روش های مدیریت داده های گمشده در یادگیری ماشین – به زبان ساده
بیشتر دادههای جمعآوری شده در جهان حقیقی، بهطور مستقیم قابل استفاده نبوده و ابتدا باید پردازش شوند. از همین جهت، رسیدگی به «دادههای گمشده» (Missing data)، بهویژه هنگام کار با دیتاستهای بزرگ، نوعی رویکرد رایج و طبیعی است. اطلاعات ناقص، عدم تمایل به اشتراکگذاری، طراحی نامناسب نظرسنجیها یا حذف بخشی از دادهها، چند نمونه از دلایل متعدد گمشدگی دادهها هستند. مشکلی که اگر بهدرستی مدیریت نشود، نتایج حاصل از تجزیه و تحلیلها را تحت تاثیر قرار داده و به تصمیمات نادرستی منجر میشود. بهطور معمول از دو رویکرد حذف و جایگزینی برای مدیریت دادههای گمشده استفاده میشود. در این مطلب از مجله فرادرس، تمرکز ما بر معرفی برخی از روش های مدیریت داده های گمشده در یادگیری ماشین و سپس پیادهسازی آنها با استفاده از زبان برنامهنویسی پایتون میباشد. همچنین مزایا و معایب هر روش را نیز شرح میدهیم تا راحتتر بتوانید تکنیک مناسب را برای مسئله خود انتخاب کنید.
- میآموزید که دادههای گمشده را در پروژههای واقعی شناسایی کنید.
- فرق انواع دادههای گمشده مانند MCAR ،MAR و MNAR را خواهید آموخت.
- روشهای حذف و جایگزینی دادههای گمشده را بهطور عملی اجرا میکنید.
- دستورات کلیدی پانداس مانند «dropna» و «fillna» را در مثالهای واقعی بهکار میگیرید.
- میآموزید به شیوهای شفاف و منظم فرآیند مدیریت دادههای گمشده را مستندسازی کنید.
- خواهید توانست از نتایج تحلیل دادههای گمشده برای تصمیمگیری در مدلسازی بهره ببرید.




در این مطلب، ابتدا یاد میگیریم منظور از دادههای گمشده چیست و با نحوه شناسایی این دست از دادهها آشنا میشویم. سپس و در ادامه، به شرح روش های مدیریت داده های گمشده میپردازیم. در انتهای این مطلب از مجله فرادرس، از الگوهای پیشنهادی برای مدیریت دادههای گمشده میگوییم و به تعدادی از سوالات متداول در این حوزه پاسخ میدهیم.
منظور از داده های گمشده چیست؟
مشکل «مقادیر گمشده» یا «دادههای گمشده» (Missing Values | Missing Data)، زمانی رخ میدهد که دادههای برخی از ویژگی یا متغیرها بهدرستی ذخیره نشده باشند. دادهها به اصطلاح زمانی گم میشوند که اطلاعات ورودی ناقص باشد، سیستم جمعآوری با خطا روبهرو شود و یا تعدادی از فایلها گمشده باشند.
بهطور معمول، هر دیتاستی با مشکل دادههای گمشده مواجه بوده و تنها کافی است نگاهی ساده به جداول مجموعهداده بیندازیم تا متوجه جای خالی دادههای گمشده شویم.
شناسایی داده های گمشده
دادههای گمشده فرمتهای مختلفی دارند. پیش از توصیف روش های مدیریت داده های گمشده، در این بخش به توضیح انواع مختلف و همچنین روش های شناسایی این قبیل دادهها میپردازیم.

