



توزیع نرمال و توزیع نرمال استاندارد – به زبان ساده
در این مطلب از مجله فرادرس با توزیع نرمال و توزیع نرمال استاندارد آشنا میشویم. شاید تا کنون بارها عبارت «توزیع آماری» به گوشتان خورده باشد، ولی تصور دقیقی از معنی این اصطلاح نداشته باشید. پس از انجام هر نوع اندازهگیری همواره تعدادی داده (عدد) در اختیار داریم که میخواهیم ارتباط بین آنها را کشف کنیم یا آنها را دستهبندی نماییم تا بتوانیم آنها را تجزیه و تحلیل کنیم. برای انجام این کار ابتدا میبایست نحوه توزیع دادهها را بدانیم. به عبارت سادهتر توزیع دادهها به ما میگوید که پراکندگی و گستردگی دادههایی که جمعآوری کرده ایم چگونه است. توزیع نرمال نیز یکی از این الگوها است.




مثلاً اگر شما هر روز هفته صبح به ورزش میپردازید، توزیع زمانهای ورزشی شما به صورت خطی است. دادهها ممکن است بسته به ماهیت آزمایش و عوامل گوناگون به انواع مختلفی توزیع یافته باشند. محققین معمولاً تلاش میکنند دریابند که توزیع دادهها به کدام توابع ریاضی نزدیکتر هستند، تا بدین ترتیب بتوانند تحلیل صحیحی از ماهیت توزیع و محاسبات بر روی آن داشته باشند. یکی از مهمترین توزیعهای آماری، «توزیع نرمال» نام دارد.
نام دیگر توزیع نرمال، «توزیع طبیعی» یا «تابع گاوسی» است، زیرا این تابع را نخستین بار کارل فردریش گاوس پیشنهاد کرده است. این توزیع یکی از مهمترین توزیعهای احتمالی پیوسته در نظریه احتمالات است. علت نامگذاری و همچنین اهمیت این توزیع، همخوانی بسیاری از مقادیر حاصل شده، هنگام نوسانهای طبیعی و فیزیکی پیرامون یک مقدار ثابت با مقادیر حاصل از این توزیع است. در ادامه انواع مختلفی از توزیعهای محتمل دادهها را نشان دادهایم.
دادهها ممکن است طوری توزیع شوند که بیشتر در سمت راست باشند.
یا ممکن است این توزیع به گونهای باشد که بیشتر در سمت چپ تجمع یابند.
همچنین ممکن است توزیع دادهها به صورت مختلط باشد.
اما موارد بسیاری وجود دارد که داده ها میل به جمع شدن در اطراف مقدار میانگین دارند. در چنین حالتی دادهها به سمت چپ یا راست تمایل ندارند، به این توزیع «توزیع نرمال» یا توزیع زنگولهای گفته میشود. مثل حالت زیر:

یک توزیع نرمال
«خمیدگی روی سطح زنگوله»، یک توزیع نرمال است. هیستوگرام زردرنگ در تصویر فوق برخی از دادهها را که به این منحنی نزدیک هستند نشان می دهد. ممکن است در مواردی این دادهها کاملاً منطبق بر شکل زنگوله نباشد و این امری معمول و طبیعی است.

این توزیع بیشتر به نام «نمودار زنگولهای» نیز نامیده میشود، زیرا شکل منحنی آن شبیه به یک زنگوله است.
موارد بسیاری وجود دارند که از توزیع نرمال تبعیت می کنند:
- قد افراد
- اندازه اجسام تولید شده ماشینآلات صنعتی
- خطاهای اندازهگیری
- فشار خون
- نمرات یک امتحان
در چنین مواردی میگوییم که دادهها «به صورت نرمال» توزیع یافتهاند:

توزیع نرمال دارای موارد زیر است:
- میانگین = میانه = مد است.
- خط تقارن در وسط قرار میگیرد.
- %50 مقادیر، کوچکتر از میانگین و %50 دیگر بزرگتر از میانگین هستند.
در آموزشهای فرادرس، آمار و داده کاوی از موضوعات جذاب و مورد پسند محسوب میشوند. در آموزش آمار و احتمال مهندسی که توسط فرادرس منتشر شده است، سرفصلهای مربوط به آموزش این درس در دانشگاه به طور کامل، پوشش داده شده و مثالها به همراه نمونه آزمون کارشناسی ارشد، مورد بحث قرار میگیرد. لینکی که در ادامه مشاهده میکنید، برای دسترسی به این آموزش است.
انحراف معیار
انحراف معیار یا خطای استاندارد (Standard Deviation)، معیار پراکندگی اعداد است. هنگامی که انحراف معیار را اندازهگیری می کنیم، به طور معمول با موارد زیر مواجه میشویم:

در تصویر اول میبینیم که 68% از مقدارها در محدوده یک انحراف معیار از میانگین هستند. در تصویر دوم، 95% از مقدارها در محدوده دو برابر انحراف معیار از میانگین هستند. در تصویر سوم، 99.7% از مقدارها در محدوده سه برابر انحراف معیار از میانگین هستند.
