



تشخیص گفتار در متلب – به زبان ساده
درک گفتار انسان توسط ماشین به عنوان یکی از اهداف اصلی «هوش مصنوعی» (Artificial Intelligence) محسوب میشود. در میان پژوهشهایی که در این راستا انجام شده است، میتوان «تشخیص گفتار» (Speech Recognition) را به عنوان یکی از شاخههای مطالعاتی این حوزه درنظر گرفت که هم پردازش گفتار و هم پردازش متن را شامل میشود. در مطلب حاضر سعی داریم به مقدمه کوتاهی از تشخیص گفتار بپردازیم و کاربرد این سیستمها و مزایا و معایب آنها را شرح دهیم. در انتهای مطلب نیز با استفاده از الگوریتم های یادگیری عمیق به پیادهسازی یک سیستم تشخیص گفتار در متلب خواهیم پرداخت.
- یاد میگیرید ساختار و کارکرد سیستمهای تشخیص گفتار را تحلیل کنید.
- میآموزید مراحل عملی و فنی پیادهسازی سیستم تشخیص گفتار در متلب چیست.
- یاد میگیرید داده صوتی را به spectrogram و ویژگیهای آن تبدیل کنید.
- میآموزید با استفاده از دادهٔ اعتبارسنجی، دقت مدل را ارزیابی کنید.
- مزایا، معایب و چالشهای سیستمهای تشخیص گفتار را تحلیل خواهید کرد.
- با مزیت تجربه عملی در پروژههای AI و متلب بیشتر آشنا میشوید.




مقدمات و پیش درآمد تشخیص گفتار در متلب
در این بخش ابتدا به مباحث مقدماتی و پیش نیاز تشخیص گفتار در متلب پرداخته میشود و سپس در بخش بعدی به بحث اصلی پرداخته شده است.
تشخیص گفتار چیست ؟
تشخیص گفتار یکی از مسائل حوزه هوش مصنوعی محسوب میشود که هدف آن طراحی سیستمهای هوشمندی است که قادر باشند صدای (کلام) انسان را تشخیص دهند و آن را به قالبی تبدیل کنند که برای ماشین قابل درک باشد. برخی از شرکتها مانند Siri ،Alexa ،Google و Cortana از فناوریهای نوینی نظیر هوش مصنوعی، «یادگیری ماشین» (Machine Learning)، «یادگیری عمیق» (Deep Learning) و «شبکههای عصبی» (Neural Networks) برای توسعه برنامههای تشخیص گفتار استفاده میکنند.
همین امر تغییر و تحولاتی در نحوه استفاده از دستگاههای سختافزاری و ابزارهای الکترونیکی مانند گوشیهای هوشمند، ابزارهای امنیتی منازل، خودروها و مواردی از این قبیل به وجود آورده است.
 در اینجا لازم است یادآوری شود که مسئله تشخیص گفتار با مسئله «تشخیص صدا» (Voice Recognition) تفاوت دارد. در تشخیص گفتار به دنبال این هستیم که سیستمی را طراحی کنیم تا قادر به ضبط صدای افراد مختلف با زبانها و گویشهای متفاوت و سپس تشخیص کلمات فایل صوتی باشد و در نهایت بتواند کلمات صوتی تشخیص داده شده را به متن تبدیل کند.
در اینجا لازم است یادآوری شود که مسئله تشخیص گفتار با مسئله «تشخیص صدا» (Voice Recognition) تفاوت دارد. در تشخیص گفتار به دنبال این هستیم که سیستمی را طراحی کنیم تا قادر به ضبط صدای افراد مختلف با زبانها و گویشهای متفاوت و سپس تشخیص کلمات فایل صوتی باشد و در نهایت بتواند کلمات صوتی تشخیص داده شده را به متن تبدیل کند.
در مقابل، هدف از مسئله تشخیص صدا، تشخیص صداهایی است که از قبل برای سیستم تعریف شده باشند. به عبارتی، سیستمهای تشخیص صدا صرفاً برای بازشناسی گفتار افراد محدودی طراحی میشوند. همچنین، دایره لغات و جملاتی که این سیستمها قادر به تشخیص هستند نیز بسیار محدود است. سیستمهای الکترونیکی که با دستورات محدودی نظیر «روشن شو»، «خاموش شو»، «دمای هوا را به ۲۵ درجه سانتیگراد تغییر بده» کار میکنند، مجهز به برنامه تشخیص صدا هستند.
