




یادگیری عمیق چیست؟ – به زبان ساده + منابع یادگیری
«هوش مصنوعی» (Artificial Intelligence) و یکی از شاخههای مهم آن، یعنی «یادگیری ماشین» (Machine Learning)، به عنوان سنگبنای حوزه جدیدی با نام «یادگیری عمیق» (Deep Learning) محسوب میشوند. هدف این شاخه از فناوری اطلاعات، ساخت سیستمهای هوشمندی است که بتوانند همانند انسان، درباره موضوعی خاص تصمیمگیری کنند و وظایف مختلفی را به شکلی هوشمند انجام دهند. در مطلب حاضر، با هدف پاسخ به پرسش یادگیری عمیق چیست، به توضیح این شاخه از علوم کامپیوتر پرداخته میشود و کاربردها و ویژگیهای مدلهای مبتنی بر یادگیری عمیق مورد بررسی قرار میگیرند. همچنین، در این مقاله به برخی از پرکاربردترین مدلهای یادگیری عمیق اشاره و به معرفی تعدادی از زبانهای برنامه نویسی رایج این حوزه پرداخته شده است.
- میآموزید یادگیری عمیق و یادگیری ماشین به لحاظ ساختاری چه تفاوتی دارند.
- مدلهای رایج در یادگیری عمیق و کاربرد آنها در حل مسائل را خواهید آموخت.
- میآموزید یادگیری عمیق چگونه فرایندهای تکنولوژیک و صنعتی را متحول کرده است.
- با مهمترین مزایا و محدودیتهای یادگیری عمیق در پروژههای واقعی آشنا میشوید.
- روشهای اصلی آموزش مدلهای یادگیری عمیق و کاربرد هرکدام را یاد خواهید گرفت.
- زبانهای برنامهنویسی و ابزارهای مهم این حوزه را خواهید شناخت.




یادگیری عمیق چیست ؟
یادگیری عمیق به عنوان یکی از زیرشاخههای حوزه یادگیری ماشین تلقی میشود. هدف یادگیری عمیق طراحی سیستمهای کامپیوتری هوشمندی است که بتوانند مشابه انسان درباره موضوعی خاص، راهحل ارائه کنند و مفاهیم جدیدی را یاد بگیرند.
پیش از ادامه این مبحث لازم است یادآور شویم که میتوانید یادگیری عمیق را با استفاده از مجموعه آموزش یادگیری عمیق، مقدماتی تا پیشرفته فرادرس یاد بگیرید.
این حوزه از فناوری، شاخهای مهم در «علم داده» (Data Science) است، زیرا اصلیترین مباحث این شاخه، آمار و مدلسازی برای پیشبینی مسائل مختلف را شامل میشود. مهندسان علم داده با استفاده از روشهای یادگیری عمیق میتوانند جمعآوری، تجزیه و تحلیل و تفسیر حجم عظیمی از دادهها را سریعتر و آسانتر انجام دهند.
الگوریتمهای یادگیری عمیق با در اختیار داشتن ورودیهای مختلفی از دنیای بیرون مانند تصاویر، صوت و متن، به دنبال پیدا کردن الگوهایی هستند که با استفاده از آنها بتوانند پیشبینی خاصی را پیرامون موضوع مطرح شده انجام دهند.
به منظور ارائه پاسخ دقیق به پرسش یادگیری عمیق چیست باید نگاهی به ساختار مدلهای این حوزه از فناوری پرداخت. مدلهای یادگیری عمیق از ساختارهای لایه به لایهای تشکیل شدهاند که به آنها «شبکه عصبی» (Neural Network) گفته میشود. طرح چنین ساختاری، الهامگرفته از مغز انسان است. «نورونهای» (Neurons) مغز انسان دارای اجزایی با نامهای «دندریت» (Dendrite)، «هسته» (Nucleus)، «جسم سلولی» (Cell Body)، «آکسون» (Axon) و «پایانههای آکسون | سیناپس» (Axon Terminals | Synapse) هستند. ورودیهای نورونها، سیگنالهایی به حساب میآیند که از حسهای بینایی، شنوایی، بویایی و لامسه انسان دریافت شده و به دندریت منتقل میشوند و سپس این اطلاعات به سمت آکسون ارسال شده و در نهایت از طریق پایانههای سیناپس به دندریت نورون بعدی فرستاده میشوند.
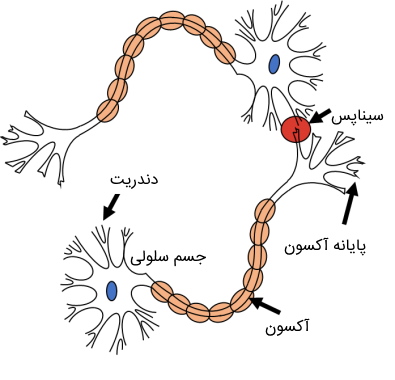
شبکههای عصبی نیز همانند مغز انسان، ورودیها را که در قالب بردارهای عددی هستند، در هر لایه با استفاده از چندین «گره» (Nodes) دریافت میکنند و با اعمال پردازش بر روی آنها، خروجی حاصل شده را به لایه بعدی خود منتقل میکنند. وزنهای موجود در شبکه عصبی، نقش سیناپس را در مغز انسان ایفا میکنند. به عبارتی، وزنها همان چیزی هستند که شبکههای عصبی باید یاد بگیرند. شبکه عصبی با استفاده از وزنهای یاد گرفته شده، تصمیم میگیرد کدام یک از ورودیهای نورونها در تعیین خروجی شبکه از اهمیت بالایی برخوردار هستند.

دادهها پس از گذشتن از تمامی لایههای میانی شبکه عصبی، به لایه آخر منتقل میشوند تا خروجی نهایی شبکه توسط این لایه محاسبه شود. خروجیهای شبکه میتوانند در قالبهای مختلفی ارائه شوند که هر یک از آنها در ادامه فهرست شدهاند:
- خروجی شبکه عصبی میتواند از نوع اعداد «پیوسته» (Continuous) باشند. قیمتهای محصولات میتواند از نوع اعداد پیوسته محسوب شوند.
- شبکه عصبی میتواند خروجی را در قالب اعداد دودوئی و به شکل 0 و 1 ارائه دهد.
- خروجی شبکه عصبی را میتوان بهصورت چندین دسته مشخص کرد. به عنوان مثال، برای پژوهشی پیرامون تشخیص انواع تصاویر حیوانات، میتوان چندین دسته مشخص کرد که هر یک از دستهها، نام حیوان خاصی مانند موش، گربه، سگ، فیل، مار و اسب را مشخص میکند.
تاریخچه یادگیری عمیق چیست ؟
به منظور رسیدن به پاسخ پرسش یادگیری عمیق چیست، بهتر است تاریخچه این شاخه از فناوری را مورد بررسی قرار داد. پیدایش حوزه یادگیری عمیق به دهه 1940 بازمیگردد. با این حال، در آن زمان به دلیل نقصهای مختلفی که در مدلهای ارائه شده وجود داشت، این حیطه از فناوری چندان مورد توجه قرار نگرفت. البته باید خاطرنشان کرد که همان مدلهای اولیه، راهگشای پیشرفت در پژوهشهای مدلهای عمیق شدند و نقش مهمی را در شکلگیری مدلهای قدرتمند امروزی ایفا کردند، به طوری که همچنان از بعضی مدلهای قدیمی در پیادهسازی برخی مسائل امروزی استفاده میشود.
در سالهای 1940 تا 1960، مطالعات اولیهای پیرامون مدلهای یادگیری عمیق شکل گرفت که ایده اولیه این پژوهشها از نحوه یادگیری بیولوژیکی انسان الهام گرفته شده بود. این مطالعات با نام «سایبرنتیک» (Cybernetics) شناخته میشدند که هدف آنها ساخت مدلهای محاسباتی بود. این مدلها مشابه مغز انسان و حیوان، به یادگیری مسئله خاصی میپرداختند. تا به امروز نیز این شاخه از مطالعات، تحت عنوان «علوم اعصاب محاسباتی» (Computational Neuroscience) ادامه دارند.

