
خوشه بندی K–Means در پایتون – راهنمای کاربردی
در این مطلب، الگوریتم خوشه بندی K-Means به طور کامل و به زبان ساده آموزش داده شده است. همچنین، نحوه پیادهسازی خوشه بندی K-Means در «زبان برنامهنویسی پایتون» (Python Programming Language) با بهرهگیری از کتابخانه Scikit-Learn و مثالی برای درک بهتر موضوع مورد بررسی قرار گرفته است.
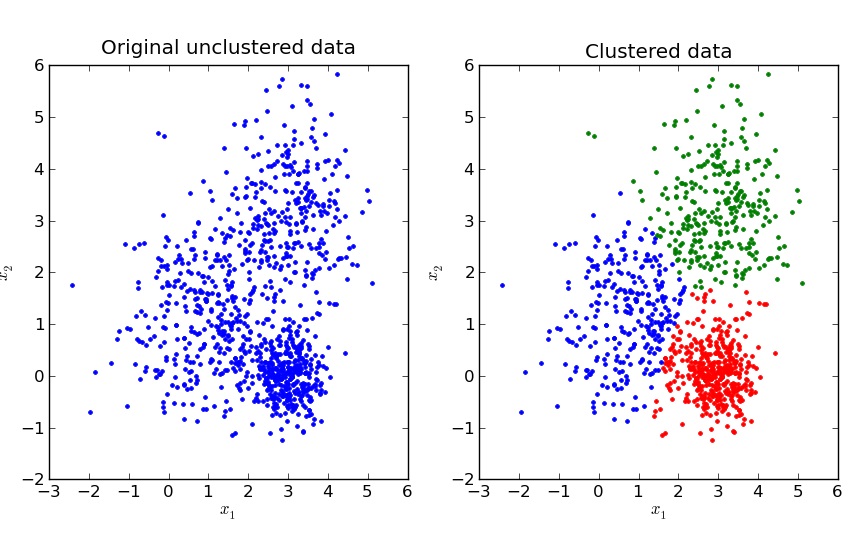


در «یادگیری ماشین» (Machine Learning)، انواع یادگیری در سه دسته «یادگیری نظارت شده» (Supervised Learning)، «یادگیری نظارت نشده» (Unsupervised Learning) و «یادگیری تقویتی» (Reinforcement Learning) قرار میگیرند. الگوریتمهایی که متعلق به دسته الگوریتمهای نظارت نشده هستند، هیچ متغیر پیشبینی وابسته به دادههایی را در ورودیها دریافت نمیکنند. در واقع، دادهها فقط دارای ورودیهای داده به صورت نمونههایی برای چندین متغیر هستند. این متغیرها، نمونه دادهها را توصیف میکنند. در چنین نوع دادههایی که «دادههای فاقد برچسب» (unlabeled data) نام دارند، از روشهای «خوشهبندی» (Clustering) برای یادگیری ماشین و دادهکاوی استفاده میشود.
خوشهبندی، وظیفه گروهبندی یک مجموعه از نمونهها به صورتی است که نمونههای داخل یک خوشه دارای بیشترین «مشابهت» (Similarity) با یکدیگر و کمترین مشابهت با دادههای خارج از خوشه خودشان باشند. مشابهت، سنجهای است که قدرت ارتباط بین دو نمونه داده را منعکس میکند.
خوشهبندی، اساسا برای «دادهکاوی اکتشافی» (Exploratory Data Mining) مورد استفاده قرار میگیرد و کاربردهای گستردهای در بسیاری از زمینهها شامل یادگیری ماشین، «بازشناسی الگو» (Pattern Recognition)، «تحلیل تصویر» (Image Analysis)، «بازیابی اطلاعات» (Information Retrieval)، «بیوانفورماتیک» (Bio-informatics)، «فشردهسازی دادهها» (Data Compression) و گرافیک کامپیوتری دارد.
در مطلب پیش رو، چگونگی عملکرد الگوریتم K-Means که یک روش خوشهبندی بسیار محبوب است شرح داده میشود. این الگوریتم به کاربر کمک میکند تا با دادههای فاقد برچسب کار کند (مجموعه دادهای که فاقد برچسب کلاس است). خوشه بندی K-Means در دسته الگوریتمهای خوشهبندی مبتنی بر «مرکزوار» (Centroid) قرار میگیرد. مرکزوار، یک نقطه داده (تخیلی یا واقعی) در مرکز خوشه است. در خوشهبندی مبتنی بر مرکزوار، خوشهها به وسیله یک بردار یا مرکزوار مرکزی ارائه میشوند. این مرکزوار الزاما عضو مجموعه داده نیست. خوشهبندی مبتنی بر مرکزوار، یک «الگوریتم تکرار شونده» (Iterative Algorithm) است که مشابهت در آن بر اساس نزدیک بودن نقطه داده به به مرکزوار خوشه تعیین میشود. موضوعاتی که در این مطلب مورد بررسی قرار میگیرند، عبارتند از:
- چگونگی عملکرد الگوریتم خوشهبندی K-Means
- یک بررسی موردی ساده در پایتون
- معایب K-Means
چگونگی عملکرد الگوریتم خوشه بندی K-Means
برای فراگیری هرچه بهتر این موضوع، ابتدا نیاز است که یک مجموعه داده (مجموعه داده آموزش)، تعریف شود.

