



انحراف استاندارد و خطای استاندارد – از صفر تا صد
اغلب در محاسبات و آزمونهای آماری با دو واژه شبیه به هم به نامهای انحراف استاندارد و خطای استاندارد مواجه میشویم. از آنجایی که این دو عبارت هر دو کلمه استاندارد را یدک میکشند، به نظر میرسند که یک ملاک عمومی برای سنجش ویژگیهایی آماری باشند. ولی آیا انحراف استاندارد و خطای استاندارد با یکدیگر تفاوت دارند یا واژهای برای بیان یک خاصیت از جامعه آماری هستند؟ در این نوشتار میخواهیم به تفاوت و البته ارتباطی که بین این دو اصطلاح آماری وجود دارند، بپردازیم.



به این منظور بهتر است ابتدا نوشتارهای دیگر مجله فرادرس مانند واریانس و اندازههای پراکندگی — به زبان ساده و امید ریاضی (Mathematical Expectation) — مفاهیم و کاربردها را مطالعه کنید. همچنین خواندن مطالب متغیر تصادفی، تابع احتمال و تابع توزیع احتمال، آزمایش تصادفی، پیشامد و تابع احتمال و میانگین وزنی — به زبان ساده نیز خالی از لطف نیست.
انحراف استاندارد و خطای استاندارد
در مباحث آماری، دادههای جمعآوری شده، اغلب با استفاده از مقدار «میانگین» (Mean) و «انحراف استاندارد نمونهای» (Sample Standard Deviation) توصیف میشوند. همچنین ممکن است این کار بوسیله مشخص کردن مقدار میانگین و «خطای استاندارد» (Standard Error) صورت گیرد.
با توجه به نزدیک بودن معنی دو اصطلاح انحراف استاندارد و خطای استاندارد اغلب ممکن است با یکدیگر اشتباه گرفته شده یا به شکل یکسانی تفسیر شوند. به یاد داشته باشید که میانگین و انحراف استاندارد، شاخصهای توصیفی برای جامعه یا نمونه آماری هستند، در حالی که خطای استاندارد یا به طور دقیقتر، «خطای استاندارد میانگین» (Standard Error of Mean)، شاخصی برای سنجش خطای برآوردگر و توصیفی از روش نمونهگیری تصادفی است.

انحراف استاندارد از دادههای حاصل از جامعه یا نمونه آماری تولید میشود. در مقابل، خطای استاندارد میانگین، یک عبارت احتمالی در مورد نسبت اندازه نمونه و انحراف استاندارد نمونهای است. این شاخص، با توجه به «قضیه حد مرکزی» (Central Limit Theorem)، سعی در اندازهگیری خطای برآورد میانگین جامعه آماری دارد.
به عبارت ساده، خطای استاندارد میانگین نمونه، تخمین میزند که میانگین نمونه از میانگین جمعیت تا چه حد دور یا نزدیک است. در مقابل انحراف استاندارد شاخصی است که متوسط اختلاف مقادیر از میانگین نمونه یا جامعه آماری را نشان میدهد.
اگر انحراف استاندارد جمعیت متناهی باشد، خطای استاندارد میانگین نمونه با افزایش حجم نمونه به صفر میرسد، زیرا برآورد میانگین جمعیت بهبود مییابد، در حالی که انحراف استاندارد (نمونه یا جامعه) اغلب با اضافه شدن مشاهده جدید به دادهها، افزایش مییابد.
به این ترتیب مشخص است که باید بین انحراف استاندارد و خطای استاندارد تفاوت قائل شد. در ادامه توضیحات بیشتری نیز ارائه میشود.
انحراف استاندارد یک شاخص توصیفی
همانطور که گفته شد، انحراف استاندارد ابزاری برای نمایش میزان پراکندگی دادهها است. شیوه محاسبه «انحراف استاندارد» درست شبیه «واریانس» (Variance) است. به فرمول زیر توجه کنید. در نظر بگیرید که جامعهای شامل مقدار مختلف مانند داریم و میخواهیم واریانس و انحراف استاندارد را محاسبه کنیم.