سیستم تشخیص گفتار چگونه کار می کند ؟
سیستمهای تشخیص گفتار شامل فرآیند پیچیدهای هستند و از ۴ مرحله اصلی تشکیل شدهاند. در مرحله اول، مدل باید کلمات موجود در گفتار را تشخیص دهد که برای این کار لازم است فایل صوتی ورودی، به قطعات کوچکتر تقسیم شود. سپس، سیستم تشخیص گفتار باید کلمات تشخیص داده شده را به متن تبدیل کند. در گام بعدی، سیستم تشخیص گفتار باید معنای جمله گفته شده را مشخص کند و در مرحله نهایی، با توجه به معنای مشخص شده، اقدام مرتبط را انجام دهد.
کاربردهای سیستم های تشخیص گفتار
از سیستمهای تشخیص گفتار در بسیاری از سازمانها استفاده میشود. یکی از مراکزی که از این سیستمها بهره میبرند، مرکز تماس شرکتها هستند. سیستم تشخیص گفتار در این مراکز به پیامهای صوتی مشتریان گوش میدهند و مطابق با نیازمندیهای آنها، خدمات و مشاورههایی ارائه میدهند.
بانکها نیز از دیگر سازمانهایی هستند که میتوانند از سیستم تشخیص گفتار برای راهنمایی و پاسخدهی به سوالات مشتریان درباره حساب بانکی خود استفاده کنند.
بیمارستانها و مراکز درمانی نیز میتوانند از سیستمهای تشخیص گفتار به منظور خدماتدهی بهتر به بیماران استفاده کنند. به عبارتی، بیماران برای ارتباط با پزشک و پرستار میتوانند درخواست خود را به سیستمهای تشخیص گفتار بدهند. بهعلاوه، این سیستمها میتوانند شرح حال بیماران را ثبت کنند و پزشکان میتوانند با اطلاعات ثبت شده در این سیستمها، از وضعیت جسمانی بیماران آگاه شوند.
کاربرد رایج دیگر سیستمهای تشخیص گفتار در فضای اینترنت و رسانههای اجتماعی است. کاربران میتوانند بدون نیاز به تایپ کردن، صحبتهای خود را با استفاده از چنین برنامههایی به متن تبدیل و آنها را برای دوستان ارسال کنند یا در رسانههای اجتماعی با دیگر افراد به اشتراک بگذارند.
مزایای سیستم تشخیص گفتار
در بخش مربوط به کاربردهای سیستم تشخیص گفتار، به تاثیرات مثبت این سیستمها در حوزههای مختلف زندگی بشر پرداخته شد. در ادامه نیز، به برخی از مهمترین مزیتهای این سیستمها اشاره میکنیم:
- برقراری ارتباط بین ماشین و انسان: با استفاده از سیستم تشخیص گفتار، انسان میتواند به زبان خود با سیستم به مکالمه بپردازد.
- دسترسی آسان: سیستمهای تشخیص گفتار از طریق برنامههای مختلف نرمافزاری بر روی کامپیوتر و گوشیهای هوشمند بهسادگی قابل دسترس هستند.
- استفاده آسان: افراد میتوانند بهسادگی از سیستمهای تشخیص گفتار بر روی دستگاههای شخصی خود نظیر گوشی هوشمند و کامپیوتر استفاده کنند و کار با این سیستمها به دانش خاصی احتیاج ندارد.
- سرعت بخشیدن در انجام کار: صحبت کردن به مراتب خیلی سریعتر از عمل نوشتن اتفاق میافتد. بدین ترتیب، میتوان در کوتاهترین زمان، با صحبت کردن از سیستمهای کامپیوتری درخواست کرد عمل خاصی را انجام دهند.
- تسهیل در انجام امور افرادی با نقص جسمی: سیستمهای تشخیص گفتار میتوانند در انجام امور مختلف به افرادی کمک کنند که دارای نقص جسمی هستند. کافی است این افراد با مکالمه با این سیستمها ارتباط برقرار کنند تا درخواستشان انجام شود.