مجموعه داده نمونه، حاوی هشت نمونه داده با مختصات Y ،X و Z مربوط به هر یک از نمونه دادهها است. وظیفه قابل انجام برای کاربر آن است که این اشیا را در دو خوشه (در اینجا است که مقدار K در الگوریتم K-Means یا همان K-میانگین تعریف میشود) قرار دهد. در واقع، در اینجا K = 2 داریم. بنابراین، الگوریتم به صورت زیر کار میکند. الگوریتم، ابتدا دو نقطه را به عنوان مرکزوار دریافت میکند (زیرا تعداد خوشهها ۲ تعیین شده و این یعنی K = 2 که در واقع به معنای داشتن دو مرکزوار است). پس از انتخاب مرکزوارها (فرض میشود که C1 و C2 دو مرکزوار منتخب هستند) نقاط داده (در اینجا مختصات) بسته به فاصلهای که از هر یک از مراکز خوشهها (مرکزوارها) دارند، به هر یک از خوشهها تخصیص پیدا میکنند (در اینجا و برای ابتدای کار، مرکزوارها = خوشهها در نظر گرفته میشوند). فرض میشود که الگوریتم (OB-2 (1,2,2 و (OB-6 (2,4,2 را به عنوان مرکزوارها و خوشههای ۱ و ۲ انتخاب میکند. برای اندازهگیری فاصلهها، تابع اندازهگیری، فاصلههای زیر را مورد استفاده قرار میدهد که به آن «تابع اندازهگیری فاصله» (Distance Measurement Function) گفته میشود.
|d=|x2–x1|+|y2–y1|+|z2–z1
این تابع، با عنوان «فاصله منهتن» (به انگلیسی به آن هم Taxicab distance و Manhattan distance گفته میشود. البته، دومین عبارت رایجتر است) نیز شناخته میشود که در آن d اندازه فاصله بین دو شی (x1,y1,z1) و (x2,y2,z2) است و Y ،X و Z مختصات دو شی است که فاصله آنها از یکدیگر سنجیده میشود. جدول زیر نشانگر محاسبه فواصل (با استفاده از تابع اندازهگیری فاصله معرفی شده در بالا) میان نقاط داده و مرکزوارها (OB-2 و OB-6) است.

اشیا بر اساس فاصله آنها با مرکزوارها، خوشهبندی میشوند. بر این اساس، نمونه دادهای که فاصله کمتری با یک مرکزوار (برای مثال C1) نسبت به مرکزوار دیگر (برای مثال C2) دارد، در خوشه C1 قرار میگیرد. پس از انجام خوشهبندی اولیه، نمونه دادهها چیزی مانند آنچه در جدول زیر قرار دارد، خواهند بود.

اکنون، الگوریتم کار به روز رسانی مرکزوارهای خوشهها را تا هنگامی انجام میدهد که دیگر امکان به روز رسانی آنها وجود نداشته باشد. به روز رسانی به صورت زیر انجام میشود:

بنابراین، با دنبال کردن قاعده بالا، خوشه ۱ در حالت به روز رسانی شده به صورت ((1+2+1+1+2)/5, (2+1+1+1+1)/5,(2+2+1+2+1)/5) = (1.4,1.2,1.6) خواهد بود. پس از این، الگوریتم دوباره شروع به پیدا کردن فاصله بین نقاط داده و مرکزوارهای جدید خوشهها میکند. بنابراین، فاصلههای جدید به صورت زیر خواهند بود:

تخصیص نمونه دادههای جدید با توجه به خوشههای به روز رسانی شده، به صورت زیر خواهد بود.

