



تفسیر مدل های یادگیری عمیق در بینایی کامپیوتر – راهنمای جامع
در طی یک دهه اخیر، «یادگیری عمیق» (Deep Learning) و «بینایی کامپیوتر» (Computer Vision)، از جمله داغترین حوزههای تحقیقاتی در «هوش مصنوعی» (Artificial Intelligence) و «یادگیری ماشین» (Machine Learning) محسوب میشوند. بنابراین، توجه روز افزون محققان این دو حوزه به استفاده از مدل های یادگیری عمیق در بینایی کامپیوتر، امری طبیعی است و گام منطقی بعدی، در جهت پیشرفت رو به جلو در حوزه بینایی کامپیوتر محسوب میشود.


هدف از این مطلب، آشنایی خوانندگان و مخاطبان با مفهوم مدل های یادگیری عمیق و نحوه کاربرد آن در پیادهسازی روشهای بینایی کامپیوتر است. به طور ویژه، در این مطلب، هدف ارائه یک چارچوب کاربردی جهت تفسیر مدل های یادگیری عمیق در بینایی کامپیوتر است. به عبارت دیگر، هدف اصلی این مطلب، آشنا کردن مخاطبان و خوانندگان با نحوه مدلسازی تصاویر توسط مدل های یادگیری عمیق در بینایی کامپیوتر و در نهایت، تفسیر خروجیها یا پیشبینیهای انجام شده توسط مدلهای یادگیری است.
در این مطلب، با مفاهیم، تکنیکها و ابزارهای تفسیر مدل های یادگیری عمیق در بینایی کامپیوتر آشنا خواهید شد. به طور خاص، این مطلب بر استفاده از مدلهای «شبکه عصبی پیچشی» (Convolutional Neural Network) در بینایی کامپیوتر تمرکز دارد. برای پیادهسازی مدل های یادگیری عمیق در بینایی کامپیوتر از رویکردی کاربردی استفاده میشود.
همچنین، جهت پیادهسازی و ارزیابی مدل های یادگیری عمیق در «زبان برنامهنویسی پایتون» (Python Programming Language)، از بستههای نرمافزاری نظیر Keras و TensorFlow استفاده خواهد شد. علاوه بر این، از ابزارهای «منبع باز» (Open Source) برای تفسیر نتایج تولید شده و یا تصمیمات اتخاذ شده در این مدلها استفاده میشود.

مقدمه
از یک دهه گذشته تا کنون، هوش مصنوعی در یک دوره «گذار» (Transition) از مقالات تحقیقاتی و پژوهشهای دانشگاهی به کاربردهای تجاری و سازمانی قرار دارد. این دوره گذار کماکان ادامه دارد و هر روز شاهد سرمایهگذاریهای روز افزون شرکتهای تجاری، سازمانهای چند ملیتی و آژانسهای دولتی در این حوزه هستیم. شرکتها و سازمان تجاری فعال در حوزههای گوناگون صنعتی و خدماتی، در حال ساختن کاربردهای مبتنی بر هوش مصنوعی (AI-Powered) در مقیاس وسیع (Large-Scale) هستند.

بسیاری از منتقدان یکپارچهسازی سریع و بدون قاعده هوش مصنوعی و سیستمهای هوشمند (در تمامی جنبههای زندگی انسانی)، اعتقاد دارند که تکیه بیش از حد بر مدلهای هوش مصنوعی، بدون درک درست از نحوه عملکرد و اتخاذ تصمیمات در آنها، ممکن است خطرات جبرانناپذیری بر آینده جامعه بشری داشته باشد. از جمله مهمترین سؤالاتی که ذهن این دسته از محققان را، در زمینه یکپارچهسازی سیستمهای هوشمند و هوش مصنوعی در کاربردهای مختلف به خود مشغول کرده است، این است که:
- آیا میتوان به تصمیمات اتخاذ شده توسط مدلهای هوش مصنوعی اعتماد کرد؟
- یک مدل هوش مصنوعی یا یادگیری ماشین (نظیر مدل های یادگیری عمیق در بینایی کامپیوتر و دیگر حوزهها) چگونه تصمیمات خود را اتخاذ میکنند؟
واقعیتی که بسیاری از فعالان در حوزه هوش مصنوعی، به ویژه «علم داده» (Data Science)، از آن چشمپوشی میکنند این است که تفسیر مدلهای یادگیری ماشین یا یادگیری عمیق در «چرخه تحلیل داده» (Data Analysis/Analytics Cycle)، معمولا از قلم افتاده است. محققان این حوزه، تنها با هدف بهبود عملکرد سیستم، از این دسته از مدلها استفاده میکنند و غالبا، هیچ تلاشی در تفسیر مدلهای پیادهسازی شده و نتایج حاصل از آنها نمیکنند. دلیل چنین موضوعی، درگیری بیش از حد «دانشمندان داده» (Data Scientists) و «مهندسان یادگیری ماشین» (Machine Learning Engineers) با فرایند پیادهسازی مدلهای هوشمند (با عملکرد مطلوب) و «بهکاراندازی» (Deploy) آنها برای کاربردهای مورد نیاز «مشتریان نهایی» (End Users) است.
نمونهای از چنین سیاستهایی در تولید و یکپارچهسازی مدلهای یادگیری هوشمند، برنامه هوش مصنوعی شرکت «فیسبوک» (Facebook) است. شرکت فیسبوک، در اقدامی که نشان از عدم درک دانشمندان داده و مهندسان یادگیری ماشین از نتایج تولید شده به وسیله دو ربات هوش مصنوعی داشت، این برنامه را تا اطلاع ثانوی لغو کرد. این موضوع زمانی اتفاق افتاد که دو ربات هوش مصنوعی تولید شده توسط این شرکت، در حال صحبت کردن با یکدیگر به زبانی بودند که تنها توسط این دو ربات قابل فهم بود.
نیاز به تفسیر و توجیهپذیری در مدلهای هوش مصنوعی و یادگیری ماشین
مدل های یادگیری عمیق در بینایی کامپیوتر نیز از این قاعده مستثنی نیستند. بسیاری از مدل های یادگیری عمیق در بینایی کامپیوتر و حوزههای مرتبط، تنها با هدف ارتقاء عملکرد سیستمهای بینایی کامپیوتر مورد استفاده قرار میگیرند؛ بدون اینکه کوچکترین تلاشی برای درک نحوه عملکرد این مدلها در کاربرد مورد نظر انجام شود. بنابراین، در هنگام پیادهسازی مدل یادگیری ماشین و هوش مصنوعی، به ویژه در کاربردهای تجاری و صنعتی، «دقت» (Accuracy) یک مدل، مهمترین عامل در موفقیت یا عدم موفقیت محصول یا سرویس مبتنی بر هوش مصنوعی محسوب نخواهد بود.

