



الگوریتم های یادگیری عمیق کلیدی را بشناسید – ۱۳ الگوریتم مهم
«یادگیری عمیق» (Deep Learning) یکی از شاخههای مهم حوزه «هوش مصنوعی» (Artificial Intelligence) محسوب میشود که امروزه کاربرد این حوزه را میتوان در اکثر جنبههای زندگی بشر ملاحظه کرد. این حیطه از هوش مصنوعی شامل الگوریتمهای مختلفی هستند که سیستمهای کامپیوتری بر اساس آنها میتوانند بدون نیاز به دخالت انسان، به حل مسائل مختلف بپردازند و به مدیران سازمانها در راستای سوددهی بیشتر، کمک بهسزایی کنند. در مطلب حاضر، به معرفی پرکاربردترین الگوریتم های یادگیری عمیق پرداخته میشود و نحوه عملکرد آنها و مزایا و معایب این الگوریتمها مورد بررسی قرار میگیرند.
- خواهید آموخت که یادگیری عمیق چگونه به خودکارسازی و تصمیمگیری هوشمند کمک میکند.
- ساختار شبکههای عصبی و ارتباط آن با مغز انسان را میآموزید.
- تفاوت شبکههای عصبی عمیق و معمولی را یاد خواهید گرفت.
- با سیزده الگوریتم مهم یادگیری عمیق و کاربردهای متنوع هریک آشنا میشوید.




یادگیری عمیق چیست ؟
یادگیری عمیق به عنوان زیرشاخهای از «یادگیری ماشین» (Machine Learning) و هوش مصنوعی محسوب میشود که با استفاده از الگوریتمهای آن میتوان سیستمهای هوشمندی را طراحی کرد که برای حل مسائل مختلف، رفتاری مشابه با رفتار انسان را دارند.
مغز انسان از بیلیونها نورون در قالب یک شبکه تشکیل شده است که این نورونها، پردازشهای مختلفی را بر روی اطلاعاتی انجام میدهند که از حسهای لامسه دریافت میشوند تا انسان در نهایت به شناخت، درک و استدلال برسد.
به منظور طراحی الگوریتم های یادگیری عمیق، از مغز انسان الهام گرفته شده است. به عبارتی، الگوریتم های یادگیری عمیق با داشتن ساختار لایهای و وجود چندین «گره | نود» (Node) در هر یک از این لایهها، میتوانند بدون نیاز به دخالت و نظارت انسان، مسائل مختلف را با استفاده از دادههای ساختاریافته یا دادههای غیرساختاریافته یاد بگیرند. از کنار هم قرار گرفتن لایههای مختلف که هر کدام دارای چندین گره هستند، «شبکه عصبی» (Neural Network) حاصل میشود. دادههای ورودی در این شبکه جریان پیدا میکنند تا با اعمال یک سری پردازشها بر روی آنها، ماشین بتواند مسئله خاصی را یاد بگیرد و همانند انسان به حل آن بپردازد.
مقدمه ای بر الگوریتم های یادگیری عمیق
پیش از آن که به معرفی لیستی از الگوریتم های یادگیری عمیق بپردازیم، در ابتدا بهتر است ساختار و نحوه یادگیری کلی این الگوریتمها به منظور درک بهتر عملکرد آنها شرح داده شوند. در این بخش، مثالی از دیتاست معروف MNIST ارائه کردیم که در مسائل مربوط به پردازش تصویر از آن استفاده میشود.
در این دیتاست، تصاویری از حالات مختلف نوشتن اعداد وجود دارد. با این که حالت نوشتن هر یک از این اعداد تا حدی با یکدیگر متفاوت هستند، اما انسان میتواند بهراحتی عدد نوشته شده را تشخیص دهد، زیرا به دفعات زیادی این اعداد را با حالتهای مختلف نوشته یا با آنها در متون مختلف برخورد کرده است.

از آن جا که به منظور طراحی الگوریتم های یادگیری عمیق و نحوه آموزش آنها، از ساختار و عملکرد مغز انسان الهام گرفته شده است، باید دادههای آموزشی مختلفی نیز برای این الگوریتمها فراهم شود تا بتوانند درباره دادههای جدید به تصمیمگیری بپردازند. در بخش قبل اشاره شد که الگوریتم های یادگیری عمیق بر پایه شبکه عصبی مصنوعی شکل گرفتهاند. این شبکهها، دارای سه لایه اصلی هستند که دو لایه ابتدا و انتهای آنها ثابت است و تعداد لایههای میانی آنها بنا به یک سری ویژگیها بیشتر یا کمتر میشوند.
به دو لایه ابتدایی و انتهایی شبکه عصبی، «لایه ورودی» (Input Layer) و «لایه خروجی» (Output Layer) و به لایههای میانی، «لایههای پنهان» (Hidden Layer) گفته میشود. شبکههای عصبی با یک لایه پنهان، «شبکههای عصبی مصنوعی» (Artificial Neural Networks) نام دارند و به شبکههای عصبی با بیش از یک لایه پنهان، «شبکههای عصبی عمیق» (Deep Neural Networks) گفته میشوند.

هر یک از گرههای موجود در لایههای شبکه عصبی، مقداری را از ورودی دریافت و آن را در یک مقدار تصادفی (وزن) ضرب و سپس یک مقدار بایاس را به نتیجه حاصل شده اضافه میکنند. سپس، مقدار نهایی به یک «تابع فعالسازی» (Activation Function) داده میشود تا خروجی نهایی گره محاسبه شود. تصویر زیر، روال محاسبات درون گرههای شبکه عصبی را نشان میدهد.
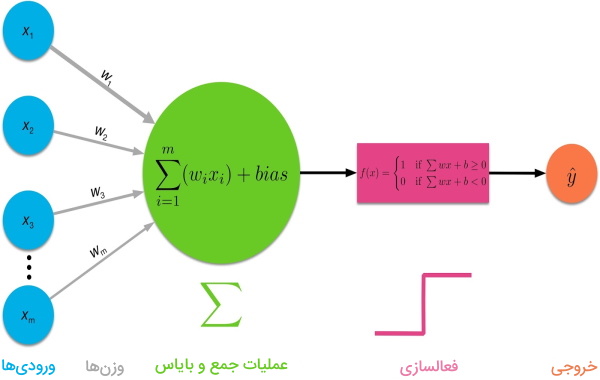
در مثالی که از دیتاست MNIST ارائه کردیم، ورودی شبکه عصبی میتواند «برداری» (Vector) باشد که شامل اطلاعات هر تصویر است. این بردار به لایه ورودی شبکه عصبی داده میشود. لایه اول، بدون اعمال محاسبات، اطلاعات ورودی را به لایه بعدی شبکه منتقل میکند. در لایههای پنهان شبکه عصبی، محاسبات مختلفی بر روی دادههای ورودی هر لایه اعمال شده و خروجیها به لایه بعد منتقل میشوند. این روند تا لایه آخر در شبکه عصبی ادامه پیدا میکند تا در نهایت، مدل به تشخیص عدد ورودی شبکه بپردازد.

