



معیار واگرایی کولبک لیبلر (Kullback Leibler)– پیاده سازی در پایتون
در تئوری آمار-ریاضی، معیار «واگرایی کولبک لیبلر» (Kullback-Leibler Divergence) روشی برای مشخص کردن میزان تفاوت بین دو توزیع احتمالی است. از جمله کاربردهای این معیار میتوان به سنجش تصادفی بودن در سری زمانی، بینظمی نسبی (آنتروپی شانون) در سیستمهای اطلاعاتی اشاره کرد.


به عنوان مقدمه در بحث واگرایی کولبک-لیبلر، بهتر است مطالب متغیر تصادفی، تابع احتمال و تابع توزیع احتمال و آزمایش تصادفی، پیشامد و تابع احتمال را بخوانید. همچنین خواندن نوشتار یادگیری ماشین به زبان قضیه بیز، بی نظمی شانون و فلسفه نیز خالی از لطف نیست.
معیار واگرایی کولبک لیبلر (Kullback-Leibler Divergence)
قبل از هر چیز باید با مفاهیم اولیهای که در معیار واگرایی کولبک-لیبلر به کار میرود، آشنا شویم. تابع توزیع احتمال و متغیر تصادفی از مهمترین واژه یا مفاهیم هستند که در این نوشتار با آنها زیاد برخورد خواهیم داشت. همانطور که در مقدمه گفته شد، در دیگر نوشتارهای فرادرس این مفاهیم و اصطلاحات معرفی و در موردشان بحث شده است.
به منظور آغاز بررسی در زمینه معیار واگرایی کولبک-لیبلر به یک مثال میپردازیم. فرض کنید که شما فضانورد هستید و به فضای خارج از منظومه شمسی سفر کردهاید. در این ماموریت به کرمهای فضایی برخورد کردهاید و میخواهید این خبر هیجانانگیز را به زمین مخابره کنید. متاسفانه هزینه ارسال خبر به زمین زیاد است و شما باید پیام خود را با کمترین حجم ارسال کنید بطوری که از میزان اطلاعاتی مورد نظرتان کاسته نشود.
یک راه برای ارسال چنین اطلاعاتی رسم یک جدول یا نمودار فراوانی است که نشان میدهد با توجه به تعداد دندانها چند کرم مشاهده شده است. به این ترتیب یک توزیع احتمال برای کرمها و دندانهایشان محاسبه یا ترسیم شده است.
تابع توزیع احتمال، اطلاعات مناسبی و به صرفهتری در باره همه کرمها نسبت به ارسال اطلاعات هر یک از کرمها مخابره میکند. بعضی از این توزیعهای احتمالی دارای اسامی خاصی هستند مانند توزیع نرمال، توزیع دو جملهای و توزیع یکنواخت. برای مثال اگر بخواهیم دادههای با توزیع یکنواخت را بشناسیم کافی است فقط دو نوع اطلاعات را ارسال کنیم، مقدار پارامتر توزیع یکنواخت و تعداد کرمها.
ولی سوالی که مطرح میشود این است که از کجا متوجه شویم دادهها چه توزیعی دارند. پاسخ به این سوال توسط معیار واگرایی «کولبک-لیبلر» که به اختصار با KL نشان داده میشود میسر است. به این ترتیب میتوان میزان اختلاف بین توزیع واقعی و توزیع حدسی مورد بررسی قرار گیرد. بنابراین میتوان معیار واگرایی KL را روشی برای اندازهگیری مطابقت بین دو توزیع در نظر گرفت.
فرض کنید ۱۰۰ کرم فضایی مشاهده شده است. جدول فراوانی برحسب تعداد دندانها به صورت زیر در آمده است.
| تعداد دندان | فراوانی | درصد فراوانی (احتمال) |
| 0 | 2 | 0.02 |
| 1 | 3 | 0.03 |
| 2 | 5 | 0.05 |
| 3 | 14 | 0.14 |
| 4 | 16 | 0.16 |
| 5 | 15 | 0.15 |
| 6 | 12 | 0.12 |
| 7 | 8 | 0.08 |
| 8 | 10 | 0.1 |
| 9 | 8 | 0.08 |
| 10 | 7 | 0.07 |
نکته: جمع فراوانیها باید برابر با ۱۰۰ یعنی تعداد کرمها باشد. از طرفی میتوان نتیجه گرفت که مجموع درصد فراوانی نیز برابر با ۱ خواهد بود.
این جدول را میتوان در نمودار زیر که به نمودار فراوانی یا هیستوگرام معروف است خلاصه کرد.