مثال: قد %95 از دانش آموزان در مدرسه بین 1.1 متر و 1.7 متر است. با در نظر گرفتن این که دادهها دارای توزیع نرمال هستند، چگونه میتوان میانگین و انحراف معیار را به دست آورد؟ پاسخ بسیار ساده است. میانگین، در میان 1.1 متر و 1.7 متر است، پس:
= میانگین
(1.1m + 1.7m) / 2 = 1.4m
95%، برابر دو انحراف از معیار در طرفین میانگین است (مجموع 4 انحراف معیار)، پس:
= 1 انحراف معیار
(1.7m – 1.1m) / 4
= 0.6m / 4
= 0.15m
و نمودار حاصل به شکل زیر است:

دانستن انحراف معیار برای ما سودمند است، چون در آن صورت در مورد توزیع دادهها موارد زیر را میتوانیم بیان کنیم:
- مقادیر ما به احتمال متوسط در محدوده یک برابر انحراف معیار از میانگین قرار دارند (68 از 100).
- مقادیر ما به احتمال زیاد در محدوده دو انحراف معیار از میانگین هستند (95 از 100)
- مقادیر ما تقریبا به احتمال بسیار زیاد در محدوده سه انحراف معیار حضور دارند (997 از 1000)
نمرات معیار
تعداد انحرافها از میانگین همچنین با نام «نمره معیار یا نمره استاندارد» (Standard Score)، نیز نامیده میشود که به صورت «سیگما» و یا «نمره z» مورد اشاره قرار میگیرند.
مثال: در همان مدرسه مثال قبل، قد یکی از دانش آموزان برابر با 1.85 متر است.
در روی نمودار زنگوله ای، مشاهده میکنید که 1.85 متر، در محدوده 3 برابر انحراف از میانگین 1.4 متر قرار دارد.

پس:
«نمره z» قد این دانش آموز برابر 3.0 است
همچنین میتوان تعداد انحرافهای عدد 1.85 از میانگین را محاسبه کرد. عدد 1.85 به چه مقدار از میانگین فاصله دارد؟
به اندازه 0.45 = 1.4 - 1.85 از میانگین فاصله دارد.
این مقدار فاصله برابر چند انحراف معیار است؟ انحراف معیار برابر 0.15 است، پس:
3 انحراف معیار = 0.45m / 0.15m
پس برای تبدیل یک مقدار به یک نمره معیار:
- ابتدا میانگین را از آن کم می کنیم،
- سپس بر مقدار انحراف معیار تقسیم می کنیم.
و انجام دادن این عمل را «استانداردسازی» مینامیم:

ما میتوانیم هر توزیع نرمال را به توزیع نرمال استاندارد تبدیل کنیم.
مثال: زمان مسافرت
یک نظرسنجی از مدت زمان مسافرت، این مقادیر را نتیحه داده است (به دقیقه):
26, 33, 65, 28, 34, 55, 25, 44, 50, 36, 26, 37, 43, 62, 35, 38, 45, 32, 28, 34
میانگین برابر 38.8 دقیقه و انحراف معیار نیز برابر 11.4 دقیقه است. مقادیر را به نمره های z یا نمرات استاندارد تبدیل کنید.
برای تبدیل 26:
- ابتدا مقدار میانگین را از آن کم کنید: 12.8- = 38.8 - 26
- سپس آن را بر مقدار انحراف معیار تقسیم کنید: 1.12 - = 11.4 / 12.8 -
پس عدد 26، 1.12- انحراف از میانگین دارد.
سه تبدیل اول را می توانید در زیر ببینید

و این سه تا را می توانید در نمودار مشاهده کنید:
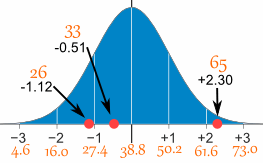
می توانید بقیه نمرات z را خودتان محاسبه کنید!
فرمول محاسبه نمره z در زیر آمده است:
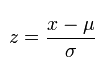
- z برابر «نمره z» (نمره معیار) است
- x مقداری است که باید استاندارد شود
- μ برابر میانگین است
- و σ برابر انحراف معیار می باشد
چرا از استانداردسازی استفاده می کنیم؟
استاندارد سازی میتواند به ما کمک کند که تصمیمهایی در مورد دادههایمان بگیریم. به مثال زیر توجه کنید.