انواع داده های گمشده
دادههای گمشده به سه دسته کلی زیر تقسیم میشوند:
- «دادههای گمشده بهطور کامل تصادفی» (Missing Completely at Random | MCAR)
- «دادههای گمشده بهصورت تصادفی» (Missing at Random | MAR)
- «دادههای بهطور تصادفی گمنشده» (Missing Not at Random | MNAR)

انتخاب روش مناسب برای مدیریت دادههای گمشده، نیازمند بهدست آوردن درک کافی از انواع روشهای عنوان شده در فهرست بالا است. در ادامه این بخش، شرح دقیقتری از هر سه روش ارائه میدهیم.
۱. داده های گمشده به طور کامل تصادفی یا MCAR
زمانی اتفاق میافتد که احتمال گمشدگی همه متغیرها و نمونههای مشاهده شده یکسان باشد. فرض کنید مجموعهای از «لِگوهای» (LEGO) رنگارنگ را در اختیار کودکی قرار دادهاید. هر لگو بیانگر بخشی از اطلاعات مانند شکل و رنگ است. هنگام بازی، ممکن است کودک تعدادی از قطعهها را گم کند. لگوهای گمشده نشاندهنده اطلاعات از دست رفته هستند و دیگر شکل یا رنگ آنها از یاد میرود. اطلاعاتی که بهطور تصادفی گمشده، اما تاثیری در دانش کودک نسبت به سایر قطعهها نمیگذارند.
۲. داده های گمشده به صورت تصادفی یا MAR
در این نوع از دادهها یا به اصطلاح MAR، احتمال مقدار گمشده نسبت مستقیمی با مقدار متغیر یا سایر متغیرهای موجود در دیتاست دارد. به این معنی که، شانس گم شدن همه نمونهها و همچنین متغیرها با یکدیگر متفاوت است. یک مثال رایج از روش MAR، نظرسنجی در جامعه علم داده است که بر اساس آن، پژوهشگرانی که همگام با پیشرفت تکنولوژی حرکت نکرده و مهارتهای خود را بهروزرسانی نمیکنند، از پاسخ دادن به برخی از پرسشها باز میمانند. در این مورد مشخص، گمشدگی دادهها با سرعت مهارتآموزی دانشمندان علم داده نسبت مستقیم دارد.
۳. داده های به طور تصادفی گم نشده یا MNAR
این حالت یا به اختصار MNAR، شرایط دشوارتری نسبت به دو مورد قبلی دارد. در حقیقت، دادههایی در این گروه قرار میگیرند که نه از نوع MAR و نه MCAR هستند. نوع خاصی که در آن، احتمال گمشدگی برای مقادیر مختلف یک متغیر بهطور کامل متفاوت است؛ در حالی که شاید حتی از علت چنین رخدادی مطلع نباشیم. یک مثال از MNAR، نوعی نظرسنجی درباره زوجهای متاهل است. زوجهایی که رابطه خوبی با یکدیگر ندارند، ممکن است بهخاطر حس شرمساری، تمایلی به پاسخ دادن برخی از پرسشها نداشته باشند.
روش های شناسایی داده های گمشده
روشهای مختلفی برای شناسایی دادههای گمشده با استفاده از کتابخانه Pandas در زبان برنامهنویسی پایتون وجود دارد. در جدول زیر، به توضیح چند نمونه از توابع مناسب این کار پرداختهایم:
| تابع | توصیف |
| isnull() | خروجی از نوع «دیتافریم» (Dataframe) و مقدار بولی متناظر با دادهها یعنی True (درست) یا False (نادرست). |
| notnull() | اگر مقادیری همچون NaN یا None شناسایی شوند، خروجی برابر با مقدار بولی False خواهد بود. |
| info() | ایجاد جدولی شامل ستون Non-Null Count، که نشانگر تعداد مقادیر گمنشده به ازای هر ستون است. |
| isna() | این تابع تنها زمانی مقدار True یا درست را خروجی میدهد که داده گمشده از نوع Nan باشد. |
برای آشنایی کامل با نحوه مدیریت دادههای گمشده در داده کاوی، با استفاده از زبان برنامهنویسی پایتون، مطالعه مطلب زیر را از مجله فرادرس به شما پیشنهاد میکنیم:
چگونه روش های برخورد با داده های گمشده را یاد بگیریم؟

