



الگوریتم *A – به زبان ساده
در این مطلب، «الگوریتم *A» به طور جامع و همراه با مثال مورد بررسی قرار گرفته و پیادهسازی آن در زبانهای برنامهنویسی گوناگون شامل ++C، «پایتون» (Python Programming Language) و «جاوا» (Java Programming Language) انجام شده است. در علوم کامپیوتر، الگوریتم *A (تلفظ آن، A Star است)، الگوریتمی است که به طور گسترده برای «مسیریابی» (Pathfinding) و «پیمایش گراف» (Graph Traversal) مورد استفاده قرار میگیرد. پیمایش گراف، فرایند پیدا کردن مسیر بین نقاط گوناگونی است که به آنها «گره» (Node) گفته میشود. الگوریتم *A به دلیل کارایی و صحتی که دارد، به طور گسترده در کاربردهای گوناگون مورد استفاده قرار میگیرد. البته، در سیستمهای عملی مسیریابی سفر، معمولا بهتر است از الگوریتمهایی استفاده شود که میتوانند گراف را برای حصول کارایی بهتر، «پیشپردازش» (Preprocess) کنند. هر چند بر اساس برخی از پژوهشهای انجام شده، در این سیستمها نیز الگوریتم *A نسبت به دیگر رویکردها، دارای عملکرد بهتری است.




«پیتر هارت» (Peter Hart)، «نیلز نیلسون» (Nils Nilsson) و «برترام رافائل» (Bertram Raphael) از «موسسه پژوهشی استنفورد» (Stanford Research Institute) که اکنون با عنوان «اسآرآی اینترنشنال» (SRI International) فعالیت میکند، برای اولینبار، مقالهای پیرامون الگوریتم *A را در سال ۱۹۶۳ منتشر کردند. این الگوریتم را میتوان به عنوان افزونهای از «الگوریتم دیکسترا» (Dijkstra's Algorithm) در نظر گرفت که توسط «ادسخر دیکسترا» (Edsger Dijkstra) در سال ۱۹۵۹ ارائه شده است. الگوریتم *A با بهرهگیری از «الگوریتم جستجوی کاشف» (جستجوی هیوریستیک | Heuristics Search) برای هدایت فرایند جستجو، به کارایی بهتری دست پیدا میکند.
الگوریتم *A در یک نگاه
از الگوریتم *A برای تخمین کوتاهترین مسیر در مسائل جهان واقعی مانند نقشهها و بازیهایی که امکان دارد موانع زیادی در آنها باشد، استفاده میشود. میتوان یک شبکه 2D را در نظر گرفت که دارای چندین مانع است؛ کار جستجو در این شبکه، از سلول منبع (به رنگ قرمز رنگآمیزی شده است) برای رسیدن به سلول هدف آغاز میشود (به رنگ سبز، رنگآمیزی شده است).
الگوریتم جستجوی *A یکی از بهترین و محبوبترین روشهای مورد استفاده در مسیریابی و پیمایش گراف است.

چرا الگوریتم جستجوی *A
الگوریتم *A برخلاف دیگر روشهای پیمایش گراف، دارای «مغز» است. این یعنی، *A الگوریتم بسیار هوشمندی است و همین ویژگی، موجب تمایز آن از دیگر الگوریتمهای مرسوم میشود. این موضوع، همراه با جزئیات بیشتر در ادامه تشریح میشود. شایان ذکر است که بسیاری از بازیها و نقشههای مبتنی بر وب، از الگوریتم *A برای پیدا کردن کوتاهترین مسیر به طور کاملا موثر، استفاده میکنند.
روش کار الگوریتم *A
یک شبکه مربعی که موانع زیادی در آن وجود دارد مفروض است. همچنین، یک خانه به عنوان خانه شروع و یک خانه به عنوان خانه مقصد (هدف) در نظر گرفته میشود. کاربر میخواهد (در صورت امکان) از خانه شروع آغاز به کار کند و با سریعترین حالت ممکن به خانه مقصد برسد. در اینجا، الگوریتم جستجوی *A نقشآفرین میشود.
کاری که الگوریتم *A انجام میدهد آن است که در هر گام، گره را متناسب با مقدار «f» که پارامتری مساوی با مجموع دو پارامتر دیگر g و h است انتخاب میکند. در هر گام، گره/خانهای که دارای کمترین مقدار f است را انتخاب و آن گره/خانه را پردازش میکند. g و h به روش سادهای که در زیر بیان شده است محاسبه میشوند.
g: هزینه حرکت از نقطه آغاز به یک مربع خاص در شبکه، با دنبال کردن مسیری که برای رسیدن به آن تولید شده است.
h: هزینه تخمین زده شده برای حرکت از یک خانه داده شده در شبکه به مقصد نهایی است. از h معمولا با عنوان هیوریستیک یاد میشود. هیوریستیک چیزی به جز نوعی حدس هوشمندانه نیست. کاربر واقعا فاصله واقعی را تا هنگام یافتن مسیر نمیداند، زیرا هر مانعی (دیوار، آب و سایر موانع) ممکن است در مسیر باشد. راههای زیادی برای محاسبه h وجود دارد که در ادامه به آنها اشاره شده است.
