



فایل robots.txt چیست؟ – از کاربرد تا نحوه ساخت به زبان ساده
کارشناسان سئو و مدیران وبسایتها بهخوبی میدانند فایل robots.txt چیست و چه اهمیتی در بهبود سئوی وبسایت دارد. فقط کاربران نیستند که وبسایت شما را میبینند و رباتهای جستجو هم برای بررسی، خزش و نمایهگذاری وبسایت به صفحات مختلف آن سر میزنند. فایل robots.txt یک فایل متنی کوچک با چند دستور ساده برای خزش وبسایت است. رباتها از طریق فایل robots.txt میفهمند کدام صفحات و بخشهای وبسایت را باید خزش کنند و به کدام بخشها باید بیتوجه باشند. در واقع با کمک فایل robots.txt دسترسی رباتهای جستجو را به صفحات وبسایت محدود و کنترل میکنیم. صفحات و پوشههای زیادی در وبسایت وجود دارند که نیازی نیست رباتها آنها را خزش کنند. ازجمله این صفحات میتوان به صفحه مربوط به مدیر وبسایت و ویرایشگر محتوا یا نسخههای آزمایشی صفحات وب اشاره کرد که انتشار آنها قطعی نیست. با اضافه کردن فایل robots.txt به وبسایت، نحوه خزش صفحات وب را کنترل و رباتهای جستجو را به طرف صفحات و فایلهای مهمتر وبسایت هدایت میکنیم.
- یاد میگیرید ساختار و دستورات اصلی فایل «robots.txt» را تنظیم کنید.
- میآموزید چگونه «robots.txt» را برای مدیریت رفتار رباتهای جستجو به کار ببرید.
- خواهید آموخت نقش «Allow» ،«Disallow» و «User-Agent» را بهدرستی تشخیص دهید.
- یاد خواهید گرفت که تفاوت «robots.txt» و متا تگ «noindex» چیست.
- نحوه تست، بارگذاری و ویرایش فایل «robots.txt» را یاد میگیرید.
- نکات امنیتی و مقابله با اشتباهات رایج در استفاده از «robots.txt» را میآموزید.




ساخت فایل robots.txt برای وبسایت یکی از اصول پایه در بهبود سئوی تکنیکال وبسایت است، بههمین دلیل در این مطلب از مجله فرادرس ضمن پاسخ به سوال فایل robots.txt چیست، کاربردها و دستورات مختلف موجود در آن میپردازیم. در گام بعدی، با روش ساخت فایل robots.txt، اضافه کردن آن به وبسایت و تست عملکرد آن آشنا میشویم. در پایان هم چند نکته مهم و حرفهای را برای ساخت بهتر فایل ربات یاد میگیریم.
فایل robots.txt چیست؟
فایل robots.txt فایل متنی کوچکی در وبسایت است که چند دستورالعمل ساده برای کنترل دسترسی رباتهای جستجو به صفحات وبسایت در آن وجود دارد. بهعبارت بهتر، با دو فرمان ساده Allow و Disallow در فایل robots.txt، دسترسی رباتها و خزندههایی را که برای خزش و بررسی صفحات و فایلهای وبسایت وارد آن میشوند، مجاز یا محدود می کنیم.
برای اینکه درک درستی از فایل robots.txt و دستورات موجود در آن پیدا کنید، در تصویر زیر، نمونه بسیار کوچک و سادهای از آن را آوردهایم:
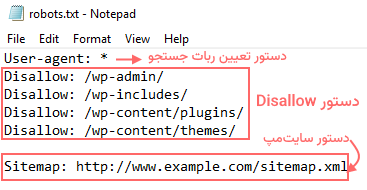
همانطور که در تصویر بالا میبینید، اولین خط از فایل robots.txt به دستور User-agent مربوط میشود که نشان میدهد خزندههای متعلق به کدام موتور جستجو (گوگل، بینگ و ...) باید از دستوری که در سطر بعدی آمده پیروی کنند. در نمونه بالا، از علامت «*» در مقابل این عبارت استفاده شده که یعنی همه رباتها باید از آن پیروی کنند.
برای درک بهتر این موضوع، میتوانید ویدیوی آموزشی مرتبط با فایل Robots.txt را مشاهده کنید:
در خطهای بعدی این فایل، «دستورالعملهای رد کردن» (Disallow Directives) دسترسی ربات به صفحات مدیریت و ویرایش وبسایت دیده میشود و در خط پایانی آن هم آدرس سایتمپ درج شده تا رباتهای جستجو در ادامه مسیر خزش برای پیدا کردن صفحات مهم به آن مراجعه کنند.

چرا وبسایت به فایل robots.txt نیاز دارد؟
در پاسخ به سوال فایل robots.txt چیست به این نکته اشاره کردیم که اصلیترین کاربرد و استفاده این فایل در وبسایت آن است که به کمک آن میتوانیم دسترسی خزش یا عدم خزش رباتهای جستجو را در بخشهای مختلف وبسایت مجاز یا محدود کنیم. بهطور کلی کاربردهای فایل robots.txt را میتوان در موارد فهرست زیر خلاصه کرد:
- محدود یا مجاز کردن دسترسی رباتها به بخشها یا صفحات مختلف وبسایت
- بهینهسازی «بودجه خزش» (Crawl Budget) با محدود کردن دسترسی رباتها به صفحات کمارزش (مانند صفحات ورود، تشکر، سبد خرید و ...)
- جلوگیری از خزش و نمایهگذاری فایلهای pdf و تصاویر توسط ربات جستجو
- نمایش محل قرار گرفتن «نقشه سایت» (Sitemap)
تا این بخش از مطلب میدانید فایل robots.txt چیست و چه کاربردهایی دارد. در ادامه این مطلب، بیشتر در مورد کاربردهای فایل robots.txt میخوانید و نحوه ساخت فایل و استفاده از دستورهای مختلف آن را یاد میگیرید. در اولین قدم، در بخش بعدی توضیح دادهایم چطور باید فایل robots.txt وبسایتهای مختلف را ببینید.
فایل robots چگونه کار می کند؟
برای اینکه نحوه کار فایل robots.txt را بهتر درک کنید، بهتر است مرور کوتاهی بر نحوه کار موتورهای جستجو داشته باشیم. هر موتور جستجو برای اینکه بتواند نتایج مرتبط را در صفحه نتایج به کاربر نشان دهد، دو کار اصلی انجام میدهد:
- «خزش» (Crawling) سطح وب برای پیدا کردن محتوا
- «نمایهگذاری» (Indexing) محتوا و اضافه کردن آن به پایگاهداده موتور جستجو با هدف نمایش در نتایج جستجوی مرتبط
فرایند بالا توسط «رباتها» یا «خزندهها» (Crawler) انجام میشود که با دنبال کردن لینکهای موجود در صفحات وارد وبسایتهای مختلف میشوند تا اطلاعات موجود در آنها را خزش کنند. دقیقا در همین مرحله است که فایل robots.txt وارد میدان میشود. اولین کاری که خزندهها پس از ورود به وبسایت قبل از شروع هر کار دیگری انجام میدهند، این است که به دنبال فایل robots.txt میگردند تا از طریق آن دستورالعملهای خزش صفحات را بخوانند.

اگر وبسایت فایل robots.txt نداشته باشد یا رباتها نتوانند به هر دلیلی آن را پیدا کنند، تصمیم میگیرند تمام صفحات وبسایت را خزش کنند. اگر هر وبسایت را یک شهر جدید و رباتهای جستجو را خودروهای ورودی به آن در نظر بگیریم، فایل robots.txt دفترچه راهنمای کوچکی است که برای گردش در آن شهر به آن نیاز است.

تا این بخش بهخوبی میدانید فایل robots.txt چیست و چرا وبسایت به آن نیاز دارد. در ادامه، یاد میگیرید چطور فایل robots.txt وبسایتهای مختلف را ببینید.
فایل robots.txt در وبسایت کجاست؟
احتمالا با توضیحاتی که در بخش قبلی دادهایم، کنجکاو شدهاید فایل robot.txt وبسایت خودتان یا دیگران را ببینید. برای این کار، پیوند یکتای کامل صفحه اصلی وبسایت خودتان یا هر وبسایت دیگری را در نوار جستجوی مرورگر وارد و در انتهای آن عبارت /robots.txt را وارد کنید.