مدیران شرکتها و کاربران نهایی (افراد شاغل و دخیل در تصمیمات سازمانی)، از توسعهدهندگان چنین سیستمهایی انتظار دارند که «عدالت» (Fairness)، «پاسخگویی» (Accountability) و «شفافیت» (Transparency) چنین سیستمهایی، در حل «مسائل جهان واقعی» (Real-World Applications) برای آنها تشریح شود. معیار عدالت، جوابگویی و شفافیت در طراحی و پیادهسازی سیستمهای هوشمند، به شرح زیر است:
- معیار دقت، پاسخ به این سؤال مهم است که چه عواملی در تولید پیشبینیهای مدل تأثیرگذار است؟
- این امکان باید برای مدیران و کاربران نهایی فراهم شود تا در مورد ویژگیهای مشخصه مدل پیادهسازی شده پرس و جو انجام دهند. به عبارت دیگر، مدیران و کاربران نهایی باید قادر باشند تا درک درستی از نحوه تعامل «ویژگیهای نهان» (Latent Features) سیستم (فرایندهای پشت صحنه)، در جهت تولید یک تصمیم سازمانی پیدا کنند. همچنین، باید این امکان برای مدیران و کاربران نهایی فراهم آید تا ویژگیهای مهم و تأثیرگذار را در شکلگیری سیاستهای تصمیمگیری در مدل نهایی شناسایی کنند. چنین شاخصهای، عدالت مدل را در حل مسائل جهان واقعی تضمین میکند.
- بسیار حیاتی است که مشخص شود چرا مدل، یک تصمیم خاص در جهت حل مسأله مورد نظر اتخاذ کرده است؟
- توسعهدهندگان مدلهای هوش مصنوعی و یادگیری ماشین باید قادر باشند که دلیل اهمیت برخی از ویژگیهای کلیدی در سیاستهای تصمیمگیری مدل هوشمند را «توجیه» (Justify) و «صحتسنجی» (Verify) کنند. چنین شاخصهای، «قابل اعتماد بودن» (Reliability) و پاسخگویی مدل را در حل مسائل جهان واقعی تضمین میکند.
- در نهایت، توسعهدهنده باید قادر باشند به این سؤال پاسخ دهند که چگونه میتوان به پیشبینیهای انجام شده توسط مدل اعتماد کرد؟
- توسعهدهندگان، مدیران و کاربران نهایی، باید قادر باشند تا هر «نمونه دادهای» (Data Sample) و نحوه انجام پیشبینی توسط مدل را روی این نمونه ارزیابی و صحتسنجی کنند. چنین کاری به مدیران و کاربران نهایی اجازه میدهد تا درک درستی از نحوه عملکرد سیستم داشته باشند و از همه مهمتر، برای آنها مشخص میکند که آیا مدل پیادهسازی شده، مطابق با انتظارات عمل میکند یا نه. چنین شاخصهای، شفافیت مدل را در حل مسائل جهان واقعی تضمین میکند.
نکته جالبی که در اینجا باید اشاره شود این است که هماکنون، شاخهای از حوزه تحقیقات علمی به نام «هوش مصنوعی توجیهپذیر » (Explainable Artificial Intelligence | XAI) وجود دارد. هدف این حوزه تحقیقاتی، تولید مدلهای هوش مصنوعی و یادگیری ماشین است که از یک سو، توجیهپذیری بیشتری نسبت به مدلهای هوش مصنوعی و یادگیری ماشین مرسوم دارند و از سوی دیگر، عملکرد (بر حسب معیارهایی نظیر دقت، صحت و سایر موارد) مطلوبی در کاربردهای جهان واقعی از خود نشان میدهند. همچنین، کاربران سیستمهای هوش مصنوعی توجیهپذیر باید قادر باشند تا درک درستی از نحوه عملکرد، ارزیابی و صحتسنجی مدلهای هوش مصنوعی و یادگیری ماشین پیادهسازی شده پیدا کنند.