معایب سیستم تشخیص گفتار
علاوهبر مزایای مطرح شده درباره سیستمهای تشخیص گفتار، میتوان به برخی از مهمترین نقاط ضعف این سیستمها اشاره کرد:
- عملکرد ضعیف: سیستمهای تشخیص گفتار ممکن است به دلایل مختلفی نظیر تنوع لهجهها و گویشهای زبانی، عدم پشتیبانی از برخی زبانها و وجود نویزهای محیط قادر به تشخیص گفتار با دقت بالا نباشند.
- مشکلات فایلهای منبع: سیستمهای تشخیص گفتار در صورتی میتوانند بهخوبی عمل کنند که تجهیزات ضبط صدای قوی داشته باشند. چنانچه این سیستمها نتوانند بهدرستی گفتار ورودی را ضبط کنند، قادر نخواهد بود گفتار را بهدرستی تشخیص دهند و در پی آن، اقدام درستی را در قبال درخواست کاربر انجام نخواهند داد.
- سرعت پایین آمادهسازی سیستم: برخی از سیستمهای تشخیص گفتار بسیار سنگین و پیچیده هستند و به زمان زیادی احتیاج است تا بتوان آنها را در دسترس کاربران قرار داد.
الگوریتم های تشخیص گفتار
به منظور طراحی و پیادهسازی یک سیستم تشخیص گفتار میتوان از روشهای مختلفی استفاده کرد که در ادامه به آنها اشاره میشود:
- «مدل مخفی مارکوف» (Hidden Markov Model | HMM): از این روش زمانی استفاده میشود که بخواهیم سیستمی را به گونهای طراحی کنیم که تمامی اطلاعات برای تصمیمگیری مدل را در دست نداشته باشد. این روش، یک روش احتمالاتی است که در سیستم تشخیص گفتار میتوان از آن برای تطبیق دادن واحدهای زبانی با هر یک از سیگنالهای صوتی به منظور بازشناسی گفتار استفاده کرد.
- روش N-grams: این روش، به عنوان سادهترین روش برای ساخت مدل زبانی به شمار میرود که توزیع احتمالاتی جمله یا عبارت را مشخص میکند. این مدل زبانی با توجه به دادههای فعلی، مشخص میکند احتمال وقوع چه کلمهای در ادامه جمله بیشتر است.
- مدلهای هوش مصنوعی: الگوریتم های یادگیری عمیق و الگوریتم های یادگیری ماشین در پیادهسازی سیستمهای تشخیص گفتار کاربرد بسیار دارند. این مدلها از اطلاعاتی نظیر دستور زبان و ویژگی ساختاری کلمات و اطلاعات سیگنال صوتی به منظور پردازش گفتار استفاده میکنند.

در مطلب حاضر قصد داریم از روش هوش مصنوعی به منظور پیادهسازی سیستم تشخیص گفتار در متلب استفاده کنیم. در ادامه، به مراحل پیادهسازی این سیستم خواهیم پرداخت.
آموزش مقدماتی تشخیص گفتار در متلب با مثال
در این بخش با استفاده از مدل یادگیری عمیق، مثالی از تشخیص گفتار در متلب ارائه میکنیم. متلب همانند زبان برنامه نویسی Python به عنوان یکی از زبانهای برنامه نویسی رایج در حوزه هوش مصنوعی به شمار میرود و امکانات و ابزارهای مختلفی را برای پیادهسازی مدلهای هوش مصنوعی در اختیار کاربران خود قرار میدهد. در ادامه، به مراحل مختلف طراحی سیستم تشخیص گفتار، از بارگذاری داده در برنامه تا ارزیابی مدل، خواهیم پرداخت.
بارگذاری داده
برای پیادهسازی یک سیستم Speech Recognition در متلب در ابتدا دادههای آموزشی مدل را در برنامه بارگذاری کنیم. در مثال حاضر، از دادههای Google Speech Commands استفاده میکنیم. با استفاده از قطعه کد زیر، دادهها را دانلود و سپس آنها را از حالت فشرده (Zip) خارج میکنیم.
مدل تشخیص گفتار در متلب باید قادر باشد علاوهبر کلمات، نویز محیط و لحظات سکوت گوینده را نیز تشخیص دهد. بدین منظور، میتوان از تابعی با نام augmentDataset استفاده کرد. این تابع برای تشخیص صدای نویز، از فایل موجود در فولدر background در دیتاست Google Speech Commands استفاده میکند.
