طراحی آزمایش چیست؟ – کامل ترین راهنما + معرفی کتاب
طراحی آزمایش راهی برای از پیش برنامهریزی کردن یک آزمایش است بهصورتی که نتایج به دست آمده از آن آزمایش، بیطرفانه و مستدل باشد. در طراحی آزمایش تمرکز بیشتر از نتایج حاصل، روی خود طراحی است. در این مطلب از مجله فرادرس میخواهیم بدانیم طراحی آزمایش چیست و چه انواعی دارد. همچنین با بررسی تعدادی مثال که در آنها از این روشها استفاده شده است، تلاش میکنیم درک خود را از این مفهوم افزایش دهیم. در پایان نیز به معرفی نرمافزارهایی پرداختهایم که میتوان از آنها برای طراحی آزمایش بهره گرفت.
- یاد خواهید گرفت که مفاهیم پایه و متغیرهای کلیدی طراحی آزمایش چیست.
- یاد میگیرید که چگونه معیارهای صحت، تکرارپذیری و مستندسازی را رعایت کنید.
- خواهید آموخت که انواع ساختارهای طراحی آزمایش را شناسایی و انتخاب کنید.
- میآموزید که روش تخصیص تصادفی تیمارها و کنترل سوگیری چگونه اجرا میشود.
- خواهید توانست تاثیر تعامل عوامل را با Design Factorial و ANOVA تحلیل کنید.
- روش استفاده از نرمافزارهای تخصصی DOE و کاربردهای صنایع را یاد خواهید گرفت.
- میآموزید که آزمایش را با رعایت محدودیتهای اخلاقی و کنترل آماری انجام دهید.
- با منابع حرفهای برای یادگیری بیشتر طراحی آزمایش و انتخاب راه ادامه آشنا میشوید.




روش طراحی آزمایش چیست ؟
«طراحی آزمایش» (Design Of Experiments) که آن را بهصورت مخفف با DOE یا DOX نیز نمایش میدهند، طراحی فرآيندی است که با هدف توصیف و توضیح گوناگونی اطلاعات تحت شرایط فرضی انجام میشود. به این فرآیند «طراحی آزمایشی» (Experimental Design) یا (Experiment Design) نیز میگویند. این مفهوم به آزمایشهایی اشاره دارد که در طراحی آنها، شرایطی که بهصورت مستقیم روی متغیرها تاثیرگذار هستند را در نظر میگیریم. با این حال میتواند به طراحی «شبه آزمایشها» (Quasi Experiments) نیز اشاره داشته باشد که در آن به بررسی شرایط طبیعی میپردازیم که روی متغیرها تاثیر میگذارند.
در سادهترین حالت طراحی آزمایش، آزمایش به هدف پیشبینی نتایج با اعمال تغییر در شرایط، طراحی میشود. این تغییرات توسط یک یا دو «متغیر مستقل» (Independent Variables)، که از آنها به عنوان «متغیر ورودی» (Input Variables) یا «متغیر پیشگو» (Predictor Variables) نیز یاد میشود، در این آزمایشها صورت میگیرد.
بهطور معمول فرض بر این است که تغییر در یک یا دو متغیر غیروابسته باعث تغییر در یک یا تعداد بیشتری «متغیر وابسته» (Dependent Variables) میشود. از متغیر وابسته با نامهای «متغیر خروجی» (Output Variables) یا «متغیر پاسخ» (Response Variables) نیز یاد میشود. یکی دیگر از مواردی که در طراحی آزمایش در نظر گرفته میشود، شناسایی و تشخیص «متغیر کنترل» (Control Variables) است که باید ثابت نگه داشته شود تا از تاثیر عوامل خارجی بر آزمایش، جلوگیری شود. طراحی آزمایش علاوه بر انتخاب متغیرهای مناسب وابسته، مستقل و کنترل، تلاش بر انجام آزمایش در شرایط بهینهای دارد که در منابع موجود، محدودیتهای آن، ذکر شده است. رویکردهای متفاوتی برای تعیین مجموعه ویژگیهای طراحی که شامل ترکیبی از تنظیمات برای متغیرهای مستقل است، برای به کارگیری در آزمایش وجود دارد.
ملزومات طراحی آزمایش
مهمترین دغدغهای که در طراحی آزمایش وجود دارد، ایجاد و برقراری سه مفهوم «صحت» (Validity)، «اطمینانپذیری» (Reliability) و «تکرارپذیری» (Replicability) است. بهطور مثال میتوان این دغدغهها را با انتخاب متغیرهای مستقل بهصورت دقیق و کاهش ریسک خطای اندازهگیری، برطرف کرد. همچنین نیاز است که مستندسازی روش انجام آزمایش با وجود جزئیات کافی، انجام شود. دغدغه دیگری که وجود دارد رسیدن به سطح مناسبی از «توان آماری» (Statistical Power) و «حساسیت» (Sensitivity) است.
آزمایشهایی که بهطور صحیح طراحی شده باشند، باعث افزایش آگاهی و دانش در زمینه علوم طبیعی، اجتماعی و مهندسی میشوند که در آنها روششناسی طراحی آزمایشها، ابزاری کلیدی برای اجرای موفقیتآمیز الگوی «کیفیت در طراحی» (Quality By Design) است. از دیگر کاربردهای طراحی آزمایش میتوان به بازاریابی و ایجاد خطیمشی و راهکار اشاره کرد. مطالعه طراحی آزمایش یکی از مهمترین موضوعات مطرح در «فراعلم» (Metascience) است.
انواع طراحی آزمایش و مفاهیم مرتبط
طراحی آزمایش مفهومی کلی است و در هر مورد میتوان آن را با توجه به ویژگیهای نمونه و نوع نتایجی که نیاز داریم، طراحی و انتخاب کرد. در زیر تعدادی از انواع طراحی آزمایش را مورد بررسی قرار میدهیم. همچنین در این توضیحات با مفاهیم آماری زیادی نیز روبرو خواهید شد که تلاش کردهایم با توضیح آنها، درک مطلب را آسانتر کنیم.
طراحی میان موضوعی
در «طراحی میان موضوعی» (Between Subject Design) گروههای جداگانهای تشکیل میشود تا تیمارهای متفاوت روی آنها آزمایش شود. در برخی موارد به این نوع طراحی آزمایش، «طراحی اندازهگیریهای مستقل» (Independent Measures Design) نیز گفته میشود. برای مثال در آزمایشهای مربوط به حوزه پزشکی برای بررسی اثر یک دارو، دو گروه در نظر گرفته میشوند. گروه اول بنا به تجویز پزشک دارو را در زمانهای مورد نیاز دریافت میکنند اما به گروه دوم «دارونما» (Placebo) داده میشود. دارونماها ترکیبهایی هستند که بهصورتی طراحی میشوند که هیچ اثر بیولوژیکی و درمانی در بدن نداشته باشند و از آنها برای مقایسه تاثیر یک داروی تازه سنتز شده، استفاده میشود. شرکتکنندگان تنها در یکی از این دو گروه گنجانده میشوند. در این حالت اگر قصد مقایسه بیش از ۱ دارو را داشته باشیم، باید گروه سومی نیز به آزمایش افزوده شود.
مزایا و معایب طراحی میان موضوعی
هر روشی که برای طراحی آزمایش مورد استفاده قرار میگیرد، مزایا و معایبی دارد که با دانستن آنها میتوان روش مناسب برای هر آزمایش را انتخاب کرد. طراحی میان موضوعی یکی از سادهترین روشهای طراحی آزمایش است و میتوان از مزایای آن به امکان بررسی تیمارهای مختلف بهصورت همزمان اشاره کرد. بهعلاوه این روش نسبت به دیگر روشهای سرعت بالایی دارد. از بزرگترین معایب این روش میتوان به این نکته اشاره کرد که هر شرکتکننده تنها یک بار تحت آزمایش قرار میگیرد و با افزوده شدن بر تیمارهای جدید باید گروههای جدیدی نیز شکل بگیرند که در این صورت با بالا رفتن تعداد تیمارها، آزمایش بسیار پیچیده میشود.
طراحی آزمایش کاملا تصادفی
«طراحی کاملا تصادفی» (Completely Randomized Design) نوعی از آزمایش است که در آن تیمارها بهصورت تصادفی به نمونهها نسبت داده میشوند. در این صورت هر نمونه آزمایشی شانس برابری برای دریافت هر تیمار دارد. با این حال از این نوع طراحی بهطور معمول در آزمایشگاهها استفاده میشود که میتوان در آن عوامل محیطی را آسانتر، کنترل کرد. در صورتی که در این طراحی تنها دو تیمار وجود داشته باشد، مانند «تی تست» (T Test) خواهد بود.
نحوه انجام طراحی آزمایش کاملا تصادفی
در این روش ابتدا از سطوح مختلف تیمار یا انواع آنها فهرستی تهیه میشود و سپس آنها را به اعداد مختلف نسبت میدهند. این اعداد در واقع همان نمونهها است.
مثال طراحی آزمایش کاملا تصادفی
در این بخش برای درک بهتر این روش میخواهیم مثالی را مورد بررسی قرار دهیم. در این مثال میخواهیم تاثیر ۴ کود شیمیایی مختلف را بر ۱۶ نمونه از سیبزمینی در گلخانهای مطالعه کنیم. در اولین مرحله باید تیمارهای مختلف را فهرست کنیم. همانطور که پیشتر گفتیم در این مورد ۴ کود (تیمار) مختلف وجود دارد که آنها را بهصورت A B C D نامگذاری میکنیم. همچنین به هر نمونه سیبزمینی نیز عددی را نسبت میدهیم. برای درک آسانتر آن را بهصورت زیر نمایش دادهایم.

در مرحله بعد اعداد ۱ تا ۱۶ را، هر کدام روی قطعهای کاغذ یادداشت کنید و در یک ظرف قرار دهید. سپس روی ۱۶ قطعه کاغذ دیگر، حروف A B C و D را نیز، هر کدام ۴ مرتبه، بنویسید و در ظرف دیگری قرار دهید. سپس یک کاغذ از ظرف اول و یک کاغذ از ظرف دوم بردارید و به این صورت تیمار هر نمونه مشخص میشود. نتیجه را میتوان بهصورت جدول زیر نمایش داد.

توجه داشته باشید که این روش نیز خالی از اشکال نیست، زیرا سیبزمینیهایی که در ردیفهای بیرونی قرار دارند، میتوانند در عمل نور خورشید بیشتری را جذب کنند و نتایج را تحت تاثیر قرار دهند.
طراحی فاکتوریال
طراحی فاکتوریال برای بررسی تاثیر دو یا تعداد بیشتری متغیر مستقل روی یک متغیر وابسته به کار گرفته میشود. در این مورد مثالی را برای درک بهتر در ادامه میآوریم. محققی میخواهد تاثیر عوامل مختلف بر نمره «آزمون SAT» دانشآموزان را بررسی کند. سه موردی که برای این کار در نظر میگیرد، بهصورت زیر هستند.