مثال: پروفسور ویلوبی در حال تصحیح ورقه های دانشجویان است. نمرات دانشآموزان در زیر آمده است (از 60 نمره):
20, 15, 26, 32, 18, 28, 35, 14, 26, 22, 17

بسیاری از دانشآموزان حتی از 60 نمره، 30 نمره هم نگرفتهاند و بیشترشان تجدید خواهند شد. امتحان باید بسیار سخت بوده باشد، پس پروفسور تصمیم می گیرد که تمامی نمرات را استاندارد کند و فقط آنهایی را که یک انحراف معیار پایینتر از میانگین نمره گرفتهاند، تجدید اعلام کند. میانگین برابر 23 و انحراف معیار برابر 6.6 است و این مقادیر، نمرات استاندارد هستند:
-0.45, -1.21, 0.45, 1.36, -0.76, 0.76, 1.82, -1.36, 0.45, -0.15, -0.91
مشاهده میکنید که تنها 2 دانشجو تجدید خواهند شد (همانهایی که در امتحان 15 و 14 گرفته بودند).
از طرف دیگر استانداردسازی کارها را آسانتر می کند، چون در این حالت ما تنها به یک جدول نیاز خواهیم داشت (جدول توزیع نرمال استاندارد)، که دیگر نیازی به انجام محاسبات تک به تک برای فاصله هر مقدار از میانگین و انحراف استاندارد وجود ندارد.
جزئیات بیشتر
در تصویر زیر توزیع نرمال استاندارد را با درصد هایی برای هر نیمه از انحراف معیار، و درصدهای تجمعی نمایش یافته است.

مثال: نمره شما در یک تست 0.5 انحراف معیار بیشتر از میانگین بود، چند نفر از شما کمتر نمره گرفته اند؟
- بین 0 و 0.5 برابر %19.1 است
- کمتر از 0 نیز برابر %50 است (نصف منحنی)
پس مجموع نمرات کمتر از نمره شما برابر است با:
50% + 19.1% = 69.1%
در تئوری، %69.1 کمتر از شما نمره گرفته اند؛ اما با دادههای واقعی، درصد ممکن است، کمی متفاوت باشد.
مثال کاربردی برای بستهبندی شکر
فرض کنید شرکتی بستههای شکر را به صورت بستههای 1 کیلوگرمی بستهبندی میکند.

وقتی شما یک نمونه از کیسهها را وزن میکنید، نتایج زیر به دست میآید:
- 1007 گرم، 1032 گرم، 1002 گرم، 983 گرم، 1004 گرم، ... (100 اندازهگیری)
- میانگین = 1010 گرم
- انحراف معیار = 20 گرم
اینک متوجه میشوید که برخی از مقادیر کمتر از 1000 گرم هستند. آیا میتوانید این مشکل را حل کنید؟
توزیع نرمال اندازهگیریهای شما به این شکل است:
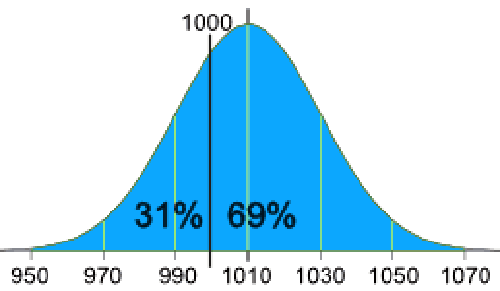
%31 از بستهها کمتر از 1000 گرم وزن دارند، که در واقع فریب مشتری محسوب میشود.
این یک اتفاق تصادفی است، پس نمی توانیم بستههای کمتر از 1000 گرم شکر را متوقف کنیم؛ اما میتوانیم تعداد آنها را به مقدار قابل توجهی کاهش دهیم. بدین منظور تنظیمات دستگاه بستهبندی را در انحرافهای معیار مختلف برای بستههای 1000 گرم بررسی میکنیم:
- در محدوده 3- برابر انحراف معیار:
در منحنی زنگولهای بزرگ مشاهده میکنیم که بستهها در این محدوده %0.1 کم هستند؛ اما شاید این عدد بسیار کوچک باشد. - در محدوده 2.5- انحراف معیار میبینیم :
در بازه زیر 3 انحراف معیار، 0.1% و مابین انحرافهای 3 و 2.5، %0.5 از بستهها کم میشود که وقتی با هم جمع کنیم مقدار %0.6 = %0.5 + %0.1 به دست میآید. این تنظیمات گزینه مناسبی برای انتخاب به نظر میرسد.
پس دستگاه را طوری تنظیم می کنیم که 1000 گرم را در محدوده 2.5- انحراف از میانگین داشته باشیم. اکنون، ما می توانیم به دو طریق تنظیم کنیم:
- مقدار شکر را در هر بسته افزایش دهیم، که میانگین را تغییر میدهد و یا
- دقت را افزایش دهیم که انحراف معیار را کاهش میدهد.
هر دو سناریو را امتحان کنیم.