که در آن ، میانگین مقادیر است. براساس واریانس، انحراف استاندارد بدست میآید.
البته شایان ذکر است که اگر به جای جامعه آماری، مشاهدات حاصل از یک نمونهای آماری از جامعه بودند، محاسبه واریانس و انحراف استاندارد کمی با تغییر همراه بود. نحوه محاسبه واریانس نمونهای و انحراف استاندارد نمونهای در ادامه دیده میشود.
در اینجا فرض بر این است که یک نمونه تایی از جامعه آماری به صورت در اختیارمان قرار گرفته است.
نکته: توجه داشته باشید که در فرمول مربوط به واریانس یا انحراف معیار جامعه از استفاده کردیم، زیرا متغیر تصادفی نیستند. ولی برای محاسبه واریانس و انحراف معیار نمونهای از نماد استفاده میشود تا نشان دهنده تصادفی بوده آنها باشد، زیرا مقدار آنها از نمونهای به نمونه دیگر متفاوت است.
و همچنین برای انحراف معیار نمونهای نیز همان ارتباط با واریانس را خواهیم داشت.
نکته: در مخرج محاسبه واریانس نمونهای از استفاده شده تا یک «برآوردگر نااریب» (Unbiased Estimator) حاصل شود.
موضوع مهم در محاسبه واریانس و انحراف معیار، استفاده از میانگین به عنوان یک نقطه مرکزی و سنجش مجموع مربعات فاصلههای مقادیر دیگر نسبت به آن است. در این حالت فقط از معیار مرکزی برای انجام محاسبات استفاده شده ولی برای برآورد آن، این عمل صورت نگرفته است و مستقیما براساس انحراف استاندارد بدست میآید.

خطای استاندارد میانگین
نمونهگیری از جامعه آماری با هدف برآورد پارامترها و شناخت آن جامعه صورت میپذیرد. به این ترتیب میانگین حاصل از یک نمونه تصادفی به اسم میتواند برآورد مناسبی برای میانگین جامعه آماری باشد. ولی از آنجایی که مقدار این برآورد از نمونهای به نمونه دیگر متفاوت است، آن را یک «متغیر تصادفی» (Random Variable) یا «آماره» (Statistics) مینامیم.
پس مشخص است که برآورد میانگین که توسط یک نمونه تصادفی حاصل شده، دارای خطا است. این خطا توسط «خطای استاندارد میانگین» (Standard Error) اندازه گیری میشود.
بنابراین باید مشخص کنیم که اگر میانگین واقعی برای جامعه آماری باشد، برآورد آن یعنی چقدر از آن فاصله دارد. این فاصله را میتوان به وسیله واریانس معرفی و محاسبه کرد.
البته میدانیم که انتظار داریم میانگین برآوردگرها () به میانگین واقعی نزدیک و تقریبا با آن فاصلهای نداشته باشد. این ویژگی را برای یک برآوردگر، «نااریبی» (Unbiasness) مینامند. پس به این ترتیب داریم:
که در آن ، نماد یا عملگر «امید ریاضی» (Mathematical Expectation) یا «مقدار مورد انتظار» (Expected Value) یا چشم داشتی است. حال فاصله برآوردگر از پارامتر یا مقدار مورد انتظار را برحسب واریانس محاسبه میکنیم. طبق تعریف واریانس مجموع متغیرهای تصادفی مستقل داریم:
از طرفی انحراف معیار براساس این واریانس نیز به صورت زیر حاصل میشود.
رابطه محاسبه خطای استاندارد میانگین برحسب انحراف معیار
توجه داشته باشید که اگر انحراف معیار جامعه () مشخص نباشد، باید از برآوردگر انحراف معیار نمونهای استفاده کرد. البته این کار احتیاج به یک ضریب تصحیح نیز دارد که در ادامه این مطلب به آن اشاره خواهیم کرد.