این همان مرحلهای است که الگوریتم دیگر مرکزوارها را به روز رسانی نمیکند، زیرا هیچ تغییری در شکلگیری خوشهها رخ نمیدهد و شکل خوشهها مانند قبل باقی میماند. پس از آنکه شکلدهی خوشهها با الگوریتم K-Means به پایان رسید، میتوان آن را روی دادههایی که الگوریتم پیش تر ندیده است (و به آنها داده آزمون یا تست گفته میشود) اعمال کرد. دادههای تست به صورت جدول زیر هستند:

پس از اعمال خوشهبندی K-Means روی مجموعه داده بالا، خوشههای نهایی به صورت زیر خواهد بود:

هر الگوریتمی، مادامی که میزان کارایی آن معلوم نباشد عملا بیفایده است. اکنون، برای ارزیابی کارایی الگوریتم K-Means میتوان از سنجههایی که برای این کار تعبیه شدهاند استفاده کرد. این سنجهها عبارتند از:
- شاخص رَند اصلاح شده (Adjusted rand index)
- امتیاز بر مبنای اطلاعات متقابل (Mutual information based scoring)
- اندازه V، همگنی، کامل بودن (Homogeneity ،V-measure و Completeness)
اکنون که مکانیزم داخلی الگوریتم K-Means تشریح شد، روی یک مساله جهان واقعی با استفاده از پایتون اعمال خواهد شد.
یک بررسی موردی ساده برای الگوریتم K-Means در پایتون
برای پیادهسازی الگوریتم K-Means، از «مجموعه داده تایتانیک» (Titanic Dataset) [+] استفاده میشود. پیش از ادامه این بخش، توضیحاتی در مورد دادهها ارائه میشود. غرق شدن کشتی تایتانیک، یکی از تلخترین غرق شدگیها در تاریخ است. کشتی تایتانیک در ۱۵ آپریل سال ۱۹۱۲، طی اولین سفر دریاییش، پس از برخورد با یک صخره یخی غرق شد و ۱۵۰۲ نفر از ۲۲۲۴ مسافر و خدمه آن کشته شدند.
این تراژدی، جامعه جهانی را متاثر کرد و منجر به وضع قوانین بهتری برای امنیت کشتیها شد. یکی از دلایلی که غرق شدن کشتی منجر به از دست دادن جان جمعیت زیادی از افراد شد، این بود که قایق نجات به اندازه کافی برای مسافران و خدمه آن وجود نداشت. این امر موجب شد تا همه سرنشینان کشتی شانس برابری برای نجات پیدا کردن نداشته باشند. بیشتر نجاتیافتگان کشتی تایتانیک، زنان، کودکان و افراد طبقه بالاتر بودند.
درباره مجموعه داده تایتانیک باید گفت که این مجموعه داده شامل چندین رکورد پیرامون مسافران تایتانیک است (همانطور که از نام مجموعه داده بر میآید). این مجموعه داده دارای ۱۲ «ویژگی» (Feature) است که دربردارنده اطلاعاتی پیرامون passenger_fare ،port_of_Embarkation ،passenger_class و دیگر موارد هستند. برچسب مجموعه داده survival است که بیان میکند وضعیت نجات یافتن (بقا) یک مسافر خاص به چه صورت بوده است. در اینجا، وظیفه نیازمند انجام، خوشهبندی رکوردها در دو دسته است؛ افرادی که نجات پیدا کردهاند و افرادی که غرق شدهاند.
ممکن است این پرسش مطرح شود که با توجه به برچسبدار بودن مجموعه داده، چگونه میتوان از آن برای خوشهبندی استفاده کرد. در این راستا، تنها کافی است که ستون «survivial» از مجموعه داده حذف شود و به همین راحتی مجموعه داده فاقد برچسب میشود. وظیفه K-Means خوشهبندی دادههای مجموعه داده بر این اساس است که آیا نجات پیدا کردهاند یا خیر.
نکته: حتما پس از دانلود مجموعه داده و پیش از استفاده از کد، باید اسامی ستونهای مجموعه داده را با آنچه در کد آمده تطبیق داد. این امکان وجود دارد که نام ستونی با آنچه در کد آمده متفاوت باشد که این امر منجر به خطا در کد میشود.
در این راهنما، کاربر برای استفاده از کدهایی که در ادامه بیان شده است، نیاز به بستههای پایتون «پانداس» (pandas)، «نامپای» (NumPy)، «سایکیت لِرن» (scikit-learn)، «سیبورن» (Seaborn) و «مَتپلاتلیب» دارد.
همه وابستگیهای مورد نیاز برای کدهایی که در ادامه راهنما مورد استفاده قرار میگیرند با بهرهگیری از قطعه کد بالا «وارد» (Import) شدند. اکنون، میتوان مجموعه داده را بارگذاری کرد.
