



توزیع های آماری F و T – مفاهیم و کاربردها
در این نوشتار به بررسی توزیعهایی میپردازیم که براساس یک نمونه تصادفی حاصل میشوند و در آزمونهای مربوط به پارامترهای جامعه کاربرد دارند. برای مثال از توزیع نمونهای F برای آزمون نسبت واریانس دو جامعه استفاده میشود و همچنین از توزیع T نیز برای آزمونهایی که مربوط به میانگین جامعه است بهره میبرند.


از آنجایی که در این نوشتار از متغیر تصادفی و تابع احتمال صحبت به میان خواهد آمد بهتر است ابتدا مطلب متغیر تصادفی، تابع احتمال و تابع توزیع احتمال را مطالعه کرده باشید. همچنین اگر به مباحث مربوط به آزمون فرض که توسط آمارههایی با توزیع F و T صورت میپذیر علاقهمندید بهتر است مطلب آزمونهای فرض و استنباط آماری — مفاهیم و اصطلاحات را بخوانید تا با آمادگی کامل به بررسی این توزیعها بپردازیم.
توزیع F یا F- Distribution
توزیع F یا توزیع فیشر-سندکور (Fisher-Snedecor) یک توزیع احتمال پیوسته است که بیشتر برای آزمونهای فرض مربوط به تحلیل واریانس (ANOVA) به کار میرود. این توزیع براساس تحقیقات «رونالد فیشر» (Ronald Fisher) و «جورج سندکور» (George Snedecore) ابداع و خصوصیات آن بررسی و ارائه شد.
تعریف توزیع F
اگر X دارای توزیع F با پارامترهای و باشد، مینویسیم در این حالت تابع احتمال این متغیر تصادفی X با مقدارهای مثبت (x>0) به صورت زیر خواهد بود:
که منظور از B همان تابع بتا است. مقدار پارامترهای و نیز اغلب صحیح و نامنفی هستند. ولی در بعضی از مواقع ممکن است که به جای اعداد صحیح، پارامترهای توزیع مقدارهای حقیقی مثبت باشند. اغلب این پارامترها را درجه آزادی توزیع F مینامند.
نکته: با توجه به تعریف ارائه شده، مشخص است که تکیهگاه متغیر تصادفی F مجموعه اعداد حقیقی مثبت است.
در تصویر زیر نمودار مربوط به تابع چگالی این توزیع ترسیم شده است. همانطور که در تصویر مشخص است تابع چگالی احتمال این متغیر تصادفی برای درجههای آزادی کوچک، دارای میزان چولگی (Skewness) زیادی است ولی با افزایش درجه آزادی و ، منحنی تابع چگالی به شکل توزیع نرمال با میانگین و واریانس که در زیر معرفی شده، نزدیک میشود.

امید ریاضی و واریانس
بر اساس تابع چگالی و توزیع متغیر تصادفی، میتوان امید ریاضی و واریانس متغیر تصادفی F را برحسب پارامترهای آن محاسبه کرد.
البته این امید ریاضی را به شرطی میتوان محاسبه کرد که باشد (اگر باشد که مخرج صفر خواهد شد و اگر هم مقدارش برابر با ۱ باشد امید ریاضی مقدارهای مثبت، عددی منفی بدست میآید که به نظر صحیح نخواهد بود). همانطور که دیده میشود، امید ریاضی متغیر تصادفی با توزیع F فقط به درجه آزادی دوم یعنی وابسته است و در آن نقشی ندارد.
البته رابطه مربوط به محاسبه واریانس، به شرطی برقرار است که باشد زیرا اگر درجه آزادی برابر با ۲ یا ۴ باشد مخرج صفر خواهد شد و اگر از ۴ نیز کوچکتر باشد، مخرج منفی شده و باعث میشود که واریانس مقداری کوچکتر از صفر بدست آید. در تصویر زیر نمودار تابع توزیع تجمعی متغیر تصادفی F ترسیم شده است. باز هم مشخص است که با افزایش درجههای آزادی توزیع F، شکل تابع توزیع تجمعی به نرمال نزدیک خواهد شد.

