



دیتافریم (DataFrame) در کتابخانه Pandas – راهنمای مقدماتی
Pandas یک کتابخانه متنباز با لایسنس BSD است که ساختمان دادهای با عملکرد بالا و سهلالاستفاده و همچنین ابزار تحلیل دادهای برای زبان برنامهنویسی پایتون ارائه میکند. ساختمان داده ارائه شد از سوی Pandas بر دو نوع است:




- قاب داده Pandas
- سریهای Pandas
ما در این نوشته قاب داده (DataFrame (Pandas آشنا میشویم. البته روند عمومی برای آموزش Pandas از جمله در مستندات رسمی آن این است که ابتدا سریهای Pandas آموزش داده میشود و سپس به قاب داده Pandas پرداخته میشود. اما شاید بهتر باشد که ابتدا یادگیری را از قاب داده Pandas آغاز کنیم. بدین ترتیب مفهوم و منطق پشت سریهای Pandas روشنتر میشود و درک آن پس از آشنایی با قاب داده Pandas آسانتر خواهد بود.

منظور از قاب داده (DataFrame) چیست؟
قاب داده نیز مانند هر مفهوم دیگری تعاریف متعددی میتواند داشته باشد:
تعریف تکنیکی
قاب داده Pandas یک ساختمان داده برچسبگذاری شده 2 بعدی با ستونهایی است که به طور بالقوه انواع متفاوتی دارند.
تعریف به بیان ساده
قاب داده Pandas چیزی به جز یک بازنمایی درون حافظهای از یک برگه اکسل در زبان برنامهنویسی پایتون نیست.
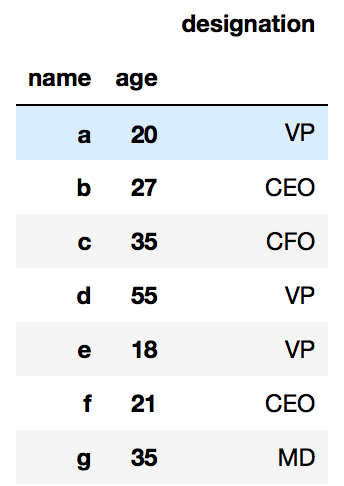
بنابراین قاب داده Pandas مشابه برگه اکسل است و ظاهر آن شبیه تصویر زیر است:
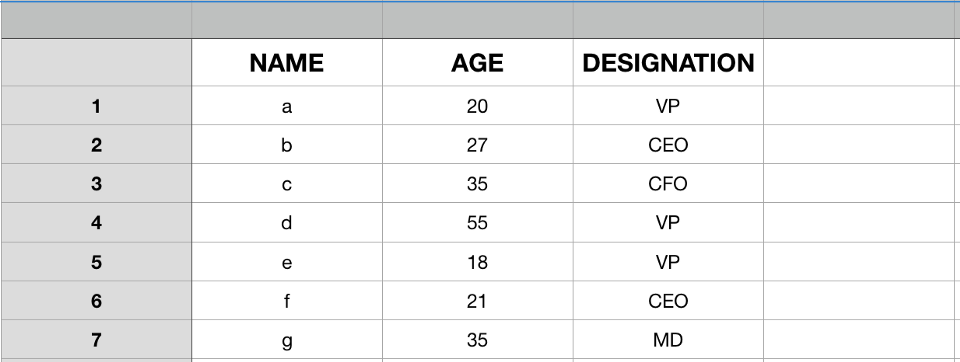
قاب داده Pandas نیز همانند اکسل کارکردهای مختلفی مانند تحلیل، تغییر و استخراج اطلاعات ارزشمند از مجموعه داده مفروض را در اختیار ما میگذارد.
چگونه یک قاب داده Pandas ایجاد کنیم؟
در دنیای واقعی یک قاب داده Pandas از طریق بارگذاری مجموعه دادهها از حافظهای دائمی برای مثال از فایلهای اکسل، csv و یا پایگاه داده MySQL ایجاد میشود. با این حال برای این که این مفهوم را بهتر درک کنید، در این بخش از ساختمان داده پایتون (دایرکتوری و لیست) استفاده میکنیم.
همان طور که در برگه اکسل فوق مشخص است، اگر نام ستونها را به عنوان کلید و لیست آیتمهای تحت هر ستون را به عنوان مقدار در نظر بگیریم، میتوانیم به راحتی از یک دیکشنری پایتون برای نمایش آن به صورت زیر استفاده کنیم:
my_dict = {
'name': ["a", "b", "c", "d", "e","f", "g"],
'age': [20,27, 35, 55, 18, 21, 35],
'designation': ["VP", "CEO", "CFO", "VP", "VP", "CEO", "MD"]
}
میتوانیم از این دیکشنری یک قاب داده Pandas به صورت زیر بسازیم:
import Pandas as pd df = pd.DataFrame(my_dict)
قاب داده حاصل میتواند ظاهری شبکه همان برگه اکسل که دیدیم داشته باشد:

این احتمال وجود دارد که ستونها به همان ترتیبی که در دیکشنری هستند نباشند، چون پایتون دیکشنری را به صورت hash پیادهسازی میکند و حفظ توالی را تضمین نمیکند.
اندیس ردیف
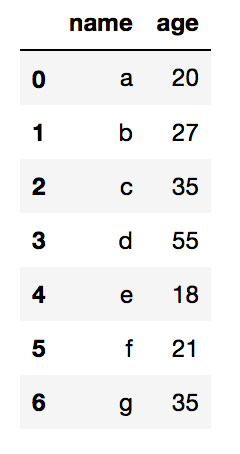
از آنجا که ما هیچ اندیس ردیفی برای قاب داده ارائه نکردهایم، به طور خودکار توالی (0 تا 6) را به عنوان اندیس ردیف تولید میکند.
برای این که خودمان اندیس ردیف ارائه کنیم، باید پارامتر index را در تابع (...)DataFrame به صورت زیر ارسال کنیم:
df = pd.DataFrame(my_dict, index=[1,2,3,4,5,6,7])
لزومی ندارد که این اندیس همیشه عددی باشد و میتوانیم رشتههایی را نیز به عنوان اندیس ارسال کنیم، برای مثال:
df = pd.DataFrame(
my_dict,
index=["First", "Second", "Third", "Fourth", "Fifth", "Sixth", "Seventh"]
)
ممکن است حدس زده باشید که اندیس ماهیتی همگن دارد یعنی میتوانیم از آرایههای NumPy نیز به عنوان اندیس استفاده کنیم. توجه کنید که متغیر index با تابع Index در پایتون فرق دارد.
np_arr = np.array([10,20,30,40,50,60,70]) df = pd.DataFrame(my_dict, index=np_arr)
ستونهای قاب داده Pandas
برخلاف لیستها دیکشنریهای پایتون و دقیقاً همانند NumPy، یک ستون در قاب داده همواره از یک نوع است.
ما میتوانیم نوع دادهی یک ستون را با استفاده از ساختار شبیه دیکشنری یا با افزود نام ستون به وسیله عملگر (.) DataFrame بررسی کنیم.
df['age'].dtype # Dict Like Syntax df.age.dtype # DataFrame.ColumnName df.name.dtype # DataFrame.ColumnName
اگر بخواهیم انواع داده همه ستونهای درون قاب داده را بررسی کنیم باید از تابع dtypes قاب داده به صورت زیر استفاده کنیم:
df.dtypes
بدین ترتیب نوع همه ستونها به صورت زیر نمایش مییابد:

مشاهده دادههای یک قاب داده
در هر زمان قاب داده Pandas شامل صدها و شاید هزاران ردیف داده خواهد بود. ما هر زمان تنها بخش منتخبی از این دادهها را میتوانیم ببینیم.
برای مشاهده گزیدهای از ردیفها میتوانیم از تابعهای (…)head و (…)tail استفاده کنیم که به طور پیشفرض ردیفهای اول یا آخر را ارائه میکند. در غیر این صورت تعداد مشخصی از ردیفها را از ابتدا یا انتها نمایش میدهد.
در ادامه روش نمایش محتوا را میبینید:
df.head() # Displays 1st Five Rows
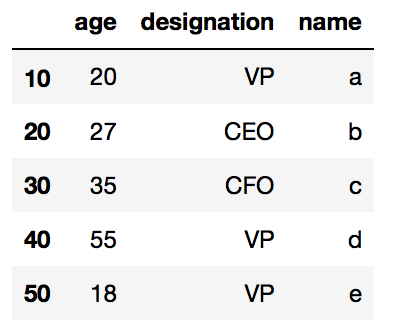
df.tail() # Displays last Five Rows
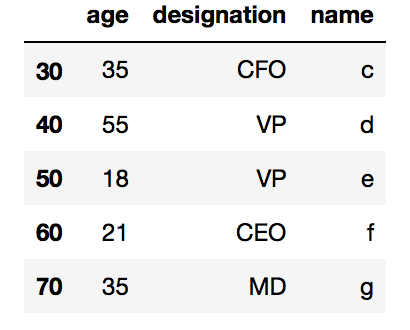
df.head(2) # Displays 1st two Rows