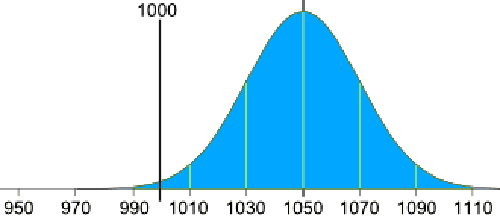
تنظیم مقدار میانگین در هر بسته
انحراف معیار برابر 20 گرم است، و میانگین ما باید در محدوده 2.5 برابری از آن قرار گیرد:
2.5 × 20g = 50g
پس دستگاه باید میانگین 1050 گرم را نتیجه دهد:
تنظیم دقت دستگاه
با این روش میتوان میانگین 1010 گرم را ثابت نگه داشت؛ اما در آن صورت ما به 2.5 انحراف معیار که برابر با 10 گرم است، نیاز داریم:
10g / 2.5 = 4g
پس انحراف معیار باید برابر با 4 گرم باشد:
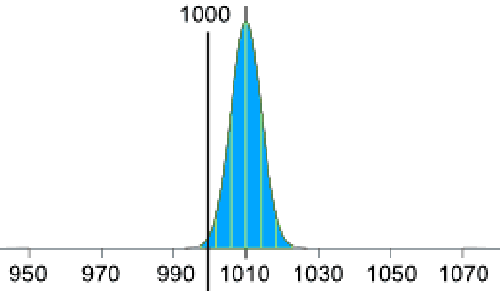
این دقت مطلوبی برای دستگاه بستهبندی به نظر میرسد.
با کمی تلاش بیشتر میتوان ترکیبی از دقت بیشتر و میانگین بالاتر به دست آورد.
مقادیر دقیقتر
می توان از جدول توزیع نرمال استاندارد استفاده کرد تا مقادیر دقیق تری به دست آورد.
آزمون توزیع نرمال و توزیع استاندارد
۱. کدام ویژگی منحنی زنگولهای، وجود توزیع نرمال را در دادهها نشان میدهد؟
تقارن کامل نمودار حول یک نقطه مرکزی
داشتن چندین قله روی نمودار
قرار گرفتن بیشترین دادهها در انتهای نمودار
پراکندگی دادهها در همه بازهها بهطور مساوی
تقارن کامل منحنی زنگولهای یکی از نشانههای اساسی توزیع نرمال است، که باعث میشود میانگین، میانه و مد با هم برابر باشند و خط تقارن دقیقا وسط توزیع قرار گیرد. وجود چند قله یا تمرکز اصلی دادهها در انتها، متعلق به توزیعهای غیر نرمال است. پراکندگی مساوی دادهها در بازههای مختلف هم در توزیع نرمال مشاهده نمیشود؛ در این توزیع، اغلب دادهها حول مرکز جامعه پراکندهاند.
۲. در توزیع نرمال، چرا مقادیر میانگین، میانه و مد با هم برابرند؟
زیرا همه دادهها دقیقا یکسان و بدون پراکندگی هستند.
چون در توزیع نرمال دادهها تصادفی و نامنظم پراکندهاند.
چون توزیع نرمال فقط یک نقطه بیشترین فراوانی دارد و نمودار آن متقارن است.
زیرا میانگین در هر توزیعی مرکز قرار میگیرد.
در توزیع نرمال، نمودار به شکل زنگولهای و متقارن حول یک خط مرکزی است و دادهها حول این مرکز بیشترین تراکم را دارند. به همین دلیل مقدار میانگین، میانه و مد همگی روی این خط مرکزی قرار میگیرند و با هم برابرند.
۳. برای مقایسه نمره دو دانشجو در یک درس با استفاده از z-score، کدام روش صحیحتر است؟
جمعزدن نمرات خام و مقایسه مجموع آنها
فقط مقایسه انحراف معیار برای هر نمره
مقایسه مستقیم اختلاف بین بالاترین و پایینترین نمره
محاسبه فاصله هر نمره تا میانگین و مقایسه مقدار z-score
برای مقایسه علمی نمرات دو دانشجو بر اساس z-score، باید مقدار z-score هر دانشجو را که بیانگر فاصله نمره او از میانگین بر حسب انحراف معیار است، حساب کرده و آنها را با هم مقایسه کرد. z-score این امکان را میدهد که جایگاه هر دانشجو نسبت به میانگین کلاس و پراکندگی نمرات شفاف شود. مقایسه نمرات خام بدون توجه به میانگین و انحراف معیار، یا بررسی فقط انحراف معیار به تنهایی، معیار صحیحی برای مقایسه وضعیت نسبی دانشجویان نیست و مقایسه مستقیم اختلاف نمرات نیز اطلاعات کافی درباره توزیع نمیدهد.
