



بخش بندی مشتریان با داده کاوی – به زبان ساده
«دادهکاوی» (Data Mining)، امروزه به یک ابزار کلیدی برای بهبود شرایط کسب و کارها از جنبههای گوناگون، شامل «مدیریت ارتباط با مشتریان» (Customer Relationship Managment)، «مدیریت زنجیره تامین» (Supply Chain Management)، «بازاریابی دیجیتال» (Digital Marketing) و بسیاری از دیگر موارد، مبدل شده است. مسائل گوناگونی را میتوان روی دادههای گردآوری شده از مشتریان در یک سازمان تعریف کرد؛ از جمله این مسائل، تحلیل رفتار خرید مشتریان یک کسب و کار و بخشبندی مشتریان بر این اساس است. در مطلب پیشِ رو، روش تحلیل رفتار و بخش بندی مشتریان با داده کاوی آموزش داده شده است.




بخشبندی مشتریان، چنانکه پس از این و در ادامه مطلب شرح داده خواهد شد، بر اساس چند دسته محصول که توسط مشتریان خریداری میشود، انجام شده است. اهداف اصلی پروژه تعریف شده در این مطلب، عبارتند از:
- بخشبندی مشتریان در چندین خوشه بر اساس شباهت رفتار خرید آنها
- توصیف تنوع در خوشههای گوناگون به منظور پیدا کردن بهترین ساختار تحویل کالا برای هر گروه
شایان ذکر است، به افرادی که علاقهمند به مطالعه بیشتر پیرامون کاربردهای دادهکاوی در حوزه تحلیل رفتار مشتریان هستند، مطالعه مطلب «پیشبینی ریزش مشتریان با دادهکاوی و R — راهنمای جامع» توصیه میشود.
بخش بندی مشتریان با داده کاوی
برای انجام پروژه مطرح شده در این مطلب، از مجموعه دادهای که در مخزن یادگیری ماشین UCI موجود است [+] استفاده خواهد شد. بخشی از این مجموعه داده از این لینک قابل دانلود است. در ادامه، به منظور آشنایی بیشتر با این مجموعه داده، اطلاعاتی پیرامون آن ارائه شده است.
مجموعه داده مذکور مربوط به اطلاعات مشتریان یک عمدهفروشی است. تعداد «ویژگیهای» (Features) این مجموعه داده ۸ عدد و تعداد نمونههای آن ۴۴۰ مورد است. همچنین، به جای «مقادیر ناموجود» (Missing Values) عبارت N/A قرار گرفته است. هر یک از ویژگیهای این مجموعه داده به شرح زیر هستند.
- FRESH: هزینه سالانه انجام شده برای خرید کالاهای تازه (متغیر عددی پیوسته)
- MILK: هزینه سالانه انجام شده برای خرید کالاهای مبتنی بر شیر (متغیر عددی پیوسته)
- GROCERY: هزینه سالانه انجام شده برای خرید خوار و بار (متغیر عددی پیوسته)
- FROZEN: هزینه سالانه انجام شده برای خرید کالاهای یخ زده (متغیر عددی پیوسته)
- DETERGENTS_PAPER: هزینه سالانه انجام شده برای خرید کالاهای شوینده و مبتنی بر کاغذ (متغیر عددی پیوسته)
- DELICATESSEN: هزینه سالانه انجام شده برای خرید مواد غذایی حاضری (متغیر عددی پیوسته)
- CHANNEL: کانال مشتریان که در اینجا Horeca (برای Hotel/Restaurant/CafA) و Retail (خردهفروشی) است (متغیر اسمی یا Nominal)
- REGION: منطقه مشتریان، شامل Oporto ،Lisnon و دیگر موارد (متغیر اسمی)
برای هر یک از ویژگیهای بیان شده، مقادیر حداقل، حداکثر، میانگین و انحراف معیار به ترتیب برابر هستند با:
- برای متغیر FRESH، از راست به چپ: 3, 112151, 12000.30, 12647.329
- برای متغیر MILK، از راست به چپ: 55, 73498, 5796.27, 7380.377
- برای متغیر GROCERY، از راست به چپ: 3, 92780, 7951.28, 9503.163
- برای متغیر FROZEN، از راست به چپ: 25, 60869, 3071.93, 4854.673
- برای متغیر DETERGENTS_PAPER، از راست به چپ: 3, 40827, 2881.49, 4767.854
- برای متغیر DELICATESSEN، از راست به چپ: 3, 47943, 1524.87, 2820.106
تعداد تکرار هر یک از مناطق برابر است با:
- Lisbon: تعداد 77 مرتبه
- Oporto: تعداد 47 مرتبه
- Other Region: تعداد 316 مرتبه
- Total: تعداد 440 مرتبه
تعداد تکرار هر یک از کانالها برابر است با:
- Horeca: تعداد 298 مرتبه
- Retail: تعداد 142 مرتبه
- Total: تعداد 440 مرتبه
تمرکز در اینجا روی شش دسته محصول برای مشتریان است. شایان توجه است که از ستونهای «Channel» و «Region» صرف نظر شده است.
در ادامه، قطعه کد لازم برای «وارد کردن» (Import) کتابخانههای لازم برای انجام این پروژه و همچنین، بارگذاری مجموعه داده، در «زبان برنامهنویسی پایتون» (Python Programming Language)، ارائه شده است. برای دانلود فایل visuals.py به این لینک [+] مراجعه شود.
مجموعه داده عمدهفروشی، دارای ۴۴۰ نمونه برای ۶ ویژگی (از مجموع ۸ ویژگی که از دو مورد از آنها یعنی Channel و Region صرف نظر شده) است.

