



الگوریتم های یادگیری ماشین که باید بشناسید – ۱۰ الگوریتم شاخص ۲۰۲۳
«یادگیری ماشین» (Machine Learning) به عنوان یکی از شاخههای مهم حوزه «هوش مصنوعی» (Artificial Intelligence) محسوب میشود که در سالهای اخیر توجه بسیاری از پژوهشگران اکثر رشتهها را به خود جلب کرده است. به عبارتی، کاربرد این حیطه از علوم کامپیوتر را میتوان در دستاوردهای مختلف بشر مشاهده کرد. یادگیری ماشین شامل الگوریتمهای مختلفی است که سیستمهای کامپیوتری با کمک آنها میتوانند بدون نیاز به دخالت انسان و بهطور خودکار به حل مسائل مختلف بپردازند. در مطلب حاضر، قصد داریم به معرفی پرکاربردترین الگوریتم های یادگیری ماشین بپردازیم و مهمترین زبانهای برنامه نویسی این حوزه را به علاقهمندان آن معرفی کنیم.
- میآموزید یادگیری ماشین چگونه مسائل را بهصورت خودکار حل میکند.
- انواع رویکردهای یادگیری ماشین و تفاوتهای اصلی آنها را خواهید آموخت.
- روشهای طبقهبندی، رگرسیون، خوشهبندی و کشف الگو را یاد خواهید گرفت.
- معیارهای انتخاب الگوریتم مناسب برای هر مسئله را بررسی میکنید.
- زبانهای برنامهنویسی یادگیری ماشین و کاربردهای آنها را میآموزید.
- یاد خواهید گرفت انتخاب مدل و ابزار مناسب چگونه به موفقیت پروژه کمک میکند.




مقدمه ای کوتاه بر یادگیری ماشین
یادگیری ماشین (ماشین لرنینگ) به عنوان یکی از زیر شاخههای حوزه هوش مصنوعی محسوب میشود. پژوهشهای یادگیری ماشین روی نحوه آموزش ماشین و سیستمهای کامپیوتری تمرکز دارند تا مسئلهای خاص را یاد بگیرند و سپس همانند انسان درباره آن مسئله به تصمیمگیری بپردازند.
به عبارتی، یادگیری ماشین شامل مجموعهای از الگوریتمهای مختلف یادگیری است که با شناسایی الگوهای موجود در دادهها، سعی در بالا بردن دقت عملکرد خود دارند تا بتوانند درباره دادههای جدید درست تصمیم بگیرند.

الگوریتم های یادگیری ماشین متنوع هستند و هر یک از آنها ویژگیهای منحصربفردی دارند. با این حال، میتوان این الگوریتمها را بر اساس رویکرد یادگیریشان، به انواع مختلفی تقسیمبندی کرد که در ادامه به توضیح آنها خواهیم پرداخت.
الگوریتم یادگیری ماشین چیست ؟
الگوریتم های یادگیری ماشین به مجموعهای از مفاهیم ریاضی اطلاق میشوند که میتوانند ماشین را قادر بسازند مسئلهای خاص را با تحلیل و بررسی مجموعهای از دادهها یاد بگیرند. هر الگوریتم، دارای دستورات، ساختار و مراحل منحصربفردی است که بر اساس آنها به دستهبندی اطلاعات میپردازد و الگوهای موجود در دادهها را شناسایی میکند.
الگوریتم های یادگیری ماشین در زمان یادگیری با دریافت دادههای آموزشی، الگوهای جدید را شناسایی میکنند و عملکرد خود را بر اساس خروجیهای خود بهبود میدهند. به عبارت دیگر، این الگوریتمها با دریافت داده جدید آموزشی، هوشمندتر از قبل میشوند.
بر اساس رویکردهای یادگیری، الگوریتم های یادگیری ماشین را میتوان به چهار نوع تقسیم کرد که در ادامه به آنها اشاره شده است:
- الگوریتم های یادگیری ماشین با رویکرد «یادگیری نظارت شده» (Supervised Learning)
- الگوریتم هایی با رویکرد «یادگیری نظارت نشده» (Unsupervised Learning)
- الگوریتم های یادگیری ماشین با رویکرد «نیمه نظارت شده» (Semi-Supervised Learning)
- الگوریتم های «یادگیری تقویتی» (Reinforcement Learning)

در ادامه مطلب حاضر، به توضیح هر یک از رویکردهای یادگیری الگوریتم های یادگیری ماشین پرداخته میشود.
رویکرد یادگیری نظارت شده در الگوریتم های یادگیری ماشین
در مسائلی که دادههای آموزشی دارای برچسب هستند، از الگوریتم های یادگیری ماشینی استفاده میشوند که از رویکرد یادگیری نظارت شده تبعیت میکنند. چنین مسائلی را میتوان به دو دسته «دستهبندی» (Classification) و «رگرسیون» (Regression) تقسیم کرد.
در مسائل دستهبندی، نوع خروجیهای مدل از قبل مشخص است و این خروجیها، تعداد محدودی دارند. به عنوان مثال، فرض کنید مجموعه دادهای از وضعیت هوای آفتابی و برفی ده سال اخیر شهرتان را با توجه به نوع فصل، دمای هوا و صاف یا ابری بودن آسمان در اختیار دارید و میخواهید مدلی را آموزش دهید که آفتابی و برفی بودن روز آینده را پیشبینی کند.
این مسئله از نوع مسائل دستهبندی است، زیرا دادههای آموزشی دارای دو برچسب آفتابی و برفی هستند و از الگوریتم های یادگیری ماشین با رویکرد نظارت شده برای پیادهسازی آن استفاده میشود.

