



انواع سلول ها و لایه ها در شبکه های عصبی – راهنمای جامع
در این مطلب، انواع سلول ها و لایه ها در شبکه های عصبی مورد بررسی قرار خواهد گرفت. خانواده روشهای محاسباتی نوین «شبکههای عصبی» (Neural Networks) اعضای متعددی دارد و هر روز نیز بر تعداد آنها افزوده میشود. پیش از این، در مطلب «انواع شبکه های عصبی مصنوعی — راهنمای جامع»، انواع شبکههای عصبی که عناوین آنها در زیر بیان شده است، مورد بررسی قرار گرفتند.




- «پرسپترون» (Perceptron | P)
- «شبکههای عصبی پیشخور» (Feed Forward Neural Networks | FF)
- «شبکههای عصبی شعاعی پایه» (Radial Basis Networks | RBF)
- «شبکه عصبی پیشخور عمیق» (Deep Feed Forward Neural Networks | DFF)
- «شبکههای عصبی بازگشتی» (Recurrent Neural Networks | RNN)
- «حافظه کوتاه مدت بلند» (Long/Short Term Memory | LSTM)
- «واحد بازگشتی گیتی» (Gated Recurrent Unit | GRU)
- «خود رمزگذار» (Auto Encoder | AE)
- «خود رمزگذار متغیر» (Variational Auto Encoder | VAE)
- «خود رمزگذار دینوزینگ» (Denoising AutoEncoder | DAE)
- «خود رمزگذار اسپارس» (Sparse AutoEncoder | SAE)
- «زنجیرههای مارکو» (Markov Chains)
- «شبکههای هاپفیلد» (Hopfield Networks | HN)
- «ماشینهای بولتزمن» (Boltzmann Machines | BM)
- «ماشین بولتزمن محدود» (Restricted Boltzmann Machine)
- «شبکه باور عمیق» (Deep Belief Network | DBN)
- «شبکه پیچشی عمیق» (Deep Convolutional Network | DCN)
- «شبکه دکانولوشنی» (Deconvolution Network | DN)