کاوش دادهها
اکنون، از کدهای پایتون و «بصریسازی» (Visualizations) دادهها به منظور درک بهتر رابطه بین ویژگیها، استفاده خواهد شد. علاوه بر آن، توصیف آماری مجموعه داده ارتباط کلی ویژگیها نیز مورد بررسی قرار میگیرند.


انتخاب نمونهها
به منظور درک بهتر مجموعه داده و چگونگی تبدیل دادهها در فرایند تحلیل، تعدادی از نقاط نمونه انتخاب میشوند و کاوش آنها همراه با جزئیات انجام میپذیرد.

نکات قابل توجه
اکنون، کل هزینه خرید مشتری از هر دسته و توصیف آماری مجموعه داده بالا برای مشتریان نمونه در نظر گرفته میشود. اگر نیاز به پیشبینی این باشد که هر یک از نمونهها (مشتریان) چه نوع خریدی انجام میدهند، میتوان از راهکاری که در ادامه میآید استفاده کرده و مقادیر میانگین در نظر گرفته میشود.
- Fresh: 12000.2977
- Milk: 5796.2
- Grocery: 3071.9
- Detergents_paper: 2881.4
- Delicatessen: 1524.8
بر اساس نتایج بالا، میتوان پیشبینیهای زیر را انجام داد.
۱) نمونه با اندیس ۸۵: خردهفروشی
- بیشترین هزینه را در کل مجموعه داده روی مواد شوینده، کاغذ و لبنیات داشته است که معمولا محصولات مصرفی خانگی هستند.
- بیش از مقدار میانگین برای شیر هزینه کرده است.
- کمتر از میانگین برای محصولات یخزده هزینه کرده است.
۲) نمونه با اندیس ۱۸۱: بازار بزرگ
- هزینه بالایی، تقریبا برای همه محصولات ممکن، کرده است.
- بیشترین هزینه را روی محصولات تازه در کل مجموعه داده کرده است. این یعنی احتمال دارد که یک فروشگاه بزرگ باشد.
- هزینه کمی روی مواد شوینده کرده است.
۳) نمونه با اندیس ۳۳۸: رستوران
- مقدار هر محصول خریداری شده کمتر از دو مشتری دیگری است که در نظر گرفته شدهاند.
- هزینه برای محصولات تازه کمترین مقدار در کل مجموعه داده است.
- هزینه برای شیر، مواد شوینده و کاغذ در چارک اول قرار دارد.
- این محل ممکن است یک رستوران کوچک و ارزان قیمت باشد که به مواد غذایی و غذاهای یخزده برای سرو کردن غذاها نیاز دارد.
ارتباط ویژگیها
اکنون، ارتباط بین ویژگیها برای درک رفتار خرید مشتریان مورد بررسی قرار خواهد گرفت. به عبارت دیگر، برای تعیین اینکه یک مشتری که مقداری از محصولات مواد غذایی خرید کرده، آیا الزاما بخشی از دیگر محصولات مواد غذایی را نیز خواهد خرید، باید ارتباط بین ویژگیها مورد بررسی قرار بگیرد.
بررسی این موضوع با آموزش دادن یک مدل رگرسیون روی مجموعه دادهای که یک ویژگی آن حذف شده انجام میشود و سپس به چگونگی عملکرد مدل روی ویژگی پیشبینی شده پرداخته میشود.