الگوریتم *A
ابتدا باید دو لیست «Open List» و «Closed List» ساخته شوند. این مورد، مشابه با کاری است که در الگوریتم دیکسترا انجام میشود. شایان توجه است که در این متن، «گره بعدی» معادلی برای واژه «Successor» است.
//الگوریتم جستجوی *A
- Open List را مقداردهی اولیه کن.
- Closed List را مقداردهی اولیه کن.
- گره آغازین را در Open List قرار بده (میتوان f آن را برابر با صفر قرار داد).
- تا هنگامی که open list خالی نیست:
- گرهای با کمترین f را در open list قرار بده و آن را «q» نامگذاری کن.
- q را از open list خارج کن.
- هشت گره بعدی (رو به جلو) را تولید کن و q را والد آنها قرار بده.
- برای هر گره بعدی:
- اگر گره بعدی هدف است، جستجو را متوقف کن.
- گره بعدی × g = فاصله بین q و گره بعدی + q.g
- گره بعدی × h = فاصله از هدف تا گره بعدی (این کار با استفاده از راهکارهای زیادی قابل انجام است؛ از هیوریستیک منهتن، قطری و اقلیدسی میتوان برای این کار استفاده کرد.)
- گره بعدی × f = گرهبعدی × g + گره بعدی × h
- اگر یک گره با موقعیت مشابه به عنوان گره بعدی در OPEN list قرار دارد و دارای f کمتر از گره بعدی است، از این گره بعدی صرف نظر کن.
- اگر یک گره با موقعیت مشابه با والد، در CLOSED list قرار دارد و دارای f کمتر از گره بعدی است، از این گره بعدی صرف نظر کن. در غیر این صورت، گره را به open list اضافه کن.
- پایان (حلقه for)
- q را در CLOSED list قرار بده (حلقه while).
به عنوان مثال اگر هدف، رسیدن به سلول هدف از سلول منبع باشد، الگوریتم جستجوی *A مسیری مانند آنچه در زیر آمده است را طی میکند. شایان توجه است که تصویر زیر، با استفاده از هیوریستیک فاصله اقلیدسی ساخته شده است.

هیوریستیک
میتوان g را محاسبه کرد؛ اما چطور باید h را محاسبه کرد؟ در این راستا، میتوان اقدامات زیر را انجام داد.
- محاسبه مقدار دقیق h (که قطعا زمانبر است)
یا
- تخمین مقدار h با استفاده از برخی از هیوریستیکها (کمتر زمانبر است)
هر دو روش بالا، در ادامه بیشتر تشریح میشوند.
هیوریستیک دقیق
میتوان مقدار دقیق h را پیدا کرد، اما این کار بسیار زمانبر است. در ادامه، روشهایی برای محاسبه مقدار دقیق h بیان شده است.
- پیشمحاسبه فاصله بین هر جفت از سلولها، پیش از اجرای الگوریتم جستجوی *A.
- اگر هیچ سلول مسدود شدهای (دارای مانع) وجود نداشته باشد، میتواند مقدار دقیق h را بدون هر گونه پیشمحاسبهای با استفاده از «فاصله اقلیدسی» (Euclidean Distance) محاسبه کرد.
هیوریستیکهای تخمین
به طور کلی، سه هیوریستیک تخمین برای محاسبه h وجود دارد که در ادامه بیان شدهاند.
فاصله منهتن
«فاصله منهتن» (Manhattan Distance) در واقع قدر مطلق تفاضل مختصات x خانه هدف از مختصات x خانه کنونی و مختصات y خانه هدف از y خانه کنونی است.
پرسشی که در این وهله مطرح میشود آن است که چه هنگامی میتوان از این هیوریستیک استفاده کرد؟ پاسخ این پرسش آن است که وقتی میتوان از فاصله منهتن استفاده کرد که حرکت تنها در چهار جهت (راست، چپ، بالا و پایین) پذیرفته شده باشد. هیوریستیک فاصله منهتن در تصویر زیر نمایش داده شده است (نقطه قرمز به عنوان خانه مبدا و نقطه سبز به خانه عنوان مقصد در نظر گرفته شده است).

