در این مسئله فقط یک زیر مجموعه از تراکنشها در هر مجموعه به برچسب کلاس کمک میکند و نشان میدهد آیا تراکنش جعلی است.
- پردازش زبان طبیعی: از الگوریتم های یادگیری چند نمونهای میتوان در مسائل پردازش زبان طبیعی نظیر تجزیه و تحلیل احساسات و طبقهبندی متن با یادگیری از مجموعهای از جملات یا اسناد استفاده کرد که در این مسائل تنها یک زیر مجموعه از جملات یا اسناد در هر مجموعه نشاندهنده برچسب کلاس هستند.
مزایای روش یادگیری چند نمونه ای
روش یادگیری چند نمونهای یکی از انواع روش های ماشین لرنینگ محسوب میشود که به دلیل مزیتهایی که دارد، در حل مسائل مختلفی میتوان از آن بهره گرفت. در ادامه، به مهمترین مزایای این روش یادگیری اشاره میکنیم:
- قابلیت مقیاسپذیری: بر خلاف رویکرد یادگیری نظارت شده، روش یادگیری چند نمونهای به حجم عظیمی از نمونههای برچسبگذاری شده نیاز ندارد و این ویژگی این امکان را فراهم میکند تا بتوان از آن در مسائلی با مجموعه دادههای بزرگ و پیچیده به راحتی بهره گرفت.
- کارایی داده: رویکرد یادگیری چند نمونهای میتواند دادههای نویزی و غیر مرتبط را مدیریت کند زیرا فقط زیرمجموعهای از نمونههای موجود در هر مجموعه به تعیین برچسب کلاس کمک میکنند. بدین ترتیب، این روش در مقایسه با الگوریتمهای یادگیری نظارت شده کارآمدتر است زیرا برای آموزش آن مدلها، باید برچسب هر نمونه داده مشخص شود.
- تعمیمپذیری: الگوریتمهای ماشین لرنینگ با رویکرد یادگیری چند نمونهای تعمیمپذیرتر از روشهای یادگیری نظارت شده هستند زیرا این الگوریتمها ساختار زیربنایی دادهها را درک میکنند و به برچسبهای تولید شده توسط انسان متکی نیستند. بدین ترتیب، این مدلها میتوانند عملکرد بهتری بر روی دادههای جدید داشته باشند.
- انعطافپذیری: از روش های یادگیری ماشین با رویکرد یادگیری چند نمونه میتوان در طیف وسیعی از مسائل نظیر طبقهبندی تصویر، تشخیص ناهنجاری و کشف دارو استفاده کرد زیرا این مدلها میتوانند دادههای نویزی را مدیریت کنند و به دلیل تعمیمپذیری، تصمیمات درستتری را درباره دادههای جدید بگیرند.
- قابل تفسیر بودن: مدلهای یادگیری چند نمونهای تفسیرپذیرتر از مدلهای یادگیری نظارت شده هستند زیرا میتوانند رابطه بین نمونهها و برچسب کلاس را بهتر تشخیص دهند که این امر برای درک نحوه عملکرد مدل و رفع خطای مدل کارآمد است.
معایب روش یادگیری چند نمونه ای
رویکرد یادگیری چند نمونهای علاوه بر مزیتهای مهمی که دارد، دارای معایبی نیز هست که در ادامه این بخش، به آنها میپردازیم:
- پیچیدگی محاسباتی: رویکرد یادگیری چند نمونهای از نظر محاسباتی سنگینتر از روش یادگیری نظارت شده است به خصوص هنگامی که از مجموعه دادههای بزرگ برای آموزش مدل یادگیری ماشین استفاده شود. این امر به این دلیل است که آموزش مدلها بر روی چندین نمونه موجود در هر مجموعه انجام میشود.
- کارایی نمونه: الگوریتمهای یادگیری چند نمونهای ممکن است برای دستیابی به عملکرد قابل مقایسه با روشهای یادگیری نظارت شده، به دادههای آموزشی بیشتری نیاز داشته باشند زیرا این الگوریتمها باید رابطه بین نمونهها و برچسب کلاس را از دادههای آموزشی بیاموزند.
- محدودیت دامنه: الگوریتمهای یادگیری چند نمونهای ممکن است به خوبی به دامنههای جدید با ویژگیهای دادههای متفاوت تعمیم نیابند. این امر به این دلیل است که این الگوریتمها بر روی انواع خاصی از دادهها آموزش میبینند و ممکن است نتوانند ساختار زیربنایی دادههای جدید را درک کنند.
۶. روش یادگیری استقرایی
یادگیری استقرایی یکی دیگر از انواع روش های ماشین لرنینگ محسوب میشود که یک مدل را برای تولید پیشبینیها بر اساس نمونهها یا مشاهدات آموزش میدهد. در یادگیری استقرایی، دانش مدل از مثالها یا نمونههای خاص حاصل میشود و این دانش کسب شده را میتوان برای تصمیمگیری برای دادههای کاملاً جدید تعمیم داد.
مدلهای یادگیری ماشین که مبتنی بر رویکرد یادگیری استقرایی هستند، از یک قانون خاص برای حل مسئله و تصمیمگیری درباره دادههای جدید استفاده نمیکنند. در عوض، مدل هوش مصنوعی یاد میگیرد ارتباطات دادهها را تشخیص دهد و سپس از این دانش برای پیشبینی نتایج دادههای جدید استفاده کند.
از یادگیری استقرایی اغلب در مسائلی استفاده میشود که بتوان آنها را با الگوریتمهای یادگیری نظارت شده پیادهسازی کرد. در این مسائل از یک سری داده با برچسب صحیح برای آموزش مدل استفاده میشود و مدل با تشخیص رابطه بین دادههای ورودی و برچسبها، یاد میگیرد درباره دادههای جدید چطور تصمیم بگیرد.

از یادگیری استقرایی در چندین الگوریتم یادگیری ماشین معروف مانند درخت تصمیم، K نزدیکترین همسایه و شبکههای عصبی استفاده میشود. از آنجایی که این روش از یادگیری ماشین امکان ایجاد مدلهایی را فراهم میکند که میتوانند الگوها و روابط زیربنایی پیچیده را به خوبی درک کنند، از آن به عنوان یکی از مهمترین روشهای ماشین لرنینگ یاد میشود.
کاربرد روش های یادگیری استقرایی
از انواع روش های ماشین لرنینگ با رویکرد یادگیری استقرایی میتوان در مسائل مختلفی بهره گرفت. در ادامه این بخش، به برخی از کاربردهای این رویکرد میپردازیم:
- طبقهبندی تصویر: از الگوریتمهای یادگیری استقرایی به طور معمول برای مسائلی نظیر دستهبندی تصویر و شناسایی اشیا استفاده میشود.
- تشخیص ناهنجاری: از روشهای یادگیری استقرایی میتوان برای شناسایی ناهنجاریها یا موارد غیر معمول در دادهها استفاده کرد. مسائلی نظیر تشخیص کلاهبرداری، تشخیص نفوذ و حملات سایبری و نظارت بر سیستم از جمله مسائلی هستند که با کمک الگوریتمهای یادگیری استقرایی میتوان به پیادهسازی آنها پرداخت.
- فیلتر کردن هرزنامه: از رویکرد یادگیری استقرایی به طور گسترده در فیلتر کردن هرزنامهها به منظور شناسایی و دستهبندی ایمیلها استفاده میشود. الگوریتمهای این رویکرد با یادگیری الگوها در ایمیلهای معتبر و هرزنامهها، یاد میگیرند که پیامهای هرزنامه را با دقت بالا فیلتر کنند.
- سیستمهای توصیهگر: رویکرد یادگیری استقرایی را میتوان در طراحی سیستمهای توصیهگر برای توصیه محصولات، فیلمها یا سایر موارد به کاربران به کار برد. با یادگیری ترجیحات و سلایق کاربران و بررسی رفتار آنها، مدلهای ماشین لرنینگ با رویکرد یادگیری استقرایی میتوانند پیشبینی کنند که کدام یک از اقلام برای یک کاربر احتمالاً لذتبخش خواهد بود.
- تشخیص پزشکی: یادگیری استقرایی در تشخیص پزشکی برای کمک به پزشکان در تصمیمگیری در مورد مراقبت از بیمار استفاده میشود. با یادگیری الگوها در دادههای پزشکی، مدلها میتوانند نوع بیماریها یا شرایط بالقوه بیمار را شناسایی کنند.
- پردازش زبان طبیعی: یادگیری استقرایی در NLP برای وظایفی مانند تجزیه و تحلیل احساسات، ترجمه ماشینی و خلاصهنویسی متن استفاده میشود. با یادگیری الگوها در دادههای زبانی، مدلها میتوانند یاد بگیرند که معنای متن را درک و متن جدید تولید کنند.
مزایای روش یادگیری استقرایی
روشهای یادگیری استقرایی دارای مزیتهای مهمی هستند و در بسیاری از مسائل میتوان از آنها استفاده کرد. در ادامه، به برخی از مهمترین مزیتهای این روش میپردازیم:
- الگوریتمهای یادگیری استقرایی به دلیل انعطافپذیری و انطباقی که دارند، برای مدیریت دادههای پیچیده و پویا بسیار مناسب هستند.
- مدلهای یادگیری استقرایی برای مسائلی مانند تشخیص الگو و دستهبندی ایدهآل هستند زیرا میتوانند ارتباطات و الگوهایی را در دادهها شناسایی کنند که ممکن است برای انسان قابل تشخیص نباشند.
- روشهای یادگیری استقرایی برای کاربردهایی مناسب هستند که نیاز به پردازش مقادیر عظیم داده دارند زیرا میتوانند حجم عظیمی از دادهها را به طور کارآمد مدیریت کنند.
- از آن جایی که مدلهای یادگیری استقرایی میتوانند بدون برنامه نویسی صریح از مثالها یاد بگیرند، برای شرایطی مناسب هستند که قوانین توسط انسان به درستی توصیف یا درک نشدهاند.
معایب روش یادگیری استقرایی
روشهای یادگیری استقرایی علیرغم مزیتهای مهمی که دارند، دارای معایبی نیز هستند که در ادامه به آنها اشاره خواهیم کرد:
- مدلهای یادگیری استقرایی ممکن است دچار بیش برازش شوند یا الگوهای دادهها را به خوبی یاد نگیرند که این امر باعث میشود برای دادههای جدید عملکرد خوبی نداشته باشند.
- استفاده از مدلهای یادگیری استقرایی در کاربردهای واقعی ممکن است به دلیل ماهیت پرهزینه محاسباتی آنها، به ویژه برای مجموعههای داده پیچیده، کمتر به کار برده شوند.