نکته: همانطور که مشاهده میشود، با افزایش تعداد نمونهها، واریانس خطای میانگین و در نتیجه خطای استاندار میانگین، کاهش مییابد. زیرا اثر افزایش تعداد، دوبار تاثیر گذار است. یکبار در محاسبه واریانس یا انحراف استاندارد نمونهای که مجموع مربعات به تعداد تقسیم میشود و یکبار هم هنگام محاسبه خطای استاندارد میانگین، عمل تقسیم صورت میگیرد.
ضریب تصحیح جامعه متناهی و همبستگی نمونهای
محاسبه خطای استاندارد میانگین به دلیل اهمیت آن در برآورد میانگین و اندازه خطای آن، باید با دقت صورت گیرد. در این میان دو دلیل برای به کار بردن ضریب تصحیح وجود دارد که اولی متناهی بودن جامعه آماری و دومی همبستگی بین نمونههای تصادفی است. ابتدا ضریب تصحیح جامعه متناهی را توضیح داده، سپس به بررسی همبستگی نمونهها خواهیم پرداخت.

ضریب تصحیح برای محاسبه انحراف استاندارد و خطای استاندارد
معمولا هنگام محاسبه انحراف معیار و خطای استاندارد میانگین، فرض بر این است که اندازه جامعه () بسیار بزرگ بوده و در مقابل، حجم نمونه () کوچک است. ولی اگر حجم نمونه بزرگ باشد و بیش از ۵٪ جامعه آماری را شامل شود، بهتر است انحراف استاندارد و خطای استاندارد میانگین را به کمک یک ضریب تصحیح، بهینه کرد. این ضریب برای هر یک از این شاخصها به صورت زیر نوشته میشود.
ضریب تصحیح جامعه متناهی برای انحراف استاندارد
ضریب تصحیح جامعه متناهی برای خطای استاندارد میانگین
مشخص است که برای انحراف استاندارد، ضریب تصحیح باعث ایجاد یک «برآوردگر نااریب» (Unbiased Estimator) میشود.
نکته: عبارت FPC مخفف «تصحیح جامعه متناهی» (Finite Population Correction) است.
برای جوامعی که اندازه جامعه بزرگ باشد، میتوان ضریب تصحیح را به صورت زیر بدست آورد.
البته در صورتی که نمونههای تصادفی، مستقل از یکدیگر نبوده و با هم به میزان ثابتی مثل ، وابستگی داشته باشند، ضریب تصحیح به صورت زیر نوشته خواهد شد.
توجه داشته باشید که وابستگی بین نمونهها، بوسیله ضریب «همبستگی سریالی» یا «ضریب خود همبستگی» (Auto-correlation) مرتبه اول مورد محاسبه قرار میگیرد.
در ادامه برای درک بهتر مفهوم اصطلاحات انحراف استاندارد و خطای استاندارد به شکل ساده (بدون در نظر گرفتن ضریب تصحیح)، به ذکر مثال و محاسباتی در این رابطه میپردازیم.
محاسبه انحراف استاندارد و خطای استاندارد در زبان برنامهنویسی R
این بخش اختصاص به بررسی کدهایی دارد که به زبان برنامهنویسی R نوشته شدهاند و به ما تفاوت بین انحراف معیار و خطای استاندارد را نشان میدهند. ابتدا یک سری داده تصادفی از توزیع نرمال (۱۰ مشاهده) تولید کرده و انحراف معیار آنها را محاسبه میکنیم.

نتیجه محاسبات با توجه به مقدار seed، برابر است با 1.144105 که انحراف معیار نمونهای است. در برنامه بعدی نمودار توزیع نرمال با میانگین صفر و واریانس یک را ترسیم کردهایم.

نکته: استفاده از دانه تصادفی (Seed) باعث میشود که تولید دادههای تصادفی در هر بار تکرار این برنامه، یکسان باشد. در نتیجه خروجی حاصل از این برنامه برای شما هم برابر با همین مقدار 1.144105 خواهد بود.
