



آموزش یادگیری ماشین با مثالهای کاربردی ــ بخش سوم
امروزه استفاده از یادگیری عمیق برای انجام پروژههای صنعتی و دانشگاهی افزایش چشمگیری داشته است. دلیل این امر، توانمندی قابل توجه این روش برای حل مسائل دادهکاوی و «یادگیری ماشین» (Machine Learning) است. به دلیل حجم بالای توجهات به این روش، مقالات، نوشتهها و سخنرانیهای زیادی درباره آن ارائه میشود. اگر پراکندگی مطالب یا پیچیدگی درک آنها موجب شده تا نتوانید درک صحیحی از مفاهیم و عملکرد آن داشته باشید، خواندن این مطلب به شما توصیه میشود.




در قسمتهای پیشین از مجموعه مطالب «آموزش یادگیری ماشین با مثالهای کاربردی» به مبانی و مفاهیم هوش مصنوعی، یادگیری ماشین، یادگیری عمیق و شبکه های عصبی پرداخته شد. همچنین، برای درک بهتر موضوع، چندین مثال کاربردی و ملموس همراه با پیادهسازی آنها با استفاده از زبان برنامهنویسی پایتون مورد بررسی قرار گرفت. در این مطلب مباحث یادگیری عمیق و شبکههای عصبی پیچشی ارائه میشود.

هدف از این مطلب، نوشتن برنامهای است که اشیای موجود در یک تصویر را با بهرهگیری از یادگیری عمیق تشخیص دهد. به عبارت دیگر، در این مطلب، یک جادوی سیاه معرفی میشود که به Google Photos امکان جستوجو در میان تصاویر بر اساس یک تصویر خاص را میدهد.
گوگل اکنون به کاربران این امکان را میدهد که تصاویر را با توضیح مورد نظرشان جستوجو کنند. حتی اگر این تصاویر دارای تگ نباشند. این کار چگونه امکانپذیر است؟
درست مانند قسمتهای اول و دوم، این راهنما نیز برای کلیه علاقمندان به «یادگیری ماشین» (Machine Learning) که نمیدانند چگونه فراگیری را آغاز کنند مفید است. هدف این نوشته، قابل فهم بودن مطالب ارائه شده برای کلیه مخاطبان است، بنابراین از بیان جزئیات ریاضی و مفاهیم خیلی تخصصی در آن چشمپوشی شده است. مطالعه قسمتهای اول و دوم به افرادی که آنها را نخواندهاند پیشنهاد میشود.
شناسایی اشیا با استفاده از یادگیری عمیق
بسیاری از افراد علاقمند به حوزه «هوش مصنوعی» (Artificial Neural Network) و «یادگیری ماشین» (Machine Learning) این کمیک را پیش از این دیدهاند.

مفهوم این کمیک آن است که هر کودک سه سالهای میتواند تصویر یک پرنده را تشخیص بدهد. اما، کشف اینکه چگونه میتوان یک کامپیوتر را بر آن داشت که اشیای کنار هم چیده شده به صورت یک پازل را تشخیص بدهد، بیش از پنجاه سال است که دانشمندان را به پژوهش وا داشته.
در سالهای اخیر، یک رویکرد مناسب برای تشخیص اشیا با بهرهگیری از شبکههای عصبی پیچشی عمیق کشف شده. ایده اصلی این روش مانند آن است که ایده ساخت دستهای از کلمات من در آوردی موجود در رمان علمی تخیلی «ویلیام گیبسون» (William Gibson) را با شکستن کلمات تشخیص داد. خب، پس هدف ساختن برنامهای است که بتواند پرندگان را تشخیص دهد!
یک شروع ساده
پیش از آنکه به آموزش چگونگی شناخت تصویر پرندگان پرداخته شود، بهتر است یک مساله سادهتر مانند تشخیص عدد «8» که با دست خط یک فرد نوشته شده مورد بررسی قرار بگیرد. در قسمت دوم این مجموعه مطلب، به چگونگی حل مسائل پیچیده توسط شبکههای عصبی با به هم متصل کردن نورونهای ساده پرداخته شد.
بر همین اساس، یک شبکه عصبی ساده برای تخمین قیمت خانهها بر مبنای اینکه یک خانه چند اتاق و در کدام محله قرار دارد و متراژ آن چقدر است ساخته شد که به صورت زیر است.

