


آموزش شبکه عصبی CNN با تنسورفلو و پایتون – راهنمای کاربردی
«شبکه عصبی پیچشی» (Convolutional Neural Network | CNN) به عنوان یکی از الگوریتم های یادگیری عمیق محسوب میشود که در حوزه پردازش تصویر و بینایی ماشین کاربرد بسیاری دارد و ماشین را قادر میسازد تا بتواند همانند انسان فضای اطراف خود را ببیند. همچنین، از این مدل به منظور استخراج ویژگی از دادهها در سایر شاخه های هوش مصنوعی نظیر پردازش زبان طبیعی نیز استفاده میشود. در این مطلب از مجله فرادرس، قصد داریم به معرفی شبکه عصبی پیچشی بپردازیم و اجزای اصلی آن را توضیح دهیم. سپس، با ارائه مثالی کاربردی، به نحوه پیادهسازی یک شبکه عصبی CNN با تنسورفلو و پایتون میپردازیم.
- جایگاه شبکه عصبی پیچشی در هوش مصنوعی و کاربردهای اصلی آن را یاد میگیرید.
- میآموزید که چگونه دادههای تصویری را به فرمت عددی مناسب تبدیل کنید.
- ساختار لایههای CNN و نقش هر کدام در پردازش تصویر را خواهید آموخت.
- مراحل فنی پیادهسازی پروژه CNN با TensorFlow و پایتون را یاد میگیرید.
- فرایند آموزش و ارزیابی دقیق مدل CNN با متریکهای عملی را میآموزید.
- نقش الهامگیری از ساختار مغز انسان در توسعه مدلهای CNN را خواهید شناخت.



شبکه عصبی CNN چیست ؟
شبکه عصبی CNN یا ConvNet یکی از الگوریتم های یادگیری عمیق به حساب میآید که از آن به منظور شناسایی شی در مسائلی نظیر دستهبندی تصاویر، تشخیص تصاویر یا تقسیمبندی تصاویر استفاده میشود. کاربرد این نوع شبکه عصبی را میتوان در ماشینهای خودران، دوربینهای مداربسته و سیستمهای مجهز به بینایی ماشین ملاحظه کرد.
شبکه عصبی CNN دارای ویژگیهای مهمی است که چنین ویژگیهایی، باعث شده است اهمیت این نوع مدل نسبت به سایر شبکههای عصبی مصنوعی یا الگوریتم های یادگیری ماشین بیشتر باشد. در ادامه، به مهمترین ویژگی های شبکه عصبی CNN پرداخته میشود:
- برخلاف مدلهای یادگیری ماشین قدیمی نظیر «ماشین بردار پشتیبان» (Support Vector Machine | SVM) و «درخت تصمیم» (Decision Tree)، شبکه عصبی CNN نیازی به مرحله مجزا برای استخراج ویژگی از دادههای ورودی ندارد و این شبکه بهطور خودکار، ویژگیهای دادهها را تشخیص میدهد.
- شبکه عصبی CNN فارغ از اطلاعاتی نظیر موقعیت قرارگیری پیکسلها، مقیاس آنها و اطلاعاتی از این قبیل، میتواند الگوهای دادهها را شناسایی کند. بدین ترتیب، این نوع شبکهها، محدودیتی برای دادههای ورودی خود اعمال نمیکنند و میتوانند برخلاف سایر شبکههای عصبی، دادههای چندبعدی را نیز بپذیرند.
- از شبکههای عصبی CNN از پیش آموزش داده شده، میتوان برای پروژههای مختلفی نظیر دستهبندی دادهها استفاده کرد و به دقت بالایی دست یافت.
- از شبکه عصبی CNN میتوان برای مسائل دستهبندی با دادههای غیرتصویری نظیر مسائل «پردازش زبان طبیعی» (Natural Language Processing | NLP)، «بازشناسی گفتار» (Speech Recognition) و «تحلیل سری زمانی» (Time Series Analysis) استفاده کرد.
در ادامه مطلب، به ویژگی دادههای شبکه عصبی پیچشی و ساختار درونی این مدل خواهیم پرداخت.
داده ها در شبکه عصبی CNN چگونه هستند ؟
مدلهای هوش مصنوعی فقط دادههایی از نوع عددی را پردازش میکنند. چنانچه دادههای جمعآوری شده برای آموزش مدل، از نوع غیرعددی باشند، باید در ابتدا آنها را به دادههای عددی تبدیل کرد. شبکه عصبی پیچشی نیز از این قاعده مستثنی نیست. در این شبکه، هر تصویر در قالب آرایهای از مقادیر عددی مشخص میشوند.
در تصویر زیر، بازنمایی عددی یک تصویر را ملاحظه میکنید.
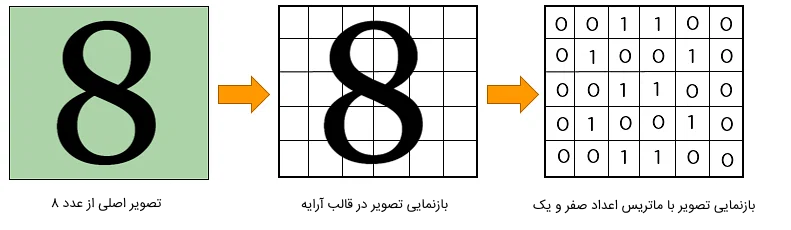
به عبارتی، میتوان گفت هر تصویر در قالب ماتریس برای شبکه عصبی بازنمایی میشود. هر پیکسل تصویر، معادل خانهای از ماتریس است. هر خانه از ماتریس عددی، مقدار رنگ پیکسل را مشخص میکند. در تصاویر سیاه و سفید، مقدار عددی معادل پیکسلهای سفید، برابر با صفر است و خانههایی از ماتریس که برابر با عدد یک هستند، نشان میدهند که پیکسلهای متناظرشان رنگ مشکی دارند.

