


آموزش پایتون: مفاهیم OpenCV برای تشخیص چهره و حرکت – راهنمای مقدماتی
شکی نیست که علم داده (به طور کلی) موضوع مهمی در زمینه علوم محسوب میشود و بر اساس آمارهای مختلف مشخص شده است که دانشمندان داده، پایتون را دوست دارند. یادگیری برخی جنبههای علم داده و پایتون با همدیگر یک ایده عالی محسوب میشود. به همین دلیل است که قصد داریم در بخشهای باقیمانده این سری مطالب آموزشی روی کاربردهای واقعی علم داده با بهرهگیری از پایتون متمرکز شویم. ما در این مقاله ابتدا مفهوم بینایی ماشین را توضیح میدهیم. البته این بدان معنی نیست که قصد داریم یک سیستم برای اتومبیلهای خودران بسازیم؛ بلکه میخواهیم در این مقاله کوتاه چندین نکته را در خصوص مفاهیم مقدماتی OpenCV بیاموزیم.




برای مطالعه قسمت قبلی این مجموعه مطلب روی لینک زیر کلیک کنید:
مسیر پیش رو طولانی است و لذا هر جا که احساس خستگی کردید کمی استراحت کنید. ابتدا باید OpenCV را نصب کنیم که اختصاری برای عبارت کتابخانه «بینایی ماشین متنباز» (Open Source Computer Vision) است. برای نصب آن کافی است دستور زیر را وارد کنید:
pip3 install opencv-python –user
توجه کنید که گاهی از اوقات ممکن است امکان دانلود مستقیم کتابخانه OpenCV را با کمک مخزن اصلی پایتون نداشته باشید. این مسئله به طور خاص در شرایطی پیش میآید که اینترنت بینالمللی قطع شده باشد. در چنین شرایطی باید توانایی نصب OpenCV با کمک میرورهای داخلی را داشته باشیم. برای انجام این کار میرورهای مختلفی در دسترس هستند.
گام 1: بارگذاری، نمایش و تغییر اندازه تصاویر
کار خود را با این مراحل ساده آغاز میکنیم.
از آنجا که بینایی ماشین کلاً به تصاویر و ویدئوها مربوط میشود، ابتدا چند کار مانند بارگذاری، نمایش دادن، تغییر دادن اندازه تصاویر و نوشتن (ذخیره) آنها را مورد بررسی قرار میدهیم. احتمالاً تاکنون در شبکههای اجتماعی با برخی تصاویر که نوشتههای خندهداری روی آنها نوشته شده است مواجه شدهاید. این تصاویر meme نام دارند و از آنجا که meme زبانی است که همه ما درک میکنیم، در ابتدا از ساخت یک meme آغاز میکنیم.
پیش از ادامه این مبحث لازم است یادآور شویم که میتوانید OpenCV را با استفاده از مجموعه آموزش اپن سی وی فرادرس یاد بگیرید.

ابتدا مانند همیشه کتابخانه خود را ایمپورت میکنیم. سپس با تابع imread در OpenCV تصویر را بارگذاری میکنیم. پارامتر دوم یا 0 (به معنی خاکستری)؛ یا 1 (RGB) و یا 1- (امکانات شفافسازی) است. اندازه تصویر ما 1200×675 است. نکته مهم که باید دقت داشته باشیم این است که تصویر ما به صورت یک آرایه numpy با ابعاد N-بعدی بارگذاری میشود. اگر به خروجی نگاه کنید میبینید که تصویر ما دارای لبههای سفید است. به همین دلیل است که مقادیر پیکسل هر چهار گوشه برابر با 255 است. در ادامه بررسی میکنیم که وقتی به جای پارامتر 0 از 1 استفاده کنیم آرایه ما به چه ترتیبی نمایش مییابد.

تغییر دادن اندازه تصویر
تغییر دادن اندازه تصویر کار آسانی است. ما تابع cv2.resize را فراخوانی میکنیم و تصویر خود را به صورت آرگومان نخست و اندازه مطلوب را به صورت آرگومان دوم ارسال میکنیم. اینک برای نمایش و ذخیرهسازی تصویر، باید موارد زیر را درک کنیم.
- cv2.imshow یک پنجره برای نمایش تصویر ایجاد میکند که آرگومان نخست نام آن پنجره و آرگومان دوم تصویری است که باید نمایش یابد.
- cv2.imwrite برای ذخیرهسازی تصویر تولید شده استفاده میشود.
- cv2.waitKey برای دانستن این که چه زمانی باید از پنجره خارج شویم استفاده میشود. 0 به این معنی است که با زدن هر کلیدی خارج میشوید. با این وجود میتوانیم زمان خاصی را نیز به صورت (cv2.waitKey(2000 تعریف کنیم که به صورت خودکار پس از 2 ثانیه بسته شود.
- cv2.destroyAllWindows همه پنجرههای فعال را میبندد.