فاصله قطری
«فاصله قطری» (Diagonal Distance) در واقع بیشینه مقادیر قدر مطلق تفاضل مختصات x خانه هدف از مختصات x خانه کنونی و مختصات y خانه هدف از y خانه کنونی است.
در پاسخ به این پرسش که چه زمان میتوان از این هیوریستیک استفاده کرد باید گفت، هنگامی که امکان حرکت در هشت جهت وجود دارد (مانند شاه در شطرنج). هیوریستیک فاصله قطری در تصویر زیر نشان داده شده است (نقطه قرمز به عنوان خانه مبدا و نقطه سبز به عنوان خانه مقصد در نظر گرفته شده است).

فاصله اقلیدسی
همانطور که از نام این هیوریستیک مشخص است، «فاصله اقلیدسی» (Euclidean Distance) در واقع فاصله بین خانه کنونی و خانه هدف با استفاده از فرمول فاصله است.
پرسشی که در این وهله مطرح میشود آن است که این هیوریستیک چه هنگامی قابل استفاده است؟ در پاسخ به این پرسش باید گفت که این هیوریستیک هنگامی قابل استفاده است که امکان حرکت در هر جهتی وجود داشته باشد. هیوریستیک فاصله اقلیدسی در تصویر زیر نمایش داده شده است (نقطه قرمز به عنوان خانه مبدا و نقطه سبز به عنوان خانه مقصد در نظر گرفته شده است).

باید توجه داشت همانطور که پیش از این نیز بیان شد، الگوریتم دیکسترا حالت خاصی از الگوریتم *A است که در آن، برای همه گرهها h = 0 است.
تاریخچه الگوریتم *A
الگوریتم *A به عنوان بخشی از پروژه «Shakey The Robot» که هدف آن ساخت یک ربات موبایل بود که میتوانست فعالیتهای خودش را برنامهریزی کند، ساخته شد. نیلز نیلسون، در اصل «الگوریتم پیمایش گراف» (Graph Traversal Algorithm) را برای برنامهریزی مسیر Shakey ارائه کرد. پیمایش گراف در الگوریتم Graph Traverser به وسیله تابع هیوریستیک (h(n، فاصله تخمین زده شده از n تا گره هدف، هدایت میشد و به طور کلی (g(n را که فاصله از گره آغازین (مبدا) به گره n بود نادیده میگرفت.
بترام رافائل پیشنهاد داد تا از مجموع (g(n) + h(n استفاده شود. پیتر هارت مفاهیمی را ابداع کرد که امروزه به آنها «پذیرفتگی» (Admissibility) و «ثبات» (Consistency) تابع هیوریستیک گفته میشود. الگوریتم *A در اصل برای پیدا کردن مسیر با کمترین هزینه طراحی شده بود که در آن، هزینه یک مسیر مجموع هزینه یالها بود؛ اما در ادامه ثابت شد که الگوریتم *A را میتوان برای پیدا کردن مسیر بهینه برای هر مسئلهای که شرایط جبر هزینه را محقق کند، استفاده کرد.
مقاله اصلی الگوریتم *A که در سال ۱۹۶۸ منتشر شد، حاوی نظریهای بود مبنی بر اینکه هیچ الگوریتم شبه *A نمیتواند گرههای کمتری را نسبت به الگوریتم *A گسترش دهد، اگر تابع هیوریستیک «ثابت» (Consistent) باشد و قاعده «رفع گرهخوردگی» (Tie-Breaking) به صورت مناسبی انتخاب شده باشد. اصلاحاتی چند سال بعد منتشر شد که نشان داد، نیاز به ثبات نیست و پذیرفتگی کافی است. اگرچه، چیزی که واقعا نشان میداد آن بود که هیچ الگوریتم مشابهی، با توجه به مجموعه گرههای توسعه یافته، نمیتواند اکیدا کارآمدتر از *A باشد.
چنانکه در پژوهشهای «دچتر» (Dechter) و «پیرل» (Pearl) پیرامون بهینگی (اکنون به آن کارایی بهینه گفته میشود) الگوریتم *A، نشان داده شده است که این امکان برای الگوریتمهای درست دیگر وجود دارد که در برخی گرافها کارایی بهتری نسبت به الگوریتم *A داشته باشند؛ در حالیکه در برخی از دیگر گرافها و یا برای گسترش گرههایی که حاوی مجموعه گرههای گسترش یافته با *A است و یا گرههایی در آن قرار دارند ، نتیجه را به *A واگذار میکنند و در واقع الگوریتم *A عملکرد بهتری دارد.