کد پایتون مربوط به تولید چنین نموداری در ادامه قابل مشاهده است. البته توجه داشته باشید که ابتدا باید کتابخانههای زیر را فراخوانی کنید.
سپس کد زیر را اجرا کنید.
مدلبندی و انتخاب توزیع مناسب
اگر ساختار و مدل احتمالی دادههای کرمهای فضایی را مشخص کنیم، به راحتی میتوانیم اطلاعات مناسب را به زمین مخابره کنیم. بنابراین احتیاج داریم که مطابقت توزیع احتمالی دادهها (جدول فراوانی) را با توزیعهایی آماری که میشناسیم اندازهگیری کنیم.

از آنجایی که مقدارهای متغیر گسسته (شمارشی) هستند، از توزیعهای گسسته به عنوان توزیعهای آزمایشی بهره میبریم. کار را ابتدا با توزیع یکنواخت (Uniform) گسسته پی میگیریم.
توزیع یکنواخت گسسته تنها یک پارامتر دارد که آن هم تعداد پیشامدها است. به این ترتیب میتوانیم رابطه زیر را بنویسیم.
مشخص است که پیشامدها مطابق با نمودار قبلی یا جدول فراوانی، دارای ۱۱ (از ۰ تا ۱۰) حالت مختلف است. در تصویر زیر نمودار مقایسه مطابقت توزیع یکنواخت با توزیع دادههای مربوط به دندانهای کرمهای فضایی دیده میشود.

این نمودار توسط قطعه کد زیر تولید شده است.
به نظر میرسد که شباهت زیادی بین توزیع واقعی دادههای و توزیع یکنواخت (Uniform) وجود ندارد. در این صورت بهتر است از توزیع دیگری در این زمینه مثلا «توزیع دوجملهای» (Binomial) استفاده کنیم.
توزیع دوجملهای نیز یکی از توزیعهای آماری است که مقدارهای گسسته (شمارشی) را شامل میشود بنابراین شرط اولیه که مطابقت تکیهگاه (مجموعه مقدارها) توزیع با مقدارهای متغیر مشاهده شده است را دارد. تابع احتمال متغیر تصادفی با توزیع دوجملهای به صورت زیر نوشته میشود.
مشخص است که در اینجا تعداد موفقیتها در n بار تکرار آزمایش برنولی است. میدانیم که میانگین (امیدریاضی) و واریانس متغیر تصادفی دوجملهای به ترتیب برابر با و است.
با توجه به مفهوم امیدریاضی برای توزیع دوجملهای و همچنین میانگین وزنی برای دادهها، محاسبات را انجام داده و نتایج را مقایسه میکنیم. مطابق با جدول فراوانی میانگین وزنی به صورت زیر محاسبه میشود.
به این ترتیب میتوانیم مقدار احتمال موفقیت () را محاسبه کنیم.
شاید به نظر برسد که مقدار باید برابر با ۱۱ (تعداد پشامدها) یا ۱۰۰ (تعداد کرمها) باشد. دلیل اینکه مقدار انتخاب شده است را در ادامه خواهید دید.
میدانیم که توزیع دوجملهای، از جمع n متغیر تصادفی برنولی که هر کدام مقدار 0 و 1 میگیرند، ساخته میشود. بنابراین اگر برای مثال یک سکه را ۱۰ بار پرتاب کنیم، احتمال مشاهده شیر (موفقیت) از طریق توزیع دوجملهای میسر است. مشخص است که تعداد موفقیتها در این بین شامل مقدارهای 0 تا ۱۰ است. بنابراین، همین فرضیات را برای تعداد دندانهای کرمها نیز خواهیم داشت.
به این ترتیب در مثال ما، تعداد دندانهای هر کرم میتواند از ۰ تا ۱۰ دندان تغییر کند و میتوانیم مشاهده دندان (وجود یا ناموجود) را به صورت ۰ و ۱ مشخص کنیم. از آنجایی که حداکثر تعداد دندانها برابر با ۱۰ است، تعداد موفقیتها (تعداد ۱ها) حداکثر برابر با ۱۰ خواهد بود. در نتیجه باید مقدار در نظر گرفته شود. حال به محاسبه احتمال مطابق توزیع دوجملهای با پارامتر و خواهیم پرداخت. در این حالت میگوییم تعداد دندانهای کرمهای فضایی دارای توزیع دوجملهای با پارامترهای و است و این جمله را با نماد ریاضی به صورت نشان میدهیم.
...
احتمالات حاصل را مطابق با نمودار زیر با احتمالات مربوط به دادههای واقعی (ستون درصد فراوانی) در جدول فراوانی مقایسه میکنیم. کدی که در ادامه قابل مشاهده است برای ترسیم چنین نموداری به کار رفته است.
مقدار احتمال موفقیت در این حالت در ادامه دیده میشود.