در مسائل رگرسیون نیز همانند مسائل دستهبندی، دادههای آموزشی دارای برچسبی هستند که این برچسب مقدار «هدفی» (Target) را مشخص میکند که مدل سعی دارد آن را یاد بگیرد. با این حال، تعداد این برچسبها مانند مسائل دستهبندی، محدود نیستند.
به عنوان مثال، مسئلهای نظیر پیشبینی میزان دمای هوا را در نظر بگیرید. با توجه به شرایط آب و هوا و در نظر گرفتن ویژگیهای مختلفی مانند نوع فصل و صاف یا ابری بودن آسمان، وزش باد و سایر موارد میتوان مقدار دمای مختلفی برای هر روز سال در نظر گرفت.
بنابراین، دمای هوا به عنوان مقادیر هدف شامل رنج متغیری از اعداد مختلف است و بازه محدودی ندارد. بدین ترتیب، چنین مسائلی جزء مسائل رگرسیون هستند و از الگوریتم های یادگیری ماشین با رویکرد نظارت شده برای مدلسازی آنها استفاده میشوند.
الگوریتم های ماشین لرنینگ با رویکرد یادگیری نظارت نشده چه ویژگی هایی دارند ؟
زمانی که برای پیادهسازی مسئلهای خاص، دادههای آموزشی بدون برچسب در اختیار داشته باشیم، باید از الگوریتم های یادگیری ماشین با رویکرد نظارت نشده استفاده کنیم. این نوع از الگوریتمها بر اساس شباهت دادهها به یکدیگر، آنها را در چندین خوشه مجزا قرار میدهند. بدین ترتیب، دادههای هر خوشه به یکدیگر شباهت زیادی دارند و از دادههای سایر خوشهها متفاوت هستند.
به عنوان مثال، در نظر بگیرید حجم زیادی از متون مختلف در اختیار دارید و میخواهید آنها را به لحاظ شباهت محتوایی تفکیک کنید. به عبارتی، در چنین مسئلهای انتظار داریم در نهایت متون علمی، ورزشی، ادبی و هر نوع سبک نوشتاری موجود در این متون، در خوشههای مجزا قرار گیرند. در این حالت، میتوان از الگوریتم های یادگیری ماشین با رویکرد نظارت نشده استفاده کرد که بر اساس شباهت ساختار متن، واژگان به کار رفته در آنها و معنا، متون مشابه را در خوشه مجزا قرار میدهند.

الگوریتم های یادگیری ماشین با رویکرد نیمه نظارت شده
رویکرد یادگیری نیمه نظارت شده در یادگیری ماشین، تلفیقی از دو رویکرد یادگیری نظارت نشده و یادگیری نظارت شده است. به عبارتی، در این رویکرد، بخشی از دادههای آموزشی دارای برچسب هستند و سایر دادههای آموزشی برچسب ندارند و هدف این است تا برچسب دادههای بدون برچسب بر پایه اطلاعات حاصل از دادههای برچسبدار مشخص شوند.

از الگوریتمهایی با رویکرد نیمه نظارت شده در مسائلی استفاده میشود که به حجم زیادی از داده آموزشی احتیاج دارند و آمادهسازی آنها زمانبر است. دستهبندی محتویات وبسایتها را میتوان از جمله مسائلی تعریف کرد که از چنین رویکردی برای پیادهسازی آن استفاده میشود.
تعداد صفحات وب و تعیین برچسب در هر یک از صفحات کار بسیار زمانبری است. بدین ترتیب، میتوان برای حل این مسئله از رویکرد نیمه نظارت شده بهره گرفت و تنها برچسب بخشی از صفحات را تعیین کرد و باقی صفحات بر اساس اطلاعات استخراج شده از صفحات (محتویات) برچسبدار، برچسبدهی شوند.
رویکرد یادگیری تقویتی در الگوریتم های یادگیری ماشین چیست ؟
رویکرد یادگیری تقویتی در یادگیری ماشین از سه رویکرد قبلی متفاوت است. در این رویکرد، خروجی مدل به عنوان معیاری برای تصمیمگیری در مورد گام بعدی محسوب میشود.
به بیان دیگر، الگوریتم های یادگیری ماشین با رویکرد تقویتی از خروجیهای قبلی خود و بازخوردهایی که در هر مرحله دریافت میکنند، به عنوان معیاری برای تصمیمگیری در مرحله بعدی استفاده میکنند. سیستمهای مبتنی بر یادگیری تقویتی در حین یادگیری انتخابهای درست و غلط را بدون دخالت انسان یاد میگیرند.

