



آموزش پردازش زبان طبیعی پروژه محور – راهنمای کاربردی
«پردازش زبان طبیعی» (Natural Language Processing | NLP) از جمله مباحثی محسوب میشود که این روزها توجهات زیادی را به خود جلب کرده است. یکی از دلایل اصلی این امر، کاربردهای زیاد و متنوعی است که پردازش زبان طبیعی دارد. در آموزش مباحثی مانند «دادهکاوی» (Data Mining)، پردازش زبان طبیعی و برنامهنویسی، استفاده از پروژههای عملی، به افزایش ضریب یادگیری کمک شایان توجهی میکند. به همین دلیل، در این مطلب با بهرهگیری از یک پروژه جذاب و کاربردی، آموزش پردازش زبان طبیعی ارائه شده است.




آموزش پردازش زبان طبیعی با یک پروژه
ساخت رزومه، نیازمند دقت و هوشمندی کافی است. برخی از چالشها و پرسشهایی که افراد ضمن ساختن رزومه خود با آنها مواجه میشود عبارتند از:
- آیا پیرامون پروژههایی که پیش از این انجام دادهام به صورت تفضیلی اطلاعات ارائه کنم و یا به صورت مختصر و تیتروار به آنها اشاره داشته باشم؟
- مهارتهای متعددی را در رزومه بنویسم و یا صرفا مهارتهای کلیدی خودم را بیان کنم؟
- آیا از زبانهای برنامهنویسی متعدد در رزومه خود نام ببرم و یا فقط به چند مورد اشاره کنم؟
- رزومه را در یک صفحه تنظیم کنم و یا تعداد بیشتری صفحه به بیان جزئیات اختصاص بدهم؟
این جنس از چالشها برای اغلب افرادی که قصد ساختن رزومه دارند وجود دارد. از سوی دیگر، افرادی که قصد استخدام نیرو دارند نیز، گاهی با حجم انبوهی از رزومهها مواجه میشوند که انتخاب رزومههای مناسب را جهت دعوت به مصاحبه دشوار میکند. دانشمندان داده نیز از این قاعده مستثنی نیستند. اما، تحلیلگران و «دانشمندان داده» (Data Scientists)، به شیوه خود به حل چنین مشکلاتی میپردازند. در این مطلب، پروژهای تعریف شده که نشان میدهد، چگونه میتوان با بهرهگیری از علم داده، رزومههای حائز شرایط را از میزان حجم انبوه رزومهها گزینش کرد.
«ونکات رمن» (Venkat Raman)، دانشمند دادهای است که این پروژه را طرحریزی کرده و انجام داده است. رمن، دوستی دارد که مالک و مدیر یک شرکت مشاوره علم داده است. دوست رمن، اخیرا یک پروژه بسیار خوب جذب کرده بود و نیاز به استخدام دو دانشمند داده داشت. بنابراین، یک آگهی شغلی تنظیم کرده و آن را در لینکدین قرار داده بود. در همین راستا، نزدیک به ۲۰۰ رزومه دریافت میکند. طی یک جلسه حضوری که بین رمن و مالک شرکت (دوست رمن) برگزار میشود، مالک چنین میگوید: اگر راهی باشد که بهترین رزومه را از میان همه رزومهها پیدا کنم، کارم با سرعت بسیار بیشتری پیش خواهد رفت. نویسنده مطلب که پیش از این روی چندین پروژه NLP کار کرده بود، تصمیم میگیرد که مشکل دوست خود را حل کند. بنابراین به او می گوید که امکان دارد بتواند با استفاده از روشهای پردازش زبان طبیعی مشکل او را حتی اگر به صورت کامل نه، ولی تا حد زیادی، حل کند. در اینجا است که پروژه رمن آغاز میشود و او برای حل این مشکل به روش یک دانشمند داده، دست به کار میشود.
بیان دقیق نیازها

شرکت تحلیل داده، نیاز به یک کارشناس «یادگیری عمیق» (Deep Learning) دارد که با دیگر الگوریتمهای «یادگیری ماشین» (Machine Learning) نیز آشنایی داشته باشند. کاندید دیگر نیز باید بر «کلان داده» (Big Data | بنا بر تصویب فرهنگستان به آن در فارسی مَهداده میگویند) و روشها و ابزارهای مهندسی دادهها از جمله «اسکالا»، AWS، «داکرز» (Dockers) و «کوبرنتز» (Kubernetes) تسلط داشته باشد.
رویکرد
هنگامی که رومن متوجه میشود که دوستش در کاندیداها به دنبال چه ویژگیهایی است، رویکردی را برای چگونگی حل این مساله طرح میکند. در ادامه، رویکرد رومن برای حل این مساله بیان شده است.
- داشتن یک دیکشنری یا جدول که همه مجموعه مهارتها را داشته باشد؛ در واقع، باید دیکشنری ساخته شود که کلماتی مانند «کِرَس» (keras)، «تنسورفلو» (tensorflow) و RNN در آن ثبت شود. سپس، موارد مذکور در ستونی با نام یادگیری عمیق قرار داده شوند.
- داشتن یک الگوریتم پردازش زبان طبیعی که کل رزومهها را «تجزیه» (Parse) کند و اساسا به دنبال کلمات منشن شده در دیکشنری یا جدول باشد.
- گام بعدی شمارش وقوع کلمات در دستههای گوناگون است. برای مثال، چیزی مانند جدول زیر باید برای هر متقاضی کار ساخته شود.