۴. در کنترل کیفیت بستهبندی شکر، چه تغییری باعث افزایش درصد بستههای با وزن نزدیک به مقدار استاندارد میشود؟
کاهش میانگین و کاهش انحراف معیار به طور همزمان
افزایش میانگین وزن بستهها بدون تغییر انحراف معیار
کاهش انحراف معیار بدون تغییر میانگین وزن
افزایش میانگین و همزمان افزایش انحراف معیار
کاهش انحراف معیار بدون تغییر میانگین سبب میشود دادهها (وزن بستهها) به میانگین نزدیکتر شوند و تعداد بیشتری از بستهها در محدوده وزن استاندارد قرار گیرند. افزایش میانگین میتواند تعدادی از بستهها را از مقدار معمول دور کند و با بزرگ بودن انحراف معیار، پراکندگی دادهها همچنان زیاد میماند. در حالتی که هم افزایش میانگین و هم افزایش انحراف معیار رخ دهد، پراکندگی بیشتر میشود و بخشی از بستهها دور از مقدار مطلوب قرار میگیرند. کاهش همزمان میانگین و انحراف معیار نیز لزوما موجب تمرکز بیشتر وزنها حول مقدار استاندارد نمیشود، زیرا میانگین باید مطلوب باقی بماند. بنابراین، «کاهش انحراف معیار بدون تغییر میانگین وزن» بهترین راه برای نزدیک شدن حداکثری وزن بستهها به مقدار استاندارد است.
۵. در مورد توزیع نرمال، عدد ۶۸٪ بیانگر چیست و چه کمکی به تعبیر پراکندگی دادهها میکند؟
۶۸٪ دادهها در انتهای چپ منحنی زنگولهای جمع میشوند.
۶۸٪ دادهها دقیقا برابر یا بزرگتر از میانگین هستند.
۶۸٪ دادهها در محدوده یک انحراف معیار از میانگین قرار دارند.
۶۸٪ دادهها خارج از سه انحراف معیار از میانگین قرار دارند.
عدد ۶۸٪ نشاندهنده این است که بیشتر دادهها، یعنی حدود شصت و هشت درصد، در فاصله یک انحراف معیار دورتر از میانگین توزیع نرمال قرار میگیرند. این موضوع کمک میکند با مشاهده توزیع دادهها بفهمیم بخش عمده مقادیر به مرکز نزدیک بوده و فقط تعداد کمی داده بسیار دور از میانگین هستند.










فوقالعاده.
سپاس فراوان 💚
خیلی عالی بود. دستتون درد نکنه. خیلی ممنون
سلام و ممنون به خاطر آموزشتون
من یه چیزی رو متوجه نشدم اگه من بخوام احتمال وقوع یک عددی بین دو انحراف معیار رو به دست بیارم باید چطور این کار رو انجام بدم ؟مثلا میانگین 500 هستش و انحراف معیار 30 ما میخایم احتمال به وقوع پیوستن 550 رو به دست بیاریم ، البته شاید من نتونستم ار متن این مطلب رو استخراج کننم ولی اگه لطف کنید و برام توضیحش بدید ممنون میشم
در این نظریه، احتمال برای فاصله تعریف میشه، بنابراین احتمال وقوع نقطه ای یک عدد برابر صفر هست!
سلام اول ۵۵۰ را از ۵۰۰ کم میکنیم بعد بعد به انحراف معیار تقسیم میکنیم جواب میشود ۱.۶۶ حال از جدول توزیع نرمال مقدار Z1.66 را بدست می آوریم میشود ۰.۴۵۱۴ بنابراین احتمال وقوع آن ۴۵.۱۴ درصد است
چقدر لذت بردم عالی بود واقعا نحوه ی بیان مطلب
بسیار ساده و قابل فهم
من یکی دانشجوی یکی از دانشگاه های اروپایی ام و واقعا کیف کردم با این مطلب تان. فقط لطف کنید اگر دکمه پرنت هم به سایت اضافه بشه خیلی عالی میشه که راحت بتونیم این جزوه را بدون بهم ریضی پرنت بگیریم.
سلام و عرض ادب خدمت استاد بزرگوار
من اهل افغانستان هستم و میخواستم یک سوال از شما یزرگوار داشته باشم
اگر اوسط وزن بسکویت های تولید شده یک شرکت در پاکت های آن 780 ملی گرم نوشته شده است اگر انحراف معیاری آن 8 ملی گرمباشد پس انتروال اطمینان 95% برای 49 نمونه گرفته شده محصول این شرکت چند می شود؟
با احترام فراوان استا بزرگوار!
توضیح بسیار مفیدی بود ممنونم
سلام من چطور ميتونم ويدئو ذخيره كنم
بسیار عالی ، استفاده بردم
با سلام؛
برای آشنایی با نحوه ذخیره ویدیوها پیشنهاد میکنیم مطلب «بهترین افزونههای گوگل کروم برای دانلود فایلهای ویدیویی و صوتی» را مطالعه کنید.
با تشکر از همراهی شما با مجله فرادرس
سلام وقت بخیر. چقدر زیبا و راحت توضیح دادین متشکرم واقعا. زنده باشید.