- تفسیرپذیری مدلهای یادگیری استقرایی ممکن است دشوار باشد و در کاربردهایی که فرآیند تصمیمگیری باید شفاف و قابل توضیح باشد ممکن است نتوان از آنها استفاده کرد.
- مدلهای یادگیری استقرایی فقط به اندازه دادههایی که روی آنها آموزش داده شدهاند خوب هستند. بنابراین اگر دادهها ناقص باشند یا از دادههای دقیقی برای آموزش مدلها استفاده نشود، ممکن است مدل به طور موثر عمل نکند.
۷. روش یادگیری استنتاجی
یادگیری استنتاجی یک روش یادگیری ماشین است که در آن یک مدل با استفاده از یک سری اصول منطقی و مراحل مختلف ساخته میشود. در یادگیری استنتاجی، مدل به طور خاص برای پیروی از مجموعهای از دستورالعملها و فرایندها طراحی شده است تا با کمک آنها تصمیماتی را برای دادههای کاملاً جدید بگیرد.

یادگیری استنتاجی اغلب در سیستمهای «مبتنی بر قاعده» (Rule Based)، «سیستمهای خبره» (Expert Systems) و سیستمهای «مبتنی بر دانش» (Knowledge Based) استفاده میشود. در این رویکرد از یادگیری، قواعد و فرایندها به وضوح توسط متخصصان حوزه تعیین میشوند و مدل بر اساس دستورالعملها و فرایندها دادهها را تجزیه و تحلیل و خروجیها را استنتاج میکند.
بر خلاف آموزش مدلهای مبتنی بر یادگیری استقرایی که بر اساس مثالهای خاص بود، آموزش مدلهای مبتنی بر یادگیری استنتاجی با مجموعهای از قواعد و فرایندها شروع میشود و این مدلها از این قواعد برای تصمیمگیری درباره دادههای ورودی استفاده میکنند. هدف یادگیری استنتاجی ساخت مدلی است که بتواند به طور دقیق به مجموعهای از دستورالعملها و فرایندها پایبند باشد تا پیشبینیهای دقیقی را با آنها انجام دهد.

یادگیری استنتاجی توسط تعدادی از الگوریتمهای یادگیری ماشین شناخته شده مانند درخت تصمیم، سیستمهای مبتنی بر قواعد و سیستمهای خبره استفاده میشود. یادگیری استنتاجی یک استراتژی مهم در یادگیری ماشین است زیرا امکان توسعه مدلهایی را فراهم میکند که میتوانند پیشبینیهای دقیقی را با توجه به قواعد و دستورالعملهای از پیش تعیین شده انجام دهند.
کاربرد روش یادگیری استنتاجی
الگوریتمهای یادگیری استنتاجی در طیف وسیعی از کاربردها استفاده میشوند که در ادامه به چند نمونه از مهمترین کاربردهای آنها اشاره شده است:
- تشخیص پزشکی: پزشکان از استدلال استنتاجی برای تشخیص انواع بیماری بر اساس علائم، سابقه پزشکی و نتایج آزمایش استفاده میکنند.
- شناسایی کلاهبرداری: بانکها و شرکتهای مالی و اعتباری از استدلال استنتاجی برای شناسایی تراکنشهای جعلی بر اساس الگوهای مختلف بهره میبرند.
- فیلتر کردن هرزنامه: از استدلال استنتاجی میتوان در سرورهای ایمیل به منظور شناسایی ایمیلهای هرز بر اساس آدرس فرستنده، محتوای ایمیل و سایر عوامل استفاده کرد.
توصیه محصول: وب سایتهای تجارت الکترونیکی از روشهای یادگیری ماشین با رویکرد استدلال استنتاجی برای توصیه محصولات به مشتریان بر اساس خریدهای گذشته، سابقه مرور و سایر دادهها استفاده میکنند. - پردازش زبان طبیعی: مدلهای زبانی از استدلال استنتاجی برای درک معنای متن و تولید متن با حفظ قواعد دستور زبان استفاده میکنند.
- مدیریت ارتباط با مشتری (CRM): در طراحی سیستمهای CRM میتوان از استدلال استنتاجی برای تقسیمبندی مشتریان بر اساس جمعیتشناسی، ترجیحات و سابقه خرید استفاده کرد.
- ارزیابی ریسک: شرکتهای بیمه میتوانند از مدلهای یادگیری ماشین با رویکرد استدلال استنتاجی برای ارزیابی ریسک مشتریان بالقوه بر اساس سابقه پزشکی، وضعیت مالی و سایر عوامل استفاده کنند.
- استدلال حقوقی: وکلای دادگستری از استدلال استنتاجی برای تفسیر قوانین و اعمال آنها در موارد خاص استفاده میکنند.
- استنتاج علمی: دانشمندان میتوانند روشهای مبتنی بر استدلال استنتاجی را برای نتیجهگیری از آزمایشها و مشاهدات به کار ببرند.
مزایای انواع روش های ماشین لرنینگ با رویکرد یادگیری استنتاجی
رویکرد یادگیری استنتاجی عملکرد خوبی در حل برخی مسائل مختلف یادگیری ماشین دارد و در موضوعات مختلف میتوان از این روش بهره گرفت. در ادامه، به مهمترین مزیتهای این رویکرد یادگیری ماشین اشاره میکنیم:
- از آنجا که یادگیری استنتاجی با مفاهیم گسترده شروع میشود و قواعد کلی را به موارد خاص اعمال میکند، اغلب سریعتر از یادگیری استقرایی است.
- یادگیری استنتاجی گاهی اوقات میتواند نتایج دقیقتری نسبت به یادگیری استقرایی ارائه دهد زیرا با اصول و قواعد خاصی شروع میشود و آنها را به منظور تجزیه و تحلیل به دادهها اعمال میکند.
- یادگیری استنتاجی برای مسائلی کاربردیتر هستند که پراکندگی زیادی در دادههای مسئله وجود دارد یا به راحتی نمیتوانیم دادههای کافی برای آموزش مدل فراهم کنیم.
معایب روش یادگیری استنتاجی
با این که روش های یادگیری ماشین با رویکرد یادگیری استنتاجی دارای مزیت هستند و در برخی از مسائل میتوان از آنها استفاده کرد، این رویکرد معایبی نیز دارد که در ادامه به آنها اشاره میکنیم:
- رویکرد یادگیری استنتاجی به شدت به مجموعه قواعدی وابستگی دارد که ممکن است ناکارآمد یا منسوخ باشند.
- از رویکرد یادگیری استنتاجی نمیتوان برای مسائلی استفاده کرد که پیچیده هستند و نمیتوان برای دادههای این نوع مسائل، قواعد دقیق یا همبستگی تعریف کرد.
- یادگیری استنتاجی برای مسائل مبهم که دارای حقایق متناقض یا غیرقابل حل هستند مناسب نیست.
- دقت یادگیری استنتاجی به کیفیت قواعد و پایگاه دانش آن بستگی دارد که ممکن است باعث ایجاد سوگیری و خطا در نتایج شود.
۸. یادگیری ترارسانی
در نظریه یادگیری آماری، واژه «انتقال» یا عبارت «یادگیری ترارسانی» به فرآیند پیشبینی نمونههای خاص با استفاده از نمونههای موجود از یک حوزه اشاره دارد. این رویکرد از یادگیری بر خلاف روش یادگیری استقرایی است که در آن مدل ماشین لرنینگ بر اساس یک مجموعه داده بزرگ از مثالهای آموزشی ایجاد میشود و سپس میتوان آن را برای پیشبینی نمونههای جدیدی استفاده کرد که در مجموعه داده آموزشی دیده نشدهاند.
یادگیری ترارسانی برای مسائلی که دارای تعدادی نمونه آموزشی محدود هستند، کاربردی است زیرا مدل میتواند از این نمونهها برای پیشبینی نمونههای جدید استفاده کند بدون این که نیاز به جمعآوری دادههای آموزشی بیشتر داشته باشد.
علاوهبراین، از رویکرد یادگیری ترارسانی میتوان برای مسائلی استفاده کرد که دارای ویژگیهای پیچیده یا نامنظم هستند زیرا مدل میتواند از این ویژگیها برای پیشبینی نمونههای جدید استفاده کند بدون این که نیاز به تعمیم الگوهایی باشد که در دادههای آموزشی مشاهده شدهاند.

برخلاف رویکرد یادگیری استقرایی، در روش یادگیری ترارسانی نیازی به تعمیمسازی نیست و برای تصمیمگیری درباره دادههای جدید، مستقیماً از سایر دادهها استفاده میشود. یکی از الگوریتمهای ماشین لرنینگ با این رویکرد، الگوریتم k نزدیکترین همسایه است که در آن نیازی به مدلسازی دادههای آموزشی نیست و صرفاً کافی است از K داده آموزشی برای تصمیمگیری درباره داده جدید استفاده شود.
کاربرد روش یادگیری ترارسانی در ماشین لرنینگ
یادگیری ترارسانی یک روش یادگیری آماری قدرتمند است که میتواند برای حل طیف وسیعی از مسائل مورد استفاده قرار گیرد. در ادامه، به برخی از کاربردهای این رویکرد یادگیری میپردازیم:
- سیستمهای توصیهگر: الگوریتمهای یادگیری ترارسانی میتوانند برای توصیه محصولات یا خدمات به کاربران بر اساس رفتار گذشته آنها استفاده شوند. به عنوان مثال، یک سرویس پخش موسیقی میتواند از این الگوریتمها برای توصیه آهنگهای جدید به کاربر بر اساس سابقه گوش دادن آنها استفاده کند.
- شناسایی ناهنجاری: الگوریتمهای یادگیری ترارسانی میتوانند برای شناسایی ناهنجاریها در دادهها، مانند تراکنشهای جعلی یا تلاشهای نفوذ استفاده شوند. به عنوان مثال، بانک میتواند از این نوع الگوریتمها به منظور شناسایی تراکنشهای مشکوک بر اساس سابقه حساب کاربر و الگوهای تراکنش کاربر استفاده کند.
- بخشبندی تصویر: الگوریتمهای یادگیری ترارسانی را میتوان برای بخشبندی تصاویر، مانند شناسایی اشیا در تصاویر یا جداسازی پیشزمینه از پسزمینه به کار برد. به عنوان مثال، یک اتومبیل خودران میتواند از این روشها برای بخشبندی جادهها و سایر اشیا در میدان دید خود استفاده کند.
- پردازش زبان طبیعی: الگوریتمهایی با رویکرد یادگیری ترارسانی میتوانند برای طیف وسیعی از مسائل در پردازش زبان طبیعی، مانند تجزیه و تحلیل احساسات و طبقهبندی متن استفاده شوند. به عنوان مثال، یک شرکت میتواند از این روشها برای طبقهبندی نظرات کاربران سایت خود در دستههای مثبت، منفی یا خنثی استفاده کند.