برای مثال، در تصویر زیر همین کار را برای دیدن فایل robots.txt وبسایت «فرادرس» انجام دادیم:
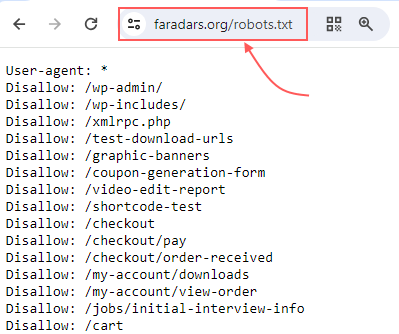
با این روش میتوانید فایل robots.txt وبسایتهای مختلف را در مرورگر ببینید. همچنین حالا که بحث محل قرارگیری فایل robots.txt است، همینجا لازم است به این نکته اشاره کنیم که این فایل در «دایرکتوری اصلی» (Root Directory) قرار میگیرد و برای دسترسی به آن باید وارد حساب کاربری هاست وبسایت شوید و از قسمت مدیریت، فایل robots.txt را پیدا و دستورالعملهای موردنظرتان را در آن وارد یا ویرایش کنید.
آیا حتما باید برای وبسایت فایل robots.txt بسازیم؟
اضافه کردن فایل robots.txt به وبسایت نقش مهمی در بهبود سئوی وبسایت دارد، چون با کمک آن به ربات جستجو نشان میدهید چطور باید صفحات وبسایت را خزش کنند. با این کار، هم بار کاری روی سرور وبسایت بهدلیل مراجعه زیاد رباتهای جستجو زیاد نمیشود و هم زمان محدود رباتهای جستجو صرف خزش صفحات غیرمهم، کمارزش یا داخلی وبسایت نمیشود. با وجود این مزایا، چون اضافه کردن فایل robots.txt به وبسایت اثر مستقیمی روی رتبه سئوی وبسایت ندارد، احتمالا بپرسید آیا حتما باید این فایل را برای وبسایت بسازیم؟
برای اینکه بفهمید وبسایت شما واقعا به فایل robots.txt نیاز دارد یا نه، از «گزارش Indexing» سرچ کنسول گوگل بخش «Pages» کمک بگیرید. در این گزارش، میتوانید تعداد صفحات نمایهگذاریشده و نمایهگذارینشده سایت را ببینید. در تصویر زیر، نمایی از این گزارش را میبینید:
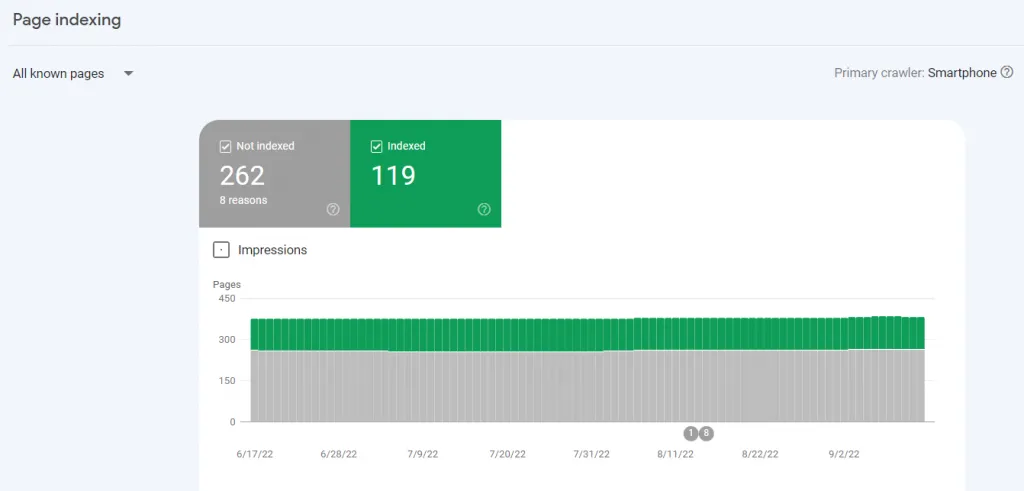
به اعداد این گزارش در وبسایت خودتان دقت کنید. اگر تعداد صفحات نمایهگذاریشده گزارش با تعداد صفحاتی که قرار بوده گوگل آنها را نمایهگذاری کند، برابر است، احتمالا به فایل robots.txt نیازی ندارید. در غیر این صورت تعداد صفحات وبسایت شما آنقدر زیاد شده که لازم باشد با استفاده از فایل robots.txt دسترسی رباتهای جستجو را به آنها محدود یا مجاز کنید.
تا اینجا بهخوبی یاد گرفتهاید کاربرد و اهمیت فایل robots.txt چیست. در ادامه انواع دستورات این فایل را بررسی میکنیم.
معرفی دستورات robots txt
فایل robots.txt با استفاده از دستورات مشخصی که در آن قرار میدهیم، رباتهای جستجو را به خزش یا عدم خزش صفحات هدایت میکند. بهطورکلی در فایل robots.txt شش دستور وجود دارند.
در جدول زیر خیلی کوتاه به نام و نقش آنها اشاره کردهایم:
| نام دستور | وظیفه دستور |
| دستور User-Agent | برای مشخص کردن ربات جستجو |
| دستور Disallow | برای مشخص کردن بخشها و صفحات غیرمجاز برای ربات |
| دستور Allow | برای مشخص کردن بخشها و صفحات مجاز برای ربات |
| دستور Sitemap | برای نمایش آدرس فایل سایتمپ |
| دستور Crawl-Delay | برای دستور نمایهگذاری با تأخیر صفحات وب |
| دستور Noindex | دستور عدم نمایش صفحه وب در SERP |
در بخش بعدی توضیح میدهیم کاربرد و محل استفاده هریک از دستورهای بالا در فایل robots.txt چیست.
۱. دستور User-Agent برای تعیین ربات جستجو
هر گروه دستوری در فایل robots.txt با دستور User-Agent آغاز و تا دستور User-Agent بعدی ادامه پیدا میکند. با دستور User-Agent مشخص میکنیم کدامیک از انواع رباتهای جستجو باید از دستوری که در سطر بعدی آمده، پیروی کنند. برای مثال، اگر بخواهیم به «ربات جستجوی گوگل» (Googlebot) دستور بدهیم صفحه مدیریت وردپرس را خزش نکند، باید دستور را به شکل زیر بنویسیم:
User-agent: Googlebot Disallow: /wp-admin/
دستور User-Agent بر اساس ربات هدف، به دو شکل در فایل robots.txt نوشته میشود:
- در حالت اول، نوع ربات را بهطور دقیق مشخص میکنیم. برای مثال در نمونه بالا، همه رباتهای موتور جستجوی گوگل از دستور Disallow که بعد از آن آمده، پیروی میکنند.
- در حالت دوم، بهجای مشخص کردن نوع ربات، از علامت «*» استفاده میکنیم که بهمعنی آن است که همه رباتها باید از دستوری که در ادامه آمده، پیروی کنند. مانند آنچه در نمونه زیر میبینید:
User-agent: * Disallow: /wp-admin/
اهمیت استفاده درست از این دستور زمانی بیشتر مشخص میشود که بدانیم گوگل و دیگر موتورهای جستجو از انواع مختلف رباتهای خزنده برای خزش و نمایهگذاری عادی صفحات، خزش تصاویر، ویدیوها و ... استفاده میکنند. بنابراین مشخص کردن نوع ربات جستجو در دستور User-Agent در زمان زیاد بودن دستورهای فایل robots.txt، کمک میکند رباتها بتوانند بلوک دستوری ویژهای را که دقیقا برای آنها نوشته شده، دنبال کنند.
ازجمله رباتهای مختلف گوگل میتوان به ربات Googlebot Image، ربات Googlebot Video و ربات Googlebot News اشاره کرد.
۲. دستور Disallow برای تعیین بخشهای غیرمجاز
دستور مهم بعدی در فایل robots.txt، دستور Disallow نام دارد که به کمک آن مشخص میکنید دقیقا خزش کدام فایلها یا بخشهایی از وبسایت برای رباتهای جستجو غیرمجاز و ممنوع است. وقتی از این دستور استفاده میکنید، ربات جستجو متوجه میشود کدام بخشهای از وبسایت را نباید بررسی کند. در نمونه زیر، به رباتهای جستجو دستور دادهایم صفحه مدیریت وردپرس وبسایت را خزش نکنند:
User-agent: * Disallow: /wp-admin/
هر فایل robots.txt میتواند چند دستور Disallow مجزا از هم داشته باشد که هرکدام به بخشهای مختلفی از وبسایت اشاره میکنند. نکته مهم در مورد این دستور آن است که در صورت مشخص نکردن مقصد دستور در مقابل آن و خالی گذاشتن خط دستور Disallow، هیچ ممنوعیتی برای وبسایت تعیین نکردهاید و ربات جستجو هم به آن توجهی نمیکند. بهعبارت بهتر، ربات جستجو اینطور برداشت میکند که شما بررسی هیچ فایلی را در وبسایت برای او ممنوع نکردهاید. مانند آنچه در نمونه زیر میبینید:
User-agent: * Disallow: /
این نکته مهم را هم بدانید که علامت «/» در دستورهای فایل robots.txt به معنای پوشه یا فایل است. بر همین اساس در توضیحی دقیقتر، دستور زیر به همه رباتهای جستجو میگوید اجازه ندارند وارد پوشه دایرکتوری مدیریت وردپرس شوند:
User-agent: * Disallow: /wp-admin/
بنابراین اگر بخواهیم دسترسی همه رباتهای جستجو را به همه پوشههای داخل وبسایت مسدود کنیم، میتوانیم از گروه دستوری زیر استفاده کنیم:
User-agent: * Disallow: /
نکته مهم: در فهرست زیر، به دو نکته مهم در استفاده از این دستور اشاره کردهایم:
- دو دستور Disallow و Allow در فایل robots.txt به کوچک یا بزرگ بودن حروف حساس نیستند، اما مقادیری که برای هرکدام پس از علامت «:» قرار میدهید، به این موضوع حساس هستند. برای مثال، ربات جستجو دو پوشه /photo/ و /Photo/ را مجزا از هم در نظر میگیرد.