در ادامه، یک پیشنمایش از دادههایی که قرار است با آنها کار شود دریافت میشود. برای این کار، برخی نمونهها از «دیتافریمهای» (DataFrames) «آموزش» (train) و «آزمون» (test) پرینت میشوند.
***** Train_Set *****
PassengerId Survived Pclass \
0 1 0 3
1 2 1 1
2 3 1 3
3 4 1 1
4 5 0 3
Name Gender Age SibSp \
0 Braund, Mr. Owen Harris male 22.0 1
1 Cumings, Mrs. John Bradley (Florence Briggs Th... female 38.0 1
2 Heikkinen, Miss. Laina female 26.0 0
3 Futrelle, Mrs. Jacques Heath (Lily May Peel) female 35.0 1
4 Allen, Mr. William Henry male 35.0 0
Parch Ticket Fare Cabin Embarked
0 0 A/5 21171 7.2500 NaN S
1 0 PC 17599 71.2833 C85 C
2 0 STON/O2. 3101282 7.9250 NaN S
3 0 113803 53.1000 C123 S
4 0 373450 8.0500 NaN S
***** Test_Set *****
PassengerId Pclass Name Gender \
0 892 3 Kelly, Mr. James male
1 893 3 Wilkes, Mrs. James (Ellen Needs) female
2 894 2 Myles, Mr. Thomas Francis male
3 895 3 Wirz, Mr. Albert male
4 896 3 Hirvonen, Mrs. Alexander (Helga E Lindqvist) female
Age SibSp Parch Ticket Fare Cabin Embarked
0 34.5 0 0 330911 7.8292 NaN Q
1 47.0 1 0 363272 7.0000 NaN S
2 62.0 0 0 240276 9.6875 NaN Q
3 27.0 0 0 315154 8.6625 NaN S
4 22.0 1 1 3101298 12.2875 NaN S
برای دریافت اطلاعات آماری پایهای مربوط به دیتافریمهای آموزش و آزمون میتوان از متد ()describe کتابخانه پانداس استفاده کرد.
***** Train_Set *****
PassengerId Survived Pclass Age SibSp \
count 891.000000 891.000000 891.000000 714.000000 891.000000
mean 446.000000 0.383838 2.308642 29.699118 0.523008
std 257.353842 0.486592 0.836071 14.526497 1.102743
min 1.000000 0.000000 1.000000 0.420000 0.000000
25% 223.500000 0.000000 2.000000 20.125000 0.000000
50% 446.000000 0.000000 3.000000 28.000000 0.000000
75% 668.500000 1.000000 3.000000 38.000000 1.000000
max 891.000000 1.000000 3.000000 80.000000 8.000000
Parch Fare
count 891.000000 891.000000
mean 0.381594 32.204208
std 0.806057 49.693429
min 0.000000 0.000000
25% 0.000000 7.910400
50% 0.000000 14.454200
75% 0.000000 31.000000
max 6.000000 512.329200
***** Test_Set *****
PassengerId Pclass Age SibSp Parch Fare
count 418.000000 418.000000 332.000000 418.000000 418.000000 417.000000
mean 1100.500000 2.265550 30.272590 0.447368 0.392344 35.627188
std 120.810458 0.841838 14.181209 0.896760 0.981429 55.907576
min 892.000000 1.000000 0.170000 0.000000 0.000000 0.000000
25% 996.250000 1.000000 21.000000 0.000000 0.000000 7.895800
50% 1100.500000 3.000000 27.000000 0.000000 0.000000 14.454200
75% 1204.750000 3.000000 39.000000 1.000000 0.000000 31.500000
max 1309.000000 3.000000 76.000000 8.000000 9.000000 512.329200
بنابراین، بر اساس خروجی بالا میتوان ویژگیهای مجموعه داده و برخی از آمارهای پایهای مربوط به آن را دانست. اسامی ویژگیها را میتوان با استفاده از کد زیر مشاهده کرد.
['PassengerId' 'Survived' 'Pclass' 'Name' 'Gender' 'Age' 'SibSp' 'Parch' 'Ticket' 'Fare' 'Cabin' 'Embarked']
شایان ذکر است که همه الگوریتمهای یادگیری ماشین، از این کار که دادههایی با «مقادیر ناموجود» (Missing Values) به آنها خورانده شود پشتیبانی نمیکنند. K-Means یکی از این الگوریتمها است. بنابراین، نیاز به مدیریت مقادیر ناموجودی که در دادهها وجود دارند، پیش از اعمال الگوریتم بر آنها است. ابتدا باید دید که کدام قسمتها دارای مقدار ناموجود هستند.