اگر تا اینجا همراه این مطلب از مجله فرادرس بوده باشید، بهخوبی میدانید که موضوع ما، یعنی روش های مدیریت داده های گمشده در یادگیری ماشین و بهطور کلی دادههای گمشده، تنها بخشی از فرایند آمادهسازی و پردازش دادهها برای کاربردهای پیچیدهتری همچون داده کاوی و ساخت مدلهای یادگیری ماشین هستند. به همین خاطر، برای توسعه مهارتهای لازم و همچنین پیدا کردن شغل مورد نظر خود در این حوزه، نیاز دارید تا علاوهبر آشنایی با ابزارهای پیادهسازی مطرح مانند زبان برنامهنویسی پایتون و کتابخانههای مرتبط، از شاخصهایی مانند میانگین، «واریانس» (Variance) و «انحراف معیار» (Standard Deviation) اطلاعات کسب کنید و نحوه رسم انواع نمودارهای آماری را نیز یاد بگیرید.
در نتیجه، اگر به این مبحث علاقهمند هستید و میخواهید بهطور اصولی و کاربردی روش های برخورد با داده های گمشده را یاد بگیرید، میتوانید از فیلمهای آموزشی فرادرس که در همین رابطه تهیه شدهاند استفاده کنید. مشاهده این فیلمهای آمورشی را به ترتیبی که در ادامه آورده شده است به شما پیشنهاد میدهیم:
- فیلم آموزش مفاهیم آماری در داده کاوی و پیاده سازی آن در پایتون فرادرس
- فیلم آموزش تجزیه و تحلیل و آماده سازی داده ها با پایتون فرادرس
روش های مدیریت داده های گمشده چیست؟
حالا که با انواع و روشهای شناسایی دادههای گمشده آشنا شدیم، در این قسمت، به بررسی تعدادی از روش های مدیریت داده های گمشده همراه با ذکر مزایا و معایب هر کدام میپردازیم. برای درک بهتر و پیادهسازی قدم به قدم این فرایند، از مجموعهداده «ریزش مشتری» (Customer Churn) که در وبسایت Kaggle موجود است و همچنین زبان برنامهنویسی پایتون بهره میبریم. از آنجا که این دیتاست هیچ داده گمشدهای ندارد، ابتدا مانند قطعه کد نمونه، زیرمجموعهای متشکل از ۱۰۰ سطر را جدا کرده و سپس بهصورت دستی، دادههای گمشدهای را به مجموعهداده اضافه میکنیم:
خروجی مانند تصویر زیر است:
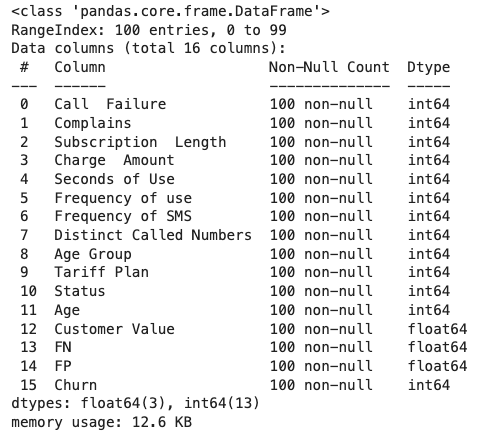
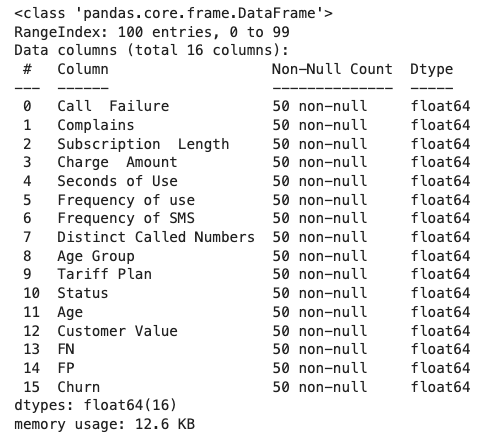
در ادامه با پیادهسازی تابع introduce_nan() ، ۵۰ درصد از مقادیر هر ستون را به دادههای گمشده تبدیل میکنیم:
سپس تابع پیادهسازی شده را بر روی زیرمجموعه جدا شده از دیتاست اصلی اعمال میکنیم:
تابع info() ، اطلاعات زیر را از مجموعهداده نتیجه میدهد:
در ادامه با فراخوانی تابع head() ، پنج سطر اول از مجموعهداده را به نمایش میگذاریم:
خروجی مانند زیر است:

روش حذف داده ها
راحتترین راه برای حذف نمونهها یا ویژگیهایی با مقادیر گمشده از دیتافریم، استفاده از تابع dropna() میباشد. در ادامه این بخش، به معرفی دو مورد از تکنیکهای رایج «حذف دادهها» (Data Dropping) میپردازیم. برای آشنایی بیشتر و یادگیری فرایند پاکسازی داده، مشاهده فیلم آموزشی پاکسازی دادهها در پایتون فرادرس که در لینک زیر آورده شده است را به شما پیشنهاد میکنیم:

۱. حذف نمونه ها از طریق مقادیر گمشده
هنگام حذف نمونه دادهها از مجموعهداده، امکان بهرهگیری از سه رویکرد زیر قابل تصور است:
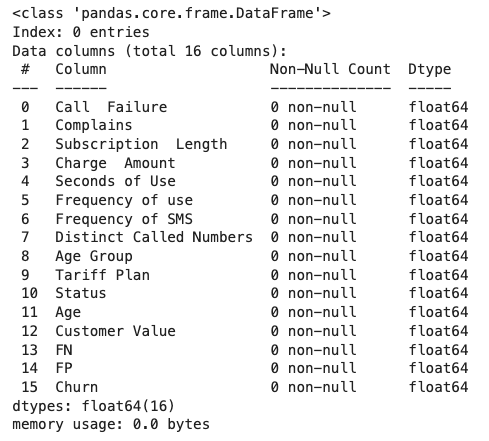
dropna() : جایگزینی تمامی سطرها با مقادیر گمشده.
همانطور که در تصویر زیر مشاهده میکنید، تمامی نمونهها حذف شدهاند. شرایطی که تجزیه و تحلیل دادهها را با چالش مواجه میکند:
dropna(how = ‘all’) : حذف سطرهایی که هیچ دادهای بهازای ستونها ندارند.
مطابق خروجی زیر، دیگر هیچ نمونهای وجود ندارد که بهازای تمامی ستونها شامل مقادیر گمشده باشد:
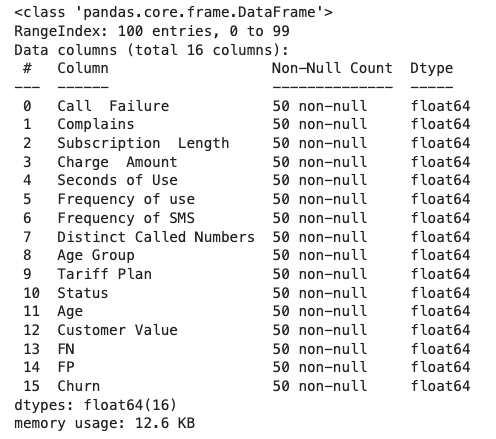
dropna(thresh = minimum_value) : حذف سطرها بر اساس «حد آستانهای» (Threshold) مشخص انجام میشود. در این رویکرد بهازای هر سطر، حد آستانهای کمینه از تعداد مقادیر گمشده تعیین میگردد.
با تنظیم مقدار ۶۰ درصد برای حد آستانه، خروجی مشابه روش قبلی خواهد بود:
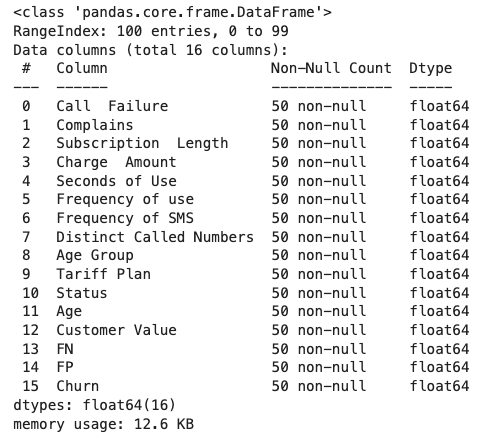
۲. حذف ستون ها از طریق مقادیر گمشده
پارامتر ورودی axis = 1 به این معنی است که میخواهیم عملیاتها بهشکل ستونی انجام شوند.
dropna(axis = 1) : حذف تمامی ستونهایی که شامل مقادیر گمشده هستند.
همانطور که در خروجی زیر مشاهده میکنید، تمامی ستونهای دیتاست حذف شدهاند؛ زیرا هر ستونی حداقل یک مقدار گمشده داشته است:

مانند بسیاری از روشهای دیگر، تابع dropna() نیز مزایا و معایبی دارد. برخی از مزایای این روش عبارتاند از:
- بدون پیچیدگی و استفاده آسان.
- موثر در کاربردهایی که مقادیر گمشده اهمیتی ندارند.
همچنین در فهرست زیر، به چند نمونه از معایب این روش اشاره کردهایم:
- استفاده از روش dropna() باعث از بین رفتن بخشی از اطلاعات میشود که ممکن است در مجموعهداده نهایی «سوگیری» (Bias) ایجاد کند.
- اگر گم شدن دادهها بهطور کامل تصادفی نباشد، بهرهگیری از این روش توصیه نمیشود.
- در صورتیکه بخش زیادی از دادههای دیتاست گم شده باشند، استفاده از این روش باعث کاهش حجم چشمگیری در مجموعهداده میشود؛ موضوعی که در نتایج حاصل از تجزیه و تحلیل آماری تاثیرگذار خواهد بود.
روش های جایگزینی میانگین و میانه
این تکنیکهای «جایگزینی» (Imputation) به توضیح چندانی نیاز ندارند. در دو روش جاگزینی «میانگین» (Mean) و «میانه» (Median)، مقادیر گمشده هر ستون به ترتیب با میانگین و میانه مقادیر گمنشده همان ستون جایگزین میشوند. فرض توزیع نرمال مجموعهداده، حالتی ایدهآل است؛ اما همیشه اینطور نیست. در چنین شرایطی، و از آنجا که حساسیتی نسبت به نمونهها «پَرت» (Outliers) ندارد، روش جایگزینی میانه مفید خواهد بود. در زبان برنامهنویسی پایتون، برای اعمال روش جایگزینی از تابع fillna() استفاده میشود. قطعه کد زیر، نحوه پیادهسازی روش جایگزینی میانگین را نشان میدهد:
خروجی مانند زیر است:

همچنین با اجرای قطعه کدی که در ادامه آورده شده است، میتوانیم از روش جایگزینی میانه استفاده کنیم:
در تصویر زیر، پنج سطر اول مجموعهداده جایگزین شده با مقدار میانه به نمایش گذاشته شده است:

روشهای جایگزینی نیز مزایا و معایبی دارند که در فهرست زیر به چند مورد از مزایای آنها اشاره کردهایم:
- پیادهسازی راحتی دارند.
- فرایند جایگزینی از طریق دادههای موجود در دیتاست انجام میشود؛ در نتیجه نیازی به اطلاعات اضافی نیست.
- دو روش جایگزینی میانگین و میانه، تخمین مناسبی از مقادیر گمشده ارائه میدهند؛ بهویژه اگر توزیع دادهها نرمال باشد.
از جمله معایب روشهای جایگزینی میتوان به موارد زیر اشاره کرد:
- این دو رویکرد را نمیتوان بر ستونهایی با نوع داده «طبقهبندی شده» (Categorical) اعمال کرد و تنها برای مقادیر عددی مناسب هستند.
- روش جایگزینی میانگین نسبت به نمونههای پرت حساس است و از همین جهت، شاید معیار خوبی برای نمایش دادههای گمشده نباشد. همین موضوع در مورد جایگزینی میانه نیز صادق است.
- جایگزینی میانگین تمامی دادههای گمشده را از نوع MCAR در نظر میگیرد؛ فرضیه که همیشه درست نیست.
روش جایگزینی با نمونه های تصادفی
ایده «جایگزینی با نمونههای تصادفی» (Random Sample Imputation) متفاوت از دیگر روشها و شامل مراحل بیشتری است؛ از جمله:
- ابتدا دو زیرمجموعه از دیتاست اصلی ساخته میشود.
- زیرمجموعه اول شامل نمونههایی بدون داده گمشده و زیرمجموعه دوم متشکل از نمونههایی با داده گمشده است.
- سپس و بهطور تصادفی از هر دو زیرمجموعه، نمونههایی انتخاب میشوند.
- در مرحله بعد، جای خالی نمونهای که بهطور تصادفی انتخاب شد، با یکی از نمونه دادههای زیرمجموعه اول پر میشود.
- این فرایند تا زمانی تکرار میشود که دیگر داده گمشدهای وجود نداشته باشد.
در قطعه کد زیر، نحوه پیادهسازی روش جایگزینی با نمونههای تصادفی را ملاحظه میکنید:
خروجی اجرای قطعه کد نمونه مانند زیر است:

این روش نیز شامل مزایا و معایبی است که ابتدا و در فهرست زیر به معرفی چند مورد از مزایای آن پرداختهایم:
- روشی ساده و بدون پیچیدگی در پیادهسازی است.
- برای هر دو نوع داده طبقهبندی شده و عددی کاربرد دارد.
- نسبت به سایر روشها، تغییر کمتری در واریانس دادهها ایجاد کرده و همچنین برخلاف دو روش جایگزینی میانگین و میانه، توزیع اصلی مجموعهداده را حفظ میکند.
برخی از معیاب روش جایگزینی با نمونههای تصادفی را در فهرست زیر ملاحظه میکنید:
- ویژگی تصادفی بودن این روش، همیشه کارساز نبوده و گاهی باعث ایجاد نویز و اختلال در دادهها میشود. از همین جهت، ارزیابی آماری نیز دچار خطا میشود.
- مشابه با روشهای جایگزینی میانگین و میانه، در این روش نیز دادههای گمشده از نوع MCAR فرض میشوند.
روش جایگزینی چندگانه
این روش، یعنی «جایگزینی چندگانه» (Multiple Imputation) نوعی تکنیک جایگزینی «چند متغیره» (Multivariate) است؛ به این معنی که از دادههای سایر ستونها به عنوان جایگزینی برای اطلاعات گمشده استفاده میشود. به عنوان مثال، اگر مقدار ستون درآمد برای فردی خالی باشد، نمیتوان فهمید که آیا خانهای اجاره کرده یا خود صاحب خانه است. در نتیجه، ارزیابی سایر ویژگیها مانند سوابق اعتباری و مدت زمان سکونت اهمیت پیدا میکند. روش «جایگزینی چندگانه از طریق معادلات زنجیرهای» (Multiple Imputation by Chained Equations | MICE) محبوبیت زیادی در میان تکنیکهای جایگزینی چند متغیره دارد. برای درک بهتر رویکرد MICE، بیایید مجموعهای از متغیرهای را در نظر بگیریم که تعدادی یا همه آنها شامل مقادیر گمشده هستند. طریقه کار الگوریتم بهصورت زیر است:


- به کمک رویکردی ساده مانند جایگزینی میانگین، مقادیر گمشده هر متغیر را با مقادیر متناظر دیگری به عنوان نوعی «نگهدارنده موقتی» (Placeholder) جایگزین میکنیم.
- سپس با استفاده از یک مدل «رگرسیونی» (Regression)، مقادیر نگهدارنده متغیر $ X1 $ به عنوان متغیر وابسته و سایر متغیرها مستقل فرض میشوند. در ادامه، همین فرایند برای سایر متغیرها نیز تکرار میشود؛ تا زمانی که همه متغیرها حداقل یکبار وابسته در نظر گرفته شده باشند.
- مقادیر نگهدارنده، با پیشبینیهای حاصل از مدل رگرسیونی جایگزین میشوند.
- بهطور معمول، این فرایند ده بار تکرار شده و در هر تکرار، مقادیر جدیدی جایگزین میشوند.
- در پایان، تمامی دادههای گمشده با مقادیر پیشبینی شدهای که نشاندهنده روابط میان دادهای هستند جایگزین میشوند.
برای پیادهسازی این الگوریتم با زبان برنامهنویسی پایتون، ابتدا باید کتابخانه miceforest را نصب کنیم:
pip install miceforestدر ادامه و در دو مرحله تکرار، کرنل را بر روی دادهها اعمال میکنیم و دادههای جایگزین شده مانند زیر ذخیره میشوند:
در تصویر زیر، پنج نمونه اول از مجموعهداده بهدست آمده را مشاهده میکنید:

روش جایگزینی چندگانه نیز مزایا و معیابی دارد. برخی از مزایای آن عبارتاند از:
- مدیریت آسان دادههای گمشده در چند متغیر و با انواع مختلف داده.
- نتایج حاصل از این روش به مراتب دقیقتر از جایگزینی میانگین و میانه است.
- میتوان از الگوریتمهایی همچون «K-نزدیکترین همسایه» (K-Nearest Neighbors | KNN)، «جنگل تصادفی» (Random Forest) و شبکههای عصبی به عنوان ساختاری پیشبینی کننده در روش جایگزینی چندگانه استفاده کرد.
همچنین، در فهرست زیر به چند مورد از معایب این روش اشاره شده است:
- در جایگزینی چندگانه، دادههای گمشده از نوع MAR در نظر گرفته میشوند.
- با وجود تمام مزایایی که نام برده شد، هزینه اجرای جایگزینی چندگانه از سایر روشها بالاتر است. بهویژه اگر مجموعهداده بزرگی داشته باشیم.
- پیادهسازی دشوارتری نسبت به سایر روشها دارد.
در مرحله بعد، قصد داریم میزان شباهت نتایج هر کدام از روشهای عنوان شده را با توزیع مجموعهداده اصلی مقایسه کنیم. به همین منظور، یکی از ستونهای مجموعهداده مانند ستون Charge Amount را انتخاب و ستون مجزایی برای هر یک از روشهای جایگزینی میانگین و میانه ایجاد میکنیم:
پس از ساخت ستونهای جدید، نمودار توزیع آنها را نیز مانند زیر رسم میکنیم:
خروجی قطعه کد فوق، نموداری مانند زیر است:

در ادامه، همین فرایند را برای دو روش جایگزینی چندگانه و تصادفی نیز تکرار و مجدد نمودار توزیع را رسم میکنیم:
در تصویر زیر، نمودار توزیع تمامی روشهای جایگزینی با یکدیگر مقایسه شدهاند:

مطابق انتظار و همانطور که پیشتر نیز با انواع روش های مدیریت داده های گمشده آشنا شدیم، جایگزینی چندگانه و تصادفی، همپوشانی بسیار نزدیکی با توزیع مجموعهداده اصلی دارند؛ موضوعی که نشاندهنده عملکرد بهتر این دو روش نسبت به جایگزینی میانگین و میانه است.
الگو های پیشنهادی برای مدیریت داده های گمشده
تا اینجا بهخوبی با رایجترین روش های مدیریت داده های گمشده آشنا شدیم. با این حال، انتخاب روش مناسب چالشبرانگیز است؛ به همین خاطر، در این بخش از مطلب مجله فرادرس، تعدادی از الگوهای پیشنهادی را برای انتخاب روش و بهطور کلی مدیریت داده های گمشده شرح میدهیم.


