



شبکه عصبی پیچشی (Convolutional Neural Networks) – به زبان ساده
«هوش مصنوعی» (Artificial Intelligence) در سالهای اخیر شاهد رشد بسیار بزرگ و مهمی در پر کردن شکاف بین تواناییهای انسان و ماشین بوده است. پژوهشگران و علاقمندان به این حوزه، روی جنبههای گوناگون آن کار میکنند تا اتفاقات ویژهای به وقوع بپیوندد. یکی از این جنبهها، «بینایی ماشین» (Machine Vision) است. هدف این زمینه قادر ساختن ماشینها به دیدن جهان به صورتی است که انسانها میبینند، و درک آن به گونهای مشابه با انسانها و حتی استفاده از دانش حاصل از این بینایی برای وظایف بسیاری مانند «بازشناسی تصویر و ویدئو» (Image & Video recognition)، «تحلیل تصویر» (Image Analysis)، «دستهبندی تصاویر» (Image Classification)، «سیستمهای توصیهگر» (Recommendation Systems) و «پردازش زبان طبیعی» (Natural Language Processing) است. پیشرفتهای حاصل شده در «بینایی کامپیوتری» (Computer Vision) با ظهور «یادگیری عمیق» (Deep Learning) در طول زمان ایجاد و کامل شده و در درجه اول برمبنای الگوریتم خاصی به نام «شبکه عصبی پیچشی» (Convolutional Neural Network) بوده است.




مقدمه
«شبکه عصبی پیچشی» (Convolutional Neural Network | CNN / ConvNet) یک الگوریتم یادگیری عمیق است که تصویر ورودی را دریافت میکند و به هر یک از اشیا/جنبههای موجود در تصویر میزان اهمیت (وزنهای قابل یادگیری و بایاس) تخصیص میدهد و قادر به متمایزسازی آنها از یکدیگر است.
در الگوریتم ConvNet در مقایسه با دیگر الگوریتمهای دستهبندی به «پیشپردازش« (Pre Processing) کمتری نیاز است. در حالیکه فیلترهای روشهای اولیه به صورت دستی مهندسی شدهاند، شبکه عصبی پیچشی (ConvNets)، با آموزش دیدن به اندازه کافی، توانایی فراگیری این فیلترها/مشخصات را کسب میکند.

معماری ConvNet مشابه با الگوی اتصال «نورونها» (Neurons) در مغز انسان است و از سازماندهی «قشر بصری» (Visual Cortex) در مغز الهام گرفته شده است. هر نورون به محرکها تنها در منطقه محدودی از میدان بصری که تحت عنوان «میدان تاثیر» (Receptive Field) شناخته شده است پاسخ میدهد. یک مجموعه از این میدانها برای پوشش دادن کل ناحیه بصری با یکدیگر همپوشانی دارند.
چرا شبکه عصبی پیچشی به جای شبکه عصبی پیشخور؟

یک تصویر چیزی به جز یک ماتریس با مقادیر پیکسلها نیست. بنابراین چرا تصویر را مسطح نکرده (با تبدیل ماتریس ۳×۳ به بردار ۱×۹ در این مثال) و به یک «پرسپترون چند لایه» (Multilayer Perceptron | MLP) به منظور انجام دستهبندی خورانده نشود؟ در تصاویر دودویی بسیار پایهای، این روش در انجام پیشبینی کلاسها ممکن است رتبه دقت متوسط را داشته باشد، اما هنگامی که صحبت از تصاویر پیچیده دارای وابستگی میان پیکسلها میشود دقت ندارد یا دقت بسیار کمی دارد.
ConvNet قادر است به طور موفقی وابستگیهای زمانی و فضایی را در یک تصویر با استفاده از فیلترهای مرتبط ثبت کند و همچنین، معماری فیلترگذاری بهتری را روی مجموعه داده تصویر به دلیل کاهش تعداد پارامترهای درگیر و استفاده مجدد از وزنها انجام میدهد. به بیان دیگر، شبکه میتواند برای درک تصاویر پیچیده به طور بهتری آموزش ببیند.