پس از پیشبینی مقدار خروجی توسط شبکه عصبی، باید توسط تابعی به نام « تابع زیان | تابع هزینه» (Loss Function | Cost Function)، میزان اختلاف مقدار پیشبینی شده توسط مدل و «مقدار هدف» (Target) محاسبه گردد تا بر اساس آن، بهروزرسانی وزنهای شبکه عصبی انجام شود. به منظور بهروزرسانی وزنهای شبکه عصبی، از روشهای مختلفی استفاده میشوند که یکی از پرکاربردترین روشها، «روش پس انتشار» (Backpropagation) است.
در پی انجام مرحله پس انتشار، با استفاده از محاسبه گرادیان تابع هزینه نسبت به پارامترهای شبکه عصبی، وزنهای شبکه بهروزرسانی میشوند. سپس، داده آموزشی جدید به شبکه وارد شده و این روند آنقدر تکرار میشود تا وزنهای شبکه عصبی به مقادیری برسند تا با انجام هر بار مرحله پس انتشار، تغییرات بسیار جزئی داشته باشند و تقریباً به مقدار ثابتی برسند. در بخش بعدی مطلب حاضر، به معرفی پرکاربردترین الگوریتم های یادگیری عمیق پرداخته میشود.
الگوریتم های یادگیری عمیق
در بخش حاضر، به معرفی رایجترین الگوریتم های یادگیری عمیق پرداخته میشود و نحوه کارکرد آنها و مزایا و معایب انواع شبکه های عصبی مصنوعی مورد بررسی قرار میگیرند. این الگوریتمها در ادامه فهرست شدهاند:
- مدل «پرسپترون چند لایه» (Multi Layer Perceptron | MLP)
- «شبکه پیش خور» (Feed-Forward Neural Network | FNN)
- شبکه عصبی «تابع پایه شعاعی» (Radial Basis Function Neural Network | RBFN)
- «شبکه عصبی پیچشی» (Convolutional Neural Network)
- «شبکه عصبی بازگشتی» (Recurrent Neural Network)
- «شبکه عصبی با حافظه طولانی کوتاه مدت» (Long Short-Term Memory | LSTM)
- «شبکه مولد تخاصمی» (Generative Adversarial Network | GAN)
- مدل «ترسیم خودسازمان دهنده» (Self Organizing Map | SOM)
- مدل «ماشین بولتزمن محدود شده» (Restricted Boltzmann Machine | RBM)
- مدل «خودرمزگذار» (Autoencoder)
- «مدل باور عمیق» (Deep Belief Network | DBN)
- «مدلهای رمزگذار-رمزگشا» (Encoder-Decoder Models)
- «شبکه عصبی ماژولار» (Modular Neural Network)
۱. مدل پرسپترون چند لایه
«مدل پرسپترون چند لایه» (Multi Layer Perceptron | MLP)، به عنوان یکی از پایهایترین و قدیمیترین الگوریتم های یادگیری عمیق به شمار میرود. این مدل، اولین مدلی است که به علاقهمندان تازهکار به حوزه یادگیری عمیق آموزش داده میشود. از این مدل نیز میتوان به عنوان نوع خاصی از شبکههای پیش خور یاد کرد.

