



فاصله اطمینان (Confidence Interval) – به زبان ساده
محققان و تحلیلگران، اغلب در مباحث آمار و دادهکاوی، از عبارت «فاصله اطمینان» (Confidence Interval) استفاده میکنند تا نشان دهند که تقریبا مطمئن هستند یک فاصله یا محدودهای عددی، شامل پارامتر مورد جامعه است. پس میتوان فاصله اطمینان را نوعی برآورد فاصلهای در نظر گرفت. این پارامتر را اغلب با CI نشان میدهند.



فاصله اطمینان با مفهوم مربوط به «سطح اطمینان» (Confidence Level) ارتباط نزدیکی دارد. منظور از سطح اطمینان، تعیین میزان شک یا یقینی است که نسبت به دربرگیری پارامتر توسط CI، داریم.
در حقیقت این محدوده، توسط یک نمونه تصادفی محاسبه میشود، در نتیجه میتوان CI را یک محدوده تصادفی در نظر داشت. با انتخاب نمونه دیگر، محاسبات برای این محدوده تغییر کرده و یک فاصله اطمینان متفاوت بدست خواهد آمد. به همین علت با سطح اطمینان مشخص، خانوادهای از فاصلههای اطمینان با توجه نمونههای مختلف تولید میشود.
به این ترتیب میتوان گفت سطح اطمینان، فراوانی نسبی، فاصلههای اطمینانی است که شامل پارامتر مجهول جامعه هستند. به بیان دیگر، اگر n فاصله اطمینان با سطح اطمینان ثابت ایجاد کنیم، نسبت آنهایی که شامل پارامتر هستند به کل فاصلهها، برابر با همان سطح اطمینان خواهد بود. هدف در محاسبه CI، بدست آوردن حدودی برای پارامتر است که در سطح اطمینان تعیین شده، شامل پارامتر باشد.
برای درک بهتر این نوشتار بهتر است که مطلب متغیر تصادفی، تابع احتمال و تابع توزیع احتمال را که در مورد تابع احتمال و ویژگیهایی متغیر تصادفی است، قبلا مطالعه کرده باشید. همچنین با توجه به قرابت موضوع فاصله اطمینان با آزمون فرض آماری و برآورد فاصلهای، خواندن مطلب آزمون های فرض و استنباط آماری — مفاهیم و اصطلاحات خالی از لطف نیست.
فاصله اطمینان
فرض کنید قد ۴۰ نفر که به طور تصادفی انتخاب شدهاند، اندازهگیری شده است. میانگین قد این افراد برابر است با ۱۷۵ سانتیمتر. از طرفی میدانیم که انحراف معیار قد در جامعه آماری ما برابر است با ۲۰ سانتیمتر.
با توجه به این موضوع، فاصله اطمینان برای میانگین قد افراد جامعه با سطح اطمینان ۹۵ درصدی برابر است با
فاصله اطمینان بیان میکند که اگر ۱۰۰ بار نمونهگیری تکرار شود و ۱۰۰ فاصله اطمینان ۹۵٪ تولید شود، 95 فاصله شامل پارامتر جامعه خواهند بود و فقط 5 تا از این فاصلهها شامل میانگین جامعه نمیشوند.
نکته: سطح اطمینان در اینجا برابر با ۹۵٪ است. پس ممکن است در ۵٪ مواقع به فاصله اطمینانی برخورد کنیم که دربرگیرنده پارامتر جامعه نباشد.تصویر بالا این امر را بهتر نشان میدهد. همانطور که دیده میشود یکی از ۲۰ فاصله اطمینان شامل میانگین جامعه نیست. پس سطح اطمینان برای این فاصله ها 95٪ یا میزان خطا برابر با 5٪ است.
متاسفانه پارامتری که قصد داریم برای آن یک فاصله اطمینان ایجاد کنیم، نامعلوم است (اگر این پارامتر معلوم بود دیگر احتیاجی به فاصله اطمینان نداشتیم) در نتیجه هرگز نمیتوانیم پیببریم که فاصله اطمینان بدست آمده حتما شامل پارامتر اس یا خیر.
به توجه به این توضیحات مشخص است که برای ایجاد فاصله اطمینان، باید سطح اطمینان مشخص شده باشد. معمولا سطح اطمینان را با نشان میدهند که در آن همان احتمال خطای نوع اول در آزمون فرض آماری است.
