



تبدیل موجک – از صفر تا صد
تبدیل موجک (Wavelet Transform) یکی از تبدیلات مهم ریاضی است که در حوزههای مختلف علوم کاربرد دارد. ایده اصلی تبدیل موجک این است که بر ضعفها و محدودیتهای موجود در تبدیل فوریه غلبه کند. این تبدیل را بر خلاف تبدیل فوریه، میتوان در مورد سیگنالهای غیر ایستا و سیستمهای دینامیک نیز مورد استفاده قرار داد. در این مطلب قصد داریم تا به بررسی تبدیل موجک و کاربرد آن در پردازش سیگنال و یادگیری ماشین بپردازیم. ابتدا مفاهیم، تئوری و عملکرد تبدیل موجک پیوسته و گسسته و تمایز آن با تبدیل فوریه را بیان میکنیم و سپس مثالهایی کاربردی از اعمال تبدیل موجک روی دو دیتاست UCI-HAR و ECG و دستهبندی دادههای آنها با استفاده از الگوریتمهای یادگیری ماشین و یادگیری عمیق در محیط پایتون را مورد بررسی قرار میدهیم. در نهایت، کدهای پیادهسازی تبدیل موجک در محیط متلب بدون استفاده از توابع آماده را بیان میکنیم و آن را روی دیتاست ال نینو پیادهسازی میکنیم.



تبدیلات ریاضی کاربردهای فراوانی در پردازش و طبقهبندی دادههای مختلف مانند سیگنالها و سریهای زمانی (Time Series) دارند. به عنوان مثال، با استفاده از تبدیل فوریه (Fourier Transform) که در مطالب قبلی مجله فرادرس مورد بررسی قرار گرفته است، میتوان یک سیگنال را از حوزه زمان به حوزه فرکانس منتقل کرد. پیکهای ظاهر شده در نمودار طیف فرکانسی یک سیگنال پس از اعمال تبدیل فوریه، نشان دهنده فرکانسهایی است که در آن سیگنال غالب هستند. هر چقدر این پیکها بزرگتر و تیزتر باشند، آن فرکانس در سیگنال حضور بیشتر و موثرتری دارد. محل قرار گرفتن پیک (مقدار فرکانس) و ارتفاع آن (دامنه فرکانس) در یک نمودار طیف فرکانسی، میتوانند به عنوان ورودی برای الگوریتمهایی طبقهبندی مانند جنگل تصادفی (Random Forest) و یا ارتقای گرادیان (Gradient Boosting) مورد استفاده قرار گیرند.
این تکنیک ساده برای بسیاری از مسائل عملکرد فوقالعاده و دقت بسیار بالایی به همراه خواهد داشت. اما قاعده کلی که در مورد تبدیل فوریه وجود دارد این است که تبدیل فوریه تا زمانی که طیف فرکانسی یک سیگنال از لحاظ آماری ایستا (Stationary) باشد، به خوبی عمل خواهد کرد. ایستا بودن طیف فرکانسی به این معنی است که فرکانسهای ظاهر شده در یک سیگنال، وابسته به زمان نباشند. به عبارت دیگر، اگر یک سیگنال شامل فرکانس X هرتز باشد، این فرکانس باید به صورت برابر در تمام طول سیگنال وجود داشته باشد.
هرچه یک سیگنال بیشتر غیر ایستا یا دینامیک باشد، نتیجه بدتر خواهد بود. پردازش سیگنالهای غیر ایستا معمولا از دشواری بیشتری برخوردار است و برای آنالیز آنها باید از تکنیکها و پیش پردازشهای دیگری استفاده کنیم. بسیاری از سیگنالهای واقعی موجود در طبیعت دارای طبیعت غیر ایستا هستند. هنگامی که تلاش داریم سیگنالهای ECG، بازار بورس، دادههای تجهیزات و سنسورها و... را در پروژههای عملی مورد پردازش قرار دهیم، به احتمال زیاد با سیگنالهای غیر ایستا و سیستمهای دینامیک رو به رو خواهیم شد. یک راه حل بسیار عالی برای پردازش سیگنالهای غیر ایستا، استفاده از تبدیل موجک به جای تبدیل فوریه است.
با این که تبدیل موجک یک ابزار بسیار قدرتمند برای پردازش و طبقهبندی سیگنالها و سریهای زمانی دینامیک محسوب میشود، اما هنوز در علم داده به صوررت گسترده مورد استفاده قرار نمیگیرد و از محبوبیت بالایی برخوردار نیست. احتمالا دلیل این امر، نیاز به داشتن دانش اولیه درباره ریاضیات، تبدیل فوریه و پردازش سیگنال است، تا پس از آن، ریاضیات نهفته در تبدیل موجک به صورت کامل قابل درک باشد. البته بسیاری از مراجع و کتابها به صورت تئوری تبدیل موجک را مورد بررسی قرار دادهاند، در حالی که دانش عملی کافی درباره نحوه استفاده از آن به ندرت مورد بحث قرار گرفته است.
به همین دلیل، در این مطلب میخواهیم به بیان مباحث تئوری مرتبط با تبدیل موجک بپردازیم و با کاربردهای عملی تبدیل موجک آشنا شویم، اما به صورت عمیق ریاضیات آن را مورد بررسی قرار نمیدهیم. در هر گام از مطلب، کدهای پایتون را ارائه میدهیم، به صورتی که در پایان قادر باشید از تبدیل موجک در پروژههای خود استفاده کنید. در کدهایی که در ادامه نوشته میشود، از پکیج PyWavelets استفاده شده است، بنابراین توصیه میشود تا این پکیج را ابتدا با دستور «pip install pywavelets» نصب نمایید.
از تبدیل فوریه به تبدیل موجک
همان طور که میدانیم، تبدیل فوریه از طریق ضرب کردن سیگنال مورد پردازش در قطاری از سیگنالهای سینوسی با فرکانسهای مختلف عمل میکند. در واقع، از این راه میتوانیم تعیین کنیم که کدام فرکانسها در سیگنال مورد پردازش وجود دارند. اگر عملگر ضرب نقطهای بین سیگنال مورد نظر و یک سیگنال سینوسی با فرکانس مشخص، برابر با یک عدد با دامنه بزرگ شود، آنگاه میتوان نتیجه گرفت که همپوشانی زیادی بین این دو سیگنال وجود دارد و در نتیجه آن فرکانس مشخص در طیف فرکانسی سیگنال مورد نظر نیز مشاهده خواهد شد. قطعا دلیل این امر از آنجایی ناشی میشود که عملگر ضرب نقطهای معیاری برای اندازهگیری میزان همپوشانی و شباهت بین دو بردار یا دو سیگنال است.
نکتهای که در مورد تبدیل فوریه میتوان به آن اشاره کرد این است که در حوزه فرکانس دارای رزولوشن بالایی است، در حالی که در حوزه زمان از رزولوشن صفر برخوردار است. به عبارت دیگر، تبدیل فوریه این توانایی را دارد که به ما بگوید دقیقا چه فرکانسهایی در یک سیگنال وجود دارند، اما نمیتوان با استفاده از آن تعیین کرد که فرکانس مورد نظر در چه لحظهای از زمان در سیگنال اتفاق میافتد. این مفهوم را میتوان به سادگی با استفاده از قطعه کد زیر به نمایش در آورد:
خروجی این قطعه کد در تصویر زیر دیده میشود. در این تصویر سیگنالهای اصلی به همراه طیف فرکانسی هر کدام نشان داده شده است.

در تصاویر بالا، در ردیف اول سیگنال اصلی به همراه طیف فرکانسی آن دیده میشود که شامل چهار فرکانس در تمام زمانها است و در ردیف پایین میتوان دید که سیگنال دوم نیز چهار فرکانس مختلف اما در چهار زمان متفاوت دارد.
در این تصویر، اولین سیگنال از سمت چپ، بر اساس تصویر طیف فرکانسی خود، چهار فرکانس مختلف در ۶۰، ۳۰، ۴ و ۹۰ هرتز دارد. این فرکانسها در تمام زمانها وجود دارند. در سیگنال دوم نیز چهار فرکانس مشابه وجود دارد، اما تفاوتی که دارد این است که فرکانس اول فقط در ربع اول از سیگنال، فرکانس دوم در ربع دوم سیگنال، فرکانس سوم در ربع سوم و فرکانس چهام فقط در ربع آخر سیگنال وجود دارند.
نکته مهمی که در اینجا باید به آن توجه شود این است که هر دو نمودار طیف فرکانسی در تصویر بالا، دارای چهار پیک دقیقا یکسان در ۴ فرکانس ذکر شده هستند. بنابراین با استفاده از تبدیل فوریه نمیتوان به این واقعیت پی برد که فرکانس در سیگنال اصلی دقیقا در کجا اتفاق میافتد. دقیقا به همین دلیل است که در مثال بالا نیز تبدیل فوریه نتوانست به ما در تمایز و تشخیص دو سیگنال از یکدیگر کمک کند. توجه کنید که وقوع لبههای گذرا جانبی در طیف فرکانسی سیگنال دوم، به دلیل ناپیوستگی بین چهار فرکانس در سیگنال است.
برای غلبه بر این مشکل، روش تبدیل فوریه زمان کوتاه (Short-Time Fourier Transform) یا STFT مورد استفاده قرار میگیرد. در این روش، سیگنال اصلی به چندین بخش با طول یکسان تقسیم میشوند. این بخشها ممکن است با یکدیگر همپوشانی داشته باشند و یا فاقد همپوشانی باشند. با استفاده از پنجرههای لغزشی (Sliding Window)، سیگنال را قبل از اعمال تبدیل فوریه به چندین بخش تقسیم میکنیم. ایده اصلی در این روش بسیار ساده است. اگر سیگنال را مثلا به 10 قسمت تقسیم کرده باشیم و تبدیل فوریه در بخش دوم فرکانس خاصی را تشخیص دهد، بنابراین با قطعیت بالا میتوان گفت که این فرکانس در بازه بین و از سیگنال اصلی به وقوع میپیوندد.
اما عیب اصلی که در این روش وجود دارد این است که با یک محدودیت فیزیکی در تبدیل فوریه رو به رو خواهد شد که عدم قطعیت نام دارد. در این روش، هرچه اندازه پنجرهها را کوچکتر کنیم، قادر خواهیم بود به صورت دقیقتر تعیین کنیم که یک فرکانس در چه زمانی از سیگنال اصلی به وقوع پیوسته است، اما از طرف دیگر اطلاعات کمتری را راجع به مقدار فرکانس سیگنال اصلی به دست خواهیم آورد. به صورت مشابه، هر چه اندازه پنجرهها را بزرگتر انتخاب کنیم، اطلاعات بیشتری راجع به مقدار فرکانس و اطلاعات کمتری راجع به زمان وقوع فرکانس به دست خواهیم آورد.
روش بهتری که برای آنالیز یک سیگنال با طیف فرکانسی دینامیک وجود دارد، استفاده از تبدیل موجک است. تبدیل موجک هم در حوزه زمان و هم در حوزه فرکانس دارای رزولوشن بالایی است. این تبدیل نه تنها مقدار فرکانسهای موجود در سیگنال را مشخص میکند، بلکه تعیین میکند که آن فرکانسها در چه زمانی از سیگنال به وقوع میپیوندند. تبدیل موجک این توانایی را از طریق کار کردن در مقیاسهای (Scale) مختلف به دست میآورد. در تبدیل موجک، ابتدا سیگنال را با مقیاس یا پنجره بزرگ در نظر میگیریم و ویژگیهای بزرگ (Large Features) آن را آنالیز میکنیم. در گام بعد، با پنجرههای کوچک به سیگنال نگاه میکنیم و ویژگیهای کوچک سیگنال را به دست میآوریم. در تصویر زیر رزولوشن حوزه زمان و فرکانس در روش تبدیلهای مختلف به نمایش درآمده است.