نخستین مدل محاسباتی توسط «وارن موکولوچ» (Warren MuCulloch) و «والتر پیتس» (Walter Pitts) در سال 1943 ارائه شد. این دو فرد به عنوان عصبشناس و منطقدان با استفاده از نحوه عملکرد نورون مغز، به طراحی مدلی پرداختند که با دریافت ورودی و اعمال عمل جمع برروی آنها، مقداری را در خروجی بازمیگرداند. وزنهای مورد نیاز این شبکه بهصورت دستی توسط انسان مشخص میشد.
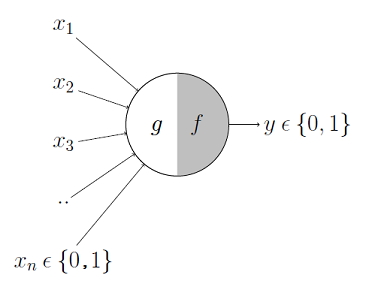
در اواخر دهه 1950، مدلی با عنوان «پرسپترون» (Perceptron) توسط روانشناس آمریکایی به نام «فرانک روزنبلات» (Frank Rosenblatt) ارائه شد. ساختار این مدل، مشابه با ساختار مدل ارائه شده توسط موکولوچ و پیتس بود اما وزنهای این شبکه عصبی بهصورت خودکار توسط مدل یاد گرفته میشدند. یکی از کاربردهای اصلی مدل پرسپترون در آن زمان، تشخیص تصاویر و دستهبندی آنها بود.
همزمان با ارائه مدل پرسپترون، مدل دیگری با عنوان «ادلاین» (ADALINE) توسط «برنارد ویدرو» (Bernard Widrow) مطرح شد که یادگیری وزنهای این مدل نیز همانند مدل پرسپترون، بهصورت خودکار بود. با این حال، بزرگترین نقصی که این مدل داشت، خطی بودن آن بود. به همین خاطر، این مدل نمیتوانست برای پیادهسازی مسائل غیرخطی نظیر XOR کارایی داشته باشد.
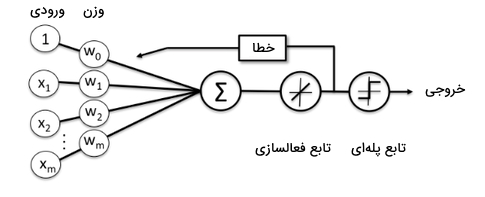
در دهه 1980، مفهمومی با عنوان «پیوندگرایی» (Connectionism) یا «پردازش توزیع شده موازی» (Parallel Distributed Processing) مطرح شد که برگرفته از «علوم شناختی» (Cognitive Science) بود و بر ساخت شبکههای عصبی با ساختار لایهای تاکید داشت که به نوعی، از نحوه ارتباط نورونهای مغز انسان الهام گرفته شده بود.
لایههای متصل به هم در این شبکهها، امکان پردازش موازی ورودیها را فراهم کردند. اتصال لایهها با مجموعهای از وزنها صورت میگرفت که این وزنها مشخص میکردند کدام ورودی، میتواند در طول شبکه جریان داشته باشد. در این دوران، مدلها و الگوریتمهایی مانند مدل «حافظه طولانی کوتاهمدت» (Long Short-Term Memory | LSTM) و روش «پس انتشار» (Backpropagation) مطرح شدند که امروزه نیز کاربرد زیادی در پژوهشهای مربوط به یادگیری عمیق دارند.
از سال 1980 تا اوایل دهه 2000، به دلیل کمبود منابع محاسباتی، پژوهشهای اندکی پیرامون یادگیری عمیق و ارائه مدلهای جدید انجام شد و سرمایهگذاران حاضر نشدند در این دوران، هزینه زیادی را در پیشرفت این مسیر صرف کنند. با این حال، در سال 2006 دوباره پژوهشهای این حوزه از فناوری بهطور جدیتر از سر گرفته شد و ارائه «شبکههای باور عمیق» (Deep Belief Networks) توسط «جفری هینتون» (Geoffrey Hinton)، سنگبنایی برای ارائه مدلهای یادگیری عمیق پیشرفتهتر شدند.
مزایا و معایب یادگیری عمیق چیست ؟
برای درک بهتر پاسخ پرسش «یادگیری عمیق چیست، باید به ویژگیهای مثبت و منفی این حوزه از هوش مصنوعی نیز اشاره کرد. پیدایش حوزه یادگیری عمیق و ارائه مدلهای مختلف و پیشرفته آن و خروجی شگفتانگیز این مدلها باعث شده است که اکثر سازمانهای بزرگ، به منظور پیشرفت در حوزه مورد فعالیت خود از ابزارهای هوشمند این شاخه از فناوری استفاده کنند. در ادامه، به برخی از مهمترین مزیتهای مدلهای مبتنی بر یادگیری عمیق اشاره شده است:
- استفاده از دادههای ساختارنیافته حجیم: بسیاری از دادههای سازمانها ساختاریافته نیستند و اکثر آنها در قالبهای مختلفی نظیر متن و عکس ذخیره شدهاند. به منظور تجزیه و تحلیل چنین دادههایی، نمیتوان از الگوریتمهای یادگیری ماشین استفاده کرد. به عبارتی، فقط مدلهای یادگیری عمیق میتوانند از اطلاعات ساختارنیافته استفاده کنند و خروجی مناسبی را ارائه دهند که بتوان با کمک آنها در راستای پیشرفت بیشتر سازمان قدم برداشت.
- عدم نیاز به مرحله استخراج ویژگی و مهندسی ویژگی: در الگوریتمهای یادگیری ماشین، مرحله استخراج ویژگی مهمترین گام در یادگیری مدل محسوب میشود. در مدلهای یادگیری عمیق، این مرحله از یادگیری، توسط خود مدل انجام میشود و نیازی نیست وقت و هزینه جداگانهای صرف تهیه ویژگیهای مورد نیاز مدل کرد.
- ارائه خروجی با دقت بالا: چنانچه مدلهای یادگیری عمیق بهخوبی با دادههای آموزشی مناسبی آموزش داده شده باشند، در سریعترین زمان میتوانند خروجی مورد انتظار را تولید کنند. این در حالی است که اگر از نیروی انسانی برای انجام مسئولیتی مشابه استفاده شود، روال انجام کار بهکندی پیش میرود و ممکن است به دلایل مختلفی مانند خطاهای انسانی، خستگی، عدم تمرکز و سایر موارد، خروجی حاصل شده، از کیفیت قابل قبولی برخوردار نباشد.

یادگیری عمیق علاوهبر مزیتهای چشمگیری که برای بشر به ارمغان آورده است، دارای معایبی نیز هست که در ادامه به برخی از مهمترین آنها اشاره میشود:
- محدود بودن بر روی مسئلهای خاص: یکی از مهمترین محدودیتهای مدلهای یادگیری عمیق این است که آنها با داشتن دادههای یک مسئله، صرفاً یاد میگیرند تنها موضوعی خاص را حل کنند. این یعنی الگوهایی که این مدلها یاد میگیرند، صرفاً محدود به الگوهای دادههای ورودی خود هستند. چنانچه برای مسئلهای خاص، داده کمی در اختیار برنامه نویس باشد یا برای یک مسئله کلی، تنها از یک مرجع خاصی، داده تهیه شود، مدل دقت بالایی در یادگیری نخواهد داشت.
- نیاز به تجهیزات سختافزاری: به منظور آموزش مدلهای یادگیری عمیق باید تجهیزات سختافزاری مناسبی نظیر واحد پردازنده گرافیکی را آماده کرد. برای تهیه این قطعات سختافزاری نیاز به صرف هزینه است.
- نیاز به دادههای زیاد: مدلهای یادگیری عمیق برای یادگیری یک موضوع خاص، به حجم زیادی از داده احتیاج دارند. به عبارتی، هر چقدر مسائل پیچیدهتر باشند، به مدلهای پیچیدهتر و سنگینتری احتیاج است که این مدلها نیز به مراتب، به دادههای آموزشی بیشتری نیاز دارند. تهیه این حجم از داده نیازمند هزینه زمانی و مالی بسیاری است.
- از دست رفتن فرصت شغلی برای انسان: با هوشمندسازی سیستمها و جایگزین کردن آنها به جای نیروهای انسانی، بسیاری از افراد شغل خود را از دست میدهند. همین امر باعث میشود درصد بیکاری و به تبعیت از آن، میزان فقر در جامعه بیشتر شود.
کاربردهای یادگیری عمیق چیست ؟
امروزه، از حوزه یادگیری عمیق در تمامی جنبههای زندگی انسان استفاده میشود. اکثر وسایل مورد نیاز در زندگی روزمره بشر، هوشمندسازی شدهاند و به این سبب، بسیاری از فعالیتهای انسان با سهولت بیشتری انجام میشوند. همچنین، در بسیاری از حوزههای علمی مختلف، از مدلهای یادگیری عمیق به منظور ساخت ابزارهای هوشمند استفاده شده است تا بسیاری از فعالیتهای سازمانها بهصورت خودکار و با دقت بالا انجام شوند. به منظور درک عمیقتر و ملموستر پاسخ پرسش یادگیری عمیق چیست، در ادامه به کاربردهای مختلف مدلهای آن در برخی از حوزهها و جنبههای زندگی انسان اشاره میشود:
- تشخیص کلاهبرداری: در دنیای دیجیتال، کلاهبرداری به عنوان یکی از مشکلات اساسی محسوب میشود. از مدلهای یادگیری عمیق میتوان به منظور شناسایی تراکنشهای غیرعادی کاربران استفاده کرد. به عبارتی، با در اختیار داشتن دادههای مربوط به مشتریان مانند موقعیت مکانی، بازههای زمانی خرید و الگوهای خرید از کارت اعتباری میتوان فعالیتهای مشکوک کاربران در رابطه با کارتهای اعتباری را شناسایی کرد.
- «بینایی کامپیوتر» (Computer Vision): مدلهای یادگیری عمیق با تقلید از نحوه یادگیری انسان درباره مسائل مختلف، قادر است الگوهای دادهها را شناسایی کنند. همین ویژگی سبب میشود تا بتوان از این مدلها در پژوهشهای مربوط به پردازش تصویر استفاده کرد و اشیای موجود در تصاویر مانند هواپیما، چهره افراد و اسلحه را تشخیص داد.
- خودکارسازی عملیات در حوزه کشاورزی: کشاورزی یکی از منابع اصلی برای تامین مواد غذایی مورد نیاز انسان است که میتوان از مدلهای یادگیری عمیق در این حیطه بهصورت کارامد استفاده کرد. کشاورزان میتوانند از ابزارهای مبتنی بر یادگیری عمیق برای تشخیص حیوانات وحشی، پیشبینی وضعیت آب و هوا، پیشبینی بازدهی محصولات و ماشینهای کشاورزی خودران استفاده کنند.
- «استخراج ویژگی» (Feature Extraction): یکی دیگر از کاربردهای مدلهای یادگیری عمیق، استخراج ویژگی است. تمامی لایههای مدلهای یادگیری عمیق، از دادههای ورودی، ویژگیهای مختلفی استخراج میکنند. بدینترتیب، میتوان خروجی هر لایه شبکه عصبی را ذخیره کرد تا بتوان از آنها به عنوان ویژگی، در سایر مدلهای یادگیری عمیق یا یادگیری ماشین استفاده کرد.