مزایای روش یادگیری ترارسانی
رویکرد یادگیری ترارسانی، به عنوان یکی از انواع روش های ماشین لرنینگ، دارای مزایایی است و در حل برخی از مسائل هوش مصنوعی میتوان از آن استفاده کرد. در ادامه، به برخی از مهمترین مزیتهای این روش میپردازیم:
- پیشبینیهای دقیقتر: الگوریتمهای ماشین لرنینگ با رویکرد یادگیری ترارسانی میتوانند پیشبینیهای دقیقتری را نسبت به الگوریتمهای یادگیری استقرایی داشته باشند زیرا این الگوریتمها به گونهای طراحی شدهاند که بر اساس دادههای آموزشی به تصمیمگیری درباره دادههای جدید میپردازند.
- عملکرد بهبود یافته: الگوریتمهای یادگیری ترارسانی اغلب میتوانند با بهرهگیری از روابط بین نقاط دادههای موجود در مجموعه داده آموزشی، عملکرد مدلهای یادگیری ماشین را بهبود بخشند زیرا این الگوریتمها برخلاف روشهای یادگیری استقرایی میتوانند الگوها را در دادهها شناسایی کنند و از آنها بهره ببرند.
- انعطافپذیری: الگوریتمهای یادگیری ترارسانی میتوانند برای طیف وسیعتری از وظایف نسبت به الگوریتمهای یادگیری استقرایی استفاده شوند. این امر به این دلیل است که الگوریتمهای یادگیری ترارسانی نیاز به تعمیمپذیری برای دادههای جدید ندارند. در نتیجه، روشهای یادگیری انتقالی برخلاف روشهای یادگیری استقرایی میتوانند برای وظایفی مانند شناسایی ناهنجاری و بخشبندی تصویر استفاده شوند.
- قابلیت ارتقا: روشهای یادگیری ترارسانی در مقایسه با الگوریتمهای یادگیری استقرایی قابل ارتقا هستند. این امر به این دلیل است که الگوریتمهای یادگیری ترارسانی نیازی به یادگیری مجموعه بزرگی از پارامترها ندارند که همین ویژگی میتواند بار محاسباتی این روشها را تا حدودی کاهش دهد.
معایب یادگیری ترارسانی در یادگیری ماشین
روشهای یادگیری ترارسانی علیرغم مزیتهایی که دارند، دارای معایبی نیز هستند که در ادامه به آنها اشاره خواهیم کرد:
- بار محاسباتی زیاد: روش های یادگیری ماشین با رویکرد یادگیری ترارسانی میتوانند از نظر محاسباتی هزینهبرتر از الگوریتمهای یادگیری استقرایی باشند. این امر به این دلیل است که الگوریتمهای یادگیری ترارسانی برای تصمیمگیری در مورد داده جدید نیاز دارند تا روابط بین همه نقاط دادههای موجود در مجموعه داده آموزشی را در نظر بگیرند.
- مناسب نبودن برای دادههای جدید: روشهای یادگیری ترارسانی برای پیشبینی خروجی دادههای جدید به اندازه الگوریتمهای یادگیری استقرایی مناسب نیستند زیرا این الگوریتمها برای تعمیم به دادههای جدید طراحی نشدهاند. در نتیجه، الگوریتمهای یادگیری ترارسانی ممکن است در شرایطی که مقدار زیادی داده جدید وجود دارد که مدل قبلاً ندیده است، عملکرد خوبی نداشته باشند.
- تفسیرپذیری دشوار: انواع روش های ماشین لرنینگ با رویکرد یادگیری ترارسانی به لحاظ تفسیرپذیری به خوبی الگوریتمهای یادگیری استقرایی نیستند. این امر به این دلیل است که این الگوریتمها اغلب بر اساس مدلهای ریاضی پیچیدهای طراحی شدهاند که درک عملکرد آنها دشوار است.
۹. انواع روش های ماشین لرنینگ با رویکرد یادگیری تقویتی
یکی دیگر از انواع روش های ماشین لرنینگ، یادگیری تقویتی است که بر اساس یک فرآیند مبتنی بر بازخورد کار میکند. در این رویکرد از یادگیری ماشین عامل هوشمند (یک جزء نرم افزاری) وجود دارد که به طور خودکار محیط اطراف خود را با آزمون و خطا، انجام عمل، یادگیری از تجربیات و و بررسی بازخورد و بهبود عملکرد خود، کاوش میکند. عامل هوشمند برای انجام هر عمل خوب پاداش دریافت میکند و برای انجام هر عمل بد مجازات میشود. بنابراین، هدف عامل هوشمند در یادگیری تقویتی به حداکثر رساندن پاداشهای دریافتی است.
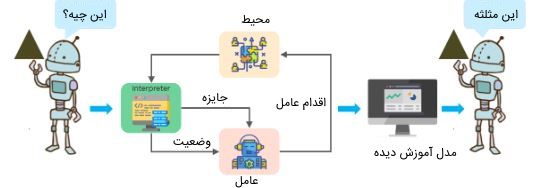
در یادگیری تقویتی، بر خلاف یادگیری نظارت شده، نیاز به دادههای آموزشی برچسبگذاری شده نیست و عامل هوشمند فقط از تجربیات خود یاد میگیرند. به عبارتی میتوان گفت فرایند یادگیری تقویتی مانند یادگیری انسان است؛ به عنوان مثال، کودک از طریق تجربیات در زندگی روزمره خود با محیط اطراف خود و کاربرد لوازم آشنا میشود. عامل هوشمند هم همانند کودک با محیط اطراف خود ارتباط برقرار میکند و با توجه به بازخوردهایی که از محیط میگیرد، میآموزد چطور مسائل را به بهترین شکل حل کند.
الگوریتم های یادگیری تقویتی
برای پیادهسازی رویکرد یادگیری تقویتی از الگوریتمهای مختلفی استفاده میشود که در ادامه به برخی از پرکاربردترین آنها اشاره شده است:

- الگوریتم Monte Carlo Control
- الگوریتم یادگیری «تفاوت زمانی» (Temporal Difference)
- الگوریتم «گرادیان سیاست» (Policy Gradient)
- الگوریتم Deep Q-learning
- الگوریتم «بازیگر - منتقد» (Actor-Critic)
- الگوریتم «یادگیری تقویتی با تخمین تابع» (Reinforcement Learning with Function Approximation)
- الگوریتم «یادگیری تقویتی احتمالاتی» (Probabilistic Reinforcement Learning)
- الگوریتم «برنامهنویسی پویای تقریبی» (Approximate Dynamic Programming)
- الگوریتم «یادگیری تقویتی با سیستمهای چند عامله» (Reinforcement Learning with Multiagent Systems)
کاربردهای یادگیری تقویتی
رویکرد یادگیری تقویتی به دلیل مزیتهای مهمی که دارد، در بسیاری از حوزههای یادگیری ماشین استفاده میشود. در این بخش، به برخی از کاربردهای این رویکرد اشاره میکنیم:
- طراحی بازیهای ویدئویی: الگوریتمهای یادگیری تقویتی در ساخت بازیهای کامپیوتری بسیار محبوب هستند. AlphaGo و AlphaGo Zero از بازیهای محبوب طراحی شده توسط یادگیری تقویتی به شمار میروند.
- رباتیک: از روشهای یادگیری تقویتی به طور گسترده در کاربردهای رباتیک استفاده میشود. رباتها در حوزه صنعتی و تولیدی کاربرد دارند و عملکردشان با یادگیری تقویتی قویتر میشوند.
- ماشینهای خودران: شرکتهای خودروسازی نظیر تسلا از روشهای یادگیری تقویتی به منظور ساخت ماشینهای خودران استفاده میکنند. این ماشینها با کسب تجربههای جدید، عملکرد خود را بهبود میبخشند.
- پردازش زبان طبیعی: از روشهای یادگیری تقویتی میتوان برای آموزش مدلهای یادگیری ماشین به منظور تولید متن، ترجمه زبانها و پاسخ به سؤالات کاربران استفاده کرد. به عنوان مثال، ربات Einstein Salesforce از رویکرد یادگیری تقویتی برای ارائه خدمات مشتری استفاده میکند.
- امور مالی: روش های یادگیری تقویتی میتوانند برای بهینهسازی استراتژیهای معاملاتی و مدیریت ریسک استفاده شوند. به عنوان مثال، برخی از صندوقهای پوشش ریسک از این رویکرد یادگیری ماشین برای معامله سهام و گزینهها استفاده میکنند.
- امور پزشکی و درمانی: از انواع روش های ماشین لرنینگ با رویکرد یادگیری تقویتی میتوان برای توسعه درمانهای جدید و تشخیص بیماریها استفاده کرد. به عنوان مثال، DeepMind گوگل از یادگیری تقویتی برای توسعه داروهای جدید و درمان سرطان استفاده میکند.
- کنترل ترافیک: روشهای یادگیری تقویتی را میتوان برای بهینهسازی جریان ترافیک و کاهش ازدحام استفاده کرد. به عنوان مثال، در برخی از شهرها از الگوریتمهای یادگیری تقویتی برای کنترل چراغهای راهنمایی و مدیریت پارکینگ استفاده شده است.
- واقعیت مجازی (Virtual Reality | VR) و واقعیت افزوده (Augmented Reality | AR): از یادگیری تقویتی میتوان برای ایجاد واقعیت مجازی و واقعیت افزوده استفاده کرد. به عنوان مثال، در طراحی برخی از بازیهای واقعیت مجازی برای ایجاد شخصیتها و محیطهای واقعیتر از روشهای یادگیری تقویتی استفاده میشود.
مزایای یادگیری تقویتی
کاربرد رویکرد یادگیری تقویتی در طراحی و ساخت سیستمهای هوشمند بیش از پیش شده است و روشهای آن دارای مزایای مهم و خوبی هستند. در ادامه، به مهمترین مزیتهای این رویکرد یادگیری ماشین اشاره میکنیم:
- یادگیری از تجربه: عامل هوشمند یادگیری تقویتی میتواند از تعاملات خود با محیط بدون نیاز به دخالت انسان یاد بگیرد چطور مسائل را حل کند. این ویژگی برای حل مسائل پیچیده مناسب است. همچنین، این رویکرد از یادگیری را میتوان برای پیادهسازی مسائلی به کار برد که کلیه شرایط و حالات آنها مشخص و واضح نیستند.