در تصویر بالا، اندازه و جهت بلوکها نشاندهنده مقدار رزولوشن در آن تبدیل است، به عبارت دیگر بلوکها در هر تبدیل تعیین میکنند که در حوزه زمان و فرکانس میتوان ویژگیهای تا چه مقدار کوچک را با استفاده از آن تبدیل تشخیص داد. سیگنال اصلی که در حوزه زمان است، دارای رزولوشن بالا در حوزه زمان و رزولوشن صفر در حوزه فرکانس است. این ویژگی به این معنی است که میتوانیم ویژگیهای بسیار کوچکی را در حوزه زمان تشخیص دهیم، اما در حوزه فرکانس هیچ ویژگی قابل تمایز نیست.
اما تبدیل فوریه زمان کوتاه، دارای رزولوشن با اندازه متوسط در هر دو حوزه زمان و فرکانس است. رزولوشن تبدیل موجک به صورت زیر تغییر میکند:
- برای مقادیر فرکانسهای کوچک، رزولوشن بالا در حوزه فرکانس و رزولوشن پایین در حوزه زمان دارد.
- برای مقادیر فرکانسهای بالا، رزولوشن پایین در حوزه فرکانس و رزولوشن بالا در حوزه زمان دارد.
بنابراین در حالت کلی میتوان گفت تبدیل موجک به صورت مصالحهای عمل میکند. در مقیاسهایی که مشخصههای وابسته به زمان جذابتر هستند، تبدیل موجک دارای رزولوشن بالاتر در حوزه زمان و در مقیاسهایی که مشخصههای وابسته به فرکانس جذابتر هستند، دارای رزولوشن بالاتر در حوزه فرکانس است. این نوع مصالحه دقیقا همان هدفی است که در پردازش سیگنال مورد نظر است.
نحوه عملکرد تبدیل موجک
همان طور که اشاره کردیم، تبدیل فوریه برای آنالیز سیگنال از یک سری امواج سینوسی با فرکانسهای مختلف استفاده میکند. در این حالت، سیگنال به صورت ترکیبی خطی از سیگنالهای سینوسی نمایش داده میشود. اما تبدیل موجک از تعدادی توابع به نام موجک استفاده میکند که هر کدام مقیاس متفاوتی دارند. همان طور که میدانیم معنی واژه موجک، موج کوچک است و توابع موجک نیز دقیقا به همین صورت کوچک هستند.
در تصویر زیر تفاوت بین یک سیگنال سینوسی و یک موجک نشان داده شده است.