- کلاس متمرکز SAT (بله یا خیر)
- کتابهای آمادگی SAT (بله یا خیر)
- تکالیف مازاد (بله یا خیر)
محقق تصمیم دارد تمامی این این متغیرهای مستقل را دستکاری کند. به هر کدام از این متغیرهای یک عامل گفته میشود و هر کدام دو سطح (بله یا خیر) دارند. از آنجا که در این آزمایش ۳ عامل، با ۲ سطح وجود دارد، طراحی ۸ عاملی است. این را میتوان بهصورت زیر به دست آورد.
بخش عمدهای از نمونههای آزمایشهای فاکتوریالی تنها دارای دو سطح هستند. در صورتی که تعداد نمونهها و سطوح بسیار زیاد و غیرقابل کنترل باشد، میتوان آنها را تقسیمبندی کرد و از روشهای دیگر مثلا از «طراحی آزمایش جزئی» (Fractional Exprimental Design) استفاده کرد.
نتیجه بیارزش
«نتیجه بیارزش» (Null Outcome) زمانی به دست میآيد که نتایج حاصل از یک آزمایش فارغ از نمونهها و سطوح، همواره یکسان باشد. برای مثال اگر در مثال بالا، مقادیر متفاوت متغیرها، هیچ تاثیری روی نمره آزمون SAT نداشته باشند، نتیجه به دست آمده بیارزش است.
اثر اصلی و اثر برهمکنش
در تحلیل نتایج به دست آمده از آزمایش فاکتوریالی دو نوع تاثیر «اثر اصلی» (Main Effect) و «اثر برهمکنش» (Interaction Effect) در نظر گرفته میشوند. اثر اصلی، اثری است که متغیرهای مستقل روی متغیر وابسته میگذارند. برای وجود داشتن اثر اصلی باید روند ثابتی از آن را روی سطوح مختلف مشاهده کنید. برای مثال در مورد بالا، ممکن است اینطوری نتیجهگیری کنید که دانشآموزانی که از کلاسهای آمادگی آزمون استفاده کردهاند، همواره نتیجه بهتری از دانشآموزان دیگر به دست آوردهاند. اثر برهمکنش بین عوامل اتفاق میافتد. برای مثال گروهی از دانشآموزان که در کلاسهای آمادگی شرکت و از کتابهای آموزشی استفاده کردهاند نسبت به گروهی از دانشآموزان که در کلاسهای آمادگی شرکت کردهاند اما کتابهای آموزشی را مطالعه نکردهاند، نتایج بهتری به دست آوردهاند. در این صورت بین این دو عامل برهمکنشی وجود دارد که خود روی نتیجه تاثیرگذار خواهد بود.
طراحی جفت همسان
«طراحی جفت همسان» (Matched Pairs Design) نوع بهخصوصی از طراحی قطعهای تصادفی است. در این طراحی، دو تیمار به گروههای همگن نسبت داده میشوند. هدف از این طراحی بیشینهسازی همگونی در هر جفت است. به عبارت دیگر، میخواهیم این جفتها تا مقدار ممکن به یکدیگر شباهت داشته باشند. قطعههای این طراحی از جفتهای همسانی تشکیل شدهاند که تیمارها بهصورت تصادفی به آنها نسبت داده میشوند.
مطالعه شهودی
«مطالعه شهودی» (Observational Study) که از آن با عنوان آزمایش طبیعی یا شبه آزمایش نیز یاد میشود، آزمایشی است که در آن آزمایشگر، شرکتکنندگان را مشاهده میکند و بدون نسبت دادن تیمار به آنها، متغیرها را اندازهگیری میکند. در این مورد مثالی را مورد بررسی قرار میدهیم.
آزمایشی را تصور کنید که هدف از آن بررسی تاثیر «درمان شناختی» (Cognitive Therapy) بر افراد مبتلا به «اختلال کمبود توجه بیشفعالی» (Attention Deficit Disorder Hyperactivity) است. در آزمایش شهودی، برخی از مراجعان درمان شناختی را دریافت میکنند و برخی دیگر تحت انواع درمانهای دیگری قرار میگیرند یا اصلا تحت درمان قرار نمیگیرند. در یک مطالعه شهودی مراجعانی را مییابید که در حال حاضر تحت درمان هستند یا در درمانهای دیگری شرکت میکنند.
بهصورت ایدهآل، تیمارها باید بهصورت تصادفی به مراجعان نسبت داده شود و مورد بررسی قرار گیرند. این نسبت دادن تصادفی به این معناست که مشخصات اندازه گرفته شده و اندازه گرفته نشده بهصورت مساوی در گروهها پراکنده شده است. به عبارت دیگر، هر تفاوت مشاهده شده بین گروهها بنابر شانس است. هر آزمایش آماری روی این گروهها میتواند نتایج قابل اطمینانی به دست دهد. با این حال انجام این نوع آزمایشها بهخصوص در مطالعات بالینی از نظر اخلاقی صحیح نیست و میتواند باعث آسیب به مراجع شود. بنابراین در چنین مواردی از آزمایش شهودی استفاده میشود.
مطابقت
در برخی حوزههای مطالعاتی، اندازهگیری مستقل برای استاندارد اندازهشناسی قابل ردیابی، ممکن نیست. به همین دلیل استفاده از «مطابقت» (Comparison) بین روش اجراها ارزش بیشتری دارد و معمولا مطلوب است. این مورد اغلب با «کنترل علمی» (Scientific Control) یا روشهای سنتی پایهای مقایسه میشود.
انتخاب تصادفی
«انتخاب تصادفی» (Randomization) فرآیندی است که طی آن افراد بهصورت تصادفی به گروهها یا گروههایی متفاوتی در یک آزمایش نسبت داده میشوند. در این حالت هر فرد در یک جمعیت شانس برابری برای حضور در مطالعه خواهد داشت. اختصاص تصادفی افراد به گروه (یا شرایطی در گروه)، آزمایشی دقیق و واقعی، نسبت به یک مطالعه شهودی یا شبه مطالعه است. شمار زیادی نظریههای ریاضی وجود دارد که عواقب تخصیص واحدها به تیمارها را به کمک مکانیسم تصادفی بررسی میکنند. (از این مورد میتوان به جدول اعداد تصادفی، استفاده از ابزارهای تصادفیسازی، مانند کارت و تاس اشاره کرد.) اختصاص واحدها به تیمارها بهصورت تصادفی، باعث تعدیل اختلالات میشود که به دلیل وجود عواملی به غیر از تیمار، بر نتایج اثرگذار هستند.
ریسک مرتبط با تخصیص تصادفی، مانند وجود عدم توازن در ویژگیهای کلیدی بین گروه تیمار و گروه کنترل، قابل محاسبه است و به همین دلیل میتوان آن را به کمک واحدهای آزمایشی کافی، به حد قابل قبولی کاهش داد. با این حال اگر جمعیتی به زیرشاخههای کوچکتری تقسیمبندی شود که با یکدیگر تفاوتهایی دارند و مطالعه نیازمند این باشد که این زیرشاخهها با یکدیگر از نظر اندازه برابری کنند، میتوان از «نمونهگیری طبقهبندی شده» (Stratified Sampling) استفاده کرد. در این صورت واحدهای هر زیرشاخه، تصادفی هستند اما این در مورد کل نمونه صدق نمیکند. در صورتی که واحدهای آزمایشی، نمونهای تصادفی از جمعیت بزرگتری باشند، نتایج یک آزمایش را میتوان با اطمینان از واحدهای آزمایشی به جمعیت آماری بزرگتری تعمیم داد. خطای احتمالی این برونیابی بستگی به اندازه نمونه دارد.
تکرار آماری
اندازهگیریها معمولا در معرض تغییر و عدم قطعیت اندازهگیری قرار دارند، بنابراین تکرار میشوند و کل آزمایش نیر برای یافتن منشا این تغییرات تکرار میشود. به این صورت میتوان تخمین بهتری از تاثیرهای واقعی تیمارها داشت و صحت و قابلیت اطمینان آزمایش را بالا برد. تنها در این حالت است که میتوان به دانش موجود در آن حوزه افزود. با این حال توجه داشته باشید که پیش از آغاز تکرار آزمایش باید به شرایط خاصی دست پیدا کرد. در فهرست زیر میتوانید تعدادی از این شرایط را مشاهده کنید.
- سوال اصلی تحقیق باید در مجلهای کارشناسی شده یا با دفعات ارجاع بالا منتشر شده باشد.
- محقق باید مستقل از آزمایش اصلی باشد. یعنی در انجام آن هیچ دخالت و شرکتی نداشته باشد.
- نخست محقق باید تلاش کند تا یافتههای اصلی را به کمک اطلاعات اصلی تکرار کند.
- این نکته که این مطالعه، تکراری از مطالعهای دیگر است که تلاش کرده شرایط واکنش را تا حد ممکن و سختگیرانه تکرار کند، باید در مکتوبات آورده شود.
قطعهبندی
«قطعهبندی» (Blocking) در واقع طبقهبندی واحدهای آزمایش به گروههایی (قطعهها) است که در آن واحدها به یکدیگر شبیه باشند. قطعهبندی باعث کاهش منابع مشخص اما غیرمرتبط به مرجع تغییرات بین واحدها میشود و به این صورت باعث افزایش دقت در تخمین منبع تغییر در مطالعه میشود.
تعامد
«تعامد» (Orthogonality) شکل مقایسهای (تضادها) را مدنظر قرار میدهد که میتواند بهدرستی و کارآمدی انجام شود. تضادها را میتوان با بردارها نشان داد و مجموعهای از تضادهای تعامدی، نامرتبط هستند و در صورتی که دادهها معمولی باشند، بهطور مستقل توزیع میشوند. به دلیل همین عدم وابستگی، هر تیمار تعامدی نسبت به دیگری اطلاعات متفاوتی به دست میدهد. برای مثال اگر تعداد تیمارها برابر با و تعداد تضادهای تعامدی برابر با باشد، تمامی اطلاعاتی که از آزمایش قابل دستیابی هستند را میتوان از مجموعه تضادها به دست آورد.
آزمایشهای چند فاکتوریالی
در مواقعی از «آزمایشهای چند فاکتوریالی» (Multifactorial Expriments) به جای آزمایشیهایی استفاده میشوند که در هر زمان تنها یک عامل را در نظر دارند. این آزمایشهای در نشان دادن تاثیرات و برهمکنشهای احتمالی چند عامل (متغیرهای مستقل) کارآمد هستند. تحلیل طراحی آزمایش بر مبنای تحلیل واریانس صورت میگیرد که مجموعهای از مدلهاست که واریانس مشاهده شده را به اجزای سازنده تقسیمبندی میکند. این کار با توجه به عواملی صورت میگیرد که در آزمایش قصد داریم آنها را تخمین بزنیم یا روی آنها آزمایشهایی را انجام دهیم.
جلوگیری از بروز خطای مثبت کاذب
استنتاج مثبت کاذب، که معمولا از عجله برای منتشر کردن یک مطالعه یا «سوگیری تایید» (Confirmation Bias) ناشی میشود، یک خطر ذاتی است که در بسیاری از زمینهها وجود دارد. یکی از راه حلهایی که میتوان برای جلوگیری از سوگیری منتج به ایجاد خطای مثبت کاذب در مرحله جمعاوری اطلاعات به کار برد، «طراحی دوگانه کور» (Doiuble Blind Design) است.