از تابع audioDatastoreمیتوان برای تعیین دادههای آموزشی مدل تشخیص گفتار در متلب بهصورت زیر استفاده کرد:
با استفاده از قطعه کد زیر میتوان کلماتی را تعریف کرد که مدل باید آنها را به عنوان «دستور» (Command) شناسایی کند تا در ازای تشخیص این کلمات در صوت، اقدامی را انجام دهد. همچنین، تمامی فایلهای صوتی را که شامل نویز هستند یا کلمات «دستور» (Command) را ندارند، باید با برچسب unknownمشخص شوند.
بخشی از دادههای مدل تشخیص گفتار در متلب را نیز به عنوان «دادههای اعتبارسنجی» (Validation Sets) در نظر میگیریم تا عملکرد مدل را بر روی آنها بسنجیم.
با استفاده از قطعه کد زیر میتوان توزیع دادههای آموزشی و دادههای اعتبارسنجی را در متلب ملاحظه کرد.
خروجی قطعه کد فوق را در قالب نمودار در تصویر زیر ملاحظه میکنید:
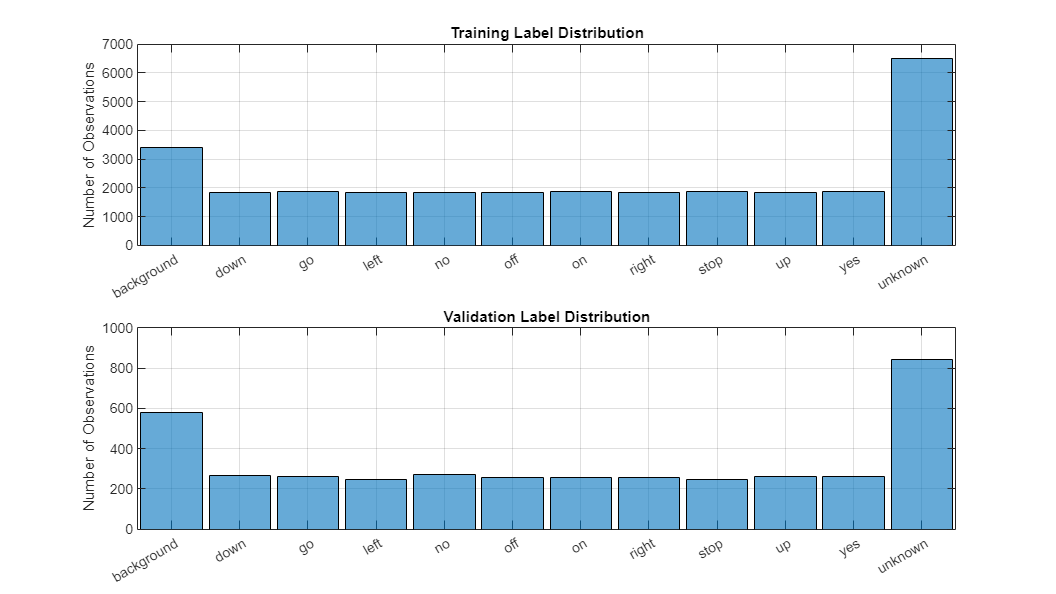
آماده سازی داده برای آموزش مدل تشخیص گفتار در متلب
در مثال فعلی از تشخیص گفتار در متلب، از «شبکه عصبی پیچشی» (Convolutional Neural Network | CNN) استفاده میکنیم. بدین منظور باید دادههای صوتی را به «طیفنگارهای صوتی» (Auditory Spectrograms) تبدیل کنیم. در این راستا لازم است پارامترهایی را نظیر فهرست زیر تعریف کنیم:
- پارامتر segmentDuration: این پارامتر مدت زمان هر فایل صوتی را بر حسب ثانیه مشخص میکند.
- پارامتر frameDuration: این پارامتر مدت زمان هر فریم برای محاسبه طیف را تعیین میکند.
- hopDuration: این پارامتر گام زمانی بین هر طیف را مشخص میکند.
- numBands: این پارامتر تعداد فیلترهای طیفنگار صوتی را تعریف میکند.
قطعه کد زیر، مقداردهی هر یک از پارامترهای تعریف شده را در متلب نشان میدهد.
پس از تعریف پارامترها، با استفاده از تابع audioFeatureExtractiorمیتوان از فایلهای صوتی، ویژگیهایی لازم برای مدل را با قطعه کد زیر استخراج کرد:
در این بخش لازم است از یک سری لایه «تبدیل» (Transform) استفاده کرد تا طول فایلهای صوتی را در وهله نخست، یکسان کنیم و سپس از آنها ویژگیهای مورد نیاز مدل را استخراج و در نهایت بر روی آنها تغییرات لگارتیمی اعمال شود.
