



وزن مشاهدات در SPSS | راهنمای کاربردی
در محاسبات و روشهای بدست آوردن شاخصهای آماری، ممکن است برای هر مشاهده میزان اهمیت بیشتر یا کمتری نسبت به دیگر مشاهدات در نظر بگیریم. یک مثال ساده در این مورد نحوه محاسبه میانگین وزنی برای بدست آوردن معدل ترم دانشگاه است. واضح است که درسهایی که اهمیت بیشتری دارند، با ضرایب بزرگتر و دروسی که ساعات کمتری در هفته به خود اختصاص دادهاند، با ضرایب کوچکتر در محاسبه معدل نقش ایفا میکنند. ضریب هر درس ممکن است یک عدد صحیح یا حتی اعشاری (غیرصحیح) باشد. به یاد داشته باشید که وزن دهی به متغیرها با وزن دهی به مشاهدات متفاوت است. معمولا وزن دهی به متغیرها برای ایجاد ترکیب خطی از آنها صورت میپذیرد و میزان اهمیت هر متغیر در ترکیب خطی را مشخص میکند. در این ترکیب از متغیرها، هدف ایجاد مدلی است که به شکل مدل ضربی یا جمعی نوشته شود. در حالیکه منظور از وزندهی مشاهدات، ایجاد اهمیت برای هر یک از مشاهدات در انجام تحلیل آماری است. برای مدل وزن دهی متغیرها میتوان به مدل عاملی یا تحلیل مولفههای اصلی اشاره کرد که وزنها توسط تحلیل محاسبه میشوند و برای وزن دهی مشاهدات نیز باید به مسئله رگرسیون با «عامل تورم واریانس» (Variance Inflation Factor) اشاره کرد که برای حل این مشکل با وزندهی به مشاهدات، واریانس را در مدل ثابت نگه میداریم. در نرمافزارهای آماری، اغلب برای تعیین وزن مشاهدات، از یک متغیر جداگانه استفاده میکنند. در این متن میخواهیم با نحوه ایجاد وزن مشاهدات در SPSS آشنا شده و شیوه بهرهبرداری از آن را مرور کنیم.


به منظور آشنایی بیشتر با نحوه کار در محیط SPSS بهتر است ابتدا نوشتارهای دیگر مجله فرادرس مانند پنجره ویرایشگر داده (Data Editor) در SPSS — راهنمای کاربردی و پنجره خروجی SPSS یا Output — راهنمای کاربردی را مطالعه کنید. همچنین خواندن نوشتارهای آمار توصیفی در SPSS — راهنمای کاربردی و تفکیک فایل داده در SPSS — به زبان ساده نیز خالی از لطف نیست.
وزن مشاهدات در SPSS
همانطور که گفته شد، وزندهی به مشاهدات به منظور تعیین اهمیت هر یک از آنها در محاسبه شاخصهای آماری است.
در این بین به نکات زیر در مورد وزن مشاهدات در SPSS توجه داشته باشید.
- مقادیر وزن برای مشاهدات به صورت یک متغیر جداگانه و به شکل متناظر با هر مشاهده ثبت میشود. به این ترتیب مقدار و وزن هر مشاهده به صورت یک زوج مرتب مشخص میشوند.
- معمولا مقدار وزن برای هر مشاهده به صورت یک عدد مثبت (صحیح یا اعشاری) تعیین شده و وزنهای منفی، صفر یا حتی با «مقادیر گمشده» (Missing Value) در تحلیلهای آماری توسط SPSS نادیده گرفته میشود.
- وزنهای کسری یا اعشاری در بعضی از شیوههای محاسباتی در SPSS مانند «جدول فراوانی» (Frequency Table)، «جدول توافقی» (Crosstabs) و جدولهای سفارشی (Custom Table) معتبر بوده و قابل استفاده و یا قابل تبدیل به مقادیر صحیح هستند.
البته در بعضی از تکنیکهای آماری، وزن مشاهدات باید یک عدد صحیح باشد. در این صورت اگر مقدار متغیر وزن، شامل مقادیر کسری یا اعشاری باشد، معمولا در آن تکنیک آماری، روشی برای تغییر آن به عدد صحیح معرفی شده است. این موضوع در ادامه متن، بخصوص در جدول توافقی، مورد بررسی قرار گرفته است.
تعیین متغیر وزن مشاهدات در SPSS
فرض کنید متغیرهای معرفی شده در یک کاربرگ به مانند تصویر ۱ باشد. متغیر courses، اسامی درسها را مشخص کرده است. واضح است که متغیر grade، نمره دانشجو و unit نیز تعداد واحدهای درسهایش است.

