
پیاده سازی الگوریتم Q–Learning در پایتون – راهنمای گام به گام
در مطالب پیشین «مجله فرادرس» با انواع آموزشهای پایتون ازجمله پیادهسازی اندیکاتور مکدی و پیادهسازی اندیکاتور شاخص قدرت نسبی RSI در پایتون آشنا شدیم. در این مطلب قصد داریم نحوه پیاده سازی الگوریتم Q-Learning در پایتون را یاد بگیریم. البته همه کدهای پیاده سازی الگوریتم Q-Learning در پایتون در قالب یک فایل زیپ و پیش از شروع آن برای دانلود در اختیار شما قرار میگیرد. اما با توجه به آموزشی بودن این مطلب، بخشهای مختلف کدها بررسی خواهند شد.


دانلود فایل آماده پیاده سازی الگوریتم Q-Learning در پایتون
با توجه به پیچیدگی کد و پیادهسازی مرحله به مرحله آن، کد نهایی برای پیاده سازی الگوریتم Q-Learning در پایتون در قالب فایل zip در لینک زیر قرار داده میشود.
- برای دانلود فایل آماده پیاده سازی الگوریتم Q-Learning در پایتون + اینجا کلیک کنید.
دسته بندی روش های یادگیری
پیش از بررسی پیاده سازی الگوریتم Q-Learning در پایتون باید گفت که به طور کلی میتوان اکثر روشهای یادگیری ماشین را در 3 دسته زیر گنجاند:
- یادگیری بدون ناظر یا نظارت نشده (Unsupervised Learning): در این روشها ورودیهای مشخصی به مدل داده میشود و بدون داشتن هر گونه برچسب (Label) و هدف (Target)، مدل خروجی مورد نیاز را تولید میکند. برای مثال شناسایی مقادیر دورافتاده (Outlier Detection) به کمک شبکههای عصبی Auto Encoder، خوشهبندی (Clustering) به کمک الگوریتم K-Means و کاهش ابعاد توسط تحلیل مولفه اساسی (Principal Component Analysis یا PCA) جزء این دسته از مدلها است.
- یادگیری با ناظر یا نظارت شده (Supervised Learning): در این روشها مدل با دریافت مجموعه دادهای شامل ورودی و خروجی متناظر، سعی میکند ارتباط بین آنها را یاد گرفته و بهترین پیشبینی ممکنه را انجام دهد. برای مثال رگرسیون (Regression) انجام شده توسط پرسپترونهای چندلایه (Multi-Layer Perceptron یا MLP) و طبقهبندی (Classification) انجام شده توسط الگوریتم K-نزدیکترین همسایه (K-Nearest Neighbors یا KNN) جز این روشها است.
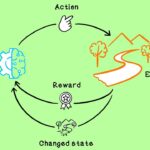
- یادگیری تقویتی (Reinforcement Learning): در این روشها یک عامل (Agent) وجود دارد که باید روش صحیح تصمیمگیری در شرایط مختلف را یاد بگیرد. این یادگیری با استفاده از فرآیند پاداش صورت میگیرد، به گونهای که عامل یاد میگیرد در هر شرایط (State) هر رفتار (Action) دارای چه کیفیتی (Quality) است. برای مثال یادگیری بازی شطرنج توسط شبکههای عصبی مصنوعی، رانندگی ماشینهای خودران و رباتهای با توانایی راه رفتن، این گونه روشهای یادگیری را مورد استفاده قرار میدهند. توجه داشته باشید که غالب تواناییهایی که انسانها در طول زندگی خود یاد میگیرند، جزء این دسته است.
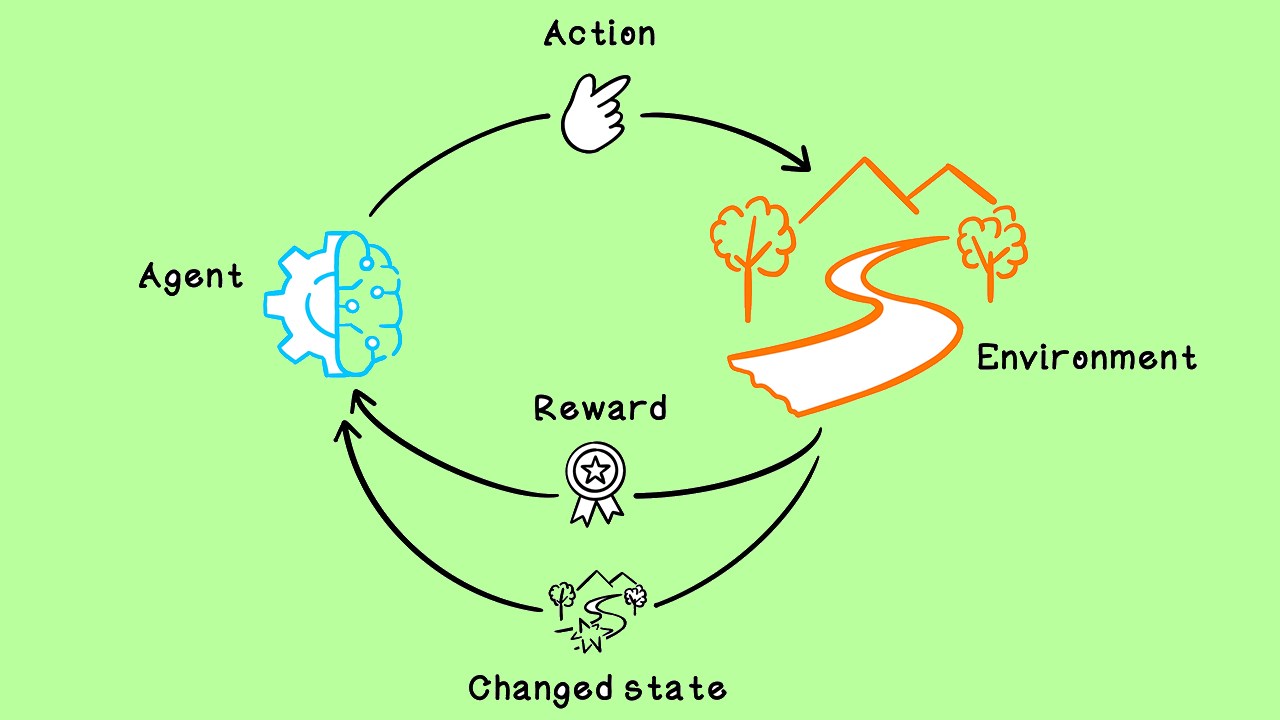
در شکل بالا یک نمای کلی از روش کار الگوریتمهای یادگیری تقویتی را مشاهده میکنید. عامل در ابتدای مسئله در شرایطقرار دارد. براساس شرایط یک تصمیم گرفته و عمل را انجام میدهد. این عمل عامل به محیط برگردانده میشود و تغییراتی در شرایط ایجاد میشود. محیط در واکنش به عملِ عامل، شرایط جدید () و پاداش دریافتی از عمل انجام شده () را برمیگرداند. این عمل تا جایی تکرار میشود که عامل به انتهای Episode برسد.
هر Episode با یک شرایط ابتدایی (Initial State) شروع میشود و به یک شرایط انتهایی (Terminal State) ختم میشود. توجه داشته باشید که بعضاً به دلیل جلوگیری از انجام گامهای بسیار زیاد، یک عدد نیز به عنوان بیشینه تعداد گام تعیین میشود و قبل از اینکه به شرایط انتهایی برسیم Episode به انتها میرسد.