خصوصیات توزیع F
اگر و دو متغیر تصادفی با توزیع کای-۲ (Chi Square) باشند، آنگاه X که به صورت زیر معرفی شده است دارای توزیع F با پارامترهای و است.
نکته: در اینجا فرض شده است که متغیرهای تصادفی و مستقل از یکدیگرند. در غیر اینصورت نمیتوان توزیع این نسبت را F در نظر گرفت.
از طرف دیگر با توجه به واریانس نمونهای و واریانس جامعه میتوان متغیر تصادفی F را براساس دو جامعه نرمال، تقسیم نسبت واریانس نمونهای به واریانس جامعه برای توزیع اول به نسبت واریانس نمونهای به واریانس جامعه برای توزیع دوم در نظر گرفت. پس:
نکته: در اینجا نیز باید و باشد. زیر میدانیم که براساس واریانس نمونهای :
به این معنی که سمت چپ دارای توزیع کای-۲ با n-1 درجه آزادی است.
با توجه به تعریفی که برای متغیر تصادفی F در این قسمت ارائه شد، مشخص است که برای آزمون نسبت واریانس دو جامعه نرمال باید از توزیع F استفاده کرد.
از خصوصیات دیگر این توزیع میتوان به موارد زیر اشاره کرد.
- اگر X دارای توزیع بتا با پارامترهای باشد، یعنی داشته باشیم ، آنگاه :
- اگر متغیر تصادفی آنگاه،
- اگر X دارای توزیع T با درجه آزادی n باشد، آنگاه و خواهد بود.
استفاده از جدول تابع احتمال متغیر تصادفی F
برای محاسبه مقدار احتمال یا احتمال تجمعی یک متغیر تصادفی با توزیع F از جدولهای بخصوصی استفاده میشود. برای مثال اگر بخواهیم به ازاء مقدارهای مختلف درجه آزادیهای توزیع F مقدار تابع چگالی احتمال را در نقطه X=0.5 محاسبه کنید، جدول زیر مناسب به نظر میرسد.

ولی گاهی باید برعکس عمل کنیم و بخصوص برای انجام آزمونهای آماری به صدکهای توزیع F احتیاج داریم. برای این منظور نیز میتوان از جدولهایی استفاده کرد که برحسب صدکها و محاسبه احتمال تجمعی بالایی یا پایینی ایجاد شدهاند. در تصویر زیر میزان احتمال صدک 9۵ام دیده میشود. (در اینجا به معنی P(X>x)=0.05 است.)

تصویر زیر، سطح زیر منحنی توزیع F را که مطابق با جدول بالا است را نمایش میدهد.

البته برای محاسبه مقدار تابع چگالی و یا صدکهای توزیع F از اکسل نیز میتوان کمک گرفت. در ادامه به بررسی توابعی که این کار را انجام میدهند میپردازیم.
فرض کنید بخواهیم صدک 95ام توزیع F را برای بدست آوریم. کافی است تابع F.INV را با پارامترهای میزان آلفا () و درجههای آزادی اجرا کنید.
همانطور که دیده میشود، این مقدار با جدول بالا که مربوط به صدکهایی بالایی است مطابقت دارد. در اینجا منظور از صدک ۹۵ام مقداری است که احتمال بزرگتر از آن مقدار برابر با 0.95-1=0.05 باشد. برای محاسبه تابع توزیع احتمال یا تابع توزیع احتمال تجمعی نیز از تابع F.Dist با پارامترهای x و درجههای آزادی میتوان استفاده کرد. برای مثال برای محاسبه تابع احتمال تجمعی تا نقطه 2.9782، برای توزیع F با درجههای آزادی ۱۰ و ۱۰، تابع را به صورت زیر مینویسیم:
که نشان میدهد مقدار 2.9782 تقریبا همان صدک 95 است زیرا احتمال محاسبه شده بسیار به 0.95 نزدیک است.
نکته: توجه داشته باشید که پارامتر True نشان میدهد که اکسل باید تابع احتمال تجمعی را محاسبه کند. با در نظر گرفتن مقدار False برای این پارامتر، تابع احتمال (تابع چگالی) در نقطه x محاسبه میشود. جدول زیر توابع مرتبط با توزیع F در اکسل را معرفی کرده است.
| ردیف | نام تابع | عملکرد | پارامترها |
| ۱ | F.DIST | محاسبه مقدار چگالی احتمال یا احتمال تجمعی برای سطح سمت چپ (کوچکتر از x) | X, Deg_freedom1, Deg_freedom2, Cumulative |
| 2 | F.DIST.RT | محاسبه مقدار چگالی احتمال یا احتمال تجمعی برای سطح سمت راست (بزرگتر از x) | X, Deg_freedom1, Deg_freedom2, Cumulative |
| ۳ | F.INV | محاسبه صدک برای سطح سمت چپ منحنی | Probability, Deg_freedom1, Deg_freedom2 |
| 4 | F.INV.RT | محاسبه صدک برای سطح سمت راست منحنی | Probability, Deg_freedom1, Deg_freedom2 |
نکته: با توجه به شکلی تابع توزیع F میتوان گفت که با جابجایی درجههای آزادی میتوان نوشت:
به این معنی که صدک ام برای توزیع F با درجه آزادی و با عکس صدک ام توزیع F با درجه آزادی و برابر است. برای مثال به رابطه زیر توجه کنید:
توزیع student's-t
در آمار و احتمالات، توزیع و آماره T بسیار کاربرد دارد. بخصوص هنگامی که میخواهیم در مورد میانگین جامعه نرمال، آزمون فرض انجام دهیم ولی واریانس جامعه مشخص نیست. در این وضعیت آماره آزمون جدیدی به نام آماره T انتخاب شده و آزمون براساس آن صورت میگیرد. همچنین اگر اندازه نمونه کوچک باشد و نتوان از قضیه حد مرکزی استفاده کرد، توزیع جایگزین به جای توزیع نرمال میتواند توزیع t باشد.