طراحی دوگانه کور
زمانی که از طراحی دوگانه کور استفاده میکنیم، شرکتکنندهها بهصورت تصادفی به گروههای آزمایشی تقسیمبندی میشوند اما آزمایشگر از تعلق هر شرکتکننده به گروه آزمایشی خود، با خبر نیست. در این صورت آزمایشگر نمیتواند تاثیری روی پاسخ شرکتکننده داشته باشد و تاثیر سوگیری حذف خواهد شد. طراحی آزمایشهایی با درجه آزادی نامعلوم، خود مشکلی به وجود میآورد. این مورد میتوان باعث به وجود آمدن «سلاخی داده» (P-Hacking) شود که در آن آزمایشگر موارد متعددی را امتحان میکند تا به نتیجه مورد نظر خود برسد. این اتفاق معمولا با دستکاریهایی، بعضا ناخودآگاه، در فرآيند تحلیل آماری و درجات آزادی همراه است. این اتفاق تا زمانی ادامه مییابد که مقدار «معناداری آماری» (Statistical Significance) به زیر برسد. از همین جهت، طراحی آزمایش باید دارای دستورالعملی باشد که آنالیزهای مورد نیاز را آورده باشد. میتوان با پیش ثبتنام تحقیقات از سلاخی داده جلوگیری کرد. در این روش محقق باید پیش از جمعآوری و اندازهگیری دادهها، به مجلهای که تمایل دارد مطالعه خود را در آن منتشر کند، روش خود در تحلیل اطلاعات را بفرستد. در این صورت میتوان اطمینان حاصل کرد که امکان دستکاری در اطلاعات به دست آمده وجود ندارد.
یک راهکار دیگر برای جلوگیری از سلاخی داده، استفاده از طراحی دوگانه کور در فاز تحلیلی است. در این روش اطلاعات به دست آمده برای تحلیلگر داده ارسال میشود. این فرد در اندازهگیری این دادهها نقشی ندارد، بنابراین از تعلق هر داده و فرد به دسته خود، آگاهی ندارد و سوگیری از بین خواهد رفت. همچنین نیاز است که از مراحل آزمایش، طبق روششناسی آزمایش، مستندات دقیق و شفافی تهیه شود تا تکرارپذیری آن را تضمین کند.
اسناد علی
در یک طراحی آزمایش خالص، متغیرهای مستقل توسط محقق، دستکاری میشود بهصورتی که تمام شرکتکنندگان مطالعه، به شکل تصادفی از یک جمعیت انتخاب میشوند و هر شرکتکننده نیز بهصورت تصادفی به شرایط متغیرهای مستقل نسبت داده میشود. تنها در این صورت است که میتوان با مشاهده تفاوت در نتایج مطمئن بود که از شرایط ناشی شدهاند. بنابراین در صورت امکان، محققان باید طراحی آزمایش را به جای انواع روشهای دیگر طراحی انتخاب کنند. با این حال طبیعت دادههای مستقل بهصورتی است که در مواردی نمیتوان به آنها دست برد. در این موراد محققان باید بر عدم تایید «اسناد علی» (Casual Attribution) در صورت عدم اجازه طراحی، آگاه باشند. برای مثال در طراحی شهودی، شرایط را بهصورت تصادفی به شرکتکنندگان نسبت نمیدهند. در این صورت اگر در نتایج متغیرها تحت شرایط متفاوت، اختلافی مشاهده شود، متوجه خواهیم شد که عاملی به غیر از شرایط باعث به وجود آمدن این تفاوت در نتایج به دست آمده شده است که به آن متغیر سوم میگوییم. گفتههای بالا در مورد طراحی تحقیق همبستگی نیز صدق میکند.
کنترل آماری
بهتر است که هر فرآيندی پیش از انجام طراحی آزمایش تحت کنترل آماری معقولی باشد. در صورتی که این مورد ممکن نباشد، قطعهبندی مناسب، تکرارپذیری و انتخاب تصادفی به انجام طراحی آزمایش بهصورت دقیق کمک میکنند. برای کنترل «متغیرهای مزاحم» (Nuisance Variables) محققان از «بررسیهای کنترلی» (Control Checks) برای اندازهگیریهای بیشتر کمک میگیرند. محققان باید اطمینان حاصل کنند که عوامل موثر کنترل نشده، نتایج به دست آمده از مطالعه را تحتالشعاع قرار ندهند. «کنترل دستکاری» (Manipulation Check) نمونهای از بررسیهای کنترلی است. کنترل دستکاری به محققان اجازه میدهد تا متغیرهای اصلی را با پشتیبانی قوی، جدا کنند تا طبق برنامه، عملکرد داشته باشند.
متغیر جعلی
یکی از مهمترین نیازمندیهای طراحی آزمایش این است که تاثیر «متغیرهای جعلی» (spurious Variables)، «متغیرهای مداخلهگر» (Intervening Variables) و «متغیرهای پیشین» (antecedent Variables) را حذف کند. در اغلب مدلهای پایهای، علت به معلول میانجامد اما در مواردی ممکن است متغیر سومی نیز وجود داشته باشد که آن را با نماد نمایش میدهیم. این متغیر سوم نیز میتوان خود بهصورت علتی عمل کند و روی تاثیر بگذارد و ممکن است علت واقعی نباشد. به این متغیر سوم، متغیر جعلی میگوییم و باید آن را کنترل کنیم. همین گفتهها در مورد متغیر مداخلهگر نیز صدق میکند. متغیر مداخلهگر مابین علت و معلول قرار دارد. همچنین متغیر پیشین، متغیری است که بر علت ارجح باشد. زمانی که متغیر سومی بهصورت کنترل نشده حضور داشته باشد، رابطه از نوع «رابطه صفر درجه» (Zero Order Relationship) خواهد بود. در بسیاری از مثالهای عملی و کاربردی طراحی تحقیق، علتهای متعددی وجود دارند و در هر زمان تنها یکی از این موارد مورد دستکاری قرار میگیرند تا بتوان تاثیر هر متغیر را مورد بررسی قرار داد.
محدودیت شرکتکننده انسانی
قوانین و ملاحظات اخلاقی مانع از انجام برخی آزمایشهای با دقت طراحی شده بر روی انسانها میشود. این ملاحظات قانونی به صلاحدید سیستم قضایی بستگی دارد. این ملاحظات شامل کمیته بررسی نهادی، رضایت آگاهانه و محرمانه بودن میشود که هم بر «کارآزمایی بالینی» (Clinical Trial)، هم آزمایشهای علوم اجتماعی تاثیر میگذارد. برای مثال در «سم شناسی» (Toxicology)، آزمایشها روی حیوانات آزمایشگاهی و با هدف مشخص کردن مقدار مجاز برای در معرض قرار گرفتن برای انسان به انجام میرسد. در زمینه انتخاب تصادفی بیمارها، اگر هیچ فردی بهترین مسیر تیمار را نداند، برای انتخاب مسیر تیمار، محدودیت اخلاقی وجود ندارد. همچنین در زمینه طراحی آزمایش، واضح است که در معرض خطر قرار دادن سوژه آزمایش در شرایطی که خود آزمایش به خوبی تعریف نشده است، اخلاقی نخواهد بود.
روند تکامل طراحی آزمایش
با توجه به اهمیت طراحی آزمایش در رشتههای گوناگون، میخواهیم کمی در مورد تاریخچه طراحی آزمایش بدانیم و روند پیشرفت و تکامل آن را مورد بررسی قرار دهیم.
آزمایشهای آماری
نظریه «استنباط آماری» (Statistical Inference) توسط «چارلز سندرز پیرس» (Charles S. Peirce) در سال ۱۸۷۷ تا ۱۸۷۸ میلادی در کتاب «توصیف منطق علم» (Illustrations Of The Logic Of Science) و در سال ۱۸۸۳ در کتاب «نظریهای بر استنباط محتمل» (A Theory Of Probable Inference) عنوان شده است. این دو عنوان بر اهمیت استنباطهای تصادفی در آمار تاکید دارند.

آزمایشهای تصادفی
چارلز سندرز پیرس داوطلبانی را برای طراحی آزمایشی کور، با اندازهگیریهای مکرر برای سنجش توانایی آنها در تشخیص تفاوت بین وزنهای مختلف، در نظر گرفت. این آزمایش برای محققان در زمینههای دیگر از جمله روانشناسی الهامبخش بود و باعث به وجود آمدن پیشرفت در طراحی این مدل آزمایشها شد. در منابع آن سالها میتوان این آزمایشها را بهوفور یافت.
طراحی بهینه برای مدلهای رگرسیونی
چارلز سندرز پیرس در تهیه اولین کتاب انگلیسی زبان برای طراحی بهینه مدلهای رگرسیونی در سال ۱۸۷۶ شرکت داشت. پیش از این «جوزف دیز گرگون» (Joseph Dies Gergonne) ریاضیدان فرانسوی در سال ۱۸۱۵ میلادی، طراحی بهینه برای رگرسیون چندجملهای را پیشنهاد داده بود. همچنین در سال ۱۹۱۸ «کریستین اسمیت» ریاضیدان هلندی، کتابی برای طراحی بهینه چندجملهایهای درجه ۶ و کمتر از آن به چاپ رساند.
آزمایشهای متوالی
استفاده از آزمایشهای متوالی که در آنها طراحی هر آزمایش به نتایج آزمایش قبلی بستگی دارد، از جمله تصمیم احتمالی برای متوقف کردن آزمایش، مورد توجه است. ابداع و گسترش این حوزه توسط «آبراهام والد» (Abraham Wald) ریاضیدان مجار در آزمایشهای متوالی برای نظریههای آماری انجام شده است. «هرمان چرنوف» (Herman Chernoff) مروری بر طراحیهای بهینه متوالی نوشته است. یکی از انواع طراحیهای بهینه، «راهزن دودست» (Two Armed Bandit)، زیرشاخه «راهزن چند دست» (Multi Armed Bandit) است که مطالعات اولیه آن در سال ۱۹۵۲ میلادی توسط «هربرت رابینز» (Herbert Robbins) انجام شده است.
قوانین فیشر
در کتابهای «رونالد فیشر» (Ronald Fisher)، روشی برای طراحی آزمایش پیشنهاد شده است. این دو کتاب با عناوین «طبقهبندی آزمایشهای میدانی» (The Arangement Of Field Expriment) در سال ۱۹۲۶ میلادی و «طراحی آزمایشها» (The Design Of Expriments) در سال ۱۹۳۵ به چاپ رسیده است. بسیاری از کارهای ابتدایی او به کاربرد طراحیهای آماری در کشاورزی اختصاص دارد. در ادامه یکی از نظریههای او را مورد بررسی قرار میدهیم. او در «نظریه خانم چاینوش» (Lady Tasting Tea Hypothesis) اینطور بیان میکند که خانمی تنها با چشیدن چای میتواند تشخیص دهد که کدام یک از ترکیبات، چای یا شیر، در ابتدا به فنجان اضافه شدهاند. این روش کاربرد گستردهای در تحقیقات بیولوژی، روانشناسی و کشاورزی پیدا کرده است.