خودروهای خودران یکی از سیستمهای هوشمندی هستند که در آنها از یادگیری تقویتی استفاده میشود و هدف در آنها، رعایت کردن قوانین راهنمایی و رانندگی و به مقصد رساندن مسافر در امنیت کامل است. این ماشینها با استفاده از رویکرد تقویتی از تجربههای حاصل شده یاد میگیرند که در چه مواقعی از سرعت خود بکاهند و در چه زمان و در چه مکان توقف داشته باشند.
انواع الگوریتم های یادگیری ماشین کدامند ؟
در بخشهای پیشین مطلب حاضر به تعریف یادگیری ماشین و انواع رویکردهای یادگیری الگوریتمهای آن پرداخته شد. در این بخش، به معرفی پرکاربردترین و مهمترین الگوریتم های یادگیری ماشین خواهیم پرداخت و کاربردهای آنها مورد بررسی قرار خواهند گرفت. در ادامه، فهرستی از این الگوریتمها ملاحظه میشود.
- مدل «رگرسیون خطی» (Linear Regression)
- «رگرسیون لجستیک» (Logistic Regression)
- مدل «آنالیز تشخیص خطی» (Linear Discriminant Analysis | LDA)
- «درخت تصمیم» (Decision Tree)
- مدل «ماشین بردار پشتیبان» (Support Vector Machine | SVM)
- «بیز ساده | نایو بیز» (Naïve Bayes)
- «k تا نزدیکترین همسایه» (K Nearest Neighbors | KNN)
- «جنگل تصادفی» (Random Forest)
- K-means
- الگوریتم «اپریوری» (Apriori)
در ادامه، به توضیح هر یک از ویژگیها و کاربردهای الگوریتم های یادگیری ماشین ذکر شده در فهرست بالا پرداخته شده است.
الگوریتم یادگیری ماشین رگرسیون خطی چیست ؟
رگرسیون خطی به عنوان یکی از الگوریتم های یادگیری ماشین با رویکرد یادگیری نظارت شده محسوب میشود که رابطه بین متغیر ورودی (متغیر مستقل) و مقدار خروجی (متغیر وابسته) را تعیین میکند. به منظور درک بهتر عملکرد این الگوریتم میتوان از مثال سادهای استفاده کرد.
فرض کنید قصد دارید تعدادی بطری پلاستیکی با اندازههای متفاوت را بر اساس وزن آنها در قفسههای جداگانه قرار دهید. در این مسئله، فرض بر این است که اطلاعاتی از وزنهای بطریها در اختیار نداریم و باید وزن آنها را بر اساس تحلیل ظاهری بطریها مانند ارتفاع و بُعد حدس بزنیم. به بیان دیگر، در چنین مسئلهای به دنبال این هستیم که بر اساس ترکیب خطی متغیرهای ارتفاع و ابعاد، بطریها را در ردیفهای جداگانه قرار دهیم.

الگوریتم رگرسیون خطی رابطه بین متغیرهای مستقل (متغیرهای ارتفاع و ابعاد) و متغیر وابسته (ردیف قفسهها) را با تعیین یک خط در فضای مختصات مشخص میکند. این مدل از فرمول زیر برای پیدا کردن خطی استفاده میکند که بر روی دادههای آموزشی منطبق میشود و به بهترین نحو، رابطه میان متغیر مستقل و متغیر وابسته را نشان میدهد.
[y = mx + b]
در فرمول بالا، چهار متغیر فهرست شده در زیر استفاده شدهاند:
- متغیر y: متغیر وابسته است که خروجی مدل را نشان میدهد.
- متغیر m: شیب خط را مشخص میکند.
- x: متغیر مستقلی است که ورودی مدل را تعیین میکند.
- b: مقدار عرض از مبدا محور خط را نشان میدهد.
مدل رگرسیون لجستیک چیست ؟
مدل رگرسیون لجستیک به عنوان یکی از الگوریتم های یادگیری ماشین شناخته میشود که آن را میتوان برای دستهبندی دادهها در دو کلاس به کار برد.

این مدل همانند الگوریتم رگرسیون خطی، با تبعیت از رویکرد یادگیری نظارت شده، به دنبال پیدا کردن وزنهایی برای ویژگیهای (دادههای) ورودی است تا بتواند با پیدا کردن خطی، دادهها را در دو دسته از هم تفکیک کند. لازم به ذکر است که این مدل بر خلاف الگوریتم رگرسیون خطی، از تابع غیر خطی برای تبدیل مقدار خروجی در بازه صفر تا یک استفاده میکند.
منحنی تابع رگرسیون لجستیک مشابه حرف S است که پس از تغییر مقدار خروجی به بازه صفر تا یک، مقدار ۰.۵ به عنوان مرز بین دو کلاس مشخص میشود. همانند مدل رگرسیون خطی، در مدل رگرسیون لجستیک نیز بهتر است ویژگیهای غیر مرتبط را برای آموزش مدل حذف کنید تا مدل رابطه بین دادههای ورودی و مقدار خروجی را بهتر یاد بگیرد.