این توزیع براساس تحقیقات عملی دانشمند آمار، «ویلیام گُست» (William Sealy Gosset) معرفی گردید ولی از آنجایی که علاقه نداشت مقالاتش به اسم خودش باشد از اسم مستعار student استفاده میکرد. به همین دلیل این توزیع به نام student شهرت دارد.
تعریف توزیع نمونهای t
اگر متغیر تصادفی X دارای توزیع t با درجه آزادی باشد مینویسیم: . فرض کنید و iid با توزیع نرمال با پارامترهای و باشند (شرط استقلال و هم توزیعی را با iid نشان میدهیم)، آنگاه اگر میانگین نمونهای و واریانس نمونهای را به صورت زیر تعریف کنیم:
خواهیم داشت:
این متغیر تصادفی دارای توزیع t با n-1 درجه آزادی خواهد بود. شکل تابع چگالی احتمال این متغیر تصادفی به صورت زیر است:
مشخص است که منظور از ، تابع گاما و نیز درجه آزادی توزیع t است.
نکته: به مانند توزیع نرمال، توزیع t نیز متقارن است زیرا در رابطه مربوط به تابع چگالی احتمال از استفاده شده است. همچنین باید توجه داشت که تکیه گاه متغیر تصادفی t، همه اعداد حقیقی است.
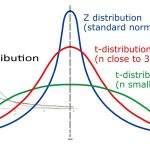
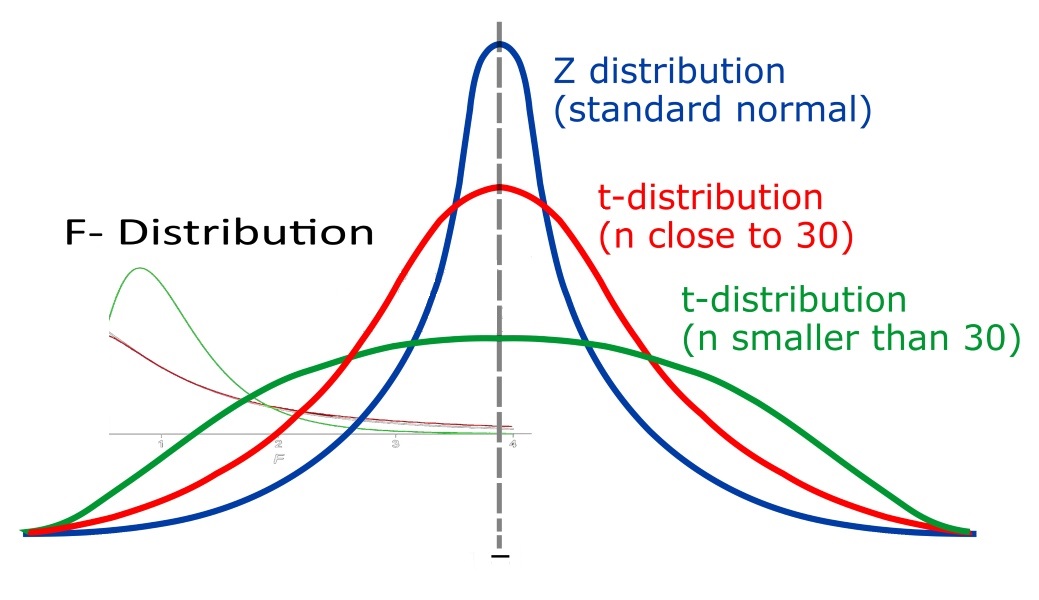
شکل منحنی تابع احتمال این متغیر تصادفی در زیر ترسیم شده است. منحنی آبی رنگ توزیع نرمال استاندارد و منحنی قرمز تابع احتمال متغیر تصادفی t را نشان میدهد. همانطور که دیده میشود به نظر میرسد دمهای این توزیع نسبت به دمهای انتهای توزیع نرمال استاندارد کمی کلفتتر است. به همین علت توزیع t را جز دسته توزیعهای «دم سنگین» (Heavy Tail) قرار میدهند.