- «شبکه گرافیکی معکوس پیچشی عمیق» (Deep Convolutional Inverse Graphics Network | DCIGN)
- «شبکههای مولد تخاصمی» (Generative Adversarial Networks)
- «ماشین حالت سیال» (Liquid State Machine | LSM)
- «ماشین یادگیری حداکثری» (Extreme Learning Machine | ELM)
- «شبکه حالت پژواک» (Echo State Network | ESN)
- «شبکه باقیمانده عمیق» (Deep Residual Network | DRN)
- «شبکه عصبی کوهنن» (Kohonen Network | KN)
- «ماشین بردار پشتیبان» (Support Vector Machine | SVM)
- «ماشین تورینگ عصبی» (Neural Turing Machine | NTM)
در این مطلب، انواع «سلولها» (Cells) و «لایهها» (Layers) در شبکههای عصبی مصنوعی، مورد بررسی قرار خواهند گرفت.
انواع سلولها در شبکههای عصبی مصنوعی
همانطور که در مطلب «انواع شبکه های عصبی مصنوعی — راهنمای جامع» مشخص است، شبکههای عصبی دارای انواع مختلفی از سلولها و قالبهای متنوع اتصال لایهها هستند. در این مطلب، انواع سلول ها و لایه ها در شبکه های عصبی مورد بررسی قرار خواهد گرفت.
در این بخش، چگونگی عملکرد هر نوع سلول تشریح میشود. در اینجا، به انواع مختلف سلولها رنگهای متفاوتی داده شده است تا تمایز شبکهها راحتتر باشد. البته میتوان گفت که این شبکهها تقریبا به شیوه مشابهی عمل میکنند.
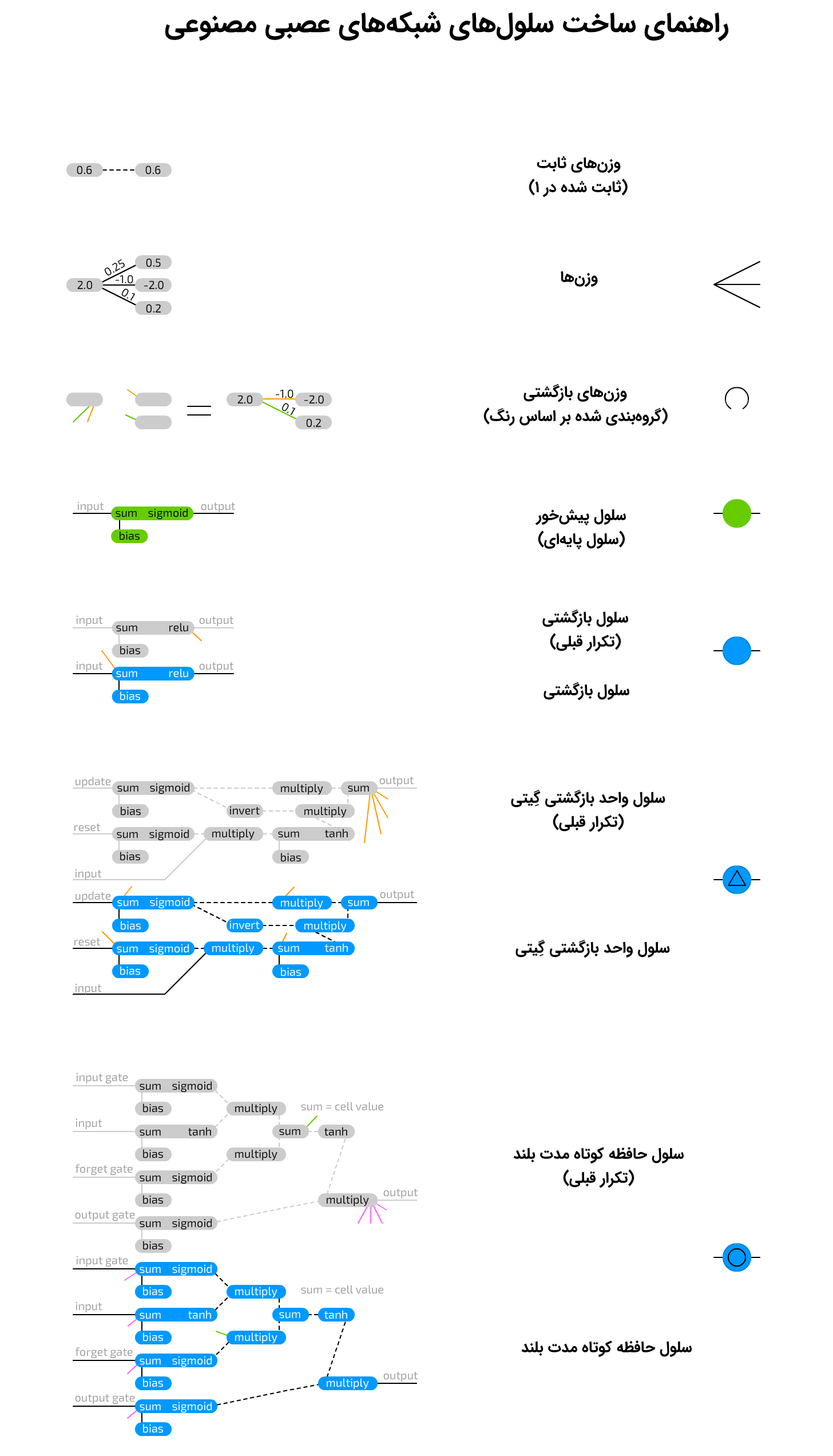
برای مشاهده تصویر در ابعاد بزرگ، روی آن کلیک کنید.
در ادامه، توضیحات مربوط به هر سلول همراه با تصویر آن، ارائه شده است.
سلول پایهای در شبکههای عصبی