برخی از کاربردهای یادگیری عمیق - «پردازش زبان طبیعی» (Natural Language Processing): با استفاده از مدلهای یادگیری عمیق میتوان الگوها و ویژگیهای پیچیده متون را تشخیص داد و به تفسیر دقیقتری از این متنها رسید. ابزارهای مختلفی برای تحلیل متن وجود دارند که مبتنی بر شبکههای عصبی هستند. ابزارهای ترجمه ماشینی، خلاصهسازی متون، تصحیح متنها، تشخیص سرقت ادبی، تحلیل احساسات در متن و چتباتها به عنوان برخی از رایجترین و پرکاربردیترین ابزارهای پردازش زبان طبیعی محسوب میشوند که بسیاری از سازمانها و مراکز علمی و تحقیقاتی از آنها استفاده میکنند.
- خدمات پزشکی: با جمعآوری شرح حال بیماران و آماده کردن آنها در قالب دادههای مناسب برای آموزش مدلهای یادگیری عمیق، میتوان ابزاری قدرتمند به منظور تشخیص بیماری تهیه کرد تا اطلاعات جامعی را در اختیار پزشکان و متخصصان قرار دهد و در راستای تشخیص بهترین راه درمان به آنها کمک کند.
- خودکار کردن خط تولید کارخانهها: امروزه در اکثر کارخانهها، بسیاری از فعالیتهای تولید محصول با ابزارهای هوشمند انجام میشوند. معمولاً، انجام فعالیتهای تکراری را که نیاز به داشتن خلاقیت و تفکر ندارند، میتوان به رباتها محول کرد. بدینترتیب، هزینههای مالی سازمانها و کارخانهها به منظور تامین دستمزد نیروهای انسانی، به طرز چشمگیری کاهش پیدا میکند.
- بازاریابی: تولیدکنندگان میتوانند با استفاده ابزارهای هوش مصنوعی، میزان سوددهی خود را چندین برابر کنند. آنها میتوانند از نرمافزارها یا برنامههای کاربردی موبایل استفاده کنند تا به مشتریان خود بر اساس سابقه خرید و سلایق آنها، محصولات جدید شرکت را پیشنهاد دهند.
معرفی فیلم های آموزش هوش مصنوعی

سایت فرادرس برای آن دسته از افرادی که علاقهمند هستند در زمینه هوش مصنوعی بهصورت حرفهای مشغول به فعالیت شوند، مجموعهای از فیلمهای آموزشی اختصاصی را تهیه کرده است. در مجموعه دورههای هوش مصنوعی فرادرس دورههایی برای یادگیری عمیق هم ارائه شدهاند که پس از مطالعه این مطلب و رسیدن به پاسخ این سوال که یادگیری عمیق چیست ، میتوان از این دورهها استفاده کرد.
دورههای آموزشی ارائه شده در این مجموعه فیلمهای آموزشی مقدماتی تا پیشرفته و پروژهمحور حوزه هوش مصنوعی را شامل میشوند. علاقهمندان میتوانند از این دوره آموزشی جامع در راستای تقویت مهارت تخصصی خود در حیطههای مختلف هوش مصنوعی استفاده کنند. در تصویر فوق تنها برخی از دورههای آموزشی مجموعه آموزش هوش مصنوعی فرادرس نمایش داده شدهاند.
- برای دسترسی به همه آموزشهای هوش مصنوعی فرادرس + اینجا کلیک کنید.
تفاوت یادگیری عمیق با یادگیری ماشین چیست ؟
یادگیری عمیق به عنوان زیرشاخهای از یادگیری ماشین محسوب میشود. به عبارتی، مدلهای این دو حوزه، با استفاده از اطلاعات آماری دادههای ورودی خود به پیشبینی مقداری در خروجی میپردازند. با این حال، این دو حوزه از علوم کامپیوتر در روال یادگیری مسائل تفاوت مهمی دارند و برای درک عمیقتر آنها و رسیدن به پاسخ پرسش یادگیری عمیق چیست ، باید تفاوت روشهای یادگیری مدلهای آنها مورد بررسی قرار گیرد.
الگوریتمهای یادگیری ماشین به منظور یادگیری دادهها و پیشبینی مقداری در خروجی، به مفهومی با عنوان «مهندسی ویژگی» (Feature Engineering) یا «استخراج ویژگی» (Feature Extraction) و «انتخاب ویژگی» (Feature Selection) متکی بوده، درحالی که مدلهای یادگیری عمیق به منظور یادگیری الگوهای دادهها، مبتنی بر مفاهیمی با نامهای «لایه» (Layer) و «عمیق» (Deep) هستند.
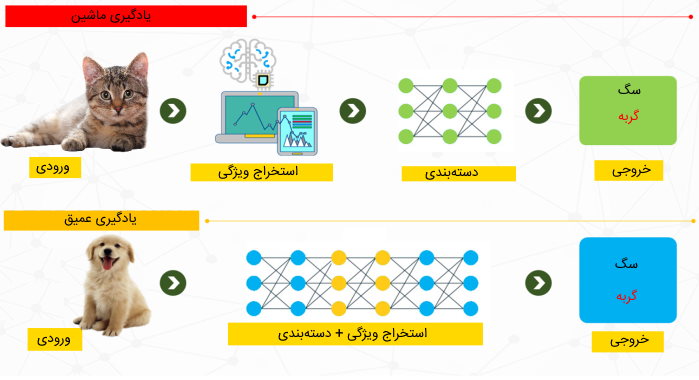
به منظور درک بهتر تفاوت یادگیری عمیق و یادگیری ماشین میتوان از مثال ملموستری استفاده کرد. چنانچه برنامه نویس قصد داشته باشد مدلی از الگوریتمهای یادگیری ماشین را آموزش دهد تا تصاویر مربوط به سگ و گربه را دستهبندی کند، در ابتدا نیاز است که ویژگیهای تصاویر (دادههای آموزشی مدل) مانند قد حیوان، رنگ موی حیوان، اندازه جثه حیوان، مدل گوشها و سایر موارد را با استفاده از روشهای مهندسی ویژگی، استخراج کند و سپس این ویژگیها را در قالب بردارهای عددی به عنوان ورودی، به مدل یادگیری ماشین بدهد.
به بیان دیگر، باید برای مدل یادگیری ماشین دقیقاً مشخص شود بر اساس چه ویژگیهایی درباره خروجی مدل تصمیم بگیرد. بدینترتیب، در این روش، میزان خروجی قابل قبول مدل تا حد زیادی به ویژگیهای استخراج شده برنامه نویس وابسته است.
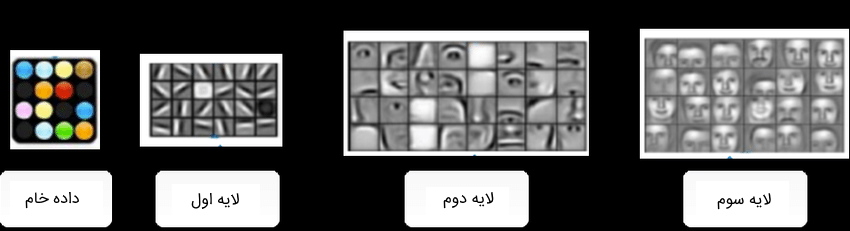
در مقایسه با الگوریتمهای یادگیری ماشین، مدلهای یادگیری عمیق نیازی به مرحله استخراج ویژگی ندارند. به عبارتی، این مدلها با داشتن ساختار لایهای میتوانند بهطور خودکار، ویژگیهای دادههای ورودی خود را یاد بگیرند. هر چقدر به تعداد لایههای شبکه اضافه شود، مدل میتواند ویژگیهای پیچیدهتری را یاد بگیرد.
چنین رویکردی باعث میشود فرایند یادگیری مدل سریعتر انجام شود. با این حال، این احتمال وجود دارد که میزان دقت مدلهای یادگیری عمیق نسبت به مدلهای یادگیری ماشین کمتر باشد. در مدلهای یادگیری ماشین، برنامه نویس باید ویژگیهای مورد نیاز را بدون داشتن هیچ گونه خطایی برای آموزش مدل تهیه میکرد، اما مدلهای یادگیری عمیق بهطور خودکار به شناسایی الگوهای دادهها میپردازند؛ بدینترتیب ممکن است این روند شناسایی بهطور کامل، به شکل صحیحی انجام نشود.
تفاوت مهم دیگر یادگیری ماشین و یادگیری عمیق در این است که به منظور آموزش مدلهای یادگیری ماشین، نیاز به تجهیزات قدرتمند و گران قیمت نیست؛ در حالی که برای آموزش مدلهای یادگیری ماشین، به تجهیزات سختافزاری قدرتمندی مانند «واحد پردازنده گرافیکی» (Graphics Processing Units | GPUs) نیاز است. بهعلاوه، زمانی که حجم داده آموزشی زیاد نباشد، مدلهای یادگیری ماشین عملکرد بهتری نسبت به مدلهای یادگیری عمیق دارند.
شیوه یادگیری مدل های یادگیری عمیق چگونه است ؟
مدلهای یادگیری عمیق با نامهای «شبکههای عصبی مصنوعی» (Artificial Neural Networks) و «شبکههای عصبی عمیق» (Deep Neural Networks) شناخته میشوند. این شبکهها بر اساس ویژگیهای منحصربفردشان، انواع مختلفی دارند؛ با این حال، شیوه یادگیری آنها تا حد زیادی مشابه یکدیگر است. به عبارتی، تمامی مدلهای یادگیری عمیق، با داشتن مقدار حجیمی از داده، مسائل مختلف را بر پایه آزمون و خطا یاد میگیرند.