الگوریتم *A از جمله «الگوریتمهای جستجوی آگاهانه» (Informed Search Algorithm) یا «جستجوی اول بهترین» (Best-First Search) است؛ بدین معنا که برای گرافهای وزندار فرموله شده است. در این الگوریتم، با شروع از یک گره مشخص آغازین از گراف، هدف پیدا کردن مسیری به یک گره هدف داده شده است که کمترین هزینه را دارد (کمترین فاصله پیموده شده، کمترین زمان پیمایش و دیگر موارد). الگوریتم *A این کار را با نگهداری یک درخت از مسیرهایی که از گره آغازین (مبدا) نشأت میگیرند و گسترش دادن آن مسیرها به اندازه یک یال در هر زمان تا هنگامی که معیارهای توقف محقق شود، انجام میدهد. در هر تکرار از حلقه اصلی، الگوریتم *A نیاز به تعیین این دارد که کدام یک از مسیرها را باید گسترش بدهد. الگوریتم، این کار را بر اساس هزینه مسیر و یک تخمین از هزینه مورد نیاز برای گسترش مسیر از آن گره تا گره هدف انجام میدهد. به طور خاص، الگوریتم *A مسیری را انتخاب میکند که تابع زیر را کمینه میکند:
f(n) = g(n) + h(n)
در تابع بالا، n گره بعدی در مسیر، (g(n هزینه مسیر از مبدا تا گره n و (h(n تابع هیوریستیکی است که هزینه ارزانترین مسیر از گره n تا هدف را مشخص میکند. الگوریتم *A هنگامی متوقف میشود که مسیری که برای گسترش انتخاب کرده، مسیری باشد از مبدا تا هدف و یا هیچ گره مطلوب دیگری برای گسترش وجود نداشته باشد. انتخاب تابع هیوریستیک، مبتنی بر مسئله است. اگر تابع هیوریستیک پذیرفتنی باشد، بدین معنا که هزینه واقعی برای رسیدن به هدف را هیچگاه بیش از اندازه واقعی تخمین نمیزد، الگوریتم *A تضمین میکند که مسیری با کمترین هزینه از مبدا تا هدف (مقصد) را پیدا کند.
پیادهسازی متداول *A «از صف اولویتدار» (Priority Queue) برای انجام تکرار انتخاب (انتخاب تکرار شونده) استفاده و گرههای دارای کمترین هزینه (تخمین زده شده) جهت گسترش را انتخاب میکند. این صف اولویتدار، تحت عنوان «مجموعه باز» (Open Set) یا «فرینج» (Fringe) نامیده میشود. در هر گام از الگوریتم، گره دارای کمترین مقدار (f(x از صف حذف میشود، مقادیر f و g نیز متعاقبا از همسایههای آن به روز رسانی میشوند و این همسایهها، به صف اضافه میشوند. الگوریتم کار را تا جایی ادامه میدهد که گره هدف، دارای مقدار f کمتری نسبت به هر گره دیگری در صف باشد (یا تا هنگامی که صف خالی است). مقدار f هدف، هزینه کوتاهترین مسیر است، زیرا h در هدف، در یک هیوریستیک پذیرفتنی، برابر با صفر است.
الگوریتمی که تاکنون تشریح شده است، فقط طول کوتاهترین مسیر را به دست میدهد. برای پیدا کردن توالی واقعی گامها، الگوریتم میتواند به سادگی معکوس شود، بنابراین هر گره اجداد خود را دنبال میکند. پس از اینکه این الگوریتم اجرا شد، گره پایانی (مقصد) به اجداد خود اشاره میکند و به همین ترتیب، تا رسیدن اجداد گرهها به گره آغازین (مبدا)، کار ادامه پیدا میکند. به عنوان مثال، هنگام جستجو برای کوتاهترین مسیر روی یک نقشه، (h(x ممکن است فاصله خط مستقیم از هدف را نشان دهد؛ زیرا به لحاظ فیزیکی، کمترین فاصله بین دو نقطه است. اگر هیوریستیک h شرط اضافی (h(x) ≤ d(x, y) + h(y را برای هر یال (x, y) در گراف محقق کند (که در آن، d نشانگر طول یال است)، h را «یکنواخت» (Monotone) یا «ثابت» (Consistent) گویند. در این شرایط، *A را میتوان به صورت کارآمدتری پیادهسازی کرد؛ در واقع، هیچ گرهای نیاز به پیادهسازی بیش از یکبار ندارد و الگوریتم *A برابر با اجرای الگوریتم دیکسترا با هزینه کاهش یافته (d'(x, y) = d(x, y) + h(y) − h(x است.
شبه کد الگوریتم *A
شبه کد الگوریتم دیکسترا، در ادامه آمده است.