این نوع سلول، در معماری شبکههای معمول «پیشخور» (Feed Forward) وجود دارد و ساختار آن کاملا ساده است. این نوع از سلول، با وزنهایی به دیگر نورونها متصل شده است. در واقع، این سلول میتواند به همه نورونهای موجود در لایه پیشین متصل شود. هر اتصال، وزن خود را دارد که در ابتدا، صرفا یک عدد تصادفی است. وزن میتواند مقداری منفی، مثبت، بسیار کوچک، بسیار بزرگ و یا صفر باشد. مقدار هر یک از سلولهایی که به آن متصل شدهاند، در وزن اتصال مربوط به آن ضرب میشود.
مقادیر حاصل، همه با هم جمع میشوند. علاوه بر اینها، یک مقدار «سوگیری» (Bias) نیز اضافه میشود. سوگیری میتواند مانع از آن شود که یک سلول در خروجی دادن صفر گیر کند و همچنین، میتواند برخی از عملیات را با کاهش مقدار نورونهای لازم برای حل مسئله، سرعت ببخشد. سوگیری نیز یک عدد است؛ این عدد گاهی مقداری ثابت (معمولا بین ۱- و ۱) و گاهی یک متغیر است. این مجموع کل، از طریق یک تابع فعالسازی پاس داده میشود و مقدار حاصل، در نهایت مقدار سلول میشود.
سلولهای پیچشی
«سلولهای پیچشی» (Convolutional Cells) شباهت زیادی به سلولهای پیشخور دارند، با این تفاوت که معمولا فقط به چند نورون از لایه قبلی خود متصل هستند. این نوع از سلولها معمولا برای حفظ اطلاعات مکانی مورد استفاده قرار میگیرند، زیرا آنها به چند سلول تصادفی متصل نیستند، بلکه به همه سلولها در یک مجاورت خاص متصل هستند. این امر موجب میشود که این سلولها برای دادههایی با میزان زیادی اطلاعات محلی، مانند تصاویر و امواج صدا (اما بیشتر تصاویر) مناسب باشند.
«سلولهای دکانولوشنی» (Deconvolutional Cells) مخالف این مورد هستند؛ آنها با اتصال به لایه بعدی به صورت محلی، به رمزگشایی اطلاعات مکانی مبادرت میورزند. هر دو سلول معمولا تعداد زیادی کلون دارند که به طور مستقل از هم آموزش داده شدهاند. هر کلون وزن خود را دارد، اما به طور دقیقا مشابهی متصل شده است. پیرامون این کلونها میتوان چنین اندیشید که در شبکههای مجزایی قرار گرفتهاند که همه دارای ساختار مشابهی هستند. هر دو اساسا مشابه با سلولهای عادی هستند، اما به شیوه متفاوتی مورد استفاده قرار میگیرند.
سلولهای پولینگ و درونیابی
سلولهای «پولینگ» (Pooling) و «درونیابی» (Interpolating) غالبا با سلولهای پیچشی ترکیب میشوند. این سلولها واقعا سلول نیستند، بلکه بیشتر عملکردهای خام هستند. سلولهای پولینگ اتصالات ورودی را دریافت میکنند و تصمیم میگیرند که کدام اتصالات از آنها عبور میکنند. در تصاویر، به این سلولها میتوان به عنوان بزرگنمایی روی یک تصویر نگاه کرد. کاربر دیگر نمیتواند همه پیکسلها را ببیند و باید بیاموزد که کدام پیکسلها را حفظ کند و کدام موارد را کنار بگذارد.
سلولهای درونیابی، عملکردی مخالف سلولهای پولینگ دارند. آنها اطلاعاتی را از ورودی دریافت و آنها را به اطلاعات بیشتری نگاشت میکنند. در نتیجه، اطلاعات اضافی ساخته میشوند، مانند آنکه شخصی روی یک تصویر دارای رزولوشن پایین بزرگنمایی کند. سلولهای درونیابی، فقط عملکرد معکوس سلولهای پولینگ را ندارند، بلکه نسبت به آنها بیشتر متداول هستند؛ زیرا پیادهسازی آنها سریع و آسان است. این نوع از سلولها به ترتیب، مشابه با سلولهای پیچشی و دکانولوشنی هستند.
سلولهای میانگین و انحراف معیار
«سلولهای میانگین» (Mean Cells) و «سلولهای انحراف معیار» (Standard Deviation Cells) برای ارائه توزیعهای احتمال مورد استفاده قرار میگیرند. میانگین یک مقدار متوسط است و انحراف معیار نشان میدهد که چقدر انحراف از این مقدار میانگین وجود دارد (در هر دو جهت). برای مثال، یک سلول احتمالی که برای تصاویر استفاده میشود میتواند شامل اطلاعاتی پیرامون این باشد که که چه میزان رنگ قرمز در یک پیکسل مشخص وجود دارد. به عنوان مثال، میانگین مقدار 0/5 و انحراف معیار مقدار ۰/۲ را دارا است.
هنگام نمونهبرداری از این سلولهای احتمالی، فرد ممکن است این مقادیر را وارد یک «مولد عدد تصادفی گاوسی» (Gaussian Random Number Generator) کند؛ هر مقداری بین ۰/۴ و ۰/۶ نتیجهای محتمل است، در حالی که مقادیر دورتر از ۰/۵ با احتمال کم و کمتری میتوانند نتیجه باشند (اما احتمالا آنها همچنان وجود دارند). این سلولها معمولا به لایه قبلی یا بعدی کاملا متصل هستند و «سوگیری» (Bias) ندارند.
سلولهای بازگشتی
«سلولهای بازگشتی» (Recurrent Cells) نه فقط در قملرو لایهها، بلکه با گذر زمان نیز اتصالاتی دارند. هر سلول به صورت داخلی مقدار پیشین خود را ذخیره میکند. این سلولها مانند سلولهای پایهای، ولی با وزنهای اضافی، به روز رسانی میشوند. سلولهای بازگشتی به مقادیر پیشین سلولها متصل هستند و اغلب مواقع نیز به همه سلولها در لایه مشابه متصل هستند. این وزنها بین مقدار کنونی و مقدار ذخیره شده پیشین، بسیار شبیه به یک حافظه فرار (مانند حافظه با دسترسی تصادفی یا همان RAM) عمل میکنند و هر دو خصوصیت داشتن یک «حالت مشخص» و حذف شدن در صورت نداشتن «خوراک» را به ارث میبرند.

