



الگوریتم های طبقه بندی – توضیح ۸ الگوریتم به زبان ساده
به تازگی سازمانها و صنایع بسیاری از انواع مجموعهدادههای بزرگ در کارهای خود استفاده میکنند. پردازش و بررسی این حجم از اطلاعات به شکل سنتی، نه بهینه است و نه ارزشی دارد. در همین راستا و به جهت کسب بازدهی بیشتر از سرمایهگذاریهای انجام شده، استراتژیهای مختلفی از روشهای خودکارسازی ساده گرفته تا تکنیکهای یادگیری ماشین اعمال میشوند. یادگیری ماشین و بهطور ویژه الگوریتم های طبقه بندی، از جمله راهکارهای پرطرفدار و رایجی هستند که در کاربردهایی همچون پیشبینی نوع محصولات محبوب مشتری و طبقهبندی تصاویر یا متون در گروههای مختلف مورد استفاده قرار میگیرند. در این مطلب از مجله فرادرس، پس از آشنایی با مفهوم یادگیری ماشین و طبقهبندی، به بررسی عمیقتر ۸ نمونه پرکاربرد از الگوریتم های طبقه بندی میپردازیم.
- میآموزید تفاوت طبقهبندی با رگرسیون را تشخیص دهید.
- یاد میگیرید مراحل ساخت مدل طبقهبندی را بهصورت عملی اجرا کنید.
- نحوه پیادهسازی مهمترین الگوریتمهای طبقهبندی را خواهید آموخت.
- میآموزید از معیارهای ارزیابی مدل و انتخاب الگوریتم مناسب استفاده کنید.
- با مزایا و محدودیتهای الگوریتمهای مهم طبقهبندی آشنا میشوید.
- خواهید توانست کاربردهای طبقهبندی در حوزههای مختلف را تحلیل کنید.




در این مطلب، ابتدا تعریفی از الگوریتم های طبقه بندی ارائه داده و همچنین به بررسی و پیادهسازی انواع رایج آن میپردازیم. سپس با مراحل ساخت یک مدل طبقهبندی آشنا شده و در انتها پس از معرفی کاربرد الگوریتم های طبقه بندی، به چند مورد از پرسشهای متداول در این زمینه پاسخ میدهیم.
طبقه بندی چیست؟
الگوریتم های طبقه بندی نوع خاصی از یادگیری ماشین نظارت شده هستند که در آن، مدل سعی میکند برچسب درست دادههای ورودی را پیشبینی کند. در رویکرد طبقهبندی، آموزش مدل با استفاده از «مجموعه آموزشی» (Training Set) انجام شده و پیش از آنکه در معرض نمونههای جدید قرار بگیرد، نسبت به «مجموعه اعتبارسنجی» (Validation Set) ارزیابی میشود. همانطور که در تصویر زیر مشاهده میکنید، تشخیص ایمیلهای عادی از اسپم، یکی از موارد کاربردی الگوریتم های طبقه بندی به حساب میآید:

پیش از عمیقتر شدن در مفاهیم طبقهبندی، ابتدا باید درک مناسبی از تفاوت میان دو یادگیرنده تنبل و مشتاق بهدست آوریم و مرز میان طبقهبندی و «رگرسیون» (Regression) را نیز مشخص کنیم.
یادگیرنده تنبل و یادگیرنده مشتاق
انواع یادگیرندهها در الگوریتم های طبقه بندی یادگیری ماشین به دو دسته زیر تقسیم میشوند:
- «یادگیرندههای مشتاق» (Eager Learners): در این الگوریتمها ابتدا مدل یادگیری ماشین با استفاده از مجموعهداده آموزشی، ایجاد شده و سپس نسبت به مجموعهدادههای جدید مورد سنجش و ارزیابی قرار میگیرد. بهخاطر اشتیاق به «عمومیسازی» (Generalization) بهتر و یادگیری پارامترهای وزنی، عمده زمان یادگیرندههای مشتاق صرف فرایند آموزش میشود و به زمان کمتری برای پیشبینی نیاز دارند. اغلب الگوریتم های یادگیری ماشین از جمله «رگرسیون لجستیک» (Logistic Regression)، «ماشین بردار پشتیبان» (Support Vector Machine | SVM)، «درخت تصمیم» (Decision Tree) و «شبکههای عصبی عمیق» (Artificial Neural Networks) در گروه یادگیرندههای مشتاق قرار میگیرند.
- «یادگیرندههای تنبل» (Lazy Learners): برخلاف نوع قبلی، این دسته از الگوریتمها برای ساخت مدلهای یادگیری ماشین از دادههای آموزشی استفاده نمیکنند و به همین خاطر است که به آنها «تنبل» گفته میشود. در عوض، یادگیرندههای تنبل با بهخاطر سپردن مجموعهداده آموزشی، هر بار که نیاز باشد در آن جستجو کرده و پاسخ را پیدا میکنند. از همین جهت، عملکرد بسیار کندی در پیشبینی دارند و الگوریتمهای «K-نزدیکترین همسایه» (K-Nearest Neighbor) و «استدلال مبتنیبر مورد» (Case-based Reasoning) دو نمونه از یادگیرندههای تنبل بهشمار میآیند.