- با وجود حساس نبودن نام دو این دو دستور، بهتر است در فایل robots.txt سطر مربوط به آنها را با حروف بزرگ شروع کنید تا خواندن فایل برای شما آسانتر باشد.
تا اینحا میدانید دو دستور اصلی فایل robots.txt چیست و هرکدام چه کاربردی دارند. در ادامه، در مورد دستورات بعدی این فایل میخوانید.
۳. کاربرد دستور Allow برای تعیین بخشهای مجاز در فایل robots.txt چیست ؟
دستور مهم بعدی در فایل robots.txt، دستور Allow است که تا زمان نگارش این مطلب، رباتهای جستجوی «Bingbot» و «Googlebot» مفهوم آن را درک میکنند. با کمک این دستور به موتورهای جستجو اطلاع میدهید پوشه یا دایرکتوری فرعی خاصی را با وجود مسدود بودن پوشه یا دایرکتوری اصلی، خزش کند. برای مثال، در نمونه زیر دسترسی ربات گوگل به پستهای وبلاگ را مسدود کردهایم ولی در سطر بعدی آن، از او خواستهایم بلاگپست مشخصی را خزش کند:
User-agent: Googlebot Disallow: /blog Allow: /blog/example-post
با استفاده از دستور بالا، ربات گوگل با اینکه نمیتواند به پستهای وبلاگ دسترسی داشته باشد، به بلاگپست خاصی که آدرس آن را برای او مشخص کردهایم، دسترسی دارد و آن را مورد بررسی قرار میدهد.
۴. دستور Sitemap برای نشان دادن آدرس فایل سایت مپ
دستور بسیار مهم بعدی در فایل robots.txt، دستور Sitemap است که وظیفه دارد آدرس سایتمپ را به رباتهای جستجویی که برای بررسی وبسایت آمدهاند، بدهد. سایتمپ فایل متنی شامل صفحات مهم وبسایت است که لازم میدانید بهطور کامل خزش و نمایهگذاری شوند. دستور سایتمپ در بالاترین یا پایینتر بخش فایل robots.txt قرار میگیرد. در تصویر زیر، سایتمپ وبسایت رسمی «فرادرس» را آوردهایم که دستور Sitemap بههمراه آدرس دقیق این فایل در آن مشخص شده است:
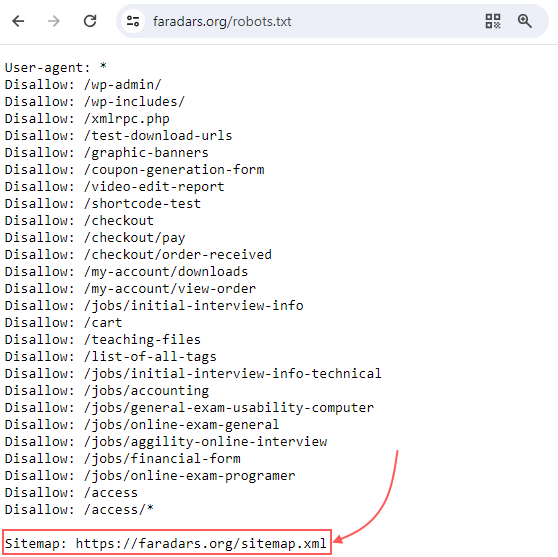
اضافه کردن دستور sitemap به فایل robots.txt روش سریع و قابلاعتمادی برای نشان دادن نقشه سایت به رباتهای جستجو است اما این نکته را فراموش نکنید که همچنان اصلیترین روش نشان دادن سایتمپ به موتورهای جستجو، ثبت آن در ابزارهای مدیریت وبسایت مانند سرچ کنسول گوگل است. این کار از طریق «گزارش Indexing»، بخش «Sitemaps» و گزینه «Add a new sitemap» قابلانجام است:
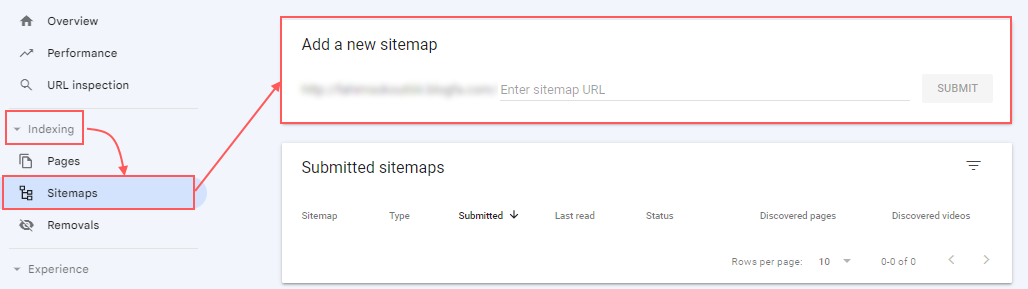
موتورهای جستجو در نهایت صفحات وبسایت شما را خزش میکنند، اما ارائه نقشه سایت به آنها، فرایند خزش صفحات مهم را سرعت میدهد. پس حتما این مرحله را انجام دهید.
تا اینجا بهخوبی میدانید اصلیترین دستورهای فایل robots.txt چیست و چطور باید از آنها استفاده کرد. در ادامه، در مورد دو دستور جدید دیگر میخوانید.
۵. دستور Crawl-Delay برای نمایه گذاری با تأخیر ربات جستجو
دستور دیگری که ممکن است در فایل robots.txt ببینید، دستور Crawl-Delay نام دارد که به خزندههای جستجو دستور میدهد درخواستهای خزش صفحات را با تأخیر برای سرور ارسال کنند. در اصطلاح سئو، به تعداد درخواستهایی که رباتهای گوگل در هر ثانیه برای خزش وبسایت برای سرور ارسال میکنند، «نرخ خزش» (Crawl Rate) گفته میشود. هدف از استفاده از این دستور، کاهش بار کاری سرور و جلوگیری از کند شدن وبسایت است.
البته موتور جستجوی گوگل دیگر از دستور Crawl-Delay پیروی نمیکند و برای تعیین نرخ خزش برای رباتهای آن، باید از طریق سرچ کنسول اقدام کنید. در عوض موتور جستجوی بینگ همچنان از این دستور پیروی میکند. در نمونه زیر، به رباتهای موتور جستجو دستور دادیم بین هربار عمل خزش، ۱۰ ثانیه صبر کند:
User-agent: * Crawl-delay: 10
۶. دستور Noindex برای حذف صفحه از نتایج جستجو
دستور آخر و قدیمی فایل robots.txt که گوگل هیچوقت پیروی از آن را رسما تایید نکرد، دستور noindex نام دارد که استفاده از آن ظاهرا نمایهگذاری صفحه و نمایش آن را در نتایج جستجو مسدود میکند. همانطور که در بخش ابتدایی مطلب در توضیح ارتباط بین تگ noindex و فایل robots.txt گفتیم، فایل ربات قرار است به رباتهای جستجو در مورد فرایند خزش بخشهای مختلف وبسایت دستورالعمل بدهد اما نمیتواند به موتورهای جستجو بگوید کدام پیوندهای یکتا را باید نمایه گذاری کرده و در SERP به کاربران نمایش دهند.
زمانی که از این دستور در فایل robots.txt استفاده میکنیم، صفحه وب در SERP متفاوت با سایر نتایج و معمولا بدون توضیح متا به کاربران نمایش داده میشود. مانند آنچه در تصویر زیر میبینید:
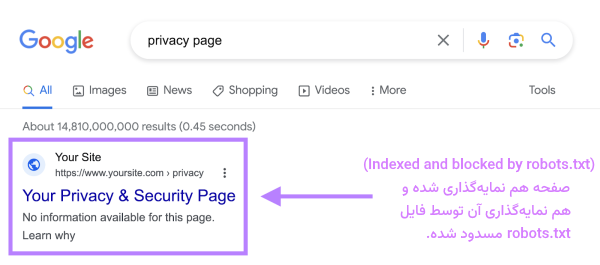
این اتفاق باعث میشود یکی از خطاهای سرچ کنسول در «گزارش Indexing» رخ دهد که باید برای برطرف کردن آن، تعیین کنید که واقعا نیازی به نمایهگذاری صفحه وب بوده یا خیر. جالب است بدانید گوگل با اینکه هیچوقت پیروی از این دستور را در فایل robots.txt تایید نکرده بود، در ابتدای سپتامبر سال ۲۰۱۹ اعلام کرد که رباتهای جستجوی او از این دستور پیروی نمیکنند.