به دلیل آنکه مقدار پیشین مقداری است که از طریق تابع فعالسازی عبور داده میشود و هر به روز رسانی، این مقدار فعال شده را همراه با دیگر وزنها از طریق تابع فعالسازی عبور میدهد، اطلاعات به طور مستمر مفقود میشوند. در حقیقت، نرخ نگهداری بسیار پایین است و فقط چهار یا پنج تکرار بعد، تقریبا همه اطلاعات مفقود میشوند.

سلولهای حافظه کوتاه مدت بلند

«سلولهای حافظه کوتاه مدت بلند» (Long Short Term Memory Cells) برای مبارزه با مسئله از دست دادن (مفقود شدن) سریع اطلاعات که در سلولهای بازگشتی به وقوع میپیوندد، مورد استفاده قرار میگیرند. سلولهای LSTM، مدارهای منطقی هستند که از چگونگی ساخته شدن سلولهای حافظه انسان، برای کامپیوترها کپیبرداری شدهاند. در مقایسه با سلولهای RNN که دو حالت را ذخیره میکنند، سلولهای LSTM چهار حالت را ذخیره میکنند. این چهار حالت عبارتند از مقدار کنونی و آخرین خروجی و مقدار کنونی و آخرین مقدار از حالت «سلول حافظه».
این سلولها، دارای سه نوع گیت ورودی (Input)، خروجی (Output) و فراموشی (Forget) هستند و همچنین، فقط ورودی عادی دارند. هر یک از این گیتها، وزن خود را دارد. بدین معنا که متصل شدن به این نوع سلول، مستلزم راهاندازی چهار وزن (به جای یکی) است. تابع گیتها شباهت زیادی به «گیتهای جریان» (Flow Gates)، و نه «گیتهای حفاظتی» (Fence Gates)، دارد. این گیتها میتوانند هر چیزی و یا حتی هیچ چیز را از خود عبور دهند. این کار با چند برابر (ضرب) کردن اطلاعات ورودی در مقداری بین ۰ و ۱ انجام میشود که در این مقدار گیت ذخیره شده است.
سپس، گیت ورودی تعیین میکند که چه میزان ورودی برای اضافه شدن به مقدار سلول پذیرفته شده است. گیت خروجی تعیین میکند که چه میزان از مقدار خروجی به وسیله کل شبکه قابل مشاهده است. گیت فراموشی به مقدار پیشین سلول خروجی متصل نیست، اما به مقدار پیشین سلول حافظه متصل است. این گیت تعیین میکند که چه میزان از حالت سلول حافظه آخر باقی بماند. به دلیل عدم اتصال این گیت به خروجی، مفقود شدن اطلاعات کمتر صورت میگیرد، زیرا هیچ تابع فعالسازی در حلقه قرار نگرفته است.
سلولهای واحدهای بازگشتی گِیتی

