




شبکه عصبی چیست؟ – کامل و به زبان ساده
در سالهای اخیر از مدلهای «یادگیری عمیق» (Deep Learning) در حوزههای بسیاری نظیر «ترجمه ماشین» (Machine Translate)، تشخیص بیماری با استفاده از اشعه ایکس، تشخیص تصاویر برای ماشینهای خودران، پیشبینی بازار سهام و سایر حوزههای دیگر استفاده شده است. معماری مدلهای یادگیری عمیق از ساختاری با عنوان «شبکه عصبی» (Neural Network) تشکیل شده است که با نام «شبکه عصبی مصنوعی» (Artificial Neural Network) نیز شناخته میشوند. افرادی که مشتاق هستند در زمینه هوش مصنوعی شروع به مطالعه و یادگیری کنند، میتوانند با مطالعه مقاله حاضر با مفاهیم ابتدایی این حوزه آشنا شوند و به پاسخ این پرسش برسند که شبکه عصبی چیست و مباحث مهم پیرامون آن را دریابند.




به منظور تعریف شبکه عصبی و کاربرد آن، نیاز است در ابتدا به توضیح مفهوم یادگیری عمیق پرداخته و تفاوت اصلی آن با حوزه «یادگیری ماشین» (Machine Learning) مشخص شود. در این مقاله، علاوه بر تحقق این هدف، به توضیح رویکردهای موجود در یادگیری عمیق، رایجترین و پرکاربردترین انواع شبکههای عصبی و مزایا و معایب هر یک از آنها پرداخته خواهد شد.
یادگیری عمیق چیست ؟
هوش مصنوعی شامل مجموعهای از روشها است که کامپیوتر را قادر میسازد به منظور تصمیمگیری درباره مسائل مختلف، عملکردی هوشمندانه و انسانگونه داشته باشند. به عبارتی، میتوان با هوش مصنوعی دادهها را برای ماشین تفسیر کرد تا آنها را یاد بگیرد و از دانش کسب شده در انجام کارهایی استفاده کند که نیاز به توانمندی هوش انسان دارد. در این راستا، میتوان از روشهای یادگیری ماشین و یادگیری عمیق استفاده کرد تا سیستمهای هوشمندی را به منظور انجام فعالیتهای مختلف آموزش داد. با این حال تفاوت مهمی بین روشهای یادگیری ماشین با روشهای یادگیری عمیق وجود دارد که در ادامه به آن پرداخته میشود.
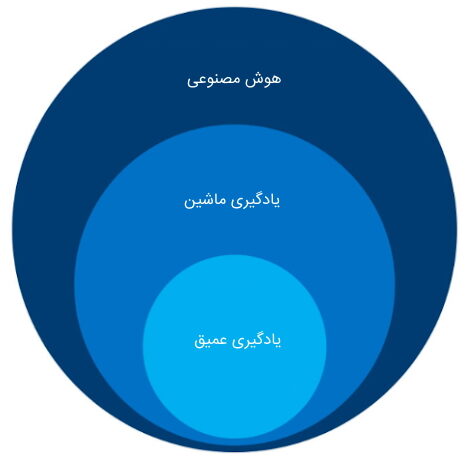
تفاوت یادگیری ماشین و یادگیری عمیق چیست ؟
روشهای یادگیری ماشین سنتی نظیر «درخت تصمیم» (Decision Tree)، «ماشین بردار پشتیبان» (Support Vector Machine | SVM)، «دستهبند بیز ساده» (Naïve Bayes Classifier) و «رگرسیون لجستیک» (Logistic Regression) را نمیتوان بهطور مستقیم بر روی دادههای خام نظیر فایلهای CSV، تصاویر و متون به منظور یادگیری دادهها اعمال کرد. به عبارتی، باید با استفاده از مرحله «پیشپردازش» (Preprocessing)، از دادههای خام، ویژگیهایی را به عنوان بازنمایی دادههای خام استخراج کرد تا از این ویژگیها به عنوان ورودی الگوریتمهای یادگیری ماشین استفاده شود.
«استخراج ویژگی» (Feature Extraction) روال پیچیدهای است و به دانشی عمیق پیرامون مسئله احتیاج دارد. بهعلاوه، باید از روال استخراج ویژگی چندین بار استفاده شود تا در نهایت بتوان بهترین ویژگیها را برای مسئله تعریف شده انتخاب کرد. با ارائه روشهای یادگیری عمیق، مشکل پیچیدگی فرآیند استخراج ویژگی و زمان استخراج آنها حل شده است. به عبارتی، مدلهای یادگیری عمیق نیازی به گام مجزا برای استخراج ویژگی ندارند و لایههای شبکههای عصبی قادر هستند بازنماییهای ضمنی دادههای خام را در روال آموزش شبکه یاد بگیرند.
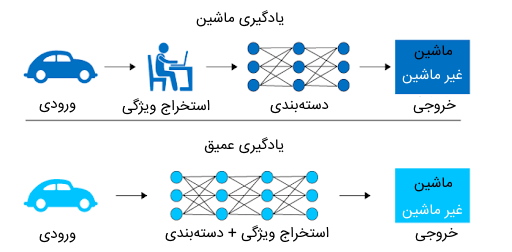
به منظور درک بهتر تفاوت یادگیری ماشین و یادگیری عمیق میتوان از مثال ملموسی استفاده کرد که در تصویر بالا مشاهده میشود. چنانچه برنامه نویس قصد داشته باشد مدلی را با استفاده از روشهای یادگیری ماشین آموزش دهد تا عکسهای شامل تصاویر ماشین را از تصاویر غیرماشین جدا کند، باید در ابتدا ویژگیهایی را برای تصاویر ماشین تعریف کند تا مدل یادگیری ماشین با استفاده از آنها به شناسایی تصاویر ماشین بپردازد.