شبکههای عصبی پیچشی
یکی از مهمترین مدلهای یادگیری عمیق برای بینایی کامپیوتر و کاربردهای آن در حوزههای مرتبط، شبکههای عصبی پیچشی هستند.
شبکههای عصبی پیچشی، شامل مجموعهای از «لایههای کانولوشن» (Convolution Layer) و «لایههای تجمعی» (Pooling Layer) هستند که مدل یادگیری عمیق را قادر میسازند تا ویژگیهای مرتبط (جهت مدلسازی و تصمیمگیری) را از «دادههای بصری» (Visual Data) نظیر تصاویر استخراج کنند.
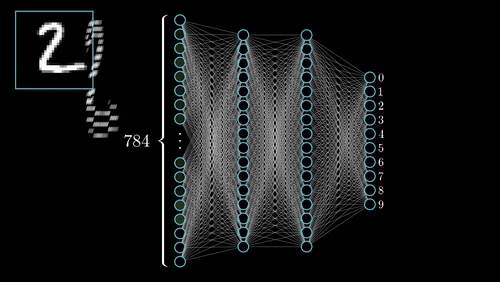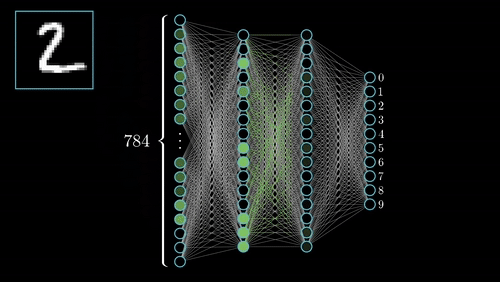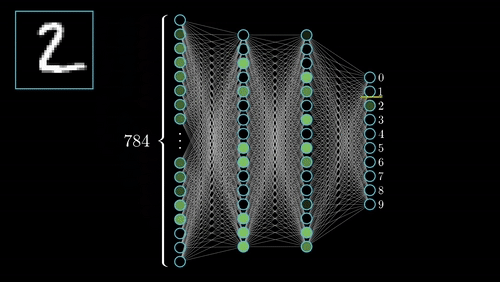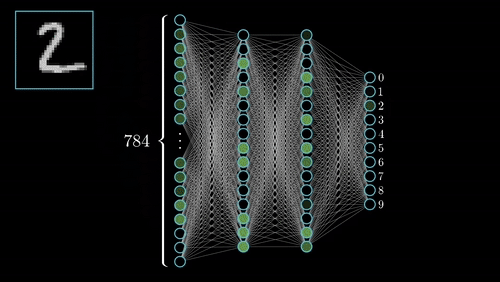
به دلیل وجود چنین «معماری چند لایهای» (Multi-Layer Architecture) در شبکههای عصبی پیچشی، این شبکهها قادر به یادگیری «سلسله مراتبی» (Hierarchical) قدرتمند از ویژگیها در تصویر خواهند بود. این دسته از ویژگیهای یادگیری شده، نسبت به تغییرات «مکانی» (Spatial Invariant)، «چرخشی» (Rotation Invariant) و «انتقالی» (Translation Invariant) حساس نیستند (یا به عبارت دیگر، این دسته از روشها نسبت به این عوامل مکانی، چرخشی و انتقالی تغییر ناپذیر هستند).

فرایندهای کلیدی در پیادهسازی شبکههای عصبی پیچشی، در شکل بالا نمایش داده شدهاند. هر تصویر را میتوان در قالب «تانسوری» (Tensor) از مقادیر پیکسلی آن نمایش داد.

لایههای کانولوشن در شبکههای عصبی پیچشی، نقش مهمی در استخراج ویژگیها از تصاویر دارند (در این حالت، «فضای ویژگی» (Feature Space) شکل خواهد گرفت). لایههای «سطحیتر» (Shallower) یا لایههای نزدیک به لایه ورودی، برای یادگیری ویژگیهای بسیار عمومی در تصویر نظیر «لبه» (Edge)، «گوشه» (Corner) و سایر موارد مورد استفاده قرار میگیرند. لایههای عمیقتر یا لایههای نزدیکتر به لایه خروجی، «ویژگیهای بسیار خاص» (Very Specific Features) مربوط به تصویر را ورودی را یاد میگیرند.
برخی از مهمترین ویژگیهای یک شبکه عصبی پیچشی در ادامه آمده است:
- شبکههای عصبی پیچشی، از یک معماری چند لایهای جهت یادگیری ویژگیهای «مکانی-زمانی» (Spatial-Temporal) سلسلهمراتبی استفاده میکنند.
- لایههای کانولوشن در شبکههای عصبی پیچشی، از «فیلترهای کانولوشن» (Convolution Filters) برای ساختن فضای ویژگی (که به آنها «نقشههای ویژگی» (Feature Maps) نیز گفته میشود) استفاده میکنند.
- لایه تجمعی در شبکه عصبی پیچشی، نقش مهمی در کاهش ابعاد فضای ویژگی، پس از عملیات لایه کانولوشن دارد.
- همانند «شبکههای عصبی مصنوعی» (Artificial Neural Networks) مرسوم، از «توابع فعالسازی غیرخطی» (Non-Linear Activation Functions) در لایههای مختلف شبکه عصبی پیچشی استفاده میشود.
- در شبکههای عصبی پیچشی، میتوان از لایههای (Dropout) یا (BatchNormalization) برای جلوگیری از «بیشبرازش» (OverFitting) مدل استفاده کرد.
- «لایههای کاملا متصل» (Fully-Connected Layers) در شبکههای عصبی پیچشی، خروجی لایههای قبل را دریافت و به مقادیر پیشبینی (میزان تعلق هر نمونه به کلاسهای مختلف موجود در دادهها) تبدیل میکنند.

از آنجایی که هدف این مطلب، آشنایی با نحوه مدلسازی و درک تصاویر توسط مدل های یادگیری عمیق در بینایی کامپیوتر است، آموزش مدل شبکه عصبی پیچشی از «پایه» (Scratch) توضیح داده نخواهد شد. در عوض، در این مطلب (و در مثال ارائه شده در ادامه)، از قدرت مدلهای شبکه عصبی پیچشی «از پیش آموزش داده شده» (Pre-Trained Model) و مفهوم «یادگیری انتقال» (Transfer Learning) استفاده میشود.