«سلولهای واحدهای بازگشتی گِیتی» (Gated Recurrent Units Cells | GRU) نوعی از سلولهای حافظه کوتاه مدت بلند (LSTM) هستند. این سلولها نیز از گیتهایی برای جلوگیری از مفقود شدن اطلاعات استفاده میکنند، اما این کار را تنها با استفاده از دو گیت «به روز رسانی» (Update) و «بازنشانی» (Reset) انجام میدهند. این امر موجب میشود که آنها اندکی کمتر شفاف باشند و در عین حال، سرعت آنها اندکی بیشتر است زیرا همه جا از اتصالات کمتری استفاده میکنند. در اصل، دو تفاوت بین LSTM و GRU وجود دارد که در ادامه بیان شدهاند. سلولهای GRU، حالت سلول پنهانی که توسط یک گیت خروجی محافظت شود را ندارند و ورودی را ترکیب میکنند و گیت را در یک به روز رسانی گیت، فراموش میکنند. ایده آن است که اگر کاربر بخواهد که میزان زیادی از اطلاعات جدید را بپذیرد، احتمالا میتواند برخی از اطلاعات قدیمی را فراموش کند.
انواع لایهها در شبکههای عصبی مصنوعی
پایهایترین راه برای اتصال نورونها برای شکل دادن نمودارها، اتصال همه چیز به همه چیز است. این مورد در شبکههای هاپفیلد و ماشینهای بولتزمن مشاهده میشود. البته، این یعنی تعداد اتصالات به صورت صعودی افزایش پیدا میکند.
به این نوع از لایهها، کاملا متصل (Fully Connected | Completely Connected) گفته میشود. پس ازمدتی، کشف شد که شکستن شبکه به لایههای مجزا، یک ویژگی مفید است که در آن، تعریف یک لایه مجموعهای از نورونها است که به یکدیگر متصل نشدهاند، بلکه فقط به نورونهایی از دیگر گروه (ها) متصل شدهاند. این مفهوم برای مثال در ماشینهای محدود بولتزمن استفاده شده است. امروزه، ایده استفاده از لایهها برای هر تعدادی از لایهها تعمیم پیدا کرده است و تقریبا در همه معماریهای کنونی پیدا میشود. به این مورد نیز (شاید گیج کننده باشد، ولی) لایههای کاملا متصل گفته میشود، زیرا در واقع شبکههای کاملا متصل تقریبا غیر متداول هستند.
لایههای متصل شده به صورت پیچشی
«لایههای متصل پیچشی» (Convolutionally Connected Layers) حتی از لایههای کاملا متصل هم محدودتر هستند. هر نورون تنها به نورونهایی در گروههای دیگر که نزدیک به این نورون هستند، متصل میشود. موجهای صدا و تصویر اگر برای خوراک دادن مستقیم یک به یک به شبکه (با استفاده از یک نورون در هر پیکسل) مورد استفاده قرار بگیرند، حاوی میزان زیادی از اطلاعات هستند. ایده اتصالات پیچشی از مشاهداتی میآید که حفظ اطلاعات مکانی احتمالا برای آنها حائز اهمیت است. استفاده از این مورد در بسیاری از کاربردهای شبکههای عصبی مبتنی بر تصاویر و موجهای صدا، نشانگر آن است که این نوع از سلولها راهکار مناسبی محسوب میشوند.