در این آموزش یکی از سادهترین روشهای یادگیری تقویتی یعنی Q-Learning را مورد بررسی قرار میدهیم و سپس پیادهسازی کنیم. حرف Q از ابتدای کلمه Quality به معنی کیفیت برداشته شده است. توجه داشته باشید که هر عمل در یک شرایط خاصی بهترین انتخاب ممکن است. برای مثال غذا خوردن به تنهایی یک عمل با کیفیت خوب یا بد نیست، اما غذا خوردن در شرایطی که گرسنه هستیم یک عمل با کیفیت خوب است. درحالیکه همان عمل غذا خوردن در شرایطی که سیر باشیم یک عمل با کیفیت پایین است. به همین دلیل کیفیت با توجه به شرایط موجود و عملی که میخواهیم انجام دهیم تعیین میشود.
در Q-Learning یک نگاشت از State و Action به Q داریم که در سادهترین حالت در یک جدول ذخیره میشود که به آن Q-Table گفته میشود. جدول زیر یک مثال ساده از Q-Table است:
| عمل | |||
| شرایط↓ | غذا خوردن | هیچکدام | غذا نخوردن |
| سیر | |||
| هیچکدام | |||
| گرسنه | |||
توجه داشته باشید که باید تمامی شرایط و تمامی عملها در این جدول وجود داشته باشند. اگر فردی بخواهد براساس جدول فوق تصمیم بگیرد، ابتدا شرایط فعلی خود را تعیین میکند. سپس در سطر مورد نظر عملی که بیشترین q را دارد را انجام میدهد. برای مثال اگر فرد نه گرسنه و نه سیر باشد، سطر دوم انتخاب میشود. در این سطر بیشترین q برابر با +1 بوده و مربوط به هیچکدام است.
روش یادگیری مقادیر Q برای پیاده سازی الگوریتم Q-Learning در پایتون
این جدول در ابتدای یادگیری عامل، مقادیر ثابت (برای مثال 0) یا تصادفی به خود میگیرد و به مرور زمان مقادیر آن تنظیم میشود. برای تنظیم این مقادیر، عبارت ریاضیاتی زیر استفاده میشود:
در رابطه بالا
- : شرایط موجود
- : عمل انجام شده
- : کیفیت انجام عمل مورد نظر در شرایط فعلی قبل از به روز کردن مقادیر
- : کیفیت انجام عمل مورد نظر در شرایط فعلی بعد از به روز کردن مقادیر
- : پاداش حاصل
- : شرایط جدید
- : عملیاتهای ممکن در شرایط جدید
- : نرخ یادگیری
- : نرخ تخفیف
این عبارت به شکل زیر نیز نوشته میشود:
توجه داشته باشید که تغییرات حاصل در هر بار اعمال این معادله به شکل زیر خواهد بود:
به بخش داخل براکت Temporal Difference گفته میشود. این عبارت اختلاف پاداش مورد انتظار از مقدار فعلی را نشان میدهد. تا زمانی که مقدار این عبارت به همگرا نشود، مقادیر Q-Table بهروزرسانی خواهند شد.

ضرایب مهم در فرمول برای پیاده سازی الگوریتم Q-Learning
به بخش داخل براکت Temporal Difference گفته میشود. این عبارت اختلاف پاداش مورد انتظار از مقدار فعلی را نشان میدهد. تا زمانی که مقدار این عبارت به 0 همگرا نشود، مقادیر Q-Table بهروزرسانی خواهند شد.
با توجه به این فرم از رابطه، میتوان موارد گفته شده را تایید کرد. مقدار جدید در واقع یک میانگین وزندار از مقدار قدیمی آن و مقدار برآورد شده برای مقدار آن در گام فعلی است. توجه داشته باشید که نشاندهنده ارزش فعلی و نشاندهنده ارزش مورد انتظار در گام بعدی است. مقدار پیشنهادی برای نرخ یادگیری اغلب عدد است، اما با توجه به شرایط محیط و مسئله ممکن است مقدار بهینه غیر از باشد.
نرخ تخفیف که با نشان داده میشود، عددی بین 0 و 1 است که اغلب عددی در بازه انتخاب میشود. اگر این نرخ بزرگتر از 1 باشد، مقادیر Q واگرا (Diverge) خواهد شد که مطلوب ناست. برای مقادیر زیاد نرخ تخفیف، عامل آیندهنگر بوده و برای به دست آوردن پاداشهای بزرگ در گامهای بعدی، در گامهای فعلی متحمل ضرر خواهد بود. در عکس این حالت، اگر نرخ تخفیف کوچک باشد، عامل نزدیکبین (Myopic) بوده و بدون توجه به آینده، تنها در گامهای فعلی به دنبال کسب بیشترین پاداش خواهد بود.
نحوه پیاده سازی الگوریتم Q-Learning در پایتون
در ادامه میتوانیم پیاده سازی الگوریتم Q-Learning در پایتون را شروع کنیم. به این منظور ابتدا کتابخانههای مورد نیاز را فراخوانی میکنیم:
کتابخانه Numpy برای محاسبات، ذخیره مقادیر Q و تولید اعداد تصادفی استفاده خواهد شد. کتابخانه Colorama برای نوشتن متون با رنگ دلخواه استفاده خواهد شد. کتابخانه Matplotlib نیز برای رسم نمودار محیط، نمودار عملکرد عامل در طول زمان و مسیر حرکت عامل استفاده خواهد شد.
حال تنظیمات زیر را نیز در ابتدای برنامه لحاظ میکنیم:
برای پیاده سازی الگوریتم Q-Learning در پایتون نیاز به یک محیط نیز داریم. در این مقاله قصد داریم محیط Frozen Lake را استفاده کنیم. این محیط یک دنیای دو بُعدی است برخی نقاط آن یخزده و سالم است. در مقابل برخی نقاط نیز وجود دارند که حفره بوده و در صورتی که عامل وارد این نقاط شود، از بین رفته و یک پاداش منفی خواهد گرفت. هدف عامل نیز رساندن خود به نقطه انتهایی است که یک پاداش مثبت بزرگی برای آن دارد.
به این منظور پیادهسازی محیط و عامل، یک کلاس تعریف میکنیم:
حال اولین متد (Method) یعنی متد سازنده را ایجاد میکنیم:
این متد در ورودی 8 مقدار دریافت میکند که 6 مورد از آنها مقدار پیشفرض دارند. این 8 ورودی به ترتیب موارد زیر را تنظیم میکنند:
- H: این عدد ارتفاع محیط دو بُعدی را تعیین میکند.
- W: این عدد عرض محیط دو بُعدی را تعیین میکند.
- nEpisode: این عدد تعداد اپیزودهای آموزش عامل را تعیین میکند. مقدار پیشفرض این ورودی برابر با 600 تعیین شده است. زیاد بودن این ورودی امکان یادگیری بیشتر محیط را فراهم میکند درحالیکه ممکن است مشکلاتی نیز با خود به همراه داشته باشد.
- mStep: این عدد بیشترین تعداد گام در هر Episode را تعیین میکند. اگر عامل به این تعداد گام برسد بدون آنکه به هدف مسئله دست یافته باشد یا وارد حفره شده باشد، آن Episode به اتمام میرسد. مقدار این ورودی به صورت پیشفرض 120 تعیین شده است. با افزایش سایز محیط، مقدار این ورودی نیز باید افزایش یابد، زیرا زیاد بودن آن به عامل امکان جستجو یا Exploration را میدهد. از طرفی در برخی مسائل اگر از مقدار مشخصی کمتر باشد، مانع از رسیدن عامل به هدف میشود و یک عامل محدودکننده محسوب میشود.