امتیاز پیشبینی برابر است با: ۰.۶۷۲۵۴۹۱۸۲۶۴۶۱۰۴۲ (Prediction Score is: 0.6725491826461042)
- تلاش شد تا ویژگی Grocery پیشبینی شود.
- امتیاز پیشبینی گزارش شده برابر با ٪۶۷.۲۵ است.
همانطور که از امتیاز پیشبینی مشهود است، برازش به خوبی انجام شده است. بنابراین این ویژگی را به سادگی میتوان با در نظر گرفتن کل عادتهای خرید پیشبینی کرد و بنابراین برای پیشبینی عادات خرید مشتریان خیلی الزامی نیست.
بصریسازی توزیع ویژگیها
به منظور درک بهتر یک مجموعه داده، «ماتریس پراکنش» (Scatter Matrix) (از ماتریس پراکنش برای تخمین ماتریس کواریانس استفاده میشود) ویژگی هر محصول نمایش داده میشود.
ویژگیهای محصولی که در ماتریس پراکنش از خود همبستگی نشان میدهند، برای پیشبینی دیگر موارد قابل استفاده هستند.

- با استفاده از ماتریس پراکنش و ماتریس همبستگی به عنوان مرجع، میتوان استنباطهای زیر را انجام داد:
- دادهها به صورت نرمال توزیع نشدهاند، بلکه دارای چولگی مثبت و شبیه به «توزیع لگاریتمی نرمال» (Log-Normal Distribution) هستند.
- در اغلب نمودارها، اغلب نقاط داده نزدیک به منشا هستند که این حاکی از وجود همبستگی ضعیف میان آنها است.
- از نمودار پراکنش و حرارتی همبستگی میتوان فهمید که همبستگی بالایی بین دو ویژگی «Grocery» و «Detergent_paper» وجود دارد. ویژگیهای «Grocery» و «Milk» نیز میزان خوبی از همبستگی را از خود نشان میدهند. این همبستگی حاکی از آن است که حدسهای زده شده پیرامون ارتباط ویژگی «Grocery»، که میتواند به درستی با ویژگی «Detergent_paper» پیشبینی شود صحیح است و در واقع، آن را تایید میکند. بنابراین، این ویژگی در مجموعه داده مطلقا ضروری محسوب نمیشود.
پیشپردازش دادهها
این گام برای حصول اطمینان از اینکه نتایج مشاهده شده، مهم، معنادار و بهینه هستند، الزامی محسوب میشود. در ادامه، دادهها با نرمال کردن و شناسایی «دورافتادگیهای» (Outliers) بالقوه پیشپردازش میشوند.

نرمالسازی ویژگیها
معمولا، وقتی دادهها به طور نرمال توزیع نشدهاند، به ویژه اگر میانگین و میانه خیلی از هم متفاوت باشند (وجود یک چولگی بزرگ)، معمولا خوب است که از نرمالسازی غیرخطی به ویژه برای دادههای مالی استفاده شود. یک راه برای این کار، استفاده از «آزمون باکس-کاکس» (Box–Cox transformation) است. این آزمون، بهترین «تبدیل توانی» (Power Transform) را برای دادها محاسبه میکند که چولگی را کاهش میدهد. یک رویکرد سادهتر که در اغلب شرایط خروجی خوبی دارد، اعمال لگاریتم طبیعی است.

