



مدل زبانی چیست؟ – Language Model در AI به زبان ساده
در سال ۲۰۲۰، هوش مصنوعی شگفتانگیزی به نام GPT-3 (همان ChatGPT)، دنیای Silicon Valley را فتح کرد. این هوش مصنوعی توسط OpenAI در سانفرانسیسکو توسعه داده شد و در آن زمان جدیدترین و قویترین نوع آن بود. یک «مدل زبانی گسترده» (Large Language Model) که پس از دریافت میلیاردها کلمه از کتابها، مقالات و وبسایتها، میتوانست متن ساده و روانی را تولید کند. با این پیشرفتها، مفهوم مدلسازی زبان وارد دوره جدیدی شد. در این مطلب به این پرسش پاسخ میدهیم که مدل زبانی چیست و میخواهیم به این مسئله بپردازیم که چه مدلهای زبانی وجود دارند و چگونه میتوان از این مدلها در وظایف پردازش زبان طبیعی (NLP) استفاده کرد؟
- یاد میگیرید مدل زبانی چگونه متن را تفسیر و تولید میکند.
- با کاربردهای شاخص مدلهای زبانی مانند ترجمه، پرسش و پاسخ و غیره آشنا میشوید.
- فرق رویکردهای مدل آماری و مدل عصبی را یاد خواهید گرفت.
- یاد میگیرید ترنسفورمر چیست و چرا «Self-Attention» آن را قدرتمند کرده است.
- توانایی مدلهای زبانی در تحلیل احساس و تولید محتوا را خواهید شناخت.
- یاد میگیرید نقش داده و کیفیت دیتاست را در موفقیت مدل زبانی ارزیابی کنید.




در این مطلب به بررسی و توضیح مسائلی چون مدلهای زبانی، انواع آنها و قابلیتهایشان میپردازیم. همچنین به مدلهای زبانی محبوب مانند GPT-3 و کاربردهای عملی آن خواهیم پرداخت.
مدل زبانی چیست ؟
مدل زبانی نوعی مدل «یادگیری ماشین» (Machine Learning) است که برای ایجاد یک توزیع احتمال بر روی کلمات، «آموزش» (Train) داده میشود. به بیان ساده، این مدل سعی میکند با توجه به متن داده شده، کلمه مناسب بعدی را برای پر کردن یک فضای خالی در جمله یا عبارت، پیشبینی کند.
به عنوان مثال، جمله مقابل را در نظر میگیریم: «سارا برای گرفتن کلیدها به شرکت سر زد، بنابراین من آنها را به [...] دادم». یک مدل خوب تصمیم میگیرد کلمهای که در جای خالی به آن نیاز داریم به احتمال زیاد یک ضمیر است. از آنجا که اطلاعات مرتبط با جمله در اینجا با سارا است، ضمیر احتمالاً «او» یا «او را» خواهد بود.
مهم این است که مدل بر روی گرامر تمرکز نمیکند، بلکه تمرکز آن بر روی این است که چگونه کلمات در این روش شبیه به نحوه نوشتن انسانها و جملهبندی آنها استفاده میشوند. حال به عنوان نمونه دیگری، به مکالمه با ChatGPT و سپس نحوه پاسخ این مدل زبانی گسترده بپردازیم. ابتدا سوالی به زبان انگلیسی از چت بات میپرسیم که پاسخ آن را طبق تصویر زیر مشاهده میکنید.

همانطور که مشاهده میشود، چت بات جی پی تی به خوبی و با استفاده از مدل زبانی خود، پاسخ مناسبی همراه با جملهبندی شبیه به انسان ارائه داده است. حال پاسخ همین سوال را در ادامه به زبان فارسی میبینیم.
واقعا شگفتانگیز است. همانطور که مشاهده میکنیم این چتبات برای معرفی و توضیح درباره خودش، به درستی پاسخ میدهد. مدلهای زبانی از جمله اجزای اساسی پردازش زبان طبیعی (NLP) هستند چرا که به ماشینها این امکان را میدهند تا زبان انسانی را درک، تولید و تجزیه و تحلیل کنند. آنها عمدتا با استفاده از مجموعه بزرگی از متن مثل مجموعه کتابها و مقالات آموزش داده میشوند. سپس مدلها از الگوهایی که از این دادههای آموزشی یاد میگیرند، برای پیشبینی کلمه بعدی در یک جمله یا تولید متنی جدید استفاده میکنند که گرامری صحیح و معنایی هماهنگ دارد.

طبق مقاله «مدلهای زبانی یادگیرنده چند منظوره» (Language Models are Few-Shot Learners) از OpenAI، مدل زبانی GPT-3 به حدی پیشرفته شده بود که بسیاری افراد مشکل در تمایز دادن بین خبرهایی داشتند که توسط این مدل تولید شدهاند و خبرهایی که توسط نویسندگان انسانی نوشته شدهاند. GPT-3 هستهای است که در ساخت چتباتی به نام ChatGPT استفاده شده است. چتبات ChatGPT کاربردهای زیادی دارد و بهویژه برای وظایف گفتگویی و چت کردن بهینه شده است.
مفهوم مدل زبانی به بیان ساده چیست ؟
مدل زبانی سیستم «هوش مصنوعی» (AI) است که برای تفسیر و تولید زبان طبیعی (مثل زبان انگلیسی، فارسی، اسپانیایی و غیره) به کار میرود. این مدلها با استفاده از دادههای حجیم آموزش داده میشوند تا توانایی فهمیدن زبان طبیعی و تولید متن های زبانی را به صورت خودکار به دست آورند. این مدلها برای کاربردهای مختلفی مانند ترجمه ماشینی، خلاصهسازی متون، پاسخ به سوالات و دیگر کاربردها استفاده میشوند.
مدل یادگیری ماشین چیست ؟
مدلهای یادگیری ماشین یا ماشین لرنینگ، الگوریتمهایی هستند که بدون «برنامه نویسی صریح» میتوانند الگوها و روابطی را از دادهها یاد بگیرند. آنها برای تحلیل و تفسیر دادهها، شناسایی الگوها و انجام پیشبینیها یا تصمیمات بر اساس دادهها طراحی شدهاند. مدلهای یادگیری ماشین در برنامههای مختلفی مانند تشخیص تصویر، تشخیص صدا، پردازش زبان طبیعی، سیستمهای توصیهگر، تشخیص تقلب و پیشبینی استفاده میشوند.

