
پاسخ به چند پرسش کلیدی پیرامون شبکه های عصبی و یادگیری عمیق
در این نوشتار به چند پرسش کلیدی پیرامون شبکههای عصبی و یادگیری عمیق پاسخ داده شده است. ابتدا به این سوال پاسخ داده میشود که چرا در شبکههای عصبی برای کاهش معیار خطا از الگوریتمهای مبتنی بر گرادیان کاهشی استفاده میشود و آیا ممکن است به جای آن مثلاً از الگوریتمهای ژنتیک استفاده کرد؟




سپس به سراغ بررسی این پرسش میرویم که در شبکههای جدید یادگیری عمیق با توجه به وجود میلیونها یا میلیاردها پارامتر، چطور میتوان متوجه شد که مدل مربوطه بهترین پارامترهای موجود را پیدا کرده است؟
برای آگاهی و درک جواب هر یک از این سوالات در ادامه با مجله فرادرس همراه باشید.
پاسخ به چند پرسش کلیدی پیرامون شبکه های عصبی و یادگیری عمیق
ناگفته نماند که علاوه بر مواردی که در مقدمه اشاره شد، در این نوشته این بحث نیز مطرح میشود که طبق چه قانون ریاضیاتی میتوان اثبات کرد با تنظیم پارامترها در هر لایه شبکه عصبی، بر اساس گرادیان کاهشی، در نهایت به پارامترهای بهینه کننده مدل میرسیم؟
آیا امکان آن وجود دارد که به فرض با عدم اعمال گرادیان کاهشی در برخی لایهها، به مقادیر بهینه برای پارامترها رسید؟ یکی دیگر از سوالاتی که در این نوشته به آن پاسخ داده میشود نیز این است که با توجه به وجود تعداد پارامترهای زیاد مثلاً در مدلهای پر استفاده چطور میتوان متوجه شد که تابع خطا محدب یا شبه محدب است؟ در صورت محدب بودن چرا راجع به مینیمم محلی بحث میشود؟
چرا در شبکههای عصبی برای کاهش معیار خطا از الگوریتم های مبتنی بر گرادیان کاهشی استفاده میشود و آیا میتوان به جای آن مثلاً از الگوریتمهای ژنتیک استفاده کرد؟
در پاسخ باید گفت که در مدلهای یادگیری ماشین، تعریف خطا در اختیار خود فرد است و خطا معمولاً به گونهای تعریف میشود که با روشهای بهینهسازی کلاسیک و تحلیلی، سازگارتر باشد. از طرفی، ساختار مدلها (مثلاً شبکههای عصبی) مشخص هستند و میتوان مشتق خطا را به ازای تمام متغیرها محاسبه و در فرایند بهینهسازی استفاده کرد.
با توجه به محدب بودن (یا شبه-محدب بودن) توابع خطا در مدلهای یادگیری ماشین (که ناشی از ماهیت این مدلها و البته انتخاب آگاهانه خود ما است)، استفاده از روشهای بهینهسازی مثل گرادیان نزولی به مراتب مقرون-به-صرفهتر است.
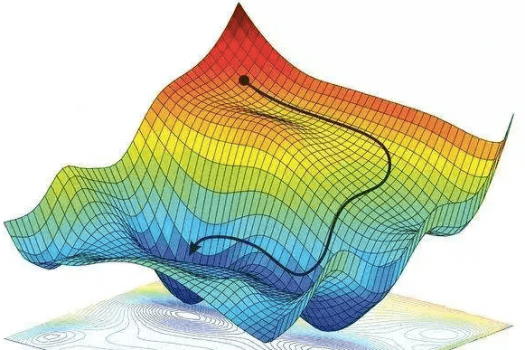
در مقابل، الگوریتم ژنتیک یا سایر روشهای محاسبات تکاملی یا روشهای بهینهسازی هوشمند، اساساً از این ویژگیهای توابع هدف و ساختار شبکه، استفاده نمیکنند. بنابراین، در فضای جستجوی بسیار بزرگ مربوط به آموزش مدلهایی مثل شبکههای عصبی، حرف زیادی برای گفتن ندارند.