شایان توجه است که در شبه کد بالا اگر به یک گره از یک مسیر رسیده شد، از openSet حذف شده و متعاقبا به وسیله مسیر کم هزینهتری به آن رسیده شود، مجددا به openSet اضافه میشود. این مورد برای تضمین آنکه مسیر بازگردانده شده بهینه است اگر تابع هیوریستیک پذیرفتنی و نه ثابت است، امری حیاتی محسوب میشود. اگر هیوریستیک ثابت باشد، هنگامی که یک گره از openSet حذف میشود، تضمین میشود که مسیر به آن گره بهینه است، بنابراین «tentative_gScore < gScore[neighbor]» همواره در صورتی که مجددا به گره رسیده شود، با شکست مواجه خواهد شد.
مثالی از الگوریتم *A
مثالی از حل یک مسئله با الگوریتم *A در ادامه ارائه شده است. در گراف زیر، شهرها به صورت راسهایی هستند که با یالها (راهها) به یکدیگر متصل شدهاند.
(h(x فاصله خط راست از نقطه هدف است.
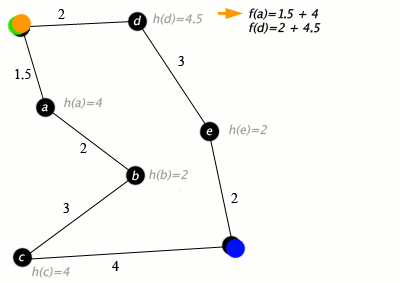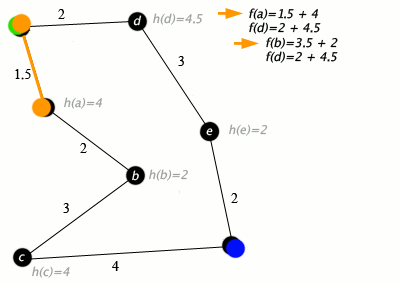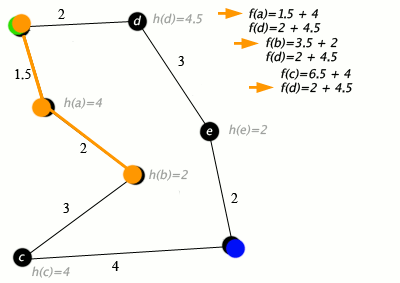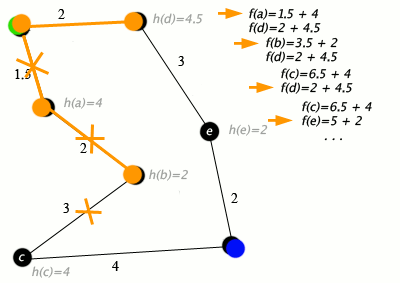
در گراف بالا، راس سبز رنگ، نقطه شروع یا مبدا، و راس آبی، هدف یا همان مقصد است. موارد نارنجی نیز راسها و یالهای ملاقات شده هستند. الگوریتم *A کاربردهای جهان واقعی نیز دارد. در این مثال، یالها جادههای ریلی و (h(x فاصله دایره بزرگ (کوتاهترین مسیر ممکن روی کره) از هدف است. الگوریتم در صدد یافتن مسیر بین «واشینگتون دی.سی» (Washington, D.C) و «لس آنجلس» (Los Angeles) است.
حالات خاص الگوریتم *A
الگوریتم دیکسترا، مثال دیگری از الگوریتم جستجوی دارای هزینه یکنواخت (Uniform-Cost) است که میتوان آن را به عنوان گونه خاصی از *A در نظر گرفت که در آن برای همه xها ۰ = (h(x است. الگوریتم «جستجوی اول عمق» (Depth-First Search) عمومی را میتوان با استفاده از *A و با در نظر داشتن اینکه یک شمارنده سراسری C با یک مقدار بسیار بزرگ مقداردهی اولیه شده است، پیادهسازی کرد.
پس از هر بار تخصیص، شمارنده C یک واحد کاهش داده میشود. بنابراین، هر چه زودتر یک گره کشف شود، مقدار (h(x آن بالاتر خواهد بود. هم الگوریتم دیکسترا و هم جستجوی اول عمق را میتوان به صورت کاراتر بدون در نظر گرفتن (h(x در هر گره، پیادهسازی کرد.
جزئیات پیادهسازی الگوریتم *A
بهینهسازیهای ساده یا جزئیات بهینهسازی وجود دارد که میتواند به طور موثر کارایی پیادهسازی الگوریتم *A را تحت تاثیر قرار دهد. اولین جزئیاتی که باید به آن دقت کرد، روشی است که صف اولویت گرههای (Ties) صف را مدیریت میکند؛ این موضوع در برخی شرایط، تاثیر قابل توجهی روی کارایی دارد. اگر گرهها (Ties) شکسته شده باشند، صف با حالت LIFO خودش عمل خواهد کرد و در نتیجه، *A مانند جستجوی اول عمق در میان مسیرهایی با هزینه یکسان رفتار میکند (اجتناب از اکتشاف بیش از یک راهکار با بهینگی مشابه).