دادههای ثبت شده برای این متغیرها نیز مطابق با تصویر ۲، ثبت شده است. فرض کنید میخواهیم میانگین یا در حقیقت معدل این دانشجو را محاسبه کنیم.

قبل از هر کاری باید وزن هر یک از درسها را در محاسبه شاخصهای آماری مشخص کنیم.
روند تعیین وزن مشاهدات در SPSS به صورت زیر است:
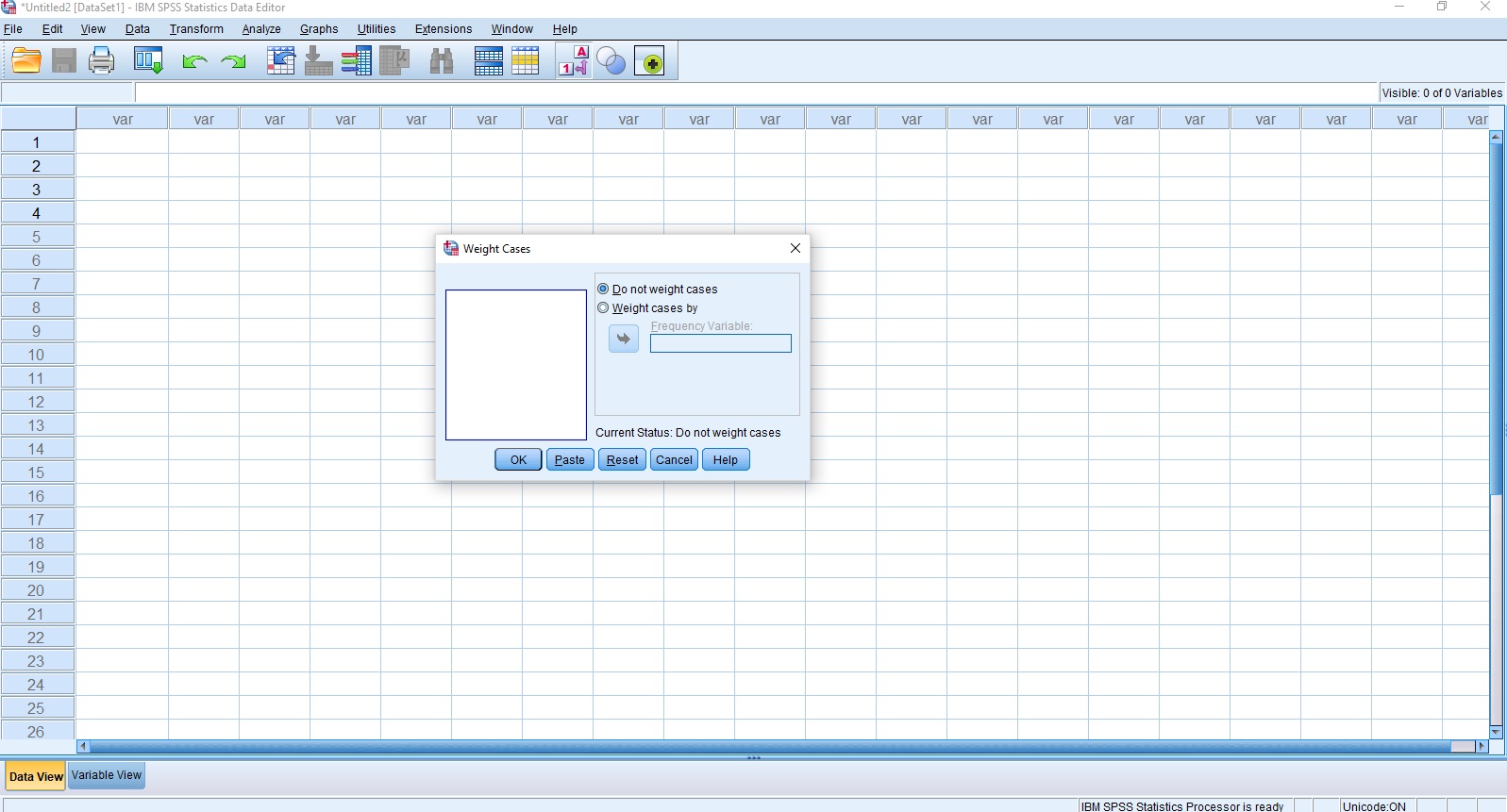
- از فهرست Data گزینه Weight Cases را انتخاب کنید.
- در پنجره ظاهر شده، قسمت Weight cases by را فعال کنید.
- متغیر مربوط به وزن مشاهدات در SPSS را به کادر Frequency Variable منتقل کنید.
- دکمه OK را به منظور اعمال این تغییرات کلیک کنید.
با انجام این کار در پنجره «ویرایشگر داده» (Data Editor)، در قسمت نوار وضعیت، عبارت Weight On را مشاهده خواهید کرد. مشخص است که در این پنجره وزن به عنوان فراوانی (frequency) در نظر گرفته شده.