نتیجه مهم: اگر قرار است صفحه وبی را به هر دلیلی از فهرست نمایهگذاری گوگل خارج کنید، این دستور را همزمان با تگ نو ایندکس استفاده نکنید. همانطور که در بخش ابتدایی مطلب هم گفتیم، در چنین مواردی بهتر است خزش صفحه را در فایل robots.txt محدود نکنید و با تگ noindex به موتورهای جستجو در این مورد اطلاعرسانی کنید.
تا این بخش بهخوبی میدانید دستورات مهم در فایل robots.txt چیست و هرکدام چه کاربردی دارند. در ادامه، توضیح میدهیم چطور برای وبسایت فایل robots.txt بسازید و آن را به هاست وبسایت اضافه کنید.
آموزش ساخت و تست فایل روبات برای سایت
ساخت فایل robots.txt هم بهصورت دستی و هم با ابزارهای robots.txt generator «+» امکانپذیر است. در فهرست زیر، مراحل انجام این کار را بهصورت دستی آوردهایم:
- ساخت و نامگذاری فایل txt
- اضافه کردن دستورات به فایل robots.txt
- بارگذاری فایل در وبسایت
- تست و بررسی عملکرد درست فایل robots.txt
در ادامه، توضیح میدهیم نکات اصلی در ساخت فایل robots.txt چیست و چطور باید آن را به وبسایت اضافه و تست کرد.
۱. ساخت و نام گذاری فایل با فرمت txt
فرمت فایل ربات، txt است بههمین دلیل برای ساخت آن میتوانید از هر ویرایشگر متنی با خروجی txt کمک بگیرید. در سادهترین حالت، با کلیک راست روی تصویر پسزمینه ویندوز، گزینه text document را بزنید تا محیط ویرایشگر متن Notepad برای شما باز شود. در ادامه مسیر، فایل را با نام robots.txt ذخیره کنید و آن را باز نگه دارید تا در مرحله بعدی دستورهای لازم را به آن اضافه کنید.
نکته مهم: قبل از اینکه فراموش کنید، همان ابتدای کار، از منوی File و گزینه Save as، انکودینگ فایل را روی UTF-8 تنظیم کنید. در همان منوی گزینه UTM-8 BOM هم وجود دارد که توصیه میشود آن را انتخاب نکنید.
۲. نوشتن فایل robots txt
همانطور که در بخشهای قبلی گفتیم، فایل robots.txt از یک یا چند گروه دستوری ساخته میشود که هر گروه شامل چند دستورالعمل مشخص و واضح برای رباتهای جستجو است. در اینجا و در فهرست زیر، نحوه قرار گرفتن این دستورها را مرور میکنیم. هر گروه دستوری با دستور User-Agent آغاز میشود و اطلاعات زیر در آن قرار میگیرد:
- ربات هدف گروه دستوری
- فایلها، دایرکتوریها یا صفحاتی که ربات هدف میتواند به آنها دسترسی داشته باشد (بعد از دستور Allow )
- فایلها، دایرکتوریها یا صفحاتی که ربات هدف نمیتواند به آنها دسترسی داشته باشد (بعد از دستور Disallow )
- آدرس فایل سایتمپ برای نشان دادن صفحات و فایلهای مهم وبسایت به ربات جستجو (این مورد الزامی نیست)
رباتهای جستجو اطلاعات سطرهایی را که با این دستورها هماهنگی نداشته باشند، نادیده میگیرند و از آنها رد میشوند.
برای مثال، فرض کنید نمیخواهید گوگل دایرکتوری /clients/ را در وبسایت خزش کند، چون از فایلهای داخلی وبسایت است. با در نظر گرفتن نکاتی که تا اینجا در مورد دستورات فایل robots.txt گفتیم، این گروه دستوری به شکل زیر درمیآید:
User-agent: Googlebot Disallow: /clients/ Disallow: /images/
هر دستور دیگری را هم میتوانید به سطر بعدی دستور بالا اضافه کنید. برای مثال، ما در سطر سوم دستور عدم خزش فایل /images/ وبسایت را وارد کردیم. زمانی که دستورات مربوط به دسترسی یا عدم دسترسی گروه خاصی از رباتها تمام شد، دو بار روی «Enter» بزنید تا گروه دستوری بعدی را شروع کنید.
در نمونه زیر همین کار را برای تمام رباتهای جستجو انجام دادیم و دستور عدم دسترسی آنها را به دایرکتوریهای /archive/ و /support/ وارد کردیم، چون این دو پوشه هم برای استفاده داخلی وبسایت هستند و نیازی به بررسی آنها توسط رباتهای جستجو نیست:
User-agent: Googlebot Disallow: /clients/ Disallow: /images/ User-agent: * Disallow: /archive/ Disallow: /support/
بعد از اینکه دستورهای موردنظرتان را با توجه به نکات گفتهشده اضافه کردید، دستور sitemap و آدرس آن را اضافه کنید. در نهایت باید نمونه زیر نوشته باشید:
User-agent: Googlebot Disallow: /clients/ Disallow: /images/ User-agent: * Disallow: /archive/ Disallow: /support/ Sitemap: https://www.yourwebsite.com/sitemap.xml
فایل robots.txt را با انکودینگ UTF-8 ذخیره کنید. فراموش نکنید که نام فایل به حروف کوچک و بزرگ حساس است و حتما باید بهصورت robots.txt آن را ذخیره کنید نه Robots.txt یا robots.TXT یا هر نام دیگری.
نکته مهم: احتمالا این سوال برایتان پیش آمده که دستورها را با چه ترتیبی باید در فایل robots.txt وارد کنیم. در پاسخ به این سوال باید گفت چون رباتهای جستجو خواندن فایل را از ابتدای آن شروع میکنند و اولین گروه دستوری را که خطاب به آنها باشد انتخاب میکنند، بهتر است فایل robots.txt را اول با دستورهای User-Agent ویژهتر شروع کنید و در ادامه به سراغ دستورهای User-Agent کلیتر که علامت «*» دارند و مخاطب آنها همه رباتهای جستجو هستند، بروید.
در ادامه یاد میگیرید روش اضافه کردن فایل robots.txt در سایت چیست و چطور باید از درست بودن دستورات آن مطمئن شد.
۳. بارگذاری فایل robots txt در وبسایت
بعد از ساخت robots.txt باید آن را در وبسایت بارگذاری کنید. نکته مهم در مورد اضافه کردن فایل robots.txt به وبسایت آن است که حتما باید آن را به «دایرکتوری اصلیِ» (Main Directory) «دامنه اصلی» (Root Directory) وبسایت اضافه کنید، چون رباتهای جستجو در زمان ورود به وبسایت فقط در همین محل به دنبال این فایل میگردند. بنابراین نتیجه میگیریم آدرس فایل robots.txt در وبسایت باید بهصورت زیر باشد:
www.example.com/robots.txt
اگر رباتها به وبسایت شما وارد شوند و فایل را پیدا نکنند، با این تصور که وبسایت شما فایل robots.txt ندارد، تمام پوشهها و صفحات وبسایت را خزش میکنند. بنابراین دقت کنید که آدرس فایل robots.txt به شکلهای زیر نباشد:
www.example.com/index/robots.txt
www.example.com/homepage/robots.txt
بارگذاری دستی این فایل در وبسایتها با سیستمهای مدیریت محتوای مختلف متفاوت است، اما بهطور کلی با ورود به حساب کاربری هاست وبسایت و بخش مدیریت، باید آن را بهطور مستقیم در دایرکتوری اصلی وبسایت اضافه کنید.