هنگامی که یک مسیر در پایان جستجو مورد نیاز باشد، متداول است که با هر گره یک ارجاع به والد آن گره نگهداری شود. در پایان جستجو، این مراجع را میتوان برای یافتن مسیر بهینه استفاده کرد. اگر این مراجع نگهداری شوند، حائز اهمیت است که گره مشابه در صف اولویت بیش از یک بار ظاهر نشود (هر ورودی مربوط به مسیر متفاوتی به گره و هر کدام با هزینه متفاوتی).
یک راهکار استاندارد بررسی این است که یک گره افزوده شده، در صف اولویت ظاهر شود. اگر چنین باشد، اشارهگرهای اولویت و والد برای مربوط شدن به مسیر دارای هزینه کمتر، تغییر پیدا میکنند. یک «هرم دودویی» (Binary Heap) استاندارد، بر مبنای صف اولویت به طور مستقیم عملیات جستجو برای یکی از عناصر آن را پشتیبانی نمیکند، اما میتواند با «جدول هش» که عناصر را به جایگاه خودشان در هرم نگاشت میکنند تکمیل (تجمیع) شود، که این امکان را فراهم میکند که عملیات کاهش اولویت در زمان لگاریتمی انجام شود. به طور جایگزین، یک هرم فیبوناچی میتواند عملیات کاهش اولویت مشابهی را در زمان استهلاکی ثابتی انجام دهد.
پذیرش و بهینگی
الگوریتم *A پذیرفتنی است و در برخی شرایط، گرههای کمتری را نسبت به دیگر الگوریتمهای جستجوی پذیرفتنی با هیوریستیک مشابه در نظر میگیرد. این امر به دلیل آن است که *A از یک تخمین «خوشبینانه» هزینه مسیر از هر گره، استفاده میکند که خوشبینانه در نظر میگیرد که هزینه واقعی مسیر از یک گره به هدف دستکم به بزرگی تخمین زده شده است. اما، با نگاهی منتقدانه میتوان گفت تخمین بهینه فقط همانقدر که *A «فکر میکند» قابل دستیابی است. برای اثبات پذیرفتنی بودن *A، مسیر راهکار بازگردانده شده توسط الگوریتم، به صورت زیر مورد استفاده قرار میگیرد.
هنگامی که *A به جستجوی خود پایان میدهد، مسیری را یافته که هزینه آن از هزینه تخمین زده شده برای هر مسیر دیگر از طریق هر گره بازی، کمتر است. اما با توجه به اینکه این تخمینها بهینه هستند، *A میتواند با امنیت آن گرهها را نادیده انگارد. به بیان دیگر، *A هرگز احتمال مسیر با هزینه کمتر را نادیده نمیگیرد و بنابراین، پذیرفتنی است.
اکنون، فرض میشود که یک الگوریتم هیوریستیک دیگر B جستجوی خود را با مسیری که هزینه واقعی آن کمتر از هزینه تخمین زده شده از طریق گرههای باز است، متوقف میکند. بر مبنای اطلاعات هیوریستیکی که B دارد، الگوریتم B نمیتواند احتمال اینکه مسیر از طریق آن گرهها دارای کمترین هزینه است را غیر محتمل بشمارد. بنابراین، در حالی که B ممکن است گرههای کمتری را نسبت به *A در نظر بگیرد، پذیرفتنی نیست. بر این اساس، *A کمترین گرهها را نسبت به هر الگوریتم جستجوی پذیرفتنی دیگری، در نظر میگیرد. این موضوع تنها هنگامی درست است که:
- *A از یک هیوریستیک پذیرفتنی استفاده کند. در غیر این صورت، *A تضمین نمیکند که گرههای کمتری را نسبت به دیگر الگوریتمها با هیوریستیک مشابه، گسترش دهد.
- *A تنها یک مسئله جستجو را به جای مجموعهای از مسائل جستجوی مشابه، حل میکند. در غیر این صورت، *A تضمین نمیکند که گرههای کمتری را نسبت به الگوریتمهای جستجوی هیوریستیک افزایشی گسترش دهد.
آزادسازی محدود (Bounded Relaxation)
در حالی که معیار پذیرفتنی یک مسیر راهکار بهینه را تضمین میکند، بدین معنا است که *A باید همه مسیرهایی که به طور مشابه شایسته انتخاب مسیر بهینه هستند را مورد آزمون قرار دهد. برای محاسبه تقریب کوتاهترین مسیر، این امکان وجود دارد که جستجو را در هزینه بهینهسازی با آزادسازی معیار پذیرش سرعت ببخشد.