همانطور که در تصویر ۳ مشاهده میکنید، فقط متغیرهای عددی برای وزندهی مورد استفاده قرار میگیرند و متغیر Courses که به صورت متنی (String) معرفی شده در لیست متغیرهای مورد استفاده دیده نمیشود.
نکته: زمانی که یک متغیر را به عنوان وزن مشاهدات معرفی میکنید، همیشه در تحلیلها به کار گرفته میشود، مگر آنکه متغیر دیگری را به عنوان وزن در نظر گرفته یا کلا وزندار کردن مشاهدات را با انتخاب گزینه Do not weight cases در پنجره Weight Cases، لغو کنید.

استفاده از جدول فراوانی (Frequency Table) و محاسبه شاخصهای آماری (Statistics) میتواند یک راهکار برای بدست آوردن معدل باشد. از فهرست Analysis و گزینه Descriptive Frequency، به دستور Frequencies دسترسی خواهیم داشت.
پنجره گفتگوی ظاهر شده را مطابق با تصویر ۴، تنظیم میکنیم، یعنی گزینه (Display Frequency Tables) را غیر فعال کرده و برای محاسبه میانگین (میانگین وزنی - Weighted Mean)، دکمه Statistics را فشار میدهیم.
در پنجره Frequencies:Statistics، گزینه Mean را کلیک کرده و با فشردن دکمه Continue به پنجره اول باز میگردیم و فرمان OK را اجرا میکنیم.

خروجی این دستور، نمایش میانگین وزنی براساس متغیر unit برای نمرات grade است.

نکته: توجه داشته باشید که میانگین عادی (بدون استفاده از وزندهی) برای این مجموعه داده براساس متغیر grade برابر با 18.6250 خواهد بود. در حالیکه با وزندار کردن مشاهدات، میانگین وزنی برای نمره دانشجو محاسبه شد.
وزن صحیح برای مشاهدات
همانطور که در قسمت قبل مشاهده کردید، اغلب وزن مشاهدات در SPSS شامل مقادیر صحیح است. به عنوان مثال اگر بخواهیم یک جدول فراوانی را در SPSS به منظور اجرای تحلیلهای دیگر وارد کنیم، ستون فراوانی (که شامل تعداد تکرارهای یک مشاهده است) را به عنوان متغیر وزن برای مشاهدات در SPSS مشخص میکردیم. جدول فراوانی زیر را در نظر بگیرید.
جدول ۱: فراوانی تعداد شرکتهای بورس براساس سرمایه برحسب هزار میلیون تومان
| کد دسته یا طبقه | کران مقادیر | فراوانی |
| ۱ | 0-100 | 10 |
| 2 | 100-250 | 15 |
| 3 | 250-500 | 8 |
| 4 | 500+ | 2 |
این اطلاعات را به مانند تصویر ۷ در محیط SPSS و در پنجره ویرایشگر داده، ثبت کردهایم.

واضح است هر گونه تحلیل برای این مجموعه داده باید با در نظر گرفتن متغیر فراوانی (freq) به عنوان وزن مشاهدات در SPSS باشد.
وزن اعشاری برای مشاهدات
دوباره به مثال مربوط به معدل ترم درسهای یک دانشجو باز میگردیم. این امکان وجود دارد که در بعضی از درسها بنا به ضرورت، تعداد واحدهای در نظر گرفته شده برای آن، عدد صحیح نباشد. برای مثال در نظر بگیرید که تعداد واحدهای درس ورزش، برابر با ۰٫۵ است.
خوشبختانه در محاسبه میانگین وزنی (Weighted Mean) این امر مشکلی ایجاد نمیکند و میتوانیم به همان شیوه قبل، معدل دانشجو را محاسبه کنیم. ولی زمانی که از جدول توافقی (Crosstabs) استفاده میکنید، وزنها باید عدد صحیح بوده تا نمایانگر تعداد مشاهدات در هر خانه از جدول توافقی باشند.
وزن اعشاری در جدول متقاطع
تعداد مشاهدات در iهر یک از سلولها جدول توافقی معمولاً مقادیر عدد صحیح هستند، زیرا این مقادیر، تعداد موارد مربوط به هر سلول را نشان داده یا مشخص میکنند. اما اگر مجموعه داده با یک متغیر وزندهی با مقادیر کسری یا اعشاری (مثلاً 1.25) وزندار شده باشد، شمارش در خانههای جدول توافقی نیز میتواند مقادیر کسری باشد.
فرض کنید بخواهید یک جدول متقاطع در SPSS ایجاد کنید. ولی از آنجایی که مشاهدات دارای یک متغیر برای در نظر گرفتن وزن مشاهدات در SPSS هستند، باید مطمئن شوید که مقادیر این وزنها، صحیح هستند. به این منظور هنگامی که با طی کردن مسیر Analyze- Descriptive Statistics گزینه Crosstabs را انتخاب کردید، میتوانید از دکمه Cells برای تعیین نحوه تغییر مقادیر وزن مشاهدات استفاده کنید.
همانطور که در تصویر ۸، میبینید، SPSS، پنج شیوه مختلف را برای تغییر مقدار وزنها پیشنهاد و به کار میگیرد.