طراحی آزمایش بعد از فیشر
برخی از طراحیهای کارآمد برای تخمین چنین اثر اصلی بهصورت مستقل و با موفقیت بالایی توسط «راج چاندرا بوس» (Raj Chandra Bose) و « کی کیشن» (K. Kishen) در سال ۱۹۴۰ میلادی در موسسه آمار هند به وجود آمده است. این طراحیها تا سال ۱۹۴۶ میلادی که طراحی «پلکت برمن» (Plackett-Burman) در مجله Biometrika به چاپ رسید، خیلی شناخته نشدند. در همین زمان، «کالیامپودی رادهاکریشنا رئا» ( Calyampudi Radhakrishna Rao) مفهوم «آرایه متعامد» (Orthogonal Arrays) را در طراحی آزمایش مطرح میکند. این مفهوم نقشی کلیدی در پیشرفت «روش تاگوچی» (Taguchi Method) توسط «گنیچی تاگوچی» داشته است که در سال ۱۹۵۰، همزمان با بازدید او از موسسه آمار هند به وجود آمد. روش او در صنایع ژاپن و هند به کار گرفته شد و به موفقیتهای خوبی دست پیدا کرد. سپس این روش در سالهای بعد توسط صنایع آمریکایی نیز با اندکی تغییر مورد استفاده قرار گرفت.
در سال ۱۹۵۰، «گرترود مری کاکس» (Gertrude Mary Cox) و «ویلیام کوکران» (William Gemmel Cochran) کتابی با نام Experimental Designs منتشر کردند که در سالهای پس از آن به عنوان اصلیترین مرجع برای طراحی آزمایشها مورد استفاده قرار گرفت.
توسعهدهندگان روش «مدل خطی» (Linear Models) مواردی که دغدغه نویسندگان پیش از خود بود را برطرف کردهاند. این نظریه شامل موضوعات پیشرفتهتری مانند «جبرخطی» (Linear Algebra)، «جبر» (Algebra) و «ترکیبیات» (Combinatorics) میشود.
مانند باقی شاخههای آماری، طراحی آزمایش نیز به کمک دو ریکرد «فراوانیگرا» (Frequenist) و «بیزی» (Bayesian) دنبال میشود. در ارزیابی رویههای آماری مانند طراحی آزمایش، آمار فراوانگرایانه، توزیع نمونه را مطالعه میکند در حالی که آماری بیزی روی توزیع احتمال مانور میدهد.
مثالی از طراحی آزمایش
در این بخش میخواهیم مثالی از طراحی آزمایش را مورد بررسی قرار دهیم. این طراحی آزمایش را به «هارولد هتلینگ» (Harold Hotelling) نسبت میدهند که بر اساس مثالهای «فرانک یاتس» (Frank Yates) طراحی شده است. آزمایش طراحی شده در این مثال شامل «طراحی ترکیبی» (Combinatorail Design) است. در ادامه مختصات و شرایط انجام آن را آوردهایم.
در این آزمایش وزن ۸ جسم متفاوت توسط یک ترازوی دوکفهای اندازهگیری در برابر مجموعهای از وزنههای استاندارد، سنجیده میشود. در هر اندازهگیری، تفاوت وزن بین اجسام در کفه سمت چپ با اجسام در کفه سمت راست، مورد اندازهگیری قرار میگیرد. در صورتی که دو جسم در کفه راست و چپ با یکدیگر تفاوت وزن داشته باشند، با افزودن وزنههای استاندارد سعی بر برقراری تعادل بین آنها داریم. هر اندازهگیری دارای خطایی تصادفی است. میانگین این خطاها برابر با ۰ است، مقدار انحراف استاندارد توزیع احتمال خطاها در اندازهگیریهای متفاوت با یکدیگر یکسان است. خطای مشاهده شده در هر اندازهگیری مستقل است. وزن واقعی هر جسم را با نمایش میدهیم. مثلا عبارت ، وزن به دست آمده از جسم ۱ را نشان میدهد.
در این مورد دو آزمایش متفاوت را در نظر میگیریم که به شرح زیر هستند:
- وزن هر جسم را در صورتی اندازه میگیریم که خود آن جسم در یک کفه ترازو و کفه دیگر خالی باشد. در این مورد وزن هر جسم را با نماد نشان میدهیم که در آن ، مقداری از ۱ تا ۸ دارد و عدد جسم را مشخص میکند.
- در مورد دوم اندازهگیری را با توجه به جدول زیر انجام میدهیم که یک «ماتریس توزین» (Weighing Matrix) است.
| شماره جسم | کفه سمت چپ | کفه سمت راست |
| ۱ | ۸ ۷ ۶ ۵ ۴ ۳ ۲ ۱ | - |
| ۲ | ۸ ۳ ۲ ۱ | ۷ ۶ ۵ ۴ |
| ۳ | ۸ ۵ ۴ ۱ | ۷ ۶ ۳ ۲ |
| ۴ | ۸ ۷ ۶ ۱ | ۵ ۴ ۳ ۲ |
| ۵ | ۸ ۶ ۴ ۲ | ۷ ۵ ۳ ۱ |
| ۶ | ۸ ۷ ۵ ۲ | ۶ ۴ ۳ ۱ |
| ۷ | ۸ ۷ ۴ ۳ | ۶ ۵ ۲ ۱ |
| ۸ | ۸ ۶ ۵ ۳ | ۷ ۴ ۲ ۱ |
برای انجام این آزمایش ابتدا مقدار را برای تمامی موارد به دست میآوریم. سپس مقدار را به کمک رابطه زیر تخمین میزنیم.
با توجه به همین الگو، میتوان محاسبات را برای اجسام دیگر نیز بهصورت زیر به انجام رساند.
سوالی که در اینجا و با انجام این محاسبات مطرح میشود این است که کدام یک از آزمایشها به پاسخ بهتری دست پیدا میکند؟
اگر از آزمایش اول استفاده کنیم، مقدار واریانس برای برابر با خواهد بود اما در صورت استفاده از آزمایش دوم مقدار این واریانس برابر با است. از اینجا میتوان متوجه شد که آزمایش ۲، برای اندازهگیری و تخمین یک مورد، به میزان ۸ برابر دقت بیشتری دارد و تمامی موارد را با دقتی برابر و در یک زمان به انجام میرساند. نتیجهای که از ۸ بار اندازهگیری توسط آزمایش ۱ به دست میآید را در صورتی که هر اندازهگیری جداگانه انجام شود، باید با ۶۴ بار آزمایش به دست آورد. با این حال توجه داشته باشید که تخمینهای به دست آمده از آزمایش دوم دارای خطاهایی است که به یکدیگر مرتبط هستند. در بسیاری از طراحیهای آزمایش، مانند این مثال از طراحی ترکیبی استفاده میشود.
کاربرد طراحی آزمایش چیست؟
از مفهوم طراحی آزمایش در مهندسی، علوم پایه و علوم اجتماعی استفاده میشود. در زیر فهرستی از حوزههایی که از طراحی آزمایش بهره میبرند را آوردهایم.
- برآورد ساختارهای فیزیکی، مواد و اجزای سازنده
- فرمولاسیون شیمیایی
- برنامههای کامپیوتری
- نظرسنجیها
- آزمایشهای طبیعی
- بررسیهای آماری
موضوعات مورد بحث در انجام یک طراحی آزمایش
برخی از این موارد را در بخشهای قبلی مورد بررسی قرار دادهایم. در فهرست زیر میتوانید تعداد از مهمترین این موضوعات را مشاهده کنید.
- این طراحی چند عامل دارد و سطوح این عوامل ثابت هستند یا تصادفی؟
- آیا کنترل بر شرایط مورد نیاز است و اگر بله، چه کنترلهایی باید باشد؟
- چک کردن دستکاریها و اینکه آیا این دستکاریها واقعا کارکرد دارند؟
- متغیرهای زمینهای کدامها هستند؟
- اندازه نمونه چقدر است؟ در این آزمایش برای داشتن مشمولیت نیاز به جمعآوری چه تعداد واحد داریم و آیا توان کافی وجود دارد؟
- چه ارتباطی در برهمکنشهای بین عوامل وجود دارد؟
- تاثیر تاخیر عوامل اساسی بر نتایج حاصل چیست؟
- استفاده مکرر از یک ابزار اندازهگیری با واحدهای یکسان در بازههای زمانی متفاوت چقدر شدنی و ممکن است؟ در مورد «پیش آزمون» (Post Test) و «پس آزمون» (Follow Up Test) چطور؟
- پرسش پیشین در مورد پیش آزمون پروکسی نیز صدق میکند؟
- در این آزمون «متغیر در کمین» (Lurking Variables) نیز حضور دارند؟
- آیا نیاز است که بیمار یا مراجع از شرایط این آزمون بیخبر باشد؟ در مورد فرد تحلیلگر آزمایش چطور؟
- آیا به کارگیری متوالی شرایط متفاوت با واحدهای یکسان شدنی و ممکن است؟
- چه تعداد از عوامل کنترل و ایجاد خطا را باید در آن در نظر داشته باشیم؟
متغیرهای مستقل یک مطالعه معمولا سطوح مختلفی دارند و در دستههای متفاوتی نیز حضور دارند. در یک آزمایش واقعی، آزمایشگرها میتوانند گروهی آزمایشی داشته باشند که در آن فرضیههای خود را به آزمایش میگذارند. همچنین گروه دیگری نیز به نام گروه کنترل حضور دارند که تمامی موارد آن مانند گروه آزمایشی است و هیچ عنصر مداخلهگری در آنها حضور ندارد. بنابراین زمانی که تمامی موارد به غیر از یک مورد مداخلهگر ثابت هستند، آزمایشگر با بررسی گروه کنترل میتواند اطمینان حاصل کند که تغییر مشاهده شده، حتما تحت تاثیر همین عامل است.
با این حال توجه داشته باشید که در برخی نمونهها داشتن گروه کنترل اخلاقی نیست. در موارد این چنینی یکی از راهحلهای موجود استفاده از دو گروه آزمایشی متفاوت است. همچنین در برخی موارد متغیرهای مستقل را نمیتوان دستکاری کرد. مثالی از این مورد آزمایش روی دو گروه است که هر کدام مبتلا به بیماریهای متفاوتی از یکدیگر هستند. مثال دیگری آزمایش روی تفاوتهای بین «جنسهای» (Genders) متفاوت است. در این موارد میتوان با طراحی یک شبه آزمایش مشکل را از سر راه برداشت.
نرم افزار طراحی آزمایش
همانطور که تا اینجا مشاهده کردید، از طراحی آزمایش در بسیاری از زمینههای مطالعاتی و تحقیقاتی استفاده میشود. با پیشرفت این روش، متخصصان توانستهاند نرمافزارهای آماری را طراحی کنند که بتوان به کمک آنها طراحی آزمایش را با سرعت هرچه بیشتر و دقت و جزئیات بهتر، به انجام رساند. برای این کار نرمافزارهای بسیار متعددی وجود دارد که بنا به نیاز میتوان از آنها کمک گرفت. در ادامه میخواهیم به بررسی تعدادی از این نرمافزارها بپردازیم.
نرم افزار NCSS
این نرمافزار به کاربر در روند طراحی آزمایش یاری میرساند تا بتواند برنامهریزی و تحلیل مطالعه خود را بهراحتی انجام دهد. زمانی که برای تحقیق خود محدودهای انتخاب کردید، ماژول طراحی، برای جمعآوری دادهها، طرحی را پیشنهاد میدهد تا بتوان تعداد دادهها را به حداقل رساند و با آنها بیشترین مقدار اطلاعات ممکن را به دست آورد.