مشاهدات
پس از اعمال لگاریتم طبیعی برای نرمالسازی دادهها، توزیع هر یک از ویژگیها نرمالتر به نظر میرسد. برای هر جفت دلخواه از ویژگیها که پیش از این مشخص شد همبسته هستند، میتوان در اینجا مشاهده کرد که همچنان همبستگی وجود دارد (و اینکه آیا قویتر از قبل است یا ضعیفتر).
شناسایی دور افتادگیها
شناسایی دور افتادگیهای موجود در دادهها، کار بسیار مهمی طی پیشپردازش دادهها محسوب میشود. وجود دورافتادگیها معمولا منجر به وجود چولگی در نتایجی شود که این دادهها را در نظر گرفتهاند. در اینجا، از «روش توکی» (Tukey’s Method) برای شناسایی دور افتادگیها استفاده شده است. گام دورافتادگی (Outlier Step) به اندازه ۱.۵ برابر «دامنه بین چارکی» (InterQuartile Range | IQR) محاسبه میشود. یک نقطه داده دارای ویژگی که بیشتر از گام ناهنجاری برای دامنه بین چارکی است، ناهنجار در نظر گرفته میشود.
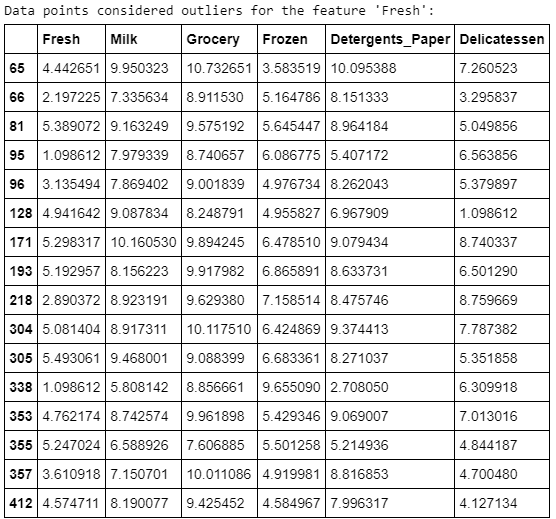
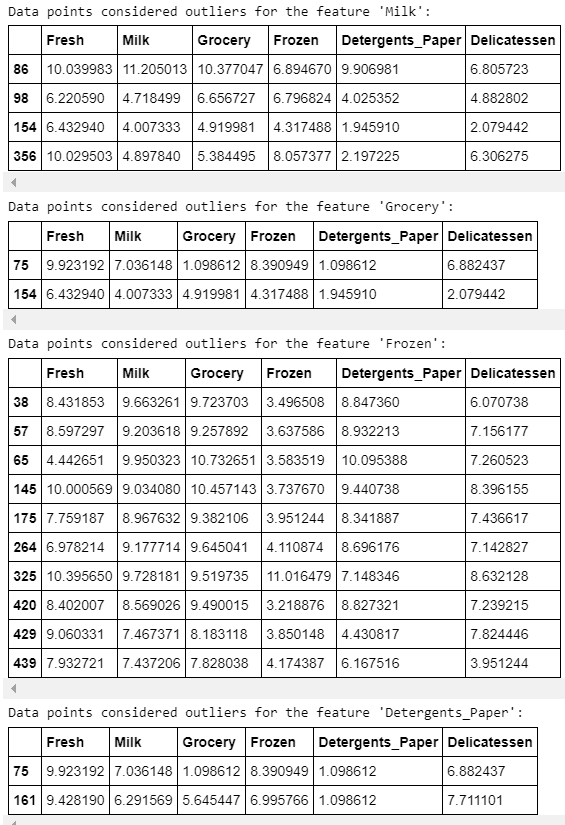
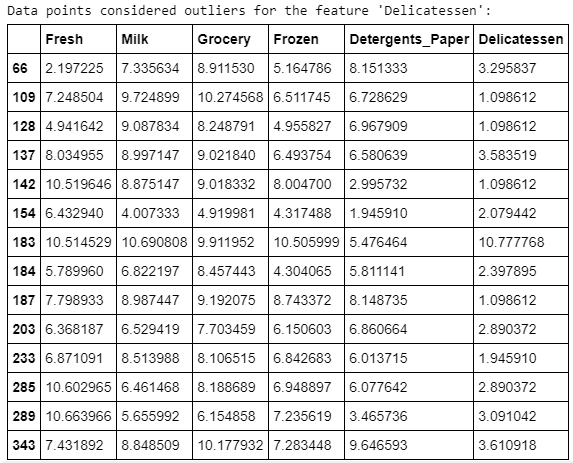