- LR: این عدد نشاندهنده نرخ یادگیری است که در رابطه مربوط به بهروزرسانی Q استفاده شد. مقدار پیشفرض این ورودی 0٫1 تعیین شده است که اغلب نتیجه خوبی دارد. کوچک بودن بیش از اندازه این عدد میتواند باعث کندی یادگیری یا حتی عدم یادگیری عامل شود.
- Gamma: این عدد نشاندهنده نرخ تخفیف است. مقدار پیشفرض این ورودی برابر با 0٫99 تعیین شده است. با بزرگ شده محیط، پیچیدگی آن افزایش مییابد و عامل نیاز به انجام اعمال بیشتری دارد تا از نقطه شروع به نقطه هدف برسد. بنابراین بزرگ بودن الزامی است. در محیطهای کوچک با اندازه 4x4 یا 5x5 میتواند مقدار را کمتر در نظر گرفت.
- eps0: مقدار اولیه اپسیلون را نشان میدهد. این عدد اغلب در بازه انتخاب میشود.
- eps1: مقدار نهایی اپسیلون را نشان میدهد. این عدد اغلب در بازه انتخاب میشود.
متغیر اپسیلون چیست؟
در پیاده سازی الگوریتم Q-Learning در پایتون برای انتخاب عمل در هر شرایط، از یک سیاست (Policy) استفاده میکنیم. یک سیاست تعیین میکند که با داشتن مقادیر Q برای هر عمل در یک شرایط، کدامیک باید انتخاب شود. یکی از این سیاستها، سیاست حریصانه (Greedy Policy) است. این سیاست در هر شرایط، عملی را پیشنهاد میکند که بیشترین کیفیت یا Q را دارد. برای مثال اگر داشته باشیم:
در این شرایط، سیاست حریصانه عمل 2 را پیشنهاد میدهد، چراکه بیشترین کیفیت را دارد. سیاست حریصانه در صورتی که یک جواب نسبتاً مطلوب پیدا کند، تا انتها آن را انتخاب میکند و از آن بیشترین استفاده را میکند که به آن Exploitation گفته میشود. مشکلی که وجود دارد، ندادن شانس به سایر اعمالی است که ممکن است بتوانند بهتر عمل کنند. برای مثال ممکن است در مثال فوق عمل 1 دارای کیفیت واقعی برابر با 5 داشته باشد اما به دلیل نداده شدن فرصت کافی، کشف نشود.
به همین دلیل سیاست حریصانه همواره خوب نیست و دارای نقایصی است. سیاست دیگری که دقیقاً در نقطه مخالف قرار دارد، سیاست تصادفی (Random Policy) است. این سیاست در هر شرایط، بدون توجه به کیفیت اعمال، یکی را به صورت تصادفی پیشنهاد میدهد. این سیاست برعکس سیاست حریصانه، کاملاً بر روی Exploration تمرکز میکند و به هر عمل شانس یکسانی میدهد. از این جهت که برخی اعمال پس از گذر تعداد مشخصی Episode، ارزش حدودی خود را نشان میدهند و برای انتخاب شدن بهینه نیستند، سیاست تصادفی نیز آنچنان بهینه نبوده و نمیتواند یک سیاست مناسبی باشد.
برای رفع این مشکل، و ترکیب Exploration و Exploitation با یکدگیر برای ایجاد یک تعادل، سیاست جدیدی به نام Epsilon-Greedy ایجاد شد. در این روش یک متغیر به نام اپسیلون تعریف میشود که در ابتدای یادگیری مقداری نزدیک به 1 و در انتها مقداری نزدیک به 0 دارد. این متغیر تعادل بین جستجو و بهرهبرداری را تنظیم میکند. سیاست Epsilon-Greedy به شکل زیر تصمیمگیری میکند:
این عبارت بیان میکند، سیاست Epsilon-Greedy، در زمان یا گام t، اگر عامل در شرایط قرار داشته باشد و مقادیر را داشته باشیم، با احتمال عملی را پیشنهاد میکند که بیشترین کیفیت را دارد و با احتمال یک عمل کاملاً تصادفی را پیشنهاد میدهد. این اتفاق باعث میشود که با زیاد بودن اپسیلون، عامل به سمت جستجو برود که ابتدای یادگیری مسئله مطلوب است. در مقابل با کم شدن مقدار اپسیلون، عامل رفتارهای حریصانهتر از خود نشان میدهد که باعث میشود عامل به سمت بهرهبرداری برود که این حالت نیز در انتهای یادگیری مسئله مطلوب است.
بنابراین باید با گذر زمان اپسیلون کاهش یابد (Decay) که میتواند به شکل نمایی یا خطی باشد.
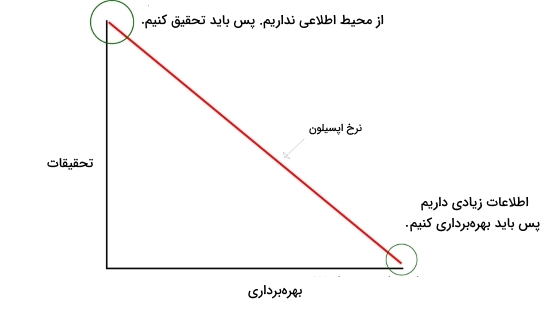
نمودار فوق به خوبی این تعادل را که توسط اپسیلون ایجاد میشود نشان میدهد.
در ورودی اخیر مربوط به متد سازنده، مقدار اولیه و نهایی اپسیلون را تنظیم میکنند.
حال ورودیهای دریافت شده در ورودی را داخل شی (Object) به عنوان Attribute ذخیره میکنیم:
به این ترتیب تمامی موارد ذخیره میشوند. حال باید برخی تنظیمات را در رابطه با شی اعمال کنیم که برخی جز قراردادهای مربوط به محیط هستند و برخی جز متغیرهای مورد نیاز در ادامه برنامه. برای این کار متد ApplySettings را در انتهای متد سازنده فراخوانی میکنیم:
حال باید این متد را تعریف کنیم:
این متد هیچ ورودی ندارد و تنها برخی موارد را اعمال و ذخیره میکند. اولین مورد که باید اعمال شود، حرکات عامل است. عامل میتواند در چهار جهت بالا، راست، پایین و چپ حرکت کند. بنابراین در یک دیکشنری (Dictionary) شماره هر عمل و تغییرات موقعیت را ذخیره میکنیم:
به این ترتیب با داشتن شماره هر عمل، میتوانیم تغییرات موقعیت را محاسبه کنیم. توجه داشته باشید که موقعیت عامل و نقاط در مختصات دکارتی نبوده و براساس شمارش ریاضیاتی در آرایهها است. بنابراین محور عمودی در اولویت بوده و شمارش عکس دارد، بنابراین حرکت در جهات بالا و پایین شامل تغییرات در بُعد اول است.
تعداد کل اعمال نیز باید به عنوان یک متغیر ذخیره شود تا بعداً در صورت نیاز استفاده شود:
مورد دیگری که باید تعیین شود، پاداش اتفاقاتی است که عامل رقم میزند. برای این منظور نیز از یک دیکشنری استفاده میکنیم:
به این ترتیب:
- اگر عامل سعی کند از مرزهای محیط عبور کند (انجام حرکت اشتباه و رخ ندادن هرگونه جابهجایی)، 1 واحد جریمه میشود.