این مدلها میتوانند با استفاده از روشهای مختلفی مانند «یادگیری نظارت شده» (Supervised learning)، «یادگیری نظارت نشده» (Unsupervised Learning) و «یادگیری تقویتی» (Reinforcement Learning) آموزش داده شوند و میتوانند در محیطهای مختلفی مخصوصاً بر روی بسترهای «ابری» (Cloud) پیادهسازی شوند.
داده چیست ؟
با توجه به توضیحات بالا، شاید این سوال برای شما ایجاد شده باشد که داده چیست، «داده» (Data) به هر نوع اطلاعاتی گفته میشود که به صورت اعداد، حروف، علائم و نمادها قابل ذخیرهسازی و پردازش باشد.

داده میتواند به صورت دیجیتال یا آنالوگ باشد و ممکن است از منابع مختلفی مانند سامانههای کامپیوتری، حسگرها، دستگاههای اندازهگیری و غیره جمعآوری شود. اطلاعاتی که برای تحلیل و استفاده کاربردی به آنها نیاز داریم، از طریق پردازش دادهها استخراج میشوند.

مدلهای زبانی چه کاری انجام میدهند ؟
مدلهای زبانی یا همان Language Modelها میتوانند بسیار هوشمندانه به نظر برسند. این مسئله فقط در استخراج پاسخ های درست از اسناد، بسیار خوب عمل میکند، زیرا به لطف تسلط آنها بر زبان انسانی و تنظیمات دقیقی که در مجموعه دادههای پرسش و پاسخی دریافت کردهاند، این فرایند شبیه به یک عامل انسانی انجام میشود که مستندات را برای استخراج اطلاعات از آنها میخواند، اما بسیار بسیار سریعتر از یک عامل انسانی پاسخگو هستند.

انواع دیگر مدلهای زبانی رویکردی کاملاً متفاوت دارند. برای مثال، خانواده محبوب GPT از مدلهای زبان مولد در واقع اطلاعات را به خاطر میسپارند. آنها پارامترهای زیادی دارند (نزدیک به میلیاردها پارامتر) که میتوانند علاوه بر یادگیری قوانین زبان، اطلاعاتی را ذخیره کنند که در طول آموزش جمعآوری میکنند.
بنابراین یک مدل زبان چه کاری میتواند انجام دهد؟ دقیقاً همان کاری که برای انجام آن آموزش دیده است، نه بیشتر و نه کمتر. برخی از مدلها برای استخراج پاسخ از متن و برخی دیگر برای تولید پاسخ از ابتدا آموزش دیدهاند. برخی برای خلاصه کردن متن آموزش دیدهاند و برخی دیگر به سادگی یاد میگیرند که زبان را نشان دهند. اگر مستندات شما از زبان بسیار تخصصی استفاده نمیکنند، یک مدل از پیش آموزش دیده شده ممکن است بدون نیاز به آموزش بیشتر به خوبی برای شما کار کند. با این حال، موارد استفاده دیگر ممکن است از مراحل آموزشی اضافی بهرهمند شوند.
مدل های زبانی توانایی انجام چه کارهایی را دارند ؟
آیا تا به حال به قابلیتهای هوشمند صفحه کلید گوگل «Gboard» یا صفحه کلید SwiftKey مایکروسافت که پیشنهادات خودکار برای تکمیل جملات در حال نوشتن پیامهای متنی را فراهم میکنند، توجه کردهاید؟ این مورد یکی از کاربردهای فراوان مدلهای زبانی محسوب میشود.

مدلهای زبانی چندین کاربرد و وظیفه در حوزه پردازش زبان طبیعی مانند بازشناسی گفتار، ترجمه ماشینی و خلاصهسازی متن دارند که پس از پاکسازی دادهها و پیش پردازش متن، میتوان آنها را به عنوان ورودی به مدل داد و برای هر کاربردی از آنها استفاده کرد. در ادامه به معرفی مفصلتر هر کدام از این وظایف میپردازیم.
تولید محتوا Content Generation
تولید محتوا یکی از حوزههایی است که مدلهای زبانی در آن بسیار موفق عمل میکنند. این مورد شامل تولید متون کامل یا بخشی از آنها بر اساس دادهها و اصطلاحات ارائه شده توسط انسانها میشود. این محتوا میتواند شامل مقالات خبری، اعلانیههای رسانهای، نوشتههای وبلاگی، توصیفات محصولات فروشگاههای آنلاین، شعرها و آکوردهای گیتار و سایر موارد باشد.
سوال و جواب Question Answering
مدلهای زبانی میتوانند به گونهای آموزش داده شوند که سؤالات را هم با در نظر گرفتن متن مرتبط و هم بدون در نظر گرفتن آن، درک کنند و پاسخ دهند. آنها میتوانند پاسخها را به چندین روش مانند استخراج عبارتهای خاص، بازگویی پاسخ یا انتخاب از فهرست گزینهها ارائه دهند.
خلاصه سازی متن Text Summarization
مدلهای زبانی میتوانند برای کوتاه کردن خودکار مستندات، مقاله، پادکست، ویدیو و موارد دیگر و تبدیلشان به قسمتهای مهمتر استفاده شوند. این مدلها به ۲ روش کار میکنند، استخراج اطلاعات مهمتر از متن اصلی یا ارائه خلاصهای از متن که خود زبان اصلی را مجدد تکرار نمیکند.

تحلیل احساسات Sentiment Analysis
رویکرد مدلسازی زبان گزینه خوبی برای وظایف تجزیه و تحلیل احساسات است، زیرا میتواند نوع صدا و تاثیر احساسی متنها را درک کند.
هوش مصنوعی مکالمهای Conversational AI
مدلهای زبان بخشی از برنامههای گفتاری به حساب می آیند که نیازمند «تبدیل صوت به متن» (STT | Speech To Text) و بالعکس هستند. به عنوان بخشی از سیستمهای هوش مصنوعی مکالمهای، مدلهای زبان میتوانند پاسخهای مرتبط با ورودیهای گفتاری را ارائه دهند.
برچسب گذاری بخشی از گفتار POS یا Part-of-Speech Tagging
برچسبگذاری یکی از وظایف پرکاربردی است که از مدلهای زبانی برای دستیابی به نتایج بهتر در این زمینه استفاده میکنند. تگگذاریِ بخشی از کلمات به معنای علامتگذاری هر کلمه در یک متن با بخش متناظر آن، مانند اسم، فعل، صفت و سایر موارد است. این مدلها با استفاده از مجموعههای بزرگی از دادههای متنی برچسبگذاریشده آموزش داده شدهاند و میتوانند با توجه به متن و کلمات محیطی در جمله به خوبی برچسب مورد نظر را پیشبینی کنند.