الگوریتم یادگیری عمیق پرسپترون چند لایه چگونه کار می کند ؟
اولین لایه در الگوریتم یادگیری عمیق پرسپترون چند لایه، ورودیهای شبکه را دریافت و آخرین لایه نیز خروجی شبکه را مشخص میکند. تعداد گرههای هر لایه در شبکه پرسپترون چند لایه با یکدیگر برابر است و هر گره به تمامی گرههای لایه بعدی متصل است. در ابتدا، مقدار وزنهای این شبکه بهصورت تصادفی مقداردهی اولیه میشوند.
سپس، وزنها و بردار ورودیها به گرهها ارسال شده تا با اعمال یک سری عملیات محاسباتی و عبور از توابع فعالسازی، خروجی گره محاسبه و به لایه بعد منتقل شود. توابع فعالسازی رایج و پرکاربرد در الگوریتم پرسپترون چند لایه، توابع Sigmoid ،ReLU و Tanh هستند.
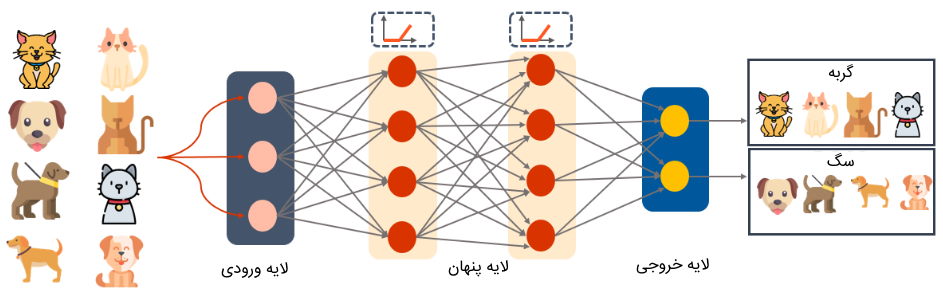
در لایه نهایی شبکه نیز پس از تعیین مقادیر خروجی، مقدار خطای شبکه محاسبه و سپس از مرحله «پس انتشار | انتشار رو به عقب» (Backpropagation) به منظور بهروزرسانی وزنهای شبکه استفاده میشود. این روند یادگیری آزمون و خطا آنقدر تکرار میشود تا مقادیر وزنهای شبکه به مقادیر تقریباً ثابتی برسند. در تصویر بالا، نمونهای از مدل پرسپترون چند لایه برای مسئله دستهبندی تصاویر دیده میشود.
کاربردهای مدل پرسپترون چند لایه چیست ؟
از مدل پرسپترون چند لایه میتوان در مسائل مختلف دستهبندی بهره برد. در سایتهای اجتماعی نظیر اینستاگرام و فیسبوک از این الگوریتم یادگیری عمیق به منظور فشردهسازی دادههای تصویری استفاده میشود. همچنین، در مسائلی نظیر تشخیص گفتار و تشخیص تصاویر نیز میتوان از این مدل شبکه عصبی استفاده کرد.
مزایا و معایب شبکه عصبی پرسپترون چند لایه چیست ؟
یکی از مزیتهای شبکه عصبی چند لایه پرسپترون این است که از این مدل میتوان برای مسائل پیچیده غیرخطی استفاده کرد. بهعلاوه، این مدل عملکرد خوبی در مسائلی دارد که میزان حجم دادههای مسئله، کم است. همچنین، مدت زمان پیشبینی مقدار خروجی مدل برای داده جدید، پایین است.
به دلیل وجود اتصال کامل هر گره با گرههای لایه بعد در ساختار مدل پرسپترون چند لایه، پارامترهای این مدل زیاد است و بنابراین پیچیدگی محاسباتی این شبکه زیاد است و به زمان محاسبات بالایی احتیاج دارد. همچنین، در این مدل نمیتوان بهراحتی به میزان تاثیر متغیرهای وابسته بر روی متغیرهای مستقل پی برد.
۲. شبکه عصبی پیشخور چیست ؟
شبکه عصبی پیشخور (Feed-Forward Neural Network | FNN) یکی از الگوریتم های یادگیری عمیق محسوب میشود که از چندین لایه متوالی تشکیل شده است. تنها تفاوت این مدل با مدل پرسپترون چند لایه در این است که تعداد گرههای هر لایه در FNN میتواند متفاوت از تعداد گرههای لایههای دیگر باشد.
الگوریتم یادگیری عمیق FNN چگونه کار می کند ؟
گرههای هر لایه در شبکه عصبی FNN به تمامی گرههای لایه بعد خود متصل هستند. هر لایه در این مدل، پس از اعمال پردازشهای محاسباتی بر روی ورودیهای خود، خروجی حاصل شده را در قالب بردار، به لایه بعد منتقل میکند. بر اساس میزان پیچیدگی مسئله، تعداد لایههای پنهان این مدل میتواند یک لایه یا بیش از یک لایه باشد. در تصویر زیر، نمونهای از شبکه عصبی FNN ملاحظه میشود.
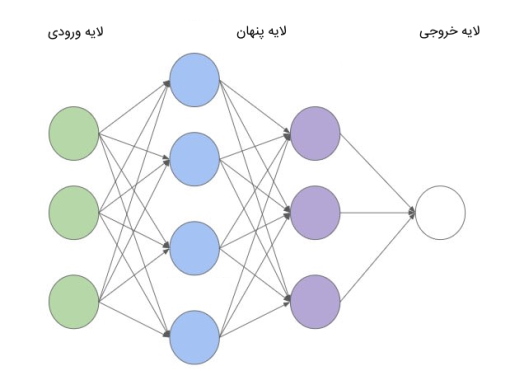
کاربردهای مدل FNN چیست ؟
معمولاً از مدل FNN برای کاهش ابعاد و تغییر ابعاد خروجیهای سایر شبکهها نظیر شبکه CNN نیز استفاده میشود. همچنین، این مدل در شناسایی الگو، تشخیص کاراکترهای دادههای متنی، بینایی ماشین و بازشناسی گفتار نیز کاربرد دارد.
مزایا و معایب شبکه عصبی FNN چیست ؟
مزیت اصلی شبکه عصبی FNN در این است که بار محاسباتی کمی دارد و همین امر سبب میشود مدت زمان یادگیری مدل در مقایسه با سایر الگوریتم های یادگیری عمیق کم باشد. همچنین، پیادهسازی این مدل بهسادگی انجام میشود و افراد تازهکار در حوزه یادگیری عمیق میتوانند بهسادگی از آن استفاده کنند.
یکی از مهمترین معایب مدل FNN این است که برای رسیدن به دقت بالا، به حجم داده زیادی احتیاج دارد. فراهم کردن دادههای آموزشی برچسبدار با حجم بالا، زمانبر است و هزینه مالی زیادی در پی دارد. بهعلاوه، ممکن است در حین یادگیری این مدل، دو مسئله «محوشدگی گرادیان» (Vanishing Gradient) و «انفجار گرادیان» (Exploding Gradient) اتفاق بیفتد. محوشدگی گرادیان به شرایطی اطلاق میشود که مدل دارای لایههای پنهان زیادی است و در حین بهروزرسانی وزنهای شبکه، مقدار گرادیان تابع هزینه به صفر نزدیکتر میشود. در پی این رخداد، فرآیند یادگیری شبکه عصبی دشوار است.
انفجار گرادیان به وضعیتی گفته میشود که مقادیر گرادیان خطا روی هم انباشته شوند و مقادیر حاصل شده، اعداد بزرگی شوند. همین امر منجر به ناپایداری شبکه خواهد شد و یادگیری شبکه بهدرستی انجام نمیشود.
۳. شبکه عصبی تابع پایه شعاعی
«مدل تابع پایه شعاعی» (Radial Basis Function Neural Network | RBFN) را میتوان نوعی از مدل چند لایه پرسپترون تلقی کرد. تنها تفاوت ساختار این مدل با شبکه عصبی چند لایه پرسپترون، در تعداد لایههای آن است. به عبارتی، این شبکه عصبی تنها از سه لایه تشکیل شده است و تنها یک لایه پنهان دارد.
الگوریتم یادگیری عمیق RBFN چگونه کار می کند ؟
لایه پنهان شبکه عصبی تابع پایه شعاعی بر پایه الگوریتم k-means کار میکند که یکی از الگوریتمهای «نظارت نشده» (Unsupervised Learning) یادگیری ماشین محسوب میشود. به عبارتی، این لایه الگوهای دادههای آموزشی را در خود ذخیره میکند و در مرحله تست، با در نظر گرفتن شباهت ویژگی داده جدید با ویژگیهای دادههای آموزشی، به تعیین مقدار هدف میپردازد. در ادامه، تصویری از شبکه عصبی RBFN نشان داده شده است.
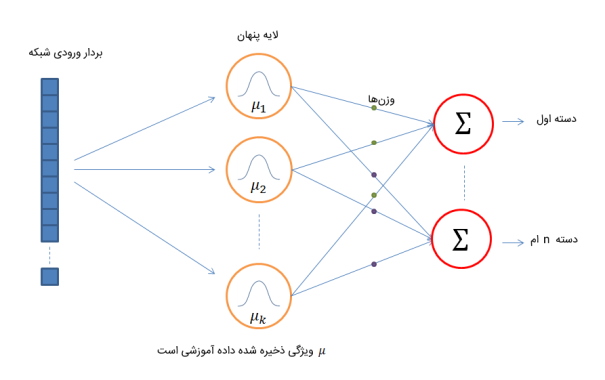
کاربردهای مدل RBFN چیست ؟
از مدل تابع پایه شعاعی میتوان در مسائل مختلف دستهبندی و مخصوصاً در موضوعات مرتبط با «تحلیل سریهای زمانی» (Time Series Analysis) نظیر تحلیل قیمتهای بازار سهام، پیشبینی قیمتهای فروش فصلی، تشخیص گفتار، تشخیصهای پزشکی، تشخیص تصاویر و مسائلی از این قبیل استفاده کرد.
مزایا و معایب شبکه عصبی RBFN چیست ؟
کم بودن تعداد لایههای مدل تابع پایه شعاعی به عنوان یکی از مزیتهای اصلی آن محسوب میشود، زیرا بار محاسباتی این مدل در مقایسه با مدل چند لایه پرسپترون بسیار کمتر میشود و درنتیجه این مدل، به زمان یادگیری کمتری احتیاج خواهد داشت. همچنین، نقش دقیق لایه پنهان این مدل در مقایسه با سایر مدلها مشخص است.
اگرچه زمان یادگیری مدل تابع پایه شعاعی در مقایسه با شبکه عصبی چند لایه پرسپترون کمتر است، با این حال، در زمان تست، داده جدید با دادههای آموزشی مقایسه و بر اساس ویژگیهای مشترکشان، نوع «دسته» (Class) داده جدید مشخص میشود. هر چه تعداد دادههای آموزشی مدل بیشتر باشد، زمان مقایسه و سنجش میزان شباهت داده جدید با کلیه دادههای آموزشی بیشتر میشود. بدین ترتیب، این مدل در مقایسه با لایه پرسپترون چند لایه به زمان بیشتری برای تصمیمگیری درباره «مقدار هدف» (Target) دادههای تست احتیاج دارد.
۴. شبکه عصبی پیچشی
«شبکه عصبی پیچشی» (Convolutional Neural Network | CNN) یا شبکه عصبی کانولوشن یکی از الگوریتم های یادگیری عمیق است که با عنوان ConvNet نیز شناخته میشود. این مدل از چندین لایه تشکیل شده است و معمولاً در مسائل پردازش تصویر و تشخیص اشیاء کاربرد دارد. در سال 1988 اولین نوع شبکه عصبی پیچشی با عنوان LeNet ارائه شد که از این مدل در تشخیص کاراکترهای کد پستی و ارقام تصاویر استفاده میکردند.
مدل شبکه عصبی پیچشی چگونه کار می کند ؟
شبکه عصبی پیچشی از سه لایه اصلی تشکیل شده است. وظیفه اصلی این مدل این است که از دادههای ورودی، ویژگی استخراج کند.