چنین روالی برای تشخیص ویژگیها، برگرفته از عملکرد مغز انسان برای شناسایی اجسام است. به بیان دیگر، مغز انسان با توجه به یک سری ویژگیهای ورودی نظیر شکل جسم، اندازه جسم، وجود یا عدم وجود پنجره، وجود یا عدم وجود چرخ و سایر ویژگیها، در نهایت تصمیم میگیرد که آیا جسم مشاهده شده میتواند به عنوان ماشین تلقی شود؟ این در حالی است که در یادگیری عمیق، برنامه نویس به منظور شناساندن دادهها به مدل، گام اضافهای انجام نمیدهد و مدل در حین آموزش به منظور دستهبندی تصاویر، ویژگیهای ماشین را بهطور خودکار یاد میگیرد.
شبکه عصبی چیست ؟
الگوریتمهای یادگیری عمیق از ساختارهای لایهای با نام شبکههای عصبی استفاده میکنند تا بر اساس تجزیه و تحلیل دادهها، برای گرفتن تصمیم خاصی، رفتار انسان را تقلید کنند. طرح این ساختار لایهای، برگرفته از ساختار مغز انسان است. همانطور که مغز انسان به شناسایی الگوهای مختلف دادهها و دستهبندی انواع اطلاعات میپردازد، میتوان شبکههای عصبی را به شیوهای مشابه با رفتار مغز انسان آموزش داد تا به تشخیص الگوها بپردازند و دستهبندی دادهها را انجام دهند.

به عبارت دیگر، زمانی که مغز انسان با اطلاعات جدیدی روبهرو میشود، در تلاش است این اطلاعات را با مفاهیم قبلی و شناخته شده خود مقایسه کند تا به درک بهتر اطلاعات جدید برسد. هدف شبکههای عصبی نیز تشخیص الگوها و دستهبندی اطلاعات جدید بر پایه دانش قبلی خود است. یادگیری آنی الگوها در قالب بردارهای عددی انجام میشود. به عبارتی، تمامی دادههای دنیای واقعی نظیر تصاویر، صوت و متن باید به بردارهای عددی تبدیل شوند و به عنوان ورودی، در اختیار شبکه عصبی قرار میگیرد تا مدل هوش مصنوعی بتواند آنها را درک کند.
کاربرد شبکه عصبی چیست ؟
شبکههای عصبی میتوانند مسائل غیرخطی را مدلسازی کنند و به خاطر همین ویژگی، میتوان از آنها در بسیاری از مسائل مختلف نظیر «تشخیص الگو» (Pattern Recognition)، «کاهش بعد» (Dimension Reduction)، ترجمه ماشین، «تشخیص ناهنجاری» (Anomaly Detection)، «بینایی ماشین» (Computer Vision)، «پردازش زبان طبیعی» (Natural Language Processing)، تشخیص بیماری، پیشبینی قیمت سهام و سایر موارد استفاده کرد.
در حالت کلی، کاربردهای شبکه عصبی را میتوان به سه گروه «دستهبندی» (Classify) دادهها، «خوشهبندی» (Clustering) دادهها و مسائل «رگرسیون» (Regression) تقسیمبندی کرد که در ادامه به توضیح هر یک از آنها پرداخته میشود.
روش دسته بندی داده در یادگیری عمیق چیست ؟
در روال دستهبندی دادهها، به منظور آموزش مدل، به حجم زیادی «داده برچسب خورده» (Labeled data) نیاز است تا مدل با استفاده از اطلاعاتی که برچسبهای دادهها در اختیارش میگذارند، به پیشبینی دستههای دادههای جدید بپردازد.
به عبارتی، در روش دستهبندی دادهها، انسان باید دانش خود را در تهیه مجموعه دادگان استفاده کند و دادههای مورد نیاز آموزش مدل را بر اساس دانش تخصصی مختلف نظیر دانش زبانشناختی برچسب بزند تا مدل، رابطه میان دادهها و برچسبها را یاد بگیرد. به این رویکرد، «یادگیری نظارت شده» (Supervised Learning) گفته میشود که در طی این روش از یادگیری، برچسبهای آماده شده توسط انسان به یادگیری مدل کمک میکنند. تشخیص اسپم و غیراسپم بودن ایمیلها، نمونهای از «وظایف» (Tasks) دستهبندی و رویکرد نظارت شده محسوب میشود.

روش خوشه بندی داده در یادگیری عمیق چیست ؟
در روش خوشهبندی، الگوریتمهای یادگیری عمیق بدون نیاز به دادههای برچسب خورده، به تشخیص گروههای دادهها میپردازند. به عبارتی، شبکههای عصبی خوشهبندی، صرفاً با بررسی میزان شباهت دادهها، آنها را در گروههای مجزا قرار میدهند و در نهایت چندین گروه از دادهها تشکیل میشوند که دادههای هر گروه، ویژگیهای مشابهی نسبت به یکدیگر دارند.
این رویکرد از یادگیری «یادگیری نظارت نشده» (Unsupervised Learning) نام دارد که در طی آن مدل بدون استفاده از هر گونه اطلاعات اضافی و صرفاً با در اختیار داشتن دادهها، به تشخیص انواع گروههای دادهها میپردازد. مزیت این روش نسبت به روش دستهبندی، عدم نیاز به فراهم کردن دادههای برچسب خورده است که در کاهش هزینههای مالی و زمانی تاثیر چشمگیری دارد.
یکی از اصول اصلی مدلهای یادگیری عمیق این است که هرچقدر تنوع و توزیع و حجم دادههای آموزشی مدل بیشتر باشد، یادگیری مدل از دادهها بیشتر بوده و مدل در شناخت دادههای جدید و تصمیمگیری پیرامون مسئله تعریف شده، عملکرد بهتری خواهد داشت. از آنجا که میزان حجم دادههای بدون برچسب در مقایسه با دادههای برچسب خورده بیشتر است، الگوریتمهای خوشهبندی دقت و عملکرد بهتری دارند.