همانطور که در تصویر فوق مشاهده میشود، برای برچسبگذاری متن، هر کلمهای که در جمله داریم را تگِ معادل میزنیم. یعنی برای کلماتی که اسم هستند از N یا Noun، برای افعال از V یا Verb، برای حروف اضافه و ضمیر و سایر نقش کلمات نیز از حروف اختصاری مربوطه استفاده میکنیم.
ترجمه ماشینی Machine Translation
قابلیت مدلهای زبانی قدرتمند، توانایی تعمیم دادن موثر به متنهای بلند را به آنها داده است که باعث بهبود ترجمه ماشینی میشود. به جای ترجمه کلمه به کلمه متن، مدلهای زبانی میتوانند با یادگیری نمایش دنباله ورودی و خروجی متن، نتایج محکمی را ارائه دهند.
تکمیل کد Code Completion
«مدلهای بزرگ زبانی» (Large-Scale Language) اخیرا توانایی قابل توجهی در تولید، ویرایش و توضیح کدهای برنامه نویسی از خود نشان دادهاند. با این حال، آنها فقط میتوانند وظایف ساده کد نویسی را با ترجمه دستورالعملها به کد یا بررسی آن برای خطاها تکمیل کنند.
مطالب بیان شده فقط چند مورد از کاربردهای قابل استفاده از مدلهای زبانی بودند که به اختصار بررسی شدند.
مدل های زبانی در انجام چه کارهایی ناتوان هستند ؟
در حالی که مدلهای زبانی بزرگ بر روی مقادیر زیادی از دادههای متنی آموزش دیدهاند و میتوانند زبان طبیعی را درک کنند و متنی شبیه به انسان تولید کنند، اما همچنان در مورد کارهایی که نیاز به استدلال و هوش عمومی دارند محدودیتهایی شامل حال آنها میشود. این مدلها نمیتوانند وظایفی را انجام دهند که مرتبط با موارد زیر هستند.
- داشتن دانش مشترک
- فهم مفاهیم انتزاعی
- ساخت استنتاجهایی بر اساس اطلاعات ناقص
همچنین آنها ناتوان هستند که دنیا را به شکلی که انسانها میبینند، درک کنند و نمیتوانند تصمیماتی بگیرند یا در دنیای فیزیکی اقدامی کنند. در ادامه این مطلب به بررسی انواع مختلف مدلهای زبانی و چگونگی کار کردن آنها میپردازیم. البته توانایی این مدلها با تکنیکهایی مانند RAG افزایش پیدا کرده است.

انواع مدل های زبانی
مدلهای زبانی هوش مصنوعی در انواع مختلفی وجود دارند که میتوان آنها را به دو دسته مدلهای زبانی آماری و مدلهای مبتنی بر شبکههای عصبی عمیق تقسیم کرد.
مدل های زبانی آماری
«مدلهای زبانی آماری» (Statistical Language Models) نوعی از مدلها هستند که از الگوهای آماری در دادهها برای پیشبینی احتمال توالی خاصی از کلمات استفاده میکنند. یک روش پایه برای ساختن مدل زبانی آماری، محاسبه احتمالات n-gram است.

n-gram یک توالی از کلمات است که در آن n عددی بزرگتر از صفر است. برای ساختن یک مدل زبانی آماری ساده، احتمالات مختلف n-gram (ترکیب کلمات) در یک متن را محاسبه میکنیم. این کار با شمردن تعداد دفعاتی که هر ترکیب کلمات ظاهر میشود و تقسیم آن بر تعداد دفعاتی که کلمه قبلی ظاهر میشود، انجام میشود. این ایده بر مفهومی به نام «فرضیه مارکوف» (Markov assumption) بنا شده است، این فرضیه میگوید احتمال ترکیب کلمات (آینده) تنها به کلمه قبلی (حال) بستگی دارد و به کلماتی که قبل از آن آمدهاند (گذشته) وابسته نیست.
مدلهای n-gram انواع مختلفی دارند مانند:
- unigrams: که هر کلمه را به صورت مستقل ارزیابی میکنند.
- bigrams: احتمال ظهور یک کلمه را با توجه به کلمه قبلی بررسی میکنند.
- trigrams: که احتمال ظهور یک کلمه را با توجه به دو کلمه قبلی بررسی میکنند و غیره.

n-gramها نسبتاً ساده و کارآمد هستند، اما به بررسی زمینه طولانی کلمات در یک توالی جملات و پاراگرافی از متن توجه نمیکنند، ولی برای استفاده در یک جمله کاربرد مناسبی دارند.
مدل های زبانی مبتنی بر شبکههای عصبی
«مدلهای زبانی عصبی» (Neural Language Models)، همانطور که از نامشان پیداست، از «شبکههای عصبی» (Neural Networks) برای پیشبینی احتمال یک توالی از کلمات استفاده میکنند. این مدلها بر روی مجموعه بزرگی از دادههای متنی آموزش داده میشوند و قادرند ساختار زبان را در پسزمینه یاد بگیرند.
در تصویر زیر معماری یک مدل شبکه عصبی عمیق Feed-Forward همراه با دو «لایه پنهانی» (Hidden Layers) میان آن را مشاهده میکنیم.

آنها میتوانند با لغات بزرگ و با استفاده از نمایشهای توزیعشده با واژههای نادر یا ناشناخته روبهرو شوند. پرکاربردترین معماری شبکه عصبی برای وظایف «پردازش زبان طبیعی» (NLP)، «شبکههای عصبی بازگشتی» (RNNها) و شبکههای ترانسفورمر (در بخش بعدی به توضیح آنها خواهیم پرداخت) استفاده میشوند.
مدلهای زبانی عصبی، قادر به دریافت بهتر زمینه جملات نسبت به مدلهای آماری کلاسیک هستند. همچنین، آنها میتوانند با ساختارهای زبانی پیچیدهتر و وابستگیهای طولانیتر بین کلمات کنار بیایند. در ادامه به بررسی نحوه کارکرد مدلهای زبانی عصبی مانند RNNها و ترانسفورمرها میپردازیم.
نحوه کار مدلهای زبانی RNNها و Transformerها چگونه است؟
در زمینه پردازش زبان طبیعی، یک مدل آماری ممکن است برای کار با ساختارهای زبانی ساده کافی باشد. با افزایش پیچیدگی، این رویکرد کماثرتر میشود. به عنوان مثال، در صورت پردازش متنهای بسیار بلند، یک مدل آماری ممکن است با مشکل مواجه شود و نتواند همه توزیعهای احتمالی مورد نیاز برای پیشبینی دقیق را به خاطر بسپارد.
دلیلش این است که در یک متن با ۱۰۰ هزار کلمه، مدل نیاز دارد که ۱۰۰ هزار توزیع احتمالی را به خاطر بسپارد و اگر مدل نیاز داشته باشد ۲ کلمه به عقب بازگردد، تعداد توزیعهایی که باید به خاطر بسپارد به ۱۰۰ هزار به توان ۲ افزایش مییابد. اینجاست که مدلهای پیچیدهتر مانند RNNها وارد بازی میشوند.
شبکه عصبی بازگشتی یا RNN چیست ؟
شبکههای عصبی بازگشتی یا RNNها، نوعی از شبکههای عصبی هستند که میتوانند خروجیهای قبلی را هنگام دریافت ورودی بعدی، به خاطر بسپارند. این با مدلهای عصبی سنتی که ورودی و خروجی آنها مستقل از یکدیگر هستند، متفاوت است.
RNNها به خصوص زمانی مفید هستند که لازم است کلمه بعدی در یک جمله پیشبینی شود، زیرا میتوانند با در نظر گرفتن کلمات قبلی در جمله، بهترین پیشبینی را ارائه دهند.