به عبارتی، دادههای ورودی با گذر از لایههای مدل پیچشی، به بردارهای ویژگی با ابعاد پایین تبدیل میشوند.
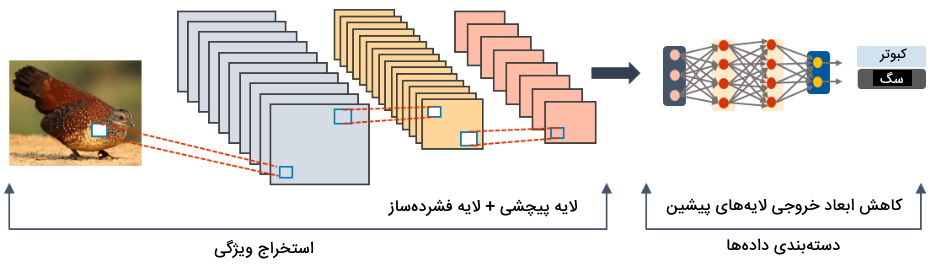
سه لایه شبکه عصبی پیچشی عبارتاند از:
- «لایه پیچشی» (Convolution Layer): این لایه، مهمترین لایه در شبکه عصبی پیچشی است که به عنوان لایه فیلتر (یا کرنل) محسوب میشود. فیلترها شامل پارمترهایی هستند که مقادیر آنها در حین آموزش شبکه، بهروزرسانی میشوند. معمولاً اندازه فیلترها کمتر از ابعاد دادههای ورودی هستند. ابعاد تمامی دادههای ورودی این لایه باید یکسان باشند. با اعمال یک سری محاسبات ریاضی بر روی دادههای ورودی و وزنهای این لایه، خروجی حاصل شده به لایه بعدی شبکه عصبی پیچشی منتقل میشود.
- «لایه فشردهساز» (Pooling Layer): معمولاً ابعاد خروجی لایه پیچشی بزرگ است. به منظور کاهش بعد خروجی لایه پیچشی، از یک لایه فشردهساز استفاده میشود. لایه فشردهساز میتوانند از روشهای مختلفی برای کاهش ابعاد دادههای ورودی خود استفاده کند. به عنوان مثال، لایه «فشردهساز بیشینه» (Max Pooling) بر اساس یافتن بزرگترین مقدار، ابعاد دادهها را کاهش میدهد. لایه فشردهساز میتواند بر اساس پیدا کردن میانگین مقادیر نیز، دادههای ورودی را فشرده کند. خروجی این لایه، ماتریسی از مقادیر است.
- «لایه تمام متصل» (Fully Connected Layer): از آنجایی که خروجی لایه فشردهساز در قالب ماتریس است، از یک لایه تمام متصل بعد از لایه فشردهساز در شبکه عصبی پیچشی استفاده میشود تا مقادیر ماتریس، در قالب یک بردار قرار گیرند و بتوان از این بردار در لایههای بعدی شبکه عصبی استفاده کرد.
کاربردهای مدل عصبی پیچشی چیست ؟
از مدل عصبی پیچشی معمولاً در موضوعات پیرامون پردازش تصویر نظیر تشخیص اشیاء و تشخیص چهره استفاده میشود. در شبکههای اجتماعی نظی اینستاگرام و فیسبوک از مدل عصبی پیچشی استفاده شده است. به عبارتی، کاربرد این نوع الگوریتم یادگیری عمیق را میتوان زمانی مشاهده کرد که کاربران این شبکههای اجتماعی، دوستان خود را بر روی تصاویر مختلف تگ میکنند.

از شبکه عصبی پیچشی در سایر مسائل نظیر تحلیل دادههای ویدئویی و «پردازش زبان طبیعی» (Natural Language Processing | NLP) نیز استفاده میشود. به عنوان مثال، در مسائل پردازش زبان از این مدل میتوان به منظور تشخیص و یادگیری کاراکترهای کلمات استفاده کرد.
مزایا و معایب شبکه عصبی پیچشی چیست ؟
مزیت اصلی شبکه عصبی پیچشی، دقت بالای آن در مسائل مربوط به پردازش تصاویر است. به عبارتی، این مدل در مقایسه با سایر الگوریتم های یادگیری عمیق در موضوعات مرتبط با تصاویر از عملکرد بهتری برخودار است.
همچنین، از این مدل میتوان برای استخراج ویژگی از دادههای ورودی استفاده و از دادههایی با ابعاد بالا، ویژگیهایی با تعداد ابعاد محدود استخراج کرد. پردازش سنگین از مهمترین معایب شبکه عصبی پیچشی محسوب میشود. هر چه تعداد لایههای فیلتر این شبکه بیشتر شود، تعداد پارامترهای مدل نیز افزایش مییابد. بدینترتیب، بار محاسباتی این مدل در زمان آموزش بیشتر میشود و به زمان طولانیتری برای آموزش احتیاج است.
۵. شبکه عصبی بازگشتی
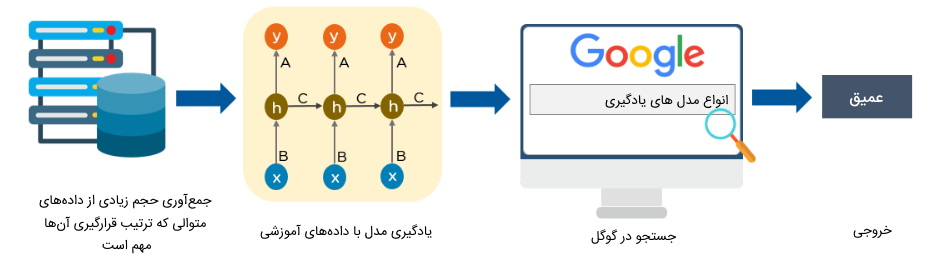
یکی از الگوریتم های یادگیری عمیق که دارای حافظه درونی هستند، «مدل عصبی بازگشتی» (Recurrent Neural Network | RNN) است. پیشفرض سایر الگوریتم های یادگیری عمیق این است که بین دادههای ورودی شبکه، هیچ گونه وابستگی وجود ندارد و دادهها از هم مستقل هستند. شبکه عصبی بازگشتی با داشتن یک حافظه درونی، مناسب مسائلی هستند که دادههای ورودی آنها به یکدیگر وابسته است و باید به ترتیب ورودی این دادهها توجه شود. مدل RNN از حافظه درونی خود برای نگهداری دادههای ورودی قبلی استفاده میکند تا بر اساس آنها به یادگیری داده جدید بپردازد.

