



متغیر پنهان در مدل ساختاری – به زبان ساده
در بسیاری از تحلیلهای آماری، ویژگیهایی وجود دارند که بواسطه مشاهده، قابل اندازهگیری نیستند و لازم است براساس متغیرهای دیگر برآورد شوند. چنین متغیرهایی به «متغیرهای پنهان» (Latent Variable) مشهور هستند. در این نوشتار به بررسی متغیر پنهان در مدل ساختاری و شیوه تشخیص و تولید آن خواهیم پرداخت. این گونه متغیرها در تحلیلهای روانشناسی، جامعهشناسی، اقتصاد، مهندسی، داروسازی و بهداشت، یادگیری ماشین، بیوانفورماتیک، اقتصاد سنجی و غیره کاربرد دارند.


برای آشنایی بیشتر با مدلهای ساختاری بهتر است نوشتار مدل معادلات ساختاری (Structural Equation Modeling) — مفاهیم، روشها و کاربردها را مطالعه کنید. همچنین آشنایی با مفهوم ضریب همبستگی و همبستگی جزئی که در مطلب ضریبهای همبستگی (Correlation Coefficients) و شیوه محاسبه آنها — به زبان ساده و ضریب همبستگی جزئی (Partial Correlation) — به زبان ساده آمده است مناسب به نظر میرسد. از طرفی مطالعه رگرسیون خطی — مفهوم و محاسبات به زبان ساده نیز خالی از لطف نیست.
متغیر پنهان در مدل ساختاری