در اصل، این یک راهکار برای فیلتر کردن اهمیت و تصمیمگیری پیرامون آن است که کدام بستههای اطلاعاتی که به طور تنگاتنگ گروهبندی شدهاند، حائز اهمیت هستند. اتصالات پیچشی برای کاهش ابعاد عالی هستند. اینکه نورونها در چه فاصله مکانی همچنان متصل باقی میمانند، بستگی به پیادهسازی دارد، اما رنجهای بیشتر از ۴ یا ۵ نورون، به ندرت مورد استفاده قرار میگیرند. شایان توجه است که «مکان» (Spatial) معمولا اشاره به فضای دوبُعدی دارد. به همین دلیل است که در بیشتر ارائهها، شیتهای سهبُعدی از نورونها به صورت متصل نمایش داده میشود. رنج اتصالات در همه ابعاد اعمال میشود.
نورنهای متصل شده به صورت تصادفی
گزینه دیگر، نورونهای متصل شده به صورت تصادفی هستند. این نورونها در دو نوع اصلی هستند. با پذیرش درصدهای خاصی از همه اتصالات ممکن یا برای متصل کردن درصد مشخصی از نورونها بین لایهها. اتصالات تصادفی به کاهش خطی کارایی شبکه کمک میکنند و در شبکههای بزرگی که لایههای کاملا متصل دچار مشکلات کارایی میشود، میتوانند مفید واقع شوند. لایهای با اتصالات اندکی پراکندهتر، میتواند در برخی از مسائل، عملکرد بهتری داشته باشد.
به ویژه هنگامی که میزان زیادی اطلاعات برای ذخیره شدن نیاز است، اما نه به اندازه اطلاعاتی که نیاز به مبادله شدن دارد (اندکی مشابه با موثر بودن لایههای متصل شده به صورت پیچشی، اما به صورت تصادفی شده). سیستمهای متصل شده به صورت بسیار پراکنده (۱ یا ۲ درصد) نیز مورد استفاده قرار گرفتهاند که میتوان آنها را در ESNها، ELMها و LSMها مشاهده کرد. به ویژه، در مورد شبکههای اسپایکی، این مورد بسیار معنادار است. زیرا هر چه تعداد اتصالاتی که یک نورون دارد بیشتر باشد، وزن، انرژی کمتری را متحمل خواهد شد و این یعنی انتشار و الگوهای تکرار شونده کمتر.
اتصالات دارای تاخیر زمانی
«اتصالات دارای تاخیر زمانی» (Time Delayed Connections) اتصالاتی بین نورونها هستند (معمولاً از لایه مشابهی و حتی متصل شده با خودشان) که اطلاعات را از لایه قبلی نمیگیرند، اما از یک لایه از گذشته (اغلب، تکرار پیشین) میگیرند. این مورد، این امکان را فراهم میکند که اطلاعات موقتی (زمان، توالی یا ترتیب) ذخیره شوند.

این نوع از اتصالات معمولا از زمانی به زمان دیگر به صورت دستی بازنشانی میشوند تا حالت شبکه پاک شود. تفاوت کلیدی اتصالات دارای تاخیر زمانی با اتصالات عادی، آن است که این اتصالات به طور مستمر در حال تغییر هستند؛ حتی هنگامی که شبکه آموزش داده نشود. تصویری که در ادامه آمده است، شبکههای نمونه کوچکی از انواع توصیف شده در بالا را به همراه اتصالات آنها نمایش میدهد.

برای مشاهده تصویر در اندازه کامل، روی آن کلیک کنید.
اگر این مطلب برای شما مفید بوده است، آموزشهای زیر نیز به شما پیشنهاد میشوند:
- مجموعه آموزشهای شبکههای عصبی مصنوعی
- آموزش شبکههای عصبی مصنوعی در متلب
- مجموعه آموزشهای هوش مصنوعی
- آموزش کاربردی شبکههای عصبی مصنوعی
- ساخت شبکه عصبی (Neural Network) در پایتون — به زبان ساده
- ساخت شبکه های عصبی در نرم افزار R
- شبکه عصبی مصنوعی و پیادهسازی در پایتون — راهنمای کاربردی
^^











سلام وقت بخیر. آموزش و کد نویسی الگوریتم gru درسایت وجود داره؟
با سلام؛
در حال حاضر چنین آموزشی در فرادرس موجود نیست اما در حال برنامهریزی برای انتشار موضوعی در این رابطه هستیم. در این میان، میتوانید نگاهی به فیلم آموزشی زیر از فرادرس داشته باشید:
آموزش طراحی شبکه عصبی LSTM در متلب برای پیش بینی داده و طبقه بندی متن و فیلم
با تشکر
و واقعا ممنون از سایت خوبتون