در این مطلب، از یک مدل شبکه عصبی پیچشی از پیش آموزش داده شده، به نام مدل VGG-16، استفاده شده است. این مدل، روی «مجموعه داده» (Datast) بسیار بزرگ و متشکل از تصاویر گوناگون در دستهبندی های مختلف آموزش دیده شده است. مجموعه دادهای که برای آموزش این شبکه عصبی پیچشی مورد استفاده قرار گرفته است، مجموعه داده (Imagenet) نام دارد. این مدل، نمایش بسیار جامع و خوبی از فضای ویژگی مرتبط با بیش از 1 میلیون تصویر (دستهبندی شده در 1000 کلاس مختلف) را یاد گرفته است.
بنابراین با در نظر گرفتن ویژگیهای ذکر شده، مدل از پیش آموزش داده شده، سلسلهمراتبی بسیار قدرتمندی از ویژگیها را یاد گرفته است. از این مدل میتوان به عنوان روشی قوی جهت «استخراج ویژگی» (Feature Extraction) از دادههای تصویری و انجام پیشبینی در مورد تصاویر جدید استفاده کرد. در نتیجه، مدل آموزش دیده شده، مدل بسیار مناسبی جهت استفاده در کاربردهای بینایی ماشین محسوب میشود.
تفسیر مدلهای شبکه عصبی پیچشی
شبکههای عصبی مصنوعی، از جمله روشهایی هستند که به «مدلهای جعبه سیاه» (Black Box Models) معروف هستند. در این دسته از روشها، کاربر فقط از تعداد ورودیها، معماری شبکه و تعداد خروجیهای قابل تولید خبر دارد؛ اما از مکانیزمهای استفاده شده جهت تبدیل ورودیها به خروجیها و چگونگی تولید پیشبینیهای نهایی مرتبط با دادههای ورودی (پیشبینی دستهبندی یا کلاس نمونههای جدید) اطلاعی ندارد. شبکههای عصبی پیچشی نیز از این قاعده مستثنی نیستند.

سؤالی که ممکن است ذهن مخاطبان و خوانندگان این مطلب را به خود مشغول کند این است که آیا راهی برای رمزگشایی جعبه سیاه شبکههای عصبی وجود دارد؟ به عبارت دیگر، آیا روشی وجود دارد که بتوان از طریق آن، مکانیزمهای درونی شبکههای عصبی را رمزگشایی کرد و با سازوکارهای تعبیه شده جهت درک تصویر توسط شبکههای عصبی مصنوعی آشنا شد؟.
برای تفسیر تصمیمات اتخاذ شده توسط مدل های یادگیری عمیق در بینایی ماشین و کاربردهای مرتبط، مجموعهای از تکنیکها و ابزارها طراحی شدهاند. در ادامه، برخی از مهمترین تکنیکهای توسعه داده شده جهت تفسیر خروجیها یا پیشبینیهای انجام شده توسط مدل های یادگیری عمیق در بینایی ماشین معرفی شدهاند:
- روش SHAP Gradient Explainer: در این روش، ایدههای موجود در تکنیکهایی نظیر «گرادیانهای یکپارچه» (Integrated Gradients)، روش «توضیحات جمعی شیپلی» (SHapley Additive exPlanations | SHAP) و روش SmoothGrad در یک معادله «امید ریاضی» (Expected Value | مقدار مورد انتظار) با هم ترکیب میشوند تا فرایند تبدیل ورودیها به خروجیها (در مدل های یادگیری عمیق در بینایی کامپیوتر) تفسیر شود.
- روش «مصورسازی لایههای فعالسازی» (Visualizing Activation Layers): در این روش، نحوه تبدیل ورودیهای شبکه عصبی (تصاویر نمونه) به خروجی مناسب در لایههای فعالسازی، نمایش داده میشود. این دسته از روشها برای کاربر مشخص میکنند که کدام یک از «نقشههای ویژگیها» (Feature Maps) در هر یک از لایههای مدل فعال میشوند و اینکه تمرکز مدل روی کدام دسته از ویژگیهای موجود در تصویر ورودی قرار دارد.
- روش «حساسیت به همپوشانی» (Occlusion Sensitivity): در این روش، از طریق همپوشانی یا مخفی کردن بخشهایی از تصویر ورودی، در یک فرایند تکراری، میزان تأثیرگذاری بخشهای مختلف یک تصویر در خروجی (پیشبینی) تولید شده توسط شبکه عصبی محاسبه میگردد.
- روش Grad-Cam: در این روش، از طریق بررسی گرادیانهای پس انتشار شده (انتشار داده شده در جهت عکس جریان اطلاعاتی شبکه عصبی) به سمت «نقشههای فعالسازی کلاسی» (Class Activation Maps)، میزان تأثیرگذاری بخشهای مختلف یک تصویر در خروجی (پیشبینی) تولید شده توسط شبکه عصبی محاسبه میگردد.
- روش SmoothGrad: در این روش، از طریق میانگینگیری از «نقشههای حساسیت گرادیانی» (Gradient Sensitivity Maps) مرتبط با یک تصویر ورودی، پیکسلهای مهم و کلیدی در تصویر شناسایی میشوند.
در ادامه، هر کدام از این تکنیکها مورد بررسی قرار میگیرند و خروجی یا پیشبینیهای انجام شده توسط برخی از مدل های یادگیری عمیق در بینایی کامپیوتر (که در پایتون و توسط بستههای Keras و TensorFlow پیادهسازی شدهاند)، به وسیله این دسته از روشها تفسیر میشوند.
روش SHAP Gradient Explainer
در این روش سعی شده است تا ایدههای موجود در روشهایی نظیر گرادیانهای یکپارچه، روش توضیحات جمعی شیپلی و روش SmoothGrad، جهت تفسیر و درک مکانیزمهای موجود در مدل های یادگیری عمیق در بینایی کامپیوتر، با یکدیگر ترکیب شوند. در این تکنیک، با استفاده از «گرادیانهای مورد انتظار» (Expected Gradient) که گسترشی بر روش گرادیانهای یکپارچه محسوب میشود، تصمیمات یا پیشبینیهای تولید شده توسط مدلهای یادگیری عمیق توضیح داده میشوند. روش SHAP Gradient Explainer، جزء روشهای «تخصیص ویژگی» (Feature Attribution) محسوب میشود؛ روشهایی که تاثیر هر یک از ویژگیهای موجود در نمونههای ورودی را، بر پیشبینیهای تولید شده توسط مدلهای یادگیری عمیق در بینایی ماشین میسنجند.
در روش SHAP، بر خلاف روش گرادیانهای یکپارچه، برای مدلسازی «توزیع پسزمینه» (Background Distribution)، از مجموعه دادهای که همجنس دادههای ورودی به سیستم است، برای یادگیری پارامترهای روش و توزیع استفاده میشود. به این مجموعه دادهای، «مجموعه داده پسزمینه» (Background Dataset) گفته میشود. در این مطلب، از بسته نرمافزاری (shap) در زبان برنامهنویسی پایتون، جهت پیادهسازی این تکنیک و تفسیر خروجیها یا پیشبینیهای انجام شده توسط مدل های یادگیری عمیق استفاده شده است.
در ادامه، کدهای لازم برای پیادهسازی این تکنیک روی چند تصویر نمونه، در زبان برنامهنویسی پایتون ارائه شده است. در ابتدا، با استفاده از کدهای زیر، برخی از «وابستگیهای برنامهنویسی» (Programming Dependencies) و توابع لازم برای «مصورسازی» (Visualization) مدل، در محیط برنامهنویسی پایتون «وارد» (Import) میشوند.
در مرحله بعد، یک مدل شبکه عصبی از پیش آموزش داده شده (از نوع شبکه عصبی پیچشی با معماری VGG-16)، در سیستم بارگیری میشود. این مدل، پیش از اینکه برای تفسیر پیشبینیهای انجام شده توسط مدل های یادگیری عمیق در بینایی کامپیوتر مورد استفاده قرار بگیرد، روی مجموعه داده (Imagenet) آموزش خواهد دید. با استفاده از قطعه کد زیر، به راحتی میتوان چنین کاری را در زبان برنامهنویسی پایتون انجام داد:
خروجی این قطعه کد:
پس از اینکه مدل شبکه عصبی پیچشی (آموزش دیده شده) در سیستم بارگیری میشود، از یک مجموعه داده کوچک (همجنس دادههای ورودی) نیز به عنوان داده پسزمینه، جهت یادگیری پارامترهای روش و توزیع پسزمینه استفاده میشود. همچنین، از چهار تصویر نمونه برای تفسیر خروجیها یا پیشبینیهای انجام شده توسط مدل های یادگیری عمیق در بینایی کامپیوتر استفاده میشود.