اکنون، مجموع تعداد «مقادیر ناموجود» (Missing Values) در هر دو مجموعه داده محاسبه میشود.
*****In the train set***** PassengerId 0 Survived 0 Pclass 0 Name 0 Gender 0 Age 177 SibSp 0 Parch 0 Ticket 0 Fare 0 Cabin 687 Embarked 2 dtype: int64 *****In the test set***** PassengerId 0 Pclass 0 Name 0 Gender 0 Age 86 SibSp 0 Parch 0 Ticket 0 Fare 1 Cabin 327 Embarked 0 dtype: int64
میتوان مشاهده کرد که در مجموعه داده آموزش، ستونهای Cabin ،Age و Embarked و در مجموعه تست، ستونهای Age و Cabin حاوی مقادیر ناموجود هستند. راهکارهایی برای مدیریت مقادیر ناموجود وجود دارد که عبارتند از:
- حذف سطرهایی با مقادیر ناموجود
- جایگذاری مقادیر ناموجود
در اینجا از راهکار دوم استفاده می شود، زیرا اگر سطری که حاوی مقدار ناموجود است حذف شود، موجب از بین رفتن دادهها و این امر به نوبه خود منجر به آموزش نامناسب مدل یادگیری ماشین میشود. اکنون، چندین راهکار وجود دارد که میتوان برای انجام جایگذاری از آنها بهره برد:
- جایگذاری یک مقدار ثابت ماند صفر که در دامنه دارای معنا و از دیگر مقادیر نیز متمایز است.
- استفاده از مقداری که به طور تصادفی از رکورد دیگری انتخاب شده است.
- جایگذاری مقدار میانگین، میانه و یا مُد ستونها
- استفاده از مقدار تخمین زده شده به وسیله یک مدل یادگیری ماشین دیگر
هر روش جایگذاری که برای مجموعه داده آموزش استفاده شد، باید روی مجموعه داده تست نیز اعمال شود. این کار هنگامی انجام میشود که قصد اعمال مدل نهایی روی مجموعه داده تست وجود دارد. نکته مذکور باید هنگام انتخاب چگونگی جایگذاری مقادیر ناموجود در نظر گرفته شود. در کتابخانه Pandas، از تابع ()fillna برای جایگذاری مقادیر ناموجود با یک مقدار خاص استفاده میشود. در اینجا، کار جایگذاری مقادیر ناموجود با «مقدار میانگین» انجام میشود.
اکنون که مقادیر ناموجودی که در مجموعه داده وجود داشتند، با مقدارهای دیگری جایگذاری شدند، زمان آن رسیده که بررسی شود آیا مجموعه داده هنوز حاوی مقادیر ناموجود هست یا خیر. این کار برای مجموعه داده آموزش با استفاده از کد زیر انجام میشود:
PassengerId 0 Survived 0 Pclass 0 Name 0 Gender 0 Age 0 SibSp 0 Parch 0 Ticket 0 Fare 0 Cabin 687 Embarked 2 dtype: int64
وجود مقادیر ناموجود در مجموعه داده تست، با استفاده از کد زیر بررسی میشود:
PassengerId 0 Pclass 0 Name 0 Gender 0 Age 0 SibSp 0 Parch 0 Ticket 0 Fare 0 Cabin 327 Embarked 0 dtype: int64
میتوان مشاهده کرد که همچنان مقادیر ناموجودی در ستونهای Cabin و Embarked وجود دارند. این امر بدین دلیل است که این مقادیر غیر عددی هستند. به منظور انجام جایگذاری، مقادیر باید به شکل عددی باشند. راههای برای تبدیل مقادیر غیر عددی به عددی نیز وجود دارد. در ادامه، تحلیلهایی به منظور کسب درک بهتری از دادهها انجام میشود. درک دادهها یک امر لازم و مهم برای انجام هر وظیفه یادگیری ماشینی است. کار با پیدا کردن ویژگیهایی که طبقهای و عددی هستند انجام میشود.
- طبقهای: Gender ،Survived و Embarked.
- ترتیبی: Pclass.
- پیوسته: Fare ،Age.
- گسسته: Parch ،SibSp.
دو ویژگی باقی ماندهاند که در هیچ یک از دستهها قرار نگرفتهاند. چنانکه مشهود است، این ویژگیها Ticket و Cabin هستند. Ticket ترکیبی از انواع دادههای عددی و «حرفیعددی» (Alphanumeric) است. Cabin نیز از نوع داده حرفیعددی محسوب میشود. در ادامه، برخی از مقدارهای نمونه مشاهده میشوند.
0 A/5 21171 1 PC 17599 2 STON/O2. 3101282 3 113803 4 373450 Name: Ticket, dtype: object
0 NaN 1 C85 2 NaN 3 C123 4 NaN Name: Cabin, dtype: object
در این قسمت، تعداد مسافران نجات یافته با توجه به ویژگیهایی که در زیر بیان شدهاند، تعیین میشود.
- Pclass
- Gender
- SibSp
- Parch
این کار برای تک به تک ویژگیهای بیان شده صورت میپذیرد.