بدین منظور در متلب از قطعه کد زیر میتوان استفاده کرد:
پس از تعریف هر لایه «تبدیل» (Transform) میتوان با استفاده از تابع readallتمامی دادههای آموزشی را به عنوان ورودی به لایههای تبدیل داد تا سه تغییر تعریف شده بر روی دادهها اعمال شوند.
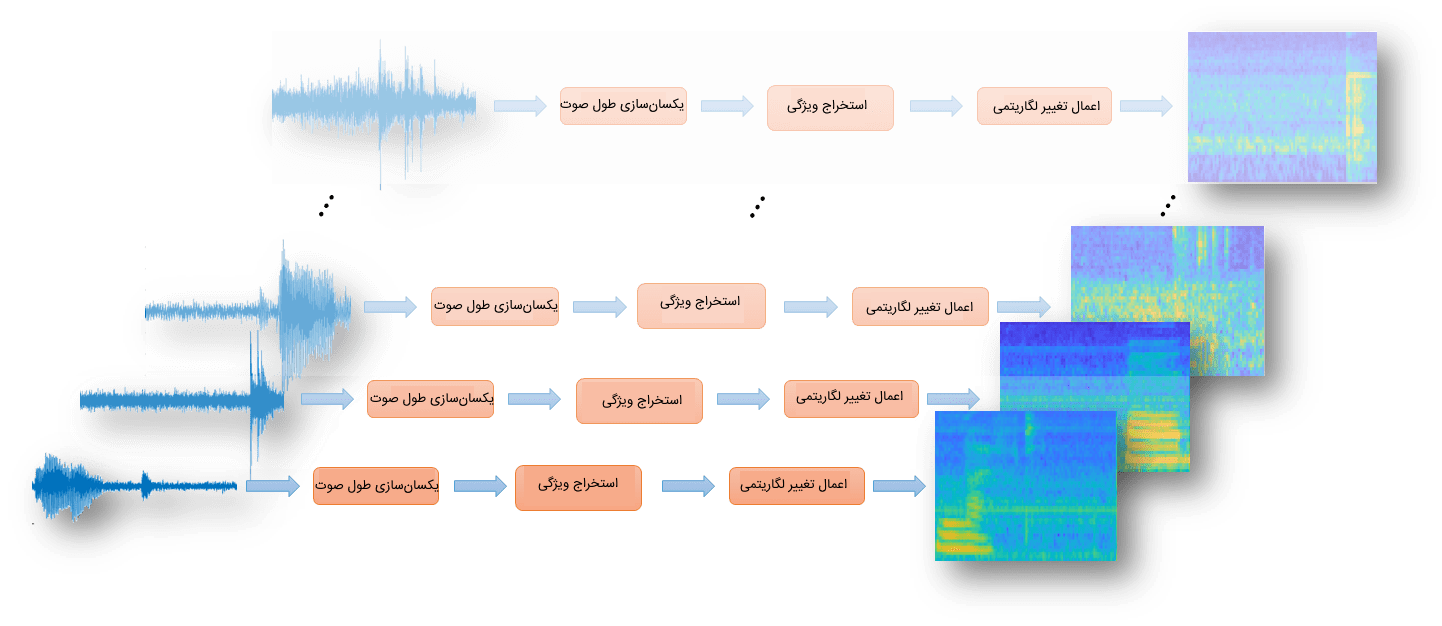
در قطعه کد زیر نحوه استفاده از تابع readallملاحظه میشود:
خروجی حاصل شده از دستور بالا، یک آرایه با طول دادههای آموزشی است که هر سلول آرایه، هر یک از طیفنگارهای صوتی استخراج شده از دادههای صوتی را در بر دارد. در آخر، آرایه حاصل شده را به آرایه ۴ بعدی تبدیل میکنیم:
خروجی حاصل شده را در ادامه ملاحظه میکنید:
numHops = 98
numBands = 50
numChannels = 1
numFiles = 28463مراحل لایههای تبدیل و تغییر بعد را با استفاده از قطعه کد زیر بر روی دادههای اعتبارسنجی نیز اعمال میکنیم:
برچسبهای دادههای آموزشی و دادههای اعتبارسنجی را نیز با استفاده از قطعه کد متلب زیر بهطور مجزا تفکیک میکنیم:
میتوان تعداد کمی از دادههای آموزشی را با استفاده از قطعه کد زیر مصورسازی کرد:
خروجی قطعه کد بالا در تصویر زیر ملاحظه میشود.