در ادامه، خروجیها یا پیشبینیهای تولید شده توسط مدل یادگیری عمیق پیادهسازی شده، به ازاء هر کدام از چهار عکس نمونه نمایش داده شده است:
خروجی:
[['n02999410', 'chain'], ['n01622779', 'great_grey_owl'], ['n03180011', 'desktop_computer'], ['n02124075', 'Egyptian_cat']]
در مرحله بعد، خروجی لایه 7اُم شبکه عصبی پیچشی (یکی از لایههای سطحی در مدل شبکه عصبی پیچشی) مصورسازی میشود. هدف از مصورسازی خروجی لایه هفتم شبکه عصبی، نمایش نحوه درک تصاویر در لایههای مختلف شبکههای عصبی پیچشی است. به عبارت دیگر، آنچه که لایههای مختلف شبکههای عصبی پیچشی در تصاویر میبینند و ویژگیهایی که در تصویر شناسایی میکنند، نمایش داده میشود.

همانطور که در شکل قابل مشاهده است، به ازاء هر کدام از چهار تصویر نمونه، دو پیشبینی برتر انجام شده توسط شبکه عصبی پیچشی نمایش داده شده است. به عبارت دیگر، بر اساس پیشبینیهای انجام شده توسط شبکه عصبی پیچشی، هر کدام از تصاویر نمونه، توسط دو کلاسی که بیشترین امتیاز ممکن را کسب کرده باشند، برچسبگذاری میشوند.
همچنین، دلیل تولید چنین پیشبینیهایی توسط شبکه عصبی پیچشی، به وسیله روش SHAP Gradient Explainer توضیح داده شده است (و در نهایت، مصورسازی خواهد شد). بهعنوان نمونه در تصویر سوم، به دلیل اینکه بیشترین پیکسلها یا ویژگیهای کلیدی شناسایی شده توسط شبکه عصبی، در ناحیه حاوی نمایشگر و صفحه کلید قرار دارد، شبکه عصبی پیچشی، خروجی (desktop_computer) را برای این تصویر پیشبینی کرده است. در مرحله بعد، خروجی لایه 14اُم شبکه عصبی پیچشی با معماری VGG-16 (یکی از لایههای عمیق در مدل) مصورسازی میشود.

