



پیاده سازی رگرسیون لجستیک در پایتون – راهنمای گام به گام
در آموزشهای پیشین مجله فرادرس با رگرسیون لجستیک آشنا شدیم. در این آموزش، به پیاده سازی رگرسیون لجستیک در پایتون میپردازیم.

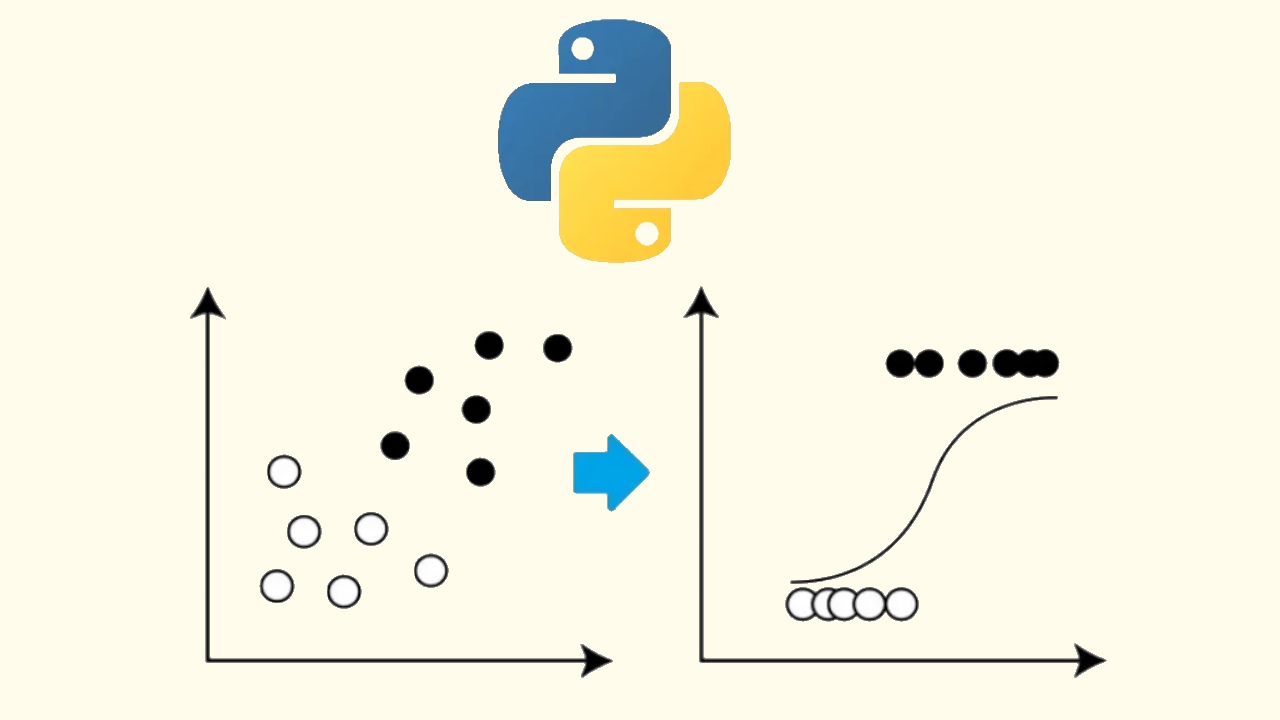


رگرسیون لجستیک چیست؟
مدل رگرسیون لجستیک، یکی از سادهترین مدلها برای طبقهبندی است. در این روش ابتدا ترکیبی خطی از ویژگیهای ورودی ایجاد میشود:
که میتوان این رابطه را به شکل برداری نیز توصیف کرد:
سپس خروجی این ترکیب خطی، وارد «تابع سیگموئید» (Sigmoid Function) یا تابع لجستیک میشود:
به این ترتیب، خروجی مدل عددی بین ۰ و ۱ خواهد بود. با تعیین یک مرز ، دادههایی که مقدار آنها خروجی کمتر از ۰٫۵ باشد، به کلاس ۰ و دادههایی که خروجی آنها بیشتر از ۰٫۵ باشد به کلاس ۱ اختصاص مییابند.
آموزش مدل رگرسیون لجستیک
برای آموزش مدل رگرسیون لجستیک، ابتدا برای مدل یک تابع هزینه به شکل زیر تعریف میکنیم:
برای آموزش این مدل نیز میتوان از الگوریتم گرادیان کاهشی استفاده کرد:
میتوان گرادیان تابع هزینه نسبت به هر پارامتر را محسابه کرده و در رابطه قرار داد که در نهایت منجر به رابطهای مستقیم برای بهروزرسانی وزنها خواهد شد.
برای یادگیری برنامهنویسی با زبان پایتون، پیشنهاد میکنیم به مجموعه آموزشهای مقدماتی تا پیشرفته پایتون فرادرس مراجعه کنید که لینک آن در ادامه آورده شده است.
- برای مشاهده مجموعه آموزشهای برنامه نویسی پایتون (Python) — مقدماتی تا پیشرفته + اینجا کلیک کنید.
پیاده سازی رگرسیون لجستیک در پایتون
برای پیاده سازی رگرسیون لجستیک در پایتون باید چند مرحله را طی کنیم که در ادامه به آنها میپردازیم.
فراخوانی کتابخانهها
ابتدا و در اولین گام از پیاده سازی رگرسیون لجستیک در پایتون کتابخانههای مورد نیاز را فراخوانی میکنیم:
این کتابخانهها به ترتیب برای کار با آرایه، محاسبه معیارهای ارزیابی، رسم نمودار و ایجاد مدلهای خطی استفاده خواهند شد.
حال Seed و Style را تنظیم میکنیم:
تولید داده
در این مرحله نیاز است تا مجموعه دادهای برای آموزش مدل ایجاد کنیم. یک مجموعه داده با ۲ ویژگی ورودی و ۲ دسته، با شرایط زیر ایجاد میکنیم:
برای ایجاد این مجموعه داده، به شکل زیر عمل میکنیم:
متغیر N نشاندهنده اندازه مجموعه داده میشود. سپس ماتریس X با دو ستون به صورت تصادفی تولید میشود.
در نهایت رابطه گفته شده برای تعیین Labelها را اعمال میکنیم.
مصورسازی مجموعه داده تولیدشده
برای بررسی شرایط مجموعه داده، نیاز است تا آن را رسم کنیم. برای این کار به شکل زیر عمل میکنیم:
به این ترتیب، یک Scatter Plot خواهیم داشت که دادههای هر دسته با رنگ مخصوص از باقی دادهها جدا شدهاند.

به این ترتیب، مجموعه داده به درستی ایجاد و نمایش داده میشود.
پیادهسازی مدل
حال باید مدل رگرسیون لجستیک را ایجاد کنیم. برای این کار ابتدا یک تابع تعریف میکنیم که با گرفتن داده ورودی و پارامترها، خروجی مدل را محاسبه کند:
به این ترتیب، ابتدا ترکیب خطی از بردار ورودی محاسبه میشود. سپس تابع سیگموئید اعمال و خروجی مدل حاصل میشود.
حال باید برای وزنها و بایاس، مقداردهی اولیه کنیم:
به این ترتیب، مقادیر اولیه برای پارامترها نیز تعیین میشود.
حال نرخ یادگیری و تعداد مراحل آموزش مدل را تعیین میکنیم:
حال میتوان هسته اصلی مربوط به آموزش مدل را پیادهسازی کرد.
باید به ازای هم مرحله و به ازای هر داده پارامترهای مدل را بهروزرسانی کنیم:
حال باید مقدار گرادیان تابع هزینه نسبت به وزنها را با استفاده از تنها یک داده محاسبه کنیم:
به این ترتیب، رابطه نهایی برای بهروزرسانی وزنها بهدست میآید. توجه داشته باشید که اگر عملیات فوق را برای بایاس نیز تکرار کنیم، به رابطه زیر خواهیم رسید:
حال روابط فوق را در برنامه اعمال میکنیم:
به این ترتیب، بخش مربوط به آموزش مدل نیز کامل میشود. برای بررسی وضعیت مدل در هر مرحله، مقدار تابع هزینه و دقت را نیز محاسبه و نمایش میدهیم.
برای این منظور، تابع هزینه را به شکل زیر پیادهسازی میکنیم:
برای پیادهسازی تابع دقت نیز به شکل زیر عمل میکنیم:
به این ترتیب، از توابع مورد نظر استفاده میشود.
حال توابع را داخل حلقه اصلی برنامه فراخوانی و نتایج را ذخیره میکنیم:
حال برنامه را اجرا میکنیم و نتایج به شکل زیر ظاهر میشود:
Iteration: 0 Cost: 0.19655169133879696 Accuracy: 71.8 % Iteration: 1 Cost: 0.1551691465551683 Accuracy: 83.2 % Iteration: 2 Cost: 0.13276571845816945 Accuracy: 89.0 % ... ... ... Iteration: 9 Cost: 0.08266471377826749 Accuracy: 97.0 % Iteration: 10 Cost: 0.07971907723185878 Accuracy: 96.8 %
به این ترتیب، مشاهده میکنیم که مدل از دقت ٪۷۱ شروع کرده و به دقت ٪۹۷ رسیده است. بنابراین الگوریتم گرادیان کاهشی بهدرستی عمل میکند.
برای مصورسازی آموزش مدل، به شکل زیر دو نمودار برای دقت و تابع هزینه رسم میکنیم (برای نمایش بهتر آموزش مدل، تعداد مراحل آموزش را به ۵۰ افزایش و نرخ یادگیری را به ۰٫۰۰۵ کاهش میدهیم):
که پس از اجرا، نمودارهای زیر حاصل میشود.