در تصویر بالا، یک شکل RGB وجود دارد که بر اساس پانلهای رنگ - قرمز، سبز و آبی - جداسازی شده است. چنین فضاهای رنگی در تصاویر «سیاه و سفید»، CMYK ،HSV ،RGB و دیگر موارد نیز وجود دارد. میتوان تصور کرد هنگامی که ابعاد غنی، برای مثال (۸K (۷۶۸۰×۴۳۲۰ شوند، کارها چقدر به لحاظ محاسباتی فشرده میشود. نقش ConvNet کاهش تصاویر به شکلی است که پردازش آنها آسانتر و بدون از دست دادن ویژگیهایی باشد که برای انجام یک پیشبینی خوب حیاتی هستند. این مساله هنگامی حائز اهمیت میشود که کاربر قصد طراحی معماری را دارد که صرفا در یادگیری ویژگیها خوب نیست، بلکه برای مجموعه دادههای بزرگ مقیاسپذیر نیز هست.
لایه پیچشی - کرنل
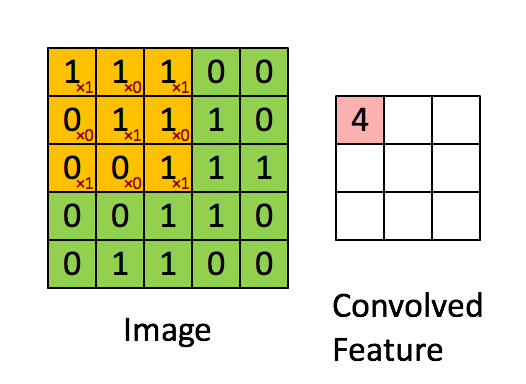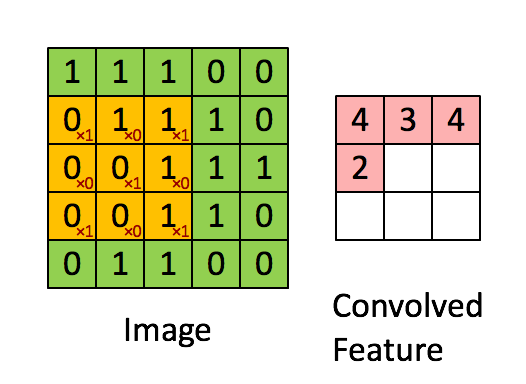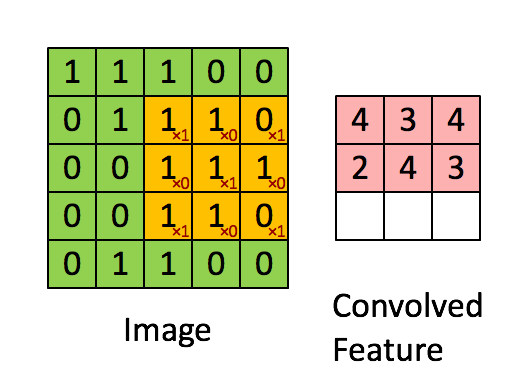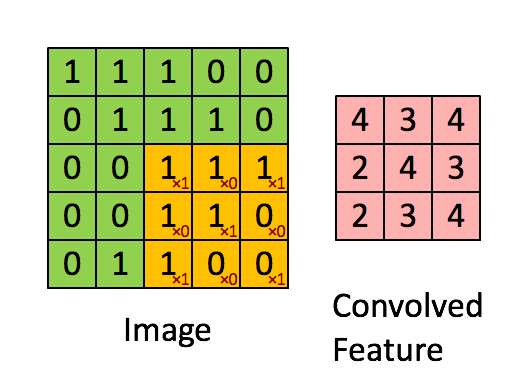
ابعاد تصویر = ۵ (ارتفاع) × ۵ (وسعت) × ۱ (تعداد کانالها، برای مثال RGB)
در ارائه بالا، ناحیه سبز شبیه تصویر ورودی ۱×۵×۵ است. عنصری که در نگهداری عملیات پیچشی در اولین بخش از لایه پیچشی قرار دارد کرنل/فیلتر، K نامیده میشود و به رنگ زرد نشان داده شده است. اکنون، K به عنوان یک ماتریس ۱×۳×۳ فراخوانی میشود.
کرنل ۹ بار شیفت پیدا میکند زیرا Stride Length = 1 (یعنی Non-Strided)، هر بار عملیات ضرب ماتریس بین K و P قسمت از تصویر که هسته در آن شناور (Hover) است انجام میشود.