نکته جالب در مورد خروجیهای تولید شده توسط روش SHAP Gradient Explainer در این مرحله این است که، هر چقدر شدت مقادیر shap بیشتر میشود، مدل های یادگیری عمیق در بینایی کامپیوتر قدرتمندتر عمل میکنند و با درجه اطمینان بالاتری، خروجی را پیشبینی میکنند. همچنین، تراکم پیکسلها یا ویژگیهای کلیدی شناسایی شده در تصویر سوم سبب میشود که تصویر توسط شبکه عصبی پیچشی، در یکی از کلاسهای (screen) یا (desktop_computer) دستهبندی شود. چنین تفسیری در مورد تصاویر دیگر و دو پیشبینی انجام شده برای آنها نیز صدق میکند.
تفسیر مدل های یادگیری عمیق در بینایی کامپیوتر توسط کتابخانه TensorFlow
برای معرفی چهار تکنیک باقیمانده (جهت تفسیر خروجیها یا پیشبینیهای انجام شده توسط مدل های یادگیری عمیق در بینایی کامپیوتر)، باز هم از یک مدل شبکه عصبی پیچشی از پیش آموزش داده شده (توسط کتابخانه TensorFlow) و پلتفرم منبع باز و مجبوب (tf-explain) در پایتون استفاده میشود.
در این بخش، هدف، آشنایی با دیگر تکنیکهای شناخته شده جهت تفسیر پیشبینیهای انجام شده توسط مدل های یادگیری عمیق در بینایی کامپیوتر است.

بارگیری مدل شبکه عصبی پیچشی از پیش آموزش داده شده
در این بخش، جهت تفسیر خروجیهای مدل های یادگیری عمیق در بینایی کامپیوتر، از یکی از پیچیدهترین و پیشرفتهترین شبکههای عصبی پیچشی به نام مدل (Xception) استفاده میشود. بنابر ادعای توسعهدهندگان، این مدل حتی بهتر از مدل معروف (Inception V3) عمل میکند. همانند مرحله قبل، مدل شبکه عصبی پیچشی Xception، روی مجموعه داده imagenet از پیش آموزش داده شده است. در مرحله اول، وابستگیهای برنامهنویسی و مدل شبکه عصبی از پیش آموزش داده شده، در محیط برنامهنویسی پایتون بارگیری میشوند.
خروجی:
# Output Model: "xception" __________________________________________________________________________________________________ Layer (type) Output Shape Param # Connected to ================================================================================================== input_1 (InputLayer) [(None, 299, 299, 3) 0 __________________________________________________________________________________________________ block1_conv1 (Conv2D) (None, 149, 149, 32) 864 input_1[0][0] __________________________________________________________________________________________________ block1_conv1_bn (BatchNormaliza (None, 149, 149, 32) 128 block1_conv1[0][0] __________________________________________________________________________________________________ ... ... __________________________________________________________________________________________________ block14_sepconv2_act (Activatio (None, 10, 10, 2048) 0 block14_sepconv2_bn[0][0] __________________________________________________________________________________________________ avg_pool (GlobalAveragePooling2 (None, 2048) 0 block14_sepconv2_act[0][0] __________________________________________________________________________________________________ predictions (Dense) (None, 1000) 2049000 avg_pool[0][0] ================================================================================================== Total params: 22,910,480 Trainable params: 22,855,952 Non-trainable params: 54,528 __________________________________________________________________________________________________
از معماری نمایش داده شده در خروجی بالا میتوان دریافت که این مدل، 14 «بلوک» (Block) خواهد داشت. همچنین، هر کدام از بلوکهای تعبیه شده، لایههای مختلفی را در خود جای دادهاند. بنابراین، شبکه عصبی آموزش داده شده، به اندازه کافی عمیق خواهد بود که بتواند خروجی یا پیشبینیهای مناسبی تولید کند.
تولید پیشبینی توسط مدل های یادگیری عمیق در بینایی کامپیوتر روی یک تصویر نمونه
در این مرحله و پس از آموزش مدل شبکه عصبی پیچشی Xception، یک تصویر نمونه وارد سیستم و بر اساس احتمالات تولید شده برای تعلق این نمونه به تمامی کلاسهای موجود در شبکه، پنج کلاس برتر مرتبط با این نمونه در خروجی تولید میشود. ابتدا تصویر مربوطه در سیستم بارگیری میشود.

در ادامه، پنج کلاس برتر مرتبط با این نمونه تصویر، توسط مدل شبکه عصبی پیچشی Xception، در خروجی نمایش داده میشود:
خروجی:
[[('n02124075', 'Egyptian_cat', 0.80723596),
('n02123159', 'tiger_cat', 0.09508163),
('n02123045', 'tabby', 0.042587988),
('n02127052', 'lynx', 0.00547999),
('n02971356', 'carton', 0.0014547487)]]
نکته جالب در مورد پیشبینیهای انجام شده این است که حداقل سه کلاس برتر پیشبینی شده توسط مدل شبکه عصبی پیچشی Xception، کاملا مرتبط با تصویر نمونه هستند.
روش مصورسازی لایههای فعالسازی
این روش نیز همانند روش قبلی، جهت تفسیر خروجیهای مدل های یادگیری عمیق در بینایی کامپیوتر مورد استفاده قرار میگیرد. در این روش، نحوه تبدیل ورودیهای شبکه عصبی به خروجی مناسب در لایههای فعالسازی شبکه، به نمایش در میآید. ایده اصلی این روش، مشخص کردن نقشههای ویژگی فعال شده در هر لایه از مدل و مصورسازی آنها است.

چنین کاری به ازاء هر کدام از لایههای موجود در شبکه عصبی پیچشی انجام میشود. قطعه کد زیر، فرایند مصورسازی لایه فعالسازی یکی از لایههای موجود در بلوک دوم شبکه عصبی پیچشی را نمایش خواهد داد.