همچنین، این ایده که یادگیری ماشین بر اساس استفاده از یک الگوریتم عمومی واحد که بتواند با دادههای گوناگون برای حل مسائل مختلف استفاده شود نیز بیان شد و مورد تاکید قرار گرفت. بنابراین، در اینجا نیز از همان شبکه عصبی ارائه شده در قسمت دوم برای تشخیص متن دست خط استفاده میشود. اما، برای سادهتر کردن کار تلاشها برای تشخیص تنها یک حرف یعنی عدد «8» است.

یادگیری ماشین تنها زمانی کار میکند که داده کافی وجود داشته باشد. از اینرو، در اینجا نیاز به حجم زیادی از دادههای مربوط به دست خطهایی است که عدد 8 را نوشتهاند. خوشبختانه پژوهشگران، مجموعه داده MNIST را که متشکل از اعداد دستنوشته است آماده ساختهاند. MNIST، با فراهم کردن ۶۰،۰۰۰ تصویر از اعداد دست نویس در ابعاد ۱۸x۱۸ برای اهداف و پروژههای گوناگون مورد استفاده قرار میگیرد. در تصویر زیر، برخی از 8های دستنویس قابل مشاهده هستند.

برخی از 8های موجود در مجموعه داده MINIST
همه چیز فقط عدد است!
شبکه عصبی که در قسمت دوم ساخته شد، تنها سه عدد را بهعنوان ورودی دریافت میکرد («۳» اتاق خواب، «۲۰۰۰» فوت مربع متراژ و محله «۱» (محلهها به یک عدد نگاشت شدهاند)). اما اکنون قصد پردازش تصویر در شبکه عصبی وجود دارد. چگونه میتوان بهجای اعداد، تصاویر را بهعنوان خوراک به شبکه عصبی داد؟! پاسخ فوقالعاده ساده است. یک شبکه عصبی اعداد را به عنوان ورودی دریافت میکند. برای یک کامپیوتر، یک تصویر تنها شبکهای است از اعداد که نشان میدهد هر پیکسل چقدر تیره است.
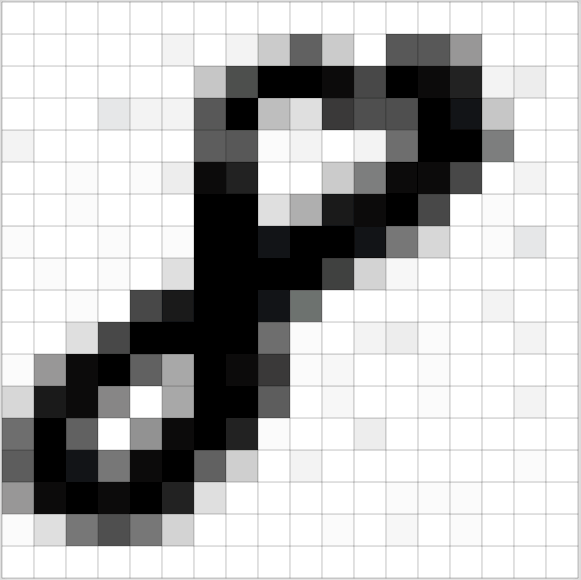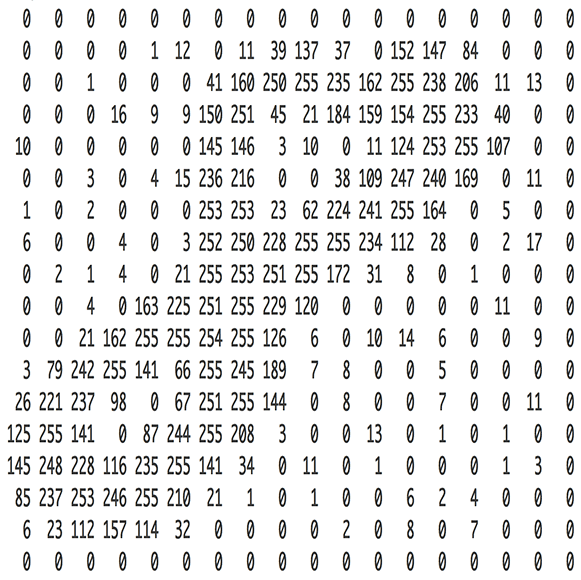 برای خوراندن یک تصویر به شبکه عصبی، با یک تصویر ۱۸x۱۸ پیکسل به عنوان آرایهای از ۳۲۴ عدد برخورد میشود.
برای خوراندن یک تصویر به شبکه عصبی، با یک تصویر ۱۸x۱۸ پیکسل به عنوان آرایهای از ۳۲۴ عدد برخورد میشود.
برای مدیریت ۳۲۴ ورودی، تنها نیاز به بزرگنمایی شبکه عصبی برای داشتن ۳۲۴ گره ورودی است.