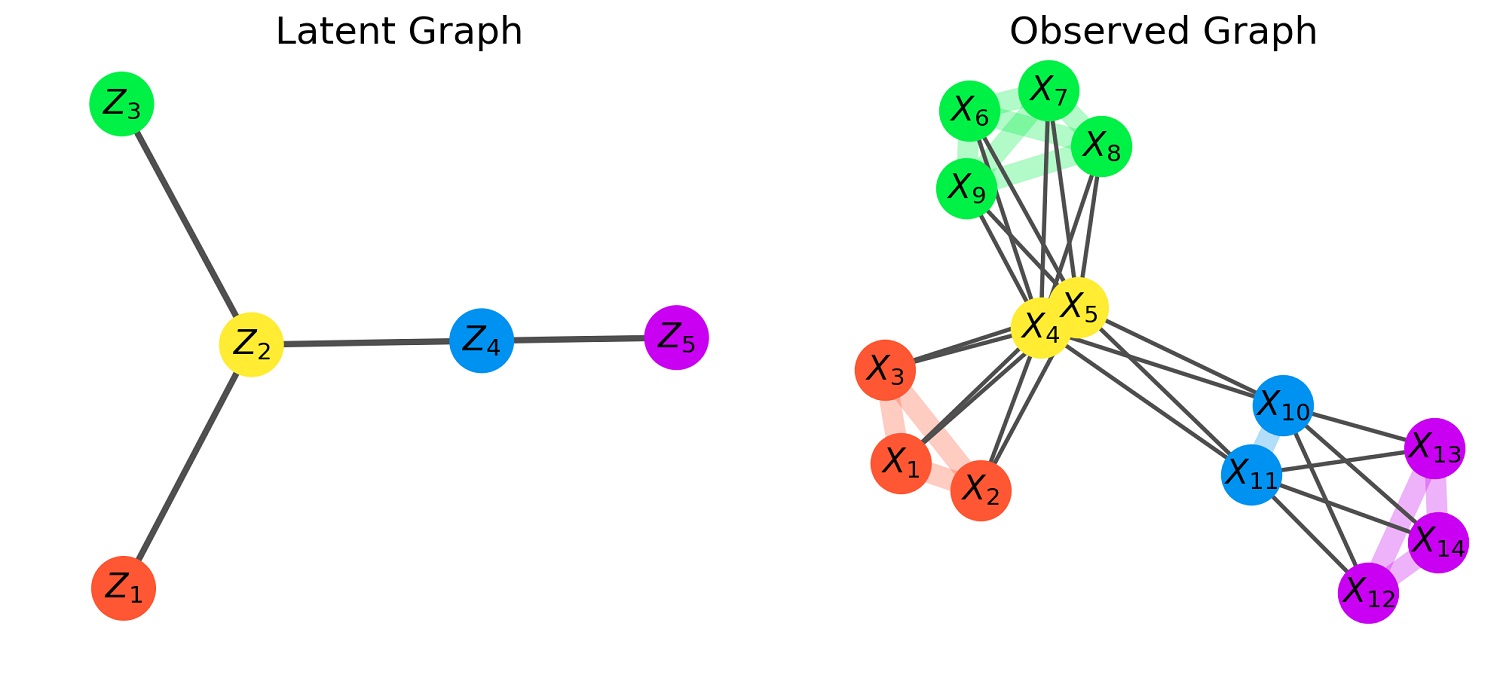
متغیر پنهان در مدل ساختاری به متغیری گفته میشود که قابل مشاهده نیست و در مقابل «متغیر قابل مشاهده» (Observable Variable) قرار دارد. از این جهت چنین متغیرهایی را با نام «متغیر پنهان» (Latent Variable) میشناسیم. متغیر پنهان در مدل ساختاری بوسیله متغیرهای دیگر (مانند متغیرهای قابل مشاهده) شناساییپذیر شده و مقدار آن اندازهگیری میشود. برای مشخص شدن موضوع به مثالی در این زمینه توجه کنید.
فرض کنید کارایی کارکنان شرکت قرار است اندازهگیری شود. واضح است که این متغیر به عوامل دیگری مانند میزان ساعت کاری، تعداد کارهای محول شده، تعداد ساعات مرخصی، میزان رضایت شغلی و غیره بستگی دارد. متغیرهایی مانند میزان ساعت کاری و یا تعداد ساعات مرخصی، قابل اندازهگیری هستند و از نوع متغیرهای قابل مشاهده محسوب میشوند ولی میزان رضایت شغلی به راحتی قابل تشخیص یا اندازهگیری نیست. از طرفی میدانیم که این متغیر (که به عنوان متغیر پنهان تلقی میشود) در میزان کارایی کارمندان شرکت تاثیر گذار است. برای اندازهگیری این متغیر پنهان شاید بتوان مدل یا رابطهای متغیرهای قابل مشاهده مانند زمان انجام کار، تعداد روزهای مرخصی در سال و میزان تاخیرات را مبنایی بر میزان رضایت در نظر گرفت و با استفاده از یک مدل ریاضی (یا آماری) میزان رضایت را برای کارکنان اندازهگیری کرد.
البته گاهی ممکن است متغیری که قابل اندازهگیری نیز هست از دید ما مخفی مانده باشد و بنا به دلایلی آن را اندازهگیری نکرده و در مدل به کار نبرده باشیم. در چنین حالتی متغیر را مخفی (Hidden) مینامند. یکی از کاربردهای بسیار موثر متغیرهای پنهان، کاهش ابعاد یک مسئله پیچیده با متغیرهای زیاد است. برای مثال میتوان با استفاده از رابطهای که بین متغیرهای قابل مشاهده برای اندازهگیری میزان رضایت شغلی ایجاد شد، کارایی کارکنان را با متغیرهایی کمتر و با ترکیبی از متغیرهای پنهان اندازهگیری کرد.
روشهای استنباط و تحلیل متغیرهای پنهان در فهرست زیر معرفی شدهاند.
- مدل مارکف پنهان (Hidden Markov Model)
- تحلیل عامل (Factor Analysis)
- تحلیل مولفههای اصلی (Principle Component Analysis)
- رگرسیون کمترین مربعات جزئی (Partial Least Squares Regression)
- الگوریتم EM
در ادامه با مثالهایی از متغیرهای پنهان در روانشناسی و اقتصاد آشنا خواهیم شد.
متغیر پنهان در مدل ساختاری و کاربرد آن در روانشناسی
متغیرهای پنهانی که توسط تحلیل عاملی ایجاد میشوند، معمولا بیانگر واریانس مشترک (Shared Variance) یا درجه تغییرات همسو متغیرها هستند. متغیرهایی که دارای همبستگی نباشند، در تحلیل عاملی نمیتوانند متغیر پنهان ایجاد کنند. در ادامه به معرفی بعضی متغیرهای پنهان که در روانشناسی کاربرد دارند میپردازیم.
- پنچ شاخص اصلی شخصیت که بوسیله تحلیل عاملی کشف و استخراج میشوند.
- غربالگری (درونگرایی یا برونگرایی)
- توانایی و قدرت درک فضا و زمان (فضا-زمان)
- خرد یا دانایی: دو ابزار مهم در ارزیابی خرد و دانایی، عبارت هستند از عملکرد مرتبط با خرد فرد و اندازهگیری مقدارهای متغیر پنهان.
- شاخص یا معیار g اسپیرمن (Spearman's g) یا عامل هوش عمومی یا درک شناختی در روانسنجی.
متغیر پنهان در مدل ساختاری و کاربرد آن در اقتصاد
نمونههایی از متغیرهای پنهان در حوزه اقتصاد عبارتند از: کیفیت زندگی، اعتماد به نفس کسب و کار، روحیه، خوشبختی و محافظه کاری. اینها همه متغیرهایی هستند که نمیتوان مقدار آنها را مستقیما اندازهگیری کرد. اما پیوند و ارتباط این متغیرهای پنهان با سایر متغیرهای قابل مشاهده، امکان اندازهگیری و تعیین مقدارشان را فراهم میکند.