گام 2: تغییر دستهای اندازه تصاویر
ما ربات نیستم و بلکه انسانیم و از این رو موجوداتی هوشمند محسوب میشویم. ما دوست نداریم همه تصاویر را به صورت تک به تک تغییر اندازه بدهیم و به جای آن از عقل خود کمک میگیریم. بدین ترتیب کارها به روشی بسیار آسانتر انجام مییابند. GLOB در کد زیر همه تصاویر با پسوند jpg. درون دایرکتوری را پیدا میکند:
گام 3: تشخیص چهره در تصاویر
آیا تاکنون با نوعی فناوری تشخیص چهره مواجه شدهاید. این فناوری امروزه بسیار متداول شده است و در بخش دوربین گوشیهای تلفن همراه و یا روی برخی از نرمافزارها که روی لپتاپ نصب میکنیم از طریق وبکم آن استفاده میشود. در این زمان شاهد کادرهای سبز رنگی هستیم که پیرامون چهره افراد موجود در تصاویر نقش میبندد. شاید کنجکاو باشید که طرز کار این نرمافزارها چگونه است. البته نکته خاصی در مورد طرز کار آنها وجود ندارد، برای این که کد ما نیز چنین کاری انجام دهد، صرفاً باید دو بخش دیگر به نامهای Cascade Classifier و Detect Multi-Scale به آن اضافه کنیم و این کار را در ادامه انجام خواهیم داد.
()cv2.CascadeClassifier
این یک ابزار «طبقهبندی آبشاری» (Cascade Classifier) است که به وسیله چند صد نمای ساده «مثبت» از یک شیء خاص (یعنی چهره) و تصاویر «منفی» دلخواه با همان اندازه آموزش دیده است. به محض این که ابزار طبقهبندی، آموزش دید، میتواند روی یک تصویر جدید استفاده شده و شیء مورد نظر را تشخیص دهد. در این مقاله، ما ابزار طبقهبندی frontface از پیش آموزش دیده را برای تشخیص چهره در تصویر استفاده خواهیم کرد.
()face_cascade.detectMultiScale
از این ابزار برای دانستن مکان دقیق چهره در تصویر استفاده میشود. ما اینجا دو پارامتر داریم. در ادامه با ماهیت آنها آشنا شده و فایدهشان را بررسی میکنیم. اندازه تصویر را طوری تغییر میدهد که وقتی چهرههای بزرگتر یا کوچکتر وجود داشته باشند، الگوریتم بتواند آنها را تشخیص دهد.

از یک گام کوچک مانند 1.05 برای تغییر اندازه استفاده کنید. 1.05 به این معنی است که اندازه تصویر به اندازه 5 درصد کاهش مییابد و بدین ترتیب احتمال تطبیق اندازه با مدل تشخیص افزایش مییابد.
minNeighbors
این پارامتر روی کیفیت چهرههای تشخیص یافته تأثیر دارد. هر چه مقادیر بالاتر باشد تعداد تشخیصها کاهش مییابد؛ اما کیفیت آنها بالاتر میرود.

اگر به خروجی نگاه کنید، چهار مقدار در شیء چهره وجود دارد. اگر این چهار مقدار را میبینید بدان معنی است که یک چهره تشخص داده شده است. اما چهره کجای تصویر است؟ پاسخ این سؤال در همان چهار مقدار است. دو مقدار نخست 241 و 153 هستند که مختصات X و Y چهره تشخیص داده شده (گوشه سمت چپ-بالا) است. دو مقدار بعدی یعنی 206 و 206 به ترتیب عرض و ارتفاع ناحیهای هستند که چهره در آن قرار دارد.
اینک که میدانیم چهره در کجای تصویر قرار دارد، میتوانیم آن را طوری نشانهگذاری کنیم که قابل تمییز باشد. بدین منظور از ()cv2.rectangle برای نشانهگذاری این کادر استفاده خواهیم کرد. پارامترهای آن بدین صورت است که پارامتر اول خود تصویر است. پارامتر دوم نقطه آغازین چهره تشخیص داده شده است که توضیح دادیم. پارامتر سوم گوشه مقابل پارامتر دوم است و در نهایت پارامتر آخر ضخامت کادری است که ترسیم خواهد شد.

بدین ترتیب میبینید که الگوریتم ما تصویر چهره الون ماسک را در حال سیگار کشیدن تشخیص داده است.
گام 4: دریافت ویدئو
اینک یک گام به سمت جلو حرکت میکنیم و تلاش میکنیم یک ویدئو را به دست آوریم. ویدئو چیزی به جز مجموعهای از تصاویر نیست و از این رو مجموعهای از فریمها نامیده میشود. همان طور که در کد زیر میبینید ما متد VideoCapture کتابخانه cv2 را فراخوانی و مقدار 0 را به آن ارسال میکنیم که به معنی دریافت ویدئو از وب کم لپتاپ است. frame آرایهای از نخستین تصویر/فریم ویدئو ترسیم میکند.