ساختار داخلی شبکه عصبی CNN از چه بخشهایی تشکیل شده است ؟
طراحی معماری شبکه عصبی CNN از ساختار نورونهای بخش بینایی مغز انسان با چندین لایه الهام گرفته شده که هر لایه مسئول تشخیص بخشی از ویژگیهای دادهها است. لایههای اصلی شبکه عصبی CNN عبارتاند از: «لایه پیچشی» (Convolutional Layer)، «لایه غیرخطی» (Non Linear Layer)، «لایه فشردهساز» (Pooling Layer) و «لایه تمام متصل» (Fully Connected Layer). در ادامه مطلب، به توضیح عملکرد هر یک از لایهها پرداخته میشود.
لایه پیچشی شبکه عصبی ConvNet چیست ؟
نخستین بخش از ساختار شبکه عصبی CNN، لایه پیچشی است که در آن، اصلیترین عملیات ریاضی انجام میشود. به بیان دیگر، این لایه، وظیفه اصلی استخراج ویژگی از دادههای ورودی را بر عهده دارد. لایه پیچشی میتواند دارای چندین فیلتر باشد که هر یک از این فیلترها، اطلاعات خاصی را از دادهها استخراج میکنند.

فیلترها ماتریسهای عددی هستند که معمولاً ابعاد آنها ۳ * ۳ است. اما میتوان هر ابعادی را برای فیلترها در نظر گرفت. ماتریس فیلتر بر روی داده (تصویر) اصلی ورودی حرکت میکند و در هر گام، ضرب داخلی اعداد ماتریس فیلتر و اعداد ماتریس داده اصلی محاسبه میشود.