با این حال، روشهای ترکیبی وجود دارند که از قابلیتهای ریاضی شیوههایی مثل GD (گرادیان نزولی) و SGD (گرادیان کاهشی تصادفی) استفاده میکنند و آن را با قابلیتهای نوآوری و اکتشاف الگوریتمهای تکاملی ترکیب میکنند تا به نتایج بهتری برسند. در ادبیات این موضوع، میتوان مقالههای خوبی را در این زمینه، به خصوص در ۱۰ سال اخیر، پیدا کرد.
با توجه به وجود میلیونها یا میلیاردها پارامتر در شبکههای جدید یادگیری عمیق چطور میتوان متوجه شد که مدل بهترین پارامترهای موجود را پیدا کرده است؟
در این خصوص نیز، اصلاً نیازی نیست که بهترین را پیدا کرد. در واقع آنچه در عمل کافی خواهد بود که نیاز ما را برآورده کند؛ هر چند بهترین جواب ریاضی نباشد. همانطور که خود ما، لزوماً بهینه نیستیم. چیزی که برای مثال یک مدیر محصول یا هیأت مدیره را در یک شرکت فناوری راضی کند، به اندازه کافی خوب است.
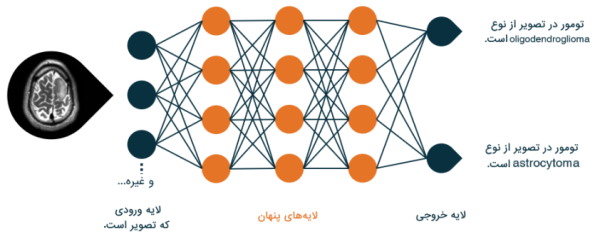
طبق چه قانون ریاضی میتوان اثبات کرد که با تنظیم پارامترها در هر لایه شبکه عصبی بر اساس گرادیان کاهشی در نهایت پارامترهای بهینه کننده مدل پیدا میشوند؟
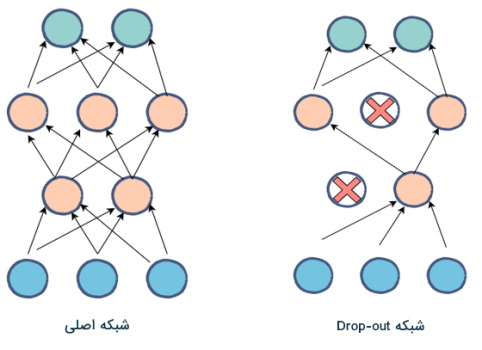
در گرادیان نزولی و هر روشی که برای بهینهسازی و تعیین پارامترها استفاده شود، هدف بهتر کردن مقدار تابع هزینه است که در نهایت، منجر به بهتر شدن عملکرد کلی مدل، البته روی دادههای آموزشی (Training Data) خواهد شد. اما برای اینکه بتوان چنین فرایندی را به نتیجه قابل تعمیم تبدیل کرد، روشهایی وجود دارند. مثلاً، تقسیم کردن دادهها یا استفاده از روشهایی مثل «متعادلسازی» (Regularization) یا لایههای Drop Out، همگی ضامن حفظ توان تعمیمدهی مدل هستند.
با توجه به وجود تعداد پارامترهای زیاد مثلاً در مدلهای پر استفاده چطور میتوان متوجه شد که تابع خطا محدب یا شبهمحدب است؟ در صورت محدب بودن چرا راجع به مینیمم محلی بحث میشود؟
نمیتوان پاسخ دقیقی در این خصوص ارائه داد. چون شکل نهایی تابع هدف، هم وابسته به ساختار شبکه و تعریف معیار عملکرد است و هم در نهایت دادههای آموزشی هم روی این موضوع تأثیر دارند. به صورت کلی، تقریباً هیچ تابع هزینهای در هیچ کاربرد عملی، محدب نیست؛ بلکه یک تابع Multi-modal به حساب میآید.