اینطور که به نظر میرسد، بین احتمالات واقعی و تابع احتمال دوجملهای، مطابقت خوبی برقرار است. به نظر میرسد مشخص کردن توزیع احتمالی دندانهای کرمهای فضایی با موفقیت همراه بوده است. بنابراین کافی است که توزیع دوجملهای با پارامترهای آن را برای زمین مخابره کنیم تا اطلاعات کافی در مورد دندانهای کرمهای فضایی را به ایستگاه زمینی داده باشیم.
البته شاید بد نباشد که مقایسه سه تایی (توزیع یکنواخت، دوجملهای و توزیع واقعی) توزیعها را نیز رسم کنیم و در بایگانی فضاپیما نگهداری کنیم.

کدهای زیر برای ترسیم چنین نموداری در پایتون استفاده شده است.
معیار واگرایی کولبک-لبیلر (KL) برای تشخیص توزیع مناسب
مطابق با نمودارهای ترسیم شده شاید بتوان نتیجه گرفت که توزیع دوجملهای مناسبتر از توزیع یکنواخت است. ولی در اینجا قصد داریم به کمک یک شاخص میزان این مطابقت را اندازهگیری کنیم.
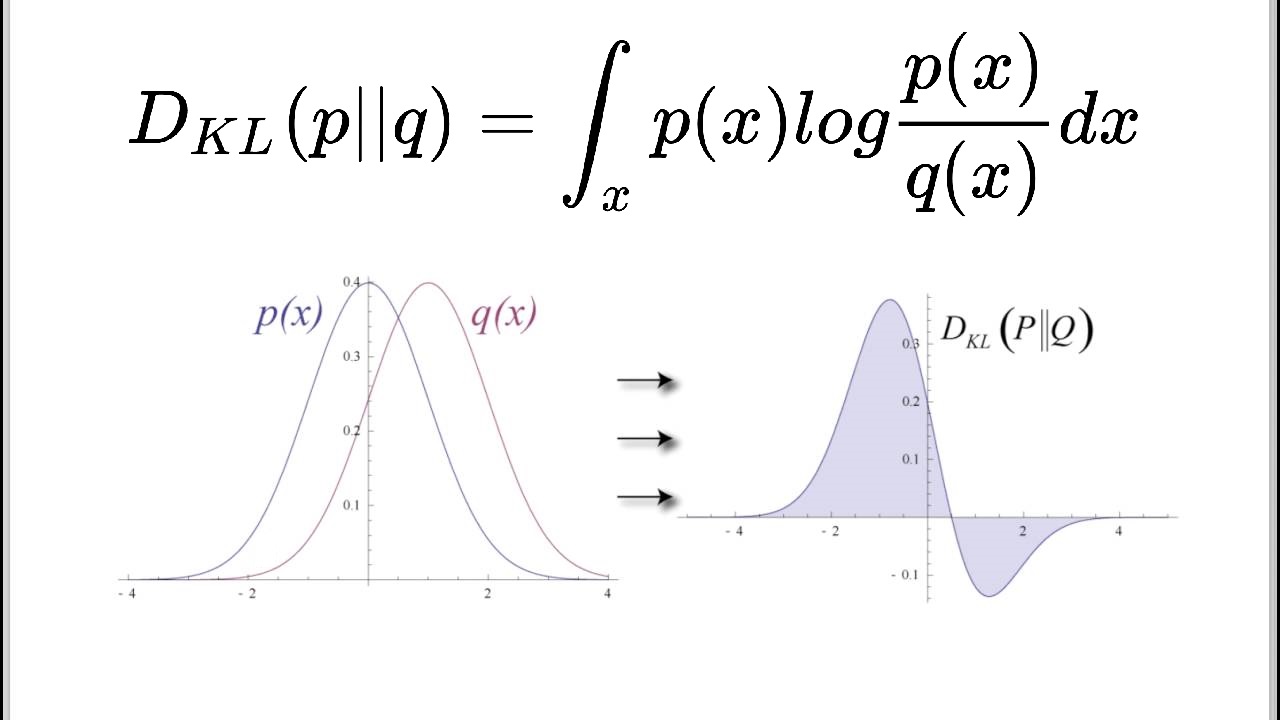
معیار واگرایی کولبک-لیبلر برای مقایسه توزیعهای گسسته با به صورت زیر تعریف میشود.
در این تعریف فرض شده است که توزیع واقعی و توزیع تقریبی برای دادهها است. این شاخص نشان میدهد که توزیع تقریبی چقدر نسبت به توزیع واقعی دور است.
اگر توزیعهای از نوع پیوسته باشند تعریف معیار KL برحسب انتگرال خواهد بود. به رابطه زیر توجه کنید.
همانطور که دیده میشود، یکی از اجزای محاسباتی برای شاخص KL، لگاریتم نسبت دو توزیع است. هر چه مقدار بزرگتر از باشد به معنی محتملتر بودن مقدار در توزیع است. پس کسر کوچکتر از ۱ میشود. بنابراین لگاریتم این کسر منفی خواهد شد. از طرفی اگر کوچکتر از باشد، نسبت این دو بزرگتر از ۱ شده و لگاریتم آن نیز مثبت است. در صورتی که این نسبت برابر با ۱ باشد (یعنی دو توزیع یکسان باشند)، مقدار لگاریتم، صفر خواهد شد.
به نظر میرسد شاخص KL، امید ریاضی (مقدار مورد انتظار) برحسب توزیع لگاریتم نسبت دو توزیع باشد. بنابراین ناحیه مطابقت دو توزیع زمانی که بزرگتر است اهمیت (وزن) بیشتری در محاسبه KL نسبت به ناحیهای دارد که کوچکتر است. به این ترتیب در نواحی که دو توزیع دارای تکیهگاه یکسانی نیستند، اهمیت یا مقدار احتمالات کاهش مییابد.
برای این شاخص میتوان خصوصیات زیر را نتیجه گرفت.
- شاخص KL همیشه نامنفی است.
- شاخص KL متقارن نیست. به این معنی که
- شاخص KL برای مقایسه هر توزیع با خودش برابر با صفر است. در نتیجه بیشترین مطابقت توسط این شاخص با صفر مشخص میشود.
- شاخص KL برای متغیرهای تصادفی مستقل به صورت جمع نوشته میشود. این امر درست به مانند بینظمی شانون است. در نتیجه اگر باشد، آنگاه:
حال به بررسی مثال کرمهای فضایی و محاسبه شاخص KL برای هر دو توزیع یکنواخت و دوجملهای خواهیم پرداخت. با توجه به رابطه KL برای متغیرهای تصادفی گسسته، شاخص KL برای توزیع یکنواخت به صورت زیر محاسبه میشود.
همین محاسبات را نیز برای مطابقت توزیع دوجملهای با توزیع واقعی دادهها انجام میٔهیم.
برای محاسبه شاخص KL از قطعه کد زیر نیز میتوانید استفاده کنید.
نتیجه اجرای این برنامه به صورت زیر است.
هر چه مقدار شاخص KL کوچکتر باشد، میزان مطابقت بین توزیع با بیشتر است. با کمال تعجب میبینیم که مقدار شاخص KL برای توزیع یکنواخت کوچکتر از توزیع دوجملهای است. بنابراین توزیع یکنواخت بهتر میتوان دادههای مربوط به تعداد دندانهای کرمهای فضایی را بیان کند. این امر نشان میدهد که همیشه نمیتوان به شهود و نتایج حاصل از آن اعتماد کرد. یا حداقل شاخص KL نظر ما را در این امر تایید نمیکند.
بهتر است برای تشخیص اینکه مقدار احتمال موفقیت در توزیع دوجملهای چه تاثیری در شاخص KL دارد، از نموداری استفاده کنیم که به ازاء مقدارهای مختلف در توزیع دوجملهای، شاخص KL را مقایسه کند. کدهای مربوط به ترسیم چنین نموداری در ادامه قابل مشاهده است.
نتیجه اجرای این کد، نموداری است که تقریبا نشان میدهد، کمترین مقدار KL برای مقایسه توزیع واقعی و دوجملهای در همان مقدار احتمال 0.544 (که با نقطه قرمز رنگ مشخص شده) بدست میآید. بنابراین باز هم شاخص KL گواهی میدهد که توزیع یکنواخت میتواند اطلاعات بیشتری در مورد توزیع واقعی دادهها در اختیارمان قرار دهد.

اگر مطلب بالا برای شما مفید بوده است، آموزشهای زیر نیز به شما پیشنهاد میشوند:
- مجموعه آموزشهای آمار، احتمالات و دادهکاوی
- مجموعه آموزشهای یادگیری ماشین و بازشناسی الگو
- آموزش آمار و احتمال مهندسی
- آموزش یادگیری ماشین
- آموزش یادگیری ماشین (Machine Learning) با پایتون (Python)
- احتمال شرطی (Conditional Probability) — اصول و شیوه محاسبه
- قضیه بیز در احتمال شرطی و کاربردهای آن
- تابع درستنمایی (Likelihood Function) و کاربردهای آن — به زبان ساده
^^











سلام
ممنون از توضیحات
من با فاصله جنسون شانون کار میکنم میخواستم ببینم ممکن است که این فاصله در داده های واقعی منفی شود؟
بسیار عالی
خیلی ممنون بابت توضیح خوبتون
بسیار عالی بود، تمام مطالبی که از آقای دکتر ری بد مطالعه کردم خیلی شفاف و رسا توضیح داده شده است.
سپاس
بسیار عالی و مفید. تشکر