لایه غیرخطی مدل CNN
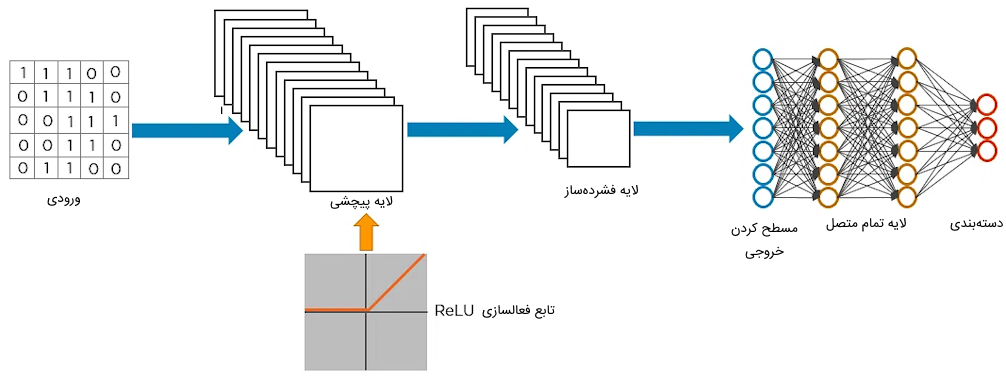
پس از محاسبه خروجی توسط لایه پیچشی در شبکه عصبی CNN، ماتریس عددی به دست آمده به یک لایه غیرخطی ارسال میشود. لایه غیرخطی شامل تابع فعالسازی «یکسوساز» (Rectified Linear Unit | ReLU) است که باعث میشود شبکه روابط غیرخطی میان ویژگیها را تشخیص بدهد.
بدین ترتیب، شبکه عصبی میتواند ویژگیهای مختلف و پیچیده تصویر را نیز شناسایی کند. همچنین، استفاده از تابع فعالسازی غیرخطی در این شبکه باعث میشود مسئله «محوشدگی گرادیان» (Vanishing Gradient) رخ ندهد. منحنی تابع ReLU در تصویر زیر ملاحظه میشود. بر اساس این منحنی، تابع ReLU مقادیر ورودی منفی خود را به مقدار عددی صفر نگاشت میکند و بر روی سایر اعداد ورودی بزرگتر از صفر، تغییری اعمال نمیکند.

لایه فشرده ساز شبکه عصبی CNN
لایه فشردهساز به عنوان سومین لایه در شبکه عصبی CNN شناخته میشود. این لایه، خروجی لایه غیرخطی را دریافت میکند و ابعاد آن را کاهش میدهد. البته کاهش ابعاد در این لایه به نحوی صورت میگیرد که اطلاعات مهم دادهها از دست نروند. چندین نوع لایه فشردهساز در شبکه عصبی CNN وجود دارند که رایجترین آنها، «فشردهسازی بیشینه» (Max Pooling)، «فشردهسازی کمینه» (Min Pooling) و «فشردهسازی میانگین» (Average Pooling) هستند.
ماتریس خروجی حاصل از لایه غیرخطی، به عنوان ورودی به لایه فشردهساز ارسال میشود. چنانچه لایه فشردهساز از نوع بیشینه باشد، بزرگترین مقادیر از اعداد ماتریس استخراج میشوند. در لایه فشردهساز از نوع کمینه و میانگین نیز، به ترتیب، کوچکترین مقادیر و میانگین مقادیر اعداد ماتریس محاسبه میشوند. در تصویر زیر، نمونهای از عملکرد لایه فشردهساز در شبکه عصبی CNN را ملاحظه میکنید.

در گام بعدی، ماتریس ۲ بُعدی حاصل شده از لایه فشردهساز، مسطح شده و به یک «بردار» (Vector) یک بُعدی تبدیل میشود.