به بیان دقیقتر، این مدلها با دریافت دادهها، به پیشبینی خروجی میپردازند و چنانچه خروجی، مطابق با خروجی مورد انتظار انسان نباشد، از خطای حاصل شده به منظور بهبود عملکرد خود استفاده میکنند. همین ویژگی مدلهای یادگیری عمیق باعث شد سازمانها به استفاده از این مدلها روی بیاورند؛ زیرا دادههای بسیاری را در اختیار داشتند که نیازمند دستهبندی و سازماندهی خودکار بودند. به همین خاطر، میزان استفاده از ابزارهای هوشمند در سازمانها به منظور تجزیه و تحلیل دادهها بیشتر شد.
رویکردهای یادگیری عمیق کدامند ؟
همانطور که در بخش قبل به آن اشاره شد، مدلهای یادگیری عمیق به دادههایی به عنوان ورودی احتیاج دارند تا با اعمال محاسبات ریاضی بر روی آنها، خروجی تولید کنند. براساس نوع داده مورد نیاز این مدلها، میتوان رویکردهای یادگیری مدلهای عمیق را به سه دسته کلی تقسیم کرد که در ادامه فهرست شدهاند:
- «یادگیری نظارت شده» (Supervised Learning)
- «یادگیری بدون نظارت» (Unsupervised Learning)
- «یادگیری نیمه نظارت شده» (Semi-Supervised Learning)
در ادامه مطلب حاضر، به توضیح هر یک از رویکردهای ذکر شده پرداخته شده و ویژگیهای آنها شرح داده میشوند.
یادگیری نظارت شده چیست ؟
رویکرد یادگیری نظارت شده به دنبال یافتن تابعی است که بر اساس دادههای آموزشی فراهم شده، ورودی را به خروجی مورد انتظار نگاشت کند. در این شیوه از آموزش مدل، به «دادههای آموزشی برچسبدار» (Labeled Training Data) نیاز است. هر نمونه از داده آموزشی شامل مقدار داده و برچسب آن است که این برچسب، مقدار خروجی مورد انتظار مدل را مشخص میکند. از چنین رویکردی به منظور «دستهبندی» (Classification) دادهها براساس دستههای از پیش تعریف شده استفاده میشود. برخی از مسائلی که میتوان آنها را با استفاده از رویکرد یادگیری نظارت شده پیادهسازی کرد، در ادامه فهرست شدهاند:
- تشخیص چهره
- تشخیص اشیاء در تصاویر
- تشخیص ایمیلهای «اسپم» (Spam) از غیراسپم
- تشخیص صدا و تشخیص نوع احساسات آن
- تشخیص نویسنده متن
- تبدیل گفتار به متن
- پیشبینی قیمت سهام، مسکن و سایر موارد
یادگیری بدون نظارت چیست ؟
در این رویکرد از یادگیری به دنبال «خوشهبندی» (Clustering) دادهها بدون نیاز به برچسب هستیم. به عبارتی، در این روش، با بررسی شباهت دادههای آموزشی به یکدیگر، دادهها در خوشههای جداگانه قرار میگیرند. خروجی حاصل شده از مدلهای مبتنی بر یادگیری بدون نظارت، چندین دسته مختلف است که هر یک از این دستهها، شامل دادههایی با خصوصیات مشابه به هم هستند، در حالی که با دادههای سایر دستهها تفاوت بسیار دارند.
از این رویکرد میتوان در مسائلی نظیر «تعبیهسازی کلمات» (Word Embedding) و «تشخیص ناهنجاریها» (Anomaly Detection) استفاده کرد. به عبارتی، در مسئله تشخیص ناهنجاریها میتوان دادههایی که مشابه با سایر دادهها نیستند را تشخیص داد که این مسئله میتواند در موضوعاتی نظیر «تشخیص کلاهبرداری» (Fraud Detection) و مسائل امنیت شبکه از اهمیت بالایی برخوردار باشد.
یادگیری نیمه نظارت شده چیست ؟
در روش یادگیری نیمه نظارت شده میتوان از دادههای برچسبدار و بدون برچسب برای آموزش مدل استفاده کرد. این روش مناسب مسائلی است که میزان حجم دادههای برچسبدار در مقایسه با حجم دادههای بدون برچسب کم باشد. بر اساس پژوهشهای انجام شده، دقت این روش از یادگیری نسبت به روش یادگیری بدون نظارت بالاتر است؛ با این حال، این رویکرد به منظور تهیه دادههای برچسبدار نیاز به هزینه زمانی و مالی دارد.
روش های آموزش مدل های یادگیری عمیق چیست ؟
برای ارائه پاسخ کامل به پرسش یادگیری عمیق چیست ، باید به معرفی انواع روشهای آموزش مدلهای یادگیری عمیق نیز پرداخت که در ادامه به آنها اشاره شده است:
- «یادگیری از ابتدا» (Training From Scratch)
- «یادگیری انتقال» (Transfer Learning)
- «میزانسازی دقیق» (Fine-Tuning)
در بخش بعدی، به توضیح هر یک از روشهای ذکر شده فوق پرداخته میشود.
یادگیری از ابتدا چیست ؟
در روش یادگیری مدلهای عمیق از ابتدا، نیاز است که دادههای مورد نیاز مدل جمعآوری و در قالب مناسب آماده شوند تا بتوان از آنها به عنوان ورودی مدل، استفاده کرد. مدل عمیقی که در این روش از یادگیری طراحی میشود، با وزنهای تصادفی شروع به یادگیری دادههای آموزشی میکند. این روش آموزشی برای مسائلی با دادههای حجیم مناسب نیستند زیرا زمان زیادی را باید به یادگیری مدل اختصاص داد.
یادگیری انتقال چیست ؟
در بسیاری از پروژههای یادگیری عمیق، از یادگیری انتقال استفاده میشود. در این روش از یادگیری، میتوان از شبکههای عصبیای استفاده کرد که از قبل بر روی حجم عظیمی از دادهها آموزش دیدهاند. به عبارتی، شبکههای از قبل آموزش داده شده، دارای وزنهای ثابت شدهای هستند و الگوهای خاصی از دادهها را یاد گرفتهاند. بدینترتیب، میتوان از این شبکهها به عنوان بخشی از مدل نهایی خود استفاده کرد و وزنهای مدل از قبل آموزش دیده را در حین آموزش مدل جدید، بهروزرسانی نکرد. این روش از یادگیری مناسب مسائلی است که در آنها حجم زیادی داده در اختیار نیست.
میزان سازی دقیق چیست ؟
میزانسازی دقیق مدل به این معناست که از مدلهای از پیش آموزش دیده، در حل مسائل جدید استفاده شود، به نحوی که وزنهای مدل نیز در حین آموزش مدل با دادههای جدید، بهروزرسانی شوند. به عنوان مثال، در حوزه پردازش زبان طبیعی میتوان از «مدلهای زبانی» (Language Models) در سایر پروژههای یادگیری عمیق استفاده کرد. مدلهای زبانی بر روی حجم زیادی از دادههای بدون برچسب آموزش دیدهاند. این دادهها میتوانند متونی درباره حوزههای مختلف ادبی، سیاسی، اقتصادی، ورزشی و سایر حوزهها باشند.
چنانچه نیاز باشد به منظور حل مسئلهای پیرامون تحلیل احساسات متن، از مدل زبانی استفاده شود، کافی است که این مدل را با دادههای جدید آموزش داد، به نحوی که وزنهای شبکه با دیدن هر داده جدید، بهروزرسانی شوند. به عبارتی، دانش قبلی مدل، به یادگیری دادههای جدید کمک بهسزایی میکند. این روش از یادگیری مناسب مسائلی است که دادههای آموزشی کمی را برای آنها در اختیار داریم.
پرکاربردترین مدل های یادگیری عمیق کدامند ؟
در پی پاسخ به پرسش یادگیری عمیق چیست ، باید به انواع روشهای کاربردی این حوزه از فناوری نیز اشاره کرد. انواع مختلفی از شبکههای عصبی وجود دارند که به لحاظ ساختار، جریان داده، تعداد و نوع نورونهای لایهها، تعداد لایهها و سایر موارد با یکدیگر تفاوت دارند. در ادامه، به برخی از رایجترین و پرکابردترین انواع شبکههای عصبی اشاره شده است:
- شبکه عصبی «چندلایه پرسپترون» (Multi Layer Perceptron | MLP)
- «شبکه عصبی پیچشی» (Convolutional Neural Network | CNN)
- «شبکه عصبی بازگشتی» (Recurrent Neural Network | RNN)
- «شبکه عصبی حافظه طولانی کوتاهمدت» (Long Term-Short Memory | LSTM)
- «شبکه مولد تخاصمی» (Generative Adversarial Network)
- مدل «خودرمزگذار» (Autoencoder)
- مدل «ترسیم خودسازمان دهنده» (Self Organizing Map | SOM)
در ادامه مطلب حاضر، به توضیح نحوه کارکرد مدلهای ذکر شده فوق پرداخته شده است و مزایا و معایب هر یک از آنها شرح داده میشوند.
شبکه عصبی چند لایه پرسپترون
شبکه عصبی چند لایه پرسپترون به عنوان یکی از قدیمیترین مدلهای یادگیری عمیق محسوب میشود. افرادی که در حوزه یادگیری عمیق تازهکار هستند، میتوانند به منظور پیادهسازی یک مسئله، از این مدل استفاده کنند و شبکه سادهای را با دادههای موجود آموزش دهند. این شبکه از چند لایه متصل به هم تشکیل شده است که لایه نخست، ورودیهای شبکه را دریافت میکند و با اعمال عملیات محاسباتی، خروجی را به لایه بعدی خود میفرستد.
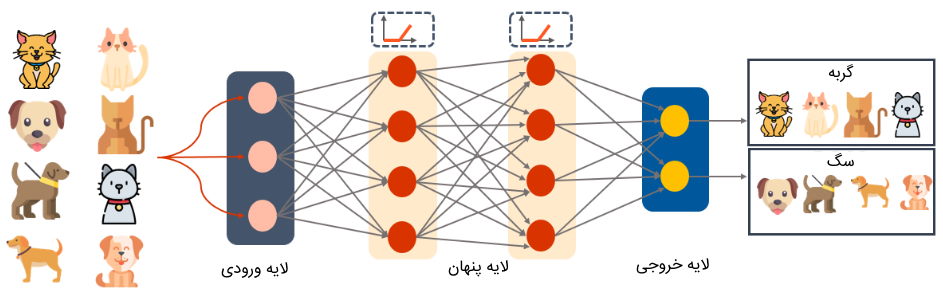
در این مدل، خروجیهای هر لایه، به لایه بعد منتقل شده تا در نهایت، مقدار نهایی شبکه توسط لایه خروجی محاسبه شود. این نوع شبکه عصبی، از الگوریتم پسانتشار برای یادگیری شبکه و بهروزرسانی وزنها استفاده میکند. «توابع فعالسازی» (Activation Functions) رایج در لایههای این شبکه، تابع «واحد خطی اصلاح شده» (Rectified Linear Unit | ReLU) است.
یکی از کاربردهای شبکه عصبی چند لایه پرسپترون، فشردهسازی تصاویر شبکههای اجتماعی مانند اینستاگرام و فیسبوک است. زمانی که سرعت اینترنت پایین باشد، این شبکه عصبی میتواند نقش بهسزایی در بارگذاری تصاویر موجود در سایت داشته باشد.
مزیت مدل پرسپترون این است که به دلیل سادگی، به انجام محاسبات پیچیدهای نیاز ندارد.
یکی از معایب اصلی این مدل این است که نمیتوان از آن برای دستهبندی دادهها با بیش از دو گروه استفاده کرد و صرفاً این مدل برای دستهبندی دوتایی (Binary) استفاده میشود. همچنین، در هنگام بهروزرسانی وزنها، ممکن است یادگیری مدل در نقطه «کمینه محلی» (Local Minimum) متوقف شود و یادگیری مدل بهطور کامل انجام نشود.