با دقت در تصویر بالا، کاملا مشخص است که سیگنال سینوسی در یک لحظه خاص از زمان واقع نشده است. این سیگنال از بینهایت شروع میشود و تا بینهایت ادامه مییابد، در حالی که یک موجک در لحظه خاصی از زمان واقع شده است. این ویژگی به تبدیل موجک اجازه میدهد تا علاوه بر اطلاعات فرکانسی، اطلاعات زمانی را نیز به دست آورد.
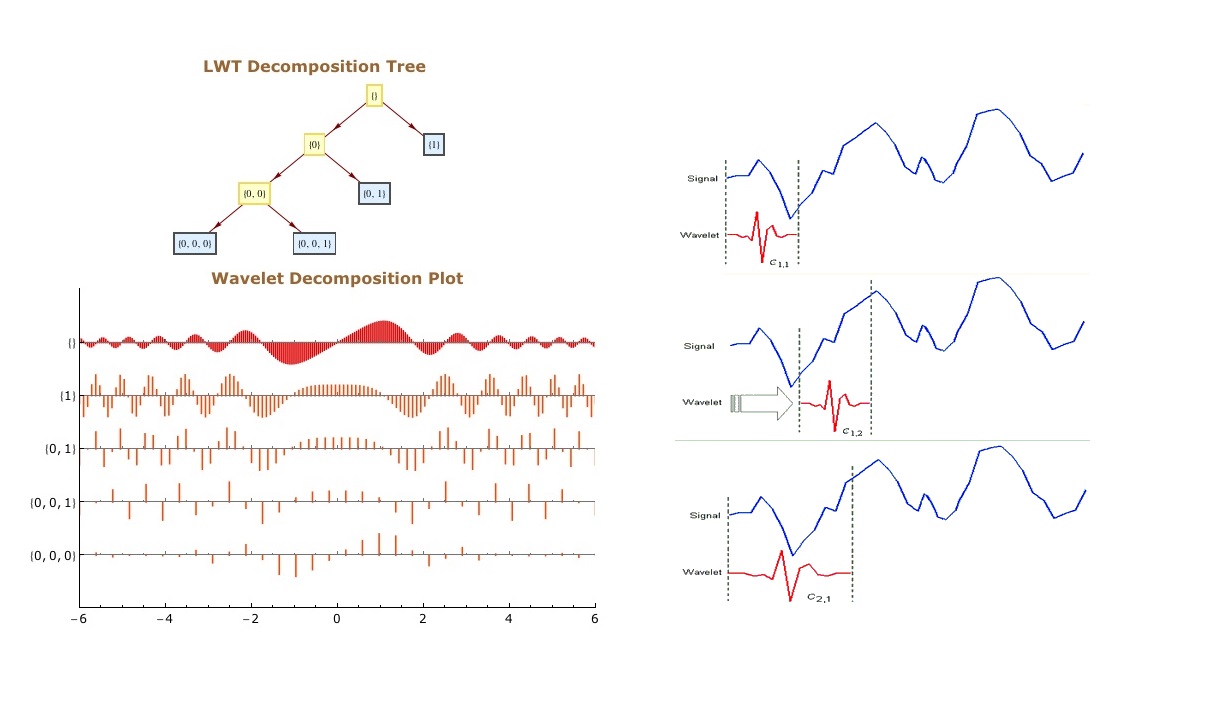
چون موجک در زمان واقع شده است، در نتیجه میتوان سیگنال اصلی را در لحظات مختلف از زمان در موجک ضرب کرد. در گام نخست، با نقاط ابتدایی سیگنال شروع میکنیم و به تدریج موجک را به سمت انتهای سیگنال حرکت میدهیم. این عمل را کانولوشن (Convolution) میگویند. بعد از این که کانولوشن را با سیگنال موجک اصلی (موجک مادر) انجام دادیم، میتوانیم آن را به نحوی مقیاسدهی کنیم که بزرگتر شود و دوباره فرایند را تکرار کنیم. این فرایند در تصویر متحرک زیر نشان داده شده است.
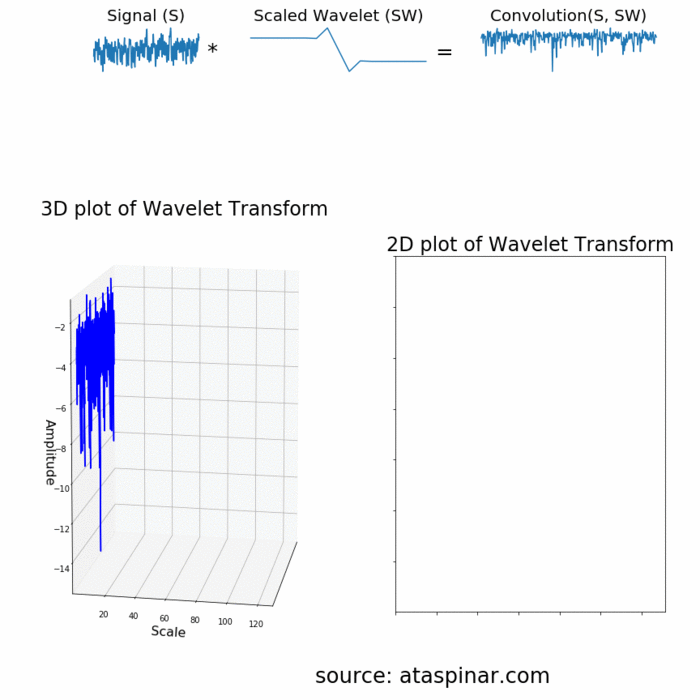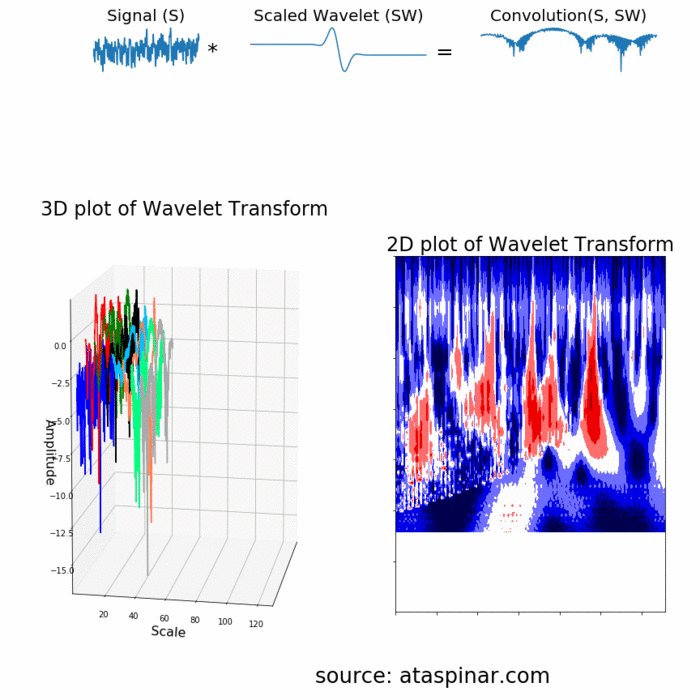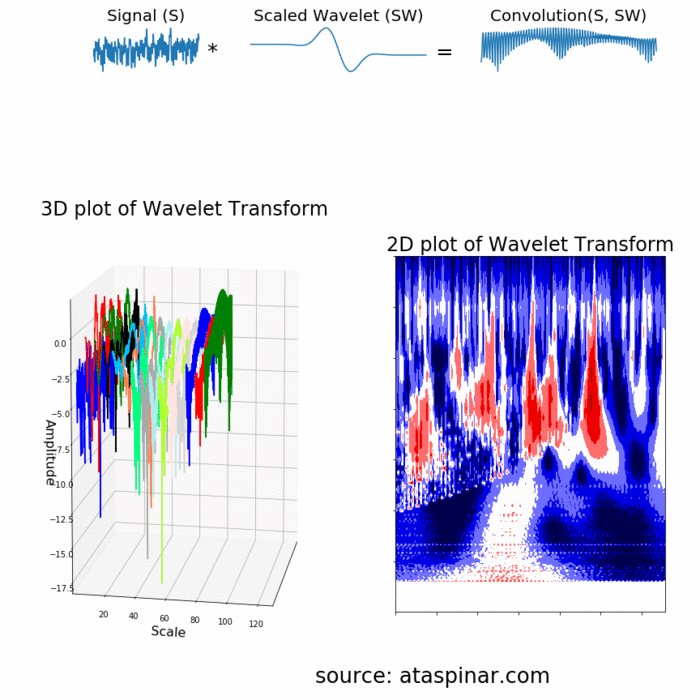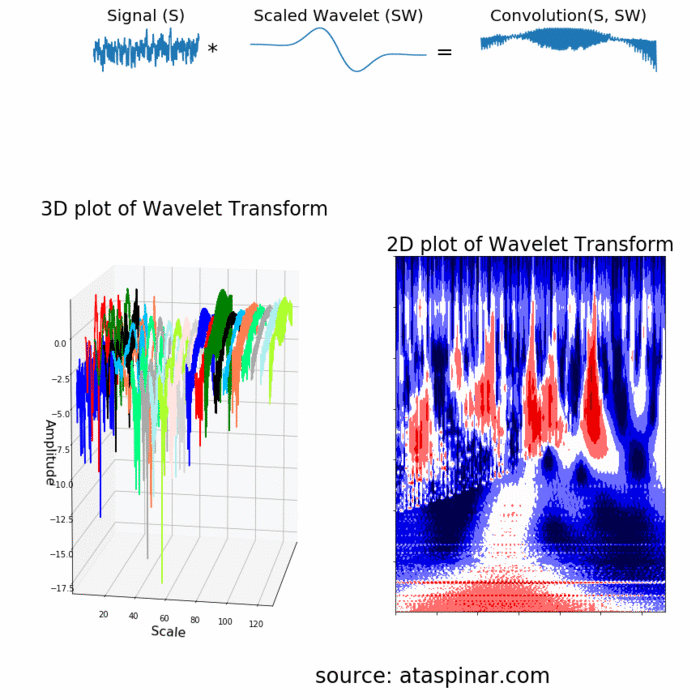
همان طور که از تصویر بالا مشخص است، تبدیل موجک یک سیگنال تک بعدی، دارای دو بعد است. این خروجی دو بعدی مربوط به تبدیل موجک، نمایش سیگنال اصلی بر حسب مقیاس و زمان است که به طیف اسپکتروگرام (Spectrogram) یا اسکالوگرام (Scaleogram) معروف است. در تصویر بالا، ابتدا تبدیل موجک به صورت سه بعدی و سپس به صورت دو بعدی نیز ترسیم شده است. ممکن است این سوال پیش بیاید که بُعد مقیاس (Scale) در تصویر اسپکتروگرام نشاندهنده چیست؟ در واقع، چون کلمه فرکانس اغلب برای تبدیل فوریه مورد استفاده قرار میگیرد، تبدیل موجک اغلب با مقیاس بیان میشود. در نتیجه در تبدیل موجک، دو بُعد اسپکتروگرام، زمان و مقیاس هستند. در مسائلی که فرکانس مناسبتتر وشهودیتر از مقیاس باشد، میتوان از طریق فرمول زیر، مقیاس را به شبهفرکانس (Pseudo-Frequencies) تبدیل کرد:
در این فرمول، برابر با شبهفرکانس، فرکانس مرکزی سیگنال موجک مادر و فاکتور مقیاس (Scaling Factor) است. واضح است که فاکتور مقیاس بالاتر (موجک طولانیتر) متناظر با فرکانسهای پایینتر است، بنابراین با مقیاسدهی به سیگنال موجک در حوزه زمان، میتوانیم فرکانسهای کوچکتر را آنالیز کنیم و در نتیجه به رزولوشن بالاتر در حوزه فرکانس میرسیم. به طریق مشابه، با استفاده از مقیاس کوچکتر، رزولوشن در حوزه زمان بالاتر خواهد رفت. بنابراین میتوان گفت مقیاس، معکوس فرکانس در تبدیل فوریه است. پکیج PyWavelets در پایتون، شامل تابع scale2frequency است تا تبدیل را از حوزه مقیاس به حوزه فرکانس انجام دهد.
انواع مختلف تبدیل موجک
تفاوت دیگری که بین تبدیل فوریه و تبدیل موجک وجود دارد، این است که تبدیل موجک انواع مختلفی دارد. برای انواع مختلف تبدیل موجک، مصالحه بین فشردگی (Compact) و صاف بودن (Smooth) با یکدیگر تفاوت دارند. این ویژگی بدین معنی است که میتوانیم نوع خاصی از تبدیل موجک را انتخاب کنیم که با ویژگی (Features) مورد نظر برای استخراج از سیگنال تناسب بیشتری داشته باشد.
به عنوان مثال کتابخانه PyWavelets شامل ۱۴ موجک مادر (انواع موجک) است. در قطعه کد زیر انواع این خانواده موجکها را میتوان مشاهده کرد.
هر خانواده از موجکها دارای شکل، فشردگی و همواری متفاوتی هستند و برای هدف متمایزی مورد استفاده قرار میگیرد. چون فقط دو شرط ریاضی وجود دارد که تابع موجک باید در آن صدق کند، در نتیجه تولید انواع مختلف موجک کار آسانی است. دو شرط ریاضی که موجک باید در آنها صدق کند، قیود متعامدسازی (Orthogonalization) و نرمالسازی (Normalization) نام دارند. بر اساس این قیود، یک موجک باید اولا انرژی محدود (Finite Energy) داشته باشد و دوما میانگین آن برابر با صفر باشد.
انرژی محدود به این معنی است که سیگنال در زمان و فرکانس متمرکز (Localized) باشد، انتگرالپذیر باشد و ضرب داخلی بین سیگنال و موجک همیشه وجود داشته باشد. همچنین بر اساس شرط مقبولیت دوم، موجک باید دارای میانگین صفر در حوزه زمان باشد یا به عبارت دیگر، در حوزه زمان و در فرکانس صفر، مقدار آن برابر با صفر باشد. این شرط برای اطمینان از انتگرالپذیری و نیز محاسبه معکوس تبدیل موجک بسیار ضروری است. علاوه بر این داریم:
- یک موجک میتواند متعامد (Orthogonal) یا غیر متعامد باشد.
- یک موجک میتواند متعامد دو طرفه (Bi-Orthogonal) باشد یا نباشد.
- یک موجک میتواند متقارن (Symmetric) یا غیرمتقارن باشد.
- یک موجک میتواند حقیقی یا مختلط باشد. موجک همیشه به دو قسمت تقسیم میشود، قسمت حقیقی که نشاندهنده دامنه و قسمت موهومی که نشاندهنده فاز است.
- یک موجک نرمالیزه میشود تا دارای انرژی واحد باشد.
با استفاده از قطعه کد زیر میتوانیم تصویری از خانوادههای مختلف موجک را ترسیم کنیم. ردیف اول شامل چهار نوع موجک گسسته و ردیف دوم شامل چهار نوع موجک پیوسته است.
خروجی این کد به صورت زیر است.

در هر یک از خانوادههای موجک، زیرگروههای موجک مختلفی نیز وجود دارد که متعلق به آن خانواده است. برای تشخیص زیرگروههای مختلف در هر خانواده از موجک، باید به تعداد ضرایب (Vanishing Moments) و سطح تجزیه (Level of Decomposition) توجه کنیم. این مفهوم در کد زیر برای یک خانواده از موجکها با نام Daubechies نشان داده شده است.
خروجی این قطعه کد به صورت زیر است.