- اگر عامل یک حرکت معمولی انجام دهد (به هدف نرسد و در حفره سقوط نکند)، به دلیل هزینه حرکت 0.1 واحد جریمه میشود.
- اگر عامل در حفره سقوط کند، 2 واحد جریمه میشود.
- اگر عامل به هدف برسد، 100 واحد پاداش میگیرد.
توجه داشته باشید که نسبت بین پاداشها و جریمهها بسیار مهم است و باید به درستی انتخاب شود. چراکه یادگیری عامل براساس این پاداشها است و براساس آنها تربیت میشود.
حال باید شمارهگزاری نقاط را نیز انجام دهیم. به این منظور نیز از یک دیکشنری دیگر استفاده میکنیم که با دادن نوع نقطه، کد مربوطه را دریافت کنیم:
به این ترتیب:
- نقاطی که یخزده هستند با کد 0 نشان داده خواهند شد.
- نقطه شروع با کد 1 نشان داده میشود.
- حفرهها با کد 2 نشان داده میشوند.
- هدف با کد 3 نشان داده میشود.
- نقاط بیرون از محیط با کد 4 نشان داده میشوند.
تنظیماتی که تا به اینجا اعمال شدند، جزء قراردادهای ما برای کدنویسی بودند. توجه داشته باشید که این موارد را میتوان به اشکال دیگر نیز توصیف و کدنویسی کرد.
حال دو متغیر جدید با نامهای MinQ و MaxQ ایجاد میکنیم. مقداردهی اولیه Qها نیز براساس این مقادیر خواهد بود:
توجه داشته باشید که در شرایط این مسئله، مقدار Q در بازه عادی است اما به دلیل اینکه ممکن است در ابتدای مسئله عامل برخی از Qها را بیش از اندازه تغییر دهد، بعداً ممکن است جبران کردن آن نیاز به مراحل بیشتری داشته باشد. در حالت کلی این مقادیر باید متناسب با بزرگی پاداشها باشند اما به سمت میانگین متمرکزتر باشند.
با توجه به اینکه الگوریتم به تعداد nEpisode بار تکرار میشود، باید در یک متغیر شماره Episode را ذخیره کنیم. با توجه به اینکه هنوز آموزش عامل شروع نشده است، مقدار مناسب خواهد بود:
حال باید مقادیر Epsilon را نیز برای هر Episode محاسبه کنیم. قصد داریم یک کاهش خطی (Linear Decay) استفاده کنیم، به همین دلیل تابع numpy.linspace مناسب است:
به این ترتیب به تعداد nEpisode نقطه با فاصله یکسان در بازه ایجاد میشود. در هر Episode از اجرای کد، Epsilon متناظر با آن استفاده خواهد شد.
حال باید یک آرایه برای ذخیره نقشه محیط ایجاد کنیم. این نقشه موقعیت محل شروع، محل هدف و نقاط حاوی حفره را ذخیره خواهد کرد. به این منظور از numpy.zeros استفاده میکنیم:
توجه داشته باشید که مقادیر این آرایه باید اعداد صحیح (Integer) باشند.
حال یک دیکشنری برای ذخیره مقادیر Q ایجاد میکنیم. کلیدهای (Key) آن نشاندهنده هر State و مقادیر آن (Value) آرایههایی به طول 4 خواهند بود که نشاندهنده کیفیت هر عمل هستند:
حال یک لیست و یک آرایه نیز برای ذخیره پاداش عامل در طول آموزش ایجاد میکنیم:
لیست ActionLog پاداش هر عمل را به ترتیب در خود ذخیره میکند. آرایه EpisodeLog نیز مجموع پاداش حاصل در هر Episode را ذخیره میکند. متد ApplySettings تا به اینجا کامل شده و عملکرد خود را خواهد داشت.
متد بعدی که لازم است پیادهسازی شود، برای نماش نقشه یا همان self.Map است. به این منظور متدی با نام ShowMap را ایجاد میکنیم:
برای رسم آرایه میتوانیم از matplotlib.pyplot.imshow استفاده کنیم:
نکته مهمی که باید توجه کرد، این است که محور افقی به عنوان بُعد دوم در نظر گرفته شده و برابر با عرض خواهد بود. محور عمودی نیز به عنوان بُعد اول در نظر گرفته شده و برابر با ارتفاع است.
متد بعدی که باید پیادهسازی شود، AddStart است. این متد با گرفتن مختصات مورد نظر برای محل شروع، آن را به نقشه محیط اضافه خواهد کرد:
این متد به شکل بالا خواهد بود. توجه داشته باشید که محل شروع باید خود به تنهایی نیز ذخیره شود، زیرا در انتهای هر Episode عامل به محل شروع برمیگردد. برای مقداردهی در نقشه نیز بهتر است از دیکشنری self.Type2Code استفاده کنید تا خوانایی کد بالاتر رفته و احتمال خطا کم باشد.
متد بعدی نیز برای اضافه کردن محل هدف استفاده خواهد شد. این متد نیز به شکل زیر تعریف میشود:
توجه داشته باشید که چون محل هدف مورد نیاز ناست و صرفاً تغییر مقدار مربوط به آن در آرایه نقشه کفایت میکند، آن را در شی ذخیره نمیکنیم.
متد بعدی نیز مشابه دو متد قبلی است، با این تفاوت که مجموعهای نقاط را به شکل آرایه دریافت خواهد کرده و این نقاط را در نقشه محیط به عنوان حفره مشخص خواهد کرد:
به این ترتیب 3 متد مورد نیاز برای ایجاد محیط کامل میشود.
حال باید متدی تعریف کنیم که بتواند در ابتدای هر Episode موقعیت و شرایط عامل را به حالت اولیه برگرداند. به این منظور متد ResetState را ایجاد میکنیم و به شکل زیر تعریف میکنیم:
در اولین خط، موقعیت عامل را به محل شروع برمیگردانیم. در خط دوم متد دیگری را فراخوانی میکنیم که براساس self.Position شرایط عامل را تعیین میکند.
برای متد UpdateState یک تابع ایجاد میکنیم و یک متغیر خالی از جنس رشته (String) را ایجاد میکنیم:
با توجه به اینکه عامل 8 خانه در اطراف خود را میتواند ببیند، دو حلقه ایجاد میکنیم تا در هر بُعد 3 مقدار را ایجاد کنند:
حلقه اول در بعد ارتفاع، یکی بالا، هم ارتفاع و یکی پایین را ایجاد میکند. حلقه دوم نیز در بعد عرض سمت راست، همعرض و سمت چپ را ایجاد میکند. بنابراین با ترکیب آنها، 9 موقعیت در نقشه قابل بررسی خواهد بود. تنها موردی که باید به آن توجه کرد، در برخی مسائل محل قرارگیری عامل نیز با کد مشخصی نشان داده میشود. در اینگونه مسائل، باید کد مربوط به محل قرارگیری عامل در State آورده نشود، چراکه تنها یک مقدار ممکن دارد.