از مسائل پیرامون پردازش زبان طبیعی میتوان به عنوان موضوعاتی یاد کرد که مدلهای عمیق بازگشتی، روشی مناسب برای پیادهسازی آنها هستند. به عبارتی، مدل برای یادگیری دادههای متنی، باید به ترتیب قرارگیری کلمات در جملات توجه کند. پیشبینی وضعیت بورس و سهام و پیشبینی وضعیت آب و هوا نیز میتوانند از دیگر مسائلی باشند که با شبکه عصبی بازگشتی پیادهسازی میشوند.
الگوریتم یادگیری عمیق بازگشتی چگونه کار می کند ؟
مدل عمیق بازگشتی از یک سری گرههای متصل جهتدار تشکیل شده است که یک حلقه را شکل میدهند. اگر مسائل سری زمانی را در نظر بگیریم که در زمان t، دادهای به مدل عصبی بازگشتی وارد میشود، خروجی داده در زمان t، به همراه داده جدید در زمان t+1 به عنوان ورودی به مدل وارد میشوند. بدینترتیب، در زمان t+1 برای پردازش داده جدید، مدل به اطلاعاتی از دادههای قبلی خود نیز دسترسی دارد.
کاربردهای شبکه عصبی RNN چیست ؟
از شبکه عصبی بازگشتی برای مسائل مختلف مبتنی بر سری زمانی نظیر پردازش زبان طبیعی استفاده میشود که ورودیهای شبکه به هم وابسته هستند. به عنوان مثال، موتورهای جستجوی شرکت گوگل از این مدل برای پیشنهاد کلمات به کاربران استفاده میکنند. به عبارتی، زمانی که کاربر قصد دارد عبارتی را در سایت گوگل جستجو کند تا سایتهای مرتبط با آن عبارات کلیدی را مشاهده کند، موتور جستجوی گوگل برای تکمیل عبارت کلیدی کاربر، کلماتی را به او پیشنهاد میکند.
مزایا و معایب شبکه عصبی بازگشتی چیست ؟
یکی از نقاط ضعف اصلی شبکههای عصبی اولیه این بود که هیچ گونه وابستگی بین ورودیهای شبکه در نظر نمیگرفتند. به همین خاطر، این نوع شبکهها کارایی خوبی برای مسائلی از نوع سری زمانی نداشتند. شبکه عصبی بازگشتی با داشتن یک حافظه درونی، ترتیب دادههای قبلی را درون خود حفظ و از آنها برای یادگیری داده ورودی جدید استفاده میکند.
یکی دیگر از مزیتهای شبکه عصبی بازگشتی این است که ورودیهایی با طول متفاوت را دریافت میکنند. سایر شبکههای عصبی فقط ورودیهایی با طولهای یکسان را دریافت میکردند. این نوع شبکهها برای یادگیری مسائلی نظیر پردازش زبان طبیعی مناسب نیستند، زیرا طول جملات زبان طبیعی متفاوت هستند. ساختار حلقهای شبکههای عصبی بازگشتی برای یادگیری این نوع مسائل مناسب است.
مدلهای RNN به دلیل داشتن ساختار حلقهای، به زمان بیشتری برای انجام محاسبات در زمان یادگیری احتیاج دارند. این موضوع به عنوان یکی از معایب این نوع از الگوریتم های یادگیری عمیق محسوب میشود.
بهعلاوه، زمانی که طول دادههای ورودی در زمان آموزش مدل بسیار زیاد میشود و از توابع فعالسازی ReLU و Tanh در مدل عمیق بازگشتی استفاده شده باشد، احتمال رخداد «محوشدگی گرادیان» (Vanishing Gradient) و «انفجار گرادیان» (Exploding Gradient) بالا میرود.
۶. شبکه عصبی با حافظه طولانی کوتاه مدت
شبکه عصبی «با حافظه طولانی کوتاه مدت» (Long Short-Term Memory | LSTM) به عنوان یکی دیگر از الگوریتم های یادگیری عمیق شناخته میشوند که دارای حافظه درونی هستند. این نوع شبکهها، نوعی از شبکههای عصبی RNN محسوب میشوند که میتوانند دادههایی با طول بیشتر را یاد بگیرند.
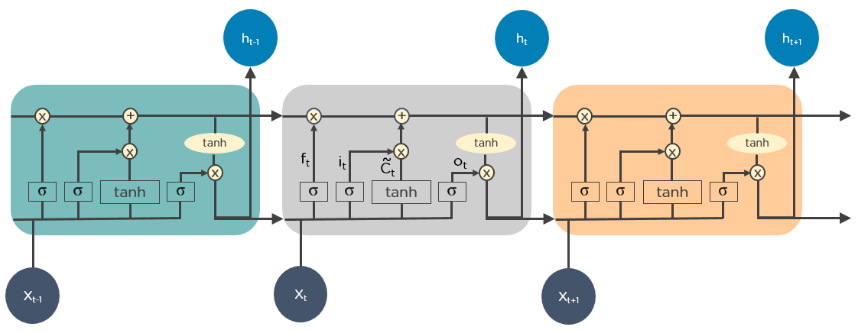
مدل LSTM چگونه کار می کند ؟
مدل LSTM نیز ساختار حلقهای دارد و به ازای تعداد اجزای داده ورودی، عمل یادگیری و پردازش دادهها تکرار میشود. شبکه عصبی LSTM دادههای غیرمرتبط و بیاهمیت قبلی را در زمان پردازش داده جدید حذف میکند و تنها اطلاعات مهم دادههای قبلی را در حافظه خود نگه میدارد.
چنانچه نیاز به بهروزرسانی اطلاعات قبلی نیز باشد، این کار توسط توابع درون این شبکه انجام میشود.
کاربردهای مدل LSTM چیست ؟
از شبکه عصبی LSTM نیز همانند مدل RNN در مسائلی استفاده میشود که دادههای ورودی به هم وابسته هستند. در پیادهسازی الگوریتم های یادگیری عمیق پیرامون موضوعات مرتبط با سریهای زمانی و پردازش زبان طبیعی میتوان از این نوع شبکه بهره گرفت.
مزایا و معایب شبکه عصبی LSTM چیست ؟
مزیتهای مدل LSTM مشابه با مزیت شبکه عصبی RNN است و علاوهبر ویژگیهای RNN، این مدل میتواند دادههایی با طول بیشتر را نیز بهتر از مدل RNN یاد بگیرد.
حجم محاسباتی و زمان بالا برای یادگیری از معایب مدل LSTM محسوب میشوند. همچنین، احتمال بروز رویداد «بیش برازش» (Overfitting) در مدل LSTM بالاست و باید از روشهای مختلفی برای جلوگیری از این رخداد استفاده کرد.
۷. شبکه مولد تخاصمی
یکی دیگر از الگوریتم های یادگیری عمیق، «شبکه مولد تخاصمی» (Generative Adversarial Network | GAN) است که از آن برای تولید نمونههای جدیدی از دادهها استفاده میشود که مشابه با دادههای آموزشی باشند.