در تصویر بالا، میتوانیم تبدیل موجک خانواده Daubechies یا به اختصار db را مشاهده کنیم. در ستون اول، تبدیل موجک db مرتبه (Order) اول (db1)، در ستون دوم تبدیل db2 و به همین ترتیب تا در ستون پنجم تبدیل موجک مرتبه ۵ ترسیم شده است.
کتابخانه PyWavelets شامل موجک Daubechies تا مرتبه ۲۰ است. تعداد مرتبههای تبدیل موجک نشاندهنده تعداد لحظات محوشدگی (Vanishing Moments) است. بنابراین db3 دارای سه لحظه محوشدگی و db5 دارای ۵ لحظه محوشدگی است. تعداد لحظات محوشدگی به درجه تقریب و همواری (Smoothness) تبدیل موجک بستگی دارد. اگر یک تبدیل موجک دارای p لحظه محوشدگی باشد، آنگاه میتواند یک تابع چندجملهای از درجه p-1 را تقریب بزند.
هنگام انتخاب کردن تبدیل موجک، میتوانیم تعیین کنیم که درجه تجزیه (Level of Decomposition) باید چقدر باشد. به صورت پیش فرض کتابخانه PyWavelets بیشینه درجه تجزیه ممکن را برای سیگنال ورودی انتخاب میکند. بیشینه درجه تجزیه توسط دستور pywt.dwt_max_level مشخص میشود و به طول سیگنال ورودی و موجک بستگی دارد.
واضح است که هر چقدر تعداد لحظات محوشدگی افزایش یابد، درجه چندجملهای موجک افزایش مییابد و هموارتر (نرمتر) میشود و هرچه درجه تجزیه افزایش یابد، تعداد نمونههایی که موجک بر اساس آن بیان میشود، افزایش مییابد.
تبدیل موجک پیوسته و تبدیل موجک گسسته
همان طور که در تصاویر دیدیم، تبدیل موجک دارای دو نوع مختلف گسسته و پیوسته است.
از لحاظ ریاضی، یک تبدیل موجک پیوسته را میتوان توسط تابع زیر توصیف کرد:
در فرمول بالا، موجک مادر پیوسته است که توسط فاکتور مقیاس و توسط فاکتور منتقل شده است. مقدار فاکتور مقیاسدهی و جابهجایی اعدادی پیوسته هستند، بنابراین تعداد بی شماری موجک وجود دارد. میتوان موجک مادر را توسط فاکتور ۱٫۳ یا ۱٫۳۱۱۱۱ یا هر عدد دیگر مقیاس کرد.
اما زمانی که راجع به تبدیل موجک گسسته بحث میکنیم، تفاوت اصلی که وجود دارد این است که از مقادیر گسسته برای فاکتور مقیاسدهی و جابهجایی در این تبدیل استفاده میشود. فاکتور مقیاس به صورت اعداد توان دو افزایش مییابد، بنابراین خواهد بود. فاکتور جابهجایی به صورت اعداد صحیح افزایش مییابند، بنابراین است. نکته مهمی که وجود دارد این است که تبدیل موجک گسسته فقط در دو حوزه مقیاس و جابهجایی گسسته است و در حوزه زمان گسسته نیست. برای کار کردن با سیگنالهای دیجیتال و گسسته، لازم است که تابع موجک را در حوزه زمان گسستهسازی کنیم. این فرمهای تبدیل موجک را تبدیل موجک گسسته در زمان یا تبدیل موجک پیوسته گسسته در زمان میگویند.
تبدیل موجک گسسته به صورت بانک فیلتری
در عمل، تبدیل موجک گسسته به صورت یک بانک فیلتری پیادهسازی میشود، بدین معنی که به صورت دنبالهای از فیلترهای پایین گذر و بالا گذر عمل میکند، به این دلیل که استفاده از بانک فیلتری یک راه بسیار موثر برای تجزیه یک سیگنال به زیرباندهای فرکانسی (Frequency Sub-bands) متعدد است. تلاش داریم تا در ادامه مفهوم پنهان در بانک فیلتری را به صورت ساده توضیح دهیم. درک عملکرد بانک فیلتری برای درک عملکرد تبدیل موجک ضروری است و میتواند در کاربردهای مختلف مورد استفاده قرار گیرد.
برای اعمال تبدیل موجک گسسته بر روی یک سیگنال، ابتدا با مقیاسهای کوچک شروع میکنیم. همان طور که قبلا گفتیم، مقیاسهای کوچک متناظر با فرکانسهای بالا است. بنابراین، ما ابتدا فرکانسهای بالا را آنالیز میکنیم. در گام دوم، مقیاس را با فاکتور دو افزایش میدهیم (فرکانس را با فاکتور دو کاهش میدهیم.) و در این حالت رفتار را در اطراف نصف فرکانس بیشینه آنالیز میکنیم. در گام سوم، فاکتور مقیاس را برابر با ۴ در نظر میگیریم و ما رفتار فرکانسی را در اطراف ربع فرکانس بیشینه تحلیل میکنیم. این روال به همین ترتیب ادامه مییابد تا به بیشینه سطح تجزیه برسیم.
برای درک مفهوم بیشینه سطح تجزیه (Maximum Decomposition Level)، ابتدا باید بدانیم که در هر مرحله متوالی، تعداد نمونهها در سیگنال با فاکتور دو کاهش مییابد. در مقادیر فرکانسهای پایین، به نمونههای کمتری نیاز داریم تا در نرخ نمونهبرداری نایکوئیست صدق کنند، بنابراین لازم نیست تعداد نمونههای بیشتری را در سیگنال حفظ کنیم؛ زیرا این کار تنها باعث میشود که هزینه محاسباتی بالاتر برود. به دلیل زیرنمونهبرداری (Downsampling) در بعضی از گامهای فرایند، تعداد نمونهها در سیگنال از طول فیلتر موجک کوچکتر میشود و در این حالت به بیشینه سطح تجزیه میرسیم.
به عنوان مثال، فرض کنید که سیگنالی با فرکانسهای در بازه 0 تا ۱۰۰۰ هرتز داریم. در گام اول، سیگنال را به دو بخش فرکانس بالا و فرکانس پایین تجزیه میکنیم. مثلا بخش اول فرکانسهای ۰ تا ۵۰۰ هرتز و بخش دوم فرکانسهای ۵۰۰ تا ۱۰۰۰ هرتز هستند. در گام دوم، بخش فرکانس پایین را در نظر میگیریم و مجددا آن را به دو بخش با فرکانسهای ۰ تا ۲۵۰ هرتز و ۲۵۰ تا ۵۰۰ هرتز تقسیم میکنیم. در گام سوم، بخش ۰ تا ۲۵۰ هرتز را در نظر میگیریم و آن را به دو بخش ۰ تا ۱۲۵ هرتز و ۱۲۵ تا ۲۵۰ هرتز تقسیم میکنیم. این روند را به همین صورت تا زمانی ادامه میدهیم که یا به درجه پالایش مورد نیاز برسیم و یا تعداد نمونهها تمام شود.
میتوان این ایده را به سادگی با استفاده از قطعه کد زیر به صورت تصویری نشان داد. در این کد نشان میدهیم که با اعمال تبدیل موجک گسسته روی یک سیگنال چیرپ (Chirp Signal)، چه اتفاقی رخ میدهد. سیگنال چیرپ، سیگنالی است که دارای طیف فرکانسی دینامیک باشد. در واقع طیف فرکانسی با زمان افزایش مییابد، سیگنال در ابتدا دارای مقادیر فرکانس پایین است و هر چه به سمت آخر سیگنال پیش میرویم، مقادیر سیگنال فرکانس بالاتر میشوند.
استفاده از سیگنال چیرپ، مصورسازی اینکه کدام بخش از طیف فرکانسی فیلتر شده است را از طریق نگاه کردن به محور زمان، سادهتر میکند.
در تصویر زیر نمایی از نحوه عملکرد تبدیل موجک گسسته به عنوان بانک فیلتری و خروجی قطعه کد بالا را میتوان دید.

در تصویر بالا میتوان سیگنال چیرپ و تبدیل موجک گسسته اعمال شده به آن را مشاهده کرد. در رابطه با این تبدیل ذکر چند نکته اهمیت بالایی دارد.
- در کتابخانه PyWavelets، تبدیل موجک گسسته توسط دستور pywt.dwt() اعمال میشود.
- تبدیل موجک گسسته دو مجموعه از ضرایب را به عنوان خروجی باز میگرداند، ضرایب تقریب (Approximation Coefficients) و ضرایب جزئیات (Detail Coefficients).
- ضرایب تقریب نشاندهنده خروجی فیلتر پایینگذر (فیلتر میانگینگیر) در تبدیل موجک گسسته هستند.
- ضرایب جزئیات نشاندهنده خروجی فیلتر بالاگذر (فیلتر مشتقگیر) در تبدیل موجک گسسته هستند.
- با اعمال تبدیل موجک گسسته مجددا روی ضرایب تقریب تبدیل موجک قبلی، تبدیل موجک مربوط به مرحله بعد را به دست میآوریم.
- در هر گام، نمونهبرداری سیگنال اصلی با فاکتور دو کاهش مییابد.
حال میتوان درک کرد که چرا تبدیل موجک گسسته به صورت بانک فیلتری پیادهسازی میشود. در هر مرحله متوالی، ضرایب تقریب به دو بخش پایینگذر و بالاگذر تقسیم میشوند و در مرحله بعد، تبدیل موجک مجددا روی بخش پایینگذر اعمال میشود. همان طور که میتوان دید، سیگنال اصلی ما در حال حاضر به سیگنالهای متعددی تبدیل شده است که هر کدام متناظر با باندهای فرکانسی مختلفی هستند. بعدا خواهیم دید که ضرایب تقریب و جزئی در زیر باندهای مختلف چگونه در کاربردهایی مانند حذف نویزهای فرکانس بالا از سیگنالها، فشرده کردن سیگنالها و یا طبقهبندی (Classifying) انواع مختلف سیگنالها مورد استفاده قرار میگیرند.
همچنین میتوانیم از دستور pywt.wavedec برای محاسبه سریع ضرایب از مرتبه بالاتر استفاده کرد. این دستور تابع اصلی و مرتبه n را به عنوان ورودی دریافت میکند و یک مجموعه از ضرایب تقریب (از مرتبه n) و n مجموعه از ضرایب جزئیات (از مرتبه یک تا n) را به عنوان خروجی باز میگرداند.
ایده آنالیز سیگنال با مقیاسهای متفاوت را آنالیز چند-رزولوشنی (Multiresolution) یا چند-مقیاسی (Multiscale) میگویند و تجزیه سیگنال به این روش را نیز تجزیه چندرزولوشنی یا کدینگ زیرباند (Sub-Band Coding) می گویند.
مصورسازی فضای حالت با استفاده از تبدیل موجک پیوسته
تا این قسمت با مفهوم تبدیل موجک، تفاوت آن با تبدیل فوریه، تفاوت بین تبدیل موجک پیوسته و تبدیل موجک گسسته، انواع خانوادههای مختلف تبدیل موجک، تاثیر درجه و سطح تجزیه روی موجک مادر آشنا شدیم و دانستیم چرا و چگونه تبدیل موجک گسسته مانند بانک فیلتری عمل میکند. همچنین دیدیم که خروجی تبدیل موجک روی سیگنال یک بعدی، منتج به یک اسپکتروگرام دو بعدی میشود. این اسپکتروگرام میتواند اطلاعات جزئی را درباره فضای حالت سیستم در اختیار ما قرار دهد یا به عبارت دیگر اطلاعاتی راجع به رفتار دینامیک سیستم در خود دارد.
دیتاست el-Nino یک سری زمانی است که برای ردیابی پدیده ال نینو مورد استفاده قرار میگیرد. این دیتاست شامل اندازه گیریهای سه ماهه دمای سطح دریا از سال 1871 تا 1997 است. به منظور درک قدرت یک اسپکتروگرام، میخواهیم تبدیل موجک را برای دادههای دیتاست ال نینو همراه با دادههای سری زمانی واقعی و تبدیل فوریه آنها نشان دهیم. این کار را با استفاده از قطعه کد زیر انجام میدهیم.
نتیجه اجرای این کد تصاویر زیر است که میتوانید آنها را مشاهده کنید.

