
شبیه سازی پیاده روی تصادفی در پایتون – راهنمای گام به گام
پیاده روی تصادفی (Random Walk) فرایندی است که در طول زمان رخ میدهد و هر قدم (Step) بهصورت تصادفی ایجاد میشود و موقعیت بعدی را ایجاد میکند. در این آموزش، با روش شبیه سازی پیاده روی تصادفی در پایتون آشنا میشویم.



پیاده روی تصادفی چیست؟
در شکل زیر حرکت براونی (Brownian Motion) برای ذرات گاز نشان داده شده است که نقطه ابتدا و انتها نشان داده شده و نمونهای از پیاده روی تصادفی است.

در پیادهروی تصادفی، از توزیعهای مختلف مانند یکنواخت و نرمال میتوان استفاده کرد. اندازه گام نیز میتواند پیوسته یا گسسته باشد.
ابتدا میخواهیم یک پیادهروی تصادفی در دو بعد ایجاد کنیم. بدین منظور، یک موقعیت برای ذره تعریف میکنیم:
سپس به تعداد مراحلی مشخص (N) اعدادی تصادفی با توزیع یکنواخت از تا ایجاد میکنیم:
سپس، میتوانیم موقعیت ذره را اصلاح کنیم:
به این ترتیب، موقعیت در هر لحظه، از روی موقعیت قبلی و با تغییراتی تصادفی ایجاد میشود.
پیاده روی تصادفی در پایتون
برای پیادهسازی، وارد محیط برنامهنویسی میشویم:
حال تنظیمات زیر را اعمال میکنیم:
در ابتدا، موقعیتهای اولیه را تعریف میکنیم:
سپس تعداد گامهای شبیهسازی را تعریف میکنیم:
حال یک فهرست برای ذخیره Xها و یک فهرست دیگر برای ذخیره Yها ایجاد میکنیم:
حال میتوانیم یک حلقه ایجاد میکنیم و در هر مرحله، بهصورت تصادفی اندازه گام محاسبه و به آخرین موقعیت اضافه کنیم:
به این ترتیب، مقادیر محاسبه و در دو فهرست ذخیره میشود. حال میتوانیم یک نموداری براساس دو لیست ایجاد کنیم تا حرکات بهخوبی مشاهده شود:
به این ترتیب، نمودار زیر مشاهده میشود.

به این ترتیب، حرکات بهخوبی نشان داده میشود.
برای یادگیری برنامهنویسی با زبان پایتون، پیشنهاد میکنیم به مجموعه آموزشهای مقدماتی تا پیشرفته پایتون فرادرس مراجعه کنید که لینک آن در ادامه آورده شده است.
- برای مشاهده مجموعه آموزشهای برنامه نویسی پایتون (Python) — مقدماتی تا پیشرفته + اینجا کلیک کنید.
میتوانیم برنامه را بهشکل زیر اصلاح کنیم و بهشکل برداری بنویسیم:
در این حالت نیز نتایج قبلی ایجاد خواهد شد. میتوان گامها را بهصورت تصادفی با توزیع نرمال ایجاد کرد:
که در این صورت، نموداری به شکل زیر خواهد بود.

توجه داشته باشید که با توجه به رفتار هر سیستم، باید از توزیع متناسبی استفاده کرد.
به این ترتیب، شبیهسازی پیادهروی تصادفی دوبعدی پیادهسازی شد.
حال میخواهیم در بخش دوم از مطلب، به شبیهسازی پیادهروی تصادفی قیمت یک نماد بپردازیم. توجه داشته باشید که در این حالت، پیشفرضمان را به این صورت در نظر میگیریم که رفتار سری زمانی کاملاً تصادفی بوده و توزیع حرکات را میدانیم.
به این منظور، کتابخانههای مورد نیاز را فراخوانی میکنیم و تنظمات را اعمال میکنیم:
حال میتوانیم دادههای روزانه را برای سه سال دریافت کرده و تغییرات نسبی روزانه را محاسبه کنیم:
توجه داشته باشید که میتوان بهشکل زیر نیز عمل کرد:
حال میتوانیم یک نمودار هیستوگرام (Histogram Plot) برای تغییرات نسبی قیمت رسم کنیم:
که شکل زیر را خواهیم داشت.

مشاهده میکنیم که توزیع دادهها به توزیع نرمال نزدیک است. به همین دلیل، میتوانیم از توزیع نرمال برای تولید گامها استفاده کنیم. برای ایجاد این توزیع، میانگین (Mean) و انحراف معیار (Standard Deviation) دادهها را محاسبه میکنیم:
حال میتوانیم موقعیت اولیه را تعریف کنیم:
حال تعداد گام را تعیین و یک آرایه برای ذخیره مقادیر جدید ایجاد میکنیم:
حال میتوانیم حلقه اصلی را ایجاد کنیم و مقدایر گام را تعیین کنیم:
عدد نشاندهنده تغییرات نسبی خواهد بود:
اکنون مقدار بعدی را میتوانیم محاسبه کنیم:
به این ترتیب، مقادیر محاسبه شد. برای رسم نمودار، به شکل زیر عمل میکنیم:
که در این صورت، نمودار به شکل زیر خواهد بود.