در تصاویر بعدی، منحنیهایی که به رنگ سبز متمایز شدهاند، نمودار تابع احتمال در مرحله قبلی است که دارای درجه آزادی کمتری هستند.





کاملا مشخص است که با افزایش درجه آزادی توزیع t، شکل نمودار احتمال به توزیع نرمال نزدیک خواهد شد. به همین علت برای زمانی که درجه آزادی بیشتر از ۳۰ باشد، میتوان نمونه را برگرفته از جامعه نرمال در نظر گرفت. در تصویر زیر نیز شکل تابع توزیع تجمعی احتمال برای این متغیر تصادفی نمایش داده شده است.

امید ریاضی و واریانس
با توجه به تقارن و مشابهت این توزیع با نرمال استاندارد مشخص است که میانگین، میانه و نما برای این توزیع نیز برابر با صفر خواهد بود.

پس امید ریاضی برای متغیر تصادفی با توزیع t برابر با صفر است (البته زمانی که درجه آزادی کمتر یا مساوی با ۱ باشد امید ریاضی تعریف نشده).
واریانس نیز براساس درجه آزادی محاسبه شده و برابر است با
خصوصیات توزیع t
فرض کنید:
- اگر Z یک متغیر تصادفی نرمال استاندارد (توزیع نرمالی که میانگین برابر با صفر و واریانس آن نیز برابر با ۱ باشد).
- V نیز یک متغیر تصادفی با توزیع کای ۲ با درجه آزادی باشد.
- ٰV مستقل از Z باشد.
در این صورت اگر داشته باشیم: آنگاه . همانطور که قبلا اشاره شد، میدانیم که متغیر تصادفی V که در پایین به آن اشاره شده است، دارای توزیع کای-۲ با n-1 درجه آزادی است.
از طرف دیگر نیز مشخص است که متغیر تصادفی Z که در رابطه زیر معرفی شده نیز دارای توزیع نرمال استاندارد است.
نکته: توجه داشته باشید که تعریف و در اینجا با تعریف ارائه شده در قسمت قبل به عنوان و یکی است.
بنابراین با توجه به تعریفی که برای متغیر تصادفی با توزیع t ارائه شد، میتوان گفت T که نسبت یک توزیع نرمال استاندارد به توزیع کای-۲ است دارای توزیع t با n-1 درجه آزادی است. این رابطه در زیر نشان بیان شده است.
از آنجایی که این آماره برحسب پارامتر مجهول جامعه () نوشته شده ولی توزیع آن به بستگی ندارد، میتوان از آن به عنوان کمیت محوری برای ایجاد فاصله اطمینان استفاده کرد. از دیگر خصوصیات این توزیع میتوان به موارد زیر نیز اشاره کرد:
- اگر آنگاه خواهد بود.
- اگر درجه آزادی برای توزیع t برابر با ۱ باشد، این توزیع را «کوشی» (Cauchy) با پارامترهای مرکزی (Location) برابر با ۰ و مقیاس (Scale) برابر با ۱ مینامند. از طرف دیگر اگر درجه آزادی به میل کند، توزیع متغیر تصادفی نرمال استاندارد خواهد بود.
- اگر Z با مقدار ثابتی جمع شده باشد، متغیر تصادفی حاصل را t-غیرمرکزی (Non-Centeral t Distribution) با مقدار پارامتر مینامند. در این حالت با توجه به تعریف گذشته میگوییم:
استفاده از جدول تابع احتمال متغیر تصادفی t
برای بدست آوردن مقدار تابع چگالی متغیر تصادفی t میتوان از جدولهای آماده استفاده کرد. در زیر یک نمونه از این جدولها دیده میشود.

از طرفی برای انجام آزمونهای آماری و یا تشکیل فاصله اطمینان برای میانگین جامعه احتیاج به صدکهای توزیع t است. استخراج این مقدارها به واسطه جدولهای مانند جدول زیر امکانپذیر است.

برای مثال، صدک 75ام برای توزیع t با درجه آزادی 30 برابر است با 0.683 که با مقایسه با همین صدک با توزیع نرمال استاندارد که برابر با 0.6744 است اختلاف اندکی وجود دارد. به همین ترتیب با افزایش درجه آزادی مشخص میشود که صدکهای توزیع t به صدکهای توزیع نرمال استاندارد نزدیک و نزدیکتر خواهند شد.
نکته: سطر اول این جدول مربوط به احتمال صدکها است ولی سطر دوم بیانگر سطح اطمینان برای ایجاد فاصله اطمینان است.