با دقت در تصویر بالا میتوان دید که در اولین نمودار، سری زمانی دیتاست ال نینو به همراه میانگین زمانی آن نشان داده شده است. در تصویر وسط، تبدیل فوریه سری زمانی و در تصویر سوم، اسپکتروگرام این سیگنال را که از طریق تبدیل موجک پیوسته سیگنال اصلی به دست آمده است، میتوان مشاهده کرد.
در این اسپکتروگرام میتوان دید که قسمت عمده توان در یک دوره ۲ تا ۸ ساله متمرکز شده است. اگر این دوره را از طریق فرمول به فرکانس تبدیل کنیم، آنگاه به بازه فرکانس ۰٫۱۲۵ هرتز تا ۰٫۵ هرتز خواهیم رسید. البته از روی نمودار تبدیل فوریه نیز میتوان افزایش توان در اطراف این فرکانسها را مشاهده کرد. اما تفاوت اصلی که نمودار تبدیل فوریه و نمودار تبدیل موجک با یکدیگر دارند، در این است که تبدیل موجک میتواند اطلاعات زمانی را نیز در اختیار ما قرار دهد، در حالی که نمودار تبدیل فوریه این توانایی را ندارد.
به عنوان مثال، در اسپکتروگرام میتوان دید که تا سال ۱۹۲۰ نوسانات بسیاری در تغییرات دما وجود دارد، در حالی که بین سالهای ۱۹۶۰ تا ۱۹۹۰ نوسانات به این شدت نیستند. همچنین میتوان دید که با پیشرفت زمان، یک انتقال از تناوبهای کوتاه به تناوبهای بلند به وجود آمده است. در واقع، این یک نوع رفتار دینامیک در سیستم است که میتوان با استفاده از تبدیل موجک به وجود آن پی برد، در حالی که تبدیل فوریه قادر به آشکارسازی رفتارهای دینامیک یک سیگنال نخواهد بود. اکنون واضحتر شده است که تبدیل موجک در کاربردهای پردازش سیگنال و یادگیری ماشین تا چه اندازه قدرتمندتر عمل میکند. برای کاملتر شدن بحث، میخواهیم به نحوه کاربرد تبدیل موجک به همراه شبکه عصبی کانولوشنی در طبقهبندی یک سیگنال بپردازیم.
استفاده از تبدیل موجک در طبقهبندی سیگنال
همان طور که گفتیم، تبدیل موجک یک سیگنال یک بعدی، یک اسپکتروگرام دو بعدی خواهد بود که حاوی اطلاعات بیشتری نسبت به سیگنال سری زمانی و یا تبدیل فوریه آن است. این حقیقت را با اعمال تبدیل موجک بر روی دیتاست ال نینو مشاهده کردیم. با اعمال تبدیل موجک روی این دیتاست، نه تنها به اطلاعات دوره تناوب بزرگترین نوسانات در دمای سطح دریا پی میبریم، بلکه خواهیم دانست این نوسانات چه زمانی رخ دادهاند و چه زمانی وجود نداشتهاند.
این اسپکتروگرام، برای درک بهتر رفتر دینامیک یک سیگنال مورد استفاده قرار میگیرد و نیز با استفاده از آن میتوان انواع مختلف سیگنالهای تولید شده توسط یک سیستم را از یکدیگر تمایز داد. اگر یک سیگنال حیاتی بدن را هنگام بالا رفتن از پلهها و نیز پایین رفتن از پله ها ضبط کنید، اسپکتروگرام سیگنال در این دو حالت با یکدیگر تفاوت خواهند داشت. به همین ترتیب سیگنالهای الکتروکاردیوگرافی (ECG) افراد سالم با سیگنالهای ECG افراد آریتمی مختلف خواهد بود. از این ویژگی میتوان در تشخیص عیب (Fault Detection) ادوات و دستگاههای مکانیکی مانند موتورها و توربینهای بادی نیز میتوان استفاده کرد.
بنابراین با نگاه کردن به اسپکتروگرام، میتوان یک روتور موتور معیوب را از یک روتور سالم یا یک فرد سالم از فرد بیمار و یا بالا رفتن از پله را از پایین رفتن از آن تشخیص داد. اما گاهی لازم است که این کار را بدون چک کردن دستی اسپکتروگرامهای متعدد مربوط به موارد مختلف انجام دهیم. یک راه برای انجام اتوماتیک این کار، ایجاد یک شبکه عصبی کانولوشنی است. این شبکه عصبی قادر است که به صورت خودکار، کلاسی که اسپکتروگرام به آن تعلق دارد را مشخص کند و در نتیجه سیگنالها را بر اساس آن طبقهبندی کند. اگر با شبکه عصبی کانولوشن آشنا نیستید، بهتر است که ابتدا مطلب «بررسی شبکه عصبی کانولوشن (CNN)» را در مجله فرادرس مطالعه کنید. در بخشهای بعد، ابتدا یک دیتاست را بارگذاری میکنیم که اطلاعات افراد در حین انجام شش فعالیت مختلف را ضبط کرده است. سپس اسپکتروگرام این دیتاست را با استفاده از تبدیل موجک ترسیم میکنیم و در نهایت با استفاده از شبکه عصبی کانولوشنی این سیگنالها را طبقهبندی خواهیم کرد.
بارگذاری دیتاست
حال میخواهیم دادههای یک دیتاست شامل سری زمان را با استفاده از اسپکتروگرام و شبکه CNN طبقهبندی کنیم. ابتدا دیتاست تشخیص فعالیتهای انسان (UCI-HAR) را از این لینک دانلود و سپس بارگذاری میکنیم. این دیتاست با استفاده از سنسورها از افراد در حال انجام کارهای مختلف مانند بالا و پایین رفتن از پله، خوابیدن، ایستادن و راه رفتن ضبط شده است. در کل، 10000 سیگنال در این دیتاست قرار دارد که هر کدام از آنها از ۹ المان تشکیل شدهاند.
بعد از اینکه دیتاست را دانلود کردیم، میتوانیم آن را با کد زیر در یک nd-array از کتابخانه numpy بارگذاری کرد.
دادههای آموزش (Training Set) شامل 7352 سیگنال هستند که هر سیگنال ۱۲۸ نمونه اندازهگیری و 9 المان دارد. بنابراین دادههای آموزش در یک ndarray با ابعاد و دادههای تست (Test Set) در یک آرایه دیگر با ابعاد بارگذاری میکنیم.
چون هر سیگنال از ۹ المان تشکیل شده است، در نتیجه باید تبدیل موجک پیوسته را به هر سیگنال ۹ بار اعمال کنیم. در تصویر زیر نتیجه حاصل از اعمال تبدیل موجک پیوسته به دو سیگنال مختلف از دیتاست را میتوان مشاهده کرد.


در تصویر بالا، نمونههای حاصل از اعمال تبدیل موجک به یک سیگنال فرد در حال بالا رفتن از پلهها و فرد خوابیده را میتوان مشاهده کرد.
اعمال تبدیل موجک پیوسته بر روی دیتاست
چون هر سیگنال دارای ۹ مولفه است، بنابراین هر سیگنال ۹ اسپکتروگرام نیز دارد. بنابراین سوال بعدی این است که چگونه این ۹ اسپکتروگرام را به شبکه کانولوشنی وارد کنیم. راههای مختلفی برای این کار وجود دارد.

- راه اول این است که برای هر مولفه، یک شبکه CNN را به صورت جداگانه آموزش دهیم و سپس نتایج این ۹ شبکه را از طریق یکی از روشهای Ensembling با یکدیگر مخلوط کنیم. اما این روش در حالت کلی منجر به نتایج ضعیفی میشود؛ زیرا وابستگیهای داخلی بین این ۹ مولفه را در شبکه عصبی دخالت ندادهایم.
- راه دوم الحاق کردن (Concatenate) این ۹ سیگنال مختلف به یکدیگر و ایجاد یک سیگنال طولانیتر و سپس اعمال شبکه عصبی به سیگنال الحاقی است. این روش نیز میتواند کارا باشد، اما در محل الحاق سیگنالها به یکدیگر، شاهد ناپیوستگیهایی خواهیم بود. این ناپیوستگیها میتوانند در محل مرزهای مولفههای سیگنال در اسپکتروگرام منجر به ایجاد نویز شوند.
- راه سوم این است که ابتدا تبدیل موجک پیوسته را محاسبه کنیم و سپس ۹ تصویر تبدیل موجک مختلف را به یکدیگر الحاق کنیم و تصویر نهایی را به شبکه عصبی وارد کنیم. این روش نیز موثر است، اما در آن نیز مجددا در لبههای تصاویر تبدیل موجک، ناپیوستگی به وجود میآید که باعث ایجاد نویز میشود و در نهایت وارد شبکه عصبی میشود. اگر شبکه عصبی کانولوشنی به اندازه کافی عمیق باشد، آنگاه قادر خواهد بود که تفاوت بین این قسمتهای نویزی و قسمتهای مفید و واقعی تصویر را تشخیص دهد. با این وجود، استفاده از راه حل چهارم پیشنهاد میشود.
- هر ۹ اسپکتروگرام را روی (Top) یکدیگر قرار دهید و یک تصویر با ۹ کانال مختلف را ایجاد کنید.
اما تصویری با ۹ کانال به چه معنی است؟ در حالت عادی، هر تصویر یا سیاه و سفید است و یک کانال دارد و یا تصویر از نوع رنگی (RGB) بوده و سه کانال دارد. اما شبکه عصبی کانولوشنی برای سادگی در مدیریت تصاویر میتواند این تصاویر مختلف را در کنار یکدیگر و به عنوان ۹ کانال در نظر بگیرد. طریقه عملکرد شبکه عصبی CNN همچنان مانند قبل است، اما تفاوتی که وجود دارد این است که در مقایسه با یک تصویر RGB، سه برابر فیلتر بیشتری وجود خواهد داشت. در تصویر زیر روند انجام این کار را میتوان مشاهده کرد.