تعداد نجاتیافتگان با توجه به Gender:

میتوان مشاهده کرد که جمعیت زنان نجات یافته به طور چشمگیری بیشتر از مردها بوده است.
جمعیت نجاتیافتگان با توجه به SibSp:

اکنون، زمان آن رسیده که برخی از نمودارها ترسیم شوند. در ادامه، نمودار «سن نسبت به نجات یافتن» (Age vs. Survived) ترسیم شده است.
seaborn.axisgrid.FacetGrid at 0x7fa990f87080

زمان آن رسیده که با رسم یک نمودار، بررسی شود که ویژگیهای Pclass و Survived چگونه به یکدیگر مرتبط هستند.

بسیار خب، به نظر میرسد این حجم از بصریسازی تا این لحظه کافی باشد. اکنون، مدل K-Means با مجموعه داده آموزش ساخته میشود. اما پیش از آن، نیاز به انجام «پیشپردازش» (Preprocessing) دادهها است. میتوان مشاهده کرد که مقادیر همه ویژگیها از یک نوع نیست. برخی از آنها عددی هستند. به منظور تسهیل محاسبات، همه دادههای عددی به مدل خورانده میشوند. با استفاده از کد زیر، نوع داده ویژگیهای موجود در مجموعه داده مشخص میشوند:
<class 'pandas.core.frame.DataFrame'> RangeIndex: 891 entries, 0 to 890 Data columns (total 12 columns): PassengerId 891 non-null int64 Survived 891 non-null int64 Pclass 891 non-null int64 Name 891 non-null object Gender 891 non-null object Age 891 non-null float64 SibSp 891 non-null int64 Parch 891 non-null int64 Ticket 891 non-null object Fare 891 non-null float64 Cabin 204 non-null object Embarked 889 non-null object dtypes: float64(2), int64(5), object(5) memory usage: 83.6+ KB
اکنون، میتوان مشاهده کرد که ویژگیهای زیر غیر عددی هستند.
- Name
- Gender
- Ticket
- Cabin
- Embarked
پیش از تبدیل این موارد به مقادیر عددی، ممکن است نیاز به انجام مقداری مهندسی ویژگیها باشد. برای مثال، ویژگیهای Cabin ،Ticket ،Name و Embarked هیچ تاثیری روی وضعیت مسافران ندارد. اغلب اوقات، بهتر است که مدل صرفا با ویژگیهای موثر آموزش ببینید، به جای آنکه با همه ویژگیها شامل موارد غیر لازم آموزش داده شود. این کار، نه فقط به آموزش موثر مدل کمک میکند، بلکه آموزش مدل با بهرهگیری از آن در زمان کمتری به وقوع میپیوندد. «مهندسی ویژگیها» (Feature Engineering) خود یک زمینه مطالعاتی گسترده است. در اینجا، مشخص است که ویژگیهای غیر عددی Cabin ،Ticket ،Name و Embarked قابل حذف هستند و هیچ تاثیر قابل توجهی روی آموزش دادن مدل K-Means ندارند.
اکنون که کار حذف ویژگیها انجام شد، ویژگی «Gender» به نوع عددی تبدیل میشود (تنها Gender باقیمانده که ویژگی غیر عددی است). این کار با استفاده از روشی که «رمزگذاری برچسبها» (Label Encoding) نام دارد، قابل انجام است.
<class 'pandas.core.frame.DataFrame'> RangeIndex: 891 entries, 0 to 890 Data columns (total 8 columns): PassengerId 891 non-null int64 Survived 891 non-null int64 Pclass 891 non-null int64 Gender 891 non-null int64 Age 891 non-null float64 SibSp 891 non-null int64 Parch 891 non-null int64 Fare 891 non-null float64 dtypes: float64(2), int64(6) memory usage: 55.8 KB