لایه تمام متصل در شبکه عصبی CNN
پس از این که خروجی لایه فشردهساز شبکه CNN مسطح شد و به شکل یک بردار درآمد، بردار حاصل به یک شبکه تمام متصل ارسال میشود تا در نهایت بتوان از ویژگیهای استخراج شده به منظور حل مسئله دستهبندی استفاده کرد.
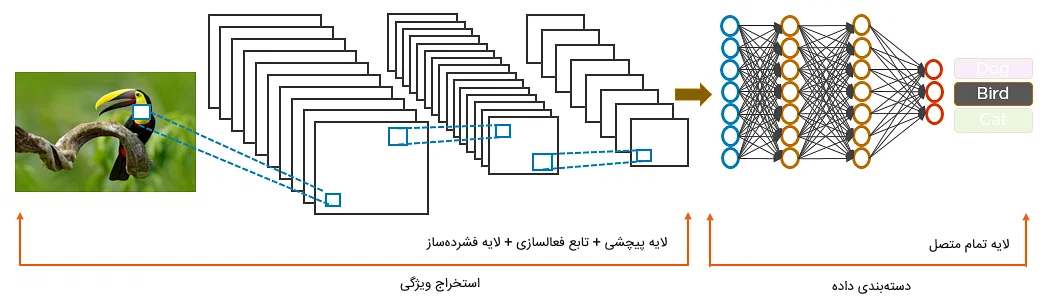
در تصویر زیر، ساختار شبکه عصبی CNN را برای دستهبندی تصاویر گربهها، سگها و پرندگان ملاحظه میکنید.
تا اینجا، به معرفی ساختار درونی شبکه عصبی پیچشی یا همان کانولوشن پرداختیم تا به درک نحوه پیادهسازی این مدل با استفاده از زبان برنامه نویسی کمک کند. در ادامه، قصد داریم به پیادهسازی یک شبکه عصبی CNN با تنسورفلو در زبان برنامه نویسی پایتون بپردازیم. پیش از پرداختن به این آموزش، مقدمه کوتاهی از کتابخانه تنسورفلو را ارائه میکنیم و به نحوه استفاده از آن در زبان پایتون اشاره خواهیم کرد.
فریم ورک تنسورفلو
شرکت گوگل در سال ۲۰۱۵ فریمورک «تنسورفلو» (Tensorflow) را برای پیادهسازی پروژههای یادگیری ماشین ارائه کرد. این فریمورک، منبع باز است و توسعهدهندگان و برنامهنویسان میتوانند بدون هیچ محدودیتی از آن استفاده کنند. فریمورک تنسورفلو دارای کتابخانههای مختلفی است که با استفاده از آنها میتوان الگوریتمهای ماشین لرنینگ و الگوریتمهای یادگیری عمیق را به سادگی پیادهسازی کرد. البته پیشتر راجع به پروژههای یادگیری ماشین و ماشین لرنینگ در مجله فرادرس صحبت کردیم.
چنانچه بر روی سیستم خود این فریمورک را تاکنون نصب نکردهاید، میتوانید از دستور pip در خط فرمان سیستم عامل خود استفاده کنید و پس از آن نام فریمورک را بنویسید. پس از نصب فریمورک تنسورفلو، میتوانید فایل پایتونی را ایجاد کنید و این فریمورک را با دستور در برنامه خود فراخوانی کنید. در قطعه کد زیر نحوه فراخوانی تنسورفلو و بررسی ورژن آن را ملاحظه میکنید.
پیاده سازی گام به گام شبکه عصبی CNN با تنسورفلو
در این بخش قصد داریم تمامی مفاهیمی را که تا به اینجا در مطلب حاضر یاد گرفتیم، برای پیادهسازی شبکه عصبی CNN با تنسورفلو به کار ببریم.
میتوان مراحل توسعه پروژه هوش مصنوعی را در چندین گام اصلی خلاصه کرد که در ادامه به آنها اشاره شده است:
- جمعآوری دادهها
- پیشپردازش دادهها
- طراحی مدل
- آموزش مدل
- ارزیابی مدل
در ادامه مطلب، به توضیح هر یک از مراحل ذکر شده در بالا میپردازیم و از یک مثال کاربردی برای آموزش نحوه پیادهسازی یک شبکه عصبی CNN با تنسورفلو استفاده میکنیم.
دادههای شبکه عصبی CNN
برای شروع کار هر پروژه برنامه نویسی، باید دادههای پروژه را مشخص کنیم تا به کمک آنها مدلهای هوش مصنوعی را آموزش دهیم. زبان برنامه نویسی پایتون شامل چندین مجموعه داده برای پروژههای مختلف هوش مصنوعی است که میتوان بهراحتی از آنها برای توسعه پروژههای خود بهره ببریم.
در آموزش فعلی، از مجموعه داده پایتون با نام CIFAR-10 استفاده میکنیم. در ادامه، به مشخصات این مجموعه داده پرداخته شده است:
- مجموعه داده CIFAR-10 شامل ۶۰ هزار تصویر رنگی با ابعاد ۳۲ * ۳۲ است.
- تصاویر موجود در این مجموعه داده در ۱۰ کلاس دستهبندی شدهاند.
- هر کلاس شامل ۶ هزار تصویر است.
- ۵۰ هزار داده این مجموعه داده متعلق به دادههای آموزشی و ۱۰ هزارتای دیگر مربوط به دادههای آزمایشی هستند.
ساختار شبکه عصبی CNN با تنسورفلو
به منظور پیادهسازی شبکه عصبی CNN با تنسورفلو برای مسئله دستهبندی تصاویر، از معماری مشخص شده در تصویر زیر استفاده میکنیم.