کاربردهای مدل رگرسیون لجستیک را میتوان در مسائلی ملاحظه کرد که قصد داریم دادهها را در دو دسته مجزا جای دهیم. مسائلی نظیر پیشبینی وقوع بارندگی، پیشبینی بردن کاندیدای ریاست جمهوری در انتخابات و تحلیل احساسات دو کلاسه متون میتوانند به عنوان مسائلی تلقی شوند که میتوان آنها را با الگوریتم رگرسیون لجستیک پیادهسازی کرد.
مدل آنالیز تشخیص خطی
یکی دیگر از الگوریتم های یادگیری ماشین با رویکرد نظارت شده، مدل آنالیز تشخیص خطی است که از آن برای مسائل دستهبندی ماشین لرنینگ استفاده میشود. این مدل به دنبال پیدا کردن ترکیب خطی ویژگیهایی است که کلاس دادهها را به بهترین نحو از یکدیگر تفکیک کند. بر خلاف مدل رگرسیون لجستیک که برای دستهبندی دو کلاس استفاده میشود، از مدل آنالیز تشخیص خطی میتوان برای دستهبندی دادهها در چندین گروه استفاده کرد.
مدل آنالیز تشخیص خطی را میتوان به عنوان یک مدل کاهش بعد نیز محسوب کرد زیرا دادههای ورودی را به فضایی با ابعاد کمتر منتقل میکند تا مجزا کردن دستههای دادهها بهتر انجام شود. این مدل در پی یافتن تفکیککنندههایی (خطوطی) است تا مقدار نسبت واریانس بین کلاسها به واریانس درون کلاسها را به بیشترین حد ممکن برسانند.
مدل آنالیز تشخیص خطی به منظور انجام دستهبندی دادهها، فرضهایی را در نظر میگیرد. به عنوان مثال، فرض این مدل بر این است که توزیع آماری دادهها از نوع «توزیع گاوسی» (Gaussian Distribution) است و مقدار کواریانس کلاسها با یکدیگر برابر هستند. بهعلاوه، این مدل بهطور پیشفرض در نظر میگیرد که دادهها را میتوان بهصورت خطی از یکدیگر تفکیک کرد.
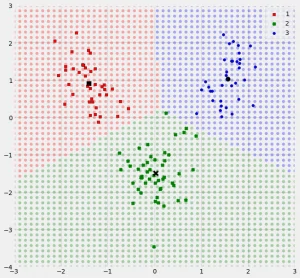
با این که مدل آنالیز تشخیص خطی، الگوریتم سادهای است که از آن میتوان برای دستهبندی دادهها در چند گروه مختلف استفاده کرد، این مدل دارای معایبی نیز است. همانطور که گفته شد، الگوریتم آنالیز تشخیص خطی فرض را بر این میگیرد که دادهها دارای توزیع گاوسی هستند. چنین فرضی برای تمامی مسائل صادق نیست و ممکن است مسئله تعریف شده دارای دادههایی با توزیعهایی غیر از توزیع گاوسی باشند.
بهعلاوه، فرض یکسان بودن مقادیر کواریانس کلاسها هم ممکن است برای تمامی مسائل دستهبندی صدق نکند. همچنین، مسائلی از نوع دستهبندی وجود دارند که دادههای آنها را نمیتوان بهصورت خطی از یکدیگر تفکیک کرد. بدین ترتیب، میتوان گفت پیشفرضهایی که مدل آنالیز خطی برای حل مسئله در نظر میگیرد، ممکن است مطابق مسئله و دادههای آموزشی نباشد.
الگوریتم درخت تصمیم
درخت تصمیم را میتوان به عنوان یکی از مهمترین الگوریتم های یادگیری ماشین با رویکرد یادگیری نظارت شده به حساب آورد. در ساخت دستهبند درخت تصمیم، از بازنمایی دودوئی استفاده میشود. همچنین، ویژگیهای مسئله را میتوان برای ساخت گرههای درخت تصمیم به کار برد و برگهای درخت را به عنوان تعیینکنندههای خروجی مدل (نوع دسته) تعریف کرد.

درخت تصمیم با دریافت داده جدید، بر اساس گرهها (ویژگیها) تصمیم میگیرد که چه شاخهای از درخت طی شود و چه دستهای را برای داده مشخص کند. مهمترین ویژگی الگوریتم درخت تصمیم این است که به زمان کمی برای آموزش و پیشبینی برای داده جدید احتیاج دارد. در تصویر زیر، مدلی از درخت تصمیم برای مسئله پیشبینی وقوع بارندگی نشان داده شده است که این مدل بر اساس ویژگیهای از پیش تعریف شده، دادهها را در دو دسته قرار میدهد.