هر یک از این گزینهها (به جز No adjustments)، باعث تغییر در وزن یا تعداد مشاهدات در هر یک از خانههای جدول توافقی خواهد شد. به یاد داشته باشید که تعداد مشاهدات در هر خانه از جدول توافقی، تابعی از وزن مشاهدات در مجموعه داده است. همانطور که میبینید بعضی از گزینهها، به گرد کردن (Round) تعداد مشاهدات در هر خانه از جدول اشاره دارند و در بعضی دیگر از برش دادن مقدار وزن مشاهدات در خانههای جدول توافقی استفاده میشود.
جدول ۲: شیوههای تبدیل وزن در جدول توافقی
| گزینه | عملکرد |
| Round cell Counts | گرد کردن تعداد مشاهدات در هر یک از خانههای جدول توافقی |
| Round case weights | گرد کردن وزن مشاهدات در جدول توافقی |
| Truncate cell counts | قطع کردن تعداد مشاهدات در هر یک از خانههای جدول توافقی |
| Truncate case weights | قطع کردن وزن مشاهدات در جدول توافقی |
| No adjustments | بدون تغییر در وزن یا تعداد مشاهدات |
نکته: توجه داشته باشید که تفاوت بین گرد کردن (Round) و برش (Truncate) در این است که گرد کردن باعث میشود که عدد به نزدیکترین عدد صحیح تبدیل شود، در حالیکه برش دادن، مقدار اعشاری را به نزدیکترین عدد صحیح کوچکتر از آن تبدیل میکند. برای مثال برش عدد ۱٫۷ به صورت ۱ بوده در حالیکه گردن شده آن برابر با ۲ خواهد بود.
همیشه در خاطر خود حفظ کنید که انتخاب گزینههای این قسمت فقط در صورتی در جدول توافقی موثر است که تعداد یا وزنهای مشاهدات اعشاری باشند در غیر این صورت، انتخاب این گزینهها، تغییری در نتیجه تحلیل اجرا شده در جدول توافقی ایجاد نخواهد کرد.
با این حال، هنگامی که از آزمون دقیق (Exact Test) در تحلیل جدول توافقی استفاده شود، بطور خودکار وزن تجمعی مشاهدات در این آزمون برحسب انتخاب گزینه برش یا گرد کردن، تبدیل به عدد صحیح شده و سپس در تحلیل و آزمون دقیق در جدول توافقی به کار گرفته میشوند. به منظور آشنایی بیشتر با آزمون دقیق بهتر است متن جدول توافقی و کاربردهای آن در SPSS — از صفر تا صد را مطالعه کنید. به این ترتیب میتوانید با ثبت مقادیر وزنها، در جدول توافقی از تکنیک برش یا گرد کردن وزن مشاهدات در تحلیلهای کیفی استفاده کنید.
خلاصه و جمعبندی
در این نوشتار با توجه به اهمیت در نظر گرفتن یک متغیر به عنوان وزن مشاهدات در SPSS به این مقوله پرداختیم. مشخص است که متغیر وزندهی، ممکن است شامل مقادیر منفی، صفر، مثبت یا اعشاری باشد. بنابر نوع تحلیل برای مشاهدات وزندار، ممکن است هر یک از این انواع مقادیر وزنها، نادیده گرفته شده یا به یک عدد صحیح مثبت تغییر یابند. از آنجایی که فقط در زمان اجرای هر تحلیل در SPSS، فقط از یک متغیر وزندهی میتوان استفاده کرد، توجه داشته باشید که هر زمان احتیاج به تغییر متغیر وزنی دارید، قبل از اجرای تحلیل آن را مشخص و به SPSS معرفی کنید. همچنین به یاد داشته باشید که هرگز از متغیری که برای وزندهی استفاده کردید در تحلیلها استفاده نکنید زیرا این کار باعث اشکال در محاسبات شده و نتایج را نامعتبر میکند.