شبکه عصبی پیچشی
از شبکه عصبی پیچشی به منظور استخراج ویژگی از دادههای ورودی و پردازش تصویر استفاده میشود. این شبکه از دو لایه اصلی با نامهای «لایه پیچشی» (Convolution Layer) و «لایه فشردهساز» (Pooling Layer) ساخته شده است. از لایه پیچشی به منظور استخراج ویژگی و از لایه فشردهساز برای کاهش ابعاد بردار خروجی لایه پیچشی استفاده میشود.
یکی از کاربردهای اصلی این شبکه عصبی در رسانههای اجتماعی مانند فیسبوک و اینستاگرام، تشخیص چهره است. زمانی که شخصی، دوست خود را بر روی تصویری «ضمیمه» (Tag) میکند، این مدل تشخیص چهره را در تصویر انجام میدهد. در بررسی ویدئو، پردازش زبان طبیعی و پیشبینی وضعیت آب و هوا نیز میتوان از شبکه عصبی پیچشی استفاده کرد.
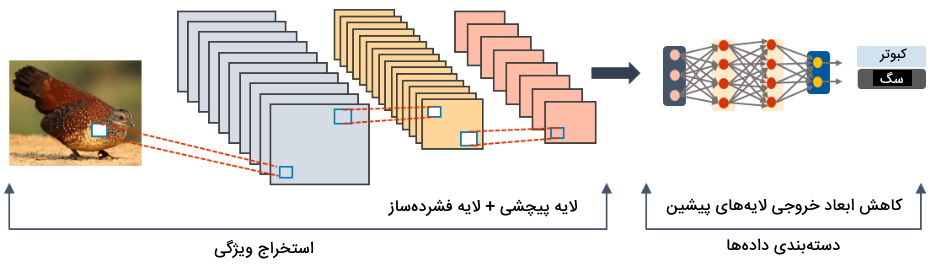
یکی از مزیتهای مهم شبکه عصبی پیچشی این است که از آن میتوان به منظور استخراج ویژگی با ابعاد پایین استفاده کرد. همچنین، در پژوهشهای مربوط به تشخیص اشیا/تصاویر، نتایج این مدل در مقایسه با سایر مدلها از دقت بالاتری برخوردار است. بهعلاوه، تعداد پارامترهای این شبکه در مقایسه با سایر شبکهها کمتر است. بدینترتیب، این شبکه به محاسبات کمتری در حین یادگیری احتیاج دارد.
از معایب اصلی شبکه عصبی پیچشی میتوان به این مورد اشاره کرد که وقتی تعداد لایههای این شبکه زیاد میشود، بار محاسباتی شبکه بیشتر شده و برای آموزش مدل، به زمان بیشتری نیاز است. علاوهبراین، این مدل به دادههای آموزشی بسیار زیادی برای رسیدن به دقت بالا در یادگیری نیاز دارد. بدینترتیب، هزینه مالی و زمانی زیادی را باید برای آموزش این شبکه در نظر گرفت.
شبکه عصبی بازگشتی
زمانی که فردی با صفحه کلید موبایل متنی را تایپ میکند، کلمات بعدی جمله بهصورت خودکار به او پیشنهاد میشوند. یکی از کاربردهای شبکه عصبی بازگشتی پیشنهاد کلمات مناسب برای تکمیل کردن جمله است.
در شبکههای عصبی بازگشتی، حافظهای وجود دارد که از آن برای نگهداری اطلاعات ورودیهای قبلی شبکه استفاده میشود. این اطلاعات در هنگام پردازش ورودی فعلی شبکه مد نظر قرار میگیرند. گوگل، موتورهای جستجو و مرورگرهای وب از شبکه عصبی بازگشتی به منظور ارائه پیشنهادات «پرس و جو» (Query) و تکمیل کردن عبارت تایپ شده توسط کاربر استفاده میکنند.
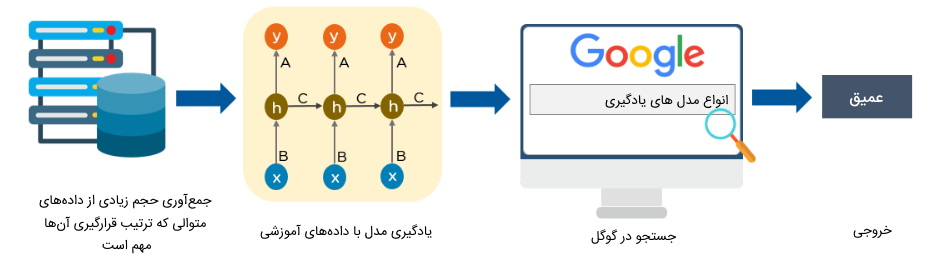
توانمندی ذخیره اطلاعات پیشین در شبکه، از مزیتهای اصلی شبکه عصبی بازگشتی محسوب میشود. این قابلیت باعث شده است که این نوع شبکه عملکرد خوبی در پردازش دادههای ورودی وابسته به هم داشته باشد.
از معایب اصلی شبکه عصبی بازگشتی، زمانبر بودن بار محاسباتی و پردازش دادهها است زیرا عمل پردازش دادهها باید به تعداد ورودیهای شبکه تکرار شوند. همچنین، چنانچه طول ورودیهای این شبکه زیاد باشد و از توابع فعالسازی «تانژانت هذلولوی» (Hyperbolic Tangent به اختصار Tanh) یا «واحد خطی اصلاح شده» (Rectified Linear Unit | ReLU) در این شبکه استفاده شود، یادگیری شبکه با اختلال مواجه میشود و وزنهای لایههای ابتدایی شبکه بهروزرسانی نمیشوند.
حافظه طولانی کوتاه مدت
مدل حافظه طولانی کوتاهمدت نوعی از شبکه عصبی بازگشتی محسوب میشود که قادر است دادههای به هم وابسته با طول زیاد را به خوبی یاد بگیرد. به عبارتی، در مسئله پیشبینی کلمه، با توجه به کلمات پیشین، عملکرد این مدل نسبت به مدل بازگشتی بهتر است.
توابع فعالسازی درون این شبکه مشخص میکنند که چه اطلاعاتی از دادههای پیشین شبکه باید در اعمال محاسبات بر روی ورودی فعلی مدل تاثیر داشته باشند و کدام اطلاعات دور ریخته شوند. از این مدل برای یادگیری دادههایی استفاده میشود که بین آنها وابستگی وجود دارد. موضوعات مربوط به تحلیل متن، پیشبینی وضعیت آب و هوا و شناسایی ناهنجاریها در ترافیک شبکه از جمله پژوهشهایی هستند که با مدل حافظه طولانی کوتاهمدت میتوان به حل آنها پرداخت.
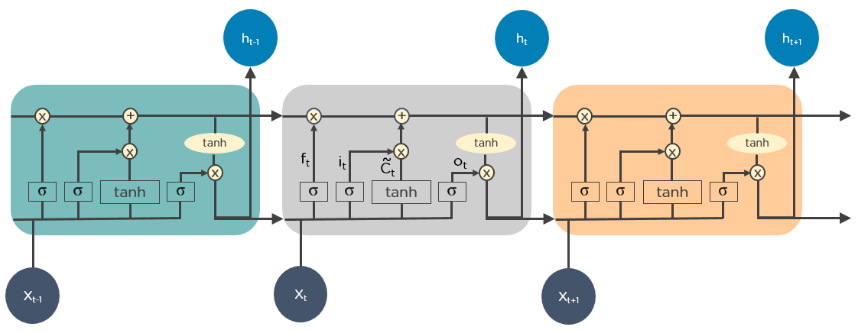
مزیت اصلی مدل حافظه طولانی کوتاهمدت، در نظر گرفتن وابستگی بین ورودیهای مدل است. همچنین، از این مدل میتوان برای پردازش دادههایی استفاده کرد که ترتیب قرارگیری آنها از اهمیت بالایی برخوردار است.
یکی از مهمترین معایب مدل حافظه طولانی کوتاهمدت این است که برای پردازش ورودیها به زمان و محاسبات زیادی احتیاج دارد. همچنین، ممکن است شبکه به وضعیت «بیش برازش | انطباق بیش از حد» (Overfitting) برسد.
شبکه مولد تخاصمی
شبکه مولد تخاصمی به عنوان یکی از الگوریتمهای رویکرد بدون نظارت محسوب میشود که هدف آن تولید «نمونههای» (Examples) جدیدی است که با دادههای آموزشی مشابهت داشته باشد.
شبکه مولد تخاصمی از دو شبکه عصبی با نامهای «شبکه مولد» (Generator Network) و «شبکه تفکیک کننده» (Discriminator Network) تشکیل شده است. شبکه مولد، مسئولیت تولید نمونههای جدید را برعهده دارد و شبکه تفکیک کننده نمونه تولید شده جدید را مورد ارزیابی قرار میدهد تا مشخص کند آیا این تصویر، جزء دادههای اصلی آموزشی است یا این تصویر توسط شبکه مولد تولید شده است.
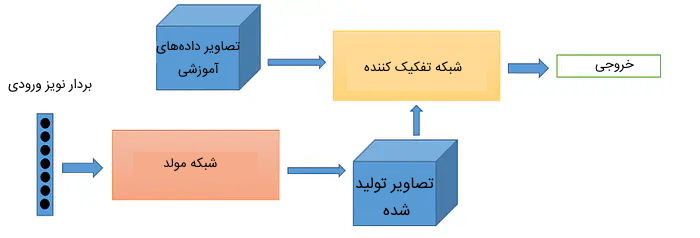
برخی از کاربردهای شبکه مولد تخاصمی در طراحی بازیهای کامپیوتری، ویرایش تصاویر، تولید متون علمی و رمان، تولید شخصیتهای کارتونی است.
یکی از مهمترین مزیت شبکههای مولد تخاصمی این است که از دادههای آموزشی بدون برچسب استفاده میکنند. به همین خاطر، در هزینه مالی و زمانی صرفهجویی میشود زیرا نیازی به تهیه دادههای آموزشی برچسبدار نیست.
یکی از معایب اصلی مدل مولد تخاصمی، بار محاسباتی و زمان زیاد برای یادگیری شبکه است. این شبکه از دو شبکه مجزا تشکیل شده است که هر کدام از آنها وزنهای مجزا دارند. بدینترتیب، یادگیری همزمان دو شبکه، زمانبر است. همچنین، مقایسه تصویر تولید شده با تصاویر دادههای آموزشی نمیتواند معیار سنجش مناسبی برای عملکرد مدل باشد زیرا تصاویر تولید شده لزوماً با تصاویر آموزشی شباهت ندارند.