در تصویر بالا نشان داده شده است که چگونه از ۹ تصویر حاصل از اعمال تبدیل موجک به ۹ مولفه سیگنال، برای ایجاد یک تصویر ۹ کانالی برای ورودی شبکه کانولوشنی استفاده شده است.
در ادامه، قطعه کد پایتون مربوط به اعمال تبدیل موجک پیوسته روی سیگنالهای دیتاست و نیز بازآرایی مجدد آنها برای کاربرد در ورودی شبکه عصبی کانولوشنی را مشاهده میکنید. دیتاست در حالت کلی شامل ۱۰۰۰۰ سیگنال است، اما در اینجا از ۵۰۰۰ سیگنال به عنوان داده آموزش و از ۵۰۰ سیگنال دیگر به عنوان داده تست استفاده میکنیم.
همان طور که از قطعه کد بالا مشخص است، تبدیل موجک یک مولفه تکی سیگنال (۱۲۸ نمونه) منجر به یک تصویر با ابعاد ۱۲۷ در ۱۲۷ پیکسل میشود، بنابراین اسپکتروگرام حاصل از ۵۰۰۰ داده آموزش، در یک آرایه با ابعاد ذخیره میشود. همچنین اسپکتروگرام حاصل از ۵۰۰ سیگنال تست، در آرایه numpy دیگری با ابعاد ذخیرهسازی میشود.
آموزش شبکه عصبی کانولوشنی
حال که دادهها در فرمت صحیحی قرار گرفتهاند، میتوان شبکه عصبی CNN را آموزش داد. برای این قسمت لازم است تا از کتابخانه Keras استفاده کنیم. بنابراین باید ابتدا آن را نصب کنیم.
در ادامه کدهای پایتون برای آموزش شبکه عصبی آورده شدهاند:
دقت طبقهبندی دیتاست UCI-HAR با استفاده از ترکیب شبکه عصبی کانولوشنی و تبدیل موجک را روی دادههای آموزش و تست می توان در تصویر زیر مشاهده کرد.

همان طور که میتوان دید، تلفیق تبدیل موجک و شبکه عصبی کانولوشنی منجر به نتایج فوقالعادهای میشود. در طبقهبندی انواع مختلف فعالیتهای انسان، استفاده از این روش منجر به 94 درصد دقت (Accuracy) میشود. این دقت بسیار بالاتر از دقتی است که با سایر روشهای طبقهبندی میتوان به آن رسید. در بخش بعد، از تبدیل فوریه گسسته استفاده میکنیم و مجددا دادههای همین دیتاست را طبقهبندی میکنیم و نتایج را در دو حالت با یکدیگر مقایسه میکنیم.
تجزیه سیگنال با استفاده از تبدیل موجک گسسته
در بخشهای قبلی دیدیم که چگونه تبدیل موجک گسسته مانند یک بانک فیلتری عمل میکند و میتواند یک سیگنال را به فرکانسهای زیر باند تجزیه کند. در این بخش، میخواهیم نحوه تجزیه یک سیگنال به فرکانسهای زیر باند و بازسازی مجدد سیگنال اصلی را با استفاده از کتابخانه PyWavelets در پایتون بررسی کنیم. PyWavelets دو روش اساسی برای تجزیه یک سیگنال در اختیار کاربر قرار میدهد.
- در روش اول میتوان pywt.dwt() را روی سیگنال اعمال کرد و ضرایب تقریب را بازیابی کرد. سپس باید تبدیل موجک گسسته را روی ضرایب بازیابی شده اعمال کرد تا ضرایب مرحله دوم را به دست آورد. این فرایند را باید تا رسیدن به سطح تجزیه مطلوب ادامه داد.
- در روش دوم، میتوان تابع pywt.wavedec() را مستقیما روی سیگنال اعمال کرد و تمام ضرایب جزئیات را تا سطح تجزیه دلخواه n به دست آورد. این تابع، سیگنال اصلی و سطح n را به عنوان ورودی دریافت میکند و یک مجموعه از ضرایب تقریب (مربوط به سطح تجزیه n) و n مجموعه از ضرایب جزئیات (از سطح یک تا سطح n) را در خروجی باز میگرداند.
با استفاده از قطعه کد زیر میتوان نتیجه استفاده از روش اول را بررسی کرد.
در تصویر زیر به عنوان خروجی میتوان سیگنال اصلی را به همراه سیگنال بازسازی شده مشاهده کرد.

در تصویر بالا، یک سیگنال را به ضرایب آن تجزیه کردیم و مجددا با استفاده از معکوس تبدیل موجک گسسته بازسازی نمودیم.
در روش دوم، از تابع pywt.wavedec() استفاده میشود تا یک سیگنال را تجزیه و سپس مجددا بازسازی کرد. روش دوم سادهترین راه برای تجزیه و بازسازی یک سیگنال است، مخصوصا زمانی که بخواهید ضرایب مرتبه بالاتر را به دست آورید. قطعه کد زیر نحوه استفاده از این تابع را نشان میدهد.
خروجی این کد به صورت تصویر زیر است که سیگنال تجزیه شده و سیگنال بازسازی شده را با یکدیگر نشان میدهد.

حذف نویز (مولفههای فرکانس بالا) با استفاده از تبدیل موجک گسسته
در بخش قبل دیدیم که چگونه میتوان یک سیگنال را به ضرایب تقریب (پایین گذر) و ضرایب جزئیات (بالا گذر) تجزیه کرد. اگر سیگنال را با استفاده از این ضرایب بازسازی کنیم، در نهایت سیگنال اصلی را میتوان مجددا به دست آورد. اما اگر تعدادی از ضرایب جزئیات را از دست بدهیم، آنگاه در بازسازی سیگنال اصلی چه اتفاقی میافتد؟ به دلیل اینکه ضرایب جزئیات، نشاندهنده قسمت فرکانس بالا در سیگنال هستند، در نتیجه میتوان گفت که در اثر حذف تعدادی از ضرایب جزئیات، بخشی از طیف فرکانسی فیلتر میشود. اگر در سیگنال نویزهای فرکانس بالای زیادی وجود داشته باشند، این روش میتواند به فیلتر و حذف کردن آنها کمک کند.
صرف نظر کردن از ضرایب جزئیات، با استفاده از دستور pywt.threshold() انجام میگیرد. در واقع این دستور مقادیر ضرایب بالاتر از حد آستانه (Threshold) خاصی را حذف میکند.
حال میخواهیم با استفاده از دیتاست «NASA’s Femto Bearing Dataset» این مفهوم را نشان دهیم. این دیتاست شامل دادههای فرکانس بالای سنسور در حضور عیب یاتاقان (Bearings) است.
قطعه کد زیر را در محیط پایتون اجرا میکنیم.
تصویر زیر در خروجی ایجاد میشود. در این تصویر سیگنال با مولفههای فرکانس بالا و سیگنال صافشده آن پس از اعمال تبدیل موجک گسسته را میتوان مشاهده کرد.

همان طور که در تصویر بالا نیز مشاهده میشود، میتوان از طریق تجزیه یک سیگنال و برابر صفر قرار دادن برخی از ضرایب در آن و سپس بازسازی مجدد سیگنال، نویزهای فرکانس بالا در سیگنال را حذف کرد. البته اگر با تکنیکهای مختلف پردازش سیگنال آشنا باشیم، میدانیم که روشهای مختلفی برای حذف نویز از یک سیگنال وجود دارد.
به عنوان مثال، در پایتون کتابخانه Scipy دارای فیلترهای صافکننده متنوعی است که استفاده از این فیلترها بسیار سادهتر است. یکی از فیلترهای صافکننده، فیلتر Savitzky-Golay نام دارد. یکی دیگر از روشهای حذف نویز، میانگینگیری از سیگنال در طول محور زمان است.
سوالی که پیش میآید این است که چرا باید از روش تبدیل موجک گسسته که نسبتا پیچیدهتر است، به جای این روشها استفاده کرد؟ در جواب باید گفت، مزیت اصلی تبدیل موجک گسسته از این ویژگی ناشی میشود که اشکال متنوعی از موجک وجود دارند که میتوان از آنها استفاده کرد. میتوان یک موجک را انتخاب کرد که شکل آن متناظر با مشخصههایی از پدیده باشد که انتظار مشاهده آن را داریم. به این طریق، تعداد کمتری از مشخصههای پدیده که مورد نیاز هستند، در اثر صاف شدن از بین میروند.
استفاده از تبدیل موجک گسسته برای طبقهبندی سیگنال
در ادامه قصد داریم تا ببینیم چگونه میتوان از تبدیل موجک گسسته و شبکه عصبی کانولوشنی برای طبقهبندی سیگنالها استفاده کرد.
ایده پنهان در طبقهبندی سیگنال با استفاده از تبدیل موجک گسسته
ایدهای که در پس طبقهبندی سیگنال با استفاده از تبدیل موجک گسسته وجود دارد را میتوان به صورت زیر بیان کرد:
ابتدا از تبدیل موجک گسسته برای تفکیک یک سیگنال به زیرباندهای فرکانسی مختلف استفاده میکنیم. این کار را تا حد ممکن یا تا حد لازم تکرار میکنیم. چون انواع مختلف سیگنالها، مشخصههای فرکانسی مختلفی را از خود نشان میدهند، در نتیجه این تمایز در رفتار باید در یکی از زیرباندهای فرکانسی خود را نشان دهد. بنابراین اگر ویژگیها (Features) را از هریک از زیرباندهای مختلف ایجاد کنیم و از مجموعه تمام ویژگیها به عنوان ورودی در یک طبقهبند (Classifier) مانند جنگل تصادفی، ارتقای گرادیان و یا رگرسیون منطقی استفاده کنیم و الگوریتم طبقهبندی را با استفاده از این ویژگیها آموزش دهیم، آنگاه الگوریتم قادر خواهد بود که تمایز بین سیگنالهای مختلف را تشخیص دهد و طبقهبندی را بر اساس آن انجام دهد. این مفهوم در تصویر زیر به خوبی نشان داده شده است.