مدل ماشین بردار پشتیبان
ماشین بردار پشتیبان به عنوان یکی دیگر از الگوریتم های یادگیری ماشین با رویکرد یادگیری نظارت شده تلقی میشود. این مدل به دنبال پیدا کردن «ابَر صفحهای» (Hyperplane) است که دادههای مشابه را از دادههای غیر مشابه تفکیک کند. به عبارتی، مدل ماشین بردار پشتیبان، ابر صفحهای را انتخاب میکند که بتواند به بهترین شکل، دادهها را در دستههای جداگانه قرار دهد و بیشترین فاصله را با هر داده از دستههای مختلف داشته باشد.
دادههایی که در مدل ماشین بردار پشتیبان به عنوان معیار سنجش میزان فاصله تا ابر صفحه مد نظر قرار میگیرند، بردارهای پشتیبان نامیده میشوند. در فضای دو بعدی میتوان ابر صفحه را به شکل خط نشان داد.
مدل ماشین بردار پشتیبان در حل مسائلی که دادههایی با ابعاد بالا دارند، از کارایی خوبی برخوردار است. با این حال، چنانچه تعداد ویژگیهای مسئله از تعداد نمونههای آموزشی مدل بیشتر شود، این مدل عملکرد خوبی نخواهد داشت.
الگوریتم Naive Bayes
مدل نایو بیز به عنوان یکی از الگوریتم های یادگیری ماشین شناخته میشود که بر پایه مدل احتمالاتی بیز طراحی شده است و از آن برای مسائل دستهبندی با رویکرد یادگیری نظارت شده استفاده میشود.
مهمترین فرضیهای که این مدل در مورد دادهها در نظر میگیرد، این است که ویژگیها مستقل از یکدیگر هستند و با تغییر مقادیر ویژگیها، تاثیری بر روی سایر مقادیر حاصل نمیشود.
به عنوان مثال، توپ بسکتبال را در نظر بگیرید. این توپ دارای ویژگیهای مختلفی نظیر رنگ، وزن و اندازه است. اگر چه مقادیر همه این ویژگیها در تعیین این پرسش دخیل هستند که آیا یک توپ، توپ بسکتبال است یا خیر، مدل نایو بیز این ویژگیها را مستقل از یکدیگر میداند تا برای تشخیص جواب، مسئله را سادهتر کند.
مدل KNN
یکی دیگر از الگوریتم های یادگیری ماشین ساده، مدل KNN است که با رویکرد یادگیری نظارت شده، به دستهبندی دادهها میپردازد. این الگوریتم تمام دادههای آموزشی را در حافظه خود ذخیره میکند و برای تشخیص کلاس داده جدید، میزان شباهت داده را نسبت به هر یک از دادههای آموزشی در نظر میگیرد. مدل KNN به منظور تعیین میزان شباهت داده جدید به دادههای آموزشی، از معیارهای سنجش فاصله در فضای مختصات مانند محاسبه فاصله اقلیدسی بهره میگیرد.
در الگوریتم KNN پارامتری با عنوان k وجود دارد که تعداد همسایههای داده جدید را تعیین میکند. به عبارتی، چنانچه پارامتر k برابر با عدد ۳ باشد، مدل KNN سه تا از نزدیکترین دادههای آموزشی (دادههای مجاور | دادههای همسایه) را برای تعیین کلاس داده جدید انتخاب میکند. اگر کلاسهای دادههای همسایه مشابه یکدیگر نباشند، مدل KNN بر اساس تعداد اکثریت کلاسها، کلاس داده جدید را تعیین میکند.

با این که مدل KNN به میزان حافظه زیادی برای نگهداری دادههای آموزشی احتیاج دارد، تنها در زمان تست نیاز به انجام محاسبه دارد تا دسته داده جدید را مشخص کند. بدین ترتیب، این مدل بر خلاف سایر الگوریتم های یادگیری ماشین به زمان مجزا برای آموزش نیاز ندارد.
الگوریتم جنگل تصادفی
مدل جنگل تصادفی به عنوان یکی از الگوریتم های یادگیری ماشین قوی و رایج محسوب میشود که بر پایه روش «یادگیری جمعی» (Ensemble Learning) طراحی شده است. الگوریتم های معمولی یادگیری ماشین تنها شامل یک مدل هستند که با دادههای آموزشی، به یادگیری مسائل میپردازند.

مدلهای ساده یادگیری ماشین ممکن است در مسائل مختلف با چالشهایی نظیر مقدار بایاس بالا یا مقدار واریانس بالا مواجه شوند که بر دقت مدل تاثیر منفی خواهند گذاشت. به منظور رفع چنین مشکلاتی، میتوان از روش یادگیری جمعی استفاده کرد که در این روش، از چندین الگوریتم ماشین لرنینگ برای پیادهسازی مسئله استفاده میشود. در آخر، خروجی نهایی مسئله، بر اساس خروجی تمامی مدلها محاسبه میشود.

الگوریتم جنگل تصادفی بر اساس رویکرد جمعی، از چندین درخت تصمیم ساخته شده است که هر یک از این درختهای تصمیم، به دستهبندی کلاس داده جدید میپردازند و در نهایت، داده جدید بر اساس خروجی کل درختهای تصمیم تعیین میشود. از آنجا که مدل جنگل تصادفی خروجی مدل را بر اساس خروجیهای چندین الگوریتم تعیین میکند، میزان دقت و کارایی این مدل در مقایسه با سایر الگوریتمهای ساده یادگیری ماشین بالاتر است.
مدل خوشه بندی K-Means چیست ؟
از میان الگوریتم های یادگیری ماشین با رویکرد نظارت نشده، میتوان به الگوریتم رایج K-Means اشاره کرد. این مدل سعی دارد دادههای آموزشی را به خوشههای جداگانه تقسیم کند. این تقسیمبندی به گونهای انجام میشود که دادههای هر خوشه به یکدیگر شباهت بسیاری دارند و نسبت به دادههای سایر خوشهها متفاوت هستند.