حال موقعیت را برای تکتک حالتها حساب میکنیم:
با توجه به اینکه برخی از این موقعیتها ممکن است بیرون از مرزهای محیط باشد، باید با یک شرط این حالات را بررسی کنیم. اگر موقعیت حاصل درست باشد، کد مربوطه از نقشه برداشته شده و به انتهای self.s اضافه میشود. در غیر اینصورت، کد مربوط به کلید Outside به انتهای آن اضافه میشود:
به این ترتیب برای عامل در هر نقطه، یک State قابل تعریف خواهد بود که شامل 9 عدد چیده شده پشت سر هم است. نکته مهمی که باید مورد توجه قرار داد، امکان ایجاد شرایط جدیدی هست که تا به اینجا مشاهده نشدهاند. در Q-Table برای هر State باید یک سطر وجود داشته باشد. بنابراین در انتهای این تابع، یک شرط اضافه میکنیم. این شرط در صورتی که به شرایط جدیدی بربخورد، برای این شرایط یک Q تصادفی جدید در self.Q ایجاد میکند:
به این ترتیب در صورت نیاز، دیکشنری self.Q بهروزرسانی میشود.
متد بعدی که باید پیادهسازی شود، مربوط به تصمیمگیری است. این متد در هر شرایط، با توجه به سیاست تعریف شده، یه عمل را انتخاب کرده و برمیگرداند. متد را به شکل زیر تعریف میکنیم:
در ورودی، سیاست مورد استفاده نیز دریافت میشود. اولین سیاست که پیادهسازی میکنیم، سیاست تصادفی است. در صورتی که Policy ورودی برابر با R باشد، یک عمل به صورت تصادفی انتخاب میشود:
سیاست بعدی نیز سیاست حریصانه است و در صورتی که Policy ورودی برابر با G باشد استفاده میشود:
در این بخش 2 سطر به ترتیب اعمال زیر را انجام میدهند:
- برای شرایط فعلی (s) مقادیر Q استخراج میشود و در t ذخیره میشود.
- تابع argmax آرایه t را دریافت میکند و اندیسی (Index) که بیشترین مقدار را دارد را به عنوان عمل منتخب در a ذخیره میکند.
حال باید سیاست Epsilon-Greedy را نیز اضافه کنیم، به این منظور باید Policy ورودی برابر با EG باشد. در این شرایط یک عدد تصادفی از 0 تا 1 تولید شده و براساس آن یکی از دو سیاست قبلی اجرا میشود:
به این ترتیب هر سه سیاست پیادهسازی شده و به درستی کار خواهند کرد. توجه داشته باشید که برای پیادهسازی سیاست Epsilon-Greedy از توابع بازگشتی (Recursive Function) استفاده کردیم تا هم کد سادهتر بوده و هم از خوانایی بیشتری برخوردار باشد.
حال متد بعدی که باید پیادهسازی شود، مربوط به جابهجایی عامل است. با انتخاب هر کدام از 4 عمل، عامل ممکن است در یکی از جهات حرکت کند، به همین دلیل باید متد یک متد نیز تعریف شود که در این شرایط عامل را جابهجا کند و شرایط را بهروزرسانی کند. این متد در ورودی مکان جدید عامل را دریافت خواهد کرد:
حال self.Position را تغییر میدهیم و با توجه به تغییر موقعیت، State عامل نیز تغییر میکند، بنابراین نیاز است تا متد UpdateState نیز فراخوانی شود:
به این ترتیب با این متد قابلیت جابهجایی عامل فراهم خواهد شد.
حال باید متدی تعریف کنیم که با گرفتن عمل منتخب، آن را در محیط اعمال کرده و نتایج را برگرداند. این متد در ورودی عمل انتخاب شده را دریافت میکند و در خروجی، پاداش حاصل، شرایط بعدی، اتمام یا عدم اتمام Episode و پیام را انتقال میدهد. در خلال کار این متد نیز باید موقعیت عامل در صورت نیاز بهروزرسانی شود. این متد در ورودی عمل انتخاب شده را دریافت میکند:
حال باید موقعیت حاصل پس از حرکت را محاسبه کنیم. تغییرات به ازای هر عمل، در دیکشنری self.Transition ذخیره شده است. بنابراین مقدار متناظر در این دیکشنری را به موقعیت فعلی اضافه میکنیم تا موقعیت بعدی محاسبه شود:
حال یک متغیر برای ذخیره اتمام یا عدم اتمام Episode ایجاد میکنیم که به صورت پیشفرض False است:
در صورتی که عامل به حفره سقوط کند یا به هدف برسد، مقدار done به True تغییر خواهد یافت.
متغیر دیگری نیز برای ذخیره پیام حاصل از این حرکت ایجاد میکنیم. این متغیر نیز به صورت پیشفرض مقدار None به خود میگیرد و در صورت نیاز مقداردهی خواهد شد:
با توجه به اینکه نیاز است در انتهای این تابع، موقعیت عامل بهروزرسانی شود، باید موقعیت جدید نیز به شکل یک آرایه ذخیره شود. ممکن است این متغیر نیز بعداً تغییر کند:
در صورتی که عامل از محیط خارج شود، جریمه مربوط به Outside را دریافت خواهد کرد. با توجه به اینکه این موقعیت صحیح ناست، باید موقعیت جدید برابر با موقعیت فعلی باشد. همچنین در این شرایط Episode به اتمام نمیرسد و هیچ پیامی برای انتقال وجود ندارد:
در صورتی که شرط فوق صدق نکند، به این معنی است که عامل از محیط خارج نشده، بنابراین میتوانیم نوع خانه مقصد را بررسی کنیم و براساس آن پاداش عامل را تعیین کنیم. اولین حالت، شرایطی را بررسی میکنیم که عامل به یک خانه «یخزده» (Frozen) یا محل شروع (Start) رفته است. در این شرایط Episode به اتمام نمیرسد و پیامی برای انتقال وجود ندارد:
حال باید حالت مربوط به سقوط در حفره را بررسی کنیم. در این شرایط Episode به اتمام میرسد، عامل پاداش مربوط به Hole را دریافت میکند و یک پیام مبنی بر شکست عامل در رسیدن به هدف ایجاد میشود:
توجه داشته باشید که با استفاده از کتابخانه Colorama رنگ متن را به قرمز تغییر میدهیم، اما برای جلوگیری از تغییر رنگ متنهای بعدی، باید بعد از متن رنگ را به حالتی قبلی برگردانیم.
تنها حالت باقیمانده، مربوط به موفقیت عامل در رسیدن به هدف است. در این حالت عامل پاداش Goal را دریافت میکند، Episode مربوطه به اتمام میرسد و یک پیام مبنی بر موفقیت عامل ایجاد میشود:
به این ترتیب متغیرهای مورد نیاز به درستی مقداردهی خواهند شد. حال باید با استفاده از متد Move2 که قبلاً پیادهسازی شد، عامل را به موقعیت نهایی منتقل کنیم و پاداش حاصل را نیز در self.ActionLog ذخیره کنیم:
در نهایت برای استفادههای بعدی، پاداش حاصل، شرایط جدید، اتمام یا عدم اتمام Episode و پیام ایجاد شده را برمیگردانیم:
به این ترتیب به کمک این متد میتوانیم حرکت عامل در محیط را شبیهسازی و پاداش را محاسبه کنیم.
متد بعدی که نیاز داریم تا پیاده کنیم، مربوط به بهروزرسانی Q است. این متد در ورودی، شرایط، عمل انتخاب شده، پاداش حاصل و شرایط نهایی را دریافت میکند:
سپس با توجه به رابطه گفته شده در ابتدای مطلب، مقدار را بهروزرسانی میکند. ابتدا Temporal Difference را محاسبه میکنیم:
حال میتوانیم TD را به نرخ یادگیری اضافه کرده، با مقدار قدیمی جمع کرده و جایگزین کنیم:
به این ترتیب این متد میتواند پس از انجام هر عمل، مقادیر Q را تغییر داده و موجب آموزش عامل شود.