پس به نظر میرسد هدف از ایجاد فاصله اطمینان، بدست آوردن فاصلهای تصادفی است که با احتمالی برابر با سطح اطمینان ، شامل پارامتر باشد.
در اینجا و حدود فاصله اطمینان هستند که برحسب نمونه تصادفی حاصل میشوند.
برای بدست آوردن CI باید علاوه بر اطلاع از سطح اطمینان، تابعی از نمونه تصادفی ایجاد کرد که بتوان برای آن احتمال را محاسبه نمود، بدون اینکه احتیاجی به دانستن پارامتر مجهول باشد. به چنین تابع، «کمیت محوری» (Pivotal Quantity) میگویند.
کمیت محوری
کمیت محوری، تابعی است از نمونه تصادفی و پارامترها، که توزیع آن به پارامتر یا پارامترهای مجهول بستگی ندارد. با توجه به این تعریف مشخص است که کمیت محوری، ماهیتی تصادفی دارد. یعنی با تغییر نمونه تصادفی، این کمیت نیز تغییر خواهد کرد. از طرفی این تابع دارای توزیع احتمالی است که به پارامتر مجهول بستگی ندارد، در نتیجه محاسبه تابع توزیع یا احتمال برای آن با مشکل مواجه نخواهد شد. معمولا کمیت محوری را با Q نشان میدهند.
اگر رابطه بالا را براساس کمیت محوری بازنویسی کنیم، خواهیم داشت:
به این ترتیب اگر a و b به شکلی باشند که آنگاه فاصله اطمینان حاصل را با دمهای برابر مینامند.

پس از پیدا کردن فاصله اطمینان برای کمیت محوری یعنی محاسبه کرانهای a و b، میتوان برای پارامتر نیز کرانهای و را بدست آورد، زیرا در کمیت محوری از پارامتر نامعلوم استفاده شده است، بنابراین با یک تبدیل معکوس به راحتی کرانهای CI محاسبه میشوند.
مراحل ساخت فاصله اطمینان برای میانگین جامعه نرمال
فرض کنید نمونههای تصادفی از متغیر تصادفی X باشند که دارای توزیع نرمال با میانگین و واریانس است. یعنی .

هدف در اینجا ساختن فاصله اطمینان برای میانگین جامعه است. از آنجایی که احتیاج به یک کمیت محوری داریم، بهتر است از برآورد نقطهای میانگین جامعه استفاده کنیم. در جامعه نرمال، برآوردگر نقطهای برای میانگین جامعه () میتواند باشد. پس سعی داریم در اینجا به کمک برآوردگر نقطهای برای میانگین جامعه، فاصله اطمینان را محاسبه کنیم.
با توجه به فرضیاتی که در این قسمت گفته شد، میدانیم توزیع برابر است با
از طرفی میدانیم که دارای توزیع نرمال با میانگین صفر است. پس داریم:
از این تابع، میتوان برای تشکیل کمیت محوری استفاده کرد به شرط آن که واریانس جامعه معلوم باشد. در نتیجه باید با توجه به معلوم و نامعلوم بودن واریانس جامعه توزیع این تابع را مشخص کرده سپس به ساختن فاصله اطمینان بپردازیم. پس دو وضعیت را بررسی میکنیم : ۱- «واریانس جامعه معلوم« (Variance Known) باشد. ۲- «واریانس جامعه نامعلوم» (Variance Unknown) است.

فاصله اطمینان برای میانگین با فرض معلوم بودن واریانس
با توجه به فرضیات بالا، سعی داریم احتمال زیر را محاسبه میکنیم.
میدانیم که
در نتیجه از Z به عنوان تابع محوری میتوان استفاده کرد. بنابراین خواهیم داشت.
همچنین اگر a را قرینه b در نظر بگیریم، میتوانیم رابطه بالا را به صورت زیر بنویسیم.
از آنجایی که Z دارای توزیع نرمال استاندارد است، پس دارای توزیع متقارن بوده (فاصله اطمینان با دمهای برابر) و طرف چپ تساوی را میتوان با توجه به قوانین محاسبه برحسب تابع توزیع احتمال، به صورت زیر نوشت:
نکته: میدانیم که منظور از مقدار تابع توزیع احتمال تجمعی نرمال استاندارد در نقطه b است.