گاهی، کاربر تمایل دارد که این آزادسازی را محدود کند، بنابراین میتواند تضمین کند که مسیر راهکار بیش از (1 + ε) برابر مسیر راهکار بهینه بدتر نیست. این تضمین جدید، با عنوان ε-پذیرفتنی (ε-admissible) نامیده میشود. تعدادی الگوریتم ε-پذیرفتنی وجود دارند که در ادامه معرفی شدهاند.
- *A وزندار/وزندهی ایستا (Weighted A*/Static Weighting): اگر (ha(n یک تابع هیوریستیک پذیرفتنی باشد، در نسخه وزندار جستجوی *A از hw(n) = ε ha(n), ε > 1 به عنوان تابع هیوریستیک استفاده میشود و جستجوی *A به طور متداول (که در نهایت سریعتر از استفاده از ha به وقوع میپیوندد، زیرا گرههای کمتری گسترش پیدا کردهاند) انجام میشود. بدین ترتیب، مسیر یافته شده توسط الگوریتم جستجو میتواند هزینهای حداکثر ε برابر مسیر با کمترین هزینه در گراف را داشته باشد.
- وزندهی پویا (Dynamic Weighting): از تابع هزینه (f(n) = g(n) + (1+εw(n))h(n استفاده میکند که در آن ، که (d(n عمق جستجو و N طول پیشبینی شده مسیر راهکار است.
- وزندهی پویای نمونهگیری شده (Sampled Dynamic Weighting): از نمونهگیری از گرهها برای تخمین بهتر و رفع سوگیری خطای هیوریستیک استفاده میکند.
- : از دو تابع هیوریستیک استفاده میکند. اولین تابع، لیست FOCAL است که برای انتخاب گرههای کاندید مورد استفاده قرار میگیرد و دومین مورد، hF برای انتخاب امیدوارکنندهترین گره از لیست FOCAL به کار میرود.
- : گرهها را با تابع Af(n)+Bh_{f}(n) انتخاب میکند که در آنها A و B ثابتها هستند. اگر هیچ گرهای قابل انتخاب نباشد، الگوریتم با تابع پسگرد میکند که در آن، C و D ثابتها هستند.
- *AlphA: برای ارتقای استخراج اول عمق با ترجیح دادن گرههایی که اخیرا گسترش یافتهاند تلاش میکند. *AlphA از تابع هزینه استفاده میکند که در آن، ، که در این رابطه λ و Λ مقادیر ثابت با است و والد n و گره اخیرا گسترش یافته است.
پیچیدگی
پیچیدگی زمانی الگوریتم *A بستگی به هیوریستیک دارد. در بدترین حالت از فضای جستجوی نامحدود، تعداد گرهها به صورت نمایی در عمق راهکار گسترش یافتهاند (کوتاهترین مسیر) (d: O(bd که در آن، b ضریب انشعاب است. در اینجا فرض میشود که حالت هدف وجود دارد و از حالت ابتدایی دسترسیپذیر است. در غیر این صورت، و در حالتی که فضای حالت نامتناهی باشد، الگوریتم متوقف نمیشود.
تابع هیوریستیک، دارای یک اثر کلی در کارایی عملی الگوریتم *A است، زیرا یک هیوریستیک خوب این امکان را فراهم میکند که *A بسیاری از گرههای bd را که جستجوی ناآگاهانه گسترش میدهد، هرس کند. کیفیت این الگوریتم را میتوان با استفاده از ضریب انشعاب موثر *b سنجید که میتواند به صورت تجربی برای یک نمونه مساله با اندازهگیری تعداد گرههای گسترش یافته، N و عمق راهکار و سپس حل معادله زیر تعیین کرد.
N + 1 = 1 + b* + (b*)2+...+(b*)d
هیوریستیکهای خوب، مواردی هستند که دارای ضریب انشعاب کمتری هستند (بهینگی با b* = 1). هنگامی که فضای جستجو یک درخت است، یک حالت هدف وجود دارد، تابع هیوریستیک h شرایط معادله زیر را برآورده میکند و پیچیدگی زمانی چندجملهای خواهد بود.
|h(x) - H*(x)| = O(log h*(x))
که در آن *h یک هیوریستیک بهینه و هزینه دقیق رسیدن از x به هدف است. به عبارت دیگر، خطای h سریعتر از لگاریتم «هیوریستیک کامل» (Perfect Heuristic) یعنی *h که مقدار صحیح فاصله x از هدف را باز میگرداند، رشد نخواهد کرد.