- انعطافپذیری: عامل هوشمند الگوریتمهای یادگیری تقویتی میتوانند با تغییرات محیط نظیر موانع جدید یا تغییرات پاداش سازگار شوند. بدین ترتیب، روشهای این رویکرد در شرایط عدم قطعیت مقاوم هستند و میتوانند موقعیتهای پیچیده و پویا را به خوبی مدیریت کنند.
- قابلیت مقیاسپذیری: الگوریتمهای یادگیری ماشین با رویکرد یادگیری تقویتی را میتوان برای طیف وسیعی از موضوعات، از طراحی بازیهای ساده گرفته تا حل مشکلات پیچیده دنیای واقعی، اعمال کرد.
- مستقل بودن الگوریتمها از انسان: عامل هوشمند روشهای ماشین لرنینگ با رویکرد یادگیری تقویتی میتواند بدون دخالت انسان تصمیم بگیرند و اقداماتی را در راستای حل مسئله انجام دهد.
- حل مسائل دشوار: الگوریتمهای یادگیری تقویتی میتوانند مسائلی نظیر بازیهای پیچیده یا کنترل رباتها را حل کنند که برای پیادهسازی آنها نمیتوان از روشهای سنتی هوش مصنوعی استفاده کرد.
معایب یادگیری تقویتی
با این که انواع روش های ماشین لرنینگ با رویکرد یادگیری تقویتی دارای مزیتهای مهمی هستند و کاربرد زیادی در حل مسائل دنیای واقعی دارند، این رویکرد دارای معایبی نیز هست که در ادامه به آنها اشاره میکنیم:
- اکتشاف در مقابل بهرهبرداری: عامل هوشمند یادگیری تقویتی به اکتشاف محیط پیرامون خود بپردازد و چیزهای جدیدی را برای یادگیری امتحان کند. این امر میتواند یادگیری عامل را در مسائلی با محیطهای پیچیده دشوار کند.
- دادههای آموزشی مورد نیاز: الگوریتمهای یادگیری تقویتی برای یادگیری مسائل به مقدار زیادی داده نیاز دارند. جمعآوری و آمادهسازی حجم عظیمی از داده به لحاظ زمانی و مالی هزینهبر است.
- پیچیدگی نمونه: انواع روش های ماشین لرنینگ با رویکرد یادگیری تقویتی پیش از این که بتوانند به عملکرد خوبی دست پیدا کنند، باید آزمون و خطای زیادی را انجام دهند. در مسائلی که حجم دادههای آموزشی کم است، نمیتوان نتیجه خوبی از الگوریتمهای یادگیری تقویتی گرفت.
- ثبات: الگوریتمهای یادگیری تقویتی نسبت به پارامترهای خود و مقدار اولیه وزنهای خود حساس هستند که این امر میتواند در یادگیری آنها تاثیرگذار باشد.
- عملکرد پیچیده: عملکرد روشهای یادگیری تقویتی را نمیتوان به راحتی توضیح داد. این امر اشکالزدایی و درک رفتار آنها را سخت میکند.
- ایمنی: عامل هوشمند یادگیری تقویتی گاهی اوقات ممکن است رفتارهای خطرناک یا مضر مانند رانندگی بی پروا یا آسیب رساندن به انسان ها را بیاموزد که همین امر به عنوان یک نگرانی جدی در کاربردهای حساس محسوب میشود.
۱۰. یادگیری چند وظیفه ای
یادگیری چند وظیفهای یه عنوان یکی از انواع روش های یادگیری نظارت شده محسوب میشود که هدف آن آموزش یک مدل بر روی یک مجموعه داده است که به چندین موضوع مرتبط رسیدگی میکند. به بیان دیگر، در این نوع آموزش، به طراحی مدلی میپردازیم که میتواند به طور همزمان روی چندین موضوع مرتبط آموزش داده شود به گونهای که عملکرد نهایی مدل با آموزش بر روی هر موضوع منفرد بهبود یابد.
از رویکرد یادگیری چند وظیفهای میتوان در حل مسائلی استفاده کرد که مقدار زیادی داده ورودی با برچسب برای یک موضوع خاص وجود دارد و از آنها میتوان برای موضوع دیگر با دادههای برچسبدار بسیار کمتر استفاده شود.

«تعبیهسازی کلمات» (Word Embedding) مثالی رایج از یادگیری چند وظیفهای است که به طور همزمان با یکی از موضوعات پردازش زبان طبیعی نظیر تحلیل احساسات، خلاصهسازی متن، دستهبندی متون و مواردی از این قبیل با استفاده از دادههای آموزشی فراهم شده یاد گرفته میشود.
کاربرد یادگیری چند وظیفه ای
یادگیری چند وظیفهای یکی از انواع یادگیری ماشین است که طیف گستردهای از کاربردها را در زمینههای مختلف شامل میشود. در ادامه، به برخی از مهمترین آنها اشاره شده است:
- پردازش زبان طبیعی: از رویکرد یادگیری چند وظیفهای میتوان به خوبی در انواع مسائل پردازش زبان طبیعی مانند ترجمه ماشینی، طبقهبندی متن و تجزیه و تحلیل احساسات استفاده کرد. با به اشتراک گذاشتن اطلاعات در سراسر وظایف، روش یادگیری چند وظیفهای میتواند عملکرد کلیه وظایف را بهبود بخشد. به عنوان مثال، این رویکرد میتواند برای آموزش مدلی استفاده شود که به طور همزمان میتواند زبانها را ترجمه و همچنین متن را به دستههای مختلف خبری، ورزشی یا سرگرمی طبقهبندی کند.
- بینایی کامپیوتری: از روش یادگیری چند وظیفهای میتوان در بینایی کامپیوتر برای وظایفی مانند تشخیص شی، دستهبندی تصویر و درک صحنه استفاده کرد. با به اشتراک گذاشتن ویژگیها در سراسر وظایف، این رویکرد میتواند به مدلها کمک کند تا درک بصری بهتری از پیرامون خود داشته باشند. به عنوان مثال، از این رویکرد میتوان برای آموزش مدلی استفاده کرد که اشیا را در تصاویر تشخیص میدهد و همچنین تصاویر را به دستههای مختلف مانند صحنههای فضای باز، صحنههای داخلی یا افراد دستهبندی میکند.
- مراقبتهای بهداشتی: رویکرد یادگیری چند وظیفهای پتانسیل بهبود تشخیص و درمان بیماریها را دارد. به عنوان مثال، این رویکرد میتواند برای توسعه مدلهایی استفاده شود که میتوانند تصاویر پزشکی را تجزیه و تحلیل و خطر بیماری را پیشبینی کنند یا الگوهایی را در دادههای بیمار تشخیص دهند.
- امور مالی: از روش یادگیری چند وظیفهای میتوان برای توسعه مدلهایی استفاده کرد که میتوانند قیمت سهام را پیشبینی کنند، ریسک اعتباری را ارزیابی و آن را مدیریت کنند.
- سیستمهای توصیهگر: از رویکرد یادگیری چند وظیفهای میتوان برای توسعه سیستمهای توصیهگر بهتر استفاده کرد که میتوانند محصولات، فیلمها یا موسیقی را به کاربران توصیه کنند.
- تشخیص ناهنجاری: رویکرد یادگیری چند وظیفهای را میتوان برای توسعه مدلهایی به کار برد که میتوانند ناهنجاریها مانند کلاهبرداری یا حملات سایبری را تشخیص دهند.
- رباتیک: یادگیری چند وظیفهای میتواند برای توسعه رباتهایی استفاده شود که میتوانند یاد بگیرند تا چندین وظیفه نظیر مانند ناوبری، دستکاری شی و تشخیص گفتار را به طور همزمان انجام دهند.
- خودروهای خودران: رویکرد یادگیری چند وظیفهای برای توسعه خودروهای خودران ضروری است که میتوانند در محیطهای پیچیده حرکت کنند و تصمیمات را در زمان واقعی بگیرند.
- کشف دارو: برای تسریع فرآیند کشف دارو با شناسایی نامزدهای داروی جدید و پیشبینی کارآیی آنها میتوان از رویکرد یادگیری چند وظیفهای استفاده کرد.
- آموزش سیستمهای شخصیسازی شده: روش یادگیری چند وظیفهای میتواند برای توسعه سیستمهای یادگیری شخصیسازی شدهای استفاده شود که میتوانند مطابق با نیازها و سبک یادگیری هر دانشآموز سازگار شوند.
مزایای انواع روش های ماشین لرنینگ با رویکرد یادگیری چند وظیفه ای
رویکرد یادگیری چند وظیفه ای دارای مزایای مهمی است که به همین خاطر در انواع مختلفی از پروژههای یادگیری ماشین از آن استفاده میشود. در ادامه به برخی از مهمترین مزیتهای این رویکرد اشاره میکنیم:
- بهبود عملکرد مدل: رویکرد یادگیری چند وظیفهای میتواند با به اشتراک گذاشتن اطلاعات در چندین مسئله، عملکرد هر یک از مدلها را بهبود بخشد.
- کاهش نیاز به حجم عظیمی از داده آموزشی: رویکرد یادگیری چند وظیفهای میتواند با استفاده از اطلاعات چندین وظیفه، مقدار داده مورد نیاز برای آموزش مدلها را کاهش دهد. این ویژگی میتواند مناسب مسائلی باشد که تهیه و آمادهسازی دادههای آموزشی مورد نیاز آن دشوار است.
- تعمیمپذیری بهتر: یادگیری چند وظیفهای میتواند منجر به تعمیم بهتر مدلها به دادههای دیده نشده شود زیرا مدل با بازنمایی اشتراکی میتواند ویژگیهای کلیتری را در یاد بگیرد. این ویژگی باعث میشود مدل یادگیری ماشین بتواند درباره دادههای جدید بهتر تصمیم بگیرد.
- انعطافپذیری بیشتر: روشهای یادگیری چند وظیفهای میتوانند از طیف گستردهتری از دادهها یاد بگیرند. به همین دلیل، مدلهای مبتنی بر این رویکرد میتوانند برای وظایفی با محیطهای مختلف مناسب باشند.
معایب رویکرد یادگیری چند وظیفه ای در یادگیری ماشین
مدلهایی که با رویکرد یادگیری چند وظیفهای آموزش میبینند، دارای معایبی نیز هستند که در ادامه این بخش به آنها اشاره میکنیم:
- افزایش پیچیدگی: رویکرد یادگیری چند وظیفهای پیچیدگی مدلها را افزایش میدهد زیرا باید همزمان چندین وظیفه را یاد بگیرد. این ویژگی باعث دشوارتر شدن آموزش و اشکالزدایی مدلها میشود.
- افزایش تداخل میان وظایف: اگر بازنمایی اشتراکی بین وظایف به دقت طراحی نشده باشد، روش یادگیری چند وظیفهای ممکن است تداخل بین وظایف را افزایش دهد. این امر منجر به کاهش عملکرد در برخی وظایف میشود.