روش رگرسیون در یادگیری عمیق چیست ؟
در مسائل رگرسیون، از شبکه عصبی به منظور یافتن رابطه میان «متغیرهای مستقل» (Independent Variables) یا ویژگیها و «متغیرهای وابسته» (Dependent Variables) یا مقدار خروجی شبکه استفاده میشود. مقادیر خروجی مدل در مسائل رگرسیون، مقادیری «پیوسته» (Continuous) هستند. رگرسیون همانند روش دستهبندی، از رویکرد یادگیری نظارت شده بهره گرفته و به منظور آموزش مدل باید مجموعه دادهای را فراهم کرد. پیشبینی هزینه قیمت محصولات و میزان فروش محصولات در یک بازه زمانی در آینده نمونه وظایفی هستند که میتوان با روش رگرسیون آنها را مدلسازی کرد.
معرفی فیلم های آموزش هوش مصنوعی

در سایت فرادرس برای آن دسته از افرادی که علاقهمند هستند در زمینه هوش مصنوعی بهصورت حرفهای مشغول به کار شوند، مجموعهای از فیلمهای آموزش هوش مصنوعی تهیه شده است. فیلمهای آموزشی موجود در سایت فرادرس پیرامون مباحث نظری و عملی هوش مصنوعی است و به توضیح الگوریتمهای مربوط به یادگیری ماشین و یادگیری عمیق با استفاده از زبانهای برنامهنویسی مختلف نظیر پایتون و متلب پرداخته است.
این دورههای آموزشی شامل فیلمهای آموزشی مقدماتی تا پیشرفته و پروژهمحور حوزه هوش مصنوعی میشوند. علاقهمندان میتوانند از این دوره آموزشی جامع در راستای تقویت مهارت تخصصی خود در حیطههای مختلف هوش مصنوعی اعم از دادهکاوی، علوم داده، پردازش تصویر و پردازش زبان طبیعی استفاده کنند. در تصویر فوق تنها برخی از دورههای آموزشی مجموعه آموزش هوش مصنوعی فرادرس نمایش داده شدهاند.
- برای دسترسی به همه آموزشهای هوش مصنوعی فرادرس + اینجا کلیک کنید.
مزایا و معایب شبکه عصبی چیست ؟
در دنیای امروز، تمامی جنبههای زندگی انسان تحت تاثیر هوش مصنوعی است و این شاخه از فناوری روزبهروز در حال پیشرفت و گسترش است. به عبارتی، نحوه زندگی و فعالیت شغلی انسانها با ظهور این حوزه از علم دستخوش تغییراتی شده که هم مزیتهای مهم و مثبتی برای بشر به ارمغان آورده و هم تاثیرات منفی مختلفی را به همراه داشته است. در ادامه، به مزایای هوشمندسازی سیستمها با استفاده از شبکههای عصبی پرداخته میشود:
- میزان بازدهی بالا در انجام فعالیتها: ماشین، برخلاف انسان، از انجام شبانهروزی کارها خسته نمیشود و میتواند بدون وقفه، مسئولیتها را انجام دهد. بدینترتیب، با استفاده از مدلهای هوشمند، در هزینه زمانی صرفهجویی شده و نتایج چشمگیری حاصل میشود.
- یادگیری سریع وظایف: مدلهای مبتنی بر شبکههای عصبی میتوانند وظایف را سریع یاد بگیرند. هزینههای آموزش نیروی انسانی به لحاظ مالی و زمانی زیاد است. بدینترتیب، آموزش مدلها برای انجام یک سری وظایف تکراری میتواند برای سازمانها، مقرونبهصرفهتر باشد.
- انجام چندین وظایف بهطور همزمان: در مدلهای پیشرفته هوشمند، میتوان مدلها را برای انجام چندین وظیفه بهطور همزمان آموزش داد.
- کاربرد وسیع مدلهای هوشمند در زمینههای مختلف زندگی انسان: از آنجایی که هدف مدلها و سیستمهای هوشمند، تقلید رفتار انسان در انجام وظایف و مسئولیتهای مختلف است، از این شاخه از علم در تمامی علوم نظیر پزشکی، مهندسی، کشاورزی و سایر جنبههای مرتبط با زندگی بشر استفاده میشود تا رفاه و آسایش زندگی بشر بیش از پیش شود.

سیستمهای مبتنی بر هوش مصنوعی، علاوهبر مزیتهای قابل توجهشان، دارای معایبی نیز هستند که در ادامه برخی از مهمترین آنها فهرست شدهاند:
- نیاز به سختافزار: به منظور پیادهسازی مدلهای هوش مصنوعی و فراهم کردن دادههای آموزشی مورد نیاز آنها، به سختافزارهای قدرتمندی احتیاج است که با توجه به میزان پیچیدگی مسائل، به مراتب به هزینه بالایی احتیاج دارند.
- عملکرد مبتنی بر احتمال: شبکههای عصبی به منظور یادگیری مسائل مختلف، از مباحث احتمالاتی استفاده میکنند. همین امر باعث میشود در برخی شرایط حساس، مدل تصمیم درستی برای حل مسئله نگیرد.
- وابستگی به داده: برای آموزش مدلهای مبتنی بر شبکه عصبی، به حجم زیادی داده نیاز است. جمعآوری دادههای مورد نیاز و آمادهسازی آنها برای آموزش مدل به هزینههای مالی و زمانی بالایی نیاز دارد. همچنین، دادههای فراهم شده، ممکن است دارای نویز باشند که همین امر میتواند بر عملکرد مدل تاثیرگذار باشد.
- از دست رفتن فرصت شغلی برای انسان: با هوشمندسازی سیستمها و جایگزین کردن آنها به جای نیروهای انسانی، بسیاری از افراد شغل خود را از دست میدهند. همین امر باعث میشود درصد بیکاران و به تبعیت از آن، میزان فقر در جامعه بیشتر شود.