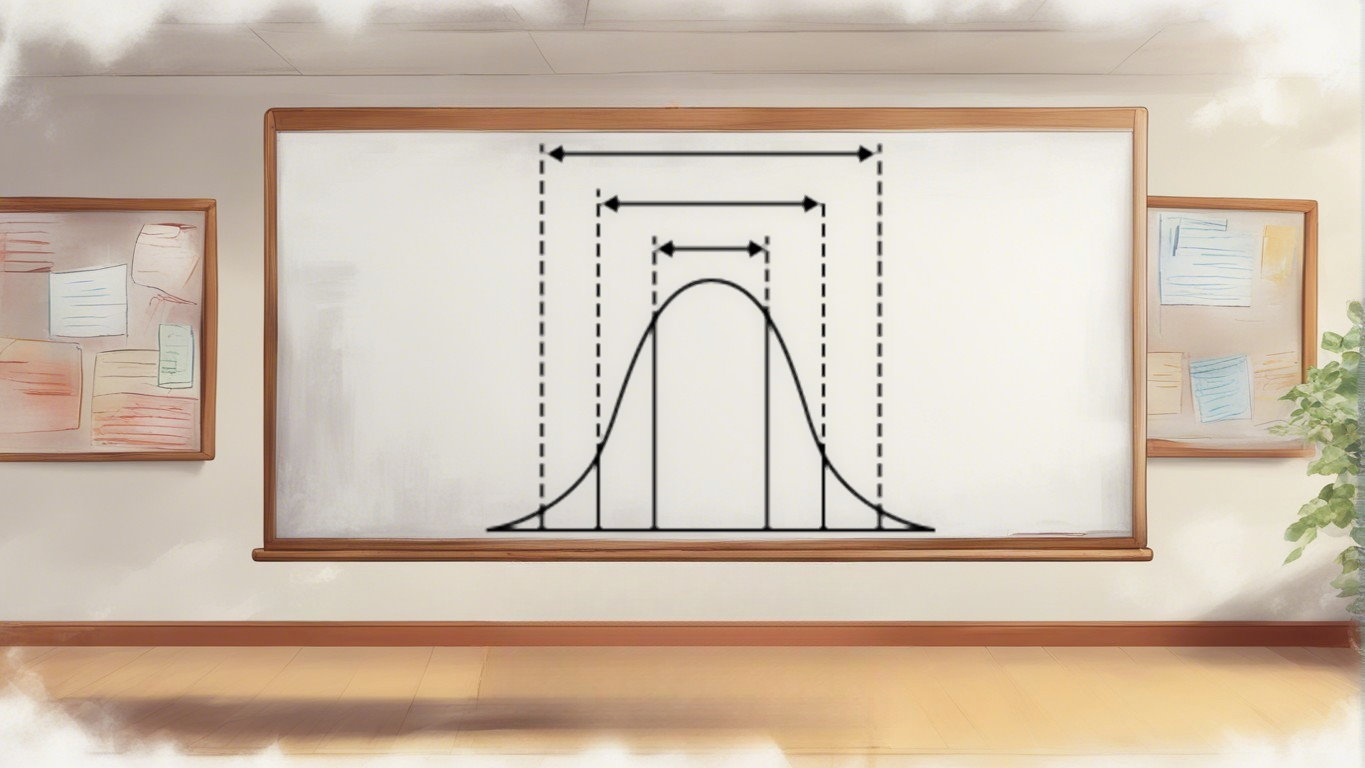
نتیجه اجرای کد بالا، تصویری است که در پایین دیده میشود. نقطههایی با فاصله یک انحراف معیار از میانگین نیز مشخص شدهاند که حدود ۶۸ درصد دادهها را تشکیل میدهد.

همچنین در فاصله ۲ انحراف استاندارد از میانگین، حدود ۹۵ درصد دادهها قرار گرفتهاند. اگر سه انحراف استاندارد از میانگین دور شویم، تقریبا ۹۹.۷ درصد از دادهها را پوشش دادهایم. به این ترتیب مشخص است که انحراف معیار، شاخصی برای نمایش دوری یا نزدیکی به میانگین است.