مشاهدات
نقاط دادهای که دورافتاده در نظر گرفته شدهاند و با بیش از یک ویژگی آمدهاند، عبارتند از ۶۵، ۶۶، ۷۵، ۱۲۸ و ۱۵۴. الگوریتم K-Means به شدت تحت تاثیر نقاط دورافتاده قرار میگیرد، زیرا آنها «تابع زیان» (Loss Function) را که الگوریتم سعی در کاهش آن دارد، به طور قابل توجهی افزایش میدهند.

این تابع زیان، مجموع مربعات فواصل هر یک از نقاط داده نسبت به «مرکزوار» (Centroid) است؛ بنابراین، اگر دورافتادگی به اندازه کافی دور باشد، مرکزوار در جایگاه غلطی قرار گرفته است. بنابراین، دورافتادگیها باید حذف شوند.
تبدیل ویژگیها
اکنون، از «تحلیل مولفه اساسی» (Principal Component Analysis | PCA) برای استخراج نتایج پیرامون ساختارهای غلط مجموعه داده استفاده خواهد شد. PCA برای محاسبه ابعادی که واریانس را بیشینه میکنند استفاده میشود تا به واسطه آن بتوان ترکیبی از ویژگیها که هر مشتری را به بهترین شکل ممکن توصیف میکند پیدا کرد.
تحلیل مولفه اساسی (PCA)
هنگامی که دادهها برای توزیع نرمال تغییر مقیاس داده شدند، میتوان PCA را روی good_data اعمال کرد تا مشخص شود که کدام ابعاد پیرامون دادهها به بهترین شکل واریانس ویژگیهای شامل شده را بیشینه میکنند. علاوه بر یافتن ابعاد، PCA نسبت واریانس توصیفی از هر بُعد را گزارش میکند (چقدر واریانس در دادهها وجود دارد بر اساس همان بُعد به تنهایی مشخص میشود).
خروجی: (3,6)

مشاهدات
- واریانس توصیف شده به وسیله دو مولفه اساسی اول برابر با ٪۷۰.۶۸ کل است.
- واریانس توصیف شده با سه مولفه اساسی برابر با ٪۹۳.۱۱ است.
توصیف ابعاد
- بُعد ۱: این بُعد به خوبی نشان میدهد، به صورت واریانس منفی، ویژگیهای Milk ،Detergent_Paper و Groceries. اغلب برای مصرف روزمره هستند.
- بُعد ۲: این بعد به خوبی نشان میدهد، به صورت واریانس منفی، این ویژگیها را: Frozen ،Fresh و Delicatessen. بیشتر مواد غذایی مصرفی هستند.
- بُعد ۳: این بعد به صورت واریانس مثبت، ویژگی Delicatessen را و به صورت واریانس منفی، ویژگی Fresh را به خوبی نشان میدهد؛ غذاهایی که به صورت روزانه مصرف میشوند.
- بُعد ۴: این بُعد به خوبی، به صورت واریانس مثبت، ویژگی Frozen و به صورت واریانس منفی، ویژگی Delicatessen را نشان میدهد؛ غذاهایی که قابل ذخیرهسازی هستند.
نکته بسیار مهم: واریانس در محاسبات آماری نمیتواند منفی باشد و در صورتی که واریانس منفی حاصل شد، یعنی خطایی در محاسبات وجود دارد. اما در اینجا، منظور از واریانس منفی، واریانس مولفهها (Components) است. واریانس مولفهها در صورتی منفی میشود که ماتریس کوواریانس، معین مثبت (Positive-Definite Matrix) نباشد.