کافی است آن حالتی که پیدا میشود به اندازه کافی بتواند خوب باشد و اهداف ما را از طراحی سیستم هوشمند فراهم کند. یعنی کافی است مدل به اندازه مشخصی بهتر باشد و بتواند کاربر نهایی یا مالک محصول را راضی کند؛ همین کافی خواهد بود.
آیا در مقالههای علمی هم به درصدی از بهینگی میرسند و آن را اعلام می کنند؟
در خصوص کارهای پژوهشی، اغلب بهتر شدن از مقالات قبلی، برای داورها و جامعه آکادمیک کافی است. یا با منابع کمتر (مثل توان محاسباتی، زمان و انرژی کمتر) باید بتوان به همان نتایج قبلی دست پیدا کرد، یا به ترتیبی، باید بتوانیم نتیجه بهتری را ثبت کنیم. در این خصوص اغلب همین کافی است.
معرفی فیلم های آموزش هوش مصنوعی
برای یادگیری مباحث هوش مصنوعی از جمله شبکههای عصبی، یادگیری عمیق، الگوریتم ژنتیک و سایر الگوریتمهای بهینهسازی هوشمند میتوان از مجموعه دورههای آموزش هوش مصنوعی فرادرس استفاده کرد. این مجموعه جامع و کاربردی شامل تعداد زیادی از دورههای آموزشی مختلف پیرامون بسیاری از مباحث هوش مصنوعی میشود. در توصویر فوق تنها برخی از دورههای این مجموعه آموزشی به عنوان نمونه نمایش داده شده است.
- برای دسترسی به همه فیلم های آموزش هوش مصنوعی فرادرس + اینجا کلیک کنید.
جمعبندی
در این مقاله پاسخ به چند پرسش کلیدی پیرامون شبکه های عصبی و یادگیری عمیق ارائه شد. ابتدا در پاسخ به این سوال که چرا در شبکههای عصبی برای کاهش معیار خطا از الگوریتم های مبتنی بر گرادیان کاهشی استفاده میشود، شرح داده شد که با توجه به محدب بودن (یا شبهمحدب بودن) توابع خطا در مدلهای یادگیری ماشین (که ناشی از ماهیت این مدلها و البته انتخاب آگاهانه خود ما است)، استفاده از روشهای بهینهسازی مثل گرادیان نزولی به مراتب مقرونبهصرفهتر است.
در خصوص پیدا کردن بهترین پارامترهای ممکن هم توضیح داده شد که اصلاً نیازی نیست که بهترین پیدا شود و همین که نیاز ما برطرف شود کافی خواهد بود. همچنین به پرسشهای دیگری نیز در خصوص تنظیم پارامترها در لایههای شبکه عصبی و همچنین محدب بودن یا شبه محدب بودن تابع خطا پاسخ داده شد.









سلام.
این مطلب مفید بود.
لطفا برای این مقاله و همچنین مطالب بیشتر در این زمینه، منبع هم ذکر کنید.
با تشکر.
با سلام و احترام؛
صمیمانه از همراهی شما با مجله فرادرس و ارائه بازخورد سپاسگزاریم.
در طول این مقاله و همچنین در انتهای آن منابع مرتبط بسیاری معرفی شده است. بهطور کلی اما این نوشته و پرسشهای مطرح شده در آن روی موضوع بهینهسازی هوشمند و محاسبات تکاملی تمرکز دارد. کاربردیترین منبع برای این دوره در ادامه آمده است که میتوانید از آن استفاده کنید:
همچنین برای یادگیری شبکه عصبی و Deep Learning نیز میتوانید منابع زیر را به کار ببرید:
بهطور کلی نیز میتوان از ۲ مجموعه آموزشهای زیر استفاده کرد:
برای شما آرزوی سلامتی و موفقیت داریم.