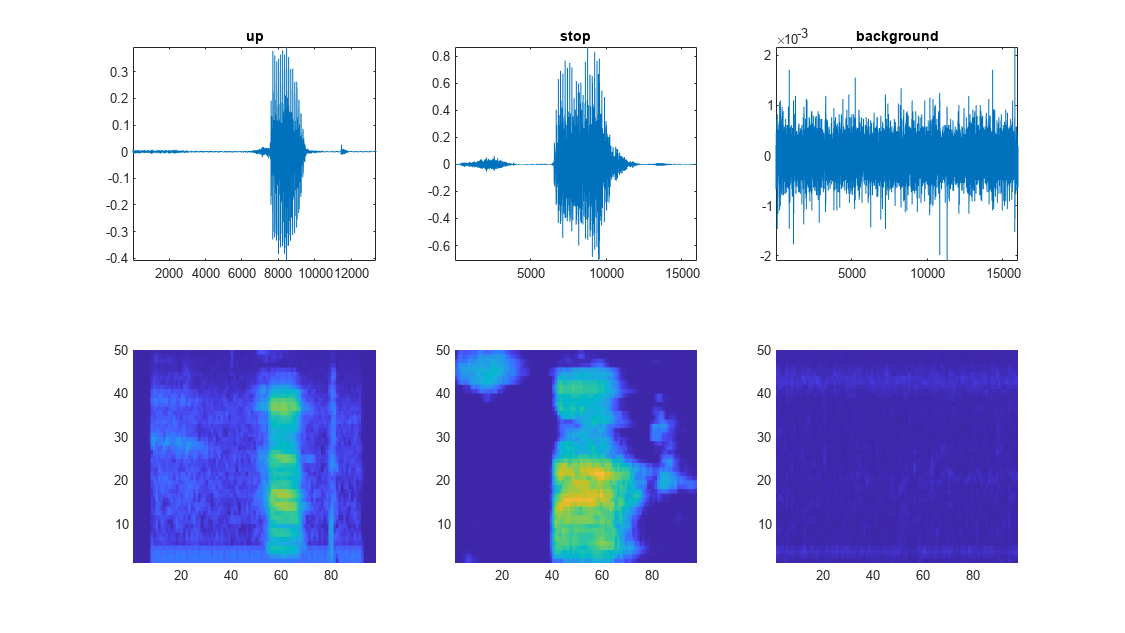
تعریف مدل تشخیص گفتار در متلب
به منظور پیادهسازی سیستم تشخیص گفتار در متلب، از یک معماری ساده شبکه عصبی استفاده کردهایم که شامل ۵ شبکه عصبی پیچشی و یک لایه «تمام متصل» (Fully Connected Layer) میشود.
متغیر numFتعداد فیلترهای شبکههای عصبی پیچشی را مشخص میکند. به منظور افزایش میزان دقت مدل، میتوان تعداد لایههای شبکه عصبی را بالا برد و از تابع فعالسازی ReLU برای مدل استفاده کرد. در تصویر زیر، معماری شبکه عصبی را ملاحظه میکنید.