شبکه GAN یکی از الگوریتم های یادگیری عمیق نظارت نشده محسوب میشود که تنها با در اختیار داشتن دادههای آموزشی و بدون نیاز به برچسب، به یادگیری الگوهای آنها میپردازد.
الگوریتم یادگیری عمیق GAN چگونه کار می کند ؟
مدل GAN از دو شبکه عصبی تشکیل شده است که در ادامه به کاربرد هر یک از آنها اشاره شده است:
- «شبکه مولد» (Generator Network): این شبکه عصبی سعی دارد نمونههایی را تولید کند که مشابه با دادههای آموزشی واقعی باشند.
- «شبکه تمیزدهنده» (Discriminator Network): این شبکه مسئولیت ارزیابی نمونههای تولید شده توسط شبکه مولد را بر عهده دارد و مشخص میکند آیا داده ورودی متعلق به دادههای واقعی هستند یا توسط شبکه مولد تولید شدهاند.
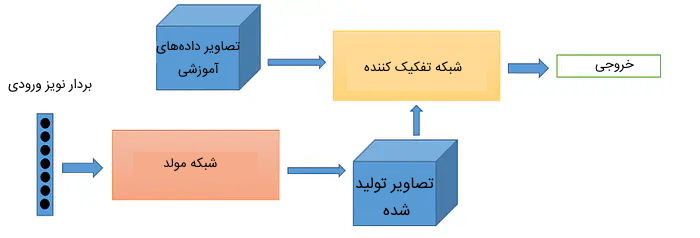
هر دو شبکه مولد و تمیزدهنده در حین یادگیری سعی دارند عملکرد بهتری نسبت به یکدیگر داشته باشند. به عبارتی، شبکه مولد با در نظر گرفتن خروجی شبکه تمیزدهنده سعی میکند نمونههای تولیدی خود را به دادههای واقعی بیشتر شبیه کند تا شبکه تمیزدهنده قادر نباشد نمونههای تولید شده را از دادههای واقعی تشخیص دهد. شبکه تمیزدهنده نیز سعی دارد دادههای واقعی و دادههای ساخته شده (جعلی) را بهخوبی از هم تشخیص دهد.
کاربردهای مدل GAN چیست ؟
از شبکه عصبی GAN در بازیهای کامپیوتری به منظور افزایش کیفیت تصاویر استفاده میشود. همچنین، کاربردهای دیگر این مدل را میتوان در ویرایش تصاویر، تولید تصاویر جعلی که به تصاویر واقعی شباهت زیاد دارند، تولید متون مختلف علمی و غیرعلمی و سایر موارد مشابه ملاحظه کرد.
مزایا و معایب شبکه عصبی GAN چیست ؟
مدل GAN مبتنی بر رویکرد یادگیری بدون نظارت است. بنابراین، برای آموزش این مدل نیازی به فراهم کردن دادههای آموزشی برچسبدار نیست. همین امر، زمان آمادهسازی دادههای مورد نیاز شبکه GAN را بهطرز چشمگیری کاهش میدهد.
یکی از معایب این شبکه این است که نمیتوان برای ارزیابی نمونههای تولید شده، معیار مشخصی را تعریف کرد. به عبارتی، نمیتوان بهطور دقیق میزان دقت مدل را سنجید. همچنین، میزان بار محاسباتی و زمان یادگیری این مدل بالا است و نحوه استفاده از این مدل برای تولید متن و صوت بسیار پیچیدهتر از دادههای تصویری است.
۸. مدل ترسیم خودسازمان دهنده چیست ؟
یکی از الگوریتم های یادگیری عمیق که برای مدلسازی دادهها با ابعاد بالا استفاده میشود، مدل ترسیم خودسازمان دهنده یا SOM است. زمانی که حجم عظیمی از دادهها را در اختیار داشته باشید که هر کدام از آنها، دارای ویژگیهای زیادی هستند، به منظور درک بهتر روابط بین ویژگیها نمیتوان بهراحتی از ابزارهای عادی مصورسازی داده نظیر «نمودار پراکندگی» (Scatter Plot) استفاده کرد.
در این حالت، بهترین روش نمایش ویژگیها، استفاده از مدل SOM است. این مدل برای تصویرسازی ویژگیها، ابعاد دادهها را کاهش میدهد و ویژگیهای غیرمرتبط را حذف میکند.
الگوریتم یادگیری عمیق SOM چگونه کار می کند ؟
مدل SOM دادههای مشابه را دستهبندی میکند و آنها را بهشکل دادههای یک بعدی یا دو بعدی به نمایش در میآورد. نحوه عملکرد این مدل، مشابه با سایر الگوریتم های یادگیری عمیق است. در ابتدای زمان یادگیری مدل، وزنهای شبکه بهصورت تصادفی مقداردهی اولیه میشوند و در هر گام از یادگیری شبکه، یک داده آموزشی جدید به مدل ارسال و میزان شباهت آن با سایر دادهها سنجیده میشود.
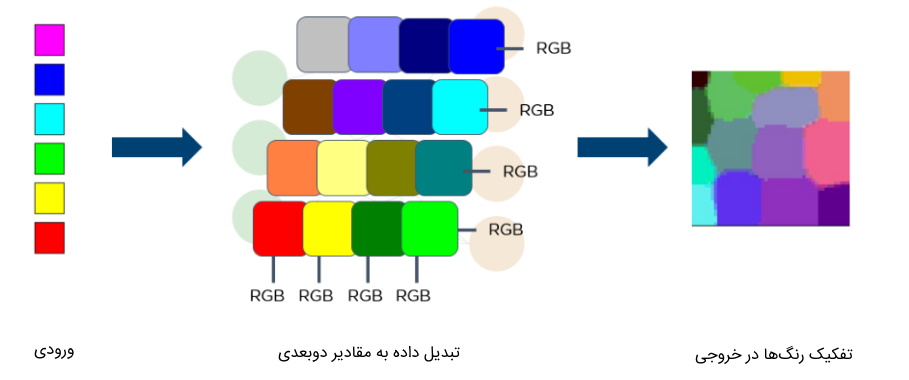
مدل SOM دارای بخشی به نام «واحد بهترین انطباق» (Best-Matching Unit | BMU) است که نزدیکترین داده آموزشی به نمونه انتخاب شده را مشخص میکند و پس از بهروزرسانی بردار وزنهای آن، فاصله سایر دادههای آموزشی مشابه به نمونه جدید نیز کمتر میشود. با تکرار این روال یادگیری، دادههای مشابه در فضای دو بعدی در مجاورت هم قرار خواهند گرفت.
کاربردهای مدل SOM چیست ؟
در تحلیل تصاویر و مانیتورینگ پردازشها و کنترل آنها میتوان از مدل SOM استفاده کرد. همچنین، از این مدل میتوان برای مدلسازی سه بعدی مغز انسان بهره گرفت و با استفاده از آن تصویرسازیهای دقیقی از مغز انسان ایجاد کرد که در امور پزشکی از اهمیت بالایی برخوردار هستند.

مزایا و معایب شبکه عصبی SOM چیست ؟
تفسیر و درک دادهها با استفاده از مدل SOM ساده میشود که همین امر به عنوان یکی از مهمترین مزیتهای این مدل به حساب میآید. بهعلاوه، از آنجایی که این مدل ابعاد دادهها را کاهش میدهد، میتوان بهراحتی دادههای مشابه را با ابعاد کمتر مصورسازی کرد.
به عنوان یکی از اصلیترین معایب مدل SOM میتوان به این نکته اشاره کرد که این مدل یادگیری عمیق برای مسائلی که حجم داده آموزشی آنها خیلی کم یا خیلی زیاد است، مناسب نیست، زیرا مدل نمیتواند اطلاعات دقیقی را در خروجی به تصویر بکشد.
۹. مدل ماشین بولتزمن محدود شده
مدل RBM یکی از الگوریتم های یادگیری عمیق قدیمی محسوب میشود که در سال 1986 توسط «جفری هینتون» (Geoffrey Hinton) ارائه شد. این مدل برای یادگیری مسائل از رویکرد بدون نظارت تبعیت میکند و نیازی به دادههای آموزشی برچسبدار ندارد. اگر ویدئویی را در سایت «یوتیوب» (YouTube) جستجو کرده باشید، متوجه میشوید که این سایت، ویدئوهای مشابه آن را به شما پیشنهاد میدهد. مدل به کار رفته در این سایت برای پیشنهاد دادن ویدئوهای مشابه با ویدئوی منتخب شما، مدل RBM است.
الگوریتم یادگیری عمیق RBM چگونه کار می کند ؟
شبکه عصبی RBM از دو لایه تشکیل شده است. لایه اول این مدل، لایه ورودی است که لایه «مرئی» نیز نامیده میشود. لایه دوم RBM لایه پنهان شبکه است. هدف از این شبکه، به نوعی کدگذاری دادههای ورودی در مرحله «رو به جلو» (Forward) است.