از طرفی میدانیم که پس خواهیم داشت:
پس رابطه بین و به صورت زیر خواهد بود:
پس مقدار b برابر است با . حال رابطه اصلی را با توجه به مقدار b بازنویسی میکنیم.
و سپس Z را جایگذاری کرده و فاصله اطمینان را بدست خواهیم آورد.
نکته: منظور از صدک ام توزیع نرمال استاندارد است.
پس
در نتیجه خواهیم داشت:

معمولا مقدار را با نشان میدهند که همان صدک توزیع نرمال استاندارد است. با توجه به این فرم رابطه فاصله اطمینان به صورت زیر در خواهد آمد:
پس میتوان گفت که فاصله زیر با احتمال شامل میانگین جامعه خواهد بود.
نکته: به کمک نرمافزارها و جداول آماری مربوط به توزیع نرمال استاندارد، میتوان مقدار را براساس های مختلف پیدا کرد.
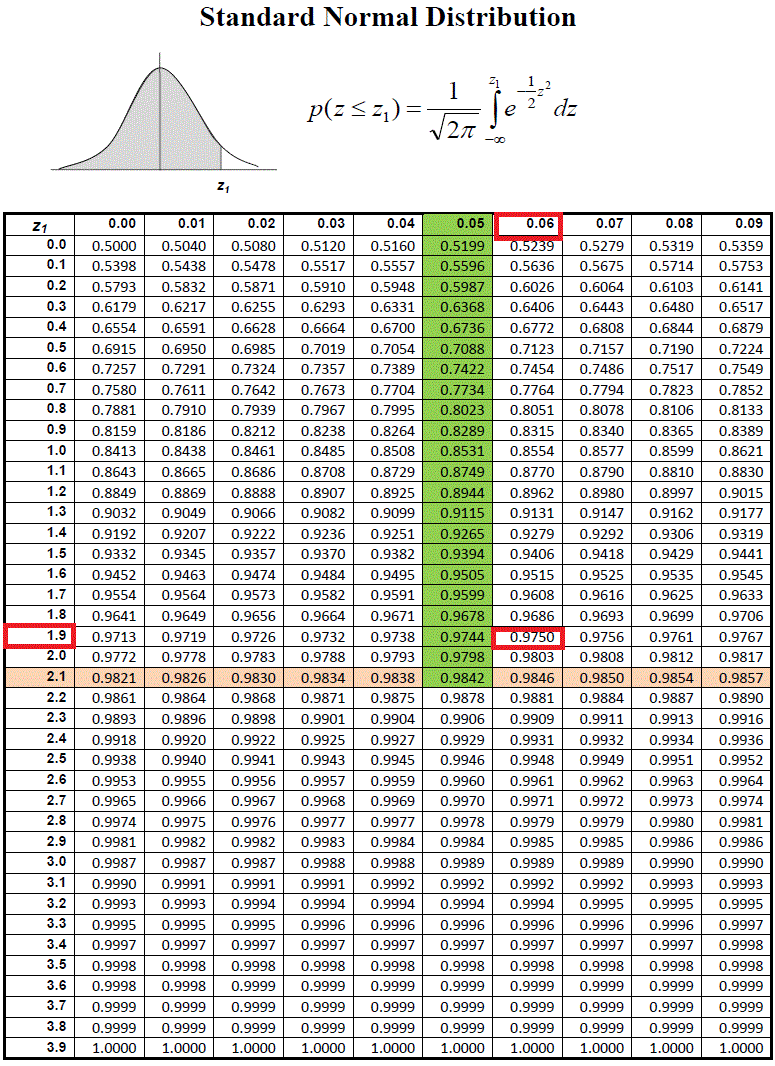 معمولا دو کاربرد برای این جدول وجود دارد. برای آشنایی با نحوه استفاده از این جدول از مثالهای زیر استفاده میکنیم.
معمولا دو کاربرد برای این جدول وجود دارد. برای آشنایی با نحوه استفاده از این جدول از مثالهای زیر استفاده میکنیم.