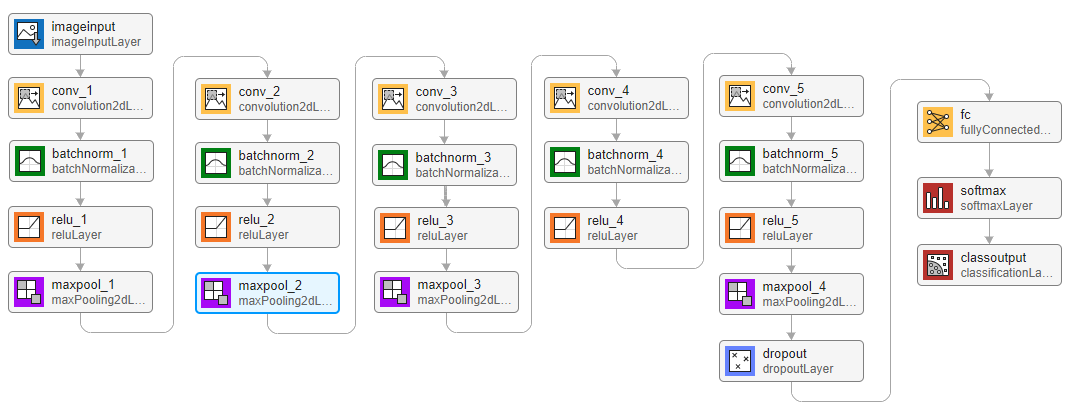
با استفاده از قطعه کد زیر میتوان مدل تشخیص گفتار را در متلب پیادهسازی کرد:
به منظور تنظیم سایر پارامترهای مدل نظیر تابع بهینهسازی، میزان Batch، تعداد Epoch و «نرخ یادگیری» (Learning Rate) میتوان از تابع trainingOptionsبه صورت زیر استفاده کرد:
برای آموزش مدل نیز از تابع trainNetworkبه صورت زیر استفاده میشود:
با اجرای قطعه کدها، آموزش مدل شروع میشود. میزان دقت و مقدار «تابع هزینه» (Loss Function) را در تصویر زیر ملاحظه میکنید:
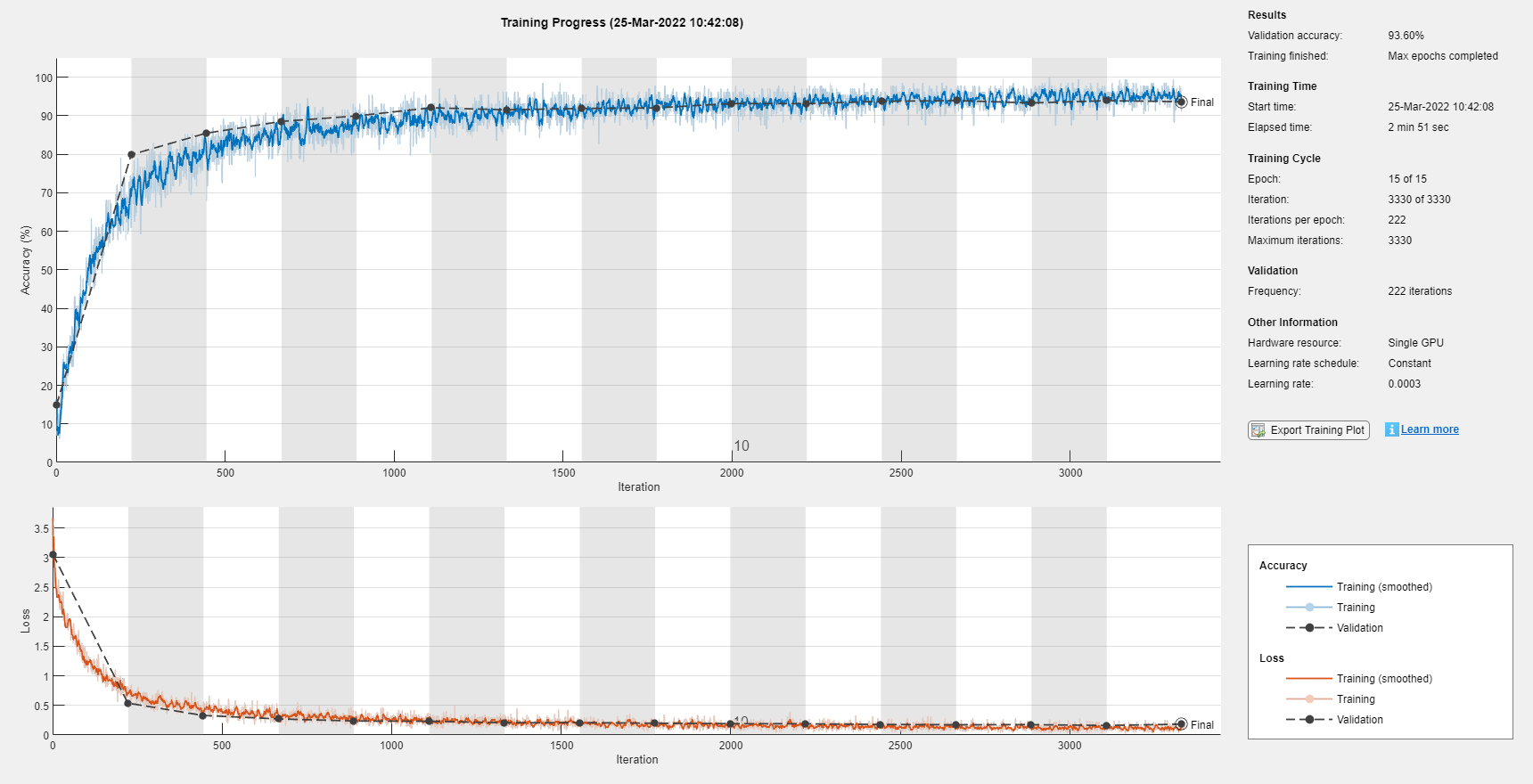
ارزیابی مدل Speech Recognition در متلب
به منظور ارزیابی مدل آموزشی، از دادههای اعتبارسنجی استفاده میکنیم. بدین منظور، در متلب میتوان از تابع classifyبه صورت زیر استفاده کرد:
خروجی قطعه کد بالا در ادامه ملاحظه میشود:
"Training error: 2.7263%"