ویژگی کلیدی RNNها، بردارهای حالت پنهان هستند که حامل اطلاعاتی درباره یک دنباله از کلمات است. این «حافظه» اجازه میدهد تا RNNها تمام اطلاعات محاسبه شده را پیگیری کنند و از این اطلاعات برای پیشبینی استفاده کنند. حالت پنهان توسط یک لایه پنهان در شبکه عصبی نگهداری میشود.
با این حال، RNNها میتوانند از نظر محاسباتی هزینهبر باشند و ممکن است برای دنبالههای ورودیِ بسیار طولانی به طور بهینه مقیاسپذیر نباشند. با افزایش طول جمله، اطلاعات از کلمات اولیه کپی میشوند و با بقیه جمله ارسال میشوند. زمانی که RNN به آخرین کلمه جمله میرسد، اطلاعات از کلمه اول به شکل چندین نسخه کپی از کپیهای قبلی تقسیم میشود و هر بار ضعیفتر میشود.
این بدان معناست که توانایی RNN در تهیه پیشبینی دقیق بر اساس اطلاعات اولیه جمله به مرور و هر چه جلوتر میرود، کاهش پیدا میکند که این به عنوان مسئله «گرادیانهای ناپدید شونده» (Vanishing Gradients) شناخته میشود.
برای حل این مشکل، ساختار «Long Short-term Memory | LSTM» توسعه داده شد. شبکه عصبی LSTM نوعی تغییریافته از RNN به حساب می آید که ساز و کار «Cell» در آن معرفی شده است که قادر به بازنگری یا دور انداختن اطلاعات در حالت پنهان است. Cell یا سلول، مولفه سازندهای است که به شبکه کمک میکند تا دادههای توالی را درک و پردازش کند، مانند یک کامپیوتر کوچک که میتواند هر چیزی را پردازش کرده و به یاد داشته باشد.

سلول LSTM شامل سه گِیت است.
- گیت ورودی جریان اطلاعات، ورودی به سلول را با تصمیمگیری در مورد بهروزرسانی مقادیر جدید در سلول، کنترل میکند.
- گِیت فراموشی تصمیم میگیرد کدام اطلاعات را دور بیاندازد.
- گِیت خروجی تصمیم میگیرد کدام اطلاعات را به خروجی بدهد.
این مسئله باعث میشود تا شبکه توانایی حفظ اطلاعات از ابتدای دنباله را در هنگام پردازش دنبالههای بلندتر داشته باشد. اما پس از آن، معماری جدید و حتی بهتری ایجاد شد، سیستمی که میتواند قسمتهای مختلف ورودی را که باید به آن توجه کرد را بیشتر مورد بررسی قرار دهد و قسمتهایی که باید در محاسبه استفاده شوند و قسمتهایی که باید نادیده گرفته شوند را تعیین کند. این معماری جدید ترنسفورمر نامیده میشود و در یک مقاله در سال ۲۰۱۷ توسط گوگل شرح داده شد.
ترنسفورمر چیست و چه کاربردی در زبان طبیعی دارد؟
«ترنسفورمرها» (Transformers) نوع قدرتمندی از شبکههای عصبی عمیق هستند که در درک مفهوم و معنا با تحلیل روابط در دادههای متوالی مانند کلمات در یک جمله، عالی عمل میکنند. نام «ترنسفورمر» از قابلیت آنها برای تبدیل یک دنباله به دنباله دیگر نشأت گرفته شده است.
از مزیت اصلی این سیستمها میتوان به قابلیت پردازش تمام دنباله بهطور همزمان به جای یک قدم در هر لحظه مانند RNN و LSTMها اشاره کرد. این اجازه میدهد تا سیستمهای ترنسفورمری قابلیت موازیسازی شدن داشته باشند و بنابراین سرعت آموزش و استفاده از آنها بیشتر شود. اجزای کلیدی مدلهای Transformer، معماری Encoder-Decoder، ساز و کار Attention و Self-Attention هستند.