فیلتر از راست با مقدار طول گام مشخصی حرکت میکند تا به طول کامل عرض را «تجزیه» (Parse) کند. در ادامه مسیر، به پایین و آغاز سمت چپ تصویر رفته و با مقدار گام مشابهی حرکت میکند و این فرآیند را تا هنگامی که کل تصویر را بپیماید ادامه میدهد.
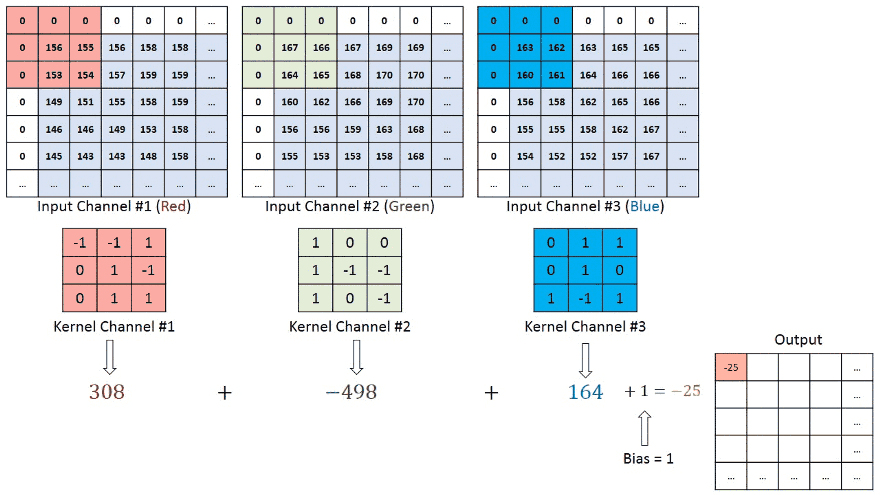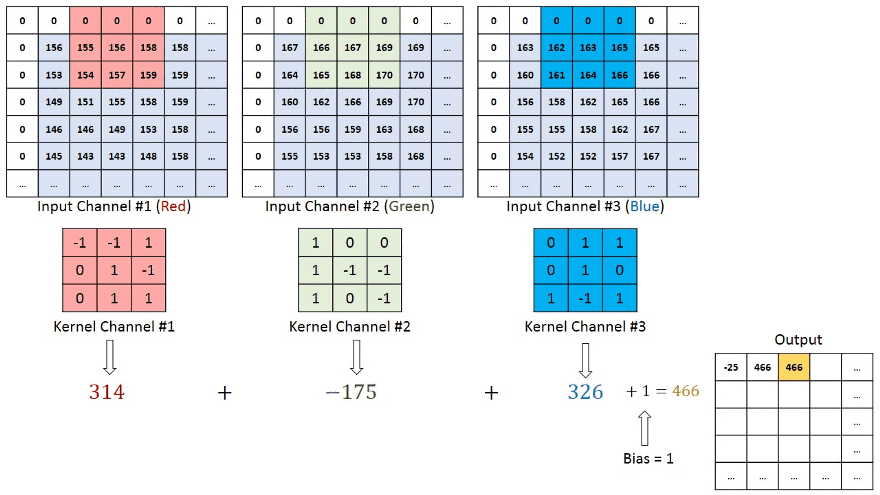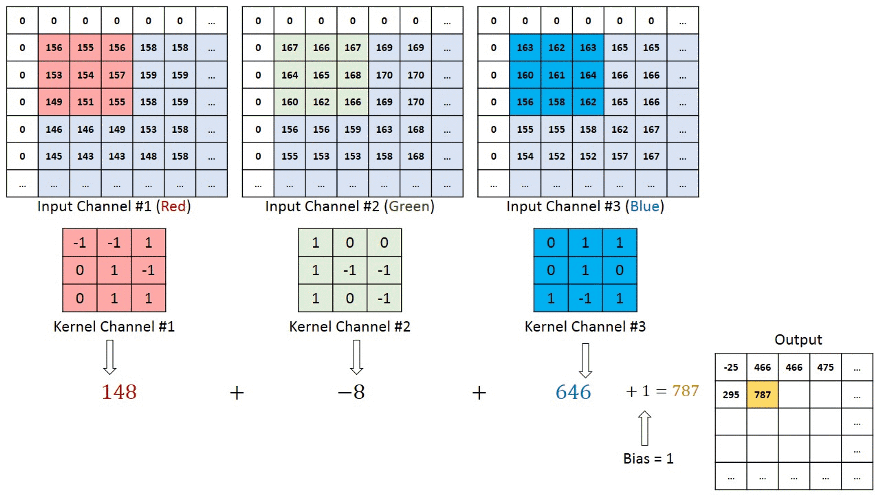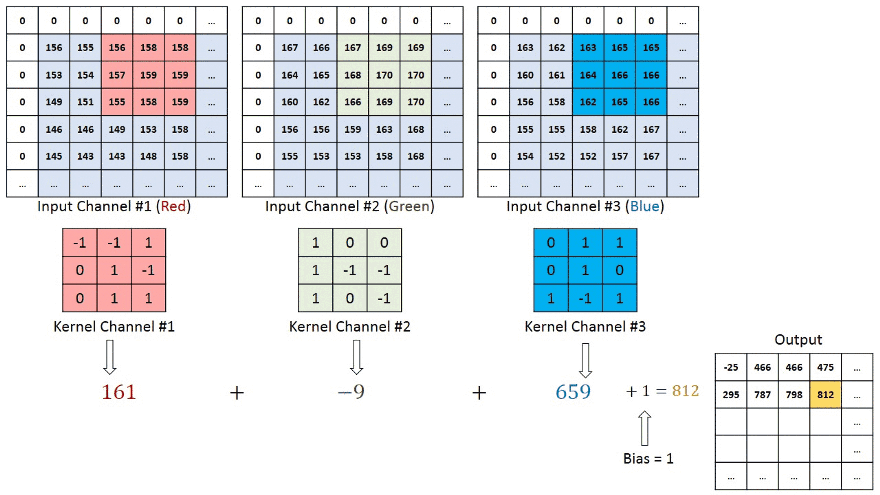
در تصاویری با چندین کانال (برای مثال تصاویر RGB)، کرنل دارای عمق مشابهی با تصویر ورودی میشود. ضرب ماتریسها بین پشته Kn و In (به صورت [K1, I1]; [K2, I2]; [K3, I3]) انجام میشود و نتایج با بایاس جمع میشوند تا یک ویژگی کانال با عمق یک پیچانده شده را در خروجی ارائه کند.