df.tail(7) # Displays last 7 Rows
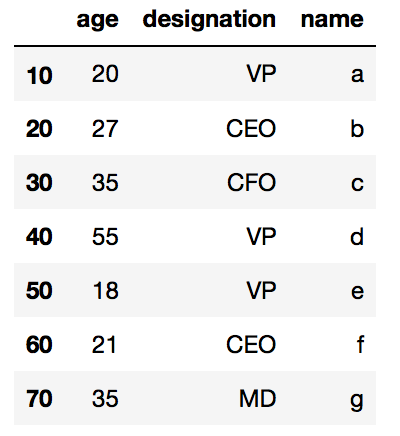
البته در دستورهای فوق تنها روش نمایش دادهها را دیدیم، حال اگر بخواهیم اندیس ردیفها و نام ستونها را ببینیم چه باید بکنیم؟ قاب داده Pandas تابعهای خاصی برای مشاهده این موارد ارائه کرده است:
df.index # For Row Indexes df.columns # For Columns
ستونهای قاب داده Pandas تابعهای کمکی ستونهای مختلف را که برای استخراج اطلاعات ارزشمند از ستونها بسیار مفید هستند ارائه میکند. برخی از آنها شامل موارد زیر هستند:
Unique – عناصر منحصر به فرد یک ستون را با حذف موارد تکراری ارائه میکند. برای مثال:
df.designation.unique()
mean – مقدار میانگین همه آیتمهای موجود در یک ستون را نشان میدهد. برای مثال:
df.age.mean()
استفاده از ستونها به عنوان اندیس ردیف
در اغلب موارد، مجموعه دادههای مفروش شامل اندیس ردیف هستند. در این موارد، نیازی به قاب داده Pandas برای تولید اندیس ردیف جداگانه نداریم. چون این اندیسها نه تنها اطلاعاتی اضافی هستند؛ بلکه حافظه را نیز بیجهت اشغال میکنند.
قاب داده Pandas امکان تعیین ستون یا مجموعه ستونهای موجود به عنوان اندیس ردیف را فراهم ساخته است. در این بخش روش استفاده از ستونهای قاب داده Pandas که قبلاً (با استفاده از دیکشنری my_dict) ایجاد شدهاند را توضیح میدهیم.
df = pd.DataFrame(my_dict)
df.set_index("name")
df.set_index("age")

ما میتوانیم با ارسال یک لیست درون (...)set_index به صورت زیر چندین ستون را به عنوان اندیس ایجاد کنیم.
df.set_index(["name","age"])
بارگذاری ستونها در قاب داده
هر فعالیت تحلیل دادهای که تصور کنید نیازمند پاکسازی داده است و این سناریو کاملاً محتمل است که به این نتیجه برسیم، نیاز داریم برخی ستونها را از تحلیل خود حذف کنیم. این کار نه تنها باعث صرفهجویی در حافظه میشود؛ بلکه به تحلیل دادههایی که مطلوب هستند نیز کمک میکند. ما از همان دیکشنری برای بارگذاری قاب داده Pandas استفاده میکنیم؛ اما این بار ستونهایی که میخواهیم بخشی از قاب داده باشند را تعیین میکنیم.
df = pd.DataFrame(my_dict, columns=["name", "age"])
حذف ردیفها و ستونها از قاب داده
قاب داده Pandas چندین روش برای حذف ردیفها و ستونها ارائه کرده است. ترجیح هر یک از روشها بر دیگری مزیت کارکردی چندانی ندارد. هر ساختاری که راحتتر یافتید را میتوانید مورد استفاده قرار دهید. با استفاده از ساختار دیکشنری برای حذف یک ستون از del به صورت زیر استفاده میکنیم:
del df['name']
با استفاده از تابع Drop میتوانیم ستونها را نیز علاوه بر ردیفها حذف کنیم. این که میخواهیم ردیفها و یا ستونها را حذف کنیم، در آرگومان دوم در تابع drop تعیین میشود. آرگومان دوم «1» در تابع (…)drop نشان دهنده حذف ستون است؛ در حالی که مقدار «0» برای حذف ردیف استفاده میشود.
# Delete Column "age"
df.drop('age',1)
# Delete the Row with Index "3"
df.drop(3,0)
همچنین امکان حذف چندین ردیف یا ستون با ارسال لیست در تابع (…)drop وجود دارد:
# Delete Columns "name" & "age" df.drop(['name','age'],1) # Delete Rows with index "2","3", & "4" df.drop([2,3,4],0)
توجه کنید که اندیس ردیف، شماره ردیف نیست؛ بلکه ردیف (ها) شامل آن مقدار هستند.