کاهش ابعاد
هنگام استفاده از روش تحلیل مولفه اساسی، یکی از اهداف اصلی، کاهش ابعاد دادهها است. طی کاهش ابعاد، ابعاد کمتری که دادههایی با واریانس بالاتر را توصیف میکنند ارائه میشود. به همین دلیل، «نسبت واریانس توصیفی تجمعی» (Cumulative Explained Variance Ratio) برای دانستن اینکه چه تعدادی از ابعاد برای مساله لازم هستند، بسیار مهم است. علاوه بر آن، اگر مقدار قابل توجهی واریانس به وسیله دو یا سه بُعد توصیف شود، دادههای کاهش یافته بعدا قابل بصریسازی هستند.
سلول زیر نشان دهنده آن است که چگونه دادههای نمونه تبدیل لگاریتمی شده پس از اعمال تبدیل PCA روی آنها با تنها دو بُعد تغییر کردهاند. میتوان مشاهده کرد که مقادیر برای دو بُعد اول در مقایسه با وقتی که تبدیل PCA روی شش بُعد انجام شده، بدون تغییر باقی ماندهاند.

بصریسازی دونموداره
یک دونموداره، نمودار پراکنشی است که در آن هر نقطه داده به وسیله امتیازهای آن در مولفه اساسی نمایش داده میشود. محورها، مولفههای اساسی هستند (در هر مورد Dimension 1 و Dimension 2). دونموداره، نشانگر تصویر شدن ویژگیهای اصلی در طول مولفهها است.
دو نموداره میتواند به تفسیر ابعاد کاهش یافته دادهها و ارتباط بین مولفههای اساسی و ویژگیهای اصلی کمک کند.

تصویر ویژگیهای اصلی در رنگ قرمز در نمودار وجود دارد و این کمک میکند تا تفسیر جایگاه مرتبط هر نقطه داده در نمودار پراکنش آسانتر باشد. برای مثال، نقطه موجود در گوشه سمت راست پایین تصویر، متناظر با آن است که مشتری هزینه زیادی را صرف Grocery ،Milk و Detergents_Paper کرده است. اما هزینه زیادی برای محصولات دیگر دستهها نداشته است.
خوشهبندی
در این بخش، یکی از الگوریتمهای خوشهبندی، یعنی K-Means و یا «مدل مخلوط گاوسی» (Gaussian Mixture Model | GMM) برای حل مساله و شناسایی بخشبندیهای گوناگون مشتریان که در دادهها وجود دارند، انتخاب خواهد شد. سپس، برخی از نقاط داده خاص از خوشهها بازیابی میشوند تا مفهوم آنها با تبدیل کردن به ابعاد و مقیاس اصلی آنها مشخص شود.
K-Means در مقایسه با GMM
۱. مزایای اصلی استفاده از K-Means برای خوشهبندی عبارتند از:
- پیادهسازی آن آسان است.
- با تعداد بالای متغیرها (در صورت کوچک بودن K)، ممکن است نسبت به خوشهبندی سلسلهمراتبی سریعتر عمل کند.
- سازگار و مستقل از مقیاس است.
- تضمین شده که همگرا میشود.
۲: مزایای اصلی الگوریتم خوشهبندی مدل آمیخته گاوسی عبارتند از:
- از نظر کوواریانس خوشهها انعطافپذیرتر است. این یعنی هر خوشه میتواند ساختار کواریانس بدون محدودیت داشته باشد. به بیان دیگر، در حالی که K-means فرض میکند که هر خوشه ساختار کروی دارد، GMM خوشههای بیضی را میپذیرد.
- نقاط با درجه عضویتهای گوناگون به خوشههای گوناگونی تعلق دارند. این سطح از عضویت احتمال آن است که هر نقطه به هر خوشهای تعلق داشته باشد.
۳. الگوریتم منتخب:
- الگوریتم منتخب، مدل آمیخته گاوی است. زیرا به دلیل آنکه دادهها در خوشههای شفاف و متفاوت بخشبندی نشدهاند، کاربر نمیداند که چه تعداد خوشه وجود دارند.
ساخت خوشهها
هنگامی که تعداد خوشههای پیشبینی شناخته شده نیست، هیچ تضمینی وجود ندارد که یک تعداد داده شده از خوشهها به بهترین شکل دادهها را دستهبندی کنند؛ زیرا واضح نیست که چه ساختاری در دادهها وجود دارد. اگرچه، میتوان «خوب بودن» خوشهبندی را با محاسبه «ضریب نیمرخ» (Silhouette Coefficient) نیز محاسبه کرد.
ضریب نیمرخ برای نقاط داده محاسبه میکند که یک نقطه داده چقدر به خوشهای که به آن تخصیص پیدا کرده شبیه اسj و مقداری از ۱- تا ۱ را به آن میدهد (مشابهت). ضریب نیمرخ میانگین برای یک روش امتیازدهی ساده در خوشهبندی داده شده محاسبه میشود.