برای محاسبه مقدار تابع چگالی توزیع t و همچنین صدکهای آن میتوانید از اکسل کمک بگیرید. در ادامه به بررسی توابعی در این زمینه میپردازیم. فرض کنید که میخواهید مقدار چگالی احتمال متغیر تصادفی t با ۵ درجه آزادی را در نقطه x=2 محاسبه کنید. کافی است تابع T.DIST را با پارامترهای 2 و 5 , False اجرا کنید.
همانطور که در راهنمای این تابع میتوان مشاهده کرد، مقدار بدست آمده با توجه به ناحیه سمت چپ منحنی چگالی استخراج شده است. همچنین برای محاسبه صدک ۵۰ام توزیع t با ۵ درجه آزادی کافی است تابع زیر را به کار برید:
از آنجایی که صدک ۵۰ام همان میانه است، مشخص میشود که برای توزیع t که تقارن نیز دارد، باید حاصل این تابع برابر با صفر باشد زیرا باید میانه را محاسبه کند. جدول زیر به معرفی توابعی از اکسل میپردازد که با توزیع t ارتباط دارند.
| ردیف | نام تابع | عملکرد | پارامترها |
| ۱ | T.DIST | محاسبه مقدار احتمال یا احتمال تجمعی برای سطح سمت چپ (کوچکتر از x) | X, Deg_freedom, Cumulative |
| 2 | T.DIST.RT | محاسبه مقدار احتمال یا احتمال تجمعی برای سطح سمت راست (بزرگتر از x) | X, Deg_freedom, Cumulative |
| ۳ | T.INV | محاسبه صدک برای سطح سمت چپ منحنی | Probability, Deg_freedom |
| 4 | T.DIST.2T | محاسبه مقدار احتمال یا احتمال تجمعی برای دو طرفه (بزرگتر از x و کوچکتر از x-) | X, Deg_freedom, Cumulative |
| 5 | T.INV.2T | محاسبه صدک برای سطح دو طرفه (دم سمت راست و چپ) | Probability, Deg_freedom |
نکته: باید توجه داشت که برای تابع T.DIST.2T مقدار x باید مثبت باشد، در غیراینصورت، نتیجه فرمول با خطا مواجه خواهد شد.
اگر به فراگیری مباحث مشابه مطلب بالا علاقهمند هستید، آموزشهایی که در ادامه آمدهاند نیز به شما پیشنهاد میشوند:
- مجموعه آموزشهای آمار، احتمالات و دادهکاوی
- آزمایش تصادفی، پیشامد و تابع احتمال
- آموزش آمار و احتمال مهندسی
- مجموعه آموزشهای SPSS
- مجموعه آموزشهای نرمافزارهای آماری
- آموزش آزمون های فرض مربوط به میانگین جامعه نرمال در SPSS
- آموزش آزمون آماری و پی مقدار (p-value)
- جامعه آماری — انواع داده و مقیاسهای آنها
- تحلیلها و آزمونهای آماری — مفاهیم و اصطلاحات
- آزمون فرض میانگین جامعه در آمار — به زبان ساده
- فاصله اطمینان (Confidence Interval) — به زبان ساده
^^











با سلام استاد گرامی. عذر میخوام من اگر بخوام برابری وراثت پذیری رو با صفر از طریق ازمون T بسنجم در اکسل باید چه تابعی وارد کنم؟ درجه ازادی ۹۶ و مقدار وراثت پذیری صفت من ۶/۰۸ , و t محاسبه شده هم ۳۷۷ هست. تشکر
با سلام و تشکر خدمت شما
سوالی داشتم چرا برای محاسبه احتمال در توزیع تی مقدار احتمال در نقطه الفا برابر مساحت سمت راست القا هست ولی در توزیع نرمال مساحت سمت چپ الفا رو در نظر می گیریم با این اینکه این دو توزیع مشابه هم هستن و فقط توزیع تی واریانس بیشتری نسبت به توزیع نرمال دارد و سوال دیگه اینکه با این فرض پیدا کردن احتمال ها از روی جدول با این توضیفات نباید مثل هم باشه
پیشاپیش ممنونم از پاسخگویی شما
یه سوال چرا برای الفا در توزیع اف پنج احتمال یک صدم و پنج صدم و ۲۵ صدم و ۲۵ هزارم را داریم؟