مدل خودرمزگذار
مدل خودرمزگذار یکی از الگوریتمهای بدون نظارت است که کاربردی مشابه با کاربرد روش «تحلیل مولفه اساسی» (Principle Component Analysis | PCA) در یادگیری ماشین دارد. از هر دو روش مذکور، به منظور تبدیل کاهش ابعاد دادهها استفاده میشود.
به منظور درک بهتر عملکرد مدل خودرمزگذار میتوان از مثال ملموسی استفاده کرد. فرض کنید فردی قصد دارد برای دوست خود فایل نرمافزاری را به اشتراک بگذارد که حجم آن برابر با یک گیگابایت است. اگر این شخص بخواهد فایل نرمافزاری را بر روی یک بستر اینترنتی نظیر «گوگل درایو» (Google Drive) بارگذاری کند، به زمان زیادی احتیاج دارد. اما اگر این شخص فایل را به حالت فشرده تبدیل کند، حجم آن کاهش مییابد و میتواند در بازه زمانی کمتری این فایل را در بستر اینترنتی به اشتراک بگذارد. فرد گیرنده نیز میتواند پس از دریافت فایل، آن را از حالت فشرده خارج کند و به فایل اصلی دسترسی داشته باشد.
در مثال قبل، فایل نرمافزاری که حجم یک گیگابایت داشت، ورودی عملیات فشردهسازی محسوب میشود. همچنین، به عملیات فشردهسازی فایل، رمزگذاری داده گفته میشود و عملیات خارج کردن فایل اصلی از حالت فشره، رمزگشایی داده نام دارد. این عملیات، روالی است که در مدلهای خودرمزگذار انجام میشود. به عبارتی، این مدلها از 3 جزء اصلی تشکیل شدهاند:
- «کدگذار» (Encoder): بخش کدگذار مدل، مسئولیت فشردهسازی ورودی را در برعهده دارد. این عملیات فشردهسازی به نحوی انجام میشود که بتوان داده فشرده شده را به حالت اولیه خود بازگرداند.
- «کد» (Code): لایه کد به عنوان لایه میانی مدل، تصمیم میگیرد کدام یک از جنبههای داده ورودی باید نادیده گرفته شوند و کدام جنبه از دادهها باید باقی بمانند.
- «کدگشا» (Decoder): بخش کدگشا، کد فشرده شده را به حالت اولیه خود تبدیل میکند.
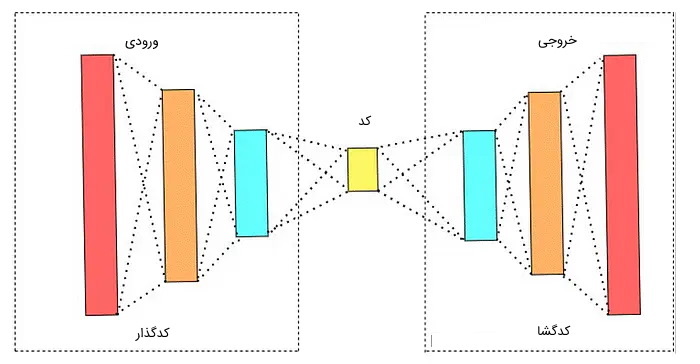
از فشردهسازی تصاویر، حذف نویز و تشخیص سرطان سینه میتوان به عنوان برخی از کاربردهای مدلهای خودرمزگذار یاد کرد.
یکی از مهمترین مزیتهای مدلهای خودرمزگذار، کاهش ابعاد دادههای حجیم است. بدینترتیب، میتوان از بخش کدگذاری شده دادهها در سایر مدلهای یادگیری عمیق استفاده کرد.
مدل خودرمزگذار در مقایسه با مدل مولد تخاصمی، کارایی مناسبی برای تولید مجدد تصاویر ندارند که همین امر، جزء یکی از اصلیترین معایب این مدلها محسوب میشود. بهعلاوه، در زمان فشردهسازی دادهها ممکن است اطلاعات مهمی دور ریخته شوند و پس از مرحله کدگشایی، نتوان آن اطلاعات را بازگرداند.
مدل ترسیم خودسازمان دهنده
در شرایطی که حجم عظیمی از دادهها وجود داشته باشند که هر کدام از آنها، دارای ویژگیهای زیادی هستند، به منظور درک بهتر روابط بین ویژگیها نمیتوان بهراحتی از ابزارهای عادی مصورسازی داده استفاده کرد. در این حالت، بهترین روش نمایش ویژگیها، استفاده از مدل ترسیم خودسازمان دهنده است. این مدل برای تصویرسازی ویژگیها، ابعاد دادهها را کاهش میدهد و ویژگیهای غیرمرتبط را حذف میکند.
در این روش، دادههای مشابه دستهبندی میشوند و بهشکل یکبعدی یا دوبعدی به نمایش درمیآیند. روش کار این مدل، مشابه با سایر مدلهای یادگیری عمیق است. وزنهای شبکه در ابتدا بهصورت تصادفی مقداردهی میشوند و در هر گام از یادگیری شبکه، یک نمونه جدید از دادههای ورودی انتخاب شده و میزان شباهت آن با سایر دادهها سنجیده میشود.
بخشی از مدل که «واحد بهترین انطباق» (Best-Matching Unit | BMU) نام دارد، نزدیکترین داده آموزشی به نمونه انتخاب شده را مشخص میکند و پس از بهروزرسانی بردار وزنهای آن، فاصله سایر دادههای آموزشی مشابه به نمونه جدید نیز کمتر میشود. با تکرار این روند، تمامی دادههای مشابه، در فضای دوبعدی در نزدیکی هم قرار خواهند گرفت.
از این مدل برای تحلیل تصاویر، کنترل و بررسی پردازشها، تشخیص خطا و در حوزه پزشکی برای تصویرسازی سهبعدی دادهها استفاده میشود.
یکی از مزیتهای اصلی مدل ترسیم خودسازمان دهنده این است که برای درک و تفسیر بهتر دادهها، میتوان آنها را با استفاده از این مدل به تصویر کشید. همچنین، با کاهش ابعاد دادههای ورودی توسط این مدل میتوان بهسادگی شباهت دادهها را تشخیص داد.
یکی از معایب اصلی مدل ترسیم خودسازمان دهنده این است که چنانچه حجم دادههای آموزشی برای این مدل، خیلی کم یا خیلی زیاد باشد، مدل نمیتواند اطلاعات دقیقی را در خروجی به تصویر بکشد.
رایج ترین زبان های برنامه نویسی یادگیری عمیق چیست ؟
برنامه نویسانی که در حوزه یادگیری عمیق فعالیت میکنند، بر اساس پژوهشهای مختلف، از زبانهای برنامه نویسی متفاوتی استفاده میکنند. به عنوان مثال، بسیاری از متخصصان هوش مصنوعی برای انجام پژوهشهای پیرامون پردازش زبان طبیعی، زبان برنامه نویسی پایتون را انتخاب میکنند. همچنین، افرادی که در حوزه امنیت و تشخیص حملات شبکه فعالیت دارند، زبان برنامه نویسی جاوا را به سایر زبانهای برنامه نویسی ترجیح میدهند.