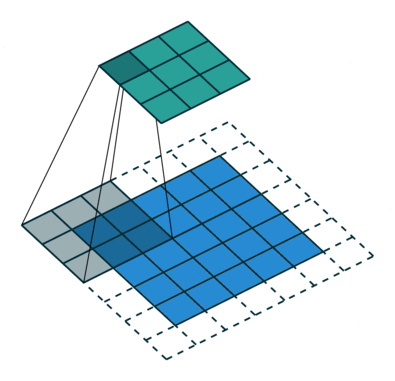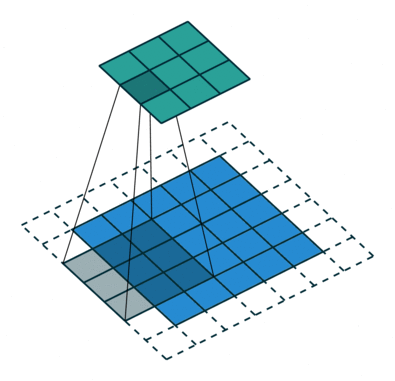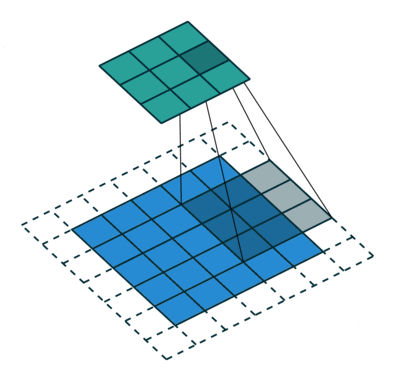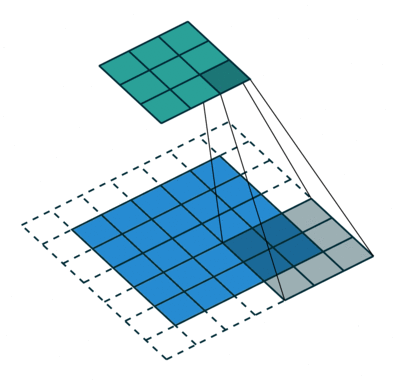
هدف عملیات پیچش، استخراج ویژگیهای سطح بالا مانند «لبهها» (edges) از تصاویر ورودی است. ConvNets نیاز دارد که صرفا به یک «لایه پیچشی» (Convolutional Layer) محدود نشود. به طور معمول، اولین ConvLayer مسئول ثبت ویژگیهای سطح پایین مانند لبهها، رنگ، جهت گرادیان و دیگر موارد است. با لایههای افزوده، معماری با ویژگیهای سطح بالا نیز سازگار میشود، و شبکهای را به دست میدهد که دارای درک کاملی از تصاویر موجود در مجموعه داده به صورتی است که انسانها تصاویر را درک میکنند. دو نوع نتیجه برای عملیات وجود دارد، یکی برای آنکه ابعاد ویژگی پیچانده شده در مقایسه با ورودی کاهش پیدا میکند، و دیگری آنکه ابعاد افزایش پیدا میکند یا برابر با مقدار پیشین باقی میماند. این کار با اعمال Valid Padding در حالت پیشین یا Same Padding در حالت بعدی انجام میشود.