"Validation error: 6.3968%"برای ملاحظه «ماتریس درهم ریختگی» (Confusion Matrix) نیز میتوان از تابع confusionchartبه صورت زیر استفاده کرد:
نتیجه ماتریس درهم ریختگی را در تصویر زیر ملاحظه میکنید.
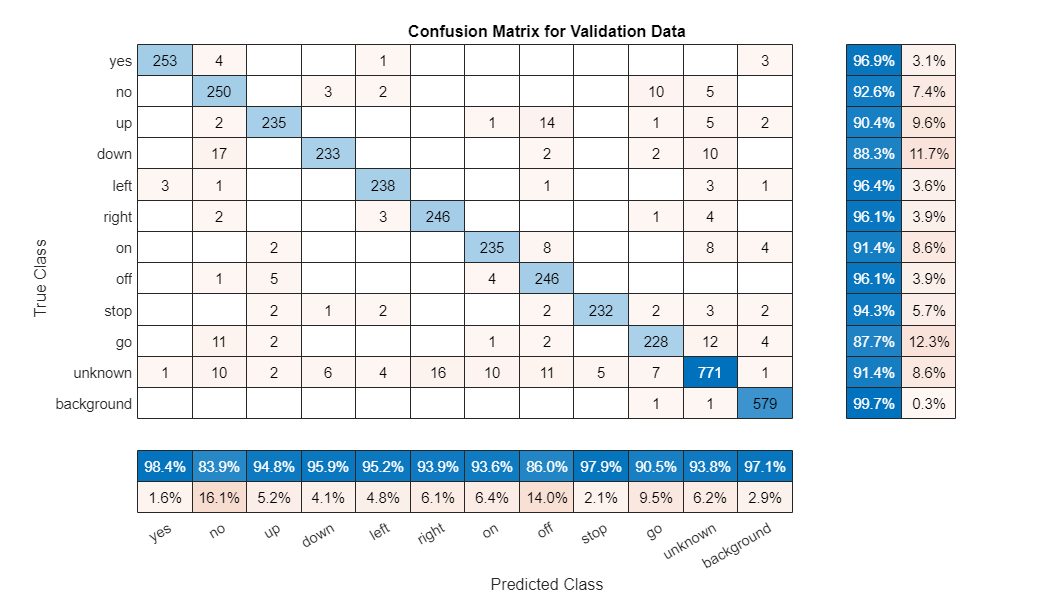
جمعبندی
سیستمهای تشخیص گفتار یکی از سیستمهای هوشمندی هستند که کاربرد موثری در حوزههای مختلف زندگی بشر دارند. استفاده از این سیستمها انجام کارهای مختلفی را برای انسان آسان کرده است. در مطلب حاضر قصد داشتیم بهطور خلاصه به معرفی سیستمهای تشخیص گفتار بپردازیم و نحوه عملکرد آنها و مزایا و معایب آنها را بررسی کنیم.

همچنین، با ارائه یک مثال کاربردی به نحوه پیادهسازی یک سیستم تشخیص گفتار در متلب نیز پرداختیم تا علاقهمندان به این حوزه با طراحی یک شبکه عصبی ساده و کار با دادههای صوتی و پردازش آنها با زبان برنامه نویسی متلب آشنا شوند.