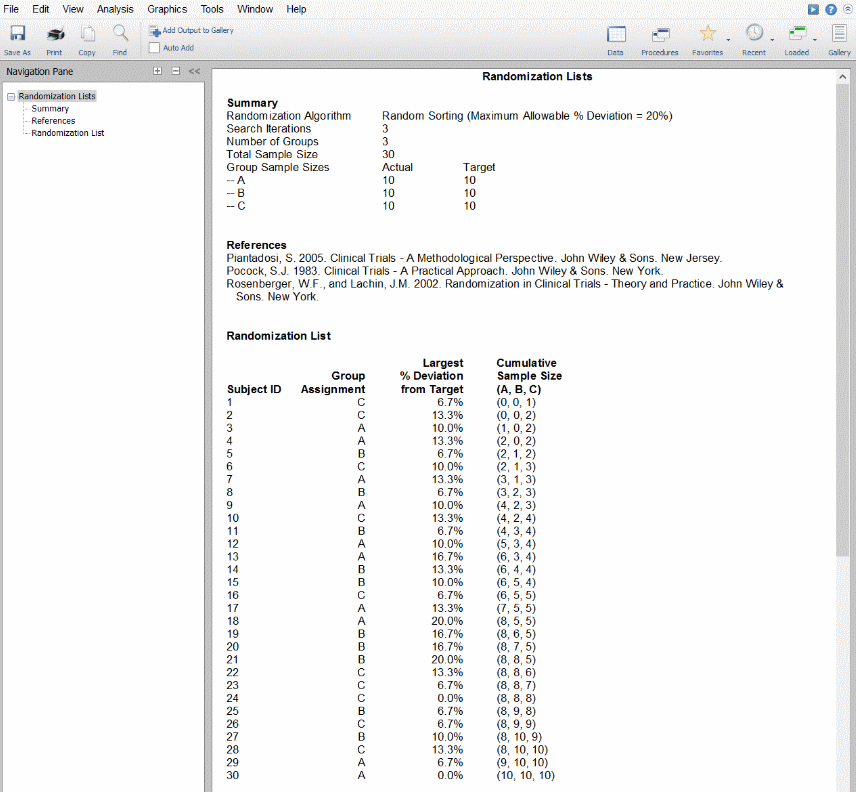
فهرست انتخاب تصادفی
از دستورالعمل فهرست انتخاب تصادفی در نرمافزار NCSS برای دستهبندی شرکتکنندگان به گروههای مختلف تیمار استفاده میشود.این نرمافزار برای انتخاب تصادفی ۶ الگوریتم را در اختیار کاربر قرار میدهد. چهار الگوریتم به یک دسته تعلق دارند که از بیشینه درصد انحراف مجاز استفاده میکنند و برای آن طراحی شدهاند تا نمونههای تصادفی متعادلی را در روند آزمایش ایجاد کنند. در تصویر زیر نمونهای از ورودیهای طراحی آزمایش در این نرمافزار را مشاهده میکنید.

دو الگوریتم دیگر پیچیدگی کمتری دارند اما احتمال عدم تعادل بالاتری نیز دارند. دادههایی که این نرمافزار در اختیار کاربر قرار میدهد را در تصویر زیر مشاهده میکنید.
طراحی قطعه متعادل ناقص
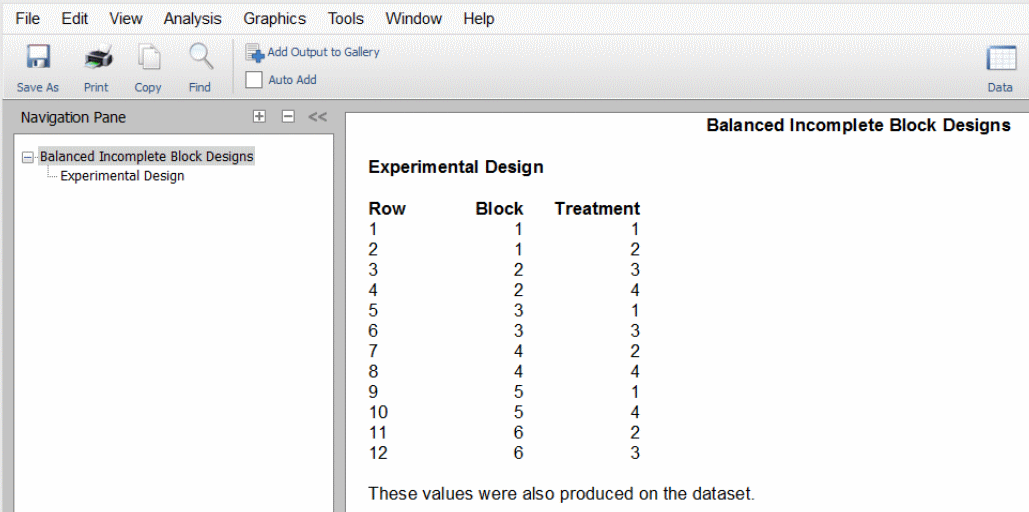
در طراحی «قطعه متعادل ناقص» (Balanced Incomplete Block)، تیمارها بهصورتی به قطعات نسبت داده میشود، که تعداد دفعات آن در هر قطعه با قطعه دیگر برابر باشد. به همین دلیل به این طراحی، متعادل بودن را نسبت میدهیم و این تعادل به این معناست که تفاوت بین تیمارها با دقت برابری اندازهگیری میشود. برای اندازهگیری دقیق، باید شرایط آزمایش یکنواخت باقی بماند. با این کار میتوان مطمئن بود که تفاوتهای مشاهده شده، به دلیل تفاوت در عملکرد تیمارها است و عوامل خارجی در آن نقشی ندارد. بهترین نوع طراحی که به این صورت انجام میشود، «طراحی قطعه تصادفی» (Randomized Block Design) است. در این طراحی تمامی تیمارها در تمامی قطعات وجود دارند.
در برخی موارد اندازه این قطعات بهصورتی است که نمیتواند تمامی تیمارها را در خود جای دهد. برای مثال تصور کنید در آزمایشی میخواهیم ۴ نوع لاستیک ماشین متفاوت را از نظر مقدار سایش مورد بررسی قرار دهیم. بهترین قطعهای که میتوان برای این آزمایش در نظر گرفت یک خودرو است. در این صورت میتوان با توجه به نوع هر اتومبیل و مسیری که طی کرده است، قضاوتی در مورد مقدار سایش ایجاد شده بر هر ۴ لاستیک داشت. با این حال اگر نمونه شامل ۶ لاستیک خودرو باشد،بایستی چکار کنیم؟
در این صورت هم میتوان خودرو را بازطراحی کرد، هم از روش طراحی قطعه متعادل ناقص استفاده کرد. در زیر میتوانید نمونهای را مشاهده کنید که در آن ۴ تیمار مختلف به ۳ واحد آزمایشی نسبت داده شدهاند که از نظر اندازه خنثی هستند. برای انجام این طراحی به ۴ قطعه نیاز داریم.
| قطعه | تیمار |
| ۱ | A B C |
| ۲ | A B D |
| ۳ | A C D |
| ۴ | B C D |
توجه داشته باشید که هر تیمار در آزمایش ۳ بار اتفاق میافتد. همچنین با کمی دقت متوجه میشویم که هر زوج تیمار، دو بار در همراهی با هم قرار میگیرند. این دو یکی از ویژگیهای اصلی طراحی متعادل ناقص است. به قوانین زیر توجه کنید.
- نسبت دادن تصادفی اعداد به قطعهها
- نسبت دادن تصادفی حروف به تیمارها
- نسبت دادن تصادفی تیمارها به قطعهها
- قطعههای تصادفی تکرار میشوند.
با طی کردن این مراحل در صورتی که تعداد تیمارها و قطعهها با یکدیگر برابر نباشد، میتوانید طراحی کارآمدی را اجرا کنید. در تصویر زیر به تعداد قطعهها و تیمارها در هر مورد توجه کنید.
طرح فاکتوریال جزئی
در این مورد، «طرح فاکتوریال جزئی دو سطحی» (Two Level Fractional Factorial Desing) با بیش از ۱۶ عامل با قطعهبندی ایجاد میشود. گزارشها الگوی همخوانی مورد استفاده را نشان میدهند. ردیفهای طرح میتواند در خروجی بهصورت استاندارد یا تصادفی باشد. این نرمافزار کتابخانهای از اطلاعات دارد که بنابر کتاب Box and Hunter منتشر شده در سال ۱۹۷۸ است. در ابتدای طراحی، نرمافزار وجود یا عدم وجود طراحی را در این کتاب مورد بررسی قرار میدهد. در صورتی که این طراحی در کتاب وجود نداشته باشد، الگوی طراحی از استاندارد پیروی میکند و برهمکنشهایی با مرتبه بالاتر در ابتدا قرار میگیرند. این روند باید بهصورتی باشد که اثرات اصلی یکدیگر را خنثی نکنند. نمونهای از این طراحی در محیط نرمافزار NCSS را میتوانید در تصویر زیر مشاهده کنید.

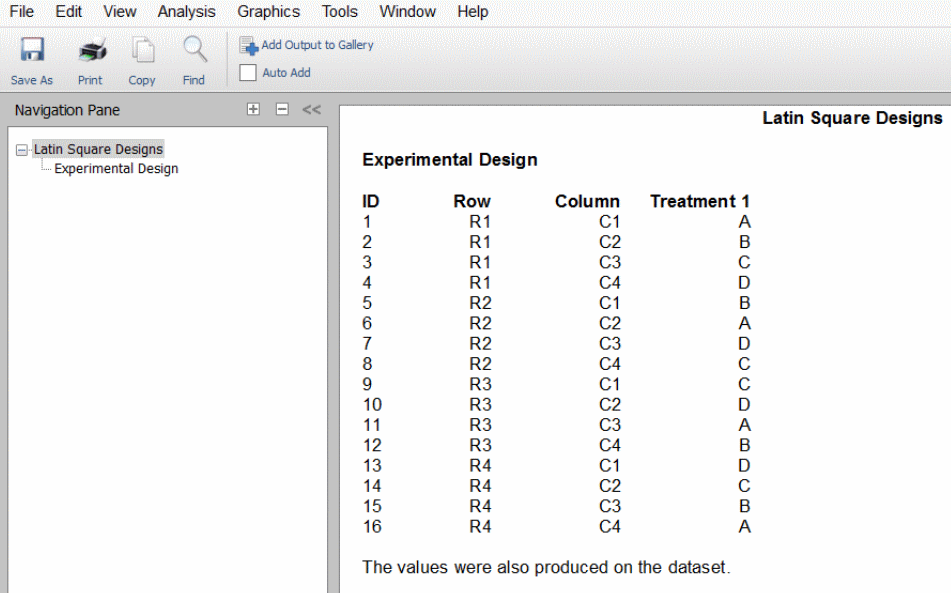
طرح مربع لاتین
این روش دو طرح «مربع لاتین» (Latin Square) و «مربع لاتین گریکو» (Graeco Latin Square) را ایجاد میکند. طراحیهایی که در این روش وجود دارند حاوی ۳ تا ۱۰ تیمار هستند. طراحی مربع لاتین مانند طراحی قطعه با انتخاب تصادفی است با این تفاوت که به جای حذف یک متغیر مسدودکننده، طراحیها بهصورتی انجام میشود که به دو عامل مسدودکننده اجازه حذف شدن میدهند. این کار با کاهش تعداد واحدهای آزمایشی مورد نیاز برای انجام آزمایش، صورت میگیرد. در جدول زیر میتوانید نمونهای از طرح مربع لاتین با ۴ تیمار را مشاهده کنید.