شبکه عصبی از چه اجزایی تشکیل شده است ؟
به منظور درک پرسش «شبکه عصبی چیست»، باید نگاهی به ساختار شبکه و اجزای تشکیل دهنده آن داشت. شبکه عصبی از چندین لایه تشکیل میشود که حداقل تعداد این لایهها، 3 لایه است که در ادامه فهرست شدهاند:
- «لایه ورودی» (Input Layer)
- «لایه میانی | پنهان» (Hidden Layer)
- «لایه خروجی» (Output Layer)
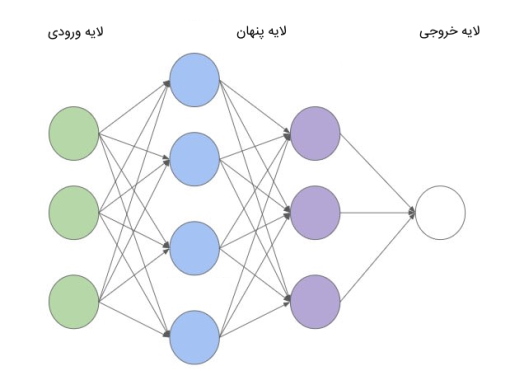
هر لایه شبکه عصبی شامل مجموعهای از گرهها یا «نود» (Nodes) است که عملکردی مشابه با «نورونهای» (Neurons) مغز انسان دارند. در تصویر زیر مشاهده میشود که لایه نخست، دارای 2 گره، لایه پنهان یا میانی دارای 3 گره و لایه آخر دارای 1 گره است. تعداد گرههای هر لایه با توجه به تعداد ابعاد دادههای ورودی و مسئلهای که بناست مدل را برای آن آموزش دهیم، متفاوت خواهد بود.
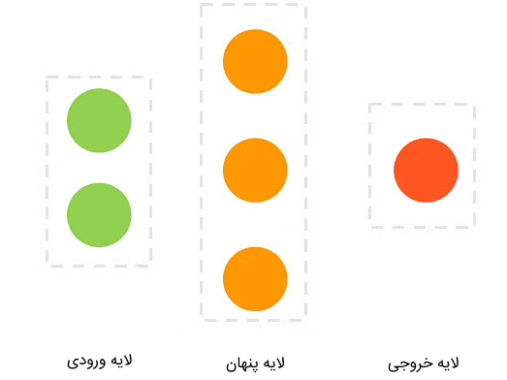
در ادامه به توضیح هر یک از لایههای شبکه عصبی و ساختار درونی گرههای آنها پرداخته میشود.
لایه ورودی در شبکه عصبی چیست ؟
هر شبکه عصبی دارای یک لایه ورودی است که دادههای دنیای بیرون را دریافت میکند و به منظور اعمال محاسبات مختلف بر روی دادهها، آنها را به لایه بعد خود میفرستد. به عبارتی، این لایه هیچ گونه عملیات محاسباتی و پردازشی بر روی دادهها اعمال نمیکند و صرفاً مسئولیت دریافت دادهها و ارسال آنها را به لایههای بعدی برعهده دارد. دادههای ورودی لایه نخست، میتواند شامل اطلاعات متنی، صوتی و تصویری باشد.
لایه پنهان در شبکه عصبی چیست ؟
لایهای که در میان لایه ورودی و لایه خروجی قرار میگیرد، لایه پنهان یا لایه میانی نام دارد. حداقل تعداد لایههای میانی شبکه عصبی، یک لایه است و بر اساس پیچیدگی و نوع مسئله میتوان به تعداد لایههای میانی شبکه اضافه کرد. هر چقدر تعداد لایههای میانی شبکه بیشتر باشد، شبکه، عمیقتر بوده و بار محاسباتی آن بیشتر میشود. لایههای میانی مسئولیت اعمال عملیات محاسباتی بر روی دادههای دریافتی از لایه پیشین خود را برعهده دارند.
اصطلاح «عمیق» (Deep) نیز برگرفته از نوع ساختار شبکه عصبی است. یکی از شبکههای عصبی قدیمی که «پرسپترون» (Perceptron) نام دارد، تنها شامل یک لایه میانی است و به همین خاطر این نوع شبکه از نوع شبکههای عصبی «کمعمق» (Shallow) محسوب میشود. امروزه، شبکههای عصبی با تعداد بیش از 3 لایه پنهان به عنوان شبکههای عمیق بهشمار میروند.
لایه خروجی در شبکه عصبی چیست ؟
آخرین لایه شبکه عصبی، لایه خروجی شبکه است که مقادیر خروجی شبکه عصبی را محاسبه میکند. به عبارتی، لایه خروجی، با دریافت ورودی خود از لایه قبلی (لایه پنهان)، محاسباتی برروی آنها انجام داده و در نهایت خروجی شبکه را تولید میکند.
گره در شبکه عصبی از چه اجزایی تشکیل شده است ؟
لایههای شبکه عصبی از واحدهای مستقلی به نام گره یا گره ساخته شدهاند که این گرهها رفتاری شبیه به رفتار نورونهای مغز انسان دارند. گرهها دادههای ورودی خود را دریافت کرده و با اعمال محاسبات بر روی آنها، مقداری را در خروجی برمیگردانند. ساختار درونی گره شامل اجزای مختلفی به شرح زیر است:
- ورودی گره: در لایه نخست شبکه عصبی، ورودی گرهها در قالب بردارهای عددی با طول یکسان هستند. به عنوان مثال، در مسئله تشخیص اشیاء، ورودی گرههای لایه نخست، لیستی از مقادیر پیکسلهای تصاویر است. ورودی گرهها در لایههای پنهان و لایههای خروجی، مقادیر خروجی حاصل از لایههای قبلی آنهاست.
- وزنهای ورودی گره: وزنها میزان اهمیت ورودیهای گرهها را مشخص میکنند. به عبارتی، با اعمال ضرب داخلی مقدار ورودی گره و ماتریس وزن، میزان اهمیت هر ویژگی ورودی مشخص میشود. به عنوان مثال، در مسئله عقیدهکاوی و تحلیل احساسات، وزن کلمات منفی و مثبت از وزن سایر کلمات بیشتر است و شبکه عصبی با توجه به کلمات با وزنهای بیشتر، تحلیل احساسات جملات را انجام میدهد. در هر مرحله از روال «پس انتشار» (Backpropagation) مقادیر وزنها بهروزرسانی شده تا مقدار نهایی «تابع زیان | هزینه» (Loss Function) کاهش پیدا کند.