اگرچه باید توجه داشت که با بهرهگیری از الگوریتمهایی مانند «درخت کِیدی» (KDTree)، میتوان زمان پیشبینی را تا حدی بهبود بخشید.
تفاوت الگوریتم های طبقه بندی و رگرسیون در چیست؟
الگوریتمهای یادگیری ماشین به چهار دسته کلی «نظارت شده» (Supervised)، «نظارت نشده» (Unsupervised)، «نیمه نظارت شده» (Semi-supervised) و «یادگیری تقویتی» (Reinforcement Learning) تقسیم میشوند. در حالی که رگرسیون و الگوریتم های طبقه بندی، هر دو زیرمجموعه یادگیری نظارت شده هستند، با یکدیگر تفاوتهایی نیز دارند که در فهرست زیر ملاحظه میکنید:
- هنگامی که «متغیر هدف» (Target Variable) یا همان پاسخ از نوع گسسته باشد، یعنی با مسئلهای از جنس طبقهبندی روبهرو هستیم. تجزیه و تحلیل احساسات از روی متن، نمونهای کاربردی از الگوریتم های طبقه بندی است.
- فرایند پیشبینی از نوع رگرسیون است، وقتی پاسخها پیوسته باشند. به عنوان مثال، میتوان به پیشبینی حقوق افراد بر اساس مدرک، سوابق کاری، موقعیت مکانی و میزان مهارت اشاره کرد.

بسیاری از الگوریتمها وجود دارند که میتوان از آنها هم در مسائل طبقهبندی و هم رگرسیون استفاده کرد. الگوریتم های طبقه بندی در واقع نوعی مدل رگرسیونی با حد آستانه یا Threshold هستند. زمانی که خروجی بیشتر از حد آستانه باشد در کلاس مثبت و در غیر اینصورت در کلاس منفی جای میگیرد.
انواع الگوریتم های طبقه بندی
برای هر نوع مسئله و مجموعهدادهای، الگوریتم های طبقه بندی متنوعی وجود دارند که در ادامه این مطلب از مجله فرادرس، به معرفی و نحوه پیادهسازی ۸ نمونه کاربردی از آنها با استفاده از کتابخانه scikit-learn در زبان برنامهنویسی پایتون میپردازیم.

نصب کتابخانه مورد نیاز
برای نصب کتابخانه scikit-learn در زبان برنامهنویسی پایتون، کافیست فرمان زیر را اجرا کنیم:
sudo pip install scikit-learnبهطور کلی، طریقه نصب این کتابخانه برای تمامی سیستمهای عامل یکسان است. پس از وارد کردن فرمان بالا و برای آنکه از نصب آخرین نسخه این کتابخانه مطمئن شویم، قطعه کد زیر را اجرا میکنیم:
با اجرای قطعه کد نمونه، باید آخرین نسخه کتابخانه scikit-learn، مانند زیر به شما نمایش داده شود:
1.3.0توجه داشته باشید که در بخش پیادهسازی الگوریتم های طبقه بندی، مجموعهدادهای فراخوانی نمیشود و فرض بر این است که مجموعه آموزشی شما در دو متغیر X_train و y_train ، شامل مقادیر ورودی و برچسبها و همچنین مجموعه آزمون در متغیر X_test به عنوان نمونه دادههای جدید ذخیره شدهاند.
۱. الگوریتم رگرسیون لجستیک
هدف الگوریتم «رگرسیون لجستیک» (Logistic Regression)، پاسخ به مسائلی است که خروجی آنها را میتوان در چند کلاس مجزا گروهبندی کرد. برای این منظور، رگرسیون لجستیک از تابعی بهنام «سیگموئید» (Sigmoid) استفاده کرده و احتمال تعلق داشتن ورودی به هر کدام از کلاسها را محاسبه میکند.

به عنوان، مثال فرض کنید میخواهیم احتمال قبول شدن در یک امتحان را بر اساس میزان ساعت مطالعه بهدست آوریم. محور y همان احتمال قبولی در امتحان و محور x نشانگر تعداد ساعت مطالعه است. الگوریتم رگرسیون لجستیک به ما اجازه میدهد تا به عنوان مدل یادگیری ماشین، تابعی خطی را نسبت به نقاط داده ورودی برازش کنیم.