سلام من به یک سوالی برخوردم اگر میشه بهم توضیح بدید هیچ جدول و نموداری هم نداده بهم
نمره T با میانگین ۵۰ و انحراف معیار شخصی که ۹۵ درصد افراد کلاس نمره بیشتری از اون گرفتن رو باید محاسبه کنیم میشه بگید چجوری باید Z رو در این مسئله حساب کنم؟
عرض ادب – مراحل توضیع مطالب با ردیف های جامع بخصوص در قسمت توزیع نرمال ( طبیعی ) منعکس که برای یادگیری بسادگی قابل فهم است . در مراجعه بعدی حتما مطالب دیگر اماری را هم جستجو خواهم نمود … با تشکر از شما .
ممنون از توضیحات خوبتون
سلام و خسته نباشید بسیار ساده راحت توضیح دادید فیلم بهتر متوجه میکنه
سلام
ضمن خسته نباشید می خواستم یک سوال بپرسم . در مجموعه داده 10 متغیری زمانی که می خواهیم توزیع داده را از نظر نرمال یا غیر نرمال بودن بسنجیم آیا باید تمام داده ها را در ارتباط با هم بسنجیم؟ یا هر متغیر را جدا بررسی کنیم؟ برای انجام اینکار بطور همزمان برای همه 10 متغیر باید چه کار کرد. مثلا دادهای شامل ارتباع ، شیب و فاصله و … باشند. با تشکر
سلام درود جناب استاد ری بد
در برخی موارد یادگیری ماشین میبینم توزیع های مختلف را به توزیع نرمال تبدیل میکنند علت این امر چیست؟
سپاسگزارم از حسن توجه جنابعالی
سلام آقای دکتر آرمان ری بد من یک سوال آمار و کابرد آن داشتم که به صورت عکس از صورت مسئله می باشد .مربوط به فصل اول جدول فراوانی می باشد .اگر امکانش هست این مسئله را حل کنید. تا اگر دوستی همچین سوالی پیش آمد در آینده بتواند به راحتی این مسئله را حل بنماید. نمیدانتم این عکس مسئله را در کجا برایتان بفرستم با تشکر از شما
من یک مقاله با عنوان شیوع یک عامل می خواستم بنویسم در حوزه میکروب شناسی ولی نمی دونم دقیقا از چه پارمتر هایی باید استفاده کنم و چطور . مطالب بالا فکر می کنم بیشتر برای علو انسانی است
سلام دوست و خواننده گرامی مجله فرادرس،
پیشنهاد میشود مطالب بررسی مدلهای ریاضی اپیدمی بیماریها — به همراه ویدیوی آموزشی و برآورد همه گیری بیماری با توزیع فوق هندسی — به زبان ساده را در این حوزه مطالعه کنید تا با مبانی چنین مقالاتی آشنا شوید.
از همفکری و همکاری شما سپاسگزاریم.
پیروز و سربلند باشید.
باسلام و خسته نباشید.
ببخشید اگر در استاندارد سازی Zکوچکتر از 4.5 بشه مقدار را چجوری باید بدست آورد؟
آخه در جدول نرمال تا 3.9 بیشتر وجود نداره….
ممنون میشم جواب بدید.
سلام و وقت بخیر،
اگر منظور شما پیدا کردن احتمال Z کوچکتر از ۴.۵ باشد، باید بگویم که این احتمال با تقریب بسیار زیاد، برابر با ۱ است. زیرا همیشه (با احتمال ۱) مقدار متغیر تصادفی نرمال استاندارد از ۳.۹ کوچکتر است.
به همین علت در جدولهای آماری برای توزیع نرمال استاندارد تا مقدار ۳.۹ مشخص شده است. که برابر با 0.999955 است. در حقیقت احتمال Z کوچکتر از ۴.۵ برابر با 0.999997 است که به ۱ بسیار نزدیک است.
موفق و تندرست باشید.
آقا دمتون گرم خدایی، چه سایت باحالیه فرادرس ?
سلام در توزیع نیم نرمال، توزیع جمع n تا از متغییر های نیم نرمال چی هست؟
سلام و درود،
برای آشنایی بیشتر با توزیعهای بریده نرمال پیشنهاد میشود مطلب توزیع نرمال بریده شده (Truncated Normal Distribution) — به زبان ساده را مطالعه کنید.
پیروز و پاینده باشید.
سلام مخواهم میانگین و انحراف معیار سبد سهام را محاسبه کنم لطفا راهنمای کنید متشکرم
درضمن مطالب جالب بود باتشکر
سلام برای مطالعه در مورد جدول توزیع احتمال کجا باید مراجعه کنم؟
موضوع تحقیق بنده هست.
درود بر شما خواننده گرامی مجله فرادرس.
برای آشنایی با نحوه محاسبه احتمال برای توزیع نرمال استاندارد از طریق جدول، مطالعه نوشتاری از مجله فرادرس از اینجا توصیه میشود.
موفق و تندرست و شاد باشید.