در تصویر خروجی نمایش داده شده، نمایی از نقشههای ویژگی فعال شده در تصویر ورودی مشخص شده است. این تصویر، تا حدودی مشخص میکند که برای تولید پیشبینیهای نهایی، تمرکز مدل بیشتر روی کدام یک از اجزاء موجود در تصویر خواهد بود. به عبارت دیگر، این روش، پیشبینیهای تولید شده توسط مدل های یادگیری عمیق در بینایی کامپیوتر را برای کاربران تفسیر میکند.
روش حساسیت به همپوشانی
ایده استفاده از روشهای حساسیت به همپوشانی، جهت تفسیر پیشبینیهای تولید شده توسط مدل های یادگیری عمیق در بینایی کامپیوتر بسیار حسی و شهودی است. به بیان سادهتر، از طریق همپوشانی یا مخفی کردن بخشهایی از تصویر، در یک فرایند تکراری، میزان تاثیرگذاری بخشهای مختلف یک تصویر در خروجی (پیشبینی) تولید شده توسط شبکه عصبی محاسبه میگردد.
در این روش، به طور سیستماتیک بخشهای مختلف تصویر ورودی توسط یک ناحیه مربعی شکل و خاکستری رنگ پوشانده میشود. سپس، خروجی (پیشبینی) تولید شده توسط مدل بررسی میشود تا میزان تأثیر بخشهای مختلف تصویر در خروجی (پیشبینی) محاسبه شود.

در حالت ایدهآل، بخشهای خاصی از تصویر که بیشترین تأثیر را در تولید پیشبینیهای شبکه عصبی دارند، همانند «نقشه حرارت» (Heatmap)، رنگ زرد یا قرمز به خود میگیرند. با این حال، خروجی حاصل شده از تصویر ورودی مسأله (تصویر گربه)، توسط طیفهای مختلف از رنگ قرمز اشباع شده است. دلیل چنین پدیدهای ممکن است «بزرگنمایی» (Zoom) تصویر ورودی باشد. با بررسی بیشتر تصویر خروجی تولید شده توسط روش حساسیت به همپوشانی، میتوان در یافت که شدت رنگ بخش سمت چپ تصویر، بیشتر از سمت راست آن است؛ یعنی، به احتمال زیاد، بخش سمت چپ تصویر تأثیر بیشتری در خروجی (پیشبینی) شبکه عصبی پیچشی دارد.
روش GradCAM
این روش، یکی از معروفترین و مجبوبترین تکنیکهای توسعه داده شده جهت تفسیر پیشبینیهای تولید شده توسط مدل های یادگیری عمیق در بینایی کامپیوتر است. در این روش، از طریق بررسی گرادیانهای پس انتشار شده (انتشار داده شده در جهت عکس جریان اطلاعاتی شبکه عصبی) به سمت «نقشههای فعالسازی کلاسی» (Class Activation Maps | CAM)، میزان تأثیر بخشهای مختلف تصویر در خروجی (پیشبینی) تولید شده توسط شبکه عصبی محاسبه میگردد.
نقشههای فعالسازی کلاسی، روشهای سادهای هستند و هدف آنها، پیدا کردن نواحی «متمایزگر» (Discriminative) در تصویر است. این نواحی، توسط مدل شبکه عصبی پیچشی جهت شناسایی یک کلاس خاص در تصویر (و تخصیص برچسب کلاسی متناظر با آن کلاس به تصویر) استفاده میشوند. به عبارت دیگر، این روش به کاربران اجازه میدهد تا نواحی مرتبط با یک کلاس خاص در هر تصویر را شناسایی و مشاهده کنند.
- خروجی این روش، پیکسلهایی خواهد بود که بیشترین تأثیرگذاری را در «بیشینهسازی» (Maximization) تابع هدف دارند.
- برای مشخص کردن پیکسلهای مرتبط با هر کلاس خاص در تصاویر ورودی، کافی است تا گرادیانهای تابع هدف نسبت به خروجیهای لایههای کانولوشن محاسبه شود. چنین کاری، در هنگام پس انتشار خطا به راحتی قابل انجام است.
با داشتن یک تصویر و یک کلاس مورد علاقه (به عنوان نمونه، کلاس tiger_cat ،Egyptian_cat یا هر کلاس دیگر در دادهها) به عنوان ورودی، تصویر در جهت جریان اطلاعاتی شبکه عصبی (رو به جلو) انتشار داده میشود. سپس، خروجیها یا پیشبینیهای خام مدل تولید میشود. در مرحله بعد، گرادیان تمامی کلاسها، به جز کلاس مورد علاقه، برابر با صفر و گرادیان کلاس مورد علاقه، برابر با 1 در نظر گرفته میشود. سپس، سیگنال تولید شده به سمت لایههای مختلف موجود در شبکه عصبی پیچشی پس انتشار (انتشار رو به عقب و در در جهت عکس جریان اطلاعاتی شبکه عصبی) داده میشود. از این طریق، ناحیههایی از تصویر که سیستم برای پیشبینی یک کلاس خاص بیشتر روی آنها تمرکز دارد مشخص میشوند (به وسیله نقشه حرارت آبی).
در ادامه، از روش GrandCAM برای جهت تفسیر پیشبینیهای تولید شده توسط مدل های یادگیری عمیق در بینایی کامپیوتر برای دو کلاس (tabby) و (Egyptian_cat) استفاده و خروجی روش، مصورسازی میشود. در ابتدا، یکی از لایههای موجود در بلوک اول (یکی از لایههای سطحی شبکه عصبی پیچشی) مصورسازی میشود.

در شکل اول از سمت چپ، شبکه روی نواحی مرتبط با کلاس (tabby) تمرکز دارد. در شکل میانی، تمرکز شبکه روی نواحی مرتبط با کلاس (Egyptian_cat) قرار دارد. همانطور که انتظار میرفت، از آنجایی که این لایه یکی از لایههای سطحی شبکه عصبی پیچشی است، ویژگیهای سطح بالا نظیر لبه و گوشهها در شبکه فعال میشوند. در ادامه، جهت درک بهتر فرایند تفسیر پیشبینیهای تولید شده توسط مدل های یادگیری عمیق در بینایی کامپیوتر و کاربردهای مرتبط، یکی از لایههای موجود در بلوک ششم (یکی از لایههای نسبتا عمیق شبکه عصبی پیچشی) مصورسازی میشود.