در مرحله «رو به عقب» (Backward) مدل سعی دارد خروجیای تولید کند که با داده ورودی مشابهت داشته باشد. به عبارتی، میتوان گفت داده ورودی کدگذاری شده در مرحله رو به جلو، در روند رو به عقب کدگشایی میشود. روند یادگیری شبکه آنقدر تکرار میشود تا دادههای ورودی با خروجیهای مدل بیشترین شباهت را داشته باشند.
کاربردهای مدل RBM چیست ؟
همان طور که در بخش معرفی مدل RBM اشاره شد، از این شبکه عصبی برای ارائه پیشنهادات مشابه با آیتمهای جستجو شده توسط کاربر استفاده میشود. همچنین، کاربردهای دیگر این مدل را میتوان در مسائلی نظیر استخراج ویژگی در «بازشناسی الگو» (Pattern Recognition)، «موتورهای پیشنهاد دهنده» (Recommendation Engines)، مسائل دستهبندی و «مدلسازی موضوع» (Topic Modeling) ملاحظه کرد.
مزایا و معایب شبکه عصبی RBM چیست ؟
از آنجایی که مدل ماشین بولتزمن محدود شده از رویکرد نظارت نشده برای یادگیری مسائل استفاده میکند، نیازی به صرف وقت اضافی برای تهیه برچسبهای دادههای آموزشی آن نیست. بدین ترتیب، در زمان حل مسئله صرفهجویی بهسزایی میشود. بهعلاوه، بار محاسباتی و زمان آموزش این مدل در مقایسه با سایر الگوریتم های یادگیری عمیق کم است، زیرا این مدل ساختاری ساده و تعداد لایههای محدود دارد.
مدل RBM برای بهروزرسانی وزنهای شبکه در مرحله رو به عقب از الگوریتمی استفاده میکند که در مقایسه با الگوریتم پس انتشار به کار رفته در سایر مدلهای یادگیری عمیق، عملکرد ضعیفتری دارد و همین امر در پیدا کردن وزنهای مناسب شبکه تاثیرگذار است.
۱۰. مدل خودرمزگذار
مدل خودرمزگذار (Autoencoder) به عنوان یکی از الگوریتم های یادگیری عمیق تلقی میشود که از رویکرد نظارت نشده برای یادگیری دادههای آموزشی استفاده میکند. هدف این نوع مدل، تولید خروجیهایی است که مشابه با ورودیهای خود باشد.
الگوریتم یادگیری عمیق Autoencoder چگونه کار می کند ؟
مدل Autoencoder از سه بخش اصلی «رمزگذار» (Encoder)، «کد» (Code) و «رمزگشا» (Decoder) ساخته شده است که در ادامه به توضیح هر بخش پرداخته میشود:
- بخش رمزگذار: بخش رمزگذار، دادهها را از ورودی دریافت و آنها را فشرده میکند. این عملیات فشردهسازی به نحوی انجام میشود که بتوان داده فشرده شده را در بخش رمزگشا به حالت اولیه خود بازگرداند.
- بخش کد: به داده فشرده توسط بخش رمزگذار، کد گفته میشود که ورودی بخش رمزگشا است.
- بخش رمزگشا: بخش رمزگشا کد دریافت شده را رمزگشایی میکند تا داده اصلی بازگردانده شود.
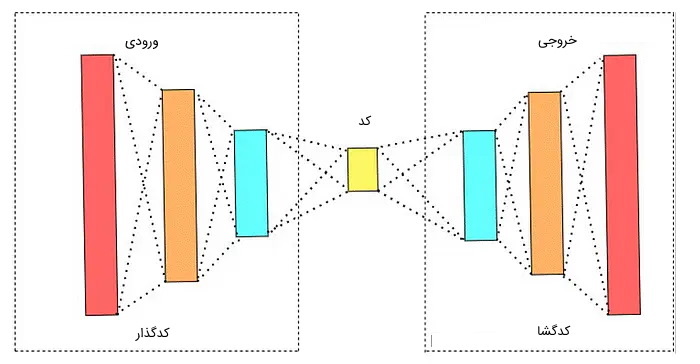
کاربردهای مدل Autoencoder چیست ؟
یکی از کاربردهای مهم مدل Autoencoder، کاهش ابعاد دادهها است. به عبارتی، از این مدل میتوان برای فشردهسازی دادهها استفاده کرد و مدل میتواند در هر زمان که کاربر به داده اصلی احتیاج دارد، دادههای فشرده شده را به حالت اصلی برگرداند.
علاوهبراین، از این مدل در حوزه پزشکی به منظور تحلیل تصاویر پزشکی نظیر تشخیص سرطان سینه استفاده میشود.
مزایا و معایب شبکه عصبی Autoencoder چیست ؟
از آنجایی که مدل Autoencoder ابعاد دادهها را با حفظ اطلاعات مهم آنها کاهش میدهد، میتوان از دادههای کد شده در سایر الگوریتم های یادگیری عمیق استفاده کرد تا بار محاسباتی یادگیری مدل کاهش پیدا کند.
از معایب مدل Autoencoder میتوان به این نکته اشاره کرد که مدل خودرمزگذار در مقایسه با مدل مولد تخاصمی (GAN) نمیتواند بهخوبی تصاویر را بازسازی کند. همچنین، زمانی که بخش رمزگذار مدل، داده ورودی را فشرده میکند، ممکن است اطلاعات مهمی از آن را نادیده بگیرد. همین امر باعث میشود بخش رمزگشا نتواند اطلاعات مهم را بازگرداند.
۱۱. مدل باور عمیق
«مدل باور عمیق» (Deep Belief Network | DBN) یکی از الگوریتم های یادگیری عمیق است که از چندین لایه ماشین بولتزمن محدود شده ساخته میشود. ساختار ظاهری این مدل مشابه با ساختار شبکه عصبی پرسپترون چند لایه است اما روال یادگیری DBN با نحوه یادگیری مدل پرسپترون تفاوت دارد.
الگوریتم یادگیری عمیق DBN چگونه کار می کند ؟
مدل DBN از چندین لایه ماشین بولتزمن محدود شده ساخته میشود. همان طور که در بخش توضیحات مربوط به مدل بولتزمن شرح داده شد، این مدل از دو لایه مرئی و پنهان تشکیل شده است. هر کدام از لایههای ماشین بولتزمن محدود شده در الگوریتم DBN نیز دارای دو لایه هستند که این لایهها پشت سر هر قرار گرفتهاند و خروجی هر ماشین بولتزمن به عنوان ورودی ماشین بولتزمن محدود شده بعدی در نظر گرفته میشود.

آموزش مدل DBN در ابتدا بهصورت نظارت نشده انجام میشود تا تمامی لایهها، ویژگیهای کلی دادههای ورودی را یاد بگیرند. این روال یادگیری با روند یادگیری سایر شبکههای عصبی نظیر CNN مغایرت دارد. در مدلهای CNN هر لایه به یادگیری بخشی از تصاویر میپردازند. به عنوان مثال، لایههای اولیه CNN تنها میتوانند خطوط تصاویر را شناسایی کنند و لایههای سطوح بالاتر، رنگبندی تصاویر را یاد میگیرند. اما در مدل DBN هر کدام از شبکههای ماشین بولتزمن محدود شده قادر هستند تمامی ویژگیهای دادههای ورودی را یاد بگیرند. همین امر سبب میشود مدل با دقت بیشتری به شناسایی الگوها بپردازد.
در انتهای آموزش مدل DBN نیز میتوان از مجموعه محدودی از دادههای آموزشی برچسبدار نیز استفاده کرد تا در نهایت بتوان از این مدل به عنوان یک «دستهبند» (Classifier) در حل مسائل مختلف استفاده کرد.
کاربردهای مدل DBN چیست ؟
از مدل باور عمیق میتوان برای حل بسیاری از مسائل دنیای واقعی نظیر تشخیص اشیاء در تصاویر، تولید تصاویر، دستهبندی تصاویر، تشخیص اشیاء در دادههای ویدئویی، تحلیل احساسات، پردازش زبان طبیعی و تشخیص گفتار استفاده کرد.

مزایا و معایب شبکه عصبی DBN چیست ؟
از مزایای مهم مدل DBN میتوان به این نکته اشاره کرد زمانی که حجم داده آموزشی برچسبدار برای مسئله تعریف شده محدود است، میتوان از این مدل برای پیادهسازی مسئله استفاده کرد. همچنین، با اضافه کردن تعداد لایههای مدل DBN، این مدل در مقایسه با مدل پرسپترون چند لایه در مسائل دستهبندی به دقت بالاتری میرسد.
یکی از معایب اصلی مدل باور عمیق این است که به تجهیزات سختافزاری خاصی برای پیادهسازی احتیاج دارد. همچنین، این مدل به زمان آموزش بیشتری احتیاج دارد، زیرا دارای ساختار پیچیدهای است. بهعلاوه، به دلیل پیچیدگی پیادهسازی این مدل، افراد تازهکار نمیتوانند بهراحتی از آن برای حل مسائل استفاده کنند.
۱۲. مدل رمزگذار-رمزگشا
مدلهای رمزگذار-رمزگشا به عنوان یکی از الگوریتم های یادگیری عمیق شاخته میشوند که هدف آنها نگاشت کردن دادههای ورودی به مقادیر خروجی است به نحوی که طول ورودیها با طول مقادیر خروجی یکسان نباشند. این حالت را میتوان در ترجمه زبان مبدأ به زبان مقصد مشاهده کرد. در مسئله ترجمه زبان، نمیتوان هر کلمه از زبان مبدأ را به یکی از کلمات زبان مقصد نگاشت (ترجمه) کرد و بدین ترتیب، طول جملات زبان مبدأ با طول جملات ترجمه شده آن در زبان مقصد با یکدیگر متفاوت هستند.
الگوریتم یادگیری عمیق Encoder Decoder چگونه کار می کند ؟
مدلهای Encoder-Decoder از سه بخش اصلی تشکیل شدهاند که در ادامه به آنها اشاره میشود:
- بخش رمزگذار: بخش رمزگذار شامل یکی از انواع شبکههای عصبی بازگشتی نظیر RNN یا LSTM است که دادههای ورودی را دریافت میکند و در هر گام از پردازش دادههای ورودی، اطلاعات کلیه دادههای قبلی به گام بعدی منتقل میشود تا در نهایت برداری از اطلاعات کلی دادههای ورودی حاصل شود.
- بردار رمزگذاری شده: بردار خروجی بخش رمزگذار، بردار رمزگذاری شده نام دارد که به عنوان ورودی بخش رمزگشا در نظر گرفته میشود.
- بخش رمزگشا: این بخش شامل یکی از انواع شبکههای بازگشتی است که با دریافت بردار رمزگذاری شده، به رمزگشایی اطلاعات آن میپردازد.
در ادامه، تصویری از نحوه عملکرد این نوع مدل در مسئله ترجمه ماشین ملاحظه میشود.