- حساسیت بیشتر به کیفیت دادهها: یادگیری چند وظیفهای میتواند نسبت به کیفیت دادهها حساستر باشد زیرا به دلیل بازنمایی اشتراکی ویژگیها سبب میشود خطاهای موجود در یک وظیفه به سایر وظایف سرایت کنند.
- دشوار بودن تفسیر مدلها: تفسیر عملکرد مدلها با رویکرد یادگیری چند وظیفهای دشوارتر است زیرا آنها از چندین منبع داده به منظور یادگیری مسائل استفاده میکنند. این امر میتواند باعث شود که درک پیشبینیهای خاص مدل دشوارتر شود.
۱۱. روش یادگیری فعال
یادگیری فعال یکی دیگر از انواع روش های ماشین لرنینگ محسوب میشود که برنامه نویس برای آموزش مدل هوش مصنوعی از مجموعه داده بزرگی استفاده میکند که تنها بخش کوچکی (مثلاً ۱۰ درصد) از آن برچسب گذاری شده است. فرض کنید در یک مجموعه داده هزار نمونه وجود دارد که صد نمونه از آنها برچسب گذاری شدهاند. یک مدل مبتنی بر یادگیری فعال با این صد نمونه برچسبدار آموزش میبیند و بر روی ۹۰۰ نمونه باقیمانده (مجموعه آزمایشی) پیشبینی را انجام میدهد.
فرض کنید از این ۹۰۰ نمونه، ۱۰ نمونه وجود دارند که مدل درباره آنها نمیتواند با اعتماد زیادی به پیشبینی بپردازد. در این حالت مدل از یک کاربر انسانی میخواهد تا برچسبهای این ۱۰ نمونه را برای او فراهم کند. به عبارت دیگر، رویکرد یادگیری فعال، یک رویکرد تعاملی است و به همین دلیل از کلمه «فعال» برای نامگذاری آن استفاده شده است.
پس از برچسبگذاری ۱۰ نمونه توسط انسان، این نمونهها به مجموعه دادههای آموزشی اضافه میشوند و یادگیری مدل مجدداً با تمامی دادههای آموزشی انجام میشود. بنابراین، در این حالت صرفاً کافی است چندین نمونه محدود از مجموعه داده آموزشی توسط انسان برچسبدهی شوند و مدل میتواند با این دادههای کم برچسبدار به یادگیری مسئله بپردازد.
رویکرد یادگیری فعال به خوبی فرآیند یادگیری انسان را شبیهسازی میکند. دانشآموزی را در نظر بگیرید که برای یادگیری از معلم خود کمک میگیرد و به حل مشکلات با نظارت نزدیک معلم میپردازد که این حالت معادل آموزش مدل هوش مصنوعی بر روی دادههای برچسبگذاری شده محدود است. سپس، از دانشآموز خواسته میشود تا چندین مسئله جدید را به تنهایی حل کند که این مرحله مشابه با تست مدل بر روی دادههای جدید است.

به علاوه، از دانشآموز درخواست میشود فقط در صورتی که واقعاً در حل مسئله و درک آن با مشکل مواجه شد، از معلم کمک بگیرد که این شرایط مشابه وضعیتی است که مدل یادگیری ماشین برای پیشبینی چند داده محدود به مشکل برمیخورد و از کاربر انسانی میخواهد که برچسب دادهها را مشخص کند. بدین ترتیب، دانشآموز با کمک گرفتن از معلم میتواند مسائل مشابه مرتبط را نیز به راحتی حل کند. مدل هوش مصنوعی نیز میتواند با استفاده از برچسبهای داده که توسط کاربر مشخص شده است، با اطمینان بیشتری به حل مسائل مشابه بپردازد.
کاربرد روش یادگیری فعال در ماشین لرنینگ
کاربردهای مختلفی را میتوان برای روش یادگیری فعال برشماریم که در ادامه این بخش به برخی از پرکاربردترین آنها اشاره خواهیم کرد:
- تشخیص پزشکی: رویکرد یادگیری فعال میتواند در تصمیمگیری درباره دادههای پزشکی از انسان کمک بگیرد. این امر میتواند به کاهش هزینه زمانی و مالی برای تشخیص بیماری مثمرثمر باشد. به عنوان مثال، یک سیستم هوشمند تصویربرداری پزشکی که مبتنی بر رویکرد یادگیری فعال است، میتواند از انسان برای درخواست برچسبدهی به تصاویر پزشکی مبهم کمک بگیرد تا با اطمینان بیشتری برای تصمیمگیری درباره تصاویر پزشکی دیگر عمل کند.
- تشخیص کلاهبرداری: از رویکرد یادگیری فعال میتوان به طور موثر در تشخیص کلاهبرداریهای مالی استفاده کرد. مدلهای هوشمند این رویکرد میتوانند از کاربر کمک بگیرند تا برچسب دادههایی را مشخص کنند که تعیین مشکوک بودن آنها دشوار است. به عنوان مثال، یک شرکت کارت اعتباری میتواند از مدلهای ماشین لرنینگ با رویکرد یادگیری فعال استفاده کند تا الگوهای خرید معمولی مشتریان خود را تشخیص دهد. این امر میتواند به شرکت در تشخیص معاملات کلاهبرداری کمک بهسزایی کند. مدل هوشمند نیز میتواند از انسان برای برچسبزنی موارد دشوار کمک بگیرد تا عملکرد خود را برای تشخیص نمونههای مشکوک مشابه بهتر کند.
- توصیه محصول: روش یادگیری فعال را میتوان در طراحی سیستمهای توصیهگر محصول به کار برد. به عنوان مثال، یک وب سایت تجارت الکترونیکی میتواند از مدل ماشین لرنینگ که مبتنی بر روش یادگیری فعال است، برای برچسبزنی اقلامی استفاده کند که به طور مکرر توسط کاربران با علاقههای مشابه مشاهده یا خریداری میشوند. وب سایت با کمک این ابزار هوشمند توانایی خود را در توصیه محصولات مرتبط به کاربران بهبود میبخشد.
- پردازش زبان طبیعی: از رویکرد یادگیری فعال میتوان برای مسائل حوزه پردازش زبان طبیعی نیز استفاده کرد. مدلهای مبتنی بر این رویکرد میتوانند از انسان برای تعیین برچسب برخی جملات زبان کمک بگیرند. به عنوان مثال، یک سیستم هوشمند تجزیهگر نحوی جملات میتواند از انسان در تعیین نوع برچسب جملاتی استفاده کند که تحلیل آنها دشوار است. این رویکرد به سیستم هوش مصنوعی کمک میکند تا توانایی خود را در درک متن پیچیده و مبهم بهبود بخشد.
- اکتشافات علمی: از روش یادگیری ماشین با رویکرد یادگیری فعال میتوان در اکتشافات علمی بهره گرفت. به عبارتی، این رویکرد میتواند به تمرکز دانشمندان بر زمینههای تحقیقاتی امیدوارکننده کمک کند و سرعت پیشرفت علمی را تسریع بخشد. به عنوان مثال، یک زیستشناس میتواند از مدل هوش مصنوعی با رویکرد یادگیری فعال برای درخواست برچسبزنی ژنها یا پروتئینهای مهم استفاده کند. این سیستم به زیستشناس کمک میکند تا اطلاعات زیستی مهم را شناسایی و توسعه داروهای جدید یا درمانها را تسریع کند.
مزایای روش یادگیری فعال
روش یادگیری فعال دارای مزایای مختلفی است و به همین خاطر از این رویکرد در توسعه پروژههای هوش مصنوعی استفاده میشود. در بخش زیر، به برخی از مهمترین مزیتهای این روش از یادگیری ماشین اشاره میکنیم:
- نیاز کمتر به دادههای برچسبگذاری شده: استفاده از رویکرد یادگیری فعال میتواند به طور قابل توجهی مقدار دادههای برچسبگذاری شده مورد نیاز را برای آموزش یک مدل یادگیری ماشین کاهش دهد. این امر به این دلیل است که مدل فقط برای دادههای مبهم و پیچیده از انسان درخواست کمک برای برچسبزنی میکند که این دادهها همان مواردی هستند که به احتمال زیاد عملکرد آن را بهبود میبخشند.
- بهبود دقت مدل: به کارگیری روش یادگیری فعال میتواند عملکرد و دقت مدل را بهبود دهد زیرا مدل توجه خود را به دادههای دشوارتر متمرکز میکند که این دادهها مواردی هستند که به احتمال زیاد باعث خطای مدل میشوند.
- تعمیمپذیری بیشتر مدل: یادگیری فعال میتواند منجر به افزایش میزان تعمیمپذیری مدل هوش مصنوعی شود و توانایی مدل را برای پیشبینی صحیح درباره دادههای جدید بالا میبرد زیرا مدل از طیف گستردهتری از دادههای اطلاعاتی یاد میگیرد که این امر میتواند به مدل کمک کند تا الگوهایی را که عمومیتر هستند، به درستی تشخیص دهد.
- کاهش هزینه: یادگیری فعال میتواند هزینه کلی توسعه و پیادهسازی یک مدل یادگیری ماشین را کاهش دهد. این امر به این دلیل است که این رویکرد نیاز به برچسبگذاری حجم عظیمی از داده ندارد. از آنجا که یکی از مراحل هزینهبر برای توسعه پروژههای هوش مصنوعی، مرحله آمادهسازی داده است، تهیه دادههای برچسبدار محدود برای مدلهای یادگیری ماشین با رویکرد یادگیری فعال به لحاظ زمانی و مالی مقرون به صرفهتر است.
معایب یادگیری فعال در یادگیری ماشین
همانطور که در بخش قبل گفتیم، روشهای ماشین لرنینگ با رویکرد فعال دارای مزیتهای مهمی هستند و از آنها در پیادهسازی انواع مختلفی از مسائل هوش مصنوعی استفاده میشوند. با این حال، این رویکرد از یادگیری ماشین معایبی نیز دارد که در ادامه به مهمترین آنها اشاره میکنیم:
- پیچیدگی: الگوریتمهای یادگیری فعال پیچیدهتر از الگوریتمهای یادگیری ماشین سنتی هستند که این امر میتواند باعث شود که پیادهسازی آنها دشوارتر شود.
- درگیری انسان: روشهای یادگیری فعال نیاز به دخالت انسان برای برچسبدهی دادهها دارند. بدین ترتیب، باید از افرادی با دانش لازم کمک گرفت که بتوانند درباره برچسب دادهها تحلیل درستی انجام دهند.