تولید ویژگی از هر زیر باند
حال میخواهیم بدانیم از مجموعه مقادیر هر زیر باند چه ویژگیهایی را میتوان ایجاد کرد؟ واضح است که این امر تا حد بسیار زیادی به نوع سیگنال و کاربرد مورد نظر بستگی دارد. اما در حالت کلی، ویژگیهای زیر را میتوان به عنوان متداولترین و پر تکرارترین ویژگیهای مورد استفاده در سیگنالها بیان کرد:
- مقادیر ضرایب مدل اتورگرسیو (Auto-regressive)
- مقادیر آنتروپی (Entropy). این مقادیر را میتوان به عنوان معیاری از پیچیدگی (Complexity) سیگنال در نظر گرفت.
و یا ویژگیهای آماری مانند:
- واریانس
- انحراف معیار
- میانگین، میانه
- مقدار صدک 25ام
- مقدار صدک 75ام
- مقدار مجذور میانگین مربعات
- میانگین مشتقات
- نرخ عبور از صفر. (تعداد دفعات عبور سیگنال از )
- نرخ عبور از میانگین. (تعداد دفعات عبور سیگنال از )
البته ایده دیگری نیز برای ایجاد ویژگی از زیرباندهای سیگنال وجود دارد. میتوانید از تعدادی از ویژگیهایی که در اینجا توصیف شدند استفاده کنید و یا حتی می توانید تمامی آنها را با هم به کار برید. اکثر طبقهبندها یا کلاسیفایرها در پکیج Scikit-Learn آنقدر توانمند هستند که میتوانند تعداد زیادی ویژگی ورودی را مدیریت کنند و انواع مفید و غیر مفید ویژگیها را از یکدیگر تمایز دهند. البته توجه کنید که تعداد بسیار زیادی توابع آماری در کتابخانه scipy.stats. وجود دارند که میتوان با استفاده از آنها ویژگیهای بیشتری را نیز ایجاد کرد.
با استفاده از قطعه کد زیر میتوان نحوه استفاده از تعدادی از ویژگیهای بیان شده در بالا را مشاهده کرد.
در قطعه کد بالا توابع زیر مورد استفاده قرار گرفتهاند:
- یک تابع برای محاسبه مقدار آنتروپی مربوط به سیگنال ورودی.
- یک تابع برای محاسبه چند مشخصه آماری مانند: میانگین، چند صدک، انحراف معیار و واریانس و ....
- یک تابع برای محاسبه نرخ عبور از صفر و نرخ عبور از میانگین.
- یک تابع برای ترکیب نتایج سه تابع بالا.
تابع نهایی در برنامه بالا ۱۲ ویژگی متمایز را برای هر لیست از مقادیر در خروجی باز میگرداند. بنابراین اگر یک سیگنال به ۱۰ زیر باند متمایز تجزیه شود و برای هر زیر باند ویژگیهایی تولید کنیم، در نهایت 120 ویژگی برای هر سیگنال خواهیم داشت.
استفاده از ویژگیها و کتابخانه Scikit-Learn برای طبقهبندی دو دیتاست ECG
تا این قسمت مطالب بسیاری را بیان کردیم. در گام بعد، باید سیگنالهای مجموعه آموزش را با استفاده از تبدیل موجک گسسته به زیر باندهای خود تجزیه کنیم و برای هر زیر باند ویژگیها را محاسبه کنیم. سپس از ویژگیها برای آموزش یک طبقهبند استفاده کنیم تا طبقهبند بتواند سیگنالهای مجموعه تست را پیشبینی کند. این فرایند را برای دو دیتاست سری زمانی انجام میدهیم.
- اولین دیتاست UCI-HAR است که در بخشهای قبل از آن استفاده کردیم. این دیتاست شامل دادههای ضبط شده سنسورهای گوشیهای هوشمند از فعالیتهای مختلف انسان مانند نشستن، ایستادن، راه رفتن، بالا رفتن از پله و پایین رفتن از پله است.
- دومین دیتاست، PhysioNet نام دارد که شامل دادههای ECG است.دیتاست PhysioNet را میتوانید با کلیک روی لینک دانلود کنید. دیتاست PhysioNet شامل مجموعهای از سیگنالهای ECG اندازهگیری شده از افراد سالم (NSR) و افراد با بیماری ARR یا CHF است. در مجموع دیتاست از 96 اندازهگیری ARR و 36 اندازهگیری NSR و 30 اندازهگیری CHF تشکیل شده است.
بعد از اینکه هر دو دیتاست را دانلود کردیم و آنها را در پوشه صحیح قرار دادیم، گام بعدی این است که آنها را در حافظه بارگذاری کنیم. در بخش قبل با نحوه بارگذاری دیتاست UCI-HAR آشنا شدیم. در قطعه کد زیر نحوه بارگذاری دیتاست ECG را مشاهده میکنید.
توجه کنید که دیتاست ECG به صورت یک فایل MATLAB ذخیره شده است. بنابراین باید از scipy.io.loadmat() استفاده کنیم تا این فایل در پایتون باز شود و دادههای اندازهگیری و برچسب هر کدام در دو لیست جداگانه بازیابی شود.
توجه کنید که دیتاست UCI HAR در فایلهایی با پسوند txt. ذخیره شده است و بعد از خواندن دادهها، باید آنها را در یک آرایه numpy با سایز ذخیره کنیم. حال میخواهیم ببینیم ویژگیهای سیگنالها به چه صورت از دیتاستها استخراج میشوند.
برای این کار باید قطعه کد زیر را در پایتون اجرا کنیم.
کاری که در کد بالا انجام دادیم این است که توابعی برای تولید ویژگی از سیگنالهای ECG و UCI HAR نوشتیم. در واقع این دو تابع تفاوتی با یکدیگر ندارند و تنها دلیل اینکه از دو تابع مختلف برای این دو دیتاست استفاده کردیم این است که دادهها در هر کدام از آن ها با یک فرمت مختلف ذخیره شده است. دادهها در دیتاست ECG در قالب لیست ذخیره شدهاند، در حالی که دادهها در دیتاست UCI HAR در قالب یک numpy ndarray سه بعدی ذخیره شدهاند.
در برنامه فوق برای دادههای دیتاست ECG، روی لیست سیگنالها حلقه زدهایم و روی هر سیگنال تبدیل موجک گسسته را اعمال کردهایم که در نهایت لیستی از ضرایب را باز میگرداند. برای هر یک از این سیگنالها یا به عبارت دیگر برای هر یک از این زیر باندها، ویژگیها را با استفاده از تابعی که در بخش قبل تعریف کردیم، استخراج میکنیم. ویژگیهایی که با استفاده از تمام ضرایب مختلف مربوط به یک سیگنال محاسبه شدهاند، به یکدیگر الحاق میشوند؛ زیرا این ویژگیها در واقع متعلق به یک سیگنال هستند.
همین کار را با دادههای دیتاست UCI HAR نیز انجام میدهیم. تنها تفاوت در این است که این بار دو حلقه for داریم؛ زیرا هر سیگنال از ۹ مولفه تشکیل شده است. ویژگیهایی که از هر یک از زیر باندهای هر مولفه یک سیگنال تولید میشود، به یکدیگر الحاق میشوند.
حال که ویژگیها را برای هر دیتاست محاسبه کردهایم، میتوانیم از تابع دستهبند یا طبقهبند ارتقای گرادیان (GradientBoostingClassifier) در کتابخانه scikit-learn استفاده کنیم و آن را آموزش دهیم. برای این کار باید قطعه کد زیر را در پایتون اجرا کنیم.
همان طور که میبینید، نتایج هنگام استفاده از تبدیل موجک گسسته به همراه Gradient Boosting Classifier بسیار عالی است. این روش روی دیتاست ECG دارای دقت 93 درصد و روی دیتاست UCI-HAR دارای دقت ۹۵ درصد است.
مقایسه دقت طبقهبندی با استفاده از تبدیل موجک گسسته، تبدیل فوریه و شبکه عصبی بازگشتی (RNN)
اگر طبقهبندی دادههای دیتاست UCI-HAR را با استفاده از تبدیل فوریه انجام دهیم، آنگاه دقت بر روی دادههای تست برابر با ۹۱ درصد خواهد بود. از طرف دیگر، اگر طبقهبندی را با استفاده از شبکه عصبی بازگشتی انجام دهیم، آنگاه بالاترین دقت روی دادههای تست حدودا ۸۶ درصد به دست میآید. در حالی که با استفاده از تبدیل موجک و CNN توانستیم به دقت ۹۴ درصد و با استفاده از تبدیل موجک و ارتقای گرادیان به دقت ۹۵ درصد روی دادههای تست برسیم.
واضح است که استفاده از تبدیل موجک باعث شده که دقت طبقهبندی نسبت به سایر روشها بسیار بالاتر باشد. این کار را میتوان با دیتاستهای دیگر نیز انجام داد و به احتمال زیاد باز هم نتایج با استفاده از تبدیل موجک نسبت به سایر روشها بهتر خواهد بود. نکته دیگری که در اینجا لازم است به آن توجه کنیم این است که شبکه عصبی بازگشتی بدترین نتیجه را در بین این سه روش دارد. حتی استفاده از روش بسیار سادهای مانند تبدیل فوریه و یافتن محل پیکهای طیف فرکانسی، به نتیجه بهتری نسبت به استفاده از شبکه عصبی بازگشتی میتوان دست یافت.
این نکته بسیار جالب است، زیرا یکی از ویژگیهای شبکه عصبی بازگشتی، توانایی یادگیری وابستگیهای موقتی (Temporal Dependencies) در دادههای ترتیبی (Sequential Data) است. اگر تبدیل فوریه قادر است هر سیگنالی را بدون توجه به پیچیدگی آن توسط المانهای فوریه توصیف کند، آنگاه با توجه به وابستگیهای موقتی، چه چیزهای بیشتری را میتواند یاد بگیرد.
دقت به دست آمده با استفاده از تبدیل موجک گسسته به ویژگیهایی که برای محاسبه در نظر گرفته میشود، موجک انتخاب شده و نوع الگوریتم دستهبند نیز بستگی دارد. برای یافتن درک نسبی، در تصویر زیر دقت طبقهبندی دادههای تست روی دیتاستهای UCI-HAR و ECG به ازای تمام موجکهای PyWavelets و ۵ مورد از پرکاربردترین الگوریتمهای طبقهبندی کتابخانه scikit-learn نشان داده شده است.

