



پیاده سازی الگوریتم خوشه بندی K–means در پایتون – راهنمای گام به گام
الگوریتم K-means یا همان خوشه بندی K میانگین (K-means Clustering)، یکی از سادهترین و رایجترین الگوریتمهای نوع بدون نظارت یا همان نظارت نشده و خوشه بندی در یادگیری ماشین به حساب میآید. الگوریتم خوشه بندی K-means برای پیدا کردن دستههایی در دادهها مورد استفاده قرار میگیرد که برچسب مشخصی ندارند. K-means میتواند برای تایید فرضیات تجاری درباره اینکه چه نوع دستهها و نظمهایی در دادهها وجود دارند یا برای شناسایی دستههای ناشناخته در مجموعه دادههای پیچیده به کار گرفته شود. در این مقاله، ابتدا به این سوال پاسخ داده میشود که K-means چیست و سپس آموزش پیاده سازی K-means در پایتون به بیان ساده و به صورت گام به گام ارائه شده است.
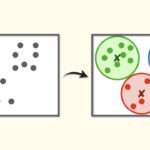
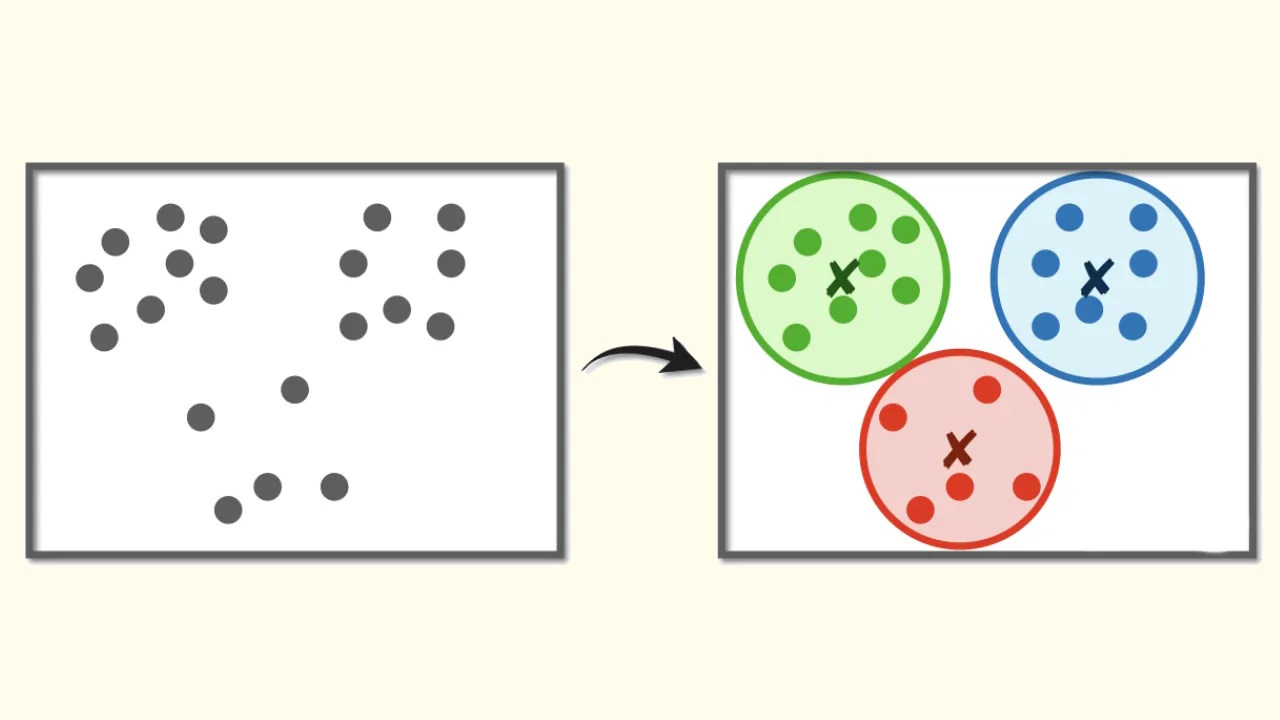


الگوریتم K-means چیست ؟
K-Means یکی از پرکاربردترین الگوریتمهای خوشهبندی دادهها به شمار میرود. در K-means با تکرار اعمالی ثابت و استفاده از توابعی مانند Norm ،Mean و Argmin، میتوان به ازای هر خوشه، مراکزی را یافت که دقت بالا و لَختی (اینرسی) کمی دارند.