اما اگر بخواهیم ویدئوی واقعی را که وبکم ما دریافت میکند ببینیم باید چه کار کنیم؟ بدین منظور کافی است از متد cv2.imshow استفاده کنید و از چرخه تکرار همانند روشی که در زمان تغییر اندازه دستهای تصاویر استفاده کردیم، بهره بگیرید.
در این کد (waitKey(1 به این معنی است که فریمها هر 1 میلیثانیه یک بار دریافت میشوند. زمانی که حرف q را وارد کنید این حلقه متوقف شده و دریافت ویدئو متوقف میشود. در تصویر زیر عملکرد واقعی این کد را در زمان روشن بودن وبکم مشاهده میکنید.
در تصویر فوق به میزان سرعت تغییر فریمها در ویدئو توجه کنید. اینک که میدانیم چگونه یک ویدئو را دریافت کنیم نوبت آن رسیده است که به بررسی چگونگی شناسایی اشیا به صورت آنی شامل چهرهها بپردازیم.
گام 5: تشخیص حرکت
ابتدا به بررسی تئوریک تشخیص حرکت میپردازیم و سپس اقدام به کدنویسی آن میکنیم. اگر نکتهای را متوجه نشدید، صرفاً به مطالعه خود ادامه بدهید، چون زمانی که به انتهای این بخش برسیم همه چیز برایتان معنی خواهد یافت.
چرا الگوریتم تشخیص حرکت را بررسی میکنیم؟
اگر بخواهیم صادق باشیم، دلیل این مسئله آن است که این سادهترین الگوریتم است. همچنین در موارد مختلف کارایی زیادی دارد. برای نمونه اگر بخواهید یک کودک یا سگ را مورد نظارت قرار دید، به دو مرحله نیاز دارید. ابتدا باید اشیا را به صورت آنی تشخیص دهید و سپس باید زمانی که این اشیا وارد فریم شده و یا از آن خارج میشوند را ثبت کنید.
مرحله اول: تشخیص شیء
- ابتدا یک فریم را ثبت میکنیم که به صوت یک فریم پسزمینه استاتیک/خالی است و از این تصویر به عنوان تصویر مبنا استفاده میکنیم تا آن را با تصاویر دیگر مقایسه کرده و تشخیص دهیم که آیا چیزی بین فریم اول و فریمهای بعدی تغییر یافته است یا نه.
- زمانی که تصویر مبنا تعیین شد، نوبت آن رسیده است که وقتی شیء وارد فریم میشود آن را شناسایی کنیم. دقت کنید که در این روش در «فریم تغییرات» (delta frame) تصویر مبنا یک پسزمینه استاتیک به رنگ سیاه است و اینک به رنگ خاکستری تغییر یافته است. فریم دوم دلتا جایی است که از فریم استاتیک ارائه شده در مرحله قبلی استفاده کردهایم و متوجه تغییر یافتن مکان سوژه در تصویر شدهایم.