نکته مهم: اگر از افزونه یواست سئو روی وبسایت استفاده میکنید، میتوانید از طریق آن خیلی راحت فایل robots.txt وبسایت را بسازید و آن را در دایرکتوری اصلی آن اضافه کنید. برای اینکار در داشبورد وبسایت، روی Yoast SEO در منوی مدیر بزنید و از بین ابزارها، گزینه File Editor را انتخاب کنید:
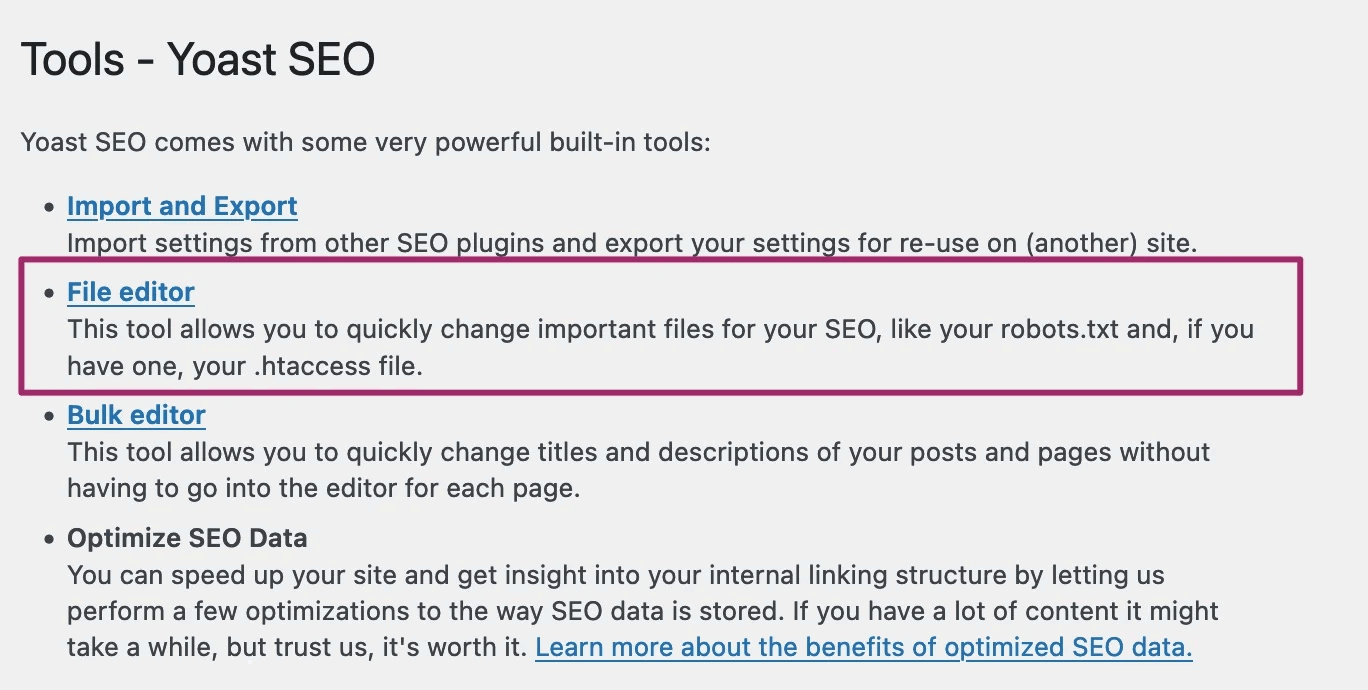
در صفحه جدیدی که باز میشود روی «Create robots.txt file» بزنید:
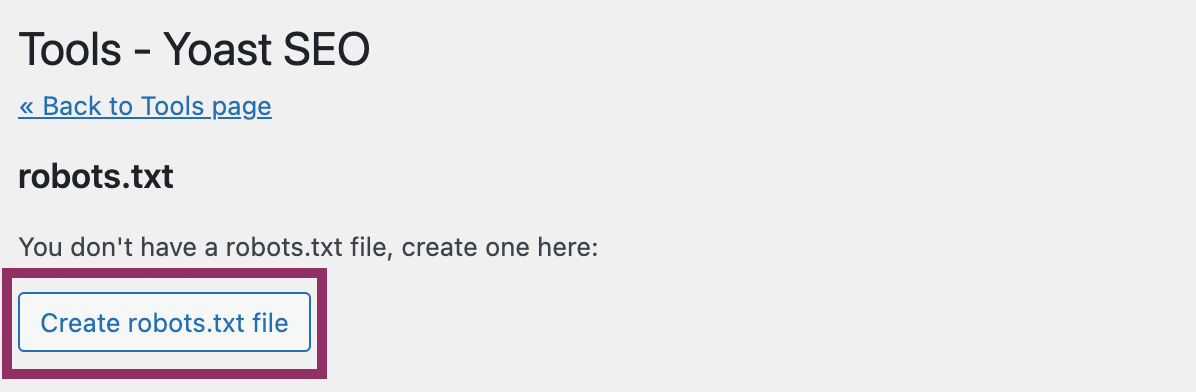
در ویرایشگری که باز میشود، دستورات را وارد کرده و درنهایت ذخیره را بزنید:
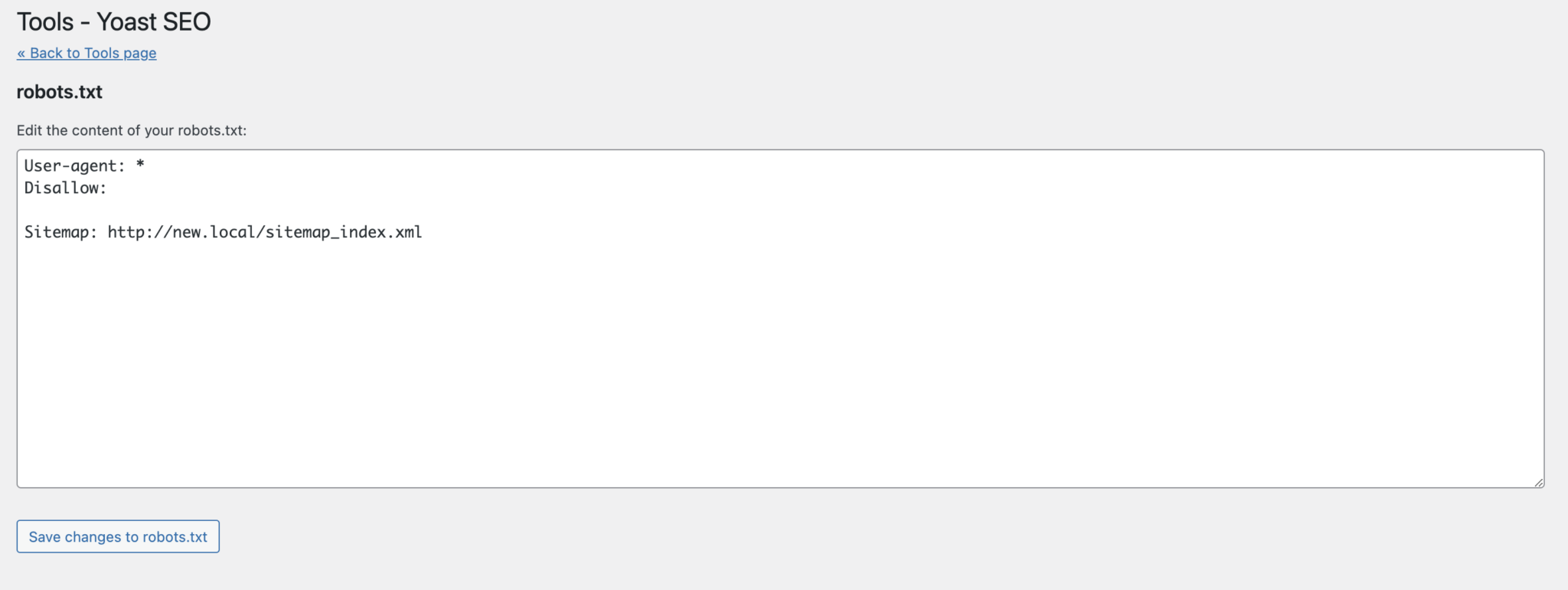
همچنین در مطلب زیر بهطور مفصل در مورد افزونه یواست سئو و قابلیتهای مختلف آن بحث کردهایم:
۴. روش تست فایل robots.txt در سرچ کنسول چیست؟
بعد از ساخت و بارگذاری فایل robots.txt لازم است آن را بهطور دقیق از نظر وجود خطا و پیکربندی درست بررسی کنید. این مرحله بسیار مهم است چون وجود حتی یک اشتباه کوچک در این فایل، ممکن است به قیمت خارج شدن کل وبسایت شما از فهرست گوگل تمام شود.
خوشبختانه خود گوگل ابزار بسیار خوبی برای تست فایل robots.txt ایجاد کرده که البته قبل از استفاده از آنها باید مطمئن شوید که فایل robots.txt وبسایت شما بهطور کامل در دسترس همه قرار گرفته است. برای اطمینان از این موضوع، یک پنجره ناشناس (Incognito) در مرورگر باز کنید و آدرس فایل robots.txt وبسایت را در آن وارد کنید. اگر فایل بهراحتی در دسترس شما قرار گرفت، به سراغ بررسی آن بروید.