- پتانسیل سوگیری: اگر الگوریتمهای یادگیری فعال با دقت طراحی نشوند، دچار سوگیری میشوند زیرا مدل صرفا از دادههای برچسبدار استفاده میکند و اگر برچسبها به درستی تعیین نشده باشند، بر یادگیری مدل تاثیر خواهند داشت.
- کیفیت دادهها: الگوریتمهای یادگیری فعال در مقایسه با الگوریتمهای یادگیری ماشین سنتی نسبت به کیفیت دادهها حساستر هستند. این امر به این دلیل است که مدل فقط از تعداد کمی از دادههای آموزشی برچسبدار یاد میگیرد. بنابراین، وجود هر گونه خطایی در دادهها میتواند تأثیر قابل توجهی بر عملکرد مدل داشته باشد.
۱۲. روش یادگیری آنلاین در ماشین لرنینگ چیست؟
یادگیری ماشینی آنلاین به عنوان یکی از انواع روش های ماشین لرنینگ محسوب میشود که در آن مدل به طور فزاینده از دادهها یاد میگیرد. این نوع یادگیری یک فرآیند پویا است که الگوریتم پیشبینی خود را در طول زمان تنظیم میکند و به مدل اجازه میدهد تا با دادههای جدید تغییر کند. این روش از یادگیری در محیطهایی با دادههای بسیار زیاد که مدام در حال تغییر هستند، بسیار مهم است زیرا میتواند پیشبینیهای به موقع و دقیق ارائه دهد.

در روشهای سنتی یادگیری ماشین یا روشهای «پردازش دستهای» (Batch Processing)، مدل یادگیری ماشین با استفاده از کل مجموعه داده به یکباره آموزش داده میشود. این فرآیند یادگیری اغلب به لحاظ محاسباتی پرهزینه است و این احتمال وجود دارد مدل نتواند تغییرات واقعی را منعکس کند. در مقابل، یادگیری ماشین آنلاین یک داده را در یک زمان پردازش و در حین انجام آن پارامترهای مدل را به روز میکند.
به منظور درک بهتر این دو فرآیند یادگیری ماشین بهتر است از یک مثال ملموس استفاده کنیم. فرض کنید قصد دارید دوچرخهسواری یاد بگیرید. یادگیری انبوه مانند خواندن یک کتاب جامع در مورد دوچرخهسواری قبل از سوار شدن بر دوچرخه است. شما تمام اطلاعات مرتبط با نحوه دوچرخهسواری را جمعآوری و مطالعه کردهاید، اما ممکن است در مسیر جاده، با شرایط مختلف زمین و آب و هوایی، نتوانید در عمل به درستی دوچرخهسواری کنید.
از سوی دیگر، یادگیری آنلاین مانند یادگیری دوچرخهسواری در حین حرکت است که حرکت دوچرخه را با تنظیم تعادل و سرعت رکاب زدن بر اساس وضعیت جاده و جهت باد و سایر عوامل در زمان واقعی سازگار میکنید.

الگوریتمهای یادگیری ماشین آنلاین بر کاهش خطای پیشبینی برای نمونههای بعدی بر اساس دادههای مشاهده شده قبلی تمرکز دارند. برخی از الگوریتمهای پرکاربرد یادگیری آنلاین عبارتاند از: Stochastic Gradient Descent (SGD)، الگوریتمهای Passive-Aggressive و Perceptron.
کاربرد روش های یادگیری ماشین با رویکرد یادگیری آنلاین
روش یادگیری آنلاین در ماشین لرنینگ را میتوان در حوزههای مختلفی استفاده کرد. در ادامه، به برخی از کاربردهای این روش در مسائل دنیای واقعی اشاره میکنیم:
- تشخیص تقلب: یادگیری ماشین آنلاین برای تشخیص تراکنشهای جعلی در سیستمهای مالی استفاده میشود. این کار با پردازش تراکنشهای ورودی در زمان واقعی و به روزرسانی مدل برای تشخیص تقلب انجام میشود.
- پیشنهاد محصول به مشتری: از روش یادگیری ماشین آنلاین میتوان برای توصیه محصولات به کاربران استفاده کرد. این کار با تجزیه و تحلیل سابقه خرید گذشته، بررسی رفتار و جستجوی کاربران انجام میشود. استفاده از این روش میتواند به ارائه توصیههای شخصیتر و مرتبطتر کمک کند و منجر به افزایش رضایت مشتری و میزان فروش شود.
- پردازش زبان طبیعی: یادگیری ماشین آنلاین برای بهبود عملکرد وظایف NLP مانند ترجمه ماشینی و چت باتها استفاده میشود.
- کشف علمی: از مدلهای یادگیری ماشین با رویکرد یادگیری آنلاین برای تسریع کشف علمی با تجزیه و تحلیل مجموعه دادههای بزرگ علمی در زمان واقعی استفاده میشود. این روش یادگیری ماشین میتواند به دانشمندان کمک کند تا الگوها و بینشهای جدیدی را در دادههای خود شناسایی کنند.
- تخصیص منابع: یادگیری ماشین آنلاین برای بهینهسازی تخصیص منابع در برنامههای کاربردی زمان واقعی مانند مدیریت ترافیک و مسیریابی شبکه استفاده میشود. این روش میتواند به بهبود کارایی این سیستمها کمک کند.
- سیستمهای کنترل وضعیت بیمار: دستگاههای پوشیدنی مانند ساعتهای هوشمند به طور پیوسته دادههایی مانند ضربان قلب، الگوهای خواب و موارد مرتبط با وضعیت جسمی بیمار را در لحظه جمعآوری میکنند. با استفاده از یادگیری ماشین آنلاین، این دستگاهها میتوانند ناهنجاریها را تشخیص داده و بر اساس دادههای واقعی، مشکلات سلامتی بیمار را پیشبینی کنند.
مزایای روش یادگیری آنلاین در ماشین لرنینگ
روشهای یادگیری آنلاین در ماشین لرنینگ به دلیل مزیتهای مهمی که دارند، در طراحی بسیاری از برنامهها و سیستمهای هوشمند استفاده میشوند. در ادامه، به برخی از مهمترین مزایای این رویکرد یادگیری ماشین اشاره میکنیم:
- انعطافپذیری: درست مانند یک دوچرخه سوار که در حین حرکت یاد میگیرد چطور به بهترین شکل دوچرخه را براند، یادگیری ماشین آنلاین نیز میتواند با الگوهای جدید دادهها سازگار شود و عملکرد خود را در طول زمان بهبود ببخشد.
- مقیاسپذیری: از آن جایی که یادگیری ماشین آنلاین دادهها را یکی یکی پردازش میکند، به فضای ذخیرهسازی زیادی برای نگهداری انبوه دادهها نیاز ندارد. این امر آن را برای کار با دادههای حجیم مقیاسپذیر میکند.
- پیشبینیهای به موقع: برخلاف روشهای یادگیری ماشین قدیمی که دادهها را به صورت دستهای پردازش میکردند و در زمان اجرا ممکن است اطلاعاتشان قدیمی یا منسوخ شده باشد، یادگیری ماشین آنلاین از اطلاعات دادههای بهروز استفاده میکند که این امر میتواند در بسیاری از کاربردها مانند معاملات سهام و پایش سلامت حیاتی باشد.
- افزایش کارایی: از آن جایی که یادگیری ماشین آنلاین امکان یادگیری و بهروزرسانی پیوسته مدلها را فراهم میکند، میتواند منجر به فرایندهای تصمیمگیری سریعتر و کارآمدتر شود.
معایب روش یادگیری آنلاین در ماشین لرنینگ
روشهای یادگیری آنلاین علاوه بر مزایای مهمی که دارند، دارای معایبی نیز هستند که در ادامه این بخش از مجله فرادرس به آنها پرداخته میشود:
- کاهش دقت و تعمیمپذیری: مدلهای یادگیری آنلاین ممکن است به اندازه مدلهای یادگیری دستهای دقیق نباشند زیرا به طور همزمان به کل مجموعه داده دسترسی ندارند. این امر میتواند منجر به رخداد بیش برازش شود. به بیان دیگر در این روش از یادگیری ماشین، مدل دادههای آموزشی را بیش از حد خوب یاد میگیرد و در زمان تست، به خوبی به دادههای جدید تعمیم نمییابد.
- هزینه محاسباتی بالاتر: مدلهای یادگیری آنلاین به منابع محاسباتی بیشتری نیاز دارند زیرا دائماً در حال یادگیری و بهروزرسانی پارامترهای خود هستند. این امر میتواند برای مسائلی با منابع محاسباتی محدود مشکلساز باشد.
- حساسیت بیشتر به کیفیت دادهها: مدلهای مبتنی بر یادگیری آنلاین در مقایسه با مدلهای یادگیری دستهای نسبت به کیفیت دادهها حساستر هستند. این امر به این دلیل است که آنها دائماً از دادههای جدید یاد میگیرند و اگر دادههای جدید نویزی یا نادرست باشند، باعث تضعیف عملکرد مدل خواهند شد.
- پیچیدهتر شدن پیادهسازی مدل: پیادهسازی الگوریتمهای یادگیری آنلاین در مقایسه با مدلهای یادگیری دستهای پیچیدهتر است زیرا به هنگام استفاده از این مدلها باید به حفظ تعادل میان دقت مدل، تعمیمپذیری و هزینه محاسباتی آن توجه داشت.
۱۳. روش یادگیری انتقال
روش یادگیری انتقال به عنوان یکی دیگر از پرکاربردترین انواع روش های ماشین لرنینگ تلقی میشود که در این روش، دانش یک مدل یادگیری ماشین که از قبل آموزش داده شده است، به یک مدل دیگر منتقل میشود. به عنوان مثال، اگر یک مدل دستهبند سادهای را آموزش دادهاید تا بتواند تصاویر گربه را از تصاویر سایر حیوانات تشخیص دهد، میتوانید از دانشی که مدل شما در طول آموزش خود کسب کرده است، برای تشخیص اشیایی مانند عینک آفتابی استفاده کنید.

با انتقال یادگیری، ما اساساً سعی میکنیم مدل از آنچه در یک مسئله آموخته شده است، برای بهبود تعمیم یک مسئله مرتبط دیگر استفاده کنیم. در این روش، وزنهایی را که یک مدل در مسئله A یاد گرفته است به مدل جدیدی منتقل میکنیم که قرار است برای حل مسئله B مورد استفاده قرار گیرد.
در این نوع یادگیری ماشین، مدل هوش مصنوعی با استفاده از مقدار زیادی داده آموزشی برچسبدار آموزش میبیند و از دانش حاصل شده توسط این مدل، در آموزش یک مدل هوش مصنوعی دیگر استفاده میشود که داده آموزشی زیادی برای یادگیری آن در اختیار نداریم. بدین ترتیب، بجای این که یادگیری مدل هوش مصنوعی با وزنهای تصادفی آغاز شود، روال آموزش مدل با وزنهای مدل اول آغاز میشود.