برای اداره ۳۲۴ ورودی، شبکه عصبی بهمنظور داشتن ۳۲۴ گره ورودی بزرگ میشود.

لازم به ذکر است که شبکه عصبی اکنون دو خروجی دارد (به جای یکی). اولین خروجی احتمال اینکه تصویر متعلق به عدد 8 نباشد را پیشبینی میکند. با داشتن یک خروجی مجزا برای هر نوع از اشیایی که قصد تشخیص آنها وجود دارد، میتوان از یک شبکه عصبی برای دستهبندی اشیا به گروههای گوناگون استفاده کرد.
شبکه عصبی که این بار ایجاد شد، نسبت به دفعه پیش بسیار بزرگتر است (۳۲۴ ورودی به جای ۳ تا!). اما هر کامپیوتر مدرنی میتواند یک شبکه عصبی را با چند هزار گره بدون دشواری فراهم کند. این شبکه حتی روی گوشی موبایل نیز به خوبی جوابگو است. تنها کار باقیمانده آموزش دادن شبکه عصبی با تصویر «8»، و نه «8-» است. بنابراین مدل میآموزد که آنها را بهطور مجزا از هم بیان کند. هنگامیکه یک 8 به عنوان ورودی به مدل داده میشود، احتمال آنکه عدد 8 است صد درصد و احتمال آنکه 8 نباشد صفر درصد است. بالعکس این مورد نیز برای مثالهای نقض وجود دارد. در تصویر زیر برخی از دادههای آزمون قابل مشاهده هستند.

دادههای آموزش
میتوان چنین شبکههای عصبی را طی چند دقیقه در یک لپتاپ مدرن آموزش داد. پس از پایان آموزش، شبکه عصبی وجود دارد که میتواند تصویر 8 را با صحت بالایی در متن دستنویس تشخیص دهد. به دنیای تشخیص تصویر (اواخر دهه ۱۹۸۰) خوش آمدید!
دید تونلی
خوراندن پیکسلها به یک شبکه عصبی کاری تر و تمیز و جوابگوی ساخت یک مدل تشخیص تصویر است. یادگیری ماشین (Machine Learning) واقعا جادو است! البته حل مسائل گوناگون با یادگیری ماشین ساده نخواهد بود. ابتدا، خبر خوب آنکه تشخیصدهنده عدد 8، روی تصاویر نمونهای که عدد در وسط تصویر قرار گرفته بهخوبی کار میکند.

اما خبر بد اینکه، هنگامی که حرف 8 دقیقا در مرکز تصویر قرار نگرفته، مدل بهطور کامل شکست میخورد. تنها یک تغییر کوچک در موقعیت تصویر منجر به شکست کامل مدل میشود.

این اتفاق به این دلیل به وقوع میپیوندد که شبکه تنها الگوهایی را میآموزد که بهطور کامل در مرکز تصویر قرار دارند. مدل، هیچ ایدهای از چیستی یک 8 که در مرکز تصویر قرار نگرفته ندارد. بلکه، فقط و فقط یک الگو را میشناسد.
ایده اول: جستوجو با یک پنجره کشویی
در حال حاضر یک برنامه خیلی خوب برای یافتن عدد 8 در مرکز تصویر ساخته شد. یک ایده آن است که همه حاشیههای تصویر برای بررسی وجود 8 در بخشهای کوچکتر اسکن شود، برای این امر در هر لحظه یک بخش از تصویر مورد بررسی قرار میگیرد تا 8 موجود در دیگر نواحی آن کشف شود.