مدل خوشهبندی K-Means دارای پارامتری به نام k است که تعداد خوشهها را مشخص میکند. روال یادگیری الگوریتم K-Means را میتوان در مراحل زیر خلاصه کرد:
- تعیین خوشهها و نقاط مرکزی آنها: در ابتدا مقداری را برای پارامتر k در نظر میگیریم تا در نهایت، دادههای آموزشی در k خوشه گروهبندی شوند. مدل به تعداد هر خوشه، داده آموزشی انتخاب میکند و آنها را به عنوان داده مرکزی خوشهها در نظر میگیرد.
- تخصیص دادههای جدید به خوشهها: داده آموزشی بعدی با دادههای مرکزی هر خوشه مقایسه میشود و در نهایت با توجه به میزان شباهت، در خوشهای قرار میگیرد که با داده مرکزی بیشترین مشابهت را داشته باشد.
- بهروزرسانی نقاط مرکزی خوشهها: پس از تخصیص دادههای آموزشی جدید به خوشهها، نقاط مرکزی هر خوشه مجدد تعیین میشوند تا دادههای آموزشی بعدی با این نقاط مورد مقایسه قرار داده شوند.
- تکرار مراحل قبل: مراحل قبل آنقدر تکرار میشوند تا تمامی دادههای آموزشی در خوشههای مجزا قرار گیرند.
الگوریتم Apriori
مدل Apriori به عنوان یکی از الگوریتم های یادگیری ماشین با رویکرد نظارت نشده تلقی میشود که هدف آن پیدا کردن روابط و قواعد بین «اقلام» (Items) مختلف است. از این مدل معمولاً در تحلیل دادههای مربوط به فروش استفاده میشود.
میتوان از یک مثال ساده به منظور درک هدف الگوریتم اپریوری یا همان Apriori کرد. اگر فردی تصمیم بگیرد از فروشگاهی شیر و شکر بخرد، احتمال بالایی وجود دارد که این فرد قصد خرید قهوه را نیز از این فروشگاه داشته باشد. به عبارتی، میتوان قاعده زیر را برای خرید مشتریان با توجه به دادههای فروش تعریف کرد:
{شیر، شکر} => قهوه
الگوریتم Apriori به دنبال استخراج چنین روابطی از دادههای مسئله است. به عبارتی، هدف این الگوریتم پیدا کردن الگوهایی است که در بین دادهها تکرار میشوند.
نحوه انتخاب الگوریتم های یادگیری ماشین برای حل مسئله
به منظور انتخاب مناسبترین الگوریتم یادگیری ماشین برای پیادهسازی مسائل، باید عوامل مختلفی را در نظر گرفت. در ادامه، برخی از مهمترین عوامل برای انتخاب الگوریتم های ماشین لرنینگ فهرست شدهاند:

- تعداد دادههای آموزشی
- نوع داده آموزشی
- میزان دقت مدل و قابلیت تفسیرپذیری آن
- زمان آموزش مدل
- تعداد ویژگیها
در ادامه این بخش، به توضیح عوامل ذکر شده در بالا میپردازیم که هر مهندس یادگیری ماشین باید به آنها توجه کند تا برای مسائل تعریف شده مناسبترین انتخاب را داشته باشد.
حجم داده های آموزشی برای انتخاب الگوریتم های یادگیری ماشین
معمولاً برای حل مسائل با استفاده از الگوریتم های یادگیری ماشین توصیه میشود که حجم زیادی از دادههای آموزشی را تهیه کنید تا مدلها بتوانند با دقت بالایی به پیشبینی بپردازند. با این حال، در برخی شرایط امکان فراهم کردن دادههای آموزشی حجیم فراهم نیست. در این حالت، میتوان از مدلهایی نظیر رگرسیون خطی، نایو بیز و ماشین بردار پشتیبان برای حل مسائل استفاده کرد.
از طرف دیگر، چنانچه حجم داده آموزشی مناسبی را برای مسئله تعریف شده فراهم کردهاید، مدلهای درخت تصمیم و KNN میتوانند بهترین انتخاب برای پیادهسازی مسئله باشند.
انتخاب الگوریتم های یادگیری ماشین بر اساس نوع داده آموزشی
همانطور که در بخش ابتدایی مطلب حاضر اشاره شد، الگوریتم های یادگیری ماشین بر پایه رویکردهای یادگیری مختلف، مسائل گوناگون را حل میکنند.

رویکردهای نظارت شده و نیمه نظارت شده به دادههای آموزشی برچسبدار نیاز دارند. بنابراین، الگوریتم های یادگیری ماشینی که بر پایه چنین رویکردی طراحی شدهاند، نمیتوانند با دادههای بدون برچسب آموزش ببینند.