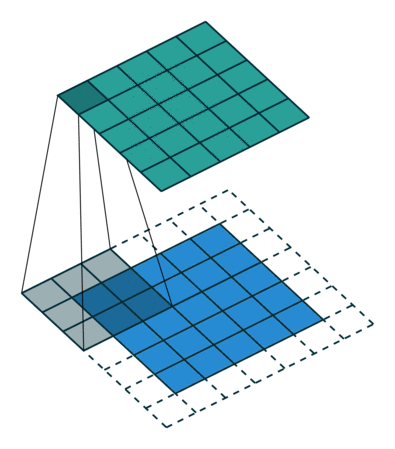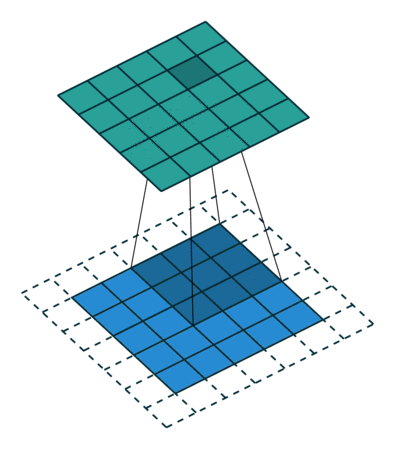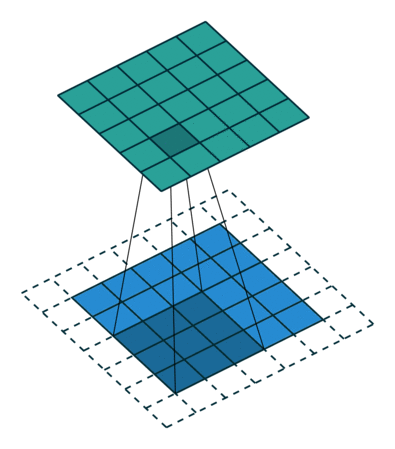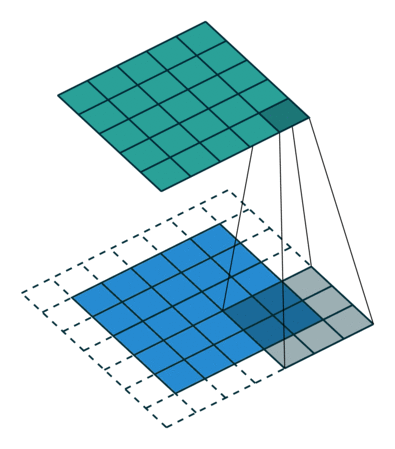
هنگامی که تصویر 5x5x1 به یک تصویر 6x6x1 تقویت میشود و سپس کرنل 3x3x1 بر فراز آن اعمال میشود، ماتریس پیچانده شده به ابعاد 5x5x1 تبدیل میشود. بنابراین آن را Same Padding نامیدهاند. از سوی دیگر، اگر عملیات مشابهی بدون پدگذاری انجام شود، ماتریسی حاصل میشود که دارای ابعاد کرنل (3x3x1) است و به آن Valid Padding گفته میشود. مخزن گیتهاب vdumoulin (+) شامل تعداد زیادی از تصاویر متحرک (Gif) مشابه آنچه در بالا وجود دارد است که به درک بهتر چگونگی پدگذاری و طول گام کمک میکند.