مثال ۱
فرض کنید متغیر تصادفی X دارای توزیع نرمال با میانگین ۵ و انحراف استاندارد 4 باشد. برای محاسبه احتمال به ترتیب زیر عمل میکنیم. از آنجایی که این جدول برای محاسبه احتمال متغیر تصادفی نرمال استاندارد قابل استفاده است، ابتدا باید متغیر تصادفی X را استاندارد کرده و به متغیر تصادفی Z تبدیل کنیم.
محاسبه بالا با توجه به میانگین و انحراف استاندارد متغیر تصادفی X صورت گرفته است. حال احتمال مورد نظر باید برحسب Z بیان شود.
برای پیدا کردن این احتمال توسط جدول به ترتیب زیر عمل میکنیم. فرض کنید منظورمان پیدا کردن مقدار احتمال تا نقطه 2.15 از توزیع نرمال استاندارد است.
- رقم یکان و اولین رقم اعشاری مقدار مورد نظر (2.1) را در ستون اول جدول پیدا میکنیم. حاصل را از عدد اولیه کم کرده و نتیجه تفاضل () را نیز در سطر اول جدول جستجو میکنیم. ممکن است این تفاضل برابر با صفر شود. در این حالت در ستون دوم (0.00) جدول جستجو را ادامه میدهیم.
- محل تقاطع سطر (نارنجی) و ستون (سبز رنگ) حاصل از مرحله قبل را در جدول مشخص میکنیم. عدد نمایش داده شده، احتمال مورد نظر است. (0.9842)
نکته: با توجه به جدول مشخص است که احتمال فقط برای مقدارهای مثبت Z نوشته شده است. برای پیدا کردن احتمال در زمانی که مقدار z منفی است، از قاعده زیر استفاده کنید.
مثلا اگر میخواهید را محاسبه کنید به صورت زیر عمل میکنیم:
مثال ۲
فرض کنید وزن یک نمونه ۴6 تایی از سیبهای یک مزرعه اندازهگیری شده است. میدانیم که انحراف استاندارد وزن سیبها برابر است با 6.2 گرم . اگر میانگین وزن این نمونه برابر با 86 گرم باشد، با سطح اطمینان 95٪، برای میانگین وزن سیبهای مزرعه، فاصله اطمینان به صورت زیر در خواهد آمد:
با توجه به اینکه سطح اطمینان برابر با 95٪ است، مشخص است که احتمال خطا برابر است با . یعنی داریم . به این ترتیب مقدار از روی جدول بالا (کادرهای قرمز رنگ) بدست میآید. پس خواهیم داشت:
پس میتوان گفت که این فاصله، با احتمال 95٪ شامل میانگین وزن سیبهای مزرعه خواهد بود.

نکته: برای محاسبه طبق «جدول احتمال تجمعی متغیر تصادفی نرمال استاندارد»، در داخل جدول مقدار 0.975 را پیدا میکنیم. مقدار سطر اول و ستون اول متناظر با این مقدار را از جدول با یکدیگر جمع میکنیم تا مقدار z مربوطه بدست آید که در اینجا مقدار سطر اول برابر با 0.06 و ستون اول 1.9 خواهد بود. جمع این دو مقدار یعنی 1.96، هزارک 975ام (صدک 97.5) یا همان را نشان میدهد.
فاصله اطمینان برای میانگین با فرض نامعلوم بودن واریانس
برای محاسبه فاصله اطمینان در این حالت نیز، از برآورد نقطهای میانگین جامعه یعنی میانگین نمونهای استفاده میشود. ولی با توجه به اینکه واریانس (انحراف معیار) جامعه مشخص نیست از کمیت محوری قبلی نمیتوان استفاده کرد، زیرا توزیع آن مشخص نیست. در زمانی که حجم نمونه (n) کم باشد، برآورد واریانس جامعه، واریانس نمونهای یعنی خواهد بود، پس میتوانیم کمیت محوری را به صورت زیر معرفی کنیم:
که در آن واریانس نمونهای به صورت زیر محاسبه میشود:
به این ترتیب، میدانیم که T دارای توزیع t با n-1 درجه آزادی است. یعنی داریم . با توجه به این موضوع، T میتواند یک کمیت محوری باشد، پس میتوانیم با انجام مراحلی که در قبل برای ایجاد فاصله اطمینان میانگین جامعه طی کردیم، CI را محاسبه کنیم. یعنی بنویسیم:
با انجام محاسبات مربوطه، در نهایت به رابطه زیر خواهیم رسید:
پس در سطح اطمینان محدوده زیر شامل میانگین جامعه خواهد بود.