هدف در الگوریتم K-means ، کمینهسازی فاصله میان نقطهها (دادهها) در یک خوشه است. K-means یک الگوریتم مبتنی بر مرکز یا مبتنی بر فاصله است که در آن فاصلهها برای تخصیص دادن یک نقطه به یک خوشه محاسبه میشوند. در K-means هر خوشه یک مرکز دارد. هدف اصلی الگوریتم K-means ، کمینهسازی مجموع فاصلههای میان نقاط با مرکز خوشه مربوطه است.
مراحل اجرای الگوریتم K-means چیست ؟
به طور کلی، گامهای اجرای الگوریتم K-means به شرح زیر است:
- تعیین تعداد خوشهها (K)
- انتخاب K عدد تصادفی از دادهها به عنوان مختصات مراکز خوشهها
- تخصیص تمام نقاط (دادهها) به نزدیکترین مرکز خوشه
- انتخاب میانگین وزندار دادههای هر خوشه به عنوان مرکز آن
- تکرار گامهای ۳ و ۴ تا زمانی که معیار توقف برقرار شود.
معیارهای توقف برای الگوریتم K-means چیست ؟
اساساً میتوان سه معیار توقف را برای متوقف کردن حلقه تکرار الگوریتم K-means به کار گرفت. این سه معیار در ادامه فهرست شدهاند:
- مرکزهای خوشههای ایجاد شده جدید تغییر نکنند.
- نقطهها (دادهها) در همان خوشه باقی بمانند و تغییر در عضویت خوشه برای دادهها ایجاد نشود.
- تعداد تکرارها به تعداد تکرار بیشینه (تعیین شده) برسد.
رابطه ریاضی الگوریتم K-means چیست ؟
این الگوریتم، به زبان ریاضی، به شکل زیر در خواهد آمد:
در ادامه مقاله K-means چیست ، پیاده سازی این الگوریتم در پایتون آموزش داده شده است. اما پیش از آن، مجموعه دورههای آموزش داده کاوی و یادگیری ماشین فرادرس به علاقهمندان به این حوزه معرفی شده است.
پیاده سازی K-means در پایتون
در این بخش از مقاله K-means چیست آموزش پیاده سازی الگوریتم K-means در پایتون به صورت گام به گام ارائه شده است. گام اول، فراخوانی کتابخانههای مورد استفاده است.
فراخوانی کتابخانهها برای پیاده سازی الگوریتم K-means در پایتون
پیاده سازی الگوریتم K-means در پایتون از کتابخانههای numpy و Matplotlib استفاده میشود، بنابراین باید وارد محیط برنامهنویسی شده و این کتابخانهها را فراخوانی کرد:
در مرحله بعد، باید دادههای مصنوعی برای اجرای K-means روی آنها تعریف شوند. این کار در ادامه این بخش از مقاله K-means چیست انجام شده است.
تولید دادههای مصنوعی برای پیاده سازی الگوریتم K-means در پایتون
پس از فراخوانی کتابخانههای مورد نیاز برای پیاده سازی الگوریتم K-means در پایتون ، باید یک مجموعه داده با مرکزهای خوشه تعیین شده (مشخص) تولید شود تا در نهایت بتوان نتایج حاصل شده از اجرای الگوریتم K-means را با مقادیر واقعی مقایسه کرد.
کدهای تولید دادههای مصنوعی با مرکزهای خوشه مشخص در پایتون به صورت زیر است:
در تابع CreateDataset که در کدهای فوق ایجاد شده است، حول هر مرکز ورودی، به تعداد nD داده به صورت تصادفی ایجاد و در خروجی بازگردانده میشود.
فراخوانی تابع تولید دادههای مصنوعی
فراخوانی تابع CreateDataset به صورت زیر است:
در کدهای فوق، ابتدا پارامترهای ورودی تابع CreateDataset شامل nD ،Cs و S تعریف و مقداردهی شدهاند. سپس، تابع CreateDataset فراخوانی و متغیرهای تعریف شده به عنوان ورودی به این تابع ارجاع داده میشوند. پس از اجرای تابع، دادههای مورد نیاز در آرایهی X ذخیره خواهند شد.