لایه تجمعی
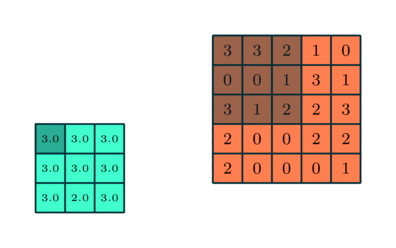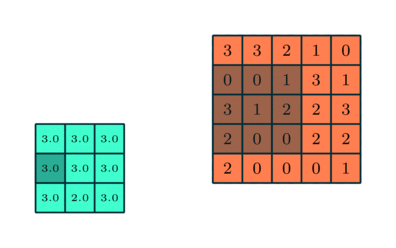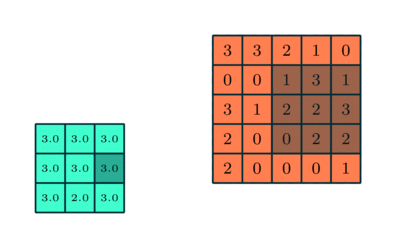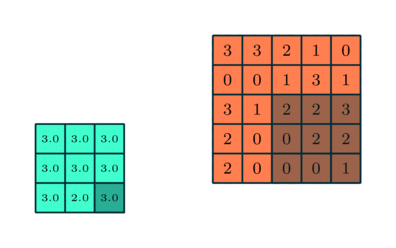
همچون «لایه پیچشی» (Convolutional Layer)، «لایه تجمعی» (Pooling layer) نیز مسئول کاهش سایز فضای ویژگی پیچانده (Convolved) شده است. این کار با هدف کاهش قدرت محاسباتی مورد نیاز برای پردازش دادهها از طریق کاهش ابعاد، انجام میشود. علاوه بر این، برای استخراج ویژگیهای «غالبی» (Dominant) مفید است که چرخش و موقعیت بدون تغییر دارند (ثابت)، بنابراین منجر به حفظ فرآیند آموزش موثر میشوند.
دو نوع تجمع (Pooling) وجود دارد: Max Pooling و Average Pooling. تجمع Max Pooling مقدار بیشینه را از قسمتی از تصویر بازمیگرداند که توسط کرنل پوشش داده شده است. از سوی دیگر، Average Pooling میانگین همه مقادیر را از قسمتی از تصویر باز میگرداند که توسط کرنل پوشش داده شده است.
Max Pooling کار «حذف نویز» (Noise Suppressant) را نیز انجام میدهد. این تجمع (Pooling)، همه فعالسازهای (Activations) نویزی را همزمان رها میکند و همچنین، کار کاهش ابعاد را همراه با حذف نویز انجام میدهد. از سوی دیگر، Average Pooling کار کاهش ابعاد را به عنوان مکانیزمی برای حذف نویز اجرا میکند. بنابراین شاید بتوان گفت که Max Pooling خیلی بهتر از Average Pooling است.

لایه پیچشی و لایه تجمعی باهم از iاُمین لایه از شبکه عصبی پیچشی هستند. بسته به پیچدگی تصاویر، تعداد این لایهها ممکن است برای ثبت جزئیات سطح پایین بیشتر افزایش یابد. پس از حرکت در فرایند بالا، مدل موفق میشود تا ویژگیها را درک کند. در ادامه، به مسطحسازی خروجی نهایی و خوراندن آن به یک شبکه عصبی با قاعده به منظور دستهبندی پرداخته خواهد شد.
دستهبندی -- لایه کاملا متصل (لایه FC)
افزودن یک «لایه کاملا متصل» (Fully-Connected layer) (معمولا) راهی ارزان برای یادگیری ترکیبهای غیر خطی سطح بالای ویژگیها به صورتی است که به وسیله خروجی لایه پیچشی ارائه شد. لایه کاملا متصل در آن فضا یک تابع احتمالا غیر خطی را میآموزد.