به این ترتیب، مشاهده میکنیم که اندازه و توزیع تغییرات، بسیار نزدیک به نمودار واقعی است. توجه داشته باشید که میتوان ابتدا روند خطی را از دادهها حذف کرده و سپس پیادهروی تصادفی را شبیهسازی کنیم که در این صورت، دادههای تولیدشده به واقعیت نزدیک خواهند بود. همچنین، میتوان خودهمبستگی (Autocorrelation) تغییرات با روزهای گذشته خود را مدل و براساس آن حرکات تصادفی را ایجاد کرد.
اگر بخواهیم چندین سناریو را بهصورت همزمان در نمودار نشان دهیم، میتوانیم به شکل زیر کد را تغییر دهیم:
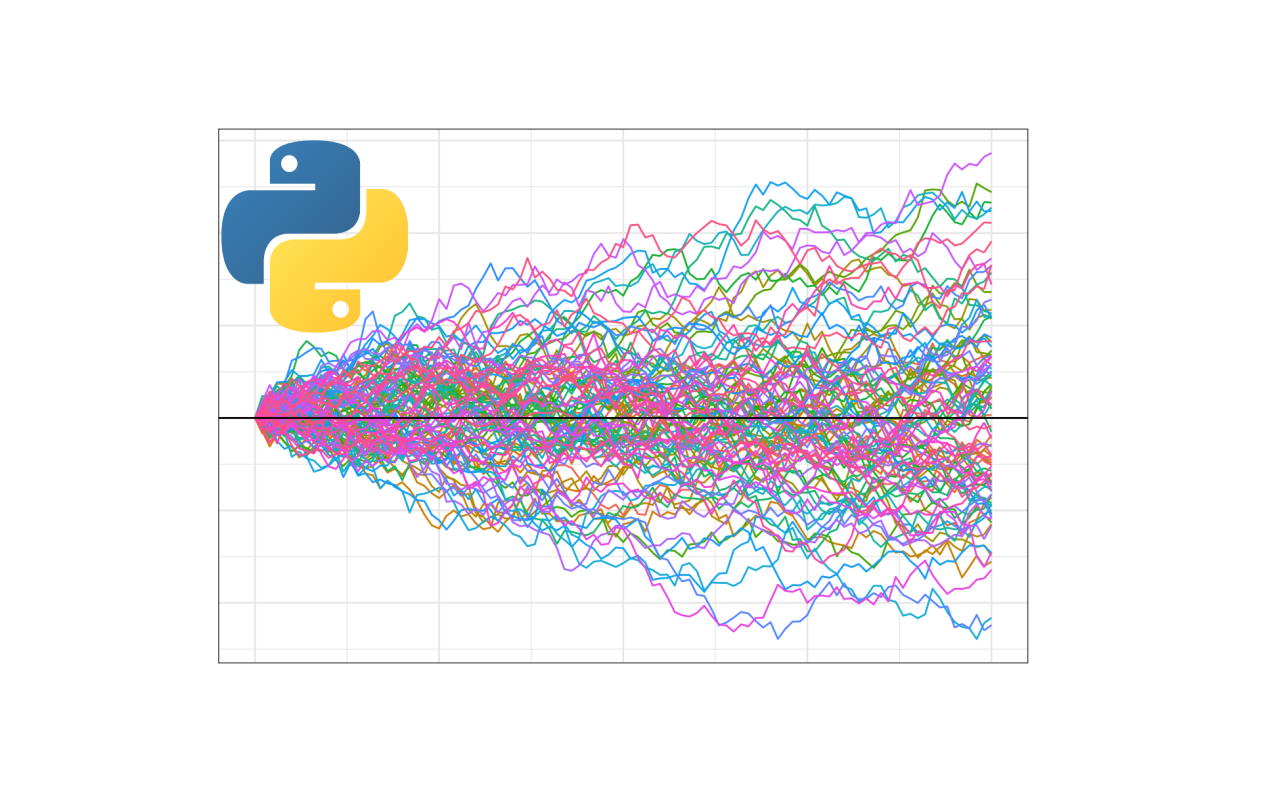
که در این صورت، به تعداد ۱۰ بار، پیادهروی تصادفی انجام میشود و نتایج زیر حاصل میشود.

به این ترتیب، مشاهده میکنیم که هر سناریو از یک نقطه شروع شده ولی رفتهرفته فاصله هرکدام از سایرین افزایش مییابد. با انجام یک مدلسازی مناسب و دقیقتر، میتوان پیشبینیهایی انجام داد که به واقعیت نزدیک هستند و در نتیجه، با بررسی سناریوهای مختلف، احتمال مشاهده قیمتی مشخص در تاریخی مشخص را محاسبه کرد.
جمعبندی
در این مطلب، با پیادهروی تصادفی آشنا شدیم و دو شبیهسازی با استفاده از آن انجام دادیم. برای مطالعه بیشتر، میتوان به موارد زیر مراجعه کرد:
- روند (Trend) در دادههای سری زمانی
- اجزای تشکیلدهنده یک سری زمانی
- توزیعهای احتمال پرکاربرد
- خودهمبستگی در سریهای زمانی