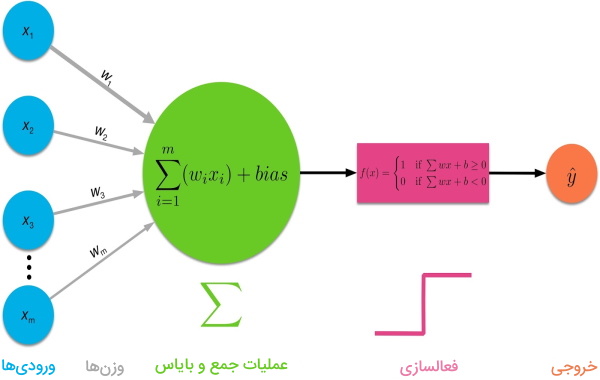
- «تابع فعالسازی» (Activation Function) گره: ورودی تابع فعالسازی، ترکیب خطی مقادیر ورودی، وزنها و مقادیر بایاس است. وظیفه تابع فعالسازی در شبکههای عصبی، تبدیل ترکیب خطی ورودیها به غیرخطی است و مقادیر ورودی را براساس نوع تابع فعالسازی به فضا با بازه مشخصی نگاشت میکند. به بیان دیگر، این توابع تعیین میکنند آیا خروجی گره برای شبکه عصبی اهمیت دارد یا باید آن را نادیده گرفت.
- بایاس گره: نقش بایاس در شبکه عصبی این است که خروجی نهایی تابع فعالسازی را تغییر دهد. نقش بایاس مشابه نقش مقدار ثابت در تابع خطی است و مقدار نهایی تابع فعالسازی را در فضای برداری به چپ و راست منتقل میکند تا تابع نهایی بر روی دادهها بهتر منطبق شود و مدل در نهایت پیشبینی دقیقتری داشته باشد.
انواع شبکه های عصبی کدامند ؟
انواع مختلفی از شبکههای عصبی وجود دارند که به لحاظ ساختار، جریان داده، تعداد و نوع نورونهای لایهها، تعداد لایهها و سایر موارد با یکدیگر تفاوت دارند. در ادامه، به رایجترین و پرکابردترین انواع شبکههای عصبی اشاره شده است:
- شبکه عصبی «پرسپترون» (Perceptron)
- «شبکه عصبی پیشخور» (Feed Forward Neural Network)
- شبکه عصبی «چند لایه پرسپترون» (Multilayer Perceptron)
- «شبکه عصبی پیچشی» (Convolutional Neural Network)
- «شبکه عصبی تابع پایه شعاعی» (Radial Basis Function Neural Network)
- «شبکه عصبی بازگشتی» (Recurrent Neural Network)
- «مدلهای رمزگذار-رمزگشا» (Encoder-Decoder Models)
- «شبکه عصبی ماژولار» (Modular Neural Network)
در ادامه مطلب حاضر، به توضیح ساختار درونی هر یک از مدلهای ذکر شده در فوق به همراه مزایا و معایب آنها پرداخته میشود.
شبکه عصبی پرسپترون چیست ؟
مدل پرسپترون یکی از سادهترین و قدیمیترین مدلهای شبکه عصبی است که از آن در مسائلی با رویکرد یادگیری نظارت شده برای دستهبندی دادهها به دو گروه مشخص استفاده میشود. مدل پرسپترون تنها دارای دو لایه ورودی و خروجی است. دادهها از طریق لایه نخست به شبکه وارد میشوند و هر یک از مقادیر، با وزنهای مدل (که در ابتدای آموزش مدل با مقادیر تصادفی مقداردهی شدهاند) ضرب میشوند. سپس حاصل جمع تمامی ضربها به لایه آخر منتقل میشود. لایه آخر دارای یک گره با تابع فعالسازی است که حد آستانهای برای مقدار ورودی خود در نظر میگیرد. چنانچه مقدار ورودی گره بیشتر از عدد 0 باشد، خروجی تابع فعالسازی برابر با عدد 1 و در غیر این صورت برابر با عدد 0 خواهد بود.
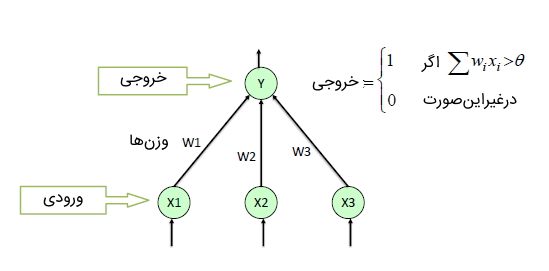
مزیت مدل پرسپترون این است که به دلیل سادگی، به انجام محاسبات پیچیدهای نیاز ندارد و برای پیادهسازی عملیات منطقی نظیر AND ،OR و NAND مناسب است.
یکی از معایب اصلی این مدل این است که نمیتوان از آن برای دستهبندی دادهها با بیش از دو گروه استفاده کرد و صرفاً این مدل برای دستهبندی دوتایی (Binary) استفاده میشود. همچنین، از این مدل برای تقسیمبندی دادهها به صورت غیرخطی نمیتوان استفاده کرد.
شبکه عصبی پیش خور چیست ؟
شبکه عصبی پیشخور از چندین لایه متوالی تشکیل شده است که هر لایه خروجی خود را در قالب بردار، به لایه بعد منتقل میکند. بر اساس میزان پیچیدگی مسئله، تعداد لایههای پنهان این مدل میتواند یک لایه یا بیش از یک لایه باشد.
در این مدل، جریان دادهها فقط بهصورت یکطرفه اتفاق میافتد. به عبارتی، وزنهای این مدل، استاتیک هستند و دادهها از طریق لایه ورودی، به شبکه وارد میشوند و پس از عبور از لایههای پنهان و اعمال عملیات محاسباتی بر روی آنها، خروجی نهایی در لایه آخر مشخص میشود و دیگر مرحله پس انتشار در این مدل انجام نمیشود.