اکنون که تصویر ورودی به شکل مناسبی از پرسپترون چند لایه مبدل شد، باید تصویر را در یک بردار ستونی مسطح کرد. خروجی مسطح شده به یک شبکه عصبی پیشخور خورانده میشود و «بازگشت به عقب» (Backpropagation) در هر تکرار از آموزش اعمال میشود.

پس از یک مجموعه از دورهها، مدل قادر به ایجاد تمایز بین ویژگیهای غالب و برخی ویژگیهای مشخص سطح پایین در تصویر و دستهبندی آنها با استفاده از روش دستهبندی «بیشینه همواره» (Softmax) است. معماریهای گوناگونی از شبکه عصبی پیچشی موجود است که نقش کلیدی در ساخت الگوریتمهایی که به «هوش مصنوعی» (Artificial Intelligence) به عنوان یک کل در آینده پیشرو قدرت میبخشند و باید قدرت ببخشند دارد. برخی از این موارد در ادامه بیان شدهاند.
- LeNet
- AlexNet
- VGGNet
- GoogLeNet
- ResNet
- ZFNet

اگر نوشته بالا برای شما مفید بوده، آموزشهای زیر نیز به شما پیشنهاد میشوند:
- مجموعه آموزشهای هوش محاسباتی
- مجموعه آموزشهای شبکههای عصبی مصنوعی
- مجموعه آموزشهای آمار، احتمالات و دادهکاوی
- مجموعه آموزشهای برنامهنویسی پایتون
- معرفی منابع جهت آموزش یادگیری عمیق (Deep Learning) — راهنمای کامل
- معرفی منابع آموزش ویدئویی هوش مصنوعی به زبان فارسی و انگلیس
^^









سلام
توضیحات کاملی بود ممنون از سایتتون.
با سلام و تشکر از ارائه شما
امکان داره در مورد نحوه بررسی داده های تست و برچسب گذاری داده های تست هم توضیح بدید.
ممنون
با سلام و احترام؛
صمیمانه از همراهی شما با مجله فرادرس و ارائه بازخورد سپاسگزاریم.
برای یادگیری بیشتر و بهتر میتوانید از دوره آموزشی زیر استفاده کنید. درس ۱۸ این دوره به موضوع ارزیابی و تست مدل اختصاص داده شده است.
دوره آموزشی فوق یکی از دورههای مجموعه آموزشهای شبکههای عصبی مصنوعی به حساب میآید. ممکن است سایر دورههای ارائه شده در این مجموعه نیز مفید واقع شوند. از طریق لینک زیر میتوانید به صفحه مجموعه فیلمهای آموزش شبکههای عصبی دسترسی داشته باشید:
برای شما آرزوی سلامتی و موفقیت داریم.
ممنون
سلام . خیلی ممنون بابت مطاالب مفیدتون
ممنون.سلامت و موفق باشید
سلام
در مورد
Dilated and causal convolution
توضیح میدین؟
تشکر
Max Pooling همچنین کار «حذف نویز» (Noise Suppressant) را انجام میدهد. این تجمع، همه فعالیتهای نویزی را همزمان ترک میکند و همچنین در طول کاهش ابعاد با حذف نویز اجرا میشود. از سوی دیگر، Average Pooling به سادگی کاهش ابعاد را به عنوان مکانیزم حذف نویز اجرا میکند. بنابراین میتوان گفت که Max Pooling خیلی بهتر از Average Pooling کار میکند.
منظورتون از این بخش رو متوجه نمیشم. امکانش هست بیشتر توضیح بدین؟
با سلام؛
از همراهی شما با مجله فرادرس سپاسگزاریم. ویرایشی در متن برای کمک درک بهتر مطلب، انجام شد. شایان توجه است که برای درک بهتر این پاراگراف، باید دو پاراگراف پیش از این پاراگراف را نیز مجددا مطالعه فرمایید. همچنین، مطالعه مطالب زیر برای درک بهتر این مطلب، به شما پیشنهاد میشود.
انواع شبکه های عصبی مصنوعی — راهنمای جامع
انواع سلول ها و لایه ها در شبکه های عصبی — راهنمای جامع
آشنایی با شبکههای عصبی پیچشی (CNN)
سپاسگزارم.