حال تنها یک متد باقی مانده تا بتوانیم آموزش عامل را کدنویسی کنیم. این متد NextEpisode نام دارد و در ابتدای هر Episode اجرا میشود تا شماره Episode را یک عدد افزایش داده و مقدار Epsilon را انتخاب کند:
توجه داشته باشید که مقدار اولیه self.Episode برابر با -1 بود، بنابراین در ابتدای اولین Episode با افزایش یک واحد آن، به 0 میرسد و اولین مقدار آرایه self.Epsilons انتخاب میشود.
حال میتوانیم متد اصلی که مربوط به آموزش عامل هست را پیادهسازی کنیم. این متد تنها یک ورودی دریافت میکند که مربوط به سیاست مورد استفاده است و به صورت پیشفرض Epsilon-Greedy استفاده خواهد شد:
حال یک حلقه ایجاد میکنیم تا برای هر Episode کدهای مربوط به آموزش را اجرا کند:
سپس در اولین اقدام، متد NextEpisode را فراخوانی میکنیم تا شروع Episode بعدی رخ دهد:
حال شماره Episode را نمایش میدهیم تا در حین کار الگوریتم، از وضعیت آن مطلع باشیم:
قبل از شروع گامها، موقعیت عامل را با محل شروع تغییر میدهیم و شرایط را Reset میکنیم. به این منظور متد ResetState را فراخوانی میکنیم:
حال موقعیت عامل را در متغیری به نام s ذخیره میکنیم:
یک حلقه به ازای تمامی گامهای ممکن ایجاد میکنیم و در هر گام یک عمل را انتخاب میکنیم. به این منظور از متد Decide استفاده میکنیم:
حال عمل انتخاب شده را انجام میدهیم و، پاداش، موقعیت جدید، اتمام یا عدم اتمام Episode و پیام حاصل را دریافت میکنیم:
حال میتوانیم مقادیر Q را با استفاده از متد UpdateQ بهروزرسانی کنیم:
به این ترتیب این گام به اتمام رسیده و عامل آموزش میبینید. حال باید پاداش حاصل را به آرایه self.EpisodeLog اضافه کنیم:
با توجه به اینکه شرایط جدید حاصل، برابر با شرایط در گام بعدی است، مقدار s را نیز با s2 تعیین میکنیم:
حال در انتهای حلقه بررسی میکنیم که آیا به انتهای Episode رسیدهایم یا نه و در صورت درست بودن، حلقه را break میکنیم:
پس از اتمام Episode باید بررسی کنیم که آیا خروج از حلقه به دلیل وقوع شرایط انتهایی بوده (Terminal State) یا بیشینه گام ممکن طی شده است. در صورتی که شرایط انتهایی رخ داده باشد، پیام حاصل را نمایش میدهیم و در صورتی که اینگونه نباشد، پیامی مبتی بر رسیدن به بیشینه تعداد گام نمایش میدهیم:
به این ترتیب دلیل اتمام هر Episode با رنگ مخصوص خود نمایش داده میشود. در انتها نیز مجموع پاداش آن Episode را نمایش میدهیم و سپس یک خط افقی به کمک متد HL رسم میکنیم:
به این ترتیب متد Train که مهمترین متد است، پیادهسازی شده و آماده کار است. برای متد HL نیز از کد زیر استفاده میشود:
حال یک تابع نیاز داریم تا مقادیر لیست self.ActionLog را در قالب یک نمودار نمایش دهد. به این منظور یک متد با نام PlotActionLog ایجاد میکنیم که در طول یک میانگین متحرک (Moving Average یا MA) را نیز دریافت میکند:
توجه داشته باشید که استفاده از میانگین متحرکها برای نشان دادن روند بهبود عملکرد الگوریتمها به خصوص در حوزه یادگیری تقویتی مرسوم است. برای آشنایی با میانگینهای متحرک، میتوانید به مطلب میانگین متحرک چیست؟ + پیادهسازی Moving Average در پایتون مراجعه کنید.
حال در ابتدا یک میانگین متحرک ساده (Simple Moving Average یا SMA) از self.ActionLog محاسبه میکنیم:
آرایه دیگری نیز برای ذخیره مقادیر محور افقی ایجاد میکنیم. به این منظور تابع numpy.arange مناسب است:
حال میتوانیم نمودار مورد نظر را رسم کنیم:
توجه داشته باشید که طول میانگین متحرک حاصل کمتر از طول لیست اولیه است به همین دلیل بخشی از ابتدای آرایه T مورد استفاده قرار نمیگیرد.
متد بعدی نیز مشابه قبلی است با این تفاوت که برای رسم self.EpisodeLog استفاده خواهد شد. به این منظور، متد زیر استفاده خواهد شد:
به این ترتیب دو متد اخیر برای مصورسازی روند آموزش عامل، به خوبی عمل خواهند کرد. در طول پیادهسازی این دو متد، از متد SMA استفاده شد. این متد نیز به شکل زیر پیادهسازی میشود:
توجه داشته باشید که در متد PlotActionLog یک لیست به عنوان ورودی اول داده میشود و متد PlotEpisodeLog یک آرایه Numpy در ورودی داده میشود. به همین دلیل بهتر است هر دو جنس در ورودی تعریف شود. برای داشتن یک میانگین متحرک ساده، به هر روز وزن برابر با میدهیم.
برای استفاده از Union باید کد زیر را به ابتدای برنامه اضافه کنیم:
تا به اینجا تمامی متدهای مورد نیاز برای آموزش و مصورسازی آموزش آن پیادهسازی شدهاند. برای تست (Test) و بررسی عملکرد عامل، یک متد دیگر باید پیادهسازی کنیم تا یک Episode را از ابتدا تا انتها شبیهسازی کرده و در نهایت نموداری از روش حرکت عامل را نشان دهد.
این متد در ورودی سیاست مورد نظر و نمایش یا عدم نمایش نمودار حرکت را دریافت میکند. با توجه به اینکه پس از اتمام Train، مدل به خوبی آموزش دیده است، استفاده از سیاست Epsilon-Greedy بیمعنی بوده و سیاست Greedy بهترین گزینه است:
حال در اولین اقدام یک خط افقی رسم کرده و سپس پیامی مبنی بر Test عامل نمایش میدهیم:
حال مشابه قبل شرایط را به شروع برگردانده، یک لیست برای ذخیره موقعیت عامل در هر گام ایجاد کرده و یک متغیر برای ذخیره پاداشها ایجاد میکنیم:
از لیست Positions برای رسم مسیر حرکت عامل استفاده خواهیم کرد. حال به تعداد گامها یک حلقه ایجاد میکنیم:
حال یک عمل را انتخاب میکنیم و آن را انجام میدهیم:
توجه داشته باشید که میتوانیم به جای متغیرهایی که نیاز نداریم، در حلقه for و خروجی توابع از Underscore استفاده کنیم.
حال موقعیت جدید عامل را به لیست اضافه و پاداش دریافتی را نیز به مقدار کل اضافه میکنیم:
حال مشابه متد Train شرایط اتمام را بررسی و پیامهای مورد نیاز را نمایش میدهیم:
حال مسیر طی شده را نیز در خروجی نشان میدهیم:
به این ترتیب متون مورد نیاز نشان داده خواهد شد. با توجه به اینکه کاربر در ورودی مقدار Plot را به False تغییر داده باشد یا نه، یک نمودار نیز برای مسیر حرکت عامل رسم میکنیم:
به این ترتیب این متد و بخشی از پیاده سازی الگوریتم Q-Learning در پایتون به اتمام میرسد. توجه داشته باشید که با تغییر سایز محیط، مقدار s=1960 باید تغییر کند.