حال این بار فرض کنید که عمل نمونهگیری از چنین جامعهای را چندین بار تکرار کردهایم و هر بار یک مقدار برای میانگین نمونهای بدست آوردهایم. خطای استاندارد، واریانس یا انحراف معیار این مقادیر را نشان میدهد.
نکته: توجه داشته باشید که در اینجا به علت بدست آوردن نمونههای متنوع از اجرای دستور set.seed چشمپوشی کردهایم. بنابراین ممکن است نتیجه محاسبه شما با چیزی که در این متن به آن اشاره شده، اندکی تفاوت داشته باشد.
طی برنامه بالا، فرض کردهایم که از جامعه نرمال با میانگین صفر و واریانس ۱، هر بار ۱۰ (n = 10) نمونه تصادفی گرفته و میانگین و انحراف معیار آن نمونه را محاسبه کردهایم. این کار را به تعداد هزار بار (m = 1000) تکرار کردهایم و هزار میانگین نیز حاصل شده است. انحراف معیار میانگینهای بدست آمده، همان خطای استاندارد میانگین هستند. شما میتوانید با تغییر مقدار m یا n، نتایج دیگری بدست آوردید و به شکلی، تخمین میانگین جامعه را با افزایش تعداد تکرارها، بهتر انجام دهید.
به منظور تاکید بیشتر در انتها نیز، طبق رابطه انحراف استاندارد و خطای استاندارد میانگین، انحراف استاندارد نمونهای را بر جذر تعداد مشاهدات تقسیم کردهایم تا خطای استاندارد حاصل شود. همانطور که در ادامه مشاهده میکنید، این دو مقدار تقریبا برابر یکدیگرند. با افزایش تعداد تکرارها (m)، خطای استاندارد میانگین حاصل از نمونههای تصادفی و همچنین فرمول مربوطه به یکدیگر نزدیک خواهند شد.
در ادامه خطای استاندارد برای n=10000 در دو حالت محاسبه و نمایش داده شده است. واضح است که با افزایش تعداد نمونهها، برآورد میانگین جامعه آماری بهتر صورت میگیرد.
مقدار خطای استاندارد در اینجا نشان میدهد که با افزایش حجم نمونه، خطای برآورد میانگین کاهشی است و دقت در برآورد میانگین بهتر شده است.
نکته: معمولا برای نمایش دقت برآوردگر و نشان دادن رابطه آن با حجم نمونه، از خطای استاندارد میانگین استفاده میکنند. در اینجا هم دیدیم که این رابطه براساس حجم نمونه، نزولی است و هرگاه حجم نمونه افزایش یابد، خطای برآورد کاهش یافته و در مقابل، دقت برآورد افزایش خواهد یافت. از طرفی اگر انحراف استاندارد جامعه زیاد باشد، دقت برآورد یا خطای استاندارد نیز افزایشی خواهد بود و برآورد مناسب و با دقتی حاصل نخواهد شد، مگر آنکه حجم نمونه را افزایش دهیم.
خلاصه و جمعبندی
در این نوشتار از مجله فرادرس، با دو مفهوم اساسی به نامهای انحراف استاندارد و خطای استاندارد آشنا شدیم که به رغم شباهتهایشان، تفاوتهای مهم و چشمگیری دارند. همانطور که دیدید، انحراف استاندارد یا معیار، به عنوان یک شاخص پراکندگی برای مقادیر دیده میشود، در حالیکه خطای استاندارد میانگین، مربوط به پراکندگی برآوردگر میانگین جامعه آماری از پارامتر واقعی آن است. به این ترتیب، واریانس و انحراف معیار به عنوان مقداری توصیفی و خطای استاندارد میانگین ابزاری برای استنباط آماری یا برآورد نقطهای است.