در اینجا، نتایج به مراتب بهتری نسبت به مرحله قبل تولید شده است و نواحی پیکسلی مهم و مرتبط با دو کلاس (tabby) و (Egyptian_cat) به شکل بهتری مصورسازی شدهاند. به عنوان نمونه، در کلاس (tabby)، شبکه عصبی پیچشی تمرکز بیشتری روی بافت، شکل کلی و ساختار کلی گربه دارد. در مورد کلاس (Egyptian_cat)، چنین امری کمتر مشهود است. در نهایت، یکی از لایههای موجود در بلوک چهاردهم (یکی از لایههای عمیق شبکه عصبی پیچشی) مصورسازی میشود.

نکته بسیار جالب در هنگام مصورسازی پیشبینیهای تولید شده برای کلاس (tabby)، تمرکز بیش از حد مدل روی نواحی اطراف گربه در تصویر است. به عبارت دیگر، شبکه عصبی پیچشی، ساختار و شکل کلی گربه به همراه برخی از ویژگیهای ساختاری چهره گربه را به خوبی یاد گرفته است.
روش SmoothGrad
این روش نیز یکی از روشهای شناخته شده جهت تفسیر پیشبینیهای تولید شده توسط مدل های یادگیری عمیق در بینایی کامپیوتر محسوب میشود. در این روش، از طریق میانگینگیری از «نقشههای حساسیت گرادیانی» (Gradient Sensitivity Maps) یک تصویر ورودی، «گرادیانهای پایدار» (Stabilized Gradients) تولید شده از وردی به سمت خروجی (پیشبینی) شناسایی و مصورسازی میشوند. هدف اصلی این روش، شناسایی پیکسلهایی است که تأثیرگذاری زیادی در تولید خروجیها یا پیشبینیهای نهایی مدل دارند.
در ابتدای کار این روش، گرادیانِ تابع تولید کننده خروجی نهایی (تعیین کننده کلاس نمونهها) نسبت به تصویر ورودی محاسبه میشود. گرادیانهای محاسبه شده را میتوان در قالب نقشه حساسیت تفسیر کرد. به عبارت دیگر، روش SmoothGrad، نقشههای حساسیت مبتنی بر گرادیان را به صورت بصری «نمایانسازی» (Sharpen) میکنند. روش کار در این روش بدین صورت است که ابتدا یک تصویر ورودی (مورد علاقه) انتخاب میشود. سپس، تعدادی تصاویر مشابه از طریق اضافه کردن نویز به تصویر ورودی تولید (نمونهگیری) میشوند. در مرحله آخر، میانگین نقشههای حساسیت تولید شده به ازاء هر تصویر نمونه (نویزی) محاسبه میشود.

به عنوان نمونه، برای کلاس (tabby)، تمرکز شبکه عصبی پیچشی بیشتر روی ویژگیهایی نظیر بخشبندیهای شکلی و ساختاری و «الگوهای راه راه» (Stripe Patterns) گربه قرار دارد. نکته مهم در مورد ویژگیهای شناسایی شده توسط این روش، متمایز کنندگی بالای آنها در جداسازی گونههای مختلف گربهای است.
جمعبندی
در این مطلب، مهمترین و شناخته شدهترین روشهای موجود جهت تفسیر خروجیها یا پیشبینیهای تولید شده توسط مدل های یادگیری عمیق در بینایی کامپیوتر معرفی شدند. در این مطلب، علاوه بر اینکه از قدرت مدلهای شبکه عصبی پیچشی از پیش آموزش داده شده و مفهوم یادگیری انتقال، برای تولید پیشبینی در مورد تصاویر جدید استفاده شد، مصورسازی نحوه تفسیر پیشبینیهای تولید شده نیز مورد بحث و بررسی قرار گرفت.

در نهایت، به خوانندگان و مخاطبان این مطلب توصیه میشود تا خروجی مدلهای خود را توسط روشهای ارائه شده در این مطلب مصورسازی کنند تا متوجه شوند که یک مدل یادگیری عمیق چگونه ورودیهای را به خروجیها یا پیشبینیهای نهایی تبدیل میکند.
اگر نوشته بالا برای شما مفید بوده است، آموزشهای زیر نیز به شما پیشنهاد میشوند:
- مجموعه آموزشهای دادهکاوی و یادگیری ماشین
- آموزش اصول و روشهای دادهکاوی (Data Mining)
- مجموعه آموزشهای هوش مصنوعی
- پرسپترون چند لایه در پایتون — راهنمای کاربردی
- پیشبینی قیمت بیت کوین با شبکه عصبی — راهنمای کاربردی
- نقشه دانش فناوریهای هوش مصنوعی و دسته بندی آنها — راهنمای جامع
- کدنویسی شبکه های عصبی مصنوعی چند لایه در پایتون — راهنمای کامل
- یادگیری عمیق (Deep Learning) با پایتون — به زبان ساده
^^









سلام من موضوع پایان نامه م در همین مورد هستش البته برای تشخیص و تفسیر سکته قلبی با استفاده از شبکه های عصبی عمیق و از شبکه LSTM برای اینکار استفاده کردم خواستم بدونم این نوع روش ها رو میشه روی سیگنال نوار قلب نمایش داد یعنی میشه به هر سمپلی که در سیگنال هست یک relevancy score نسبت بدیم و به صورت هیت مپ نشون بدم نتیجه رو خصوصا اینکه از شبکه های عصبی بازگشتی استفاده کردم