مزیت شبکه عصبی پیشخور این است که بار محاسباتی کمی دارد و پیادهسازی آن بهسادگی انجام میشود. همچنین، به دلیل آن که مرحله پس انتشار در این مدل رخ نمیدهد، سرعت اجرای مدل بالا است.
مهمترین نقطه ضعف مدل پیشخور، عدم وجود مرحله پس انتشار است که به عنوان یکی از مهمترین مرحله در یادگیری مدلهای یادگیری عمیق محسوب میشود.
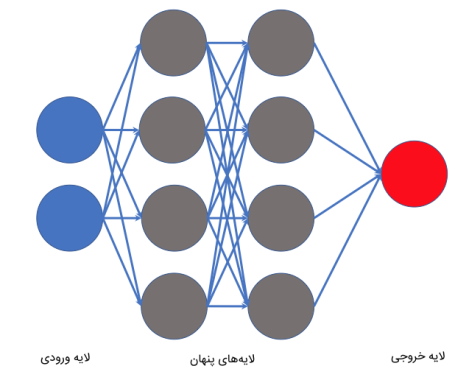
مدل چند لایه پرسپترون چیست ؟
شبکه عصبی چند لایه پرسپترون، ساختاری مشابه با ساختار مدل پرسپترون دارد اما تعداد لایههای پنهان آن بیش از یک لایه است. همچنین، این مدل نوعی شبکه پیشخور محسوب میشود با این تفاوت که در مدل چند لایه پرسپترون، تعداد تمامی گرههای هر لایه با هم برابر است و ارتباط کاملی بین گرههای هر لایه وجود دارد. خروجی هر لایه در قالب بردار، به عنوان ورودی به لایه بعد منتقل میشود. در این مدل، از توابع فعالسازی غیرخطی نظیر Sigmoid ،Tanh ،ReLU و سایر توابع مشابه استفاده میشود. با مدل چند لایه پرسپترون میتوان عملگرهای منطقی NOT ،XOR ،XNOR ،NOR ،AND و OR را پیادهسازی کرد.
مزیت مدل چند لایه پرسپترون این است که از این مدل میتوان برای مدلسازی مسائل غیرخطی استفاده کرد. بهعلاوه، این مدل عملکرد خوبی در مسائلی دارد که میزان حجم دادههای مسئله، کم است.
از معایب این مدل میتوان به پیچیدگی محاسباتی زیاد و زمان محاسبات بالا اشاره کرد. همچنین، در این مدل نمیتوان بهراحتی به میزان تاثیر متغیرهای وابسته بر روی متغیرهای مستقل پی برد.
شبکه عصبی پیچشی چیست ؟
از شبکه عصبی پیچشی برای استخراج ویژگیهایی داده ورودی استفاده میشود. این شبکه دارای دو بخش اصلی به شرح زیر است:
- «لایه پیچشی» (Convolution Layer): در این لایه، فیلتری به منظور استخراج ویژگی بر روی داده ورودی اعمال میشود و سپس نتایج حاصل از این فیلتر، از تابع فعالسازی ReLU عبور کرده تا اعداد منفی حاصل شده، به عدد صفر نگاشته شوند.
- «لایه فشردهساز» (Pooling Layer): ورودی این لایه، خروجی لایه پیچشی است و از آن به منظور کاهش تعداد پارامترهای شبکه استفاده میشود.
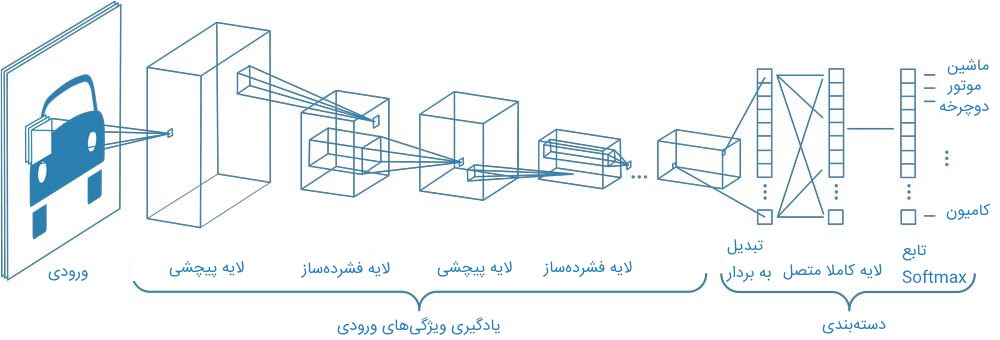
مزیت شبکه عصبی پیچشی در این است که از آن میتوان به منظور استخراج ویژگی با ابعاد پایین استفاده کرد. همچنین، زمانی که از این شبکه به منظور استخراج ویژگی از دادهها در مسئله خاصی استفاده میشود، در مقایسه با سایر مدلها از دقت بالاتری برخوردار است. بهعلاوه، تعداد پارامترهای این شبکه در مقایسه با سایر شبکهها کمتر است. بدینترتیب، این شبکه به محاسبات کمتری در حین یادگیری احتیاج دارد.
یکی از معایب اصلی این شبکه این است که برای رسیدن به دقت بالا، به حجم زیادی از داده آموزشی احتیاج دارد. جمعآوری و تهیه دادههای برچسب خورده نیازمند هزینه مالی و هزینه زمانی بالایی است. علاوهبراین، هرچقدر از تعداد لایههای میانی بیشتری در این شبکه استفاده شود، زمان یادگیری شبکه به مراتب بیشتر میشود.
شبکه عصبی تابع شعاعی پایه چیست ؟
ساختار شبکه عصبی تابع شعاعی پایه، مشابه با ساختار شبکه چند لایه پرسپترون است و تنها تفاوتی که با مدل چند لایه پرسپترون دارد، محدودیت در تعداد لایههای میانی آن است. تعداد لایه میانی شبکه عصبی تابع شعاعی پایه، یک عدد است و از آن به منظور دستهبندی غیرخطی ورودیها استفاده میشود.