توجه به این نکته لازم است که مجموعه تست، دارای ویژگی Survived (که همان برچسب است) نیست.
<class 'pandas.core.frame.DataFrame'> RangeIndex: 418 entries, 0 to 417 Data columns (total 7 columns): PassengerId 418 non-null int64 Pclass 418 non-null int64 Gender 418 non-null int64 Age 418 non-null float64 SibSp 418 non-null int64 Parch 418 non-null int64 Fare 418 non-null float64 dtypes: float64(2), int64(5) memory usage: 22.9 KB
به نظر میرسد کار آموزش دادن مدل K-Means تا این لحظه خوب پیش رفته است. ابتدا میتوان ستون Survival را از دادهها با استفاده از تابع ()drop حذف کرد.
میتوان همه ویژگیهایی که قرار است به الگوریتم داده شود را با دستور ()train.info بررسی کرد.
<class 'pandas.core.frame.DataFrame'> RangeIndex: 891 entries, 0 to 890 Data columns (total 7 columns): PassengerId 891 non-null int64 Pclass 891 non-null int64 Gender 891 non-null int64 Age 891 non-null float64 SibSp 891 non-null int64 Parch 891 non-null int64 Fare 891 non-null float64 dtypes: float64(2), int64(5) memory usage: 48.8 KB
اکنون، مدل K-Means ساخته میشود.
میتوان همه پارامترهای دیگر مدل را به جز n_clusters را مشاهده کرد. در حال حاضر، این امکان وجود دارد که بررسی شود مدل با بررسی درصدهای مربوط به رکوردهای مسافران که به درستی دستهبندی شدهاند، چقدر خوب کار میکند.
0.5084175084175084
برای ابتدای کار خوب است. مدل قادر به خوشهبندی درست برای ۵۰٪ از دادهها است (صحت مدل). اما به منظور بهبود کارایی مدل، میتوان برخی از پارامترهای مدل را تغییر داد و در واقع تنظیم کرد. برخی از پارامترهایی که در پیادهسازی کتابخانه Scikit-Learn الگوریتم K-Means وجود دارند، عبارتند از:
- algorithm
- max_iter
- n_jobs
اکنون، مقدار پارامترها تنظیم میشود و سپس تغییرات رخ داده در نتایج خروجی مورد بررسی قرار میگیرد. در مستندات کتابخانه «سایکیتلرن» (Scikit-Learn) [+] اطلاعاتی پیرامون پارامترهای بیان شده وجود دارد که توصیه میشود افراد آنها را مطالعه کنند.
0.49158249158249157
چنانکه مشخص است، کاهشی در امتیاز به وقوع پیوسته. یکی از دلایل این امر آن است که مقادیر ویژگیهای گوناگون پیش از داده شدن به مدل استاندارد نشدهاند. ویژگیهای موجود در مجموعه داده در طیف متنوعی از مقادیر قرار دارند، بنابراین تغییرات ناچیزی که در برخی ویژگیها به وقوع میپیوندند، دیگر ویژگیها را تحت تاثیر قرار نمیدهند. بنابراین، بسیار اهمیت دارد که مقادیر برای همه ویژگیها در یک طیف خاص استاندارد شوند. اکنون، کار استانداردسازی دادهها برای تبدیل آنها به مقادیر بین ۰ و ۱ انجام میشود تا همه ویژگیها در طیف یکسانی قرار بگیرند.
0.6262626262626263
خیلی خوب است. میتوان مشاهده کرد که با انجام این کار، ٪۱۲ صحت افزایش یافته است. تا این لحظه، چگونگی بارگذاری دادهها، پیشپردازش آنها، انجام اندکی مهندسی ویژگیها و پیادهسازی و اعمال مدل K-Means بررسی شد. اما الگوریتم K-Means دارای محدودیتهایی نیز هست که در ادامه بیان میشوند.