به این رویکرد «پنجره کشویی» (sliding window) گفته میشود. این رویکرد یک راهکار بروت فورس است که در موارد محدودی کار میکند، اما در کل واقعا ناکارآمد محسوب میشود. در این روش باید یک تصویر بارها و بارها برای کشف اشیا موجود در آن در ابعاد گوناگون مورد بررسی قرار بگیرد. به نظر میرسد که میتوان راهکار بهتری برای حل مساله یافت.
ایده ۲: دادههای بیشتر و شبکه عصبی عمیق
هنگام آموزش شبکه، تنها تصاویر 8هایی به آن نشان داده شد که در مرکز تصویر قرار داشتند. یک راهکار برای حل مساله موجود استفاده از دادههای بیشتر و تصاویری است که در آنها، 8ها در موقعیتهای گوناگون تصویر قرار گرفته باشند.

برای این کار حتی نیاز به گردآوری دادههای آموزش جدید نیز نیست. میتوان یک اسکریپت نوشت که تصاویر جدیدی از 8های موجود، در موقعیتهای گوناگون بسازد.

«دادههای آموزش مصنوعی» (Synthetic data) با ساخت نسخههای گوناگون از تصاویر آموزش ایجاد شدند. این روش بسیار کارآمد است.
با استفاده از این روش، میتوان به سادگی یک تامینگر دادههای آموزش ساخت. دادههای بیشتر، مساله را برای شبکه عصبی موجود سختتر میکنند، اما میتوان این مساله را با ساخت شبکه عصبی بزرگتر جبران کرد تا شبکه قادر به تشخیص الگوهای پیچیدهتر شود. برای ساخت شبکه عصبی بزرگتر، لایهها روی لایههای گرهها قرار داده میشوند.

به این مدل، «شبکه عصبی عمیق» گفته میشود، زیرا نسبت به یک شبکه عصبی سنتی، لایههای بیشتری دارد. این ایده از دهه ۱۹۶۰ مطرح بوده اما تاکنون آموزش دادن چنین شبکه عصبی بزرگی بسیار کندتر از آن بوده که مفید واقع شود. هنگامی که چگونگی استفاده از کارتهای گرافیک سهبُعدی کشف شد (که برای ضرب ماتریسها با سرعت بالا ساخته شده بودند) بهجای پردازشهای کامپیوتری متداول، کاربردهای شبکه عصبی ناگهان افزایش چشمگیری پیدا کرد. در واقع، همان کارت ویدئوی NVIDIA GeForce GTX 1080 که برای انجام بازی «اُورواچ» استفاده میشد را میتوان برای آموزش دادن شبکه عصبی بهطور فوقالعاده سریع مورد استفاده قرار داد.

اما حتی اگر یک شبکه عصبی بسیار بزرگ با یک کارت گرافیک سهبُعدی به سرعت آموزش داده شود، باز هم آنچه برای حل مشکل موجود در این مثال مورد نیاز است را فراهم نمیکند. اینکه شبکه را برای تشخیص 8 در بالا و پایین تصویر بهطور جداگانه گویی که دو شی متفاوت هستند آموزش دهیم، کاری بیمعنی به نظر میرسد.
باید راهی وجود داشته باشد که شبکه عصبی به اندازهای هوشمند شود که بتواند 8 را در هر کجای تصویر بدون دریافت آموزش جداگانه تشخیص دهد. خوشبختانه این روش وجود دارد. راهکار پیچشی است! انسانها بهطور حسی میدانند که یک تصویر ساختار سلسله مراتبی یا مفهومی دارد. تصویر زیر برای انسانها یک تصویر عادی است، زیرا به سادگی میتوانند مفهوم و سلسله مراتب آن را درک کنند.