| واحد آزمایشی | تیمار |
| ۱ | A B C D |
| ۲ | B C D A |
| ۳ | C D A B |
| ۴ | D A B C |
در جدول بالا، ۴ تیمار را مشاهده میکنید که با حروف A، B، C و D مشخص شدهاند. این تیمارها بهصورتی به هر ردیف اختصاص داده شدهاند که تنها یک بار در هر ردیف و ستون حضور داشته باشند. توجه داشته باشید که یک طرح تصادفی ساده نیازمند ۶۴ واحد آزمایشی است اما در طرح مربع لاتین تنها به ۱۶ واحد آزمایشی نیاز است. در این مورد شاهد کاهشی ۷۵٪ هستیم. همچنین میتوان تاثیر عامل چهارم را با اختصاص دادن مجموعه دیگری از حروف از بین برد. این طراحی جدید را با نام طرح مربع لاتین گریکو میشناسیم. برای درک بهتر این مفهوم به جدول زیر توجه کنید.
| واحد آزمایشی | تیمار |
| ۱ | Aa Bb Cc Dd |
| ۲ | Bd Ca Db Ac |
| ۳ | Cb Dc Ad Ba |
| ۴ | Dc Ad Ba Cb |
بهطور معمول ۴ عامل در ۴ سطح، نیازمند ۲۵۶ واحد آزمایشی است با این حال در طراحی بالا این عدد به ۱۶ میرسد و در حدود ۹۴٪ کاهش پیدا میکند. مربع لاتین گریکو ازترکیب مربعهای لاتین متعامد به وجود میآيد. این طراحی را میتوان برای هر تعدادی از تیمارها به جز ۶ عدد، به کار برد. در تصویر زیر میتوانید نمونهای از این طراحی را در محیط نرمافزار NCSS مشاهده کنید.
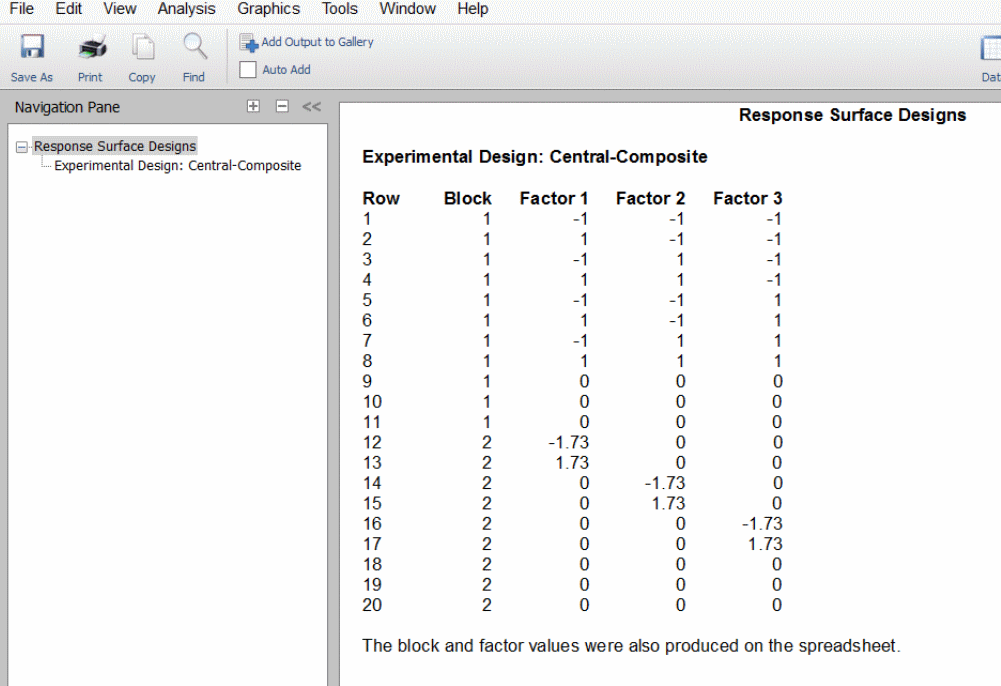
طرح سطح پاسخ
«طرح سطح پاسخ» (Response Surface Design) تنها طرحی است که در آن امکان حضور بیش از دو سطح وجود دارد. طرح سطح پاسخ به دو نوع تقسیمبندی میشود. طرح «مرکب مرکزی» (Cenral Composite) به هر عامل ۵ سطح را اختصاص میدهد. طرح «باکس بنکن» (Box Behnken) به هر عامل ۳ سطح را اختصاص میدهد. طرح مرکب مرکزی از یک طراحی دو سطحی به وجود میآید که به آن چند نقطه مرکزی و ستاره افزوده شود. پنج مقدار برای یک عامل بهصورت هستند. مقدار بهصورتی تعیین میشود که طراحی حاصل متعامد باشد. برای مثال در صورتی که تصمیم دارید از ۴ یا ۵ عامل استفاده کنید، مقدار عددی عبارت برابر با ۲٫۰۰ خواهد بود. مقادیر واقعی این سطوح بهصورت زیر به دست میآید.
- به سطح پایین عدد ۱- را اختصاص میدهیم.
- به سطح بالا عدد ۱ را اختصاص میدهیم.
- به میانگین این دو مقدار عدد ۰ را نسبت میدهیم.
- از مقادیر دو عبارت و به ترتیب برای یافتن مقدار بیشینه و کمینه استفاده میشود.
در ادامه برای درک بهتر این موضوع، مثالی را مورد بررسی قرار میدهیم. در این مثال به سطح پایین عدد ۵۰ و به سطح بالا عدد ۶۰ را نسبت میدهیم. در این صورت سطوح دیگر را میتوان به شکل زیر نوشت.
| سطوح | مقدار واقعی |
| ۴۵ | |
| 1- | ۵۰ |
| 0 | ۵۵ |
| 1 | ۶۰ |
| ۶۵ |
مقدار عددی عبارت بستگی به تعدا عوامل موجود در طراحی دارد. به مثال موجود در جدول زیر توجه کنید.
| عوامل | مقدار |
| ۲ | ۱٫۴۱ |
| ۳ | ۱٫۷۳ |
| ۴ | ۲٫۰۰ |
| ۵ | ۲٫۰۰ |
| ۶ | ۲٫۲۴ |
طرح باکس بنکن با طرح مرکب مرکزی دو تفاوت دارد. یک اینکه از چرخه عملیاتی کمتری استفاده میکند و دوم اینکه به جای ۵ سطح تنها از ۳ سطح استفاده میکنند. مقدار واقعی این سطوح مانند طرح مرکب مرکزی به دست میآید با این تفاوت که مقدار در نظر گرفته نمیشود. این را میتوانید در تصویر زیر مشاهده کنید.
طرح غربالگری
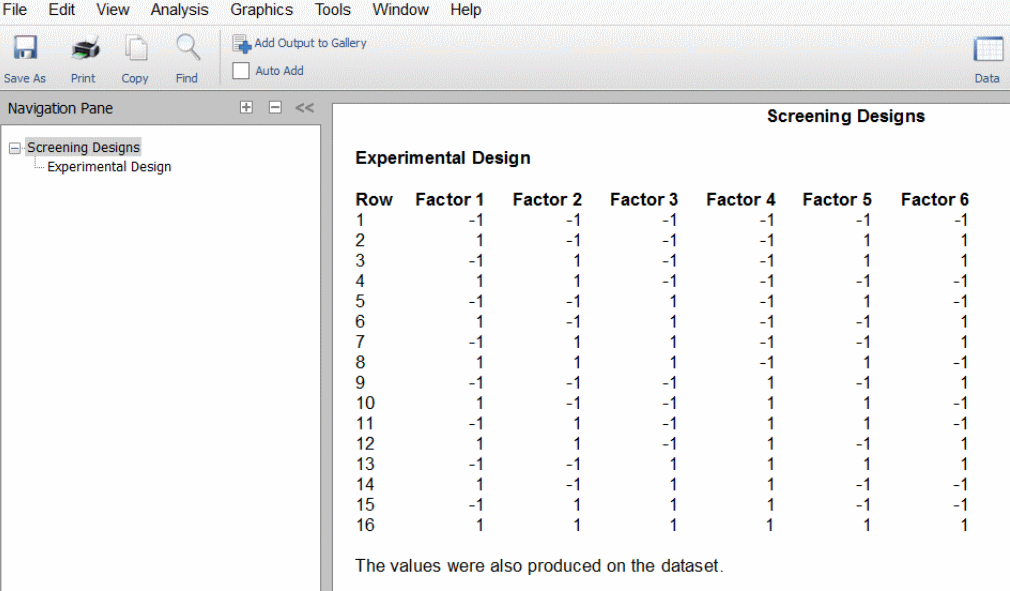
«طرح غربالگری» (Screening Design) برای یافتن عوامل مهم از میان تعداد زیادی عامل (تا ۳۱ عامل) دو سطحی مورد استفاده قرار میگیرد. در صورتی که تعداد چرخههای عملیاتی بهصورت ۴، ۸، ۱۶ و ۳۲ باشد، طرح یک طرح تکرارپذیر جزئی معمولی است. اما در صورتی که تعداد چرخههای عملیاتی به شکل ۱۲، ۲۰، ۲۴ و ۲۸ باشد، طرح از نوع پلاکت برمن است. در این روند از طراحی غربالگری استفاده میشود که در کتاب لوسن در سال ۱۹۸۷ آورده شده است. توسط این طراحیها میتوان عوامل تاثیرگذار اصلی را بررسی و مشخص کرد. در تحلیل دادههای به دست آمده از این طراحی، استفاده از «رگرسیون چندگانه» (Multiple Regression) سادهترین روش است. برای مدل اولی که مورد بررسی قرار دادیم، استفاده از برنامه تحلیل طراحی دو سطحی مطلوب است. در تصویر زیر میتوانید نمونهای از این طرح را در محیط نرمافزار NCSS مشاهده کنید.