کاربردهای یادگیری انتقال
یادگیری انتقال را میتوان به عنوان یک روش مهندسی طراحی مدل در نظر گرفت که در سایر روشهای یادگیری ماشین مانند یادگیری فعال کاربرد دارد. به عبارتی، میتوان گفت یادگیری انتقال یک بخش یا حوزه مطالعاتی منحصربهفرد یادگیری ماشین نیست. با این حال، این روش از یادگیری ماشین به دلیل استفاده گسترده از شبکههای عصبی که به مقادیر زیادی داده و توان محاسباتی نیاز دارند، در سالهای اخیر بسیار محبوب شده است. در ادامه، به برخی از مسائلی اشاره میکنیم که در پیادهسازی آنها میتوان از روش یادگیری انتقال استفاده کرد:
- کشف دارو: از رویکرد یادگیری انتقال میتوان برای شناسایی داروی جدید با استفاده از دانش مدلهای دارویی موجود استفاده کرد. به عنوان مثال، یک مدل آموزش دیده بر روی مجموعه دادهای از داروهای شناخته شده میتواند برای پیشبینی مشابه بودن ترکیبات جدید دارویی استفاده شود.
- تشخیص پزشکی: روش یادگیری انتقال را میتوان برای توسعه ابزارهای تشخیص بیماری با استفاده از دانش مدلهای پزشکی موجود استفاده کرد. به عنوان مثال، یک مدل آموزش داده شده بر روی مجموعه دادهای از سوابق بیماران میتواند برای شناسایی الگوهای جدیدی استفاده شود که ممکن است نشان دهنده بیماری باشند.
- تشخیص کلاهبرداری: کاربرد روش یادگیری انتقال را میتوان در بهبود سیستمهای تشخیص کلاهبرداری ملاحظه کرد که بر پایه دانش مدلهای تشخیص کلاهبرداری فعلی طراحی شدهاند. به عنوان مثال، از یک مدل آموزش داده شده بر روی مجموعه داده تراکنشهای جعلی میتوان برای شناسایی الگوهای کلاهبرداری جدید استفاده کرد.
- پردازش زبان طبیعی: رویکرد یادگیری انتقال در بهبود مسائل حوزه پردازش زبان طبیعی (NLP) مانند تجزیه و تحلیل احساسات و ترجمه ماشینی کاربرد بسیار دارد. به عنوان مثال، از یک مدل آموزش دیده بر روی دادههای متنی و برچسبدار میتوان برای شناسایی الگوهای احساس در متن جدید استفاده کرد.
- سیستمهای توصیهگر: رویکرد یادگیری انتقال میتواند برای بهبود عملکرد سیستمهای توصیهگر با استفاده از دانش سیستمهای توصیهگر فعلی به کار رود. به عنوان مثال، یک مدل آموزش دیده بر روی مجموعه دادهای از ترجیحات کاربر و رتبهبندی محصول را میتوان برای شناسایی محصولات جدیدی به کار برد که ممکن است برای کاربران جدید جالب باشند.
مزایای روش یادگیری انتقال در ماشین لرنینگ
به دلیل مزیتهای مهمی که روش یادگیری انتقال دارد، از آن در حل بسیاری از مسائل یادگیری ماشین استفاده میشود. در فهرست زیر، به برخی از مهمترین مزایای این رویکرد یادگیری ماشین اشاره میکنیم:
- نیاز کمتر به تهیه داده آموزشی با حجم زیاد: رویکرد یادگیری انتقال میتواند برای حل مسائل با دادههای آموزشی محدود مناسب باشد زیرا دانش مدلهای از پیش آموزش داده شده را میتوان برای کمک به مدل جدید با داده آموزشی کمتر استفاده کرد. این ویژگی میتواند در بسیاری از کاربردها، مانند تشخیص پزشکی و تشخیص کلاهبرداری، یک مزیت بزرگ محسوب شود.
- بهبود عملکرد مدل: رویکرد یادگیری انتقال را میتوان برای بهبود عملکرد مدلهای موجود به ویژه در مسائلی با الگوهای پیچیده استفاده کرد.
- قابلیت انتقال دانش: یادگیری انتقال میتواند برای انتقال دانش از یک مدل به مدل دیگر استفاده شود. این قابلیت میتواند برای مسائلی که به یکدیگر مرتبط هستند، مفید باشد. به عنوان مثال، از این رویکرد یادگیری میتوان در مسائل پردازش زبان طبیعی مانند تجزیه و تحلیل احساسات و ترجمه ماشینی استفاده کرد.
- قابلیت مقیاسپذیری: با رویکرد یادگیری انتقال میتوان از مدلهای موجود در سایر مسائل استفاده کرد بدون آن که نیاز باشد مدل آموزش داده شده را مجدد برای مسئله جدید آموزش داد.
معایب روش یادگیری انتقال در ماشین لرنینگ
با این که روش یادگیری انتقال به عنوان یکی از پرکاربردترین انواع روش های ماشین لرنینگ محسوب میشود و مزایای مهمی دارد، اما میتوان معایبی را نیز برای آن در نظر گرفت که در ادامه به آنها اشاره میکنیم:
- عدم سازگاری دادهها: روش یادگیری انتقال ممکن است در مسائلی که دارای منابع دادهای با توزیعهای بسیار متفاوتی هستند، کاربردی نباشد زیرا ممکن است مدل نتواند به طور موثر از دادههای جدید یاد بگیرد.
- رخداد بیش برازش: رویکرد یادگیری انتقال ممکن است منجر به رخداد بیش برازش شود اگر مدل از پیش آموزش داده شده با مدل جدید مرتبط نباشد زیرا مدل از پیش آموز داده شده ممکن است به جای الگوهای مورد نیاز مدل جدید، دادههای نویزی آن را زیاد کند.
- تغییر دامنه یادگیری: اگر بین مدل از پیش آموزش داده شده و مدل جدید تغییر دامنه وجود داشته باشد، استفاده از روش یادگیری انتقال ممکن است موثر نباشد زیرا مدل موجود ممکن است نتواند به دامنه جدید تعمیم یابد.
- احتمال رخداد سوگیری: چنانچه مدل آموزش داده شده از قبل را با دادههای سوگیری آموزش داده باشیم، با روش یادگیری انتقال اطلاعات دادههای سوگیری به مدل جدید منتقل میشوند.
۱۴. روش یادگیری جمعی در ماشین لرنینگ چیست؟
یادگیری جمعی از دیگر روش های یادگیری ماشین است که دقت و عملکرد نهایی مدل را با در نظر گرفتن چندین مدل بهبود میبخشد. هدف این روش از یادگیری ماشین کاهش خطاها یا سوگیریهایی است که احتمال دارد در هر یک از مدلهای ماشین لرنینگ وجود داشته باشند.
مفهوم اصلی یادگیری جمعی این است که خروجیهای مدلهای مختلف یادگیری ماشین را برای ایجاد پیشبینی دقیقتر ترکیب کنیم. با در نظر گرفتن چندین دیدگاه و استفاده از نقاط قوت مدلهای مختلف، یادگیری جمعی عملکرد کلی سیستم هوش مصنوعی را بهبود میبخشد. این رویکرد نه تنها دقت مدل را بالا میبرد، بلکه مدل میتواند درباره دادههای مبهم نیز بهتر تصمیم بگیرد.

به منظور درک روال یادگیری جمعی میتوان از یک مثال ملموس در دنیای واقعی کمک گرفت. فرض کنید شما یک کارگردان فیلم هستید و یک فیلم کوتاه درباره یک موضوع بسیار مهم و جالب ساختهاید. اکنون، میخواهید قبل از انتشار آن، بازخورد مقدماتی (امتیاز) فیلم را بگیرید. چه روشهایی برای انجام این کار وجود دارد؟ سه حالت را میتوان برای گرفتن بازخورد مقدماتی درباره فیلم در نظر بگیریم:
- حالت اول: ممکن است از یکی از دوستان خود برای ارزیابی فیلم درخواست کمک کنید. ممکن است فردی را که انتخاب میکنید، شما را بسیار دوست داشته باشد و نظر واقعی و انتقادات خود را به شما اعلام نکند تا شما ناراحت نشوید.
- حالت دوم: میتوانید از ۵ نفر از همکاران خود بخواهید تا درباره فیلم شما نظر بدهند. این حالت ایده بهتری است زیرا ممکن است بازخوردهای صادقانهتری را از سوی این افراد دریافت کنید. اما هنوز یک مشکل وجود دارد و آن هم این است که این ۵ نفر ممکن است نظر تخصصی درباره موضوع فیلم شما ارائه ندهند. مطمئناً این افراد سینماتوگرافی، فیلمبرداری یا صدا را درک میکنند اما در عین حال ممکن است بهترین داور برای فیلم شما محسوب نشوند.
- حالت سوم: میتوان از ۵۰ نفر درخواست کنید تا فیلم شما را ارزیابی کنند. بعضی از این افراد ممکن است دوستان و همکاران شما و برخی از آنها میتوانند افراد غریبه باشند. در این حالت، بازخوردها عمومیتر و متنوعتر خواهند بود زیرا اکنون شما نظرات افراد مختلف را با دیدگاهها و ایدههای فنی مختلف دریافت میکنید و به نظر میرسد که این رویکرد برای گرفتن بازخوردهای صادقانه نسبت به موارد قبلی بهتر نتیجه میدهد.

با در نظر گرفتن این سه حالت میتوان نتیجه گرفت که گروهی از افراد با نظرات و دانش تخصصی مختلف میتوانند درباره موضوعی خاص تصمیمات بهتری بگیرند. این مثال، یک نمونه واقعی از کاربرد روش جمعی است که در این رویکرد از یادگیری ماشین، به جای تکیه بر تصمیمگیری یک مدل هوش مصنوعی، میتوان از خروجیهای چندین مدل استفاده کرد تا تصمیم بهتری درباره مسئله گرفته شود.
کاربرد روش یادگیری جمعی
از روش یادگیری جمعی میتوان برای حل مسائل مختلف هوش مصنوعی استفاده کرد که در ادامه به برخی از کاربردهای این روش اشاره میکنیم:
- مسائل دستهبندی: از رویکرد یادگیری جمعی میتوان در مسائل دستهبندی نظیر فیلتر کردن هرزنامه، تشخیص بیماری در تصاویر پزشکی و تشخیص کلاهبرداری استفاده کرد. این رویکرد یادگیری با ترکیب نقاط قوت مدلهای مختلف یادگیری ماشین میتواند عملکرد بهتری نسبت به مدلهای فردی داشته باشد. همچنین، روش یادگیری جمعی در هنگام مواجهه شدن با دادههای نویزی بهتر تصمیم میگیرد.