تا به اینجا پیادهسازی محیط و عامل به اتمام رسید. حال میتوانیم یک شی از کلاس پیادهسازی شده ایجاد کنیم:
به این ترتیب یک محیط 6x8 ایجاد میشود.
حال محل شروع عامل و محل هدف را تعیین میکنیم:
در یک آرایه نیز موقعیتهایی را به عنوان حفره در نظر میگیریم و به عنوان ورودی متد AddHoles استفاده میکنیم:
حال میتوانیم با استفاده از متد ShowMap محیط را نمایش دهیم:
که در خروجی خواهیم داشت:
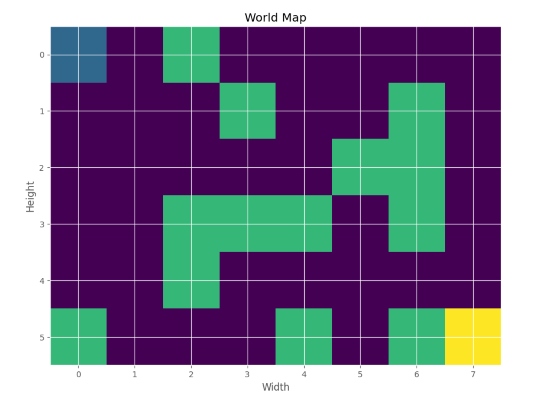
به این ترتیب مشاهده میکنیم که یک محیط با ارتفاع 6 و عرض 8 ایجاد شده است. نقطه بالا سمت چپ به عنوان محل شروع و نقطه پایین سمت راست نیز به عنوان محل هدف تعیین شده است.
حال میتوانیم متد Train را فراخوانی و عامل را آموزش دهیم:
در حین اجرای این متد نتایجی به شکل زیر نمایش داده خواهد شد:
به این ترتیب مشاهده میکنیم که عامل در ابتدای آموزش به پاداشی در حدود دست یافته و نتوانسته خود را به هدف برساند. درحالیکه در انتهای آموزش به پاداشی در حدود دست یافته و توانسته خود را به هدف برساند.
برای نمایش بهتر روند آموزش عامل، متد PlotActionLog را فراخوانی میکنیم:
که نمودار زیر را خواهیم داشت:
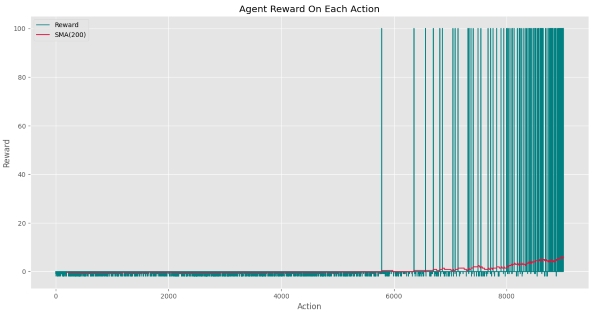
مشاهده میکنیم که تا Action شماره 5600 عامل نتوانسته پاداش مربوط به هدف دریافت کند. پس از دستیابی عامل به هدف، به مرور زمان تعداد دفعات دستیابی به هدف افزایش یافته. بهبود عملکرد عامل با شیب نمودار SMA کاملاً مشهود است. اگر تنها نمودار SMA را رسم میکردیم، نموداری به شکل زیر داشتیم:
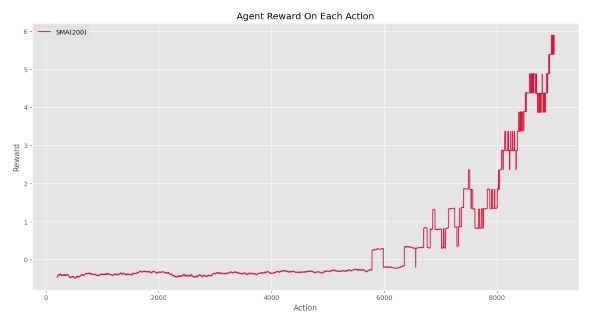
به این صورت روند بهبود میتواند آشکارتر نشان داده شود.
حال میتوانیم مجموع پاداش دریافتی در هر Episode را نیز رسم کنیم. به این منظور متد PlotEpisodeLog را فراخوانی میکنیم:
که خواهیم داشت:
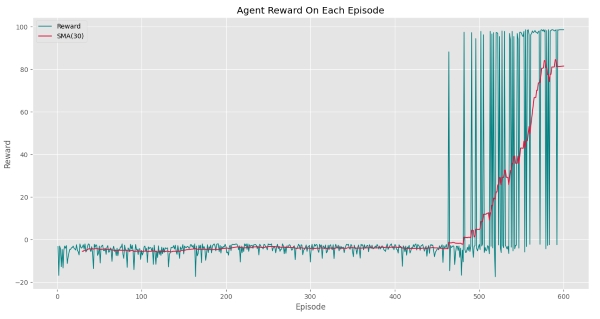
به این ترتیب مشاهده میکنیم که عامل برای اولین بار در Episode شماره 460 به هدف رسیده است و Episodeهای نهایی با احتمال بالایی هدف را یافته است. برای این تابع نیز اگر تنها SMA را رسم کنیم، خواهیم داشت:
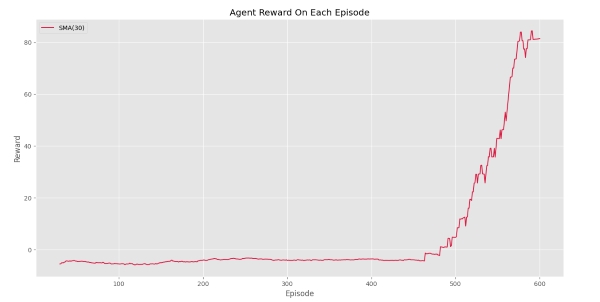
بنابراین میتوان گفت عامل در 30 Episode نهایی، به میانگین پاداش 81 دست یافته است. شروع روند افزایش پس از اولین دستیابی به هدف، نکته حائز اهمیتی است.
به این ترتیب تا به اینجا محیط را ایجاد کردیم، عامل را آموزش دادیم و روند آموزش آن را بررسی کردیم. حال میتوانیم برای بررسی عملکرد آن، از متد Test استفاده کنیم:
که نتایج زیر را برای نمایش خواهد داد:
به این ترتیب مشاهده میکنیم که عامل با سیاست حریصانه توانسته به هدف برسد و مجموع پاداش 98٫5 را دریافت کند.
در بخش بعدی نیز مسیر طی شده از ابتدا تا انتها نوشته شده است که مشاهده میکنیم عامل از موقعیت [0,0] شروع کرده و در نهایت به موقعیت [5,7] رفته است. در طول این مسیر 16 بار حرکت رخ داده که 15 مورد به خانههای یخزده بوده بنابراین مجموعاً واحد جریمه دریافت کرده است. در نهایت نیز با وارد شدن به خانه مربوط به هدف، 100 واحد پاداش دریافت کرده است که برآیند آنها برابر با 98٫5 است.