در ادامه نسخه بهبودیافتهای از فریم دلتا وجود دارد که فریم آستانه است. اگر اختلاف بین فریم قبلی و این فریم بیش از (مثلاً) 100 باشد، این پیکسلها به صورت سفید در میآیند. همان طور که میبینید، چهره موجود در این تصویر به صورت پیکسلهای سفید در آمده است در حالی که پسزمینه سیاه است.
طرز کار تشخیص حرکت یک شیء در تصویر اساساً به همین شکل است. ما ابتدا کانتورها (یعنی نقاطی که جابجا شده) تصویر سفید را مییابیم و اگر مساحت ناحیه کانتور بیش از 500 پیکسل باشد، در این صورت آن را به معنی تغییر مکان شیء ثبت میکنیم. بدین ترتیب آن شیءها را با کادرهایی مشخص میسازیم. کد نهایی به همراه توضیحات به صورت زیر است:
ویدیو در زیر نمایش داده شده است.
مرحله دوم: ثبت زمان وقوع حرکت
فرض کنید مشغول رصد حرکات یک سگ هستیم. ما روی مکانی که وی معمولاً قرار دارد یک دوربین تنظیم کردهایم. اینک قصد داریم زمان را ثبت کنیم تا بدانیم این سگ چند بار از جای خود بلند میشود تا خانه را به هم بریزد.
به این منظور ابتدا باید نقاطی را که شیء وارد فریم شده و از آن خارج میشود ثبت کنیم. ما یک شیء به نام status ایجاد میکنیم و آن را برابر با 0 و 1 (به ترتیب خطوط 20 و 47) قرار میدهیم.
اینک مقادیر را در یک لیست (خط 52) ذخیره میکنیم. این لیست مانند تصویر زیر خواهد بود. دو مورد اول none هستند، زیرا این یک فریم استاتیک است. سری صفرها به این معنی است که شیء مورد نظر در فریم نیست و سپس سریهای 1 به این معنی است که شیئی در تصویر وجود دارد.
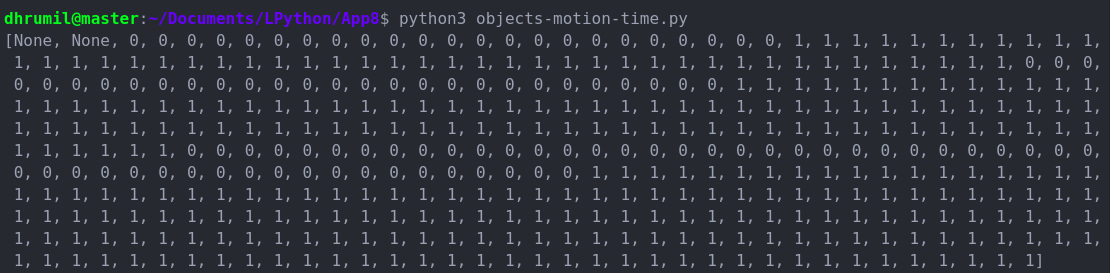
اما ما به همه این موارد نیاز نداریم. ما تنها میخواهیم مواردی را ثبت کنیم که شیء مورد نظر وارد فریم شده و از آن خارج شده است. بنابراین باید هر بار عنصر آخر را با عنصر ماقبل آخر مقایسه کنیم تا ببینیم آیا از 0 به 1 یا برعکس تغییر یافته است یا نه. اگر چنین باشد، در این صورت آن زمان را (در خطوط 54 تا 57) ذخیره میکنیم و در نهایت زمان را به دیتافریم الحاق و آن را روی سیستم ذخیره میکنیم. نتیجهای که ما به دست آوردهایم چیزی مانند تصویر زیر است. شما میتوانید آن را بر اساس نیازهای خود تنظیم سفارشی بکنید.

سخن پایانی
بینایی رایانه رشتهای است که هر روز پیشرفتهای زیادی در آن رخ میدهد. ما مطمئن هستیم که شما از برخی از این موارد آگاه هستید. علاوه بر آن، شما اینک با روش دستکاری تصاویر، طرز شناسایی یک چهره در تصاویر، چگونگی تشخیص اشیا به صورت همزمان (که کاربردهای واقعی آن در مواردی مانند اتومبیلهای خودران است) و شیوه ثبت زمان ورود و خروجی شیء به فریم آشنا هستید. بدین ترتیب شما با مطالعه این مقاله پیشرفت زیادی کردهاید و موفق شدهاید دانش نظری/مفهومی خود را به یک دانش عملی تبدیل کنید.
برای مطالعه قسمت بعدی این مجموعه مطلب آموزشی میتوانید روی لینک زیر کلیک کنید:
اگر این مطلب برای شما مفید بوده است، آموزشهای زیر نیز به شما پیشنهاد میشوند:
- مجموعه آموزشهای برنامهنویسی پایتون
- آموزش پردازش تصویر با OpenCV
- مجموعه آموزشهای هوش مصنوعی
- پردازش تصویر با OpenCV – رفع قرمزی چشم (به همراه کد پایتون و ++C)
- آموزش پایتون (Python) — مجموعه مقالات جامع وبلاگ فرادرس
- آموزش یادگیری ماشین با مثالهای کاربردی ــ بخش چهارم
==









فیلمی که در انتهای بخش «مرحله اول: تشخیص شیء» آمده اشتباه شده و مربوط به بخش قبل است.
سلام، وقت شما بخیر؛
از بابت تذکر این موضوع از شما بسیار سپاسگزاریم؛ موضوع مطرح شده بازبینی و اصلاح شده است.
سلام برای من این ارور را می دهد باید چی کار کنم
cv2.error: Unknown C++ exception from OpenCV code
سلام خسته نباشید خدمت شما
مطلب بسیار مفید بود استاد اما این خط کد رو متوجه نشدم
face_cascade = cv2.CascadeClassifier(“haarcascade_frontface_default.xml”)
و به من ارور میدهد
سلام وقت بخیر
این پیغام خطا به خاطر نبودن این فایل در مسیر opencv داده میشه اگه فایل رو توی پوشه جاری برنامه ندارید ، اونو دانلود کنید و در آدرس مشخصی قرار داده و همون آدرس رو معرفی کنید.قطعا مشکل حل میشه
سلام
برای من این خط رو ارور میده:
face_cascade = cv2.CascadeClassifier(“haarcascade_frontface_default.xml”)