بصریسازی دادههای تولید شده
برای نمایش و بصریسازی دادههای تولید شده میتوان دادهها را به یک صورت نمودار توزیعی (Scatter Plot) رسم کرد:
باید توجه داشت که در کدهای فوق، دوبار از دستور plt.scatter استفاده شده است. در اولین فراخوانی plt.scatter، توزیع دادههای ماتریس X و در فراخوانی دوم، مراکز خوشهها رسم شدهاند. در این مقاله برای پیاده سازی الگوریتم K-means در پایتون از دادههای دو بُعدی استفاده شده است. این کار با هدف سادهسازی محاسبات و امکان نمایش دادهها در نمودار صورت گرفته است. میتوان با تغییر دادن ابعاد X در تابع CeateDataset، دادههایی با ابعاد بالاتر ایجاد کرد. نمودار توزیعی کدهای فوق در خروجی به صورت زیر چاپ میشود:


تعیین تعداد خوشهها مراکز آنها
در کدهای فوق باید توجه داشت که برای تعیین مراکز خوشه تصادفی میتوان بازههای پایین و بالا را تغییر داد. با توجه به اینکه دادههای تولید شده دارای دو بُعد هستند، مراکز خوشهها نیز در یک محیط دو بُعدی قرار خواهند گرفت.
ایجاد تابعی برای تخصیص هر داده به یک خوشه
در مرحله بعد، باید تابعی ایجاد شود که با دریافت مختصات مراکز خوشهها و نقاط موجود در ، هر داده را به نزدیکترین خوشه اختصاص داده و در نهایت آرایهای از دادههای موجود در هر خوشه بازگردانده شود. این تابع به صورت زیر تعریف میشود:
ایجاد یک لیست برای ذخیره دادههای هر خوشه
اکنون باید یک لیست ایجاد شود که در آن به تعداد nClusters لیست خالی وجود داشته باشد تا بعداً هر داده به لیست مربوط به آن خوشه اضافه شود:
در خروجی کدهای فوق، لیست Clusters، به شکل زیر خواهد بود:
محاسبه فاصله هر نقطه از مرکز
حال باید به ازای هر داده ، فاصله را از هر مرکزِ محاسبه کرد. برای انجام این کار، ابتدا حلقهای به ازای تمامی دادهها ایجاد و سپس یک آرایه خالی برای افزودن فاصله هر مرکز از تعریف میشود.
پس از آن، باید به ازای تمامی مراکز خوشهها، فاصله تا را محاسبه کرد. این موارد در کدهای زیر انجام شده است:
در کدهای فوق، با کم کردن دو بردار و از یکدیگر، بردار حاصل میشود که مقدار L2-Norm آن، بیانگر فاصله اقلیدسی خواهد بود. تابع norm به طور پیشفرض، از روش L2 استفاده میکند. البته در صورت نیاز، میتوان از روشهای دیگر نیز استفاده کرد. حال باید داده را به لیست مربوط به نزدیکترین مرکز خوشه اضافه کرد:
به این ترتیب، تابع مورد نظر تا به اینجا کامل شده و عملکرد مورد نیاز را انجام میدهد.
تبدیل لیستهای خوشهها به آرایه
بهتر است در انتها، لیستهای موجود در Clusters به آرایه تبدیل شوند تا استفاده از آنها، راحتتر باشد:
اکنون میتوان در متن اصلی برنامه، از تابع ایجاد شده استفاده کرد:
پیاده سازی گامهای تکرار شونده ۳ و ۴ الگوریتم K-means در پایتون
تا این مرحله در مقاله «K-means چیست»، گامهای 1 و 2 الگوریتم K-means کامل و در پایتون پیاده سازی شدهاند، حال برای پیاده سازی تکرار مراحل 3 و 4، نیاز به ایجاد یک حلقه وجود دارد:
ابتدا باید در هر مرحله مختصات مراکز خوشهها بهروز شوند. برای این فرآیند، باید یک تابع به صورت زیر تعریف کرد:
اکنون باید به ازای هر خوشه، مرکز مربوطه، در میانگین نقاط مربوط به آن خوشه قرار گیرد:
به این ترتیب، مقادیر با استفاده از تابع np.mean به روزرسانی میشوند. نکته مهمی که در این مرحله وجود دارد، مقدار axis است. مقدار axis در این موارد، باید برابر صفر باشد تا عمل میانگینگیری به ازای هر سطر انجام نشود، بلکه باید به ازای هر ستون صورت گیرد. مشکلی که ممکن است در این بخش به وجود آید، خالی بودن آرایه مربوط به یک خوشه است.