معماری رمزگذار رمزگشا Encoder-Decoder
در مدل Transformer، رمزگذار دنبالهای از دادههای ورودی (که معمولاً متن هستند) را دریافت کرده و آنها را به بردارهایی تبدیل میکند، مانند بردارهایی که حاوی مفاهیم و موقعیت یک کلمه در جمله هستند. این بازنمایی پیوسته اغلب با نام «تعبیه» (Embedding) دنباله ورودی نامیده میشود. رمزگشا خروجیِ رمزگذار را دریافت کرده و از آنها برای تولید متن و تولید خروجی نهایی استفاده میکند.
هر دو رمزگذار و رمزگشا از یک «پشته» (Stack) از لایههای مشابه تشکیل شدهاند، هر یک حاوی ساز وکار Self-Attention و یک لایه شبکه عصبی «پیشرو» (Feed-Forward) هستند. همچنین در پشتهی Decoder، یک لایه Encoder-Decoder Attention نیز وجود دارد.
ساز و کار لایههای Attention و Self-Attention
قطعه اصلی سیستمهای ترانسفورمر، مکانیزم Attention است که به مدل اجازه میدهد هنگام پیشبینی، بر روی بخشهای خاصی از ورودی تمرکز کند. ساز و کار Attention، وزن را برای هر عنصر ورودی محاسبه میکند که نشاندهنده اهمیت آن عنصر برای پیشبینی فعلی است. این وزنها سپس برای محاسبه جمع وزندار ورودی استفاده میشوند که برای تولید پیشبینی نهایی مورد استفاده قرار میگیرد.
Self-Attention نوع خاصی از مکانیزم Attention به حساب میآید که در آن مدل برای پیشبینی، به بخشهای مختلف دنباله ورودی توجه میکند. این بدان معناست که مدل چند بار به دنباله ورودی نگاه میکند و هر بار که به آن مینگرد، بخشهای مختلف آن را مورد توجه قرار میدهد.
در معماری ترانسفورمر، مکانیزم Self-Attention به صورت چند بار همزمان اعمال میشود که این قابلیت را به مدل میدهد تا روابط پیچیدهتری را بین دنباله ورودی و دنباله خروجی یاد بگیرد.
در مرحله Training، ترانسفورمرها از یک نوع یادگیری «شبه نظارتی» (Semi-Supervised) استفاده میکنند. ابتدا با استفاده از یک «مجموعه داده» (Dataset) بزرگ از دادههای بدون برچسب به صورت «بدون نظارت» (Unsupervised) آموزش داده میشوند. این آموزش اولیه به مدل این امکان را میدهد تا الگوها و روابط کلی در داده را یاد بگیرد. پس از آن، مدل با استفاده از «یادگیری نظارت شده» (Supervised Training)، که در آن با مجموعه دادههای کوچکتر مشخص شده برای این مظیفه، آموزش داده میشوند و بهبود مییابد. این «میزانسازی دقیق» (Fine-Tuning)، مدل را قادر میسازد تا در وظایف خاص بهتر عمل کند.
پرکاربرد ترین مدلهای زبانی و کاربردهای واقعی آن ها
هر چند چشمانداز مدلهای زبانی هوش مصنوعی به طور مداوم و به ازای پروژههای جدید بهروز میشود، اما در این بخش فهرستی از چهار مدل را تهیه کردهایم که جزء مهمترینِ این مدلها هستند.
مدل زبانی GPT-3 و GPT-4 از OpenAI
مدل GPT-3 مجموعهای از مدلهای زبانی پیشرفته به حساب میآید که توسط تیم OpenAI توسعه داده شده است. این تیم در آزمایشگاهی پژوهشی در سان فرانسیسکو مستقر است و در حوزه تخصصی هوش مصنوعی فعالیت میکند..
کلمه اختصاری «GPT» به معنای «Generative Pre-Trained Transformer» است و عدد «۳» نشاندهنده این است که این سومین نسل از این مدلها به حساب میآید. لازم به ذکر است نسل جدیدتری از این مدل زبانی هوش مصنوعی نیز به تازگی توسعه داده شده است که با نام GPT-4 میتوان از آن استفاده کرد. در مطلبی که در این خصوص در مجله فرادرس نوشته شده است میتوان اطلاعات بیشتری را درباره این مدل مطالعه کرد.
به عنوان یک مدل همه منظوره، GPT-3 نسخه کوچکتر و بیشتر متمرکز بر گفتگو با نام ChatGPT دارد که به طور خاص برای وظایف مکالمهای مانند پاسخ به سؤالات یا شرکت در گفتگوها تنظیم شده است. ChatGPT بر روی مجموعهای بزرگ از متنهای مکالمهای آموزش دیده و برای پاسخ دادن به نحوی طراحی شده است که پاسخهایش شبیه به پاسخ انسان در یک گفتگو باشند.
در مورد GPT-3، یکی از ویژگیهای اصلی آن، توانایی تولید متنی است که به نظر میرسد توسط انسان نوشته شده باشد. این مدل میتواند شعر، ایمیل، شوخی و حتی کدهای سادهای بنویسد. این کار از طریق استفاده از تکنیکهای یادگیری عمیق و پیشآموزش مدل بر روی مجموعه داده بزرگی از متن انجام شده است.

توسعه دهندگان از ۱۷۵ میلیارد پارامتر برای آموزش آن استفاده کردند. پارامترها مقادیر عددی هستند که کنترلکننده روش پردازش و فهم واژگان توسط مدل هستند. هر چه تعداد پارامترها در یک مدل بیشتر باشد، حافظه آن برای ذخیره اطلاعات درباره دادههای دیده شده در دوره آموزش بیشتر میشود، که به آن امکان پیشبینی دقیقتر از دادههای جدید میدهد. برخلاف بسیاری از مدلهای جدید، GPT-3 در موارد مختلفی قبلاً استفاده شده است. در زیر چند مثال از کاربردهای آن آمده است.
نوشتن تبلیغات
روزنامه The Guardian از GPT-3 برای نوشتن مقالهای استفاده کرد. این مدل با ایدههایی تغذیه شده بود و هشت مقاله مختلف تولید کرد، که سپس ویراستاران آنها را ترکیب کردند و یک مقاله نهایی به دست آمد.

نوشتن نمایشنامه
یک گروه تئاتر در بریتانیا از GPT-3 برای نوشتن نمایشنامه استفاده کردند. در تابستان ۲۰۲۱ تئاتر Young Vic در لندن نمایشنامهای که توسط این مدل تولید شده بود را اجرا کرد. طی سه روز اجرا، نویسندگان پیشنهادهایی را به سیستم وارد میکردند، که سپس داستانی را ایجاد میکرد. بازیگران سپس خطوط خود را تطبیق دادند تا داستان را افزایش دهند و پیشنهادهای اضافی را برای هدایت مسیر داستان فراهم کنند.
تبدیل زبان به SQL
کاربران توییتر از GPT-3 برای همه نوع کاربردی، از نوشتن متن تا جداول اکسل استفاده کردهاند که یکی از برنامههایی که شناخته شد، استفاده از مدل برای نوشتن کوئریهای SQL بود.
خدمات مشتری و چت بات
شرکتهایی مانند ActiveChat از GPT-3 برای ساخت چتبات، گزینههای چت زنده و سایر خدمات هوش مصنوعی مکالمهای برای کمک به خدمات و پشتیبانی مشتری استفاده میکنند. ارائه فهرست کاملی از کاربردهای واقعی GPT-3 بسیار طولانی میشود، میتوانید خودتان آن را امتحان کنید و از کار کردن با آن لذت ببرید. البته در نظر داشته باشید با وجود تمام این کاربردهای جذاب، مدلهای زبانی همچنان محدودیتهای زیادی دارند.
مدل زبانی BERT توسعه داده شده توسط گوگل
مدل BERT خلاصه شده عبارت (Bidirectional Encoder Representations from Transformers) یک مدل زبانی «از پیش آموزش دیده شده» (Pretrained Language Model) به حساب میآید که توسط گوگل در سال ۲۰۱۸ توسعه داده شده است.
این مدل طراحی شده است تا با تحلیل روابط بین کلمات در یک جمله، به جای مشاهده کلمات به صورت جداگانه، توانایی درک متن مورد نظر را داشته باشد. بخش «Bidirtional» در نام این مدل، به معنای این است که مدل میتواند متن را از سمت راست و چپ پردازش کند.