گوگل برای انجام این کار، دو روش را توصیه میکند:
- استفاده از ابزار robots.txt Tester موجود در سرچ کنسول گوگل
- استفاده از کتابخانه منبعباز robots.txt گوگل (در سطح پیشرفته)
از آنجا که روش دوم بیشتر برای توسعهدهندگان وب حرفهای کاربر دارد، در ادامه نحوه استفاده از روش اول را توضیح میدهیم. نکته مهم برای استفاده از این ابزار آن است که باید حتما حساب کاربری سرچ کنسول را فعال کرده باشید.
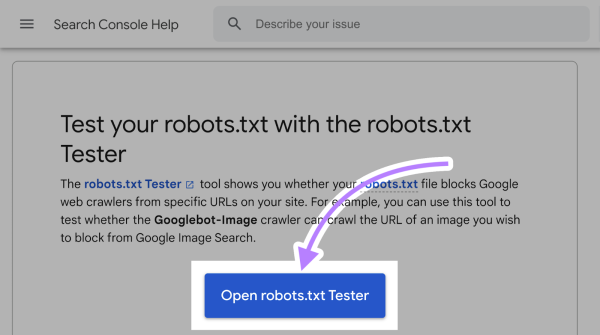
برای شروع، وارد صفحه ابزار robots.txt Tester «+» شوید و روی گزینه «Open robots.txt Tester» کلیک کنید. مانند آنچه در تصویر زیر میبینید:
اگر سرچ کنسول را به وبسایت متصل نکرده باشید، صفحه زیر برای شما باز میشود که ابتدا باید به آن property را اضافه کنید. مانند آنچه در تصویر زیر میبینید:
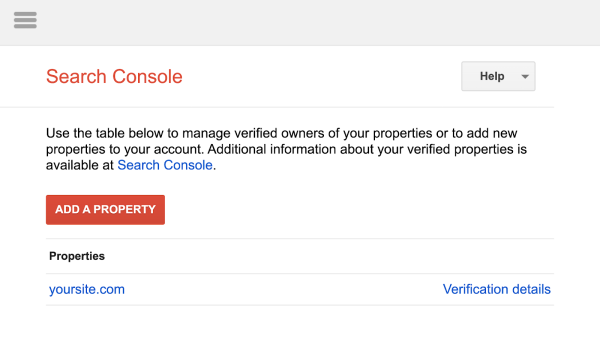
روی دکمه قرمز رنگ بالا کلیک و مالکیت وبسایت را اثبات کنید.
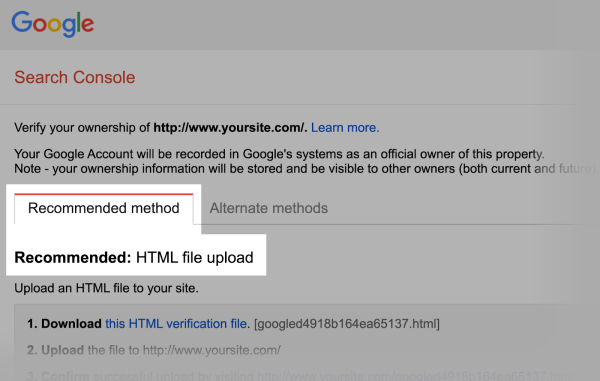
نکته مهم: گوگل تصمیم دارد این شیوه نصب و پیکربندی را تغییر دهد پس ممکن است در آینده لازم باشد property را بهطور مستقیم در سرچ کنسول ثبت کنید. در مطلب زیر از مجله فرادرس بهطور مفصل در مورد روشهای انجام این کار بحث کردهایم:
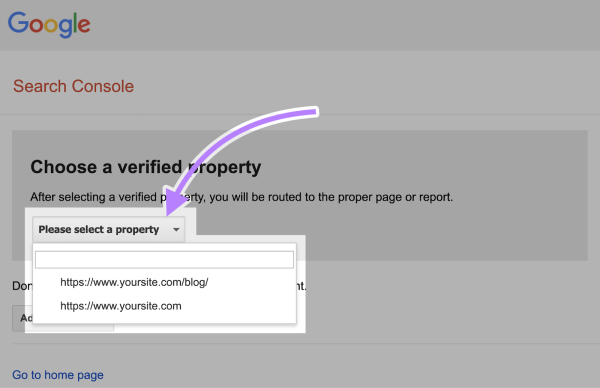
اگر از قبل مالکیت وبسایت را در سرچ کنسول ثبت کرده باشید، از منوی مخصوص به آن، property موردنظرتان را انتخاب کنید. مانند آنچه در تصویر زیر میبینید:
در ادامه مسیر، صفحهای به شکل زیر برای شما باز میشود که ابزار در آن خطاهای دستوری یا منطقی فایل robots.txt را با تعداد خطاها و هشدارها مشخص کرده است:
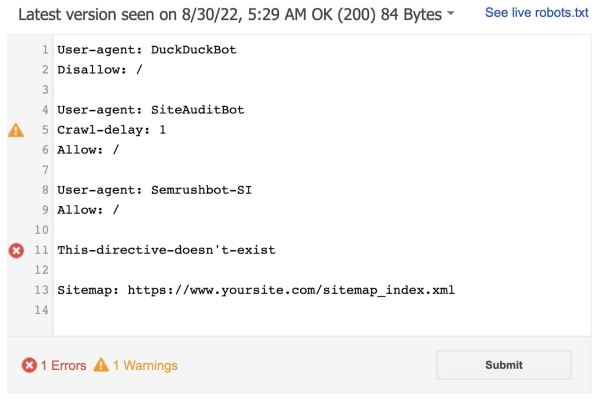
در این صفحه میتوانید بهطور مستقیم خطاها و هشدارهای فایل را برطرف و آن را دوباره با ابزار تست کنید. البته به این نکته مهم هم توجه داشته باشید که ویرایش فایل robots.txt در اینجا بهمعنی ویرایش فایل اصلی در وبسایت نیست. بنابراین بعد از اینکه از درست بودن همه خطوط فایل مطمئن شدید، متن آن را کپی و در فایل اصلی در وبسایت جایگزین کنید.
نکات کلیدی در ساخت فایل robots.txt
اگر تا این بخش مطلب را بهخوبی مطالعه کرده باشید، میدانید نحوه ساخت و تست فایل robots.txt چیست و چطور میتوان از درست بودن تمام بخشهای آن مطمئن شد. در فهرست زیر به چند نکته مهم در ساخت این فایل اشاره کردهایم:
- هر دستور را در یک سطر جدید وارد کنید.
- دستورهای مربوط به هر User-Agent را در یک گروه دستوری وارد کنید.
- برای دقیق مشخص کردن دستورها از علامت «*» استفاده کنید.
- از علامت «$» برای مشخص کردن انتهای پیوند یکتا استفاده کنید.
- از علامت هشتگ «#» برای اضافه کردن نظر به فایل robots.txt استفاده کنید.
- برای هر دامنه فرعی از یک فایل robots.txt مجزا استفاده کنید.
- آدرس همه سایت مپ های متعلق به دامنه را در فایل robots.txt اضافه کنید.
در ادامه یاد میگیرید اهمیت انجام هریک از نکات بالا در نوشتن فایل robots.txt چیست.
۱. ایجاد سطر جدید برای هر دستور
در فایل robots.txt برای هر دستور جدید باید یک سطر جداگانه و جدید ایجاد کنید. در غیر این صورت، چون رباتهای جستجو نمیتوانند دستورات را بخوانند، آنها را نادیده میگیرند و در عمل انگار هیچ دستوری برای آنها ثبت نکردهاید. در زیر نمونه دستور اشتباه را در فایل robots.txt آوردهایم:
User-agent: * Disallow: /admin/ Disallow: /directory/
همانطور که احتمالا شما هم حدس میزنید، نمونه درست دستورات بالا به شکل زیر است:
User-agent: * Disallow: /admin/ Disallow: /directory/
۲. وارد کردن دستورات مربوط به هر User-Agent در یک گروه دستوری
در بخش معرفی دستورات مهم در فایل robots.txt به این نکته اشاره کردیم که در ابتدای هر گروه دستوری، از دستور User-Agent برای مشخص کردن ربات هدف دستور استفاده میکنیم. نکته مهم در استفاده از دستور User-Agent این است که بهتر است دستورات مربوط به هر ربات جستجو را در یک گروه دستوری در کنار هم در فایل بنویسیم. البته رعایت این نکته الزامی نیست، اما از گیج شدن رباتهای جستجو جلوگیری میکند و فایل را ساده و مرتب نگه میدارد. برای مثال نمونه زیر، ممکن است ربات گوگل را سردرگم کند:
User-agent: Googlebot Disallow: /example-page User-agent: Googlebot Disallow: /example-page-2
کدهای بالا را بهتر است بهصورت زیر بنویسیم:
User-agent: Googlebot Disallow: /example-page Disallow: /example-page-2
البته گوگل دستور قبلی را هم دنبال کرده و خزش دو صفحه مشخصشده در دستور را انجام نمیدهد اما نوشتن همه دستورات متعلق به یک User-Agent فقط با یک بار ذکر نام آن، خواندن فایل را برای رباتها آسانتر میکند.