از طرف دیگر، الگوریتم های یادگیری تقویتی به دادههای آموزشی احتیاج ندارند. به عبارتی، چنین مدلهایی با بازخوردهایی که از محیط دریافت میکنند، مسئله را یاد میگیرند. بدین ترتیب، نوع دادههای آموزشی مسئله به عنوان عامل دیگری برای انتخاب مناسبترین الگوریتم برای پیادهسازی مسائل یادگیری ماشین محسوب میشود.
انتخاب الگوریتم های یادگیری ماشین بر اساس دقت مدل
دقت مدل یکی از معیارهای مهم برای انتخاب مدل محسوب میشود. دقت مدل نشان میدهد که مدل تا چه میزان میتواند مسئله را بهدرستی حل کند. معمولاً رابطه دو طرفهای میان میزان تفسیرپذیر بودن مدل و میزان دقت آن وجود دارد.
هرچه میزان تفسیرپذیری مدل بالاتر باشد، معمولاً دقت مدل کمتر میشود. مدلهایی مانند رگرسیون خطی تفسیرپذیری بالایی دارند و دارای محدودیت هستند، زیرا صرفاً میتوانند یک خط مستقیم در خروجی تولید کنند. مدلهایی نظیر الگوریتم KNN نیز مدلهایی هستند که انعطافپذیری بالایی دارند. این ویژگی بدین معنا است که چنین مدلهایی می توانند به شکلهای متنوعی دادهها را تقسیم کنند.
چنانچه هدف از پیادهسازی الگوریتم های یادگیری ماشین، تفسیر کردن مسئله باشد، مدلهایی نظیر رگرسیون خطی میتوانند نیاز ما را بر طرف کنند. در شرایطی که دقت بالای مدل برای کاربر مهم باشد، مدلهای انعطافپذیر مانند KNN مناسبترین انتخاب برای حل مسائله هستند.
انتخاب الگوریتم های ماشین لرنینگ بر اساس زمان آموزش مدل
زمان آموزش مدل به عنوان یکی دیگر از معیارهای مهم برای انتخاب مناسبترین الگوریتم یادگیری ماشین محسوب میشود. مدلهایی که از دقت بالایی در حل مسائل برخوردار هستند، اصولاً به زمان بیشتری برای یادگیری احتیاج دارند. بهعلاوه، چنانچه حجم دادههای آموزشی زیاد باشد، زمان آموزش مدل نیز به مراتب بیشتر خواهد شد.
الگوریتم های یادگیری ماشین مانند نایو بیز، رگرسیون لجستیک و رگرسیون خطی به زمان کمی برای آموزش و اجرا احتیاج دارند. از سوی دیگر، برای مدلهایی با تعداد پارامتر زیاد نظیر ماشین بردار پشتیبان، مدل جنگل تصادفی و الگوریتم های یادگیری عمیق باید زمان بیشتری را برای آموزش در نظر گرفت.
انتخاب الگوریتم های ماشین لرنینگ بر اساس تعداد ویژگی
دادههای آموزشی ممکن است دارای ویژگیهای بسیار زیادی باشند. برخی از این ویژگیها نیز ممکن است به مسئله تعریف شده غیر مرتبط باشند که در این حالت بهتر است در زمان آموزش مدل، استفاده نشوند.

بررسی ویژگیهای دادههای آموزشی از مهمترین مراحل پیش از انتخاب مدل محسوب میشود. چنانچه ویژگی دادههای آموزشی مسئله زیاد است، بهتر است از مدلهایی نظیر ماشین بردار پشتیبان استفاده شود. البته، خاطر نشان میشود که زیاد بودن ویژگی دادهها باعث بالا رفتن زمان آموزش مدل میشود.
در شرایطی که ابعاد دادهها زیاد هستند، بهتر است پیش از آموزش مدل، از روشهایی مانند کاهش بعد دادهها یا استخراج ویژگی استفاده کنید. استفاده از چنین روشهایی نه تنها باعث کاهش زمان آموزش مدل میشوند، بلکه در میزان دقت نهایی مدل تاثیر منفی نخواهند گذاشت.
زبان های برنامه نویسی برای پیاده سازی الگوریتم های یادگیری ماشین
در بخش حاضر به معرفی رایجترین و پرکاربردترین زبانهای برنامه نویسی برای طراحی و ساخت الگوریتم های یادگیری ماشین پرداخته میشود تا افراد علاقهمند به این حوزه با ابزارها و کتابخانههای رایج این زبانها آشنا شوند.
در فهرست زیر، برخی از مهمترین زبانهای برنامه نویسی یادگیری ماشین ملاحظه میشوند:
- زبان برنامه نویسی پایتون
- زبان برنامه نویسی R
- زبان برنامه نویسی جاوا و جاوا اسکریپت
- زبان برنامه نویسی Julia
- زبان برنامه نویسی Lisp
- زبان برنامه نویسی Scala
- زبان برنامه نویسی TypeScript

در ادامه، به توضیح مختصری از کاربرد زبانهای برنامه نویسی ذکر شده در فهرست بالا در حیطه یادگیری ماشین پرداخته میشود.
زبان برنامه نویسی پایتون در یادگیری ماشین
زبان برنامه نویسی پایتون، زبانی همه منظوره است که از آن میتوان در توسعه تمامی پروژههای کامپیوتری استفاده کرد. یادگیری این زبان ساده است و کتابخانههای جامع و کاربردی مختلفی را در اختیار کاربران خود قرار میدهد. همچنین، این زبان از انواع رویکردهای مختلف برنامه نویسی مانند برنامه نویسی رویهای و برنامه نویسی شی گرا پشتیبانی میکند.
زبان پایتون دارای کتابخانههای قدرتمندی در حوزه یادگیری ماشین، یادگیری عمیق، «دیتا ساینس» (Data Science)، تحلیل داده و بصریسازی داده است و به همین خاطر، در میان توسعه دهندگان و برنامه نویسان به عنوان یکی از محبوبترین زبانهای برنامه نویسی حوزه هوش مصنوعی شناخته میشود. برخی از مهمترین کتابخانههای هوش مصنوعی زبان برنامه نویسی پایتون که در پروژههای یادگیری ماشین از آنها استفاده میشوند، در ادامه فهرست شدهاند:

یادگیری ماشین با زبان برنامه نویسی R
زبان برنامه نویسی R به عنوان یکی از زبانهای منبع باز (اپن سورس) محسوب میشود که با استفاده از آن میتوان مدلها و الگوریتم های یادگیری ماشین و پروژههایی مبتنی بر محاسبات آماری را پیادهسازی کرد.