مدل BERT میتواند برای چندین کاربرد پردازش زبان طبیعی از جمله «پاسخ به پرسشها» (QA)، «تحلیل احساسات» (Sentiment Analysis)، «موجودیتهای نامدار» (Named Entity) و موارد دیگری Fine-Tune شود، در ادامه به معرفی این کاربردها میپردازیم.
پاسخ به پرسشها (Question Answering)
BERT بر روی مجموعه دادههای «پاسخ به پرسشها» (QA)، Fine-Tune شده است، که این امکان را به مدل میدهد تا بر اساس یک متن یا مستندات داده شده، به پرسشها پاسخ دهد. این مسئله در هوش مصنوعی محاورهای و چتباتها استفاده میشود که BERT به سیستم این امکان را میدهد تا پرسشها را با دقت بیشتری درک کرده و پاسخ دهد.
کاربرد BERT در جستجو
مدل BERT برای بهبود مرتبط بودن نتایج جستجو با درک متن براساس کلمات مورد نظر (Query)، استفاده میشود. گوگل BERT را در الگوریتم جستجو خود پیادهسازی کرده است، که منجر به بهبود قابل توجهی در مرتبط بودن جستجو آن شده است.
کاربرد BERT در تحلیل احساسات Sentiment Analysis
از مدل برت میتوان برای وظیفه Sentiment Analysis استفاده کرد. تحلیل احساسات فرایند بررسی عواطف موجود در متن و طبقهبندی آنها به عنوان مثبت، منفی یا خنثی است. با اجرای تجزیه و تحلیل احساسات در پستهای رسانههای اجتماعی، دیدگاههای محصول، نظرسنجیها و بازخورد مشتریان، کسبوکارها میتوانند شواهد ارزشمند بودن سرمایه خود را درباره چگونگی درک برند آنها توسط مشتریان دریافت کنند.
طبقه بندی متن Text Classification
مدل BERT میتواند برای وظایف طبقهبندی متنی، مانند «تحلیل احساسات» (Sentiment Analysis)، Fine-Tune شود که این امکان را به آن میدهد تا به احساس یک متن مورد نظر بپردازد. این مسئله کاربرد زیادی در بازاریابی و خدمات مشتری دارد. به عنوان مثال، فروشگاه آنلاین Wayfare از BERT برای پردازش سریعتر و موثرتر پیامهای مشتریان استفاده میکند.
مدل زبانی MT-NLG توسعه داده شده توسط انویدیا و مایکروسافت
مدل MT-NLG خلاصه شده (Megatron-Turing Natural Language Generation) یک مدل زبان پیشرفته و قدرتمند است که بر اساس معماری ترانسفورمر ساخته شده است. این مدل قادر به انجام گسترهای از وظایف زبان طبیعی از جمله استنتاجهای زبان طبیعی و درک مطالب میباشد.

این مدل آخرین نسخه از مدلهای زبانی هوش مصنوعی توسعه داده شده توسط مایکروسافت و انویدیا است و میتواند کارهای زیادی را از جمله تکمیل خودکار جملات، درک استدلهای مشترک و درک متن انجام دهد.

مدل MT-NLG با استفاده از 15 مجموعه داده که هر کدام شامل 339 میلیارد توکن (کلمه) از وبسایتهای انگلیسی زبان بوده، آموزش داده شده است. سپس این دادهها به 270 میلیارد توکن کاهش یافتهاند. برای آموزش این مدل از سوپرکامپیوتر Selene ML شرکت Nvidia استفاده شد که شامل 560 سرور هرکدام با 8 GPU A100 80GB مجهز میباشد.
MT-NLG یک مدل تازه توسعه داده شده است، بنابراین تاکنون ممکن است کاربردهای واقعی زیادی برای آن وجود نداشته باشد. با این حال، سازندگان مدل این ادعا را دارند که این مدل پتانسیلی برای تحول فناوری و محصولات پردازش زبان طبیعی در آینده را دارد.
مدل LaMDA از گوگل چیست ؟
لامدا یا LaMDA، یک مدل زبان برای برنامههای گفتگویی است که توسط گوگل توسعه داده شده است. این مدل برای تولید دیالوگ مکالمهای به صورت آزاد طراحی شده است، که آن را به مدلهای کلاسیک (که معمولاً مبتنی بر وظایف هستند)، طبیعیتر و پیچیدهتر میکند.
پس از ادعای یک مهندس گوگل که این مدل به نظر میرسد هوشمند است، به دلیل قابلیت ارائه پاسخهایی که نشان میدهد مدل درکی از طبیعت خودش دارد، این مدل توجه بسیاری را به خود جلب کرده است.
لامدا با دادههای گفتگویی با 137 میلیارد پارامتر آموزش داده شده است. این موضوع به مدل اجازه میدهد تا به نکات پیچیده و طبیعی گفتگو توجه کند. گوگل قصد دارد از این مدل در محصولات خود، از جمله جستجو، Google Assistant و Workspace استفاده کند.
در رویداد I/O 2022، شرکت گوگل نسخه بهبودیافته این مدل را یعنی LaMDA 2 را معرفی کرد که به صورت دقیقتر و با توانایی ارائه پیشنهادات بر اساس پرسشهای کاربر، آموزش داده شده بود. LaMDA 2 بر روی مدل زبانی Pathways گوگل (PaLM) با 540 میلیارد پارامتر آموزش داده شده است.
محدودیت های فعلی مدل های زبانی چیست و روند آینده آن چگونه است؟
قابلیتهای Language Model ها مانند GPT-3 به سطحی رسیدهاند که تعیین محدودیت قابلیتهای آنها دشوار است، زیرا با استفاده از شبکههای عصبی قدرتمند میتوانند مقالات را ترکیب کنند، کد نرمافزار را توسعه دهند و در مکالماتی شرکت کنند که شباهت زیادی به تعاملات انسان دارد.
شخص ممکن است شروع به فرض کند که این مدلها دارای توانایی استدلال و برنامهریزی مانند انسانها هستند. همچنین، احتمال وجود نگرانیها وجود دارد که این مدلها به گونهای پیشرفته شوند که میتوانند به جای انسانها در کارهای آنها جایگزین شوند. بیایید بر محدودیتهای کنونی مدلهای زبانی توضیح دهیم تا نشان دهیم که این مدلها هنوز به آنجا نرسیدهاند.
محدودیتهای کنونی مدل های زبانی چیست ؟
مدلهای زبانی دنیا را تحت تأثیر خود قرار دادهاند و در حال حاضر در حاشیهنشینی به سر میبرند، اما این به این معنا نیست که آنها تمامی کارهای پردازش زبان طبیعی را به تنهایی انجام میدهند.
Language Model ها در حوزه استدلال عمومی شکست میخورند. با وجود پیشرفت مدلهای هوش مصنوعی، قدرت استدلال آنها هنوز به نحو مناسبی توسعه نیافته است. این محدودیت شامل استدلال عمومی، استدلال منطقی و استدلال اخلاقی است.