۳. استفاده از علامت * برای توضیح بهتر دستورات
در بخشهای قبلی به این نکته اشاره کردیم که با استفاده از علامت «*» در مقابل User-Agent ، به همه رباتهای جستجویی که فایل را میبینند، دستور میدهیم که از دستور موردنظر که در ادامه میآید پیروی کنند. کاربرد علامت «*» فقط به دستور User-Agent محدود نیست و میتوانید از آن برای محدود کردن دسترسی ربات جستجو به URL-های دارای پارامتر هم استفاده کنید. برای درک بهتر این موضوع، به مثال زیر توجه کنید.
فرض کنید در یک فروشگاه اینترنتی قرار است دسترسی همه رباتهای جستجو را به دستهبندی /shoes/ از برندهای مختلف مسدود کنید. برای این کار باید دستورات فایل robots.txt را به شکل زیر بنویسید:
User-agent: * Disallow: /shoes/vans? Disallow: /shoes/nike? Disallow: /shoes/adidas?
دستورات بالا را با استفاده از علامت «*» میتوان به شکل موثرتر و بهتری نوشت. در زیر، نمونه بهتر آن را میبینید:
User-agent: * Disallow: /shoes/*?
دستور بالا، دسترسی خزش همه رباتهای جستجویی را که برای بررسی همه پیوندهای یکتای پوشههای فرعی دستهبندی /shoes/ آمدهاند، در کنار یک علامت سوال مسدود میکند.
۴. استفاده از علامت $ برای مشخص کردن انتهای URL
اضافه کردن علامت «$» به انتهای آدرس پیوند یکتا به ربات جستجو میگوید اقدام مشخصی را برای همه آدرسهایی که با دنباله مشخصی به پایان میرسند، انجام دهد. در مثال زیر، مفهوم این موضوع را بهتر درک میکنید.
اگر قرار باشد دسترسی خزش همه رباتهای جستجو را به تمام فایلهای .jpg داخل وبسایت مسدود کنیم، چارهای نداریم جز اینکه دستور مربوط به هرکدام را بهصورت جداگانه در سطرهای مختلف بنویسیم. مانند آنچه در نمونه زیر میبینید:
User-agent: * Disallow: /photo-a.jpg Disallow: /photo-b.jpg Disallow: /photo-c.jpg
این شیوه نگارش دستورات در فایل robots.txt اثربخشی لازم را ندارد، بههمین دلیل با استفاده از علامت «$» میتوانیم آن را بهشکل موثرتری بنویسیم:
User-agent: * Disallow: /*.jpg$
دستور بالا، تمام آدرسهایی را که با عبارت .jpg به پایان میرسند، مسدود میکند. برای مثال، از خزش آدرس /dog.jpg جلوگیری میشود ولی آدرس /dog.jpg?p=32414 چون با jpg. تمام نشده، همچنان توسط رباتها خزش میشود. عبارت «$» در شرایطی مثل نمونه بالا کاربردهای زیادی دارد، اما اگر بهدرستی از آن استفاده نکنید ممکن است مشکلات زیادی در فایل robots.txt شما ایجاد کند.
۵. استفاده از علامت هشتگ برای افزودن یادداشت به فایل robots.txt
رباتهای جستجو از هر چیزی که با علامت هشتگ در فایل robots.txt شروع شود، بیتوجه رد میشوند. بههمین دلیل توسعهدهندگان اغلب از هشتگ برای اضافه کردن یادداشت به فایل robots.txt استفاده میکنند. یادداشتها معمولا فایل را دستهبندی کرده و خواندن آن را برای رباتها آسانتر میکنند.
برای اضافه کردن یادداشت به فایل robots.txt فقط کافیست در ابتدای سطر مربوط، از علامت هشتگ استفاده کنید. مانند آنچه در نمونه زیر میبینید:
User-agent: * #Landing Pages Disallow: /landing/ Disallow: /lp/ #Files Disallow: /files/ Disallow: /private-files/ #Websites Allow: /website/* Disallow: /website/search/*
گاهی اوقات توسعهدهندگان وب از پیامهای طنز یا مخصوص در فایل robots.txt استفاده میکنند، چون میدانند تقریبا هیچکس آنها را نمیبیند. برای مثال، فایل robots.txt وبسایت رسمی «فرادرس» را در نمونه زیر ببینید که یادداشت عبارت «Faradars» و جملهای در مورد استخدام شدن در این سازمان به آن اضافه شده است:

۶. استفاده از فایل robots.txt مجزا برای هر دامنه فرعی
هر دامنه فرعی در دامنه اصلی از فایل robots.txt جداگانه مخصوص به خود برای دستور دادن به رباتهای جستجو استفاده میکند. به عبارت بهتر، برای کنترل خزش هر دامنه فرعی، باید از یک فایل robots.txt جداگانه استفاده کنید. بنابراین اگر وبسایت شما روی آدرس زیر فعال است:
example.com
لازم است فایل robots.txt زیر را برای آن بسازید:
example.com/robots.txt
همچنین اگر وبسایت شما هر دامنه فرعی دیگری مثل دامنه وبلاگی به آدرس زیر دارد:
blog.example.com
باید یک فایل robots.txt جداگانه هم مانند نمونه زیر برای آن ایجاد کنید:
blog.example/robots.txt
یکی از این فایلها متعلق به دایرکتوری اصلی دامنه و دیگری متعلق به دایرکتوری اصلی دامنه فرعی (برای مثال وبلاگ) است.
۷. اضافه کردن آدرس همه سایت مپ های متعلق به دامنه در فایل robots.txt
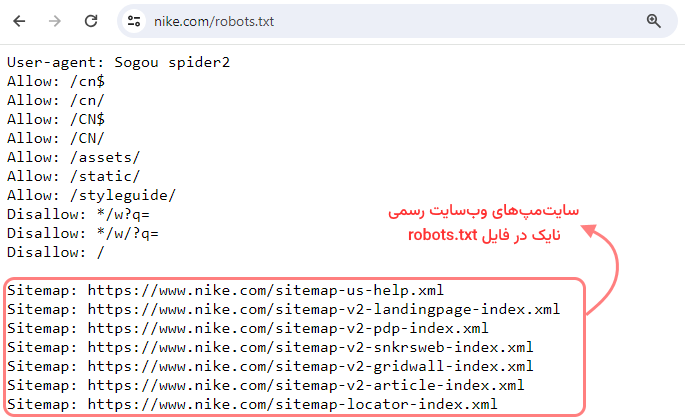
نکته مهم و آخری که باید در بحث فایلهای robots.txt باید مطرح کرد، به اضافه کردن سایتمپ در این فایل مربوط است. متخصصان سئو توصیه میکنند که همه سایتمپهای مرتبط با دامنه را در بخش انتهایی سایتمپ اضافه کنید. در تصویر زیر، بخش پایانی فایل robots.txt وبسایت رسمی برند نایک را میبینید که آدرس تمام سایتمپها در آن ذکر شده است:
آیا با فایل robots.txt می توان صفحات را از نتایج جستجو خارج کرد؟
سوال دیگری که در رابطه با فایل robots.txt مطرح میشود، این است که آیا با کمک آن میتوان صفحات وب را از نتایج جستجو حذف کرد؟ برای پاسخ درست به این سوال باید به کاربرد متا تگ noindex اشاره کنیم. تگ نوایندکس یکی از متا تگهای robots است که با اضافه کردن آن به کد اصلی صفحاتی که توسط رباتها خزش شدهاند، به رباتهای جستجو اطلاع میدهیم آن را در صفحه نتایج به کاربران نمایش ندهند. اگر صفحه وب از قبل نمایهگذاری شده باشد، با افزودن تگ نوایندکس، میتوان آن را از صفحه نتایج حذف کرد.
در پاسخ به سوال فایل robots.txt چیست گفتیم این فایل مجموعهای از دستورالعملها را در مورد خزش یا عدم خزش صفحات وبسایت در اختیار رباتهای جستجو قرار میدهد و نمیتواند جلوی نمایش آنها را در صفحه نتایج بگیرد. از این دو تعریف به نتیجه مهم زیر میرسیم:
- اگر قرار باشد صفحه وب به هر دلیلی توسط ربات جستجو خزش شود، ولی در صفحه نتایج به کاربران نمایش داده نشود، باید از تگ نوایندکس در کد اصلی آن استفاده کنید (مراقب باشید که دسترسی خزش آن را در فایل robots.txt روی دستور Disallow تنظیم نکرده باشید.) در حالت دوم، اگر نیاز است بهطور کلی صفحه یا دایرکتوری موردنظر شما اصلا توسط رباتهای جستجو بررسی نشود، آن را به فایل robots.txt اضافه کنید و دستور Disallow را روی آن لحاظ کنید.