معایب الگوریتم K-Means
اکنون که ساز و کار الگوریتم K-Means به خوبی مشخص شده است، برخی از معایب آن تشریح میشود. بزرگترین عیب الگوریتم K-Means آن است که نیاز به از پیش تعریف شدن تعداد خوشهها (K) دارد. اگرچه، برای مجموعه داده تایتانیک، با بهرهگیری از دانش دامنه این امکان وجود داشت که تعداد خوشهها (نجات یافتن یا نیافتن افراد) مشخص شود. این موضوع برای مسائل جهان واقعی همیشه صادق نیست. «خوشهبندی سلسلهمراتبی» (Hierarchical Clustering) رویکردی جایگزین است که نیازی به تعداد خوشهها ندارد. یک عیب دیگر الگوریتم K-Means این است که نسبت به «دورافتادگیها» (Outliers) حساس است و در صورت تغییر ترتیب دادهها ممکن است خروجیها تغییر کنند.
K-Means یک یادگیرنده تنبل است که عمومیسازی دادههای آموزش تا هنگامی که یک کوئری برای سیستم ایجاد شود، به تاخیر میافتد. این یعنی K-Means تنها زمانی کار میکند که برای انجام آن راه اندازی شود، بدین ترتیب روش یادگیری تنبل میتواند تخمین متفاوت یا نتایج متفاوتی را برای تابع هدف، جهت هر کوئری که با آن مواجه است فراهم کند. K-Means یک روش خوب برای «یادگیری آنلاین» (Online Learning) است، اما نیاز به میزان زیادی حافظه برای ذخیرهسازی دادهها دارد و هر درخواست شامل آغاز شناسایی مدل محلی از پایه میشود.
نتیجهگیری
در این راهنما، ساز و کار یکی از محبوبترین روشهای خوشهبندی، یعنی الگوریتم K-Means تشریح شد. سپس، یک بررسی موردی با استفاده از این الگوریتم انجام و در نهایت پیادهسازی مدل با بهرهگیری از کتابخانه Scikit-Learn پایتون انجام پذیرفت.
اگر نوشته بالا برای شما مفید بوده است، آموزشهای زیر نیز به شما پیشنهاد میشوند:
- مجموعه آموزشهای آمار، احتمالات و دادهکاوی
- آموزش خوشه بندی K میانگین (K-Means) با نرم افزار SPSS
- مجموعه آموزشهای یادگیری ماشین و بازشناسی الگو
- پیاده سازی الگوریتم های یادگیری ماشین با پایتون و R — به زبان ساده
- خوشه بندی k میانگین (k-means Clustering) — به همراه کدهای R
^^








سلام عالی
اما کاش ارزیابی مدل رو هم می گفتید
سلام خوب هستین خانم من به کمک شما نیاز دارم تو روخدا جواب بدین ….پروژه من داده کاوی روی داده های رمزنگاری شده همومورفیک….تو قسمت رمزنگاری ازPailierاستفاده کردم ی فایل از اعداد دارم که میگیره رمزنگاری میکنه بعد عملیات انجام میده و خروجی نشون میده الان تو قسمت داده کاوی موندم …که میخوام داده های که به ابر فرستاده میشن بعد تو \ایگاه داده ذخیره میشن به صورتk-meansخوشه بنذی کنم بنظرتون قابل اجرااست …توروخدا کمکم کنید6ماه درگیرشم
سلام ممنون بابت انتشار مقاله مفیدتون، 15 آپریل سال 1912 این کشتی غرق شد نه 2015!!
با سلام؛
از همراهی شما با مجله فرادرس و ارائه بازخورد، سپاسگزاریم. تاریخ در مطلب اصلاح شد.
پیروز، شاد و تندرست باشید.
سلام.
ممنون از مطالب مفیدتون.
لطاف کد ها رو با کامنت گذاری کمی بیشتری توضیح دهید که قابل فهمتر باشد.