تصویری از پسر نویسنده اصلی مطلب، آقای آدام گایتگی
یک انسان میتواند سلسله مراتب موجود در این تصویر را تشخیص دهد، برای مثال:
- زمین با چمن و بتن پوشش داده شده
- یک بچه وجود دارد
- بچه روی یک اسب فنری نشسته است
- اسب فنری روی چمنها قرار گرفته
مهمتر آنکه، وجود یک بچه در تصویر بدون توجه به اینکه روی چه چیزی قرار دارد قابل تشخیص است. یک انسان برای تشخیص بچه نیاز به تشخیص هر سطح ممکنی که او روی آن قرار گرفته ندارد. اما در حال حاضر، شبکه عصبی نمیتواند چنین کاری را انجام دهد. شبکه عصبی فکر میکند که 8 در بخشهای گوناگون تصویر کاملا متفاوت است. شبکه حتی نمیتواند درک کند که تغییر مکان یک شی در تصویر تفاوتی ایجاد نمیکند. این یعنی نیاز به بازآموزی شناسایی هر شی در هر موقعیت ممکن از تصویر وجود دارد. این مساله خیلی بد است.
در اینجا نیاز است که به شبکه عصبی درکی از انحراف انتقال 8 داده شود، بدین معنا که 8 فارغ از محل قرارگیری آن در تصویر به عنوان ورودی به مدل داده شود. این کار با استفاده از فرآیندی که به آن پیچش گفته میشود قابل انجام است. ایده پیچش تا حد زیادی از علوم کامپیوتر و زیستشناسی الهام گرفته شده (دانشمندان، مغز گربهها را با پروبهای عجیب و غریب تکان میدادند تا تشخیص دهند آنها چگونه تصاویر را پردازش میکنند).
پیچش چگونه کار میکند؟
به جای آنکه کل تصویر به یک شبکه عصبی به عنوان یک شبکه از اعداد خورانده شود، کاری بسیار هوشمندانهتر انجام پذیر است. در این رویکرد، از این ایده استفاده شده که یک شی فارغ از محل قرارگیری آن در تصویر، یک شی واحد و مشابه است. در این راستا، تصویر اصلی به ۷۷ کاشی با ابعاد مساوی و کوچک مبدل میشود.
گام اول: شکستن تصویر به کاشیهای همپوشان
مشابه با جستوجوی پنجره کشویی که پیش از این تشریح شد، در اینجا نیز تصویر به بخشهای کوچک و مساوی تقسیم میشود. با این تفاوت که تصویر اصلی به کاشیهایی با ابعاد مساوی شکسته شده و نتیجه مربوط به هر تصویر برای هر کاشی جداگانه ذخیره میشود.

گام دوم: خوراندن تصاویر به یک شبکه عصبی کوچک
پیش از این، یک تصویر منفرد به شبکه عصبی داده شد تا وجود یا عدم وجود عدد 8 در آن را تشخیص دهد. در ادامه کاری مشابه انجام میشود، با این تفاوت که فرآیند تشخیص 8 برای کلیه کاشیهای موجود در تصویر به صورت جداگانه صورت میپذیرد.

این را ۷۷ بار تکرار کن، یکبار به ازای هر کاشی
در اینجا، یک پیچیش بزرگ وجود دارد. وزنهای شبکه عصبی مشابهی برای هر یک از کاشیهای تصویر اصلی حفظ میشود. به عبارت دیگر، با همه تصاویر به طور مشابه برخورد میشود. اگر چیز جالب توجهی در هر یک از کاشیهای ورودی کشف شود، آن کاشی با عنوان جالب علامتگذاری میشود.
گام سوم: ذخیرهسازی نتایج هر کاشی در یک آرایه جدید
باید سازماندهی کاشیها مورد بررسی قرار بگیرند. بنابراین، نتایج پردازشهای هر کاشی در یک شبکه با سازماندهی مشابه تصویر اصلی ذخیره میشود. خروجی چیزی شبیه تصویر زیر خواهد بود.