نکته مهم: تگ نوایندکس کاربرد زیادی در خارج کردن فایلهای pdf و تصاویر وبسایت از صفحه نتایج ندارد و برای این دسته از فایلها بهتر است همچنان از فایل robots.txt استفاده کنید.
فایل robots.txt چطور به سئو کمک میکند؟
اگر تا این بخش از مطلب را بهخوبی مطالعه کرده باشید، میدانید فایل robots.txt چیست و چطور ساخته و استفاده میشود. استفاده کردن از فایل robots.txt شاید ضمانتی برای قرار گرفتن وبسایت در رتبههای بالای صفحه نتایج نباشد ولی از جهات مختلفی به سئوی وبسایت کمک میکند، چون فقط کاربران نیستند که از وبسایت شما استفاده میکنند و باید وبسایت را برای رباتهای جستجو هم بهخوبی بهینه کنید تا دسترسی آسانتر و سریعتری به بخشهای مهم وبسایت داشته باشند.
در فهرست زیر به ۴ دلیل بهبود سئو به کمک فایل robots.txt اشاره کردهایم:
- استفاده حداکثری بودجه خزش
- مسدود کردن صفحات تکراری و غیرعمومی
- کمک به نمایه گذاری نشدن منابع (فایلهای pdf، تصاویر و ...)
- امکان تنظیم دستورالعمل خزش برای انواع مختلف رباتهای جستجو

در ادامه، هریک از موارد بالا را بررسی میکنیم.
اهمیت فایل robots.txt در استفاده حداکثری از بودجه خزش چیست؟
در بخشهای قبلی به این نکته اشاره کردیم که اصلیترین کاربرد و اهمیت اضافه کردن فایل robots.txt در وبسایت، جلوگیری از مصرف بیدلیل «بودجه خزش» (Crawl Budget) است. اما بودجه خزش چیست و فایل robots.txt دقیقا چطور به مصرف درست آن کمک میکند؟
وبسایتهای زیادی در سطح وب وجود دارند که با فعالیت بیشتر بهطور دائم تعداد صفحات خود را افزایش میدهند. واضح است که تعداد زیادی از این صفحات توسط رباتهای خزش شوند. از طرف دیگر، بسیاری از این وبسایتها نمیتوانند ورود دائم رباتهای جستجو و کاربران را بهطور همزمان مدیریت کنند. برای حل این دو چالش، موتورهای جستجو از معیاری به نام بودجه خزش استفاده میکنند.


به زبان ساده، بودجه خزش سهمیهای است که رباتهای جستجو بر اساس نوع وبسایت و میزان اعتبار آن در فضای وب به آن اختصاص میدهند. هدف از تعیین بودجه خزش، اولویتبندی موارد نیازمند به خزش، زمان خزش و کیفیت خزش است. در تعریفی کوتاه بودجه خزش بهمعنی تعداد صفحاتی است که رباتهای جستجو در یک بازه زمانی مشخص در وبسایت خزش و نمایهگذاری میکنند. دو فاکتور مهم وجود دارند که بر بودجه خزش تأثیرگذار هستند:
- «محدودیت نرخ خزش» (Crawl rate limit): محدودیتی که روی رفتار رباتهای جستجو اعمال میشود تا با درخواستهای مکرر سرور وبسایت را بیشازحد مشغول نکند.
- «تقاضای خزش» (Crawl demand): محبوبیت و جدید بودن محتوا که تعیین میکند وبسایت به خزش بیشتر نیاز دارد یا کمتر.
از آنجا که رباتهای گوگل بهطور نامحدود صفحات وبسایت شما را خزش نمیکنند، با اضافه کردن فایل robots.txt به وبسایت، از خزش صفحاتی اضافه و غیرضروری جلوگیری کرده و رباتها را به طرف صفحات مهم وبسایت که لازم است هرچه زودتر به فهرست و در نهایت نتایج جستجو اضافه شوند، هدایت میکنید. این کار در مصرف بودجه خزش صرفهجویی میکند و دیگر نیازی نیست نه شما و نه گوگل نگران صرف زمان رباتها برای بازدید از صفحات نامرتبط و غیرضروری باشید.
مسدود کردن صفحات تکراری و غیرعمومی
صفحات بسیاری در وبسایت وجود دارند که نیازی نیست توسط موتورهای جستجو خزش و نمایهگذاری شده و در نهایت به کاربران نمایش داده شوند. برای مثال ممکن است نسخه آزمایشی از یکی از صفحات وبسایت ساخته باشید یا صفحات ورود مشخصی داشته باشید. این موارد صفحات داخلی وبسایت هستند و باید وجود داشته باشند اما در عین حال نمیخواهید کاربران اتفاقی در معرض دید کاربران قرار بگیرند.
با کمک فایل robots.txt این صفحات را برای رباتهای جستجو مسدود میکنید. این کار هم به مصرف درست بودجه خزش کمک میکند و هم رباتها را به صفحات مهمتر وبسایت میفرستد.
امکان تنظیم دستورالعمل خزش برای انواع مختلف رباتهای جستجو
هر موتور جستجو از انواع مختلفی از رباتها برای خزش صفحات مختلف وبسایت استفاده میکند. در بخش معرفی دستور User-Agent به نام چند مورد از انواع رباتهای گوگل اشاره کردیم. خوبی استفاده از فایل robots.txt این است که با کمک آن میتوانید بهطور دقیق ورود به فایلها و صفحاتی را که نمیخواهید در نتایج جستجو نمایش داده شوند، برای رباتهای مخصوص به هرکدام مسدود کنید.
برای مثال، اگر نمیخواهید تصاویر وبسایت در نتایج جستجوهای تصویری گوگل به کاربران نمایش داده شوند، میتوانید دستور آن را بهطور دقیق روی Imagebots گوگل و فایل تصاویر تنظیم کنید.
کمک به نمایه گذاری نشدن منابع
در بخشهای قبلی به این نکته اشاره کردیم که در حال حاضر روش اصلی جلوگیری از نمایهگذاری صفحات وبسایت یا خارج کردن آنها از فهرست گوگل، استفاده از تگ Noindex در بخش <head> کد اصلی این صفحات است و فایل robots.txt نمیتواند بهطور از نمایهگذاری صفحات جلوگیری کند. با این وجود، متا تگ نوایندکس هنوز کاربرد زیادی در نمایهگذاری نشدن منابع چندرسانهای مانند فایلهای pdf و تصاویر ندارد و برای خزش و نمایهگذاری نشدن آنها همچنان بهتر است از فایل robots.txt استفاده کنید.
جمعبندی
در این آموزش از مجله فرادرس ضمن پاسخ دادن به سوال فایل robots.txt چیست در مورد کاربردها، دستورات، نحوه ساخت و مزایای استفاده از این فایل در بهبود سئوی وبسایت بحث کردیم. در فهرست زیر چند نکته کلیدی و مهم را که باید در زمان ساخت فایل robots.txt به آنها توجه کنید، بیان کردهایم:
- برای اینکه رباتهای جستجو بتوانند فایل robots.txt وبسایت را پیدا کنند، حتما آن را در دایرکتوری اصلی وبسایت بارگذاری کنید.
- فایل robots.txt را حتما بههمین صورت نامگذاری و با انکودینگ UTF-8 نامگذاری کنید.
- برای هر دامنه فرعی از یک فایل robots.txt مجزا استفاده کنید.
- از آنجا که فایل robots.txt برای همه قابلدیدن است، از آن برای پنهان کردن اطلاعات خصوصی کاربر استفاده نکنید.
سوالات متداول
در بخشهای قبلی این مطلب در مورد فایل robots.txt، کاربردها و روش ساخت و بارگذاری آن در وبسایت بحث کردیم. در ادامه به چند سوال متداول در همین خصوص پاسخ میدهیم.
کاربرد علامت * در فایل robots.txt چیست؟
علامت «*» دو کاربرد اصلی در فایل robots.txt دارد. کاربرد اول آن، این است که بعد از قرار گرفتن در دستور User-Agent، دستوراتی را که در سطر بعدی آمده، برای همه رباتهای جستجو الزامی میکند. همچنین میتوانید از این علامت برای محدود کردن دسترسی ربات جستجو به URL-های دارای پارامتر استفاده کنید.
ترتیب وارد کردن دستورات در فایل robots txt چگونه است؟
رباتهای جستجو خواندن دستورات فایل robots txt را از ابتدای آن شروع میکنند و اولین بلوک دستوری را که خطاب به آنها باشد، انتخاب میکنند. بههمین دلیل بهتر است فایل robots.txt را اول با دستورهای User-Agent که گروه خاصی از رباتهای جستجو را خطاب قرار میدهند، شروع کنید و در ادامه به سراغ دستورهای کلیتر بروید.