سلام و وقت بخیر..فرمول تابع توزیع توزیع نرمال رو میگین بهم لطفا
با سلام و تشکر فراوان
یک سوال داشتم. اگر دو عامل خطا با توزیع نرمال در یک متغیر وجود داشته باشه، خطای کل رو چطور باید حساب کرد؟
آیا باید یک سیگمای هردو خطا رو باهم جمع کرد؟ خطای حاصل یک سیگمای کل است؟
با سلام به شما همراه فرادرس،
در پاسخ به سوال شما باید گفت، نحوه ترکیب خطاها بستگی به نحوه ترکیب عاملها دارد. اگر دو عاملی که در موضوع مورد بحث شما وجود با یکدیگر دارای ارتباطی نباشند، خطای مدل به صورت جمع خطای هر یک از عاملها سنجیده میشود. در این صورت معمولا رابطه بین دو متغیر را جمعی در نظر میگیریم. مثل X+Y. ولی گاهی ممکن است که رابطه بین دو متغیر به صورت ضربی باشد XY به این معنی که تاثیر هر یک از آنها به طور توام روی متغیر وابسته به کار میرود. واضح است که در این صورت خطاها هم در هم ضرب میشوند. گاهی ممکن است اثرات تکی و همچنین اثرات متقابل دو عامل در مدل در نظر گرفته شود X+Y+XY. در این صورت نحوه محاسبه خطا متفاوت خواهد بود. در نتیجه آنچه که مهم است، نحوه ارتباط بین متغیرهای عامل و همچنین ارتباطشان با متغیر پاسخ است.
از اینکه خواننده نوشتارهای مجله فرادرس هستید سپاسگزاریم.
پیروز و سربلند باشید.
سلام واقعا سپاسگزارم . من سه تا کتاب آمار خواندم به این خوبی توضیح نداده بودن.
بسیار خوب و آموزنده بود. با زبان ساده
ممنون
خیلی مطلبتون ساده و خوش بیان بود
ممنون موفق باشيد خيلي عالي بود
سلام ممنون از اطلاعات مفیدتون ،
در مثال اول چرا ۱.۱ و ۱.۷ رو از هم تفریق کردین ؟
با سلام و تشکر از بازخورد شما.
انحراف معیار نشاندهنده میانگین فاصله مقادیر آماری از مقدار میانگین است. بدلیل نرمال بودن توزیع در این مثال، باید فاصله بین ماکزیمم و مینیمم را به ۴ قسمت مساوی تقسیم کرد. هریک از این قسمتها نشاندهنده مقدار انحراف معیار است. مقدار این فاصله نیز برابر با ۱.۱-۱.۷ است.
عالی بود
با تشکر از نويسنده محترم، مطالب بسيار روان و قابل استفاده هست.
با سلام ، شما با بیان مفهومی و ساده مطلب کمک بزرگی به یادگیری دانشجو میکنید واساتید اینکار رو کمتر انجام میدهند و فرمول وار درس میدهند و به این لحاظ واقعا حق معلمی بر گردن من دارید و مفاهیم اماری زیادی رو ازتون یاد گرفتم و ازتون ممنون هستم، یک سوال هم داشتم ، امکانش هست راجع به نحوه اثبات فروݦل گاوسی این ابع نرمال هم توضیح بدین که جچطور بدست می اوریم؟ مثل توضیح تابع پواسون که از روی دو جمله ای بدست اوردید ، باز هم ممنون
باسلام . من برای مقایسه مینگین زمان کاری ۳۱ استان با کل که هر استان از نظر تعداد مراجعه و تعداد کاربر و … متفاوتند میانگین هر استان را نسبت به کل کشور استاندارد کردم . حالا برای جمع بندی نهایی باید از جدول استاندارد استفاده کنم؟
تشکر میکنم.قابل فهم و ساده بود
در متن این مقاله و شرح انحراف معیار برای توزیع نرمال اشاره کردید که با یک انحراف معیار 68% داده در یک انحراف معیار و 95% داده در 2 انحراف معیار است. این 68 و 95 درصد یک اصل هستند یا دلیل خاصی دارد . برداشت بنده با توجه به اینکه از آن در مثال قد استفاده کردید اینست که یک اصل هستند و می توان از آن در حل سایر مسائل آماری استفاده کرد.
سلام و تشکر از اینکه مطالب وبلاگ فرادرس را دنبال می کنید.
در پاسخ به پرسش شما باید بگویم که این یک اصل در توزیع نرمال است. به این معنی که اگر توزیع داده ها به صورت نرمال باشد، باید درصد قرارگیری دادهها در بازهها، مطابق با درصدهایی باشد که در متن نوشته شده است. میزان فاصله نیز برحسب ضرایبی از انحراف معیار نسبت به میانگین است.
سلام ببخشید من یه سوال دارم میخوام ببینم سطح زیر منحنی چطور محاسبه میشه
سلام
تدریستون عالی بود
واقعا خیلی ساده و روون توضیح دادید
میشه بگید از کجا و با چه محاسباتی فهمیدید مقادیر ما به احتمال متوسط در محدوده یک برابر انحراف معیار از میانگین قرار دارند (68 از 100).