انتخاب بر اساس نوع داده های گمشده
همانطور که تا اینجا یاد گرفتیم، روش های مدیریت داده های گمشده متنوع است و نباید بدون بررسی قبلی مورد استفاده قرار گیرند. انتخاب روش مناسب از این جهت اهمیت دارد که از ایجاد سوگیری در دادهها و در نتیجه تصمیمگیری اشتباه جلوگیری میکند. در جدول زیر، روش جایگزینی مناسب هر نوع داده گمشده عنوان شده است:
| نوع دادههای گمشده | روش جایگزینی |
| دادههای گمشده بهطور کامل تصادفی (MCAR) | جایگزینی میانگین و میانه |
| دادههای گمشده بهصورت تصادفی (MAR) | جایگزینی چندگانه و رگرسیون |
| دادههای بهطور تصادفی گمنشده (MNAR) | جایگزینی الگو و برآورد حداکثر درستنمایی |
ارزیابی تاثیر عمل جایگزینی بر تجزیه و تحلیل آماری
باید توجه داشته باشید که پس از اعمال هر نوع روش جایگزینی، دیگر دادههای اولیه قابل بازیابی نیستند. اگر چه میتوان از تکنیکهایی استفاده کرد که نتایجی شبیه به دادههای اصلی تولید کنند. در فهرست زیر، به نکاتی اشاره کردهایم که بهتر است به آنها توجه داشته باشید:
- همزمان چند روش مختلف را بر روی دادهها آزمایش کنید. به این صورت، متوجه مشکلات هر روش شده و بهترین را برای مسئله خود پیدا میکنید.
- برای سنجش عملکرد هر روش، نتایج بهدست آمده را با دادههای اولیه مقایسه کنید.
- فرایند مدیریت دادههای گمشده را قسمتی ضروری در نظر بگیرد و آن را نیز در کنار مراحلی همچون پاکسازی و ساخت مدل یادگیری ماشین انجام دهید.
اشتراک گذاری داده های گمشده و روش های جایگزینی
در اختیار داشتن دادههای با کیفیت، هدف هر مدیر و متخصصی است. به همین جهت، بسیار مهم است که هنگام گزارش دادن، دو اصل شفافیت و صداقت را در نظر بگیریم و نتایج کاملی ارائه دهیم. فهرست زیر، شامل برخی از مهمترین جنبههایی است که باید در نظر داشته باشید:
- فارغ از نوع دادههای گمشده، نسبت به محتوای هر نمونه داده آگاهی کامل داشته باشید.
- روش هایی که برای مدیریت داده های گمشده بهکار بردهاید را بهطور شفاف مستندسازی کنید و توصیفی از مزایا و معایب هر کدام ارائه دهید.
- نتایج بهدست آمده از ارزیابیها را به شیوهای ساده و قابل فهم، برای افراد نا آشنا با این حوزه توضیح دهید.
سوالات متداول درباره روش های مدیریت داده های گمشده
حالا که روش های مدیریت داده های گمشده را یاد گرفتیم، زمان خوبی است تا در این بخش، به چند مورد از پرسشهای متداول در این زمینه پاسخ دهیم.

منظور از داده های گمشده چیست؟
به بخشی از ویژگیهای دیتاست شامل سطرها و ستونهایی که فاقد داده هستند گفته میشود.
داده های گمشده چه انواعی دارند؟
دادههای گمشده به سه دسته کلی زیر تقسیم میشوند:
- دادههای گمشده بهطور کامل تصادفی (MCAR)
- دادههای گمشده بهصورت تصادفی (MAR)
- دادههای بهطور تصادفی گمنشده (MNAR)

مدیریت داده های گمشده چگونه انجام می شود؟
برای رفع مشکل داده های گمشده، میتوانیم از روشهایی مانند جایگزینی میانگین و میانه، جایگزینی با نمونههای تصادفی و همچنین جایگزینی چندگانه استفاده کنیم. البته تکنیکهای مدیریت داده های گمشده به اینجا ختم نمیشود و هر روش مزایا و معایبی نیز دارد.
چرا داده های گمشده اهمیت دارند؟
دادههای گمشده اهمیت دارند؛ زیرا در عملکرد مدلهای یادگیری ماشین تاثیرگذار بوده و با ایجاد سوگیری در نتایج تجزیه و تحلیل آماری، به اشتباهاتی بزرگ در تصمیمگیری ختم میشوند.
جمعبندی
مسئله دادههای گمشده امری متداول در اکثر دیتاستها است و ساخت مدلهای یادگیری ماشین کارآمد، نیازمند مدیریت مناسب این دست از دادهها است. همانطور که در این مطلب از مجله فرادرس خواندیم، روش های مدیریت داده های گمشده متنوع است و بسته به نوع مسئله، میتوانیم بهترین روش را انتخاب کنیم. آشنایی کامل با مجموعهداده یا همان دیتاست، اولین قدم در شناسایی و سپس انتخاب تکنیکهای کارآمد برای پیشپردازش و مدیریت داده های گمشده است.