همچنین، مهندسان کامپیوتر که به یکی از زبانهای برنامه نویسی خاصی تسلط دارند، ترجیح میدهند برای انجام پروژههای مرتبط با یادگیری عمیق از همان زبان استفاده کنند. با این حال، صرف نظر از ترجیحات و سلیقههای شخصی افراد، میتوان رایجترین و پرکاربردترین زبانهای برنامه نویسی حوزه یادگیری ماشین و یادگیری عمیق را به شرح زیر لیست کرد:
- زبان برنامه نویسی پایتون (Python)
- زبان برنامه نویسی R
- زبان برنامه نویسی Julia
- زبان برنامه نویسی جاوا
- زبان برنامه نویسی Lisp
- زبان برنامه نویسی متلب
در ادامه، به ویژگیهای زبانهای ذکر شده در بالا و ابزارهای مرتبط با حوزه هوش مصنوعی در این زبانها پرداخته میشود.
کاربرد زبان برنامه نویسی پایتون در یادگیری عمیق چیست ؟
در سالهای اخیر، زبان پایتون به عنوان یکی از محبوبترین زبانهای برنامه نویسی حوزه یادگیری عمیق شناخته میشود. بسیاری از متخصصان علم داده و هوش مصنوعی از این زبان برای تحلیل داده و پژوهشهای مربوط به علم داده و هوش مصنوعی استفاده میکنند زیرا این زبان علاوهبر این که ساده است، دارای کتابخانههای مختلفی برای پیادهسازی مدلهای یادگیری ماشین و یادگیری عمیق است. از پایتون در پروژههای مختلف برنامه نویسی شرکتهای بزرگی نظیر گوگل، اینستاگرام، فیسبوک، نتفلیکس، یوتوب و آمازون استفاده میشود.