طرح آزمایش تاگوچی
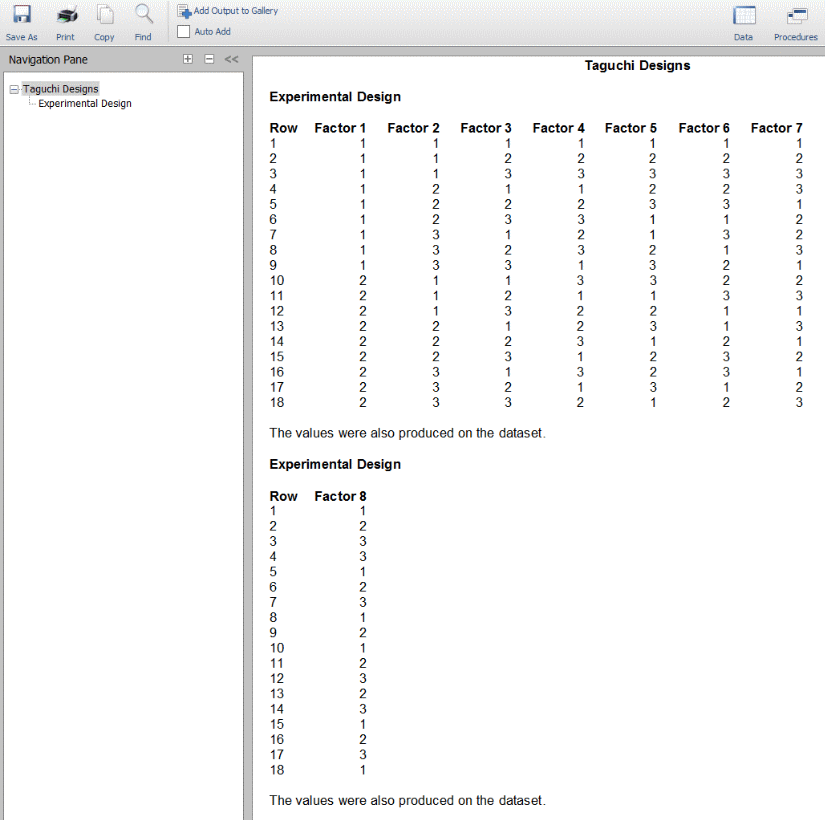
طراحی آزمایش «تاگوچی» (Taguchi) که در بیشتر مواقع با عنوان «آرایههای متعامد» (Orthogonal Ararays) شناخته میشود، مجموعهای از طرحهای فاکتوریال جزئی است که برهمکنشها را نادیده میگیرد و بر تخمین اثرات اصلی تمرکز میکند. ماژول این برنامه معروفترین طرحهای تاگوچی را تولید میکند. در طراحی تاگوچی برای نامگذاری آرایههای متعامد به روش زیر عمل میشود.
La(b^c)
حال میخواهیم بدانیم معنای هر کدام از این عبارتها در این روش نامگذاری چیست.
- : تعداد چرخههای عملیاتی آزمایش
- : تعداد سطوح هر عامل
- : تعداد متغیرهای موجود
طراحیها میتوانند دارای عواملی باشند که هر کدام چند سطح دارند. با این حال طراحیهایی با دو و سه سطح از بقیه موارد متداولتر هستند. طراحی با نام احتمالا از بقیه موارد معروفتر است. وقتی یک طراحی انجام میشود، سطوح هر عامل در مجموعه داده جاری ذخیره و جایگزین دادههایی میشود که از پیش در آنجا حضور داشتند. در این روش شاهد تهیه گزارش خروجی نخواهیم بود. در تصویر زیر میتوانید نمونهای از طراحی تاگوچی را در محیط نرمافزار NCSS مشاهده کنید.
طراحیهای دو سطحی
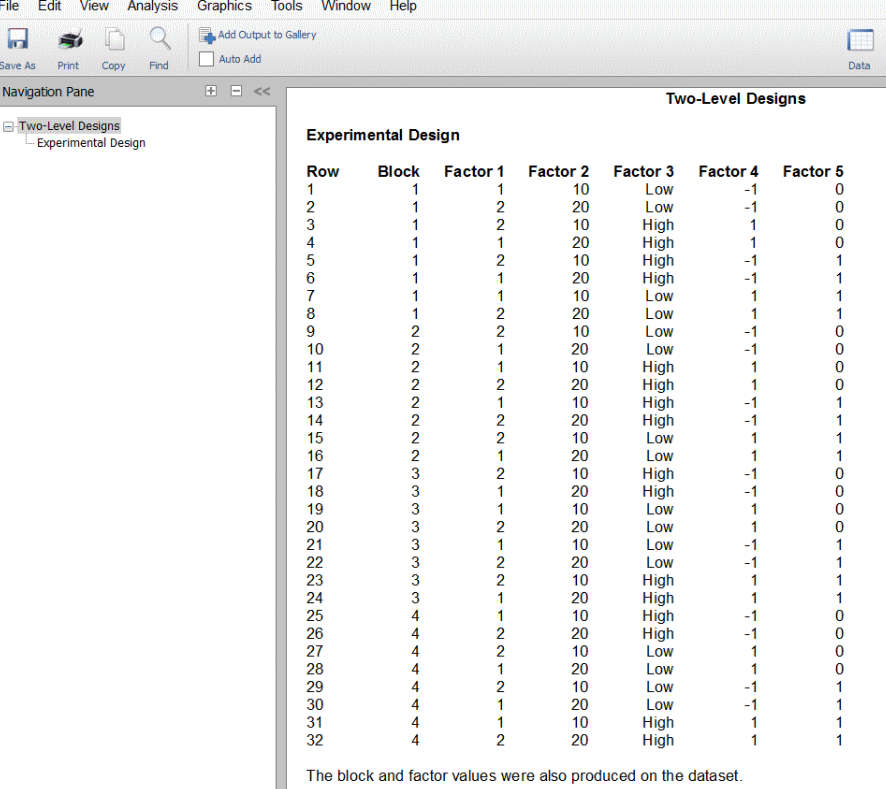
در این روند طراحی، طرحهای فاکتوریل دوگانه با بیش از ۷ عامل تهیه میشوند. در این صورت طراحی میتواند قطعهبندی و تکرار شود. ردیفهای طراحی ممکن است به شکل استاندارد یا تصادفی قرار بگیرند. بعد از این مرحله با مراجعه به کتاب Box and Hunter، وجود این طراحی را بررسی میکند. در صورت موجود بودن، از همان الگوی موجود برای این طراحی استفاده میشود. در غیر این صورت از روند استاندارد برای آن استفاده میشود که در آن برهمکنشهایی با مرتبه بالاتر در ابتدا قرار میگیرند تا از ایجاد تغییر بر قطعهها جلوگیری شود. در زیر تصویر طراحی دو سطحی را در نرمافزار NCSS مشاهده میکنید.
مولد طراحی
در این روش طراحیهای فاکتوریال با اندازههای تکراری و قطعات تقسیمبندی شده، تا ۱۰ عامل پوشش داده میشود. همچنین این طراحیها در جدول دادههایی مانند تصویر زیر قابل مشاهده هستند.

طراحی D-Optimal
در این روش طراحیهای D-Optimal برای آزمایشهای چند فاکتوریال با هر دو عامل کیفی و کمی، انجام میشود. این عوامل میتوانند تعداد سطوح متفاوتی داشته باشند. بنابراین میتوان از این روش برای طراحی آزمایشی با دو عامل کیفی و یک عامل کمی استفاده کرد. هرکدام از عوامل کیفی دارای سه سطح هستند و عامل کمی نیز ۷ سطح دارد. طراحی D-Optimal برای کمینهسازی «واریانس تعمیم یافته» (Generalized Varaiance) ضرایب رگرسیون تخمینی به وجود آمده است.
در تنظیمات رگرسیون چندگانه، از ماتریس X، برای نمایش ماتریس داده متغیرهای مستقل استفاده میشود. طراحیهای D-Optimal باعث کمینه شدن واریانس کلی ضرایب رگرسیونی تخمینی از طریق بیشینه کردن دترمینان میشود. طراحیهایی که به این روش انجام میشوند، تقریبا در معیارهای دیگری نیز بهینه هستند. در ادامه میخواهیم بدانیم در چه مواقعی از طراحی D-Optimal استفاده میشود. از طراحی D-Optimal در مواقعی استفاده میشود که بودجه محدودی در دسترس است و نمیتوان طراحی عاملی تکرارپذیر را به انجام رساند. در این مورد مثالی را بررسی میکنیم.
در مطالعهای تصمیم داریم پاسخ به ۳ عامل را مورد بررسی قرار دهیم. عامل با سه سطح، عامل با چهار سطح و عامل با هشت سطح. برای تکرار کامل این آزمایش نیاز به ۹۶ واحد آزمایشی داریم. در حالتی که تنها بتوانیم ۲۰ واحد آزمایشی را پوشش دهیم، آنها را به کدام یک از ۹۶ واحد اختصاص دهیم؟ در این صورت میتوان از طراحی D-Optimal استفاده کرد که انتخابی منطقی به دست میدهد. انجام این نوع طراحی در تصویر زیر در محیط نرمافزار NCSS نشان داده شده است.
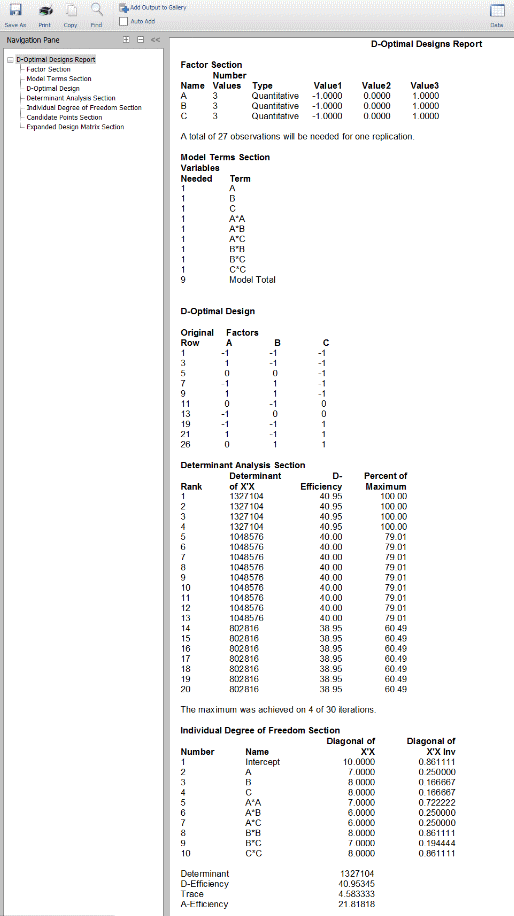
نرمافزار Statgraphics
نرمافزار Statgraphics قابلیتهای گستردهای برای خلق و تحلیل آزمایشهای آماری دارند. در این نرمافزار میتوان طراحیهای آزمایش را با انواع روشها به انجام رساند. در ادامه میخواهیم کمی بیشتر با نحوه عملکرد این نرمافزار و محیط آن آشنا شویم.
طراحی غربالگری
از این طراحی در مواقعی استفاده میشود که میخواهیم تاثیر مهمترین عوامل را بر نتیجه به دست آمده بدانیم. در بسیاری از طراحیها، عوامل تنها دو سطح دارند. این عوامل نیز میتوانند کمی یا دستهبندی شده باشند. این روش شامل طراحی فاکتوریال دو سطحی، طراحی فاکتوریال با سطوح مختلط، طراحی فاکتوریال جزئی، طراحی فاکتوریال نامنظم و طراحی پلاکت برمن است. برای طراحیهایی که در آن وضوح کامل نباشد، شاهد الگویی آشفته خواهیم بود. در این مورد دو انتخابی که پیش رو داریم، قطعهبندی و تصادف انتخابی است. در تصویر زیر نمونهای از این طراحی را مشاهده میکنید.