مثال ۳
دادههای زیر مربوط به میزان pH در 10 نمونه از آب معدنی یک شرکت است. فاصله اطمینان 95 و 99 درصدی برای میانگین pH تولیدات آب معدنی این شرکت به صورت زیر محاسبه میشود.
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 6.39 | 6.51 | 6.54 | 6.42 | 6.52 | 6.47 | 6.69 | 6.37 | 6.63 | 6.62 |
میانگین نمونهای برابر خواهد بود با و انحراف استاندارد نمونهای نیز .
اگر سطح اطمینان را 95٪ در نظر بگیریم، خواهیم داشت:
در نتیجه طبق رابطه فاصله اطمینان میتوان نوشت:
پس
در نتیجه فاصله اطمینان به صورت زیر خواهد بود:

نکته: برای محاسبه مقدار صدکهای توزیع t میتوان از نرمافزارهای محاسباتی یا جداول آماری توزیع t استفاده کرد. در زیر یک نمونه از این جدول دیده میشود. برای نحوه استفاده از این جدول، محاسبات مثال قبل را مورد بررسی قرار میدهیم. در مثال ۳ احتیاج به مقدار داریم. در سطر اول جدول مقدار t0.975 و در ستون اول نیز مقدار ۹ را پیدا میکنیم. تقاطع این سطر و ستون مقدار هزارک 975ام توزیع t با ۹ درجه آزادی است. البته در سطر آخر جدول نیز سطح اطمینان (0.95) برای CI مشخص شده که از آن هم برای تشکیل فاصله اطمینان و تعیین صدک یا هزارک توزیع t میتوان استفاده کرد.

طول و دقت در فاصله اطمینان
طول این فاصله برابر است با 0.16. به این ترتیب مشخص است که انحراف این فاصله از میانگین جامعه برابر است با 0.16. از طرفی میتوان دقت این فاصله اطمینان را با عکس طول آن متناسب دانسنت. در نتیجه دقت این فاصله برابر است با .
حال با سطح اطمینان 99٪ فاصله اطمینان را محاسبه میکنیم. کافی است که در محاسبات، را بدست آورده و جایگذاری را انجام دهیم.
پس
در نتیجه فاصله اطمینان به صورت زیر خواهد بود:
طول این فاصله اطمینان نیز برابر است با 0.23، در نتیجه دقت آن نیز برابر خواهد بود با 4.42، در نتیجه با مقایسه فاصله اطمینان 95٪ با فاصله اطمینان 99٪ مشاهده میشود که طول فاصله اطمینان اولی کمتر از دومی است یا به عبارتی میتوان گفت دقت فاصله اطمینان اولی بیشتر از فاصله اطمینان دومی است.
به این ترتیب میتوان گفت با افزایش سطح اطمینان، دقت برآوردگر فاصله کمتر خواهد شد. البته این موضوع در مورد همه نوع فاصله اطمینان صادق است. برای مثال در فاصله اطمینان مربوط به میانگین جامعه با فرض معلوم بودن واریانس نیز همین نکته به چشم میخورد.

نکته: اگر حجم نمونه زیاد باشد، با توجه به قضیه حد مرکزی، میتوان برای تشکیل فاصله اطمینان برای میانگین جامعه، از روش قبلی استفاده کرد. فقط کافی است که به جای واریانس جامعه از برآورد نمونهای آن کمک گرفت و محاسبات مربوطه را انجام داد.
آزمون سنجش یادگیری
۱. تفاوت اصلی بین فاصله اطمینان (Confidence Interval) و سطح اطمینان چیست و هرکدام چه اطلاعاتی درباره پارامتر ناشناخته یک جامعه ارائه میدهد؟
فاصله اطمینان همیشه برابر سطح اطمینان است و هر دو درصدی از نمونههایی که پارامتر را پوشش میدهند را نشان میدهد.
فاصله اطمینان بازهای برای مقدار ممکن پارامتر و سطح اطمینان احتمال حضور پارامتر در آن بازه را بیان میکند.