ایجاد یک قاب داده Pandas از یک لیست
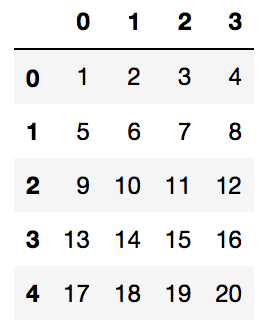
شاید این سؤال برایتان پیش آمده باشد که اگر یک مجموعه داده بدون هیچ ستونی داشته باشیم، چطور میتوانیم از آن قاب داده بسازیم؟ پاسخ این است که برای قاب داده Pandas مهم نیست که قاب داده با افزودن صریح اندیس ردیف ساخته میشود یا با استفاده از هدرهای ستونها. برای مثال اگر یک قاب داده را از لیست زیر بسازیم:
my_list = [[1,2,3,4],
[5,6,7,8],
[9,10,11,12],
[13,14,15,16],
[17,18,19,20]]
df = pd.DataFrame(my_list)
شبیه تصویر زیر خواهد بود:
اگر بخواهیم که قاب داده Pandas اندیسهای ردیفها و نام ستونها را به طور خودکار ایجاد نکند، میتوانیم این مقادیر را در تابع DataFrame به صورت زیر ارسال کنیم:
df = pd.DataFrame( my_list, index = ["1->", "2->", "3->", "4->", "5->"], columns = ["A", "B", "C", "D"] )
که به صورت زیر نمایش مییابد:

لازم به ذکر است که میتوانیم قاب داده Pandas را از آرایههای NumPy نیز به صورت زیر بسازیم:
np_arr = np.array([[1,2,3,4],
[5,6,7,8],
[9,10,11,12],
[13,15,16,16],
[17,18,19,20]])
df = pd.DataFrame(np_arr)
عملیاتهای ریاضی روی قاب داده
همانند برگههای اکسل در مورد قاب داده Pandas نیز آسانتر است که عملیاتهای ریاضی روی کل قاب داده انجام یابند. البته امکان انجام یک عملیات ریاضی روی ستون منفرد نیز وجود دارد و این همان جایی است که ما به سریهای Pandas نیاز داریم. در این بخش روش استفاده از عملیاتهای ریاضی روی کل یک قاب داده را بررسی میکنیم.
ضرب: ما میتوانیم قاب داده را در یک مقدار اسکالر از قاب داده دیگر ضرب کنیم.
df * df
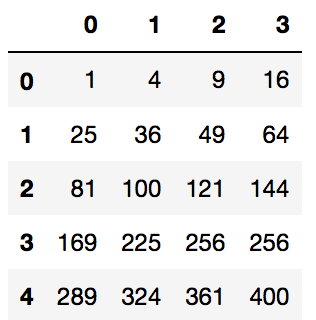
df * 10

جمع / تفریق: همانند عملیات ضرب، میتوان یک مقدار اسکالر را به یک قاب داده افزود یا کسر کرد.
df + 100
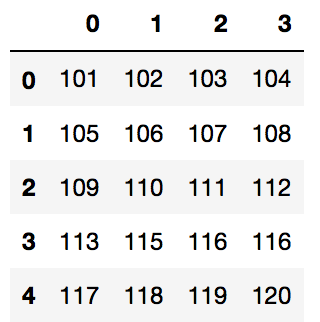
عملیات بیتی: امکان اجرای عملیاتهای بیتی AND (&)یا OR (|) و غیره بر روی قاب داده به عنوان یک کلیت وجود دارد.
df & 0

سریهای پاندا چیست؟
اینک که با مفهوم قاب داده آشنا شدید، باید بگوییم که در واقع منظور از سری Pandas چیزی به جز یک ستون منفرد از یک قاب داده Pandas نیست. هر زمان که با بیش از یک ستون سروکار داشته باشیم در واقع مشغول کار روی یک قاب داده هستیم. به طور مشابه میتوان گفت که قاب داده Pandas مجموعهای از سریهای Pandas است.
اگر این نوشته مورد توجه شما قرار گرفته است، پیشنهاد میکنیم موارد زیر را نیز بررسی کنید:
- آموزش برنامه نویسی پایتون – مقدماتی
- مجموعه آموزشهای آمار، احتمالات و دادهکاوی
- آموزش الگوهای طراحی (Design Patterns) در پایتون (Python)
- مجموعه آموزشهای برنامه نویسی پایتون
- آموزش یادگیری ماشین (Machine Learning) با پایتون (Python)
- مجموعه آموزشهای برنامهنویسی
==










سلام متد ()corr چه استفاده ای داره؟
با سلام و احترام؛
این متد، ضریب «همبستگی» (Correlation) بین ستونهای دیتافریم را محاسبه میکند.
از همراهی شما با مجله فرادرس سپاسگزاریم.
ممنون
خیلی عالی بود,ممنون.
عالی ممنون