بهعبارت دیگر، کار با یک تصویر بزرگ آغاز شده و با آرایههای کوچکتری که بخشهای جالبتر تصویر اصلی را ثبت میکنند به پایان میرسد.
گام ۴: Downsampling
نتیجه گام سوم آرایهای است که قسمتهای جالبتر تصویر را نگاشت میکند. اما این آرایه همچنان بسیار بزرگ است.

برای کاهش سایز آرایه، باید آن را با استفاده از الگوریتمی که به آن max pooling گفته میشود Downsample کرد. تنها کافیست به هر مربع ۲x۲ در آرایه نگریست و بزرگترین اعداد را حفظ کرد.

ایده این کار آن است که اگر چیز جالبی در هر یک از چهار کاشی ورودی یافت شد، صرفا جالبترین بیت نگهداری شوند. این امر موجب کاهش سایز آرایه با نگهداری جالبترین بیتها میشود.
گام نهایی: ساخت پیشبینی
تا این لحظه، تصویر غول پیکر اصلی به یک آرایه به اندازه کافی کوچک تقلیل یافت. این آرایه، دستهای از اعداد است که میتوان از آن بهعنوان ورودی یک شبکه عصبی دیگر استفاده کرد. این شبکه عصبی نهایی خواهد بود که تصمیم میگیرد تصویر با الگوی مورد نظر مطابق هست یا خیر. برای متمایز کردن این گام از مرحله پیچش، به آن شبکه «کاملا متصل» گفته میشود. از آغاز تا پایان این رویکرد، کل مراحل پنجگانه آن را میتوان به صورت شکل زیر نشان داد.

افزودن گامهای بیشتر
فرآیند پردازش تصویر برای حل این مساله شامل یک مجموعه از گامها از جمله پیچش، max-pooling، و در نهایت شبکه کاملا متصل است. هنگام حل مسائل جهان واقعی، این مراحل را میتوان به تعداد دفعات مورد نظر ترکیب و تجمیع کرد. میتوان دو، سه یا حتی ده لایه پیچشی داشت. همچنین، هر بار که نیاز باشد میتوان از max pooling برای کاهش سایز دادهها استفاده کرد.

ایده اصلی آغاز کردن کار با تصاویر بزرگ و پایین آوردن مداوم بزرگی آن به صورت گام به گام، تا زمان کشف نتیجه است. هر چه تعداد گامهای پیچشی موجود بیشتر شود، شبکه قادر خواهد بود بیاموزد که ویژگیهای پیچیدهتری را شناسایی کند. برای مثال، اولین گام پیچشی میآموزد که لبههای تیز را شناسایی کند، گام پیچشی دوم نوکهای تیز را با استفاده از دانش مرزهای تیز شناسایی میکند و سومین گام شناسایی کل پرنده با استفاده از دانش شناسایی نوکهای تیز است. در تصویر زیر، طرح واقعگرایانهتری از شبکه پیچشی عمیق ارائه شده است (شبیه آنچه در مقالات علمی دیده میشود):

در این مورد، کار با یک تصویر ۲۲۴x۲۲۴ آغاز شده، پیچش و max pooling دو بار، پیچش سه بار، max pooling و سپس دو لایه کاملا متصل اعمال میشود. نتیجه نهایی آن است که تصویر در ۱۰۰۰ دسته طبقهبندی میشود.
ساخت شبکه صحیح
اکنون چگونه میتوان فهمید که برای انجام دستهبندی کدام گامها باید با یکدیگر ترکیب شوند؟ پاسخ صادقانه این است که این کار را با کسب تجربه و آزمودن زیاد میتوان انجام داد. فردی ممکن است ۱۰۰ شبکه را پیش از کشف ساختار بهینه و پارامترهای آن برای حل یک مساله آموزش بدهد. یادگیری ماشین دارای آزمون و خطاهای زیادی است.
ساخت دستهبند پرنده
سرانجام، میتوان برنامهای نوشت که تشخیص میدهد یک تصویر متعلق به پرنده هست یا خیر. همچون قبل، نیاز به دادههایی برای آغاز کار وجود دارد. مجموعه داده رایگان و آزاد CIFAR10 شامل ۶،۰۰۰ تصویر پرنده و ۵۲،۰۰۰ تصویر از چیزهایی غیر از پرنده است. اما برای داشتن دادههای بیشتر، مجموعه داده Caltech-UCSD Birds-200–2011 نیز که دارای تصاویر ۱۲،۰۰۰ پرنده است افزوده میشود. در عکس زیر برخی از تصاویر موجود در مجموعه داده پرندگان به صورت ترکیبی قابل مشاهده هستند.