پس از متون فوق، نمودار مربوط به مسیر حرکت نیز نمایش داده میشود:
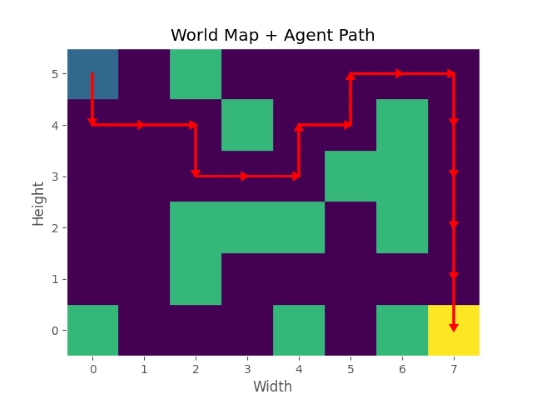
مشاهده میکنیم که عامل به درستی توانسته موانع را پشت سر گزاشته و خود را به هدف برساند. توجه داشته باشید که عامل میتوانسته مسیر سمت چپ را در پیش بگیرد که در این صورت میتوانسته به پاداش 98٫7 دست یابد که نتوانسته این مسیر را بیابد. با اینکه از سیاست Epsilon-Greedy استفاده کردهایم اما با این حال باز هم الگوریتم نتوانسته برخی جوابهای بهتر را بیابد. به همین دلیل تنظیم برخی پارامترها میتواند بسیار تاثیرگزار باشد.
به این ترتیب Test عامل نیز انجام میشود و نتایج مصورسازی میشود.
حال میتوانیم مقادیر دیکشنری Q را نیز بررسی کنیم. این دیکشنری به شکل زیر است:
به این ترتیب مشاهده میکنیم که برای 46 شرایط مختلف، مقادیر Q برای 4 عمل محاسبه و ذخیره شده است.
برای مثال خانه یکی مانده به هدف را بررسی میکنیم. این خانه به شکل زیر است:
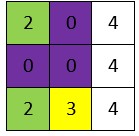
با توجه به اینکه 3 خانه سمت راست، خارج از محیط است، کد 4 را به خود میگیرند. حال اگر State را ایجاد کنید به کد زیر خواهیم رسید:
204004234
حال برای این State میتوانیم مقادیر Q را بیابیم که به شکل زیر خواهد بود:
برای سادگی مقادیر را تا دو رقم اعشار گرد میکنیم. حال میتوانیم به خوبی مشاهده کنیم که عمل سوم دارای بیشترین ارزش برابر با 100٫87 است. عمل شماره سوم، حرکت به سمت پایین بود که در این موقعیت، باعث حرکت عامل به هدف خواهد شد. از این روی این عمل دارای کیفیت نزدیک به 100 یعنی پاداش حاصل از دستیابی به هدف است.
سایر خانههای در مسیر رسیدن به هدف نیز دارای ارزش بالایی است.
نکات مهمی که در رابطه با الگوریتمهای یادگیری تقویتی باید به آن توجه کرد:
- پیادهسازی این الگوریتمها نسبت به سایر الگوریتمهای یادگیری ماشین سخت است بنابراین نیاز به دقت بالایی در کدنویسی دارد.
- تنظیم هایپرپارامترهای مربوط به مسئله و یادگیری عامل، از اهمیت بسیار بالایی برخوردار است، به نحوی که ممکن است با اندکی تغییر، عامل نتواند یاد بگیرد.
- یادگیری تقویتی بخش بزرگی از مهارتهای انسانی را شامل میشود، به همین دلیل نقش بسیار مهم و بزرگتری در آینده هوش مصنوعی دارد.
برای بررسی گزاره دوم، میتوان مقدار Gamma را از 0٫99 به 0٫95 تغییر داد. در این شرایط، نتیجه Test به شکل زیر خواهد بود:
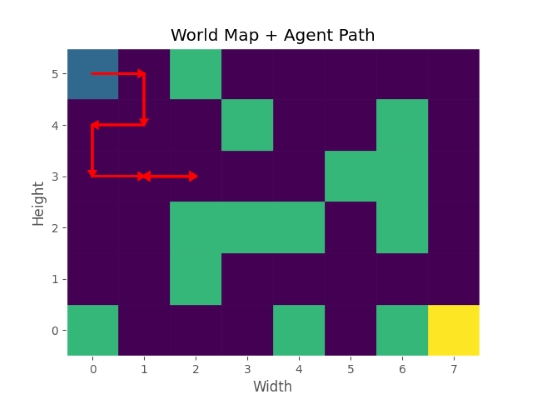
به این ترتیب مشاهده میکنیم که تغییرات کوچک در هایپرپارامترها، میتواند تا چه اندازه نتایج را تحت تاثیر قرار دهد.
همچنین اگر مقدار نرخ یادگیری یا LR را از 0٫1 به 0٫2 تغییر دهیم، نتیجه Test به شکل زیر تغییر میکند:
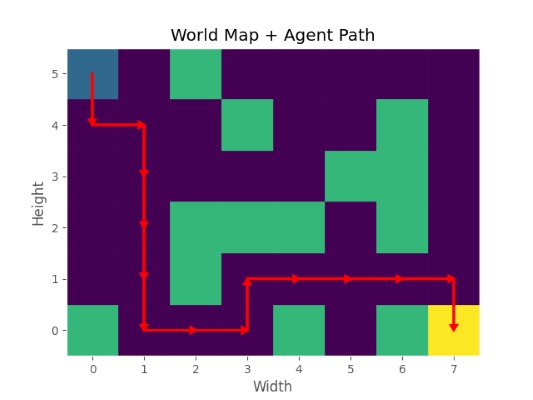
به این ترتیب عامل میتواند مسیر بهتری به سمت هدف بیابد.
مطالعه بیشتر برای پیاده سازی الگوریتم Q-Learning در پایتون
برای مطالعه بیشتر در رابطه با پیاده سازی الگوریتم Q-Learning در پایتون میتوان موارد زیر را بررسی کرد:
- اگر این پروژه بدون استفاده از شیگرایی (Object Oriented Programming یا OOP) پیادهسازی شود، چه مشکلاتی وجود خواهد داشت؟
- اگر روند کاهشی Epsilon به جای خطی (Linear Decay)، به صورت نمایی (Exponential Decay) باشد، چه اتفاقی رخ میدهد؟
- چگونه میتوان به عامل قابلیت حرکت به درون هر 8 خانه اطراف را داد؟
- اگر برای حرکت به سمت بیرون از محیط جریمهای در نظر گرفته نشود، چه مشکلی پیش خواهد آمد؟
- اگر برای محل شروع کد اختصاصی تعیین نشود و از کد 0 استفاده شود، چه اتفاقی برای سرعت یادگیری و Q-Table رخ خواهد داد؟
- اگر مقادیر MinQ و MaxQ به جای -1 و +1، برابر با -10 و +10 تعیین شود، سرعت یادگیری چگونه تغییر میکند؟
- کد مربوط به متد UpdateState را به گونهای تغییر دهید که کد مربوط به محل قرارگیری عامل را در State دخالت ندهد.
- انواع دیگری از میانگینهای متحرک نیز وجود دارد. در مورد آنها تحقیق کنید.
- اگر عامل، به جای یک مربع 3x3 به یک مربع 5x5 دید داشته باشد و بتواند در 8 جهت حرکت کند، پیچیدگی Q-Table چند برابر حالت فعلی خواهد بود؟










به شکل فوق العاده ای این مطلب عالی و بی نظیر بود
با سپاس از اقای دکتر کلامی
سلام، خیلی ممنون از بازخورد و همراهی شما. موفق باشید.