بر اساس تصویر بالا، ورودی شبکه عصبی CNN تنسوری با ابعاد ۳۲ * ۳۲ * ۳ است که به ترتیب مقادیر عرض، طول و تعداد کانال تصویر را مشخص میکنند. در این معماری شبکه، از ۲ لایه پیچشی استفاده شده است. اولین لایه پیچشی، ۳۲ فیلتر به ابعاد ۳ * ۳ دارد و دومین لایه پیچشی دارای ۶۴ فیلتر به ابعاد ۳ * ۳ است. خروجی لایههای پیچشی نیز به توابع غیرخطی ReLU ارسال میشوند.
پس از لایههای غیرخطی نیز از لایههای فشردهساز بیشینه به ابعاد ۲ * ۲ استفاده شده است. در لایه آخر شبکه عصبی CNN نیز یک لایه تمام متصل با تعداد گرههای ۱۲۸ در نظر گرفته شده است که در نهایت خروجی آن، به ۱۰ گره خروجی نگاشت میشوند. این ۱۰ گره، کلاس تصاویر را مشخص میکنند که برای توابع فعالسازی آنها، از تابع Softmax استفاده میکنیم.
بارگذاری داده برای آموزش شبکه عصبی CNN با تنسورفلو
به منظور استفاده از مجموعه داده CIFAR-10 و بارگذاری آن در پروژه، از قطعه کد زیر استفاده میکنیم.
میتوان از قطعه کد زیر به منظور بررسی چند نمونه از دادههای موجود در مجموعه داده استفاده کرد.
خروجی قطعه کد بالا را در تصویر زیر ملاحظه میکنید که هر تصویر با برچسب مشخص شدهاند.

پیش پردازش داده برای شبکه پیچشی با تنسورفلو
پیش از آموزش مدل باید دادههای آموزشی را نرمالسازی کنیم و مقادیر عددی ورودیها را در بازه مشخصی نظیر صفر تا یک قرار دهیم. در پردازش تصویر، پیش پردازش دادهها یکی از گامهای مهم محسوب میشود که باعث میشود همگرایی شبکه سریعتر اتفاق بیفتد. از قطعه کد زیر به منظور پیش پردازش دادهها استفاده میکنیم.
برچسبهای دادههای این مجموعه داده، قالب عددی ندارند و با اسم (مانند گربه، اسب و پرنده) مشخص شدهاند. چنین برچسبهایی را باید به قالب عددی تبدیل کنیم تا شبکه عصبی بتواند آنها را یاد بگیرد. بدین منظور، از قطعه کد زیر استفاده میکنیم.
پیاده سازی شبکه عصبی پیچشی با تنسورفلو
پس از آمادهسازی دادهها در قالب مناسب شبکه عصبی، باید مدل را پیادهسازی کنیم. در مثال حاضر، برای تعریف مدل از کلاس Sequential()استفاده میکنیم. با استفاده از این کلاس میتوان هر لایه شبکه را با تابع add()به مدل اضافه کنیم.

در قطعه کد زیر، نحوه استفاده از کلاس Sequential()و تابع add()ملاحظه میشود.
با استفاده از تابع model.summary()میتوان خلاصهای از معماری تعریف شده برای مدل را در خروجی ملاحظه کرد.