شبکه عصبی تابع شعاعی پایه به منظور دستهبندی دادهها، از معیار میزان شباهت داده جدید با مجموعه دادههای آموزشی استفاده میکند. به عبارتی، لایه میانی این شبکه از نورونهایی تشکیل شده است که ویژگیهای دادههای آموزشی را در خود ذخیره میکنند. زمانی که داده جدیدی به مدل وارد میشود تا گروه آن مشخص شود، مدل با محاسبه «فاصله اقلیدسی» (Euclidean Distance) داده نسبت به دادههای آموزشی، نزدیکترین گروه را برای داده مشخص میکند.
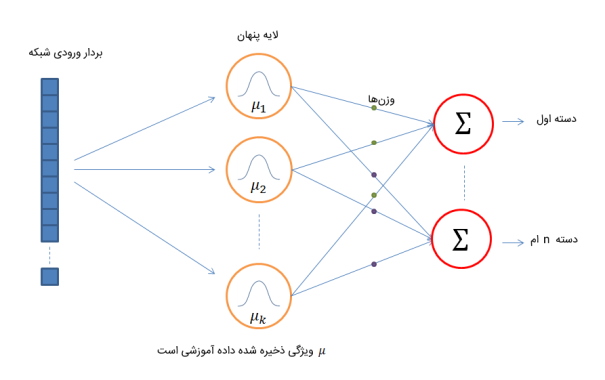
کم بودن تعداد لایههای شبکه عصبی تابع شعاعی پایه به عنوان مهمترین مزیت این شبکه محسوب میشود که بار محاسباتی یادگیری شبکه را کاهش میدهد. افزونبراین، با اینکه این مدل تنها دارای یک لایه پنهان است، اما میتوان از آن برای دستهبندی دادهها با بیش از دو کلاس نیز استفاده کرد.
با وجود اینکه یادگیری شبکه عصبی تابع شعاعی پایه بهسرعت اتفاق میافتد و بار محاسباتی مدل کم است، با این حال روند دستهبندی دادهها با سرعت پایین انجام میشود زیرا این مدل برای تشخیص گروه داده جدید، بر پایه سنجش میزان شباهت آن با دادههای آموزشی خود عمل میکند. بدینترتیب، سرعت عملکرد این مدل در مقایسه با سرعت عملکرد شبکه عصبی چند لایه پرسپترون بیشتر است.
شبکه عصبی بازگشتی چیست ؟
از شبکه عصبی بازگشتی در مسائلی نظیر ترجمه ماشین یا «برچسبگذاری اجزای کلام» (Part-Of-Speech Tagging | POS Tagging) استفاده میشود که ترتیب در دادهها اهمیت داشته باشد. به عنوان مثال، در تشخیص اجزای کلام در جملات، نحوه قرارگیری فاعل، مفعول، فعل و سایر اجزای تشکیلدهنده جمله اهمیت دارد.
برخلاف سایر مدلها، این نوع شبکه عصبی دارای حافظهای است که اطلاعات دادههای قبلی خود را ذخیره میکند. در شبکههای عصبی قبلی، فرض بر این بود که اجزای ورودی مدل هیچ گونه وابستگی به یکدیگر ندارند. اما خروجی مدل بازگشتی، به ورودیهای قبلی آن وابسته است. مدلهای بازگشتی دارای انواع دیگری نظیر مدل «حافظه طولانی کوتاه مدت» (Long Short-Tem Memory | LSTM) و مدل «واحد بازگشتی گیت» (Gated Recurrent Unit | GRU) هستند که به لحاظ ساختار درونی، تفاوت جزئی با یکدیگر دارند.
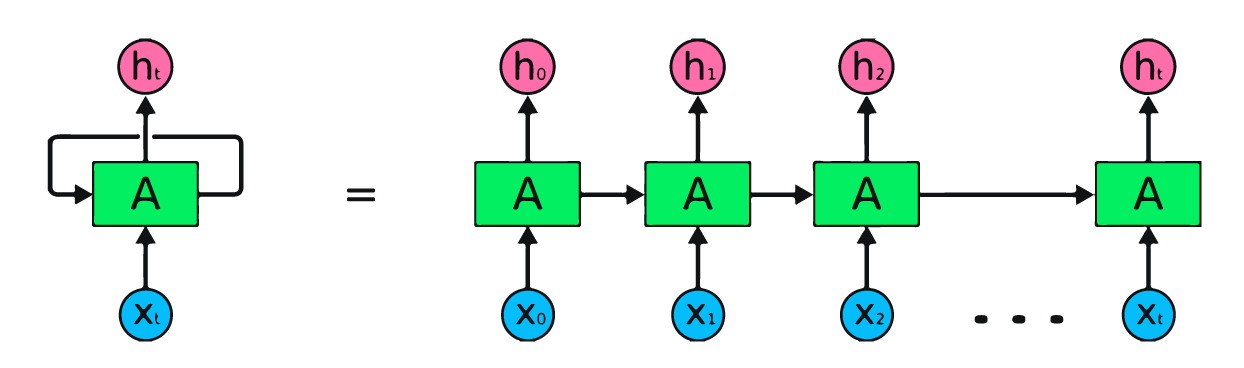
مهمترین و اصلیترین مزیت شبکه عصبی بازگشتی، ویژگی بازگشتی بودن آن است که این قابلیت را به مدل میدهد تا ترتیب ورودیهای خود را در حافظه خود نگه دارد و به نوعی، وابستگی دادهها را در زمان یادگیری مدنظر قرار دهد.
دو مورد از اصلیترین نقاط ضعف شبکههای عصبی بازگشتی، «محوشدگی گرادیان» (Vanishing Gradient) و «انفجار گرادیان» (Exploding Gradient) است. زمانی مسئله محوشدگی گرادیان اتفاق میافتد که تعداد لایههای شبکه عصبی زیاد باشد که در پی آن، مقدار گرادیان تابع هزینه به صفر نزدیکتر میشود. در پی این رخداد، فرآیند یادگیری شبکه عصبی دشوار است. کوچک بودن خروجی مشتق تابع در شبکههای عمیق در طی مرحله پس انتشار، باعث میشود مقدار گرادیان بهصورت نمایی کاهش پیدا کند و به عدد صفر نزدیک شود. همین امر سبب میشود پارامترهای شبکه عصبی نظیر مقادیر وزنها و بایاسها در لایههای ابتدایی شبکه بهروزرسانی نشوند و بنابراین یادگیری شبکه بهدرستی انجام نگیرد.