کاندیدای مشخص شده در جدول بالا، گزینه خوبی برای دانشمند داده یادگیری عمیق محسوب میشود و به نظر میرسد فردی است که که صاحب شرکت به دنبال آن میگردد. اطلاعات بالا باید به شیوه بصری ارائه شوند تا انتخاب کاندید مناسب را آسان کنند.
پیادهسازی
اکنون که رویکرد مورد استفاده مشخص شد، مانع بعدی که باید بر آن غلبه کرد نحوه پیادهسازی روش بیان شده است.

پردازش زبان طبیعی
Spacy، کتابخانهای است که میتوان از آن برای تطبیق کلمه و عبارت استفاده کرد. در این کتابخانه، قابلیتی وجود دارد که به آن «Phrase Matcher» گفته میشود. در ادامه، از این قابلیت برای حل مساله موجود استفاده خواهد شد.
خواندن رزومه
بستههای گوناگونی وجود دارند که به خواندن رزومهها کمک میکنند. خوشبختانه، همه رزومههایی که شرکت دریافت کرده در قالب PDF هستند. بنابراین، میتوان از بستههایی مانند PDF-Mine یا PyPDF2 برای انجام این کار استفاده کرد. در این مطلب، از PyPDF2 استفاده شده است. در ادامه، پیادهسازی روش بیان شده با استفاده از زبان برنامهنویسی پایتون و کتابخانه Matplotlib انجام شده است.
اکنون که کد کامل موجود است، نیاز به تاکید بر دو نکته است که در ادامه بیان شدهاند.
فایل CSV کلیدواژهها
فایل CSV کلیدواژهها در خط ۴۴ کد، با عنوان «emplate_new.csv» ارجاع داده شده است. هر سازمانی میتواند آن را با پایگاه داده اختصاصی خود جایگزین کند (و تغییرات مورد نیاز را در کد ایجاد کند) اما برای راحتی بیشتر در اینجا از فایل CSV ساخته شده در اکسل استفاده شده است.
کلمات موجود در هر دسته قراردادی و قابل تغییر هستند. در تصویر زیر، لیست کلماتی که برای تطبیق عبارات موجود در رزومهها مورد استفاده قرار میگیرد را میتوان مشاهده کرد.
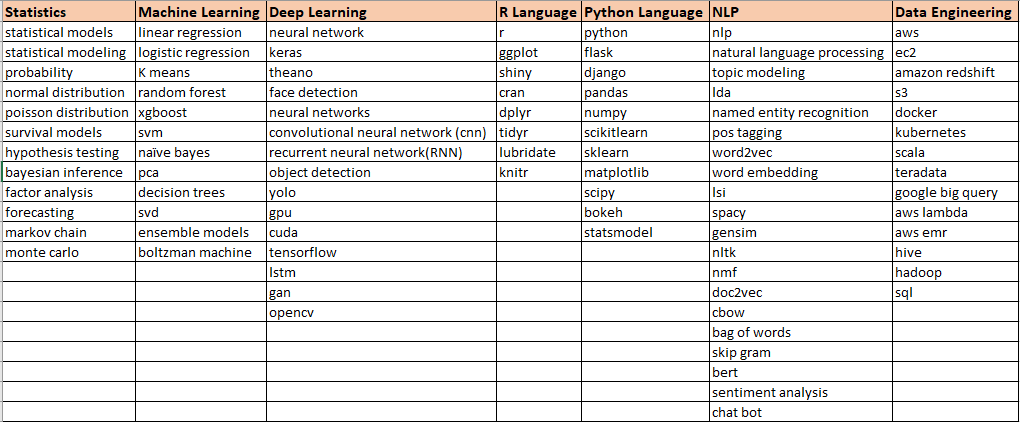
جدول کلیدواژهها
در خط ۱۱۴ کد، خطی اجرا میشود که فایل CSV را تولید میکند. این فایل CSV تعداد کلیدواژههای محاسبه شده برای هر کاندید را مشخص میکند (نام واقعی کاندیدها در اینجا پوشانده شده است).