کاربردها
الگوریتم *A به طور متداول برای مسائل مسیریابی در مواردی مانند بازیها مورد استفاد میگیرد، اما در اصل، برای الگوریتم پیمایش کلی گراف طراحی شده بود. این الگوریتم، کاربردهایی در مسائل گوناگون دارد که از این جمله میتوان به مساله «تجزیه کننده» (Parsing) با استفاده از «گرامر تصادفی» (Stochastic Grammars) در «پردازش زبان طبیعی» (Natural Language Processing) اشاره کرد. دیگر موارد شامل «جستجوی اطلاعاتی» (Informational Search) با «یادگیری آنلاین» (Online Learning) میشوند.
ارتباط با دیگر الگوریتمها
آنچه الگوریتم *A را از «الگوریتم حریصانه جستجوی اول بهترین» (Greedy Best-First Search Algorithm) متمایز میکند، این است که این الگوریتم هزینهای/فاصلهای که تاکنون پیموده شده است، یعنی (g(n را در محاسبات خود دخیل میکند.
گونههای متداولی از الگوریتم دیکسترا وجود دارند که میتوان به آنها به عنوان نوع خاصی از الگوریتم *A نگاه کرد و در آنها، برای همه گرهها داریم که هیوریستیک 0 = (h(n است. هر دو الگوریتم دیکسترا و *A به نوبه خود، گونه خاصی از «برنامهنویسی پویا» (Dynamic Programming) محسوب میشوند. *A خود، گونه خاصی از تعمیم الگوریتم «شاخه و حد» (Branch and Bound) است و میتواند از الگوریتم اولیه-دوگان (Primal-Dual Algorithm) برای «برنامهنویسی خطی» (Linear Programming) مشتق شود.
گونههای الگوریتم *A
الگوریتم *A گونههای مختلفی دارد که عناوین برخی از آنها در ادامه بیان شدهاند.
- جستجوی هیوریستیک افزایش (Incremental heuristic search)
- *A اصلاح در هر زمان (*Anytime Repairing A* | ARA)
- *A مسدود
- *D
- *D زمینه
- فرینج (Fringe)
- فرینج سیوینگ *A (به اختصار *Fringe Saving A*| FSA)
- *A تعمیم یافته تطبیقپذیر (*Generalized Adaptive A* | GAA)
- *A تکرار شونده عمیقتر
- جستجوی اطلاعاتی (Informational search)
- جستجوی نقطه پرش (Jump Point Search)
- *A برنامهریزی طول عمر (*Lifelong Planning A)
- *A ساده شده حافظه محدود (*Simplified Memory bounded A)
- تتا* (*Theta)
- *A هر زمان (*Anytime A)
- *A پویای هر زمان (*Anytime Dynamic A)
- *A زمان محدود (*Time-Bounded A* | TBA)
کد الگوریتم *A در ++C
میتوان از هر ساختاری برای پیادهسازی open list و closed list استفاده کرد؛ اما برای داشتن بهترین کارایی، از ساختار داده set در C++ STL (به صورت یک درخت سرخ-سیاه پیادهسازی شده است) و «جدول درهمسازی بولین» (Boolean Hash Table) برای یک closed list استفاده شده است.
پیادهسازی الگوریتم *A نیز مشابه با الگوریتم دیکسترا است. در صورت استفاده از هرم فیبوناچی برای پیادهسازی open list به جای هرم دودویی/درخت خودمتوازن، کارایی بهتر خواهد شد (زیرا هرم فیبوناچی زمانی از درجه O(1) برای درج کردن در open list و کاهش کلید میبرد). همچنین، برای کاهش زمان مورد نیاز برای محاسبه g، از «برنامهنویسی پویا» (Dynamic Programming) استفاده خواهد شد.
کد الگوریتم *A در پایتون
کد الگوریتم *A در جاوا

اگر مطلب بالا برای شما مفید بوده، آموزشهای زیر نیز به شما پیشنهاد میشود:
- مجموعه آموزشهای هوش مصنوعی
- آموزش هوش مصنوعی – تکمیلی
- مجموعه آموزشهای الگوریتمهای بهینهسازی هوشمند
- شبیه سازی تبرید (Simulated Annealing) — به زبان ساده
- جست و جوی هیوریستیک (Heuristic Search) در پایتون — راهنمای کاربردی
- الگوریتم دایجسترا (Dijkstra) — از صفر تا صد
^^










مطالب مفیدی بود ممنون ازتون.
توضیخات بسیار عالی و کامل بود
ممنون
خیلی عالی بود
ممنون از توضیحات جامع و کاملتون