تعداد خوشه با بهترین ضریب نیمرخ برابر با ۲ و امتیاز آن ۰.۴۲ است.
بصریسازی خوشهها
هنگامی که تعداد بهینه خوشهها برای الگوریتم خوشهبندی با استفاده از سنجه امتیازدهی بالا محاسبه شد، میتوان نتایج را با قطعه کد زیر بصریسازی کرد.


بازیابی دادهها
هر خوشه نمایش داده شده در بصریسازی بالا، دارای یک نقطه مرکزی است. این مرکزها (یا میانگینها) به طور مشخص نقاط دادهای از دادهها نیستند، بلکه میانگین همه نقاط داده پیشبینی شده در خوشههای مربوطه هستند. برای مساله ساخت بخشبندی مشتریان، یک نقطه مرکز خوشه متناظر با مشتری میانگین آن بخش است.

از آنجا که دادهها در حال حاضر در ابعاد کاهش پیدا کردهاند، به وسیله تغییر مقیاس با لگاریتم، میتوان هزینه انجام شده توسط مشتریان را از این نقاط داده با اعمال تبدیل معکوس به دست آورد.

- بخش ۰ ممکن است حاکی از بازار مواد غذایی تازه باشد؛ زیرا هر ویژگی به جز Frozen و Fresh، کمتر از میانه است.
- بخش ۱ ممکن است نشان دهنده سوپرمارکتها باشد، زیرا هر ویژگی به جز fresh و frozen، بالاتر از میانه است.

کد زیر نشان میدهد که هر نمونه داده به کدام یک از خوشههای پیشبینی شده تعلق دارد.

مشاهدات
- نقطه نمونه ۰ --> سوپرمارکت است و حدس اصلی آن بوده که خردهفروشی باشد. این تفاوت بین حدس و واقعیت ممکن است به خاطر اندازه خوشه باشد (سایز خوشه بسیار بزرگ است).
- نقطه نمونه ۱ --> سوپرمارکت است که حدس اصلی یکی بوده است.
- نقطه نمونه ۲ --> حدس زده میشود که بازار مواد غذایی تازه باشد، در واقعیت رستوران است و با توجه به مقدار زیاد هزینهای که این نمونه برای هر یک از ویژگیها انجام داده بود، منطقی است.
نتیجهگیری
چگونه یک توزیعکننده عمدهفروشی میتواند یک مشتری جدید را با استفاده از اطلاعات خریدهایی که انجام داده و دادههای بخشبندی مشتریان، برچسبگذاری کند. یک الگوریتم یادگیری نظارت شده میتواند با هزینههای تخمینزده شده برای هر محصول به عنوان خصیصه و بخشبندی مشتریان به عنوان متغیر هدف، این مساله را به یک مساله دستهبندی مبدل کند (دو برچسب احتمالی وجود خواهد داشت). از آنجا که هیچ رابطه ریاضیایی شفافی بین بخش مشتریان و هزینه محصولات وجود ندارد، KNN میتواند الگوریتم خوبی برای حل این مساله باشد.

بصریسازی توزیعهای اساسی
در آغاز این پروژه، ویژگیهای Channel و Region از مجموعه داده (و در واقع از تحلیلها) حذف شدند، بنابراین دستههای محصولات مشتریان در تحلیلها مورد تاکید قرار گرفته است. با معرفی مجدد ویژگی Channel به مجموعه داده، هنگام در نظر گرفتن کاهش ابعاد با PCA مشابهی با مجموعه داده اولیه، یک ساختار جالب توجه ظهور میکند. بلوک کد زیر نشان میدهد هر نقطه داده به صورت RetailHoReCa (سرنامی برای Hotel/Restaurant/Cafe) یا Retail در فضای کاهش یافته برچسبگذاری شده است.