جدول فوق شاید به اندازه لازم بصری نیست. بنابراین، بصریسازی دادهها به شکل زیر انجام شده تا فرایند انتخاب را تسریع و تسهیل کند.
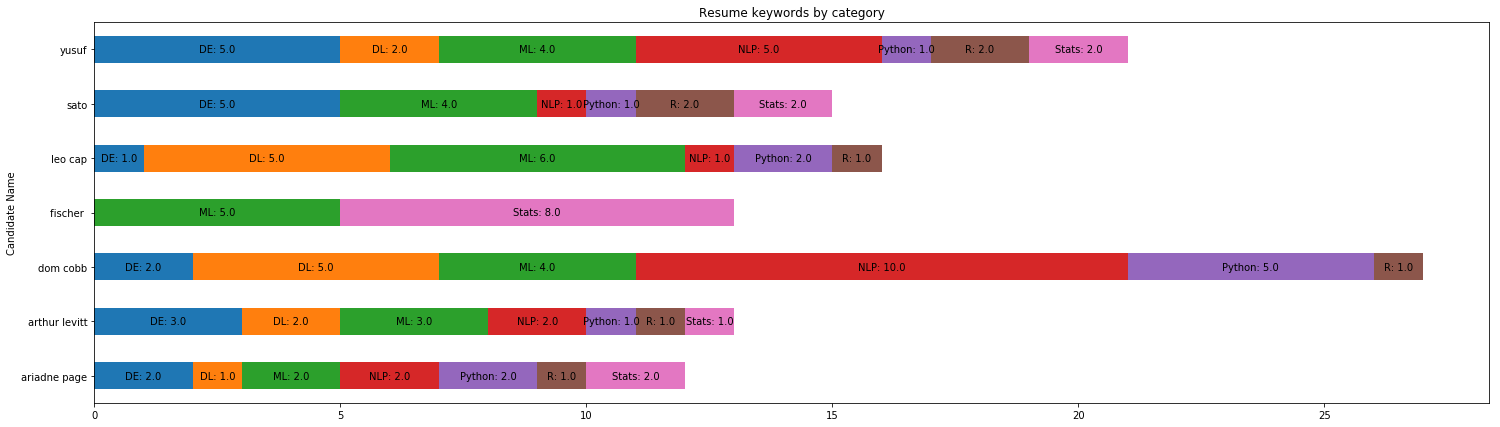
از نمودار چنین به نظر میرسد که Dom Cobb و Fischer بیشترین شباهت را به کارشناس مورد نظر مدیر شرکت دارند و زمینه فعالیت سایر افراد عمومیتر است.
آیا این رویکرد موثر است؟
مدیر شرکت با اجرای این کد، موفق به انتخاب ۱۵ رزومه از میان ۲۰۰ رزومه شده است. در مصاحبهها مشخص شده که انتخابهای حاصل از اجرای این پروژه، گزینههای مناسبی بودهاند. انجام چنین کاری بدون بهرهگیری از پردازش زبان طبیعی و کد پایتون، کاری بسیار زمانبر خواهد بود.
دستهبندی و تطبیق عبارت
حتی اگر مالک شرکت، همه رزومهها را بخواند، گفتن اینکه فرد در یادگیری ماشین متخصص است یا نه، باز هم کار سختی محسوب میشود. زیرا فرد تعداد عبارات مرتبط را به ذهن نمیسپارد. این در حالی است که کد اراسه شده در بالا، کلیدواژهها را شکار، دفعات وقوع آنها را محاسبه و در نهایت آنها را دستهبندی میکند.
بصریسازی دادهها
بصریسازی دادهها جنبه بسیار مهمی از یک پروژه تحلیل داده محسوب میشود. این کار، فرایند تصمیمگیری را با تعیین این که کدام کاندید، کلیدواژههای موجود در یک دسته خاص را بیشتر به کار برده، بهبود میبخشد.
از سوی دیگر، اگر فرد گستره بالایی از مهارتها را داشته باشد، مشخص است که یک دانشمند داده عمومی است. میتوان مقایسهای بین کاندیداها انجام داد که به فیلتر کردن رزومهها و حذف مواردی که مورد نیاز نیستند کمک کند.
نحوه استفاده از کد
این احتمال وجود دارد که بسیاری از شرکتها کدهایی مانند آنچه در بالا ارائه شده را برای بررسی اولیه رزومههایی که دریافت میکنند مورد استفاده قرار دهند. بر همین اساس، توصیه میشود که در صورتی که قصد ارسال رزومه برای یک فرصت شغلی خاص را دارید، از پراکندهنویسی اجتناب و برای آن موقعیت مشخص رزومه خود را تکمیل کنید.

اگر نوشته بالا برای شما مفید بوده است، آموزشهای زیر نیز به شما پیشنهاد میشوند:
- مجموعه آموزشهای آمار، احتمالات و داده کاوی
- آموزشهای داده کاوی یا Data Mining در متلب
- مجموعه آموزشهای هوش محاسباتی
- یادگیری علم داده (Data Science) با پایتون — از صفر تا صد
- داده کاوی (Data Mining) — از صفر تا صد
- معرفی منابع جهت آموزش یادگیری عمیق (Deep Learning) — راهنمای کامل
^^