سپس نمونه ورودی به نسبت فاصلهاش با حد آستانهای که از پیش تعریف کردهایم، در یکی از دو گروه «قبول» یا «رد» قرار میگیرد. در قطعه کد زیر، پایهایترین حالت رگرسیون لجستیک را پیادهسازی کردهایم و بسته به مسئله، میتوانید پارامترهای کلاس LogisticRegression را تغییر دهید:
۲. الگوریتم بیز ساده
مدلهای «بیز ساده» (Naive Bayes) زیرمجموعهای از مدلهای خطی هستند که فرض میکنند ویژگیهای ورودی نسبت به یکدیگر مستقل هستند. یعنی با بررسی هر ویژگی بهصورت جداگانه و با استفاده از «قضیه بیز» (Bayes Theorem)، احتمال یک برچسب کلاسی برای نمونه ورودی محاسبه میشود. متفاوت با اغلب روش های یادگیری ماشین که وابستگی زیادی به مجموعهدادههای بزرگ دارند، الگوریتم بیز ساده حتی با مجموعهدادههای کوچک نیز عملکرد به نسبت قابل قبولی از خود به جا میگذارد. در قطعه کد زیر، پیادهسازی نوع خاصی از دستهبند بیز ساده را با عنوان «بیز ساده گاوسی» (Gaussian Naive Bayes) ملاحظه میکنید:
۳. الگوریتم درخت تصمیم
از الگوریتم «درخت تصمیم» (Decision Tree) به عنوان راهحلی رایج برای نمایش نتایج یک تصمیم یا رفتار در غالب احتمالات یاد میشود. بهطور خلاصه، درخت تصمیم نمایشی سلسله مراتبی از فضای خروجی است که در آن هر «گره» (Node) نماد یک انتخاب یا عمل و «برگها» (Leaves) همان برچسبها هستند. به دلیل پیروی از ساختاری مشخص که در ادامه فهرست کردهایم، الگوریتم درخت تصمیم از قابلیت تفسیرپذیری بالایی برخوردار است:
- شروع از گره «ریشه» (Root).
- پیدا کردن مسیر بعدی.
- تکرار این فرایند تا زمانی که یک مسیر به انتها رسیده و خروجی حاصل شود.
حالا میتوانیم مانند تصویر زیر، الگوریتم درخت تصمیم را در غالب ساختاری درختی ترسیم کنیم که در آن هر گره برگ، نشانگر یک برچسب است و شاخههای داخلی همان مسیرهای منتهی به پاسخ هستند.

در مثال بالا، میخواهیم ببینیم که آیا شرایط آبوهوایی، مناسب برگزاری مسابقه فوتبال هست یا خیر. اولین قدم، شروع از گره ریشه با برچسب «آبوهوا» است که وضعیت آبوهوا را نشان میدهد. در مرحله بعد، بسته به نوع آبوهوا که ممکن است آفتابی، ابری یا بارانی باشد، به یکی از گرههای «شرجی» یا «طوفانی» منتقل میشویم. سپس تا جایی به سمت پایین درخت حرکت میکنیم که به پاسخ نهایی یعنی «امکان برگزاری» یا «عدم امکان برگزاری» برسیم. پیادهسازی الگوریتم درخت تصمیم از طریق کلاس DecisionTreeClassifier انجام میشود:
۴. الگوریتم جنگل تصادفی
همانطور که از اسمش پیداست، «جنگل تصادفی» (Random Forest) مجموعهای از چند درخت تصمیم است. الگوریتم جنگل تصادفی، شیوه رایجی از روشهای ترکیبی با نتایجی تجمعی از چندین مدل پیشبینی کننده است. تکنیک Bagging یکی از روشهای مورد استفاده در جنگل تصادفی است که ابتدا هر درخت را با نمونههایی تصادفی از مجموعهداده اصلی آموزش داده و سپس کلاسی انتخاب میشود که بیشتری تکرار را در میان گرههای برگ داشته باشد. در مقایسه با درخت تصمیم، الگوریتم جنگل تصادفی قابلیت عمومیسازی بیشتر و تفسیرپذیری کمتری دارد. قطعه کد زیر، نمایشی از پیادهسازی الگوریتم جنگل تصادفی در زبان برنامهنویسی پایتون است:
۵. الگوریتم ماشین بردار پشتیبان
به گروهی از الگوریتم های طبقه بندی که دادههای شما را به یک فضای تصمیم خطی منتقل میکنند، «ماشین بردار پشتیبان» (Support Vector Machine | SVM) گفته میشود. این الگوریتم، دادهها را بر اساس مرزی با عنوان «ابَرصفحه» (Hyperplane) در دو کلاس مثبت و منفی طبقهبندی میکند. به عنوان مثال در مسئله شناسایی ایمیلهای اسپم، دادهها در دو گروه اسپم و عادی دستهبندی میشوند.

مشابه با درخت تصمیم و جنگل تصادفی، الگوریتم ماشین بردار پشتیبان نیز هم در مسائل طبقهبندی و هم رگرسیون کاربرد دارد. نوعی از این الگوریتم که در مسائل طبقهبندی استفاده میشود، «دستهبند بردار پشتیبان» (Support Vector Classifier | SVC) نام دارد که در قطعه کد زیر طریقه پیادهسازی آن را ملاحظه میکنید:
۶. الگوریتم K-نزدیکترین همسایه
میتوانید به الگوریتم «K-نزدیکترین همسایه» (K-Nearest Neighbour | KNN) به عنوان نمایی از نقاط داده در فضایی n بعدی نگاه کنید که n در واقع همان تعداد ویژگیهای ورودی است. نحوه کار الگوریتم KNN به این صورت است که فاصله میان هر نمونه با سایر نقاط داده را محاسبه کرده و سپس به نزدیکترین و دورترین نمونهها، برچسب «همسایه» یا «غیر همسایه» میدهد. از جمله مزایای KNN میتوان به موارد زیر اشاره کرد:
- تفسیرپذیری و پیادهسازی آسان.
- دقت بالا.