برای مثال «کیفیت زندگی» (Life Quality) یک متغیر پنهان است که قابل اندازهگیری نیست ولی متغیرهای قابل مشاهده برای اندازهگیری کیفیت زندگی عبارتند از میزان یا مقدار ثروت، ساعت کاری، محیط زیست، سلامت جسمی (مثلا فشار خون، چربی و وزن ...)، آموزش (سطح تحصیلات)، تفریحی و اوقات فراغت (تعداد دفعات رفتن به سینما و تئاتر) و غیره.
متغیر قابل مشاهده و متغیر پنهان در مدل ساختاری
مدل متغیر پنهان، یک مدل آماری است که در آن رابطه بین متغیرهای قابل مشاهده و متغیرهای پنهان بیان میشود. در اینجا فرض بر این است که متغیرهای قابل مشاهده دارای ارتباط با متغیرهای پنهان هستند و میتوان براساس آنها، مقدار متغیرهای پنهان را مشخص کرد. از طرفی شرط اصلی برای متغیرهای قابل مشاهده آن است که بعد از کنترل متغیر پنهان، ارتباطی بینشان وجود ندارد. به معنی دیگر ارتباط بین متغیرهای قابل مشاهده فقط از طریق متغیرهای پنهان امکانپذیر و قابل توجیه است. جدول زیر ارتباط و نوع تحلیل به کار رفته برای متغیرهای پنهان و قابل مشاهده با توجه به پیوسته یا طبقهای (Categorical) بودن آنها را نشان میدهد.
| متغیر قابل مشاهده | ||
| متغیر پنهان | پیوسته | طبقهای (گسسته) |
| پیوسته | تحلیل عاملی (Factor Analysis) | نظریه پاسخ گزینهای (Item Response Theory) |
| طبقهای (گسسته) | تحلیل مدل آمیخته (Mixture Model) | تحلیل کلاسبندی متغیرهای پنهان (Latent Class Analysis) |
در تحلیل عاملی و تجزیه متغیرهای پنهان به عنوان متغیرهای با توزیع احتمالی نرمال و متغیر تصادفی پیوسته در نظر گرفته میشوند. ولی در حالت طبقهای با استفاده تحلیل کلاسبندی متغیرهای پنهان، توزیع احتمالی برای متغیرهای پنهان، دوجملهای یا چندجملهای محسوب میشود. متغیرهای قابل مشاهده در تحلیل عاملی پیوسته بوده و در بیشتر مواقع توزیع شرطی آنها با ثابت بودن متغیر پنهان، نرمال چند متغیره در نظر گرفته میشود.
متغیرهای قابل مشاهده گسسته معمولا به صورت مقادیر دو وضعیتی (Dichotomous) یا ترتیبی یا اسمی هستند. توزیع شرطی آنها با ثابت بودن متغیر پنهان، دوجملهای (Binomial Distribution) یا چندجملهای (Multinomial Distribution) است.
اخیرا از تحلیل متغیرهای پنهان به منظور بهینهسازی (مانند الگوریتم EM) نیز استفاده شده است. مدلسازی متغیرهای پنهان میتواند یک ابزار مناسب برای بهینهسازی تکنیکهای تحلیلی باشد که به اجرای پروتکلهای بهینهسازی دقیق، سیستماتیک و کارآمد کمک میکند. همچنین محاسبات مربوط به معادلات ساختاری در نرمافزارهای آماری AMOS یا نرمافزار لیزرل (LISREL) نیز امکانپذیر است.
اگر مطلب بالا برای شما مفید بوده است، آموزشهای زیر نیز به شما پیشنهاد میشوند:
- مجموعه آموزشهای آمار، احتمالات
- آموزش همبستگی و رگرسیون خطی در SPSS
- مجموعه آموزشهای نرمافزار آماری SPSS
- آموزش مدل سازی معادلات ساختاری با AMOS
- ضریبهای همبستگی (Correlation Coefficients) و شیوه محاسبه آنها
- رگرسیون خطی — مفهوم و محاسبات به زبان ساده
^^











سلام وقت بخیر
توضیحات کامل بود فقط اگه روی مدلی مثل TVPFAVAR توضیحات بطور عملی گفته شود ویا مدل سازی با TVPFAVAR گفته شود بسیار عالی خواهدبود. سپاسگزارم
سلام خسته نباشید
لطفا در خصوص بارگذاری و نام گذاری متغیر پنهان که از یک پرسشنامه تهیه شده و داده ها در نرم افزار spss میباشند و به نرم افزار ایموس منتقل میشوند بیشتر توضیح دهید . چون در زمان گرفتن خروجی به مشکل میخورم یا اصلا خروجی به من نمیده