انفجار گرادیان نیز زمانی رخ میدهد که مقادیر گرادیان خطا روی هم انباشته شوند و بدینترتیب این مقادیر، خیلی بزرگ شوند. این مسئله باعث میشود مقدار نهایی وزنها بسیار بزرگ شود که همین امر منجر به ناپایداری شبکه خواهد شد. در برخی مواقع، ممکن است مقادیر بزرگ وزنها باعث «سرریز شدن» (Overflow) وزنها و رسیدن به مقادیر NaN شوند. در پی انفجار گرادیانها، یادگیری شبکه متوقف شده و وزنهای شبکه تغییر نخواهند کرد.

مدل رمزگذار-رمزگشا چیست ؟
مدل رمزگذار-رمزگشا از دو شبکه عصبی بازگشتی ساخته میشود. اولین مدل بازگشتی، دادههای ورودی را کدگذاری میکند و دومین مدل بازگشتی، خروجی مدل بازگشتی نخست را کدگشایی میکند. از این مدل برای مسائلی نظیر ترجمه ماشین، «سیستمهای پرسش و پاسخ» (Question Answering Systems) و «چتبات» (Chatbot) استفاده میشود که طول ورودی شبکه با طول خروجی شبکه یکسان نیست.
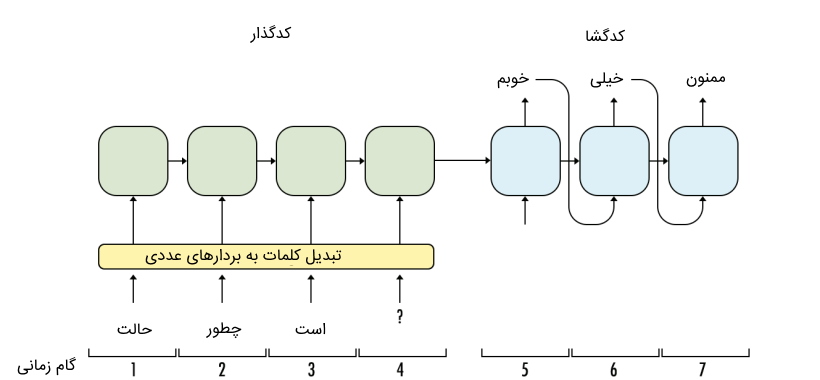
مزیت اصلی مدل رمزگذار-رمزگشا این است که با استفاده از آنها میتوان خروجیهایی تولید کرد که طول آنها وابسته به طول ورودی مدل نباشند. بدینترتیب، این مدل محدودیت مدلهای بازگشتی را ندارند.
مشکل اصلی مدل رمزگذار-رمزگشا در این است که هر چقدر تعداد لایههای این شبکه بیشتر باشد، بار محاسباتی یادگیری شبکه بیشتر میشود. همچنین، چنانچه از این مدل در مسئله ترجمه ماشین استفاده شود و ورودی این مدل، از جملات طولانی تشکیل شده باشد، ممکن است مدل با مسئله محوشدگی گرادیان روبهرو شود.
شبکه عصبی ماژولار چیست ؟
شبکه عصبی ماژولار از چندین شبکه عصبی به عنوان ماژول ساخته میشود که هر کدام از این ماژولها بخشی از مسئله را یاد میگیرند. در نهایت، خروجیهای هر یک از این شبکههای عصبی با یکدیگر یکپارچه شده تا خروجی نهایی مدل حاصل شود.
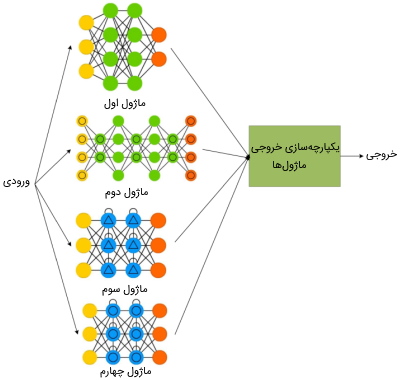
یکی از مزیتهای اصلی مدلهای ماژولار این است که در این روش، میتوان یک مسئله پیچیده را به زیر بخشهای سادهتر تقسیم کرد تا به یادگیری مدل کمک شود. همچنین، در این روش میتوان از شبکههای عصبی مختلفی برای ماژولها استفاده کرد. بهعلاوه، در این روش میتوان یادگیری چندین وظیفه (Task) مختلف را بهطور همزمان پیش برد.
مدلهای ماژولار عملکرد ضعیفی در حل مسائلی دارند که باید هدف متحرکی را در فضای مشخص شده شناسایی کنند. مسائلی نظیر شناسایی شئ متحرک در فضا، کنترل ترافیک، دنبال کردن هدف در بازیهای کامپیوتری از این دست مسائل هستند.
جمعبندی
امروزه، هوش مصنوعی یکی از پرمتقاضیترین رشتهها و حوزههای کاری محسوب میشود و کاربردهای وسیعی در تمامی جنبههای مختلف زندگی بشر دارد. در مقاله حاضر سعی شد تا در ابتدا به تفاوت میان حوزه یادگیری عمیق و یادگیری ماشین پرداخته شود و سپس اصلیترین مفهوم حوزه یادگیری عمیق، یعنی شبکه عصبی توضیح داده شود و به کاربرد آن در حیطههای مختلف اشاره شود. همچنین، به توضیح ساختار جزئی شبکه عصبی و در نهایت به معرفی رایجترین و پرکاربردترین انواع شبکههای عصبی پرداخته شد و مزایا و معایب هر یک از آنها مورد بررسی قرار گرفت.









بسیار ممنون از توضیح روان و گویا تون.
perfect
عالی.مطالب جالب و شیوا بود. تشکر