این زبان شامل ابزارهای کاربردی مختلفی را برای رسم گراف و مدلها است و به دلیل داشتن چنین امکاناتی مورد توجه بسیاری از فعالان حوزه هوش مصنوعی و مخصوصاً حوزه دیتا ساینس قرار گرفته است، زیرا این افراد میتوانند با چنین ابزارهایی دادهها را به شکل بصری تحلیل کنند. همچنین، از این زبان میتوان بر روی سیستمعاملهای مختلف استفاده کرد.
کاربرد زبان برنامه نویسی جاوا و جاوا اسکریپت در یادگیری ماشین
از زبانهای برنامه نویسی جاوا و جاوا اسکریپت میتوان در توسعه اکثر پروژههای نرمافزاری استفاده کرد. این زبانها دارای ابزارهای خوبی برای پیادهسازی الگوریتم های یادگیری ماشین هستند و از پردازش «کلان داده | مه داده | دادههای حجیم» (Big Data) پشتیبانی میکنند.
Weka و Rapid Miner به عنوان فریمورکهای مهم یادگیری ماشین در این زبانها به شمار میروند که با استفاده از آنها میتوان انواع مختلفی از مدلهای یادگیری ماشین مانند درخت تصمیم، مدلهای رگرسیون و سایر مدلها را پیادهسازی کرد.
یادگیری ماشین با زبان برنامه نویسی Julia
زبان Julia به عنوان یکی از زبانهای سطح بالا در برنامه نویسی محسوب میشود که از آن میتوان برای توسعه برنامههای مبتنی بر ماشین لرنینگ استفاده کرد.

یادگیری این زبان برای تازهکاران حوزه برنامه نویسی ساده است، زیرا این زبان قواعد دستوری یا همان نحو «سینتکس» (Syntax) بسیاری سادهای دارد. با استفاده از این زبان میتوان پروژههای نرمافزاری مختلفی در حوزه محاسبات عددی و تحلیلهای آماری با رویکردهای تابعی و شی گرایی را توسعه داد. به همین خاطر، این زبان میتواند به عنوان زبانی کاربردی برای افراد فعال در حوزه آمار و تحلیل داده محسوب شود.

کاربرد زبان Lisp در حوزه ماشین لرنینگ
زبان Lisp به عنوان یکی از قدیمیترین زبانهای برنامه نویسی حوزه هوش مصنوعی و یادگیری ماشین محسوب میشود.
این زبان با ابزارها و قابلیتهای مختلفی که در اختیار برنامه نویسان حوزه هوش مصنوعی قرار میدهد، باعث شده است که فعالان این حوزه همچنان از این زبان برای توسعه انواع پروژههای یادگیری ماشین خود استفاده کنند.
یادگیری ماشین با زبان Scala
زبان برنامه نویسی Scala یکی از زبانهای کامپایلری است که با فریمورکها و کتابخانههای زبان جاوا سازگاری دارد. از این زبان میتوان برای کار با دادههای حجیم استفاده کرد و ابزارهای مختلفی نظیر «آپاچی اسپارک» (Apache Spark) از این زبان پشتیبانی میکنند.
با ابزارهای مختلف زبان Scala میتوان به طراحی و توسعه الگوریتم های یادگیری ماشین پرداخت و با استفاده از کتابخانههای مختلف این زبان نظیر Aerosol و Saddle میتوان محاسبات مختلف ریاضی و جبر خطی را انجام داد. بهعلاوه، با استفاده از کتابخانههای موجود در این زبان میتوان پردازشهای مختلفی بر روی دادهها اعمال و آنها را برای آموزش مدلهای یادگیری ماشین آماده کرد.
زبان TypeScript برای یادگیری ماشین
زبان برنامه نویسی TypeScript یکی از زبانهای برنامه نویسی شی گرا است که در سال ۲۰۱۲ توسط مایکروسافت ارائه شد. با استفاده از کتابخانه Kalimdor این زبان میتوان در توسعه برنامههای مبتنی بر یادگیری ماشین استفاده کرد.

یکی از مهمترین ویژگیهای زبان TypeScript این است که این زبان به عنوان نسخه ساده شده زبان جاوا اسکریپت تلقی میشود. به همین خاطر، یادگیری، خواندن، درک و رفع خطای قطعه کدهای نوشته شده به این زبان برای برنامه نویسان تازهکار آسان است.
جمعبندی
یادگیری ماشین به عنوان یکی از داغترین مباحث حوزه علوم کامپیوتر محسوب میشود که بسیاری از پژوهشگران برای پیشبرد پژوهشهای علمی خود از مدلهای آن بهره میبرند. به عبارتی، یادگیری ماشین به عنوان یکی از زیرشاخههای هوش مصنوعی، شامل مباحثی پیرامون الگوریتم ها و روشهای مختلف یادگیری سیستمهای کامپیوتری در راستای طراحی و ساخت سیستمهای سختافزاری هوشمند است.
در مطلب حاضر سعی بر این بود تا پس از توضیح رویکردهای یادگیری الگوریتم های یادگیری ماشین، به معرفی پرکاربردترین مدلهای این حیطه پرداخته شود تا علاقهمندان این شاخه از رشته کامپیوتر با کاربرد و ویژگیهای آنها آشنا شوند و بتوانند بر اساس ویژگیهای مختلف این مدلها، مناسبترین مدل را برای حل مسائل انتخاب کنند.