الگوریتم KNN در ساخت «سیستمهای توصیهگر» (Recommendation Systems) نیز کاربرد دارد. قطعه کد زیر، نمونهای از پیادهسازی این الگوریتم در زبان برنامهبنویسی پایتون است:
۷. الگوریتم تحلیل تبعیض خطی
از جلمه الگوریتم های طبقه بندی که پس از نگاشت دادههای آموزشی بر یک مرز تصمیم خطی، آنها را در کلاسهای مختلف گروهبندی میکند. وظیفه الگوریتم «تحلیل تبعیض خطی» (Linear Discriminant Analysis | LDA)، یافتن ابَرصفحهای است که همزمان با کمینهسازی «واریانس» (Variance) درونکلاسی، فاصله میان کلاسهای مختلف را بیشینه کند. بیشترین کاربرد الگوریتم LDA در مسائل «طبقهبندی چندکلاسه» (Multi-class Classification) است که میخواهیم دادهها را بر اساس ویژگیهای مشترک، در کلاسهای مختلف طبقهبندی کنیم.

پیادهسازی الگوریتم LDA با استفاده از کلاس LinearDiscriminantAnalysis و مانند نمونه انجام میشود:
۸. الگوریتم تحلیل تبعیض درجه دوم
گونه دیگری از الگوریتم LDA که برای مسائلی با فضای داده غیر خطی طراحی شده است. الگوریتم «تحلیل تبعیض درجه دوم» (Quadratic Discriminant Analysis | QDA) برخلاف رویه خطی الگوریتم LDA، دادهها را بر یک منحنی درجه دوم برازش میکند. همچنین نسبت به LDA و بهدلیل محاسبه واریانس درونکلاسی برای هر کلاس، پیچیدگی محاسباتی الگوریتم QDA بیشتر است. با این حال، اگر مجموعهداده بزرگی داشته باشید و نمونه دادهها به صورت خطی قابل جداسازی نباشند، الگوریتم QDA انتخاب بهتری باشد. برای پیادهسازی الگوریتم QDA از کلاس QuadraticDiscriminantAnalysis استفاده میکنیم:
علاوهبر روشهای ذکر شده، از رویکردهای دیگری مانند شبکههای عصبی عمیق نیز به عنوان الگوریتم های طبقه بندی بهرهبرداری میشود. با این حال، در این بخش به معرفی و پیادهسازی رایجترین الگوریتم های طبقه بندی پرداختیم.
مراحل ساخت یک مدل طبقه بندی
حال که با نمونههای مختلف الگوریتم های طبقه بندی آشنا شدیم، در این بخش عملکرد ۸ روش معرفی شده را بر مجموعهداده Heart Disease UCI از وبسایت Kaggle ارزیابی میکنیم.
فراخوانی و بررسی مجموعهداده
در این مثال، مجموعهداده Heart Disease UCI را برای پیشبینی وجود یا عدم وجود بیماری قلبی بر اساس معیارهای مختلف سلامتی انتخاب کردهایم. فراخوانی مجموعهداده از طریق تابع read_csv کتابخانه Pandas انجام شده و در ادامه، چهار نمونه اول را به نمایش میگذاریم:
جدول زیر، نتیجه فراخوانی تابع head از کتابخانه Pandas بر روی مجموعهداده است:

با بهکارگیری تابع info به شکل df.info() ، خلاصهای از ویژگیهای مختلف مجموعهداده همچون نوع داده و تعداد نمونهها حاصل میشود:

تحلیل داده اکتشافی
نمودار «هیستوگرام» (Histogram)، «نمودار میلهای گروهبندی شده» (Grouped Bar Chart) و «نمودار جعبهای» (Box Plot)، از جمله تکنیکهای مناسب «تحلیل داده اکتشافی» (Exploratory Data Analysis | EDA) برای الگوریتم های یادگیری ماشین هستند.

نمودار هیستوگرام
از آنجایی که تمام ویژگیها یا همان ستونهای مجموعهداده شامل مقادیر عددی هستند، نمودار هیستوگرام اطلاعات خوبی در اختیار ما قرار میدهد. پیادهسازی زیر، نمودار هیستوگرام را برای هر ۱۴ ویژگی ترسیم میکند:
اجرای قطعه کد بالا، مجموعه نمودارهای زیر را نتیجه میدهد:

محور عمودی با عنوان Frequency در تمامی نمودارهای هیستوگرام، میزان تکرار نمونههای مربوط به هر ویژگی را نشان میدهد.
نمودار میلهای گروهبندی شده
برای نشان دادن ارتباط میان تعداد دادهها با کلاس هدف، از «نمودار میلهای گروهبندی شده» (Grouped Bar Chart) استفاده میشود. اگر صرفنظر از مقدار ویژگی، توزیع متغیر هدف یکسان باشد، یعنی همبستگی میان ویژگی و کلاس هدف وجود ندارد. قطعه کد زیر، نحوه پیادهسازی نمودار میلهای گروهبندی شده را نشان میدهد:
پس از اجرای این قطعه کد، مجموعهای از نمودارهای میلهای مانند تصویر زیر حاصل میشود:
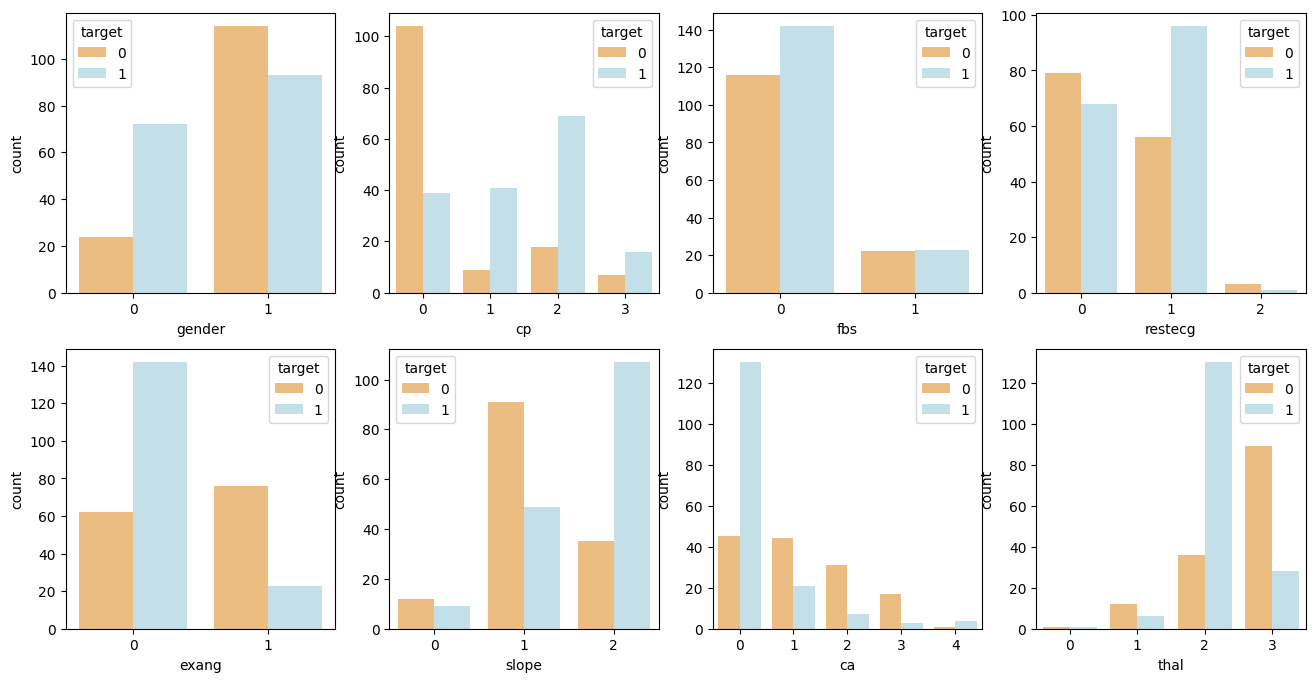
همانطور که در تصویر نیز مشاهده میکنید، به عنوان مثال، ویژگی جنسیت یا Gender، بهازای مقادیر ۰ و ۱، توزیع هدف متفاوتی دارد که یعنی احتمال مشارکت و سودمندی آن در پیشبینی نهایی زیاد است. در نمودارهای ترسیم شده محور افقی، ویژگیها و محور عمودی که با عنوان Count نمایش داده شده است، تعداد تکرار نمونههای مربوط به هر ویژگی را نشان میدهد. همچنین دو کلاس ۰ و ۱ به ترتیب با رنگهای زرد و آبی و عنوان Target نمایش داده شدهاند.
نمودار جعبهای
یکی دیگر از معیارهایی که تغییر ویژگیهای عددی را نسبت متغیر هدف نشان میدهد، «نمودار جعبهای» (Box Plot) نام دارد. برای نمایش نمودار جعبهای ویژگیهای ورودی مانند زیر عمل میکنیم:
پس از اجرای قطعه کد بالا، خروجی زیر حاصل میشود:
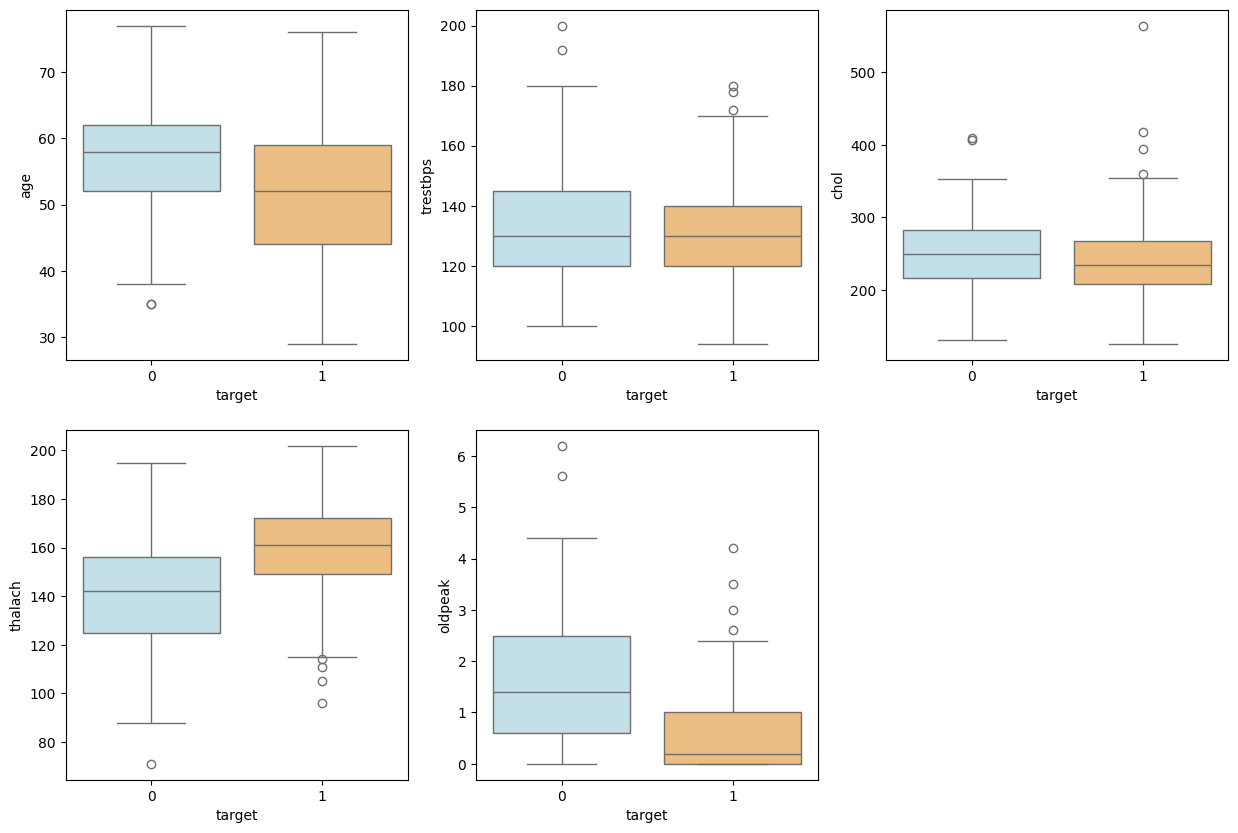