میتوان مشاهده کرد که الگوریتم خوشهبندی، عملکرد بسیار خوبی را برای خوشهبندی دادهها و در واقع بخشبندی مشتریان داشته است، زیرا خوشه ۰ میتواند به خوبی به خردهفروشی و خوشه ۱ به Ho/Re/Ca تخصیص پیدا کند.

اگر مطلب بالا برای شما مفید بوده، آموزشهای زیر نیز به شما پیشنهاد میشود:
- مجموعه آموزشهای دادهکاوی و یادگیری ماشین
- مجموعه آموزشهای دادهکاوی یا Data Mining در متلب
- مجموعه آموزشهای هوش مصنوعی
- زبان برنامهنویسی پایتون (Python) — از صفر تا صد
- یادگیری ماشین با پایتون — به زبان ساده
- آموزش یادگیری ماشین با مثالهای کاربردی — مجموعه مقالات جامع وبلاگ فرادرس
- چگونه یک دانشمند داده شوید؟ — راهنمای گامبهگام به همراه معرفی منابع
^^









با سلام و تشکر از آموزش بسیار خوبتون
فایل visuals.py رو برای بصری سازی داده ها نیاز داره ممنون میشم لینک دانلود این فایل رو هم قرار بدید
با سلام؛
از همراهی شما با مجله فرادرس و ارائه بازخورد سپاسگزاریم. لینک دانلود فایل مورد نظر، به مطلب اضافه شد.
شاد، پیروز و تندرست باشید.
سلام خسته نباشید ببخشید این کدهازو اگر در پایتون بخواهیم اجرابگیریم دقیقا درست مثل خروجی های بالا رو میده به ما یا نه نیاز هست که چیزی به آنها اضافه بشه تا اجرا بشه ؟
با سلام؛
از همراهی شما با مجله فرادرس سپاسگزاریم. پیرامون خروجی گرفتن از کدهایی که در آموزش ارائه شده باید به چند مسئله توجه داشت. مورد اول آنکه این کدها به صورت تکه تکه برای هر بخش از توضیحات ارائه میشوند و آنچه در آن بخش از توضیحات اعلام شده را انجام میدهند. مورد دوم آنکه در برخی از قسمتهای کد، گاهی ناگزیر نیاز به ارائه اطلاعاتی است که نویسنده اصلی مطلب اطلاعات خود را وارد کرده و بنابراین نیاز به آن است که کاربر این موارد را تغییر دهد. همچنین، برای داشتن یک برنامه کامل که خروجیهای کاملی را ارائه میکند، نیاز به نصب کلیه کتابخانهها و دیگر وابستگیهای لازم و همچنین انجام کلیه اقدامات جنبی است که در مطلب بیان شده است. بنابراین، داشتن یک کد یکپارچه که خروجی بدهد، گاهی مستلزم آن است که فعالیتهایی در ابعاد موارد بیان شده، از سوی مخاطب انجام شود.
در واقع و به طور کلی، باید گفت که فردی که قصد دارد از محتوای ارائه شده در مطالب تخصصی هوش مصنوعی، یادگیر یماشین، علم داده و برنامهنویسی استفاده کند، با توجه به «سطح آن مطلب»، نیاز به حداقل دانشهایی دارد. بنابراین برای مثال برای این مطلب، فرد نیاز به حداقل دانش برنامهنویسی و علم داده دارد تا بتواند با استفاده از محتوای جامع ارائه شده، روی پروژههای خود کار کند.
سلام
ببخشید دیتاست این پروژه رو ممکنه قرار بدین؟
ازتون خیلی ممنون میشم
با سلام؛
از همراهی شما با مجله فرادرس سپاسگزارم. لینک دانلود مجموعه داده در بخش «بخش بندی مشتریان با داده کاوی» و در جمله اول این مطلب ارائه شده است. شما با مراجعه با وبسایت ارائهدهنده مجموعه داده میتوانید فایلهای متعدد مربوط به این مجموعه داده را به طور جداگانه دانلود کنید. همچنین، در حال حاضر یک لینک نیز برای دانلود بخشی از مجموعه داده به صورت کلی نیز در همان بخش از متن قرار داده شده است.
پکیج vituals رو چجوری باید در پایتون نصب کنم؟