فاصله اطمینان فقط از واریانس نمونه ساخته میشود و سطح اطمینان به برآورد نقطهای مربوط است.
سطح اطمینان تنها مقدار عددی طول فاصله اطمینان را مشخص میکند.
توضیح صحیح این است که فاصله اطمینان محدودهای از اعداد است که برآورد میکند پارامتر واقعی جامعه در آن قرار دارد، در حالی که سطح اطمینان درصد نمونههایی را نشان میدهد که انتظار داریم این بازه شامل پارامتر واقعی باشد. به عبارت دیگر، «فاصله اطمینان بازهای برای مقدار ممکن پارامتر» است، و «سطح اطمینان احتمال حضور پارامتر در آن بازه» را بیان میکند. گزینههای دیگر نادرستاند زیرا فاصله اطمینان و سطح اطمینان یکی نیستند (آنها مفهوم متفاوتی دارند)، سطح اطمینان طول فاصله را مشخص نمیکند، و فاصله اطمینان به ترکیبی از دادههای نمونه و ویژگیهای توزیع وابسته است و نه فقط واریانس یا برآورد نقطهای.
۲. اگر حجم نمونه (Sample Size) افزایش یابد، اثر آن بر طول و دقت فاصله اطمینان (Confidence Interval) با توجه به مفاهیم آماری چیست؟
تاثیری بر طول و دقت فاصله اطمینان ندارد.
طول فاصله اطمینان بیشتر میشود و دقت کاهش مییابد.
طول فاصله اطمینان کمتر شده و دقت افزایش مییابد.
دقت و طول فاصله اطمینان هر دو کاهش پیدا میکنند.
وقتی حجم نمونه افزایش مییابد، «طول فاصله اطمینان کمتر شده و دقت افزایش مییابد»؛ زیرا طبق فرمولهای آماری، افزایش حجم نمونه موجب کاهش خطای تصادفی و محدودتر شدن بازه CI میشود. به همین دلیل حدس ما از پارامتر جامعه دقیقتر و فاصله بازه کوچکتر میگردد. گزینه «طول فاصله اطمینان بیشتر میشود و دقت کاهش مییابد» نادرست است، زیرا افزایش حجم نمونه دقیقا عکس این تاثیر را دارد. گزینه «دقت و طول فاصله اطمینان هر دو کاهش پیدا میکنند» نیز اشتباه است، چون دقت بالا میرود و طول کمتر میشود. گزینه «تاثیری بر طول و دقت فاصله اطمینان ندارد» نیز با حقایق آماری سازگار نیست.
۳. در هنگام ساخت فاصله اطمینان برای میانگین جامعه، در چه وضعیتی باید از توزیع t به جای توزیع نرمال استفاده شود؟
زمانی که جامعه نرمال و واریانس آن معلوم باشد.
هنگامی که واریانس جامعه نامعلوم و نمونه کوچک باشد.
وقتی تعداد نمونه بسیار زیاد باشد و واریانس معلوم باشد.
در مواقعی که پارامتر جامعه به صورت دقیق مشخص باشد.
استفاده از توزیع t جایگزین توزیع نرمال زمانی ضروری است که واریانس جامعه ناشناخته باشد و برای محاسبات از انحراف معیار نمونهای استفاده کنیم، به ویژه اگر حجم نمونه کم باشد. گزینه «هنگامی که واریانس جامعه نامعلوم و نمونه کوچک باشد» دقیقا این شرایط را بیان میکند. در مقابل، زمانی که واریانس معلوم باشد یا نمونه بسیار بزرگ باشد، میتوان از توزیع نرمال استفاده کرد. همچنین استفاده از توزیع t در حالتی که پارامتر جامعه کاملا معلوم باشد مطرح نیست و کاربرد ندارد.
۴. کمیت محوری (Pivotal Quantity) در تعیین کرانهای فاصله اطمینان چه نقشی دارد و چرا توزیع آن به پارامتر مجهول وابسته نیست؟
کمیت محوری برای تعیین حجم نمونه مورد نیاز کاربرد دارد.
کمیت محوری تنها برای محاسبه میانگین نمونه بهکار میرود.
کمیت محوری به ما امکان میدهد بدون دانستن پارامتر مجهول بازهای برای آن بسازیم.
کمیت محوری مستقیما مقدار پارامتر مجهول را برآورد میکند.