افرادی که به دنبال پیادهسازی مدلهای یادگیری ماشین و یادگیری عمیق با استفاده از زبان پایتون هستند، میتوانند از کتابخانههای این زبان بهراحتی استفاده کنند که در ادامه به آنها اشاره شده است:
- کتابخانههای NLTK ،SciKit و NumPy برای کار با دادههای متنی استفاده میشوند.
- کتابخانههای Sci-Kit و OpenCV برای پردازش تصاویر کاربرد دارند.
- از کتابخانه Librosa میتوان برای پردازش دادههای صوتی استفاده کرد.
- از کتابخانههای TensorFlow ،Keras و PyTorch میتوان برای پیادهسازی مدلهای یادگیری عمیق استفاده کرد.
- کتابخانه Sci-Kit برای پیادهسازی الگوریتمهای یادگیری ماشین استفاده میشود.
- کتابخانه Sci-Py برای محاسبات علمی کاربرد دارد.
- کتابخانههای Matplotlib ،Sci-Kit و Seaborn برای مصورسازی دادهها و اطلاعات به کار میروند.
کاربرد زبان برنامه نویسی R در یادگیری عمیق چیست ؟
متخصصان علم آمار زبان برنامه نویسی R را ساختهاند که از آن برای پیادهسازی الگوریتمهای یادگیری ماشین، تحلیل داده و انجام کارهای آماری استفاده میشود. این زبان، جزء زبانهای برنامه نویسی «با دسترسی باز» (Open-Source) محسوب میشود و امکان انجام عحملیات مختلف محاسبات ماتریسی را فراهم میکند.

زبان برنامه نویسی R دارای ابزارهای مختلفی برای آموزش و ارزیابی الگوریتمهای یادگیری ماشین است که در ادامه میتوان به لیستی از کتابخانههای آن اشاره کرد:
- از کتابخانه MICE برای کار با دادهها و مقادیر «گم شده» (Missing) استفاده میشود.
- کتابخانه CARET برای پیادهسازی مسائل دستهبندی و «رگرسیون» (Regression) کاربرد دارد.
- کتابخانهای PARTY و rpart برای تقسیمبندی دادهها به کار میروند.
- برای ساخت «درخت تصمیم» (Decision Tree) از کتابخانه randomFOREST استفاده میشود.
- برای دستکاری دادهها میتوان از کتابخانههای dplyr و tidyr استفاده کرد.
- به منظور مصورسازی دادهها از کتابخانه ggplot2 استفاده میشود.
- از کتابخانههای Rmarkdown و Shiny میتوان برای گزارشگیری از دادهها و اطلاعات استفاده کرد.

زبان برنامه نویسی Julia برای یادگیری عمیق
زبان برنامه نویسی Julia یکی از زبانهای برنامهنویسی پویا و همهمنظوره است که در حوزه یادگیری ماشین، به عنوان یکی از رقیبان زبانهای برنامه نویسی پایتون و R محسوب میشود. این زبان کارایی بالایی در تحلیلهای عددی و علوم محاسباتی دارد.
همچنین، زبان Julia از تمامی سختافزارهای لازم برای پیادهسازی الگوریتمهای یادگیری ماشین مانند TPU و GPU پشتیبانی میکند و از طریق این زبان میتوان مدلها را بر روی فضای ابری اجرا کرد. شرکتهای بزرگی نظیر Apple ،Disney ،Oracle و NASA از این زبان به دلیل داشتن ویژگیهای گسترده در حوزه یادگیری ماشین استفاده میکنند.

زبان Julia با داشتن فریمورک LLVM میتواند کدهای نوشته شده را در سریعترین زمان اجرا کند. بدینترتیب، برنامه نویسان حوزه یادگیری ماشین میتوانند در کمترین زمان به خروجی مدل دست پیدا کنند. همچنین، کدهای زبان Julia را میتوان با استفاده از سایر زبانهای برنامه نویسی نظیر پایتون و R کامپایل کرد. بهعلاوه، این زبان برای پیادهسازی مدلهای یادگیری عمیق و یادگیری ماشین از کتابخانههای TensorFlow ،MLBase.jl ،Flux.jl و SciKitlearn.jl پشتیبانی میکند و میتوان از «محیطهای یکپارچه توسعه» (Integrated Development Environment | IDE) مانند Visual Studio و Juno برای پیادهسازی و اجرای کدهای زبان Julia استفاده کرد.
زبان برنامه نویسی جاوا در یادگیری عمیق
اگرچه زبان پایتون و R جزء محبوبترین زبانهای حوزه یادگیری ماشین محسوب میشوند، با این حال برنامه نویسانی که تجربه کار با زبان برنامه نویسی جاوا را دارند، ترجیح میدهند با همین زبان به پیادهسازی مدلهای هوش مصنوعی بپردازند زیرا نیازی نیست زمان بیشتری را به یادگیری زبانهای جدیدی اختصاص بدهند.
ابزارهای پردازش دادههای حجیم نظیر Hadoop و Spark نیز به زبان جاوا نوشته شدهاند. بهعلاوه، بسیاری از پروژههای نرمافزاری سازمانها با زبان جاوا پیادهسازی میشوند. همین امر سبب شده است برای برنامه نویسان زبان جاوا، پیادهسازی الگوریتمهای یادگیری ماشین، استفاده از کتابخانهها، خطایابی برنامهها و نمایش گرافیکی دادههاُ سادهتر شوند.

همچنین، زبان برنامه نویسی جاوا دارای کتابخانههای بسیاری برای پیادهسازی الگوریتمهای یادگیری ماشین است. به عنوان مثال، میتوان از کتابخانه Arbiter جاوا برای تنظیم «هایپرپارامترهای» (Hyperparameters) مدلهای یادگیری ماشین استفاده کرد. بهعلاوه، با استفاده از کتابخانه Deeplearning4J میتوان الگوریتمهای رایج یادگیری ماشین مانند K-Nearest Neighbor و انواع شبکههای عصبی را پیادهسازی کرد.
کاربرد زبان برنامه نویسی Lisp در یادگیری عمیق چیست ؟
زبان برنامه نویسی Lisp که مخفف عبارت «پردازش لیست» (List Processing) است، به عنوان دومین زبان برنامه نویسی قدیمی در حوزه هوش مصنوعی محسوب میشود. تولیدکنندگان زبانهای برنامه نویسی پایتون، Julia و جاوا از کاربرد زبان Lisp در حوزه هوش مصنوعی ایده گرفتند و به توسعه ابزارها و کتابخانههای مرتبط با یادگیری ماشین و یادگیری عمیق پرداختند.
نخستین پروژه چتبات ELIZA نیز با زبان Lisp پیادهسازی شد. امروزه، از این زبان برای طراحی و ساخت چتباتهای حوزه تجارت الکترونیک نیز استفاده میشود. اگرچه این زبان برای پیادهسازی تمامی الگوریتمهای یادگیری ماشین مناسب است، اما از کتابخانههای شناخته شده حوزه یادگیری ماشین و یادگیری عمیق پشتیبانی نمیکند. همچنین، یادگیری این زبان دشوار است و به همین خاطر، جامعه مخاطبان این زبان محدود است و افراد تازهکار در حوزه یادگیری عمیق ترجیح میدهند زبانهای برنامه نویسی دیگری را در شروع یادگیری برنامه نویسی انتخاب کنند.
کاربرد زبان برنامه نویسی متلب در یادگیری عمیق چیست ؟
افراد تازهکاری که علاقهمند هستند در حوزه هوش مصنوعی مشغول به فعالیت شوند، میتوانند با یادگیری زبان برنامه نویسی متلب، به آسانی الگوریتمهای یادگیری ماشین و یادگیری عمیق را پیادهسازی کنند. همچنین، زبان متلب دارای ابزارها و توابع مختلفی برای مدیریت دادههای حجیم و مصورسازی آنها است.
یکی از مزیتهای مهم زبان متلب این است که با نوشتن تعداد کمی کد، میتوان مدلهای مختلف هوش مصنوعی را پیادهسازی کرد. بدینترتیب، این زبان برای افرادی مناسب است که دانش تخصصی و عمیق در حوزه یادگیری عمیق ندارند و بهتازگی به دنبال یادگیری این حوزه از فناوری هستند.
جمعبندی
یادگیری عمیق به عنوان یکی از مهمترین شاخههای هوش مصنوعی محسوب میشود که بسیاری از فعالیتهای سازمانها و زندگی بشر را دستخوش تغییراتی کرده است. مقاله حاضر مناسب افرادی است که به دنبال پاسخ پرسش یادگیری عمیق چیست هستند و قصد دارند با ویژگیهای مدلهای عمیق و انواع رویکردهای آنها آشنا شوند. همچنین، در این مقاله به یکی از رایجترین سوالات حوزه هوش مصنوعی با عنوان «تفاوت بین دو شاخه یادگیری ماشین و یادگیری عمیق چیست» پرداخته شد و کاربرد هر یک از این حیطهها مورد بررسی قرار گرفت. بهعلاوه، در پایان مطلب حاضر، به معرفی برخی از رایجترین مدلهای یادگیری عمیق اشاره و کاربرد و ویژگیهای هر یک از آنها شرح داده شد.








چقدر خوب بود و مفید 💥💥💥💥💥💥
عالی بود و کامل
بسیار عالی بود. متشکر بابت تهیه این مطالب.
عالی بود
سلام مطالب شما بسیار عالی و مفید بود
با تشکر فراوان احسنت