در عکس زیر برخی از تصاویر موجود در مجموعه داده شامل ۵۲،۰۰۰ تصویر غیر پرنده قابل مشاهده است.

این مجموعه داده برای هدفی که در این مطلب دنبال میشود بسیار مناسب است، اما ۷۲،۰۰۰ تصویر با کیفیت پایین همچنان برای کاربردهای جهان واقعی بسیار کوچک محسوب میشوند. برای دستیابی به کارایی در سطح گوگل نیاز به میلیونها تصویر بزرگ است. در «یادگیری ماشین» (Machine Learning)، داشتن دادههای بیشتر همواره از داشتن الگوهای بهتر مهمتر است. اکنون قابل درک خواهد بود که چرا گوگل با کمال رضایت انباری از تصاویر را در اختیار عموم قرار میدهد. آنها به دادههای کاربران بسیار علاقمند هستند.
در این مطلب برای ساخت دستهبند، از TFLearn استفاده شده است. TFLearn یک پوشش برای کتابخانه یادگیری عمیق TensorFlow است که یک رابط برنامهنویسی کاربردی (API) ارائه میکند. این امر ساخت یک شبکه عصبی پیچشی را به اندازه نوشتن چند خط کد برای تعریف لایههای شبکه آسان میسازد. در ادامه کد مربوط به تعریف و آموزش شبکه آورده شده است.
اگر آموزش با کارت ویدئو خوب و میزان رم (RAM) کافی انجام شود (مانند Nvidia GeForce GTX 980 Ti یا حتی بهتر)، این فرآیند در کمتر از یک ساعت انجامپذیر است. اما چنانچه آموزش با یک پردازنده معمولی صورت پذیرد، این فرآیند بیشتر به طول میانجامد. هرچه مدل بیشتر آموزش ببیند، صحت افزایش مییابد. پس از اولین گذر، صحت ۷۵.۴٪ حاصل میشود. پس از ۱۰ دوره، تا ۹۱.۷٪ نیز افزایش مییابد. پس از ۵۰ دوره یا بیشتر، صحت به چیزی حدود ۹۵.۵٪ درصد میرسد و آموزش بیشتر کمکی به افزایش صحت نمیکند. لذا فرآیند آموزش در همینجا پایان داده میشود. اکنون مدل میتواند پرندگان را با موفقیت، در تصویر شناسایی کند.
آزمودن شبکه
اکنون که شبکه عصبی آموزش دیده آماده شده، میتوان از آن استفاده کرد. این یک اسکریپت ساده است که میتواند فایل یک تصویر را دریافت کرده و پیشبینی کند که پرنده است یا خیر. اما، برای مشاهده اینکه شبکه چقدر موثر است، باید با استفاده از تعداد زیادی عکس ارزیابی شود. از همین رو، مجموعه دادهای از ۱۵،۰۰۰ تصویر برای این کار ساخته شد. هنگامی که این ۱۵،۰۰۰ تصویر در شبکه اجرا میشوند، مدل در ٪۹۵ مواقع پاسخ صحیح را پیشبینی میکند. به نظر میرسد مدل صحت خوبی دارد ، اما حقیقت این است که خوب یا بد بودن این میزان صحت بستگی به مسائل متعددی دارد.