- مسائل رگرسیون: یادگیری جمعی را میتوان برای حل مشکلات رگرسیون مانند پیشبینی قیمت سهام، پیشبینی قیمت خانه و تخمین ارزش عمر مشتری به کار برد. روشهای یادگیری جمعی میتوانند به کاهش واریانس و بهبود عملکرد کلی مدلهای رگرسیون کمک کنند به خصوص زمانی که روابط زیربنایی در دادهها پیچیده یا غیرخطی هستند.
- شناسایی ناهنجاری: روشهای یادگیری جمعی برای شناسایی ناهنجاریها یا موارد غیرمعمول در دادهها مناسب هستند و میتوانند برای تشخیص کلاهبرداری و فعالیتهای مشکوک، نظارت بر عملکرد سیستم و کاربردهای کنترل کیفیت موثر باشند. به بیان دیگر، با ترکیب مدلهای گوناگون یادگیری ماشین میتوان جنبههای مختلف داده را ثبت کرد تا به طور موثر بین الگوهای طبیعی و غیر طبیعی دادهها تمایز قائل شد.
- سیستمهای توصیهگر: یادگیری جمعی نقش مهمی در بهبود دقت و عملکرد سیستمهای توصیهگری دارد که در تجارت الکترونیکی، رسانههای اجتماعی و پلتفرمهای محتوا مورد استفاده قرار میگیرند. رویکرد یادگیری جمعی با ترکیب چندین مدل میتواند توصیههای شخصیتری ارائه کند و در عین حال تأثیر سوگیریها یا محدودیتهای فردی الگوریتمهای ماشین لرنینگ را کاهش دهد.
- تشخیص تصویر و گفتار: از یادگیری جمعی میتوان در مسائل تشخیص تصویر و گفتار مانند تشخیص چهره، تشخیص شی و تبدیل گفتار به متن استفاده کرد. روشهای مبتنی بر این رویکرد با ترکیب مدلهای مختلف یادگیری ماشین با معماریها و تکنیکهای متفاوت استخراج ویژگی میتوانند در این زمینههای چالشبرانگیز دقت بالاتری را به دست آورند.
- نگهداری پیشگیرانه: از روشهای یادگیری جمعی میتوان در کاربردهای نگهداری پیشگیرانه به منظور شناسایی خرابیهای احتمالی تجهیزات قبل از وقوع اتفاق، کاهش زمان خرابی و بهبود مدیریت کلی داراییها استفاده کرد. با تجزیه و تحلیل دادههای تاریخی و اطلاعات حسگرها، مدلهای یادگیری جمعی میتوانند احتمال خرابی تجهیزات را پیشبینی کنند و امکان مداخله به موقع و نگهداری پیشگیرانه را فراهم آورند.
- ارزیابی ریسک و تشخیص کلاهبرداری: یادگیری جمعی نقش حیاتی در سیستمهای ارزیابی ریسک و تشخیص کلاهبرداری مانند تشخیص جعل کارت اعتباری و پیشگیری از جعل بیمه دارد. روشهای یادگیری جمعی با ترکیب مدلهای مختلف یادگیری ماشین میتوانند ارزیابیهای جامعتر و دقیقتری از ریسکهای احتمالی ارائه دهند.
- بازاریابی و تبلیغات هدفمند: یادگیری جمعی در کمپینهای بازاریابی و تبلیغات هدفمند برای شخصیسازی تجربه کاربر و بهبود اثربخشی تلاشهای بازاریابی استفاده میشود. با تجزیه و تحلیل رفتار و ترجیحات کاربر، مدلهای یادگیری جمعی میتوانند محتوای تبلیغاتی مرتبط با سلایق و نیاز هر فرد را شناسایی کنند و تجربه کاربر را بهبود بخشند.
- کشف علمی و انجام پژوهشهای مختلف: یادگیری جمعی در یادگیری ماشین به طور فزایندهای در تحقیقات علمی و تجزیه و تحلیل دادهها استفاده میشود و به دانشمندان کمک میکند تا الگوها، همبستگیها و ناهنجاریها را در مجموعه دادههای بزرگ شناسایی کنند. این رویکرد یادگیری با ترکیب مدلها و روشهای آماری مختلف میتواند یافتههای جامعتر و آموزندهتری را ارائه دهد که میتواند منجر به کشفیات جدید و پیشرفت در حوزههای مختلف شود.
- پیشبینی و معامله بازار سهام: از یادگیری جمعی میتوان در الگوریتمهای پیشبینی و معامله بازار سهام برای شناسایی فرصتهای معاملاتی احتمالی و بهبود استراتژیهای سرمایهگذاری استفاده کرد. به عبارتی، با ترکیب مدلهای یادگیری ماشین مختلف میتوان به بینش جامعتر و دقیقتری از روندها و تغییرات قیمت بازار دست پیدا کرد.
مزایای روش یادگیری جمعی
یادگیری جمعی به عنوان یکی از روشهای قدرتمند در یادگیری ماشین محسوب میشود و با مزایای متعددی که دارد، از آن میتوان در مسائل مختلف هوش مصنوعی استفاده کرد. در ادامه، به برخی از مهمترین مزیتهای این روش یادگیری ماشین میپردازیم:
- افزایش دقت مدل: مدلهای مبتنی بر یادگیری جمعی اغلب از مدلهای تکی بهتر عمل میکنند به خصوص زمانی که با مسائلی سر و کار داشته باشیم که دادههای آموزشی آماده شده پیچیده یا نویزی باشند. با ترکیب نقاط قوت مدلهای یادگیری ماشین مختلف، میتوان نقاط ضعف هر یک از مدلها را جبران کرد و دقت کلی بالاتری را به دست آورد.
- کاهش احتمال رخداد بیش برازش و کم برازش: روشهای یادگیری جمعی در تعادل بین سوگیری و واریانس بهتر عمل میکنند. با ترکیب مدلهای یادگیری ماشین مختلف میتوان سوگیری و واریانس را به حداقل رساند که این امر منجر به پیشبینیهای پایدارتر و تعمیمپذیرتر شدن مدل میشود.
- تصمیمگیری بهتر درباره دادههای نویزی: مدلهای یادگیری جمعی به طور کلی نسبت به مدلهای تکی ماشین لرنینگ درباره دادههای نویزی و دادههای پرت بهتر تصمیم میگیرند زیرا ترکیب پیشبینیهای چندین مدل میتواند خطاهای هر یک از مدلها و سوگیریها را جبران کند.
- انعطافپذیری: روشهای یادگیری جمعی را میتوان در انواع مختلفی از مسائل یادگیری ماشین از جمله طبقهبندی، رگرسیون، خوشهبندی و تشخیص ناهنجاری به کار برد. با انتخاب مدلهای پایه و روشهای یادگیری جمعی مناسب میتوان به طور موثر انواع مختلف دادهها و مشکلات را مدیریت کرد.
معایب روش یادگیری جمعی
علیرغم این که روشهای یادگیری جمعی مزیتهای مهمی در حل مسائل یادگیری ماشین دارند، معایبی را نیز میتوان برای آنها برشمرد که در ادامه به توضیح آنها میپردازیم:
- قابلیت تفسیرپذیری: تفسیر مدلهای یادگیری جمعی دشوارتر از مدلهای تکی یادگیری ماشین است و همین امر میتواند درک الگوها و روابط زیربنایی در دادهها را مختل کند.
- پیچیدگی محاسباتی: آموزش روشهای یادگیری جمعی به لحاظ بار محاسباتی سنگینتر هستند و به زمان بیشتری برای آموزش نیاز دارند. آموزش چندین مدل و همچنین ترکیب پیشبینیهای آنها پیچیدگی محاسبات و نیازهای حافظه سیستم را افزایش میدهد.
- انتخاب نامناسب مدلهای پایه: انتخاب مناسب مدلهای پایه و روشهای یادگیری جمعی برای دستیابی به عملکرد بهینه مهم است و انتخاب مدلهای نامناسب یا روش اشتباه یادگیری جمعی میتواند منجر به کاهش دقت و افزایش میزان احتمال رخداد بیش برازش شود.
- تنظیم پارامترها: تنظیم پارامترهای مدلهای یادگیری جمعی میتواند چالشبرانگیزتر از مدلهای تکی باشد. تعامل بین چندین مدل و فرآیند تجمیع، یافتن تنظیمات بهینه پارامترها را دشوارتر میکند.
نحوه یادگیری ماشین لرنینگ با فرادرس
اگر مطلب را تا اینجا مطالعه کرده باشید، به خوبی میدانید که انواع روش های ماشین لرنینگ چیست و چطور میتوان هریک از این روشها را بررسی و پیادهسازی کرد. با وجود این، یادگیری هریک از آموزشهای بالا ممکن است به صرف زمان و هزینه بسیار زیادی نیاز داشته باشد. اگر میخواهید ماشین لرنینگ را با صرف هزینهای معقول و در خانه یا محل کار یاد بگیرید، پیشنهاد میکنیم از مجموعه فیلمهای آموزش داده کاوی و یادگیری ماشین فرادرس استفاده کنید که لینک آن در زیر آورده شده است.
جمعبندی
امروزه، بسیاری از امور روزانه انسان با استفاده از هوش مصنوعی و زیر شاخههای اصلی آن، یعنی یادگیری ماشین و یادگیری عمیق، به طور سادهتر انجام میشوند و ابزارها و دستاوردهای این حوزه تحولات عظیمی را در سبک زندگی انسان به وجود آوردهاند. یادگیری ماشین با ارائه الگوریتمها و روشهای مختلف ریاضیاتی این امکان را به کامپیوتر میدهد تا به طور خودکار به انجام امور مختلف بپردازند و با یادگیری از دادهها و تجربیات قبلی خود، عملکرد خود را در انجام کارها بهبود بخشند. برای الگوریتمهای یادگیری ماشین میتوان بر اساس عوامل مختلفی از جمله نوع داده آموزشی مورد نیاز برای یادگیری مدل، نحوه یادگیری و معماری مدل، رویکردهای یادگیری مختلفی تعریف کرد. در این مطلب از مجله فرادرس، به معرفی انواع روش های ماشین لرنینگ پرداختیم و ویژگیها و کاربردهای آنها را شرح دادیم تا علاقهمندان به این حوزه بتوانند به سادگی با نحوه یادگیری و عملکرد مدلهای یادگیری ماشین آشنا شوند.