کمیت محوری یا Pivotal Quantity ابزاری آماری است که با استفاده از توزیع شناختهشدهاش و بدون وابستگی به پارامتر مجهول، میتوان کرانهای فاصله اطمینان را تعیین کرد. چون توزیع کمیت محوری به گونهای تعریف میشود که به پارامتر مجهول وابسته نباشد، میتوان با کمک آن بازهای محتمل برای پارامتر ناشناخته ساخت. عبارت «تنها برای محاسبه میانگین نمونه بهکار میرود» درست نیست زیرا کاربرد کمیت محوری فراگیرتر است. مورد «برای تعیین حجم نمونه کاربرد دارد» ربطی به نقش کمیت محوری ندارد و «مستقیما مقدار پارامتر را برآورد میکند» نیز نادرست است، چون برآورد بازهای ارائه میشود نه مقدار دقیق.
۵. در هنگام محاسبه فاصله اطمینان برای میانگین جامعه نرمال زمانی که واریانس معلوم است، چه کاربردی برای z-score و جدول نرمال استاندارد وجود دارد؟
z-score برای محاسبه کرانهای فاصله استفاده میشود و جدول نرمال صدکِ متناظر را تعیین میکند.
جدول نرمال تنها برای محاسبه میانگین نمونه مورد استفاده قرار میگیرد.
z-score فقط برای محاسبه پارامتر جامعه به کار میرود و جدول نرمال نقش ندارد.
z-score صرفا برای مقایسه نمونهها بوده و در محاسبه فاصله اطمینان کاربرد ندارد.
در روش فاصله اطمینان برای میانگین جامعه نرمال و واریانس معلوم، از "z-score" جهت تعیین کران بالا و پایین فاصله اطمینان بهره گرفته میشود و مقدار صدک مورد نیاز از «جدول نرمال استاندارد» استخراج میگردد تا میزان پوشش سطح اطمینان مشخص شود. پاسخهایی مانند استفاده «z-score فقط برای محاسبه پارامتر جامعه»، «جدول نرمال برای محاسبه میانگین نمونه»، یا اینکه «z-score صرفا برای مقایسه نمونهها» بوده، همگی نادرست هستند زیرا نقش اصلی z-score و جدول نرمال در تعیین حدود فاصله اطمینان است.
۶. اگر یک پژوهشگر سطح اطمینان (Confidence Level) فاصله اطمینان (Confidence Interval) را از ۹۵٪ به ۹۹٪ تغییر دهد، چه اثری بر طول فاصله و دقت برآورد خواهد داشت؟
طول فاصله اطمینان بیشتر و دقت کمتر میشود.
طول فاصله اطمینان بیشتر و دقت بیشتر میشود.
طول فاصله اطمینان کمتر و دقت بیشتر میشود.
طول فاصله اطمینان کمتر و دقت کمتر میشود.
وقتی سطح اطمینان از ۹۵٪ به ۹۹٪ افزایش یابد، «طول فاصله اطمینان بیشتر و دقت کمتر میشود». در این حالت، فاصله بزرگتر برای پوشش دادن مقدار واقعی پارامتر با اطمینان بالاتر انتخاب میشود و این موضوع باعث کاهش دقت تخمین میشود؛ زیرا برآورد دقیقتری ارائه نمیدهد. گزینههایی مانند «طول فاصله اطمینان کمتر و دقت بیشتر میشود» و سایر انتخابها نادرستاند، چراکه رابطه بین سطح اطمینان و طول فاصله اطمینان بهصورت مستقیم و با دقت بهصورت معکوس است. پس افزایش سطح اطمینان منجر به فاصله طولانیتر اما تخمین کمدقتتر خواهد شد.











عالی
آرمان ریبد ، درود و تشکر من رو پذیرا باش بخاطر زحمتی که میکشی. مطالبی که آموزش میشی نشان از درک بالای تو از ریاضیات داره که مباحث پیچیده رو به راحتی قابل فهم میکنی. دستت رو میفشارم به نشانه احترام و ارادتی که بهت دارم
خوب
سلام . یکسری سوال امار دارم که خیلی وقته دنبال جوابشونم. ینفر میخوام که راهنماییم کنه. هست ؟!!