مقادیر ما به احتمال زیاد در محدوده دو انحراف معیار از میانگین هستند (95 از 100)
مقادیر ما تقریبا به احتمال بسیار زیاد در محدوده سه انحراف معیار حضور دارند (997 از 1000)
این قسمت رو متوجه نشدم متاسفانه
سلام دوست و همراه مجله فرادرس،
با توجه به جدولهای آماری میتوان احتمال این ناحیه را مشخص کرد. البته این جدولها نیز به کمک انتگرال گیری عددی در هر یک از ناحیهها، محاسبه شدهاند. یعنی اگر سطح زیر منحنی توزیع نرمال استاندارد را در بازه بین یک انحراف معیار بیشتر و کمتر از میانگین محاسبه کنیم به مقدار ۰٫۶۸ خواهیم رسید. همین محاسبه سطح زیر منحنی برای بدست آوردن مقدار احتمال در نواحی دیگر نیز به کار میآید. البته مشخص است که انتگرال گیری از تابع چگالی احتمال توزیع نرمال استاندارد به صورت صریح امکانپذیر نیست و به کمک روش های عددی این کار انجام میشود.
از این که مشکلات خود را با ما درمیان میگذارید خوشحالیم و امیدواریم که بتوانیم گرهگشای آنها باشیم.
تندرست و پیروز باشید.
با عرض سلام و وقت بخیر
ممنون که با فرادرس همراه هستید. برای محاسبه سطح زیر منحنی تابع چگالی توزیع نرمال، باید از روشهای عددی استفاده کرد. به همین جهت با استفاده از خاصیت و رابطهای که متغیر تصادفی نرمال استاندارد با بقیه توزیعهای نرمال دارد، میتوان سطح زیر منحنی یعنی مقدار احتمال X
ممنون از پاسختون. ممکنه منبعی برای مطالعه ی روش های پارامتریک و ناپارامتریک معرفی بفرمایید؟
با سلام و وقت بخیر!
برای آشنایی بیشتر میتوانید به کتابهای آماری در این زمینه مراجعه کنید. در بیشتر کتابهای معمول که در زمینه آزمون فرض مطلب دارند، روشهای پارامتری معرفی شدهاند. برای مثال کتاب روشهای مقدماتی آمار تالیف جناب دکتر بهبودیان از بهترین کتابها در این زمینه است. همچنین کتاب آمار تاپارامتری ایشان نیز به بررسی استنباط ناپارامتری در آمار میپردازید. که البته مطالعه هر دو کتاب را به شما پیشنهاد میکنم.
به عنوان یک کتاب منبع انگلیسی نیز برای رشتههای کامپیوتر و فنی نیز کتاب All of Statistics تالیف larry Waserman نیز توصیه میشود. در این کتاب همه روشهای آماری (پارامتری و ناپارامتری) اشاره و بررسی شدهاند. برای توضیحات در مورد این کتاب میتوانید به اینجا مراجعه کنید.
باز هم از اینکه همراه ما هستید متشکریم.
آیا پارامتریک یا غیر پارامتریک بودن متغیر ها در انتخاب روش تحلیل آماری و رگرسیون گیری موثر هستند؟ ممکنه منبع یا نوشتاری در مورد نحوه ی تطبیق توزیع های مختلف پراکندگی با توابع ریاضی معرفی کنید؟
با سلام و درود خدمت خواننده گرامی
از اینکه با مطالب فرادرس همراه هستید خوشحالیم!
در پاسخ به پرسش شما باید یک نکته را روشن کنم. پارامتریک یا ناپارامتریک بودن مربوط به متغیرها نیست بلکه مربوط به روش و تکنیکی است که متغیرها را به کمک تحلیل میکنیم.
از طرفی برای تطبیق دادهها با توزیعهای آماری از روشهای مختلفی مانند روشهای نموداری یا آزمونهای برازش توزیع استفاده میشود. میتوانید در مطلب آزمون نیکویی برازش (Goodness of Fit Test) و استقلال — کاربرد توزیع کای2 این موضوع را بیشتر مطالعه کنید.
با تشکر از زحمات شما.
در اولین جدول، ستون نمرات استاندارد (نمره Z) مقادیر محاسبه نشده اند و همان مقادیر خام نوشته شدها ند.
با تشکر از توجه شما. نظر شما کاملا صحیح بود. جدول براساس محاسبات اصلاحی، به روز شده و نتایج در آن قابل مشاهده است.
خیلی ممنون. مفید بود.
در مورد محاسبه مقدار انحراف میانگین و استفاده از جدول بیشتر توضیح میدادید بهتر میشد.
خیلی خوب بود
سلام.بسیار عالی بود.
بسیار جامع و قابل فهم بود؛متشکرم
سلام بشما بزرگوار. خیلی مفید بود. سپاس بیکران
با سلام و احترام مفاهیم بسیار عالی به خواننده منتقل میشود. تشکر از زحمات
ممنون عالی توضیح دادید