کاربردهای مدل مرزگذار-رمزگشا چیست ؟
از مدل Encoder-Decoder در مسائل مختلفی استفاده میشود که یکی از آنها، موضوع ترجمه ماشینی است. بهعلاوه، از این مدل میتوان در تولید متونی استفاده کرد که تصویری را شرح میدهند. در این نوع مسئله، ورودی مدل رمزگذار-رمزگشا مجموعهای از تصاویر است و مدل بر اساس ویژگیهای موجود در تصاویر، به شرح رویداد ثبت شده عکس میپردازد.
مزایا و معایب شبکه عصبی رمزگذار-رمزگشا چیست ؟
در مسائلی که طول دادههای ورودی به طول دادههای خروجی وابسته نیستند، نمیتوان از شبکههای عصبی ذکر شده در بخشهای پیشین استفاده کرد. مدلهای Encoder-Decoder برای حل چنین مسائلی استفاده میشوند که همین امر، برتری این مدل را نسبت به سایر مدلهای عمیق نشان میدهد.
مدل رمزگذار-رمزگشا از دو شبکه عصبی ساخته شده است که هر یک از آنها رمزگذاری و رمزگشایی دادهها را بر عهده دارند. هر چقدر طول دادههای ورودی این مدل بیشتر باشد و در پی آن تعداد لایههای این شبکه افزایش یابد، بار محاسباتی یادگیری شبکه بیشتر میشود که این امر به عنوان یکی از معایب این مدل به حساب میآید. همچنین، از آنجایی که در ساختار درونی این مدل از مدلهای بازگشتی استفاده شده است، ممکن است مدل Encoder-Decoder با مشکلات مدلهای بازگشتی، مخصوصاً مشکل محو شدگی گرادیان، روبهرو شود.
۱۳. مدل عصبی ماژولار
مدلهای عمیق ماژولار یکی از الگوریتم های یادگیری عمیق محسوب میشوند که از چندین شبکه عصبی مختلف تشکیل شدهاند. از این نوع مدلهای عمیق برای پیادهسازی مسائل پیچیده استفاده میشود و هر یک از شبکههای عصبی مجزای موجود در این مدلها، برای یادگیری بخشهای مختلف مسئله به کار میروند.
الگوریتم یادگیری عمیق Modular چگونه کار می کند ؟
هر یک از شبکههای عصبی موجود در مدل عمیق ماژولار، به عنوان یک ماژول مجزا تلقی میشوند. در این مدل، یک بخشی به نام «یکپارچهساز» (Integrator) وجود دارد که مسئله را به چندین بخش تقسیم میکند و یادگیری هر بخش را به یکی از ماژولهای مدل تخصیص میدهد. همچنین، بخش یکپارچهساز خروجیهای هر یک از ماژولها را با یکدیگر یکپارچه میکند تا در نهایت خروجی سیستم مشخص شود.
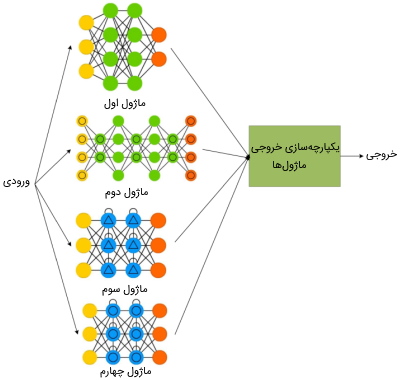
کاربردهای مدل عمیق Modular چیست ؟
ایده طراحی ساختار مدل ماژولار از مفاهیم بیولوژیکی نشأت گرفته شده است. بر اساس مطالعات علوم شناختی، هر ناحیه از مغز نقش مجزایی را برای پردازشهای دادههای دریافتی بر عهده دارند. از مدل عمیق ماژولار به منظور حل مسائل پیچیدهای میتوان استفاده کرد که هر یک از بخشهای شبکه مسئول انجام پردازشی خاص هستند. همین امر، باعث سادهسازی درک مسائل پیچیده میشود.
مزایا و معایب شبکه عصبی Modular چیست ؟
یکی از مزیتهای مدل عمیق ماژولار این است که میتوان بهراحتی، تعداد ماژولهای (زیر شبکههای عصبی) مدل را افزایش داد. همچنین، چنانچه در یادگیری یکی از ماژولها خللی ایجاد شود، در روال یادگیری سایر ماژولها تاثیر منفی ایجاد نمیشود. بهعلاوه، عملکرد این نوع از الگوریتم یادگیری عمیق در مقایسه با سایر مدلهای شبکه عصبی تفسیرپذیرتر است، زیرا میتوان بهراحتی مشخص کرد که هر یک از ماژولها چه عملکردی دارند.
یکی از مهمترین معایب مدل ماژولار این است که روال یادگیری آن در مقایسه با سایر مدلهای عمیق بهکندی انجام میشود، زیرا دادههای ورودی باید از چندین ماژول عبور کنند تا در نهایت با یکپارچهسازی خروجی ماژولها، خروجی نهایی مدل ماژولار مشخص شود. بهعلاوه، پیادهسازی و آموزش جداگانه ماژولها و یکپارچهسازی نتایج آنها پیچیده است. افزونبراین، هر یک از ماژولهای موجود در مدل Modular در حین یادگیری، اطلاعاتی را بین خود منتقل میکنند که همین امر سبب افزایش زمان آموزش مدل میشود.
جمعبندی
کاربرد سیستمهای هوشمند مصنوعی را تقریباً میتوان در تمامی جنبههای زندگی بشر ملاحظه کرد. این سیستمها بر پایه یک سری الگوریتم های ریاضیاتی به یادگیری مسائل مختلف میپردازند و پس از آموزش، بدون نیاز به دخالت انسان میتوانند از پس انجام مسئولیت مشخص شده برآیند. یادگیری عمیق به عنوان یکی از زیرشاخههای هوش مصنوعی، شامل مباحثی پیرامون الگوریتم ها و روشهای مختلف یادگیری سیستمها است تا برنامهها و سیستم های سختافزاری هوشمندی را بر پایه آنها آموزش داد.
در مطلب حاضر سعی بر این بود تا روال کلی یادگیری الگوریتم های یادگیری عمیق شرح داده شوند و سپس رایجترین مدلهای موجود در حوزه یادگیری عمیق به لحاظ ساختار، کاربرد و مزایا و معایب مورد بررسی قرار گیرند.