به این ترتیب، مشاهده میکنیم که مدل روند آموزش خود را به خوبی طی کرده و بهدرستی آموزش دیده است.
اگر در انتهای برنامه، پارامترها را پرینت کنیم، به نتایج زیر میرسیم:
W = [[ 3.13467116], [-2.30283268]] B = 0.8992552752157723
در ظاهر، نتایج به دست آمده، با پارامترهای اولیه متفاوت است، نکتهای که وجود دارد این است که این اعداد مضربی مشخص از پارامترهای اولیه است. تمامی پارامترها، ۱٫۹۵ برابر پارامترهای انتخابشده است. توجه داشته باشید که ضرب این اعداد در یک عدد مشخص، نتایج را تحت تأثیر قرار نمیدهد. به دلیل همین اتفاق، میتوان از Regularization استفاده کرد.
استفاده از کدهای آماده پایتون
در کتابخانه Scikit-learn نیز امکاناتی برای انجام رگرسیون لجستیک وجود دارد.
میتوان برای ایجاد و آموزش این مدل، به شکل زیر عمل کرد:
در نهایت، برای بررسی دقت خواهیم داشت:
پس از اجرا، دقت ٪۹۸٫۴ حاصل میشود که عددی بسیار نزدیک به الگوریتم پیادهسازیشده است.
برای بررسیهای بیشتر در رابطه با نتایج مدل، میتوان معیارهای بیشتری را بررسی کرد:
که خواهیم داشت:
Classification Report: precision recall f1-score support 0.0 1.00 0.95 0.98 176 1.0 0.98 1.00 0.99 324 accuracy 0.98 500 macro avg 0.99 0.98 0.98 500 weighted avg 0.98 0.98 0.98 500
به این ترتیب، عملکرد مناسب الگوریتم مشخص میشود.
توجه داشته باشید که مجموعه داده نامتعادل است و در صورتی که به دقت مناسب در کلاسهای مختلف نرسیم، میتوانیم از روشهای وزندهی به دستهها و یا تغییر مجموعه داده استفاده کرد.
برای استخراج پارامترهای مدل ایجادشده در Scikit-learn نیز میتوانیم به شکل زیر عمل کنیم:
که خواهیم داشت:
W: [[ 6.09624843 -4.51185994]] B: [1.72291912]
این پارامترهای نیز ۳٫۸ برابر مقادیر انتخاب شده هستند.
با تغییر مدل به شکل زیر:
پارامترها به ۱٫۵۴ برابر مقادیر اصلی میرسند:
W: [[ 2.47052748 -1.77922621]] B: [0.89601296]
بنابراین، تعیین Regularization با C کوچکتر، الگوریتم را به انتخاب وزنهای با اندازه کوچکتر سوق میدهد.
به این ترتیب، اهمیت Regularization نیز در تنظیم مدل کاملاً مشهود است.

جمعبندی
در این مطلب با پیادهسازی رگرسیون لجستیک در پایتون آشنا شدیم و با ایجاد یک مجموعه داده مصنوعی، آن را پیادهسازی کرده و روی مجموعه داده آموزش دادیم. در نهایت نیز توابع آماده را بررسی کردیم.

برای مطالعه بیشتر میتوان موارد زیر را بررسی کرد:
- تغییر کد پیادهسازی شده، برای آموزش مدل با توجه به وزن دستهها
- تغییر کد پیادهسازی شده، برای آموزش مدل Regularized
- استفاده از نرخ یادگیری پویا در طول آموزش مدل
- بررسی چگونگی محاسبه میزان اطمینان مدل از خروجی
- بررسی ارتباط خروجی مدل رگرسیون لجستیک با احتمال اختصاص داده به هر کلاس
- بررسی چگونگی طبقهبندی مجموعه دادهای با بیش از ۲ کلاس با استفاده از رگرسیون لجستیک