مدلهای زبانی با برنامه ریزی و تفکر روشمند عملکرد ضعیفی دارند. بر اساس تحقیقاتی که توسط دانشمندان دانشگاه ایالت آریزونا، تمپه انجام شده است، ثابت شده است که هنگامی که به تفکر سیستماتیک و برنامهریزی میپردازد، مدلهای زبانی کارایی نامناسبی دارند و اشتراک بسیاری از کمبودهای حاضر در سیستمهای یادگیری عمیق فعلی را دارا هستند.
مدلهای زبانی ممکن است پاسخهای نادرستی ارائه دهند. برای مثال، در پاسخ به برخی سوالات هنگام استفاده از ChatGPT، پلتفرم Stack Overflow آن را ممنوع کرده است، زیرا باعث ورود جوابها و محتواهای اشتباهی شده است. این پلتفرم بیان کرده است:
به دلیل اینکه میانگین دریافت پاسخهای صحیح از ChatGPT خیلی کم است، ارسال پاسخهای ایجاد شده توسط ChatGPT برای سایت و کاربرانی که درخواست و جستجوی پاسخهای درست میکنند، آسیب زیادی به آنها وارد میکند
مدلهای زبانی ممکن است حرف بیمعنی بزنند و این کار را با اعتماد به نفس بالا انجام میدهند، زیرا آنها نمیدانند کدام دانش اشتباه است. بر خلاف مدلهای دیگر، ChatGPT میتواند این ادراک را داشته باشد که اشتباه است. اما در برخی موارد ChatGPT هنوز پس از اینکه به اشتباهات آن اشاره کردیم، پاسخهای نادرستی ارائه میدهد.
این مسئله زمانی بدتر میشود که امکان دارد اطلاعات بیمعنایی که مدلهای زبانی ارائه میدهند برای افرادی که در زمینه آن تخصصی ندارند، به سادگی قابل درک نباشد و فرض بر درستی اطلاعات داشته باشند.
مدلهای زبانی نمیتوانند مفهوم دقیقی از اینکه چه چیزی را میگویند بدست آورند. این مدلها تنها در شرایط مناسب میتوانند زبان انسان را تقلید کنند، اما نمیتوانند مفهوم متن را به خصوص در مورد مفاهیم انتزاعی به خوبی درک کنند.
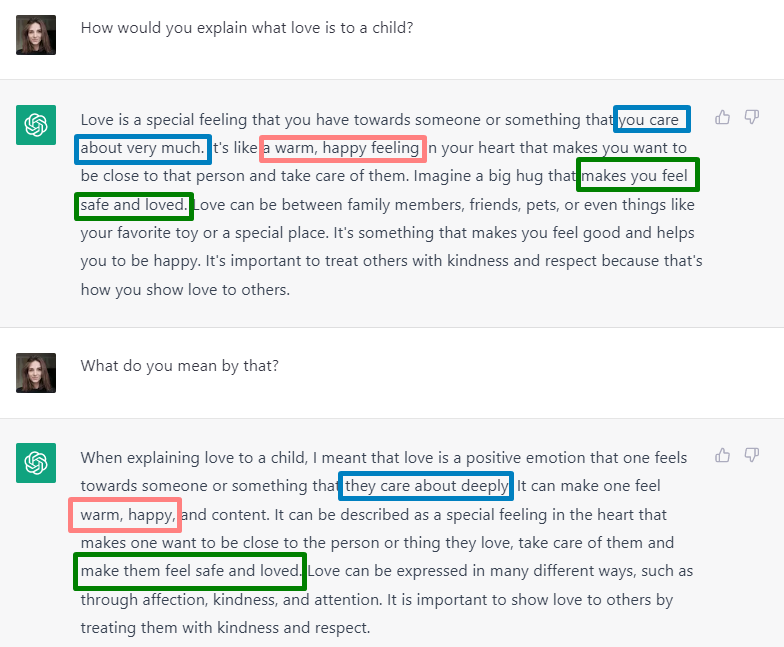
همانطور که مشاهده میکنیم، مدل به سادگی بدون هیچ درکی از آنچه میگوید، حرف خود را در پاسخهای مختلف که با رنگهای یکسان مشخص شده است، تکرار میکند.
Language modelها میتوانند محتوای تبعیضآمیز یا کلیشهای ایجاد کنند. به دلیل وجود تعصبات در دادههای ورودی آموزشی، مدلهای زبانی به صورت منفی بر افراد و گروههایی خاص تأثیر میگذارند و با افزایش تصویرهای نادرست و ایجاد نمایشهای تحقیرآمیز، باعث ایجاد پیامدهای مضر میشوند.
با این تفاسیر افرادی که از این موضوع میترسند که در آیندهای نزدیک هوش مصنوعی جامع و قدرتمند جهان را به دست بگیرد و آنها را بدون کار رها کند، میتوانند نفسی راحت بکشند.
آینده مدلهای زبانی چیست ؟
در گذشته برنامههای کسب و کار هوش مصنوعی بر وظایف آیندهنگری مانند پیشبینی، تشخیص تقلب، نرخ کلیک، تبدیل یا اتوماسیون وظایف با کمترین مهارتها تمرکز داشتند. این برنامهها دارای محدودیت در دامنه و نیاز به تلاش زیادی برای پیادهسازی صحیح و درک نتایج بودند و معمولاً فقط در مقیاس بزرگ مفید بودند. با این حال، ظهور مدلهای بزرگ زبانی این دینامیک را تغییر داده است.
پیشرفتهای مدلهای بزرگ زبانی مانند GPT-3 و مدلهای تولیدی مانند Midjouney و DALL-E به طور واقعی این صنعت را متحول ساخته است و انتظار میرود که هوش مصنوعی در سالهای آینده بر تقریباً هر جنبهای از کسب و کار تأثیر زیادی داشته باشد.
در ادامه برخی از قابل توجهترین گرایشها برای مدلهای زبانی را بررسی میکنیم.
- مقیاس و پیچیدگی: احتمالاً مدلهای زبانی در زمینه حجم دادهای که بر آنها آموزش داده میشوند و تعداد پارامترهایی که دارند، به دنبال افزایش هستند.
- قابلیتهای چند وجهی: انتظار میرود که مدلهای زبانی با سایر رسانهها مانند تصاویر، ویدئو و صدا یکپارچه شوند تا درک بهتری از دنیا داشته باشند و برای برنامههای جدید قابل استفاده باشند.
- قابلیت توضیح و شفافیت: با استفاده روز افزون از هوش مصنوعی در تصمیمگیری، نیاز به شفافیت و توضیحی برای مدلهای یادگیری ماشینی افزایش مییابد. محققان در حال کار بر روی روشهایی هستند تا مدلهای زبانی قابل تفسیرتر شوند و دلایل پشت پیشبینیهای آنها را درک کنند.
- تعامل و گفتگو: در آینده، انتظار میرود که مدلهای زبانی در محیطهای تعاملی مانند چتباتها، دستیار های مجازی و خدمات مشتریان بیشتر مورد استفاده قرار گیرند، جایی که آنها قادر به درک و پاسخ به ورودی کاربر در یک شیوه طبیعیتر خواهند بود.
در کل، انتظار میرود که مدلهای زبانی به رشد و بهبود خود ادامه دهند و در تعداد بیشتری از برنامهها در دامنههای مختلف استفاده شوند.