با توجه به نمودارهای ترسیم شده، ویژگی مانند oldpeak بهازای مقادیر ۰ و ۱، بازه تغییر متفاوتی داشته که نشاندهنده اهمیت آن در مسئله است. اما ویژگیهای دیگری مانند trestbps و chol برای هر کلاس هدف توزیع به نسبت یکسانی دارند و شاید بتوان با بررسی دقیقتر، آنها را حذف کرد. در هر کدام از نمودارهای ترسیم شده، محور افقی با عنوان Target، بیانگر برچسب کلاسی و محور عمودی، ویژگی یا همان ستونهای مجموعه داده را نشان میدهد.
تقسیم مجموعهداده به دو گروه آموزشی و آزمون
الگوریتم های طبقه بندی زیرشاخهای از یادگیری نظارت شده هستند و به همین خاطر، مجموعهداده باید به دو بخش آموزشی برای آموزش دادن مدل و مجموعه آزمایشی برای ارزیابی مدل یادگیری ماشین دستهبندی شود. متغیر هدف در مجموعهداده Heart Disease UCI برابر با ویژگی target است که از طریق تابع train_test_split ، مقادیر آن را در دو مجموعه آموزشی و آزمون ذخیره میکنیم:
ساخت مدل یادگیری ماشین
در این بخش، برای آنکه مقایسهای میان ۸ مدل معرفی شده انجام داده باشیم، ابتدا لیستی به نام model_pipeline ایجاد کرده و سپس نمونه شیءای از کلاس الگوریتم های طبقه بندی را به آن اضافه میکنیم:
در ادامه و در بخش ارزیابی مدل، با استفاده از یک حلقه تکرار، نتایج تمامی مدلهای ذخیره شده را بهدست میآوریم.
ارزیابی مدل
به عنوان برخی از معیارهای رایج در ارزیابی مدلهای طبقهبندی، میتوان به معیار «دقت» (Accuracy)، «نمودار مشخصه عملکرد» (Receiver Operating Characteristic | ROC)، «سطح زیر نمودار منحنی مشخصه عملکرد» (Area Under the ROC Curve | AUC) و «ماتریس درهم ریختگی» (Confusion Matrix) اشاره کرد. برای پیادهسازی معیارهای ارزیابی، مانند زیر عمل میکنیم:

معیار دقت
آسان و در عین حال رایجترین معیار برای ارزیابی عملکرد مدل، معیار «دقت» (Accuracy) است. برای محاسبه این معیار از معادله زیر استفاده میشود:
معیار ROC و AUC
نمودار مشخصه عملکرد یا همان ROC، معیاری برای نشان دادن نسبت نمونههای «مثبت درست» (True Positive | TP) به نمونههای «مثبت نادرست» (False Positive | FP) در چند حد آستانه مختلف است. معیار AUC نیز همان سطح زیر نمودار ROC است و هر چقدر بیشتر باشد، یعنی مدل از عملکرد بهتری برخوردار است.

ماتریس درهم ریختگی
با مقایسه مقادیر حقیقی و مقادیر پیشبینی شده، «ماتریس درهم ریختگی» (Confusion Matrix) تعداد نمونههای «منفی درست» (True Negative | TN)، «مثبت نادرست» (False Positive | FP)، «منفی نادرست» (False Negative | FN) و «مثبت درست» (True Positive) را در فرمت ماتریس ذخیره میکند.

برای ترسیم ماتریس درهم ریختگی الگوریتم های طبقه بندی، از کتابخانه Seaborn زبان برنامهنویسی پایتون کمک میگیریم:
نتیجه اجرای قطعه کد بالا را در تصویر زیر مشاهده میکنید. توجه داشته باشید که در ماتریسهای رسم شده، عنوان Actual Values همان مقادیر حقیقی و Predicted Values برابر با مقادیر پیشبینی شده است.
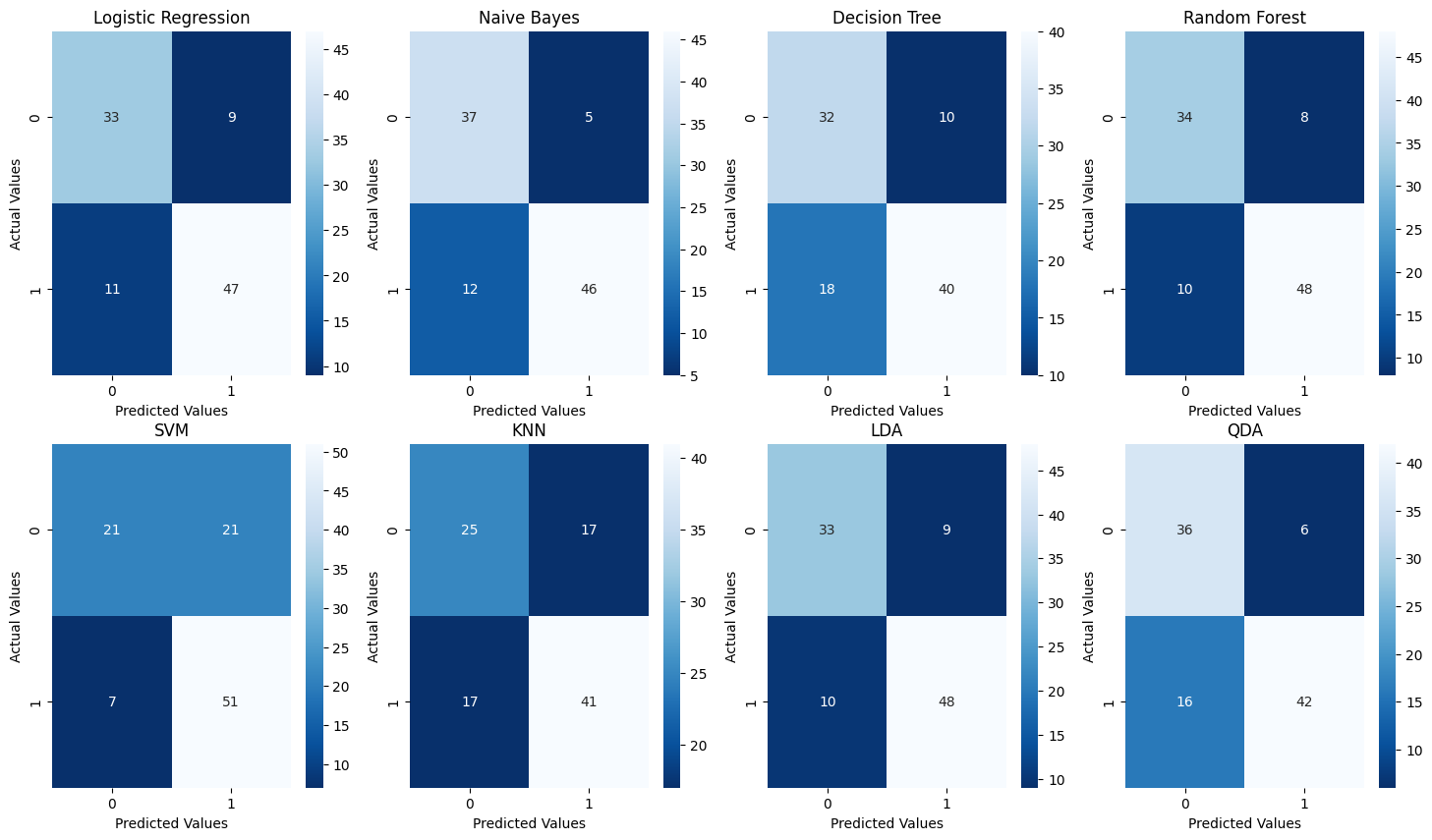
در مرحله بعد، برای نمایش معیار دقت و AUC الگوریتم های طبقه بندی، مانند زیر عمل میکنیم:
خروجی پیادهسازی بالا، جدولی مانند نمونه است:

همانطور که در جدول نیز مشاهده میکنید، بر اساس سه معیار بهکار گرفته شده، الگوریتم های طبقه بندی جنگل تصادفی و بیز ساده بهترین و الگوریتم KNN ضعیفترین عملکرد را دارد؛ اما نه به این معنی که الگوریتم های جنگل تصادفی و بیز ساده بهصورت کلی بهتر هستند. بلکه تنها میتوان گفت که این دو الگوریتم برای مجموعهداده ما که اندازه به نسبت کوچکی داشته مناسبتر بودهاند.
هر الگوریتم مزیتهای خود را داشته و نیازمند تکنیکهای پردازش داده و مهندسی ویژگی منحصربهفردی است. به عنوان مثال الگوریتم KNN به توزیع متفاوت ویژگیها حساس است و مشکل «همخطی چندگانه» (Multicollinearity) بر نتیجه رگرسیون لجستیک اثر میگذارد. آشنایی با ویژگیهای هر الگوریتم به ما این امکان را میدهد تا مطابق با مجموعهدادهای که داریم، مناسبترین راهحل را برای مسئله خود انتخاب کنیم.
کاربرد الگوریتم های طبقه بندی
الگوریتم های طبقه بندی، کاربردهای بسیاری در صنایع مختلف و همچنین زندگی روزمره ما دارند. خدمات درمانی، آموزش و پرورش، حمل و نقل و کشاورزی پایدار از جمله این کاربردها هستند که در ادامه به بررسی هر کدام میپردازیم.

خدمات درمانی
آموزش دادن یک مدل یادگیری ماشین با استفاده از سوابق پزشکی بیمار، به متخصصان این امکان را میدهد تا تحلیل دقیقتری از تشخیصهای خود بهدست آورند:
- در زمان همهگیری کرونا، مدلهای یادگیری ماشین مختلفی برای پیشبینی موثر علائم کووید ۱۹ معرفی و پیادهسازی شدند.
- پژوهشگران میتوانند با استفاده از مدلهای یادگیری ماشین، بیماریهای ناشناختهای که ممکن است در آینده شیوع پیدا کنند را پیشبینی و شناسایی کنند.
آموزش و پرورش
حوزه آموزش و پرورش بهرهبرداری زیادی از محتوای متنی، ویدئویی و صوتی دارد. تجزیه و تحلیل این نوع محتوای «بدون ساختار» (Unstructured) با کمک فناوریهای زبان طبیعی در زمینههای بسیاری مورد استفاده قرار میگیرد؛ همچون:
- طبقهبندی اسناد مرتبط.
- خودکارسازی فرایند بررسی مدارک دانشآموزان.
- تجزیه و تحلیل احساسات دانشآموزان نسبت به معلمان.

حمل و نقل
از حمل و نقل به عنوان یکی از مهمترین اجزای توسعه اقتصاد کشورها یاد میشود. به همین خاطر، صنایع به استفاده از مدلهای «یادگیری عمیق» (Deep Learning) روی آوردهاند:
- پیشبینی موقعیت جغرافیایی مکانهای شلوغ.
- پیشبینی وقوع مشکلات ناشی از شرایط آبوهوایی.
کشاورزی پایدار
تصور بقای انسان بدون کشاورزی غیرممکن است. پایدارسازی فرایند کشاورزی، بهرهوری کشاورزان را بدون آسیب دیدن محیط در سطوح مختلفی بهبود میبخشد:
- استفاده از الگوریتم های طبقه بندی برای شناسایی زمین مناسب در جهت کاشت دانههای گیاهی.
- پیشبینی آبوهوا برای انجام اقدامات پیشگیرانه.
سوالات متداول درباره الگوریتم های طبقه بندی
پس از آشنایی با انواع الگوریتم های طبقه بندی و یادگیری نحوه پیادهسازی آنها، در این بخش به چند مورد از سوالات متداول این حوزه پاسخ میدهیم.
چرا از الگوریتم های طبقه بندی استفاده میکنیم؟
طبقهبندی نوعی یادگیری ماشین نظارت شده است که در پیشبینی برچسب دادههای ورودی مورد استفاده قرار میگیرد.
چه الگوریتم هایی هم در مسائل طبقه بندی و هم رگرسیون کاربرد دارند؟
الگوریتم ماشین بردار پشتیبان یا به اختصار SVM و شبکههای عصبی در مسائل طبقهبندی و رگرسیون کاربرد دارند.
کدام الگوریتم ها برای طبقه بندی چندکلاسه مناسب هستند؟
درخت تصمیم، بیز ساده، جنگل تصادفی و KNN، از جمله محبوبترین الگوریتمهایی هستند که در طبقهبندی چندکلاسه بهکار گرفته میشوند.
چه الگوریتم هایی برای مجموعه داده های کوچک بهتر هستند؟
در مواردی که مجموعهداده کوچکی داشته باشیم، الگوریتم های طبقه بندی رگرسیون لجستیک، SVM و بیز ساده، بهترین عملکرد را نتیجه میدهند.
جمعبندی
الگوریتم های طبقه بندی از جمله پایهایترین انواع یادگیری ماشین محسوب میشوند. همانطور که در این مطلب از مجله فرادرس خواندیم، روشهایی همچون ماشین بردار پشتیبان، ساختارهای درختی مانند جنگل تصادفی و درخت تصمیم، KNN و رگرسیون لجستیک، چند نمونه پراستفاده از الگوریتم های طبقه بندی هستند. الگوریتمهایی که به مدلهای یادگیری ماشین این امکان را میدهند تا از دادههای آموزشی یاد گرفته و سپس آموختههای خود را در کاربردهای حقیقی بهکار گیرند.