با توجه به این تصویر میتوان دید که دقت طبقهبندی، متناظر با الگوریتم طبقهبندی انتخاب شده و تابع موجک، تغییر خواهد کرد، اما در حالت کلی میتوان گفت که الگوریتم ارتقای گرادیان عملکرد بهتری دارد. نکته دیگری که باید به آن اشاره کرد این است که موجک انتخاب شده میتواند تاثیر زیادی روی دقت نهایی طبقهبندی داشته باشد. بهترین راه برای انتخاب موجک مناسب، آزمایش و خطای بسیار و نیز انجام تحقیق روی کاربرد قبل از پیادهسازی است.
تبدیل موجک در متلب
برای آشنایی با پیادهسازی تبدیل موجک در متلب در این قسمت میخواهیم تبدیل موجک را روی بخشی از دیتاست ال نینو اعمال کنیم. دادهها را میتوان از طریق کلیک روی sst_nino3.dat دانلود کرد. این فایل شامل دادههای دیتاست ال نینو است که باید در قالب فایل dat. در متلب ذخیره شود. حال باید توابع chisquare_inv.m و chisquare_solve.m و wave_bases.m و wave_signif.m و wavelet.m را دانلود کرده و در یک محل قرار دهیم.
در نهایت برای تست کردن نتیجه اعمال تبدیل موجک میتوان کد زیر را اجرا کرد.
wavetest.m
نتیجه حاصل از اجرای کد بالا، در تصویر زیر نشان داده شده است.

اگر این مطلب برای شما مفید بوده است، آموزشهای زیر نیز به شما پیشنهاد میشوند:
- مجموعه آموزشهای پردازش سیگنال
- آموزش مقدماتی پردازش سیگنال با Python (پایتون)
- مجموعه آموزشهای هوش مصنوعی
- آموزش یادگیری عمیق (Deep learning)
- تبدیل فوریه سریع (fft) — به زبان ساده
- سری فوریه مختلط — به زبان ساده
- شبکه عصبی در متلب — از صفر تا صد
^^










بسیار عالی و مفید بود برام،واقعا ممنوم
سلام
خیلی ممنون
مطلب کامل و فوق العاده مفیدی بود
سلام خداقوت. مطالب خیلی خوب و کامل بود. تشکر از وقتی که برای نوشتن این مطالب گذاشتید.
بسیار عالی ومفید متشکرم
با سلام و احترام
ضمن تشکر از تلاش ها و زحمات شما در گردآوری این مجموعه عالی برای بخش “مصورسازی فضای حالت با استفاده از تبدیل موجک پیوسته” قطعه کد زیر به همراه کتابخانه های مربوطه جهت اجرای دیتا ست پدیده El Nino به کدهای ارائه شده اضافه گردد:
from numpy import *
from scipy import *
import pandas as pd
from pylab import *
import pywt
def get_ave_values(xvalues, yvalues, n = 5):
signal_length = len(xvalues)
if signal_length % n == 0:
padding_length = 0
else:
padding_length = n – signal_length//n % n
xarr = array(xvalues)
yarr = array(yvalues)
xarr.resize(signal_length//n, n)
yarr.resize(signal_length//n, n)
xarr_reshaped = xarr.reshape((-1,n))
yarr_reshaped = yarr.reshape((-1,n))
x_ave = xarr_reshaped[:,0]
y_ave = nanmean(yarr_reshaped, axis=1)
return x_ave, y_ave
با سلام و احترام؛
صمیمانه از همراهی شما با مجله فرادرس و ارائه بازخورد سپاسگزاریم.
از اینکه این مطلب مورد توجه شما قرار گرفته است بسیار خرسند و مفتخریم.
برای شما آرزوی سلامتی و موفقیت داریم.
ممنون از مطالب ارزشمند شما. ممنون میشم اگر در مورد موجک با الگوریتم meyerتوضیح کاملی بدید. با تشکر
با سلام و احترام
1- از تبدیل موجک در پردازش تصاویر ماهواره ای چگونه استفاده کنم؟ و برای این کار از چه نرم افزاری استفاده کنیم؟
با تشکر
بسیار عالی. دست شما نویسنده گرامی درد نکند.
سلام و خدا قوت
بسیار عالی و آموزنده بود
با سلام و تشکر از ترجمه خوب شما. مطلب بسیار کاربردی و خوب هست فقط توی قسمت “تبدیل فوریه گسسته به صورت بانک فیلتری” هم عنوان و هم در قسمت هایی از متن “فوریه” به جای “موجک” نوشته شده که لطفا اصلاح کنین.
سلام.
متن بازبینی و اصلاح شد.
سپاس از همراهی و بازخوردتان.
سلام. من منبع این مطلب را نتوانستم در سایت پیدا کنم. مطالبی که به این شکل ترجمه می شوند بسیار کار خوبی هستند و زحمت کشیده شده ارزشمند است ولی باید مرجع اصلی اشاره گردد.
ضمنا کدها نیز به راحتی قابل اجرا نیست.
با تشکر
سلام، وقت شما بخیر؛
منابع کلیه مطالب مجله فرادرس در انتهای آنها و در پس از بخش معرفی آموزشها و مطالب مرتبط ذکر شدهاند.
از اینکه با مجله فرادرس همراه هستید از شما بسیار سپاسگزاریم.
سلام خسته نباشید
دست بوس عزیزانی هستم که در فرادرس زحمت می کشند.کاش زودتر از اینها این پروژه دانش بنیان در دسترس بود.
ان شاء الله علمتون در رونق تر بشه.
سلام .
مطلب بسیار مفید و آموزنده است . خسته نباشید . خدا قوت .
بنده در مورد تبدیل shearlet مطالعه می کنم . برای تبدیل یک تصویر به باند فرکانس پایین و بالا با استفاده از NSST . آیا امکان راهنمایی وجود دارد . سپاسگزارم
با تشکر از وقت و انرژی که برای ترجمه این مقاله گذاشته شد. طبق عرف علمی و حرفه ای حداقل باید نام نویسنده اصلی و لینک متن آن به اشتراک گذاشته می شد.
حذف منبع و عدم ذکر آن لطمه جدی به اعتبار پلت فرم آموزشی فرادرس می زند.
سلام، وقت شما بخیر؛
اگر دقت بفرمائید در انتهای مطلب و بعد از بخش معرفی مطالب و آموزشهای مشابه، منابعی که این مطلب بر اساس آنها تهیه و تنظیم شدهاند ذکر شدهاند.
از اینکه با مجله فرادرس همراه هستید از شما بسیار سپاسگزاریم.
سلام
مشخصه که برای این متن وقت و حوصله به خرج دادین و دلم نیومد بدون تشکر صفحه رو ببندم.
خیلی خوبه، خداقوت
با سلام و احترام
این آموزش، برای شروع کار با موجک بسیار مناسبه.
مثالها به فهم بهتر کمک کرده.
لینکها در جای مناسبشون قرار دارن.
ممنون
خدا قوت
مطالب آموزشی فرادرس واقعا مفید هستند و کامل. اما نبود مرجع بسیار از اعتبار متن کم میکنه.
قطعا تمامی مباحث بالا و امثالهم از انواع مراجع برداشته شده و به زبان فارسی برگردانده شده پس بهتره حتما مراجع ذکر بشه. به نظر من وجود مراجع با کیفیت باعث اصالت متن میشه.
اما وقتی متن بدون مرجع توسط یه دانشجو و یا دانش آموخته نوشته میشه زیاد جالب نیست.
با تشکر
سلام، وقت شما بخیر؛
در انتهای هر یک از مطالب مجله فرادرس، بعد از بخش مطالب مرتبط پیشنهادی، منبع هر نوشتار ذکر شده است؛ علاوه بر این مورد، مطالب مجله فرادرس در هر حوزه، توسط نیروهای متخصص در همان حوزه نگارش میشوند که کاملاً روی مبحث یا مباحث مربوطه تسلط دارند.
از اینکه با مجله فرادرس همراه هستید بسیار سپاسگزاریم.
چند جا اشکال داره از جمله:
همان طور که گفتیم، تبدیل فوریه یک سیگنال یک بعدی، یک اسپکتروگرام دو بعدی خواهد بود که حاوی اطلاعات بیشتری نسبت به سیگنال سری زمانی و یا تبدیل فوریه آن است.
–تبدیل فوریه اول باید تبدیل موجک باشد–
ضرایب تقریب نشاندهنده خروجی فیلتر پایینگذر (فیلتر میانگینگیر) در تبدیل فوریه گسسته هستند.
ضرایب جزئیات نشاندهنده خروجی فیلتر بالاگذر (فیلتر مشتقگیر) در تبدیل فوریه گسسته هستند.
–در تبدیل موجک باید نوشته میشد نه فوریه–
سلام.
اصلاحات لازم اعمال شد.
از همراهی و بازخورد شما سپاسگزاریم.
سلام.
با گرامی داشتن کوشش شما برای گردآوری این نوشته علمی ارزشمند، شایسته است منابع در انتهای مطلب آورده شوند. بهتر بود جملات با شماره گزاری دارای منبع علمی باشند تا قابل استناد شوند.
سپاس