جمعبندی
یک مدل زبانی دقیقاً همان کاری را انجام میدهدکه برای انجام آن آموزش دیده است، نه بیشتر و نه کمتر. برخی از مدلها برای استخراج پاسخ از متن و برخی دیگر برای تولید پاسخ از ابتدا آموزش دیدهاند. برخی برای خلاصه کردن متن آموزش دیدهاند و برخی دیگر به سادگی یاد میگیرند که زبان را چگونه نشان دهند. در این مطلب به معرفی مدل زبانی به زبان ساده و روان و بررسی انواع آن پرداختیم، همچنین از تواناییها و ناتوانی مدلهای زبانی برای انجام برخی وظایف و کاربردهای فراوان آنها در فناوریهای مختلف از جمله ChatGPT آگاه شدیم.
مدلهای زبانی زیرشاخهای از حیطه پردازش زبانهای طبیعی یا NLP به حساب میآید، در صورت علاقهمندی به این حوزه لازم است مفاهیمی از هوش مصنوعی، ماشین لرنینگ و پردازش زبان طبیعی را فرا بگیرید، علاوه بر آن، ورود به این شاخه نیازمند داشتن درک عمیقی نسبت به برنامه نویسی است که خود گستردگی زیادی دارد و لازم است برای شروع پیش نیازهای برنامه نویسی را بیاموزیم و طبق نقشه راه برنامه نویسی قدم به قدم پا به دنیای فناوری بگذاریم.
سوالات متداول در مورد مدلهای زبانی چیست ؟
در این بخش به چندین سوال رایج پیرامون مدلهای زبانی هوش مصنوعی یا Language Models پاسخ میدهیم.
برنامه نویسی هوش مصنوعی چیست ؟
برنامه نویسی هوش مصنوعی روشی برای پیادهسازی پروژههای هوش مصنوعی و یادگیری ماشین است که امروزه یکی از مهمترین و پرکاربردترین حوزهها در علوم کامپیوتر به حساب میآید. هوش مصنوعی دارای بخشهای زیادی از جمله یادگیری عمیق و شبکههای عصبی است که با استفاده از آنها میتوان پروژههای هوش مصنوعی را پیادهسازی کرد.
مدل زبانی در chatGPT چه کاربردی دارد ؟
مدل زبانی در ChatGPT وظیفه تولید متن جدید با توجه به متن ورودی و همچنین پیشبینی کلمات بعدی در یک جمله را دارد. این مدل زبانی با بهرهگیری از شبکه های عصبی، قادر به پردازش و فهمیدن متون بلند و پیچیده است. همچنین مدل زبانی به عنوان یکی از قدرتمندترین روشها برای پردازش زبان طبیعی شناخته میشود و در زمینههای مختلفی از جمله ترجمه ماشینی، خلاصهسازی متن، پاسخگویی به سوالات و تولید محتوا به کار میرود. در ChatGPT به دلیل قابلیت انعطافپذیری و توانایی تولید متن با کیفیت بالا، از این مدل زبانی برای تولید پاسخهای هوشمند به سوالات کاربران استفاده میشود.
تفاوت هوش مصنوعی و یادگیری ماشین چیست ؟
هوش مصنوعی به معنای هوشمند کردن ماشینها و دستگاههایی است که توسط انسان ساخته میشوند اما یادگیری ماشین به روشهای یادگیری وظایف ماشینی با استفاده از این الگوریتمها و مدلها گفته میشود. به عبارتی، هوش مصنوعی شاخهای از علوم کامپیوتر است که با استفاده از آن میتوان ماشینهایی ساخت که مشابه انسان هوشمندانه رفتار کنند و موضوعات جدید را یاد بگیرند و با تجزیه و تحلیل اطلاعات ورودیشان، بدون نیاز به دخالت انسان به تصمیمگیری بپردازند. در مقابل، یادگیری ماشین زیرشاخهای از هوش مصنوعی است و سیستمهای مصنوعی هوشمند به منظور یادگیری مسائل، از روشهای یادگیری ماشین استفاده میکنند.
مدل زبانی gpt-3 چیست ؟
GPT-3 یک مدل زبانی عمیق محسوب میشود که توسط شرکت OpenAI توسعه داده شده است. این مدل از ساختار Transformer برای پردازش زبان طبیعی استفاده میکند و قادر است به صورت خودکار متنهای طولانی و با کیفیت تولید کند و بهترین پاسخها را به سؤالات مطرح شده ارائه دهد. کاربردهای GPT-3 شامل تولید محتوا، پاسخ به سؤالات، ترجمه متون، تولید شعر و موسیقی، پرسش و پاسخ در موضوعات مختلف، طراحی دیالوگ و گفتگوی خودکار با رباتها و موارد دیگر است.









سلام
من تازه وارد در دنیای یادگیری ماشین و هوش مصنوعی مولد هستم و مطالب این پست خیلی خوب بود. اگر امکان داشت با جزئیات بیشتر به مدل های زبانی پرداخته بشه عالی میشه.
بازم ممنونم