در چنین شرایطی، مقدار میانگین به عدد خواهد رسید که باعث اختلال در اجرای برنامه میشود. به همین دلیل، باید شرطی تعیین کرد تا عمل به روزرسانی در صورتی انجام شود که آرایه مربوطه خالی نیست:
به این ترتیب، تابع مورد نیاز برای بهروزرسانی مراکز ایجاد شده است. حالا باید حلقهی ایجاد شده را تکمیل کرد:
بنابراین، پیاده سازی الگوریتم K-means در پایتون انجام شده است و الگوریتم K-means به درستی عمل خواهد کرد.
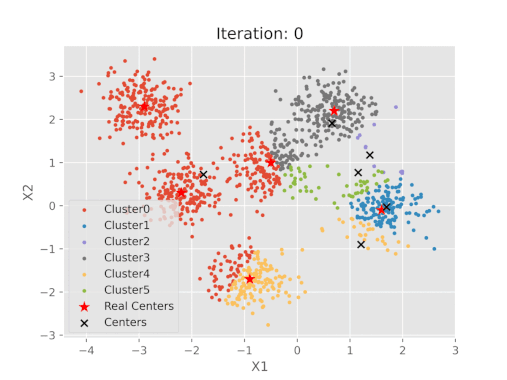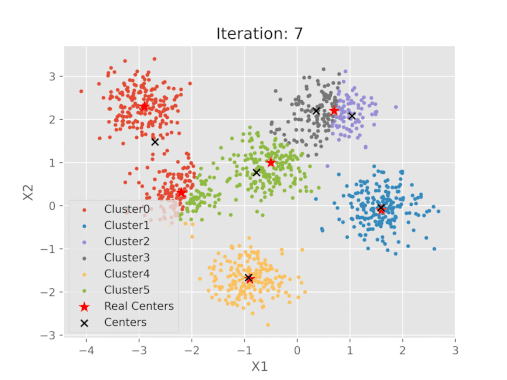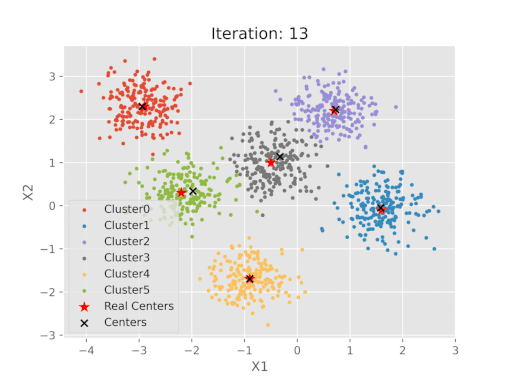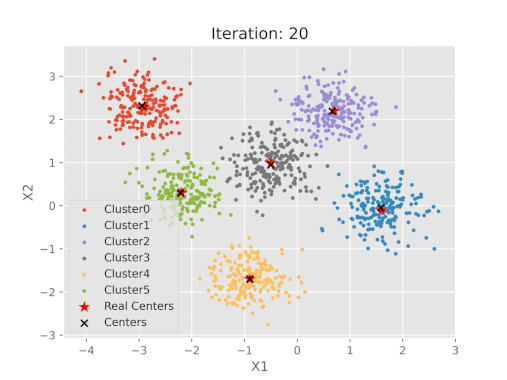
مقایسه نتایج پیاده سازی شده الگوریتم K-means با مراکز خوشه واقعی
پس از اتمام مراحل، میتوان نمودار مختصات مراکز حاصل از الگوریتم K-Means را با مراکزی که تعیین شده بودند، مقایسه کرد.
پس از اجرای کدهای فوق، تصویر خروجی به صورت زیر خواهد بود:

نمایش بصری مراحل الگوریتم K-means

جمعبندی
در این مقاله، ابتدا به این سوال پاسخ داده شد که الگوریتم k-means چیست و سپس پیاده سازی الگوریتم K-means در پایتون به صورت گام به گام و تا حد امکان به بیان ساده ارائه شد. در این پیاده سازی ابتدا دادههای مصنوعی تولید و مراکز خوشه برای آنها تعیین شد. سپس، کدها و توابع لازم برای پیاده سازی K-means ایجاد شدند و این الگوریتم روی دادههای تولید شده اجرا و نتایج آن با مراکز تعیین شده برای خوشهها مقایسه شد.