۹۵٪ صحت چقدر صحیح است؟
شبکه از خود صحت ٪۹۵ را نشان داده است. اما در جزئیات آن رازی نهفته است. این صحت ۹۵ درصدی میتواند حاوی مضامین گوناگونی باشد. برای مثال، اگر ۵٪ دادههای آموزش پرنده و ٪۹۵ غیره پرنده باشند چه میشود؟ برنامهای که هر بار حدس «پرنده نیست» بزند، در ۹۵٪ مواقع صحیح است. البته چنین مدلی ٪۱۰۰ غیر قابل استفاده است!
لذا نیاز به اعداد دقیقتر و فراتر از یک عدد صحت کلی است. برای قضاوت کردن درباره اینکه یک سیستم دستهبندی چقدر خوب عمل میکند نیاز به بررسی چگونگی شکست و نه فقط درصد دفعاتی که شکست خورده نیز هست. به جای فکر کردن درباره پیشبینیهای «صحیح» و «غلط»، باید آنها را به چهار دسته جدا شکست.
- اول اینکه برخی از پرندگان توسط شبکه به خوبی بهعنوان پرنده شناسایی میشوند. به این موارد مثبت صحیح گفته میشود.

فوقالعاده است! شبکه توانسته انواع بسیاری از پرندگان را به درستی تشخیص دهد!
- دوم، در اینجا تصاویری وجود دارد که شبکه به درستی تشخیص داده که «پرنده نیستند». به این موارد منفی صحیح گفته میشود.

اسبها و تراکتورها نمیتوانند شبکه را گول بزنند.
- سوم اینکه تصاویری وجود دارند که شبکه آنها را پرنده محسوب میکند در حالیکه واقعا پرنده نیستند. به این موارد مثبت کاذب گفته میشود.

تصاویر زیادی به اشتباه پرنده محسوب شدهاند.
- و در نهایت، تصاویری از پرندگان وجود دارند که پرنده تشخیص داده نشدهاند. این موارد منفی کاذب هستند.

این پرندهها توانستهاند مدل را به خطا بیاندازند.
با استفاده از مجموعه دادههای معتبر برای ۱۵،۰۰۰ تصویر، اکنون تعداد دفعاتی که نوع پیشبینیها در یکی از چهار دسته بیان شده است در تصویر زیر نشان داده شده. به جدول زیر ماتریس در همریختگی گفته میشود.

دلیل آنکه خطاها بدین شکل شکسته و در ماتریس درهمریختگی قرار میگیرند آن است که تعداد خطاها از انواع مختلف با هم برابر نیستند. مثالی مفروض است که در آن هدف نوشتن برنامه تشخیص سرطان از روی تصاویر MRI است. در خطاها ممکن است مثبت کاذب و منفی کاذب وجود داشته باشد. منفی کاذب بدترین حالتی است که شاید در این شرایط اتفاق بیافتد زیرا برنامه به فرد مبتلا به سرطان میگوید که بیمار نیست. به جای گشتن به دنبال یک صحت کلی، متریکهای «صحت» (Recall) و «دقت» (Precision) سنجیده میشوند. این متریکها تصویر صحیحی از میزان صحت خروجیهای مدل ارائه میکنند.

ماتریس درهمریختگی بالا نشان میدهد ۹۷٪ مواردی که پرنده تشخیص داده شدهاند واقعا پرنده هستند. همچنین میگوید ۹۰٪ از مواردی که پرنده هستند را کشف کرده است. به عبارت دیگر، ممکن است همه پرندهها پیدا نشوند اما وقتی پرندهای پیدا میشود مطمئنا و به درستی پرنده است.
گام بعدی چیست؟
اکنون که مبانی شبکه پیچشی عمیق بیان شد، میتوان برای آشنایی بیشتر با معماریهای گوناگون شبکههای عصبی، مثالهای مختلفی را با استفاده از tflearn پیاده کرد. tflearn دارای مجموعه دادههای توکار متعددی است و موجب میشود که کاربر حتی نیاز نداشته باشد به دنبال مجموعه داده تصاویر بگردد.

بخش چهارم این مطلب را از اینجا مطالعه کنید.
اگر نوشته بالا برای شما مفید بوده است، آموزشهای زیر نیز به شما پیشنهاد میشود:
- آموزش مقدمهای در رابطه با یادگیری ماشین با پایتون
- آموزش یادگیری ماشین
- گنجینه آموزشهای یادگیری ماشین و دادهکاوی
- مقدمهای بر یادگیری ماشین
- مهمترین الگوریتمهای یادگیری ماشین (به همراه کدهای پایتون و R)
^^