آموزش مدل CNN با تنسورفلو
پس از تعریف ساختار شبکه عصبی CNN با تنسورفلو ، با استفاده از توابع compile()و fit()میتوان تنظیمات مختلفی را برای آموزش مدل مشخص کرد.
در ادامه، به سه مورد از این تنظیمات اشاره میشود:
- پارامتر «بهینهساز» (Optimizer): با استفاده از این پارامتر میتوان نحوه بهینهسازی مدل و بهروزرسانی وزنهای شبکه عصبی را مشخص کرد. در مثال حاضر، از الگوریتم بهینهساز «آدام» (Adam) استفاده میکنیم.
- پارامتر «تابع زیان | تابع هزینه» (Loss Function): این پارامتر نوع تابع هزینه را مشخص کند.
- پارامتر «معیار ارزیابی» (Metrics): از این پارامتر به منظور تعیین نوع ارزیابی عملکرد مدل استفاده میشود.
در قطعه کد زیر، نحوه استفاده از توابع و پارامترهای ذکر شده در بالا را با فریمورک تنسورفلو در پایتون ملاحظه میکنید.
ارزیابی مدل CNN با تنسورفلو
پس از آموزش مدل، باید عملکرد مدل را روی دادههای آموزشی و دادههای تست بسنجیم. میتوان مقادیر معیارهای ارزیابی مدل را در قالب منحنی رسم کنیم تا عملکرد مدل بهتر ملاحظه شود. بدین منظور از قطعه کد زیر استفاده میکنیم.
در تصویر زیر، منحنیهای مربوط به دو معیار accuracyو precisionرا ملاحظه میکنید.
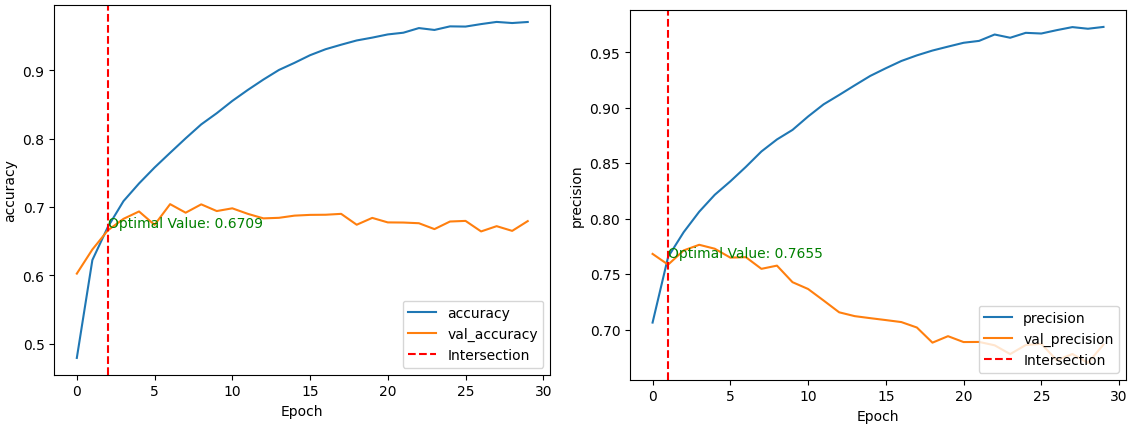
همانطور که در تصویر بالا ملاحظه میکنید:
- دقت مدل برابر با ۶۷.۰۹ درصد است. به عبارتی، مدل میتواند ۶۷ درصد از دادهها را بهدرستی دستهبندی کند.
- ۷۶.۵۵ درصد از کل برچسبها، توسط مدل به درستی تشخیص داده شدهاند و مدل حدود ۲۳ درصد از برچسبها را بهاشتباه برچسبدهی کرده است.
- افزایش تعداد دادههای آموزشی
- استفاده از روش «یادگیری انتقال» (Transfer Learning) و به کارگیری مدلهای از پیش آموزش داده شده نظیر ResNet ،MobileNet یا VGC
- استفاده از روشهای «تعادلسازی» (Regularization) مانند L1 و L2
- مقداردهی مختلف به «هایپرپارامترها» (Hyperparameters) مانند پارامتر «نرخ یادگیری» (Learning Rate) و تعداد لایههای شبکه

جمعبندی
پیدایش مدلهای هوش مصنوعی ریشه در الهامگیری از فرآیند پردازش اطلاعات مغز و نحوه یادگیری آن دارد. یکی از این مدلها، شبکه عصبی CNN است که هدف اولیه آن، یادگیری دادههای تصویری توسط ماشین و تقویت بینایی ماشین بود. با گسترده شدن حوزه مطالعاتی هوش مصنوعی در سایر حیطهها، کاربرد این شبکه عصبی در دیگر شاخههای هوش مصنوعی نیز بیشتر شده و از CNN به عنوان لایهای برای استخراج ویژگی از دادهها نیز استفاده شده است.

در مطلب حاضر، قصد داشتیم به معرفی مدل CNN بپردازیم و اجزای اصلی داخلی آن را به زبان ساده توضیح دهیم. در نهایت نیز، با ارائه یک مثال کاربردی، نحوه پیادهسازی شبکه عصبی CNN با تنسورفلو با زبان پایتون را آموزش دادیم.