طرح سطح پاسخ
از طراحی سطح پاسخ برای تعیین تنظیمات بهینه برای عوامل آزمایشی استفاده میشود. این طراحی حداقل ۳ سطح در عوامل آزمایشی دارد. این طراحی شامل طراحی مرکب مرکزی، طراحی باکس بنکن، طراحی عاملی سه سطحی و طراحی «دراپر لین» (Draper Lin) میشود. در این مورد به تصویر زیر توجه کنید.
آزمایشهای ترکیبی
«آزمایشهای مخلوط» (Mixture Expriments) شامل اجزایی از یک مخلوط است که سطوح آنها به ۱۰۰٪ یا مقدار تعیین شده دیگری محدود میشود. در این مورد ممکن است حد بالا و پایین برای هر جز مشخص باشد. این طراحی شامل «شبکهای ساده» (Simplex Latiice)، «مرکز ثقل ساده» (Simplex Centroid) و طراحی «رئوس حدی» (Extreme Vertices) میشود.
طراحی D-Optimal
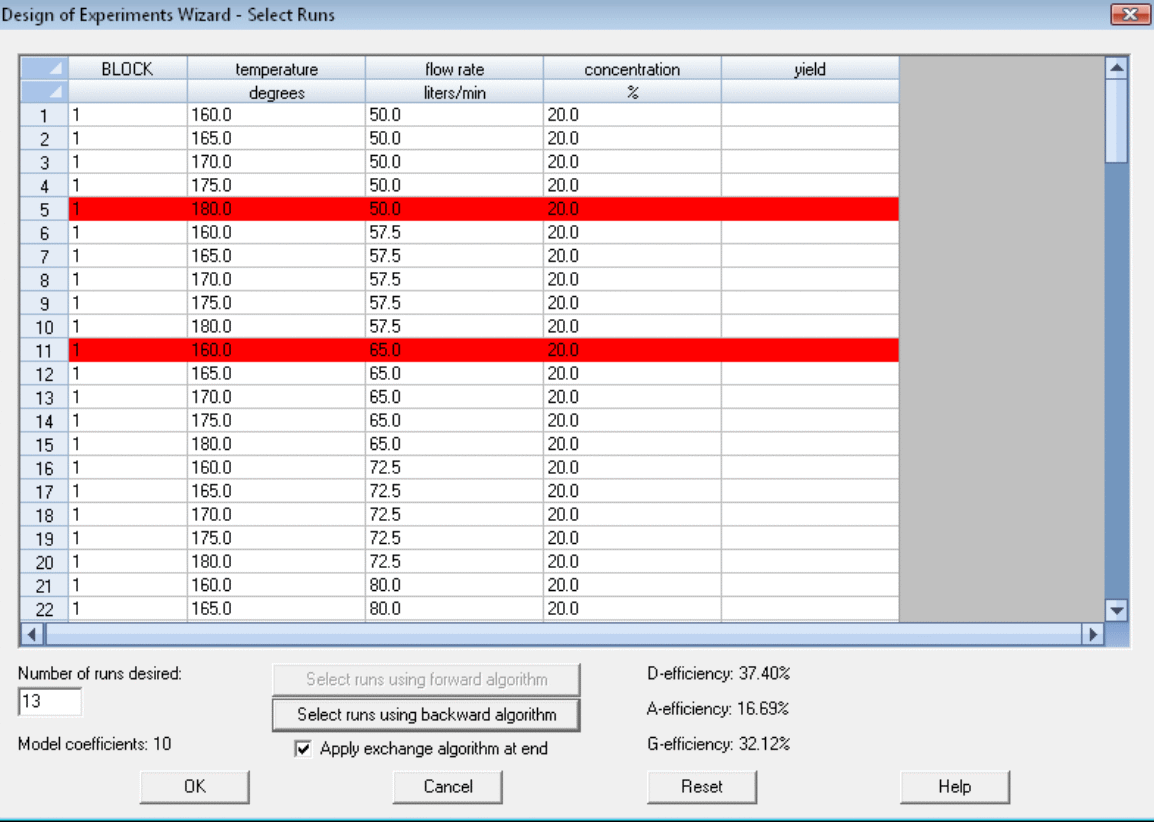
طراحیهای D-Optimal به دنبال طراحیهایی هستند که در آن ماتریس کوواریانس ضرایب تخمینی در یک آماری، کمینه شود. از این طراحی در مواردی استفاده میشود که ناحیه طراحی محدود باشد یا برای بهبود ویژگیهای آماری یک آزمایش طراحی نشده نیاز به افزودن چرخههای عملیاتی مازاد باشد.
کاربران نرمافزار Statgraphics بهطور معمول کار خود را با ایجاد مجموعهای از چرخههای عملیاتی منتخب با استفاده از طراحی فاکتوریال چند سطحی آغاز میکنند. سپس این نرمافزار طراحی آزمایش یک زیرمجموعه بهینه را از بین آنها انتخاب میکند. این کار به کمک انتخاب روبه جلو یا معکوس به همراه الگوریتم تبادلی انجام میشود. برای درک بهتر به تصویر زیر توجه کنید.
طرح مولفه قدرتمند
نرمافزار Statgraphics میتواند آزمایشهایی را برای استفاده در «طراحی مولفه قدرتمند» (Robust Parameter Design) ایجاد کند. در چنین آزمایشهایی دو نوع عامل وجود دارد. نوع اول عوامل قابل کنترل هستند که آزمایشگر میتواند هم در فرآیند آزمایش، هم در تولید آنها را دستکاری کند. نوع دوم عوامل پرت هستند که میتوان در فرآیند آزمایش آنها را دستکاری کرد اما بهطور معمول غیرقابل کنترل هستند. هدف از انجام این طراحی این است که سطوح عوامل کنترلپذیر را بیابیم، در حالی که متغیرهای پاسخ بهطور معمول به تغییرات عوامل پرت حساس نیستند.
طراحی غربالگری قطعی
«طراحی غربالگری قطعی» (Definitive Screening Design) طراحیهای کوچکی هستند که توانایی تخمین مدلها چه اثر آنها بهصورت خطی باشد، چه درجه دوم، را دارند. با این حال برهمکنشهای درجه دو در بسیاری موارد با خود و با اثرات درجه دوم اشتباه گرفته میشوند. به علاوه طراحی در صورتی که بیش از ۶ عامل وجود داشته باشد، منجر به طراحی میشود که توانایی تخمین مدلهای درجه دوم را برای هر ۳ عامل دارد.

طراحیهای کامپیوتری
طراحیهایی که با کامپیوتر انجام میشوند به کاربر اجازه میدهند تا طراحی آزمایشی داشته باشد که در آن ویژگیها با توجه به تخمین مدلهای آماری ویژه، بهینه میشوند. در این طراحی اطلاعاتی مانند ناحیه آزمایشی، مدل تخمینی و تعداد چرخههای عملیات آزمایشی قابل اجرا است. نرمافزار به دنبال مجموعهای از چرخههای عملیاتی میگردد تا معیارهای بهینه را به حداکثر برساند. در زیر نمونهای از طراحی انجام شده بهصورت کامپیوتری را مشاهده میکنید.
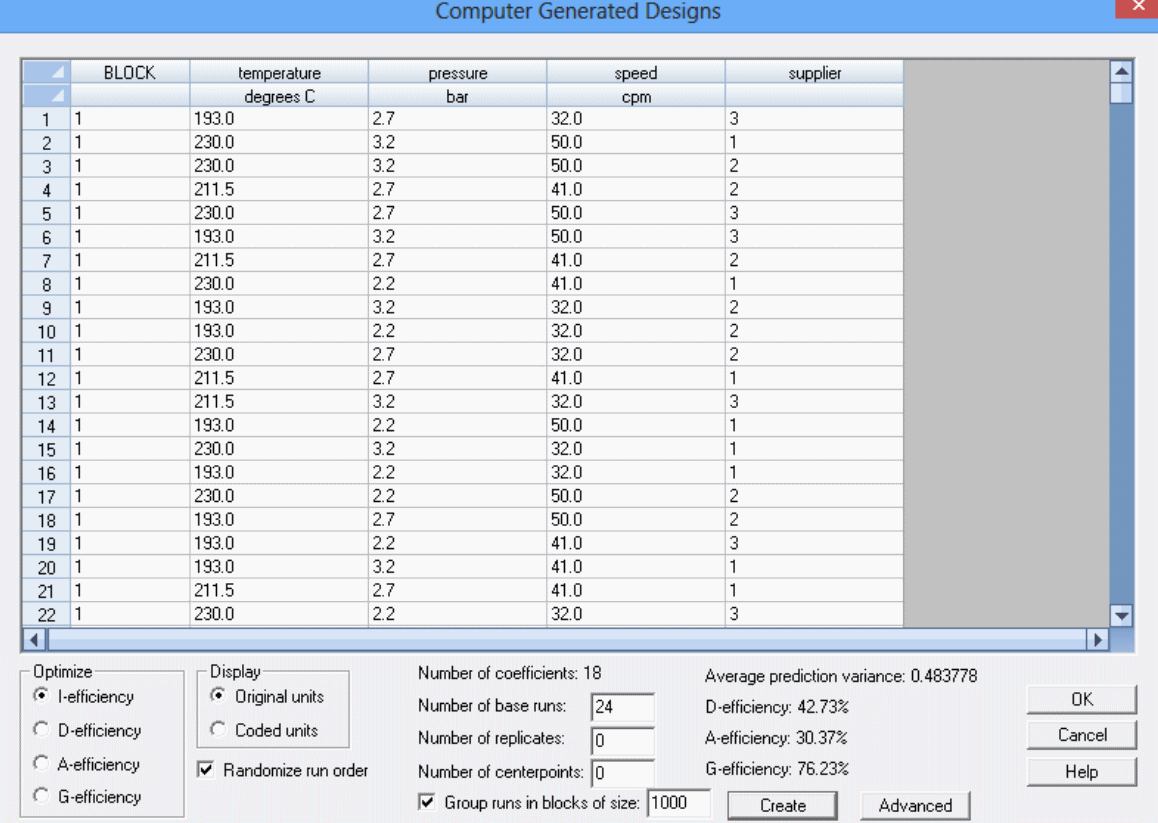
طراحی دستهای تک عاملی
از «طراحی دستهای تکعاملی» (Single Factor Categorical Design) برای مقایسه سطوح یک عامل غیر کمی استفاده میشود. این طراحیها شامل طراحیهای کاملا تصادفی، طراحی قطعه تصادفی، طراحی قطعه تعادلی ناقص، مربع لاتین، مربع لاتین گریکو و مربع لاتین گریکو هایپر هستند.
طراحی دستهای چندعاملی
از «طراحی دستهای چند عاملی» (Multi Factor Categorical Design) برای مطالعه عوامل چندگانه غیرکمی با سطوح مختلف استفاده میشود. نتایج حاصل از آن به کمک تحلیل چند عاملی واریانس بررسی میشود.
طراحی اجزای واریانس
از «طراحی اجزای واریانس» (Variance Component Design) برای مطالعه تاثیر دو یا تعداد بیشتری عامل تودرتو بر تغییرات حاصل بر نتایج استفاده میشود. در این طراحی، تخمینی از میزان اثر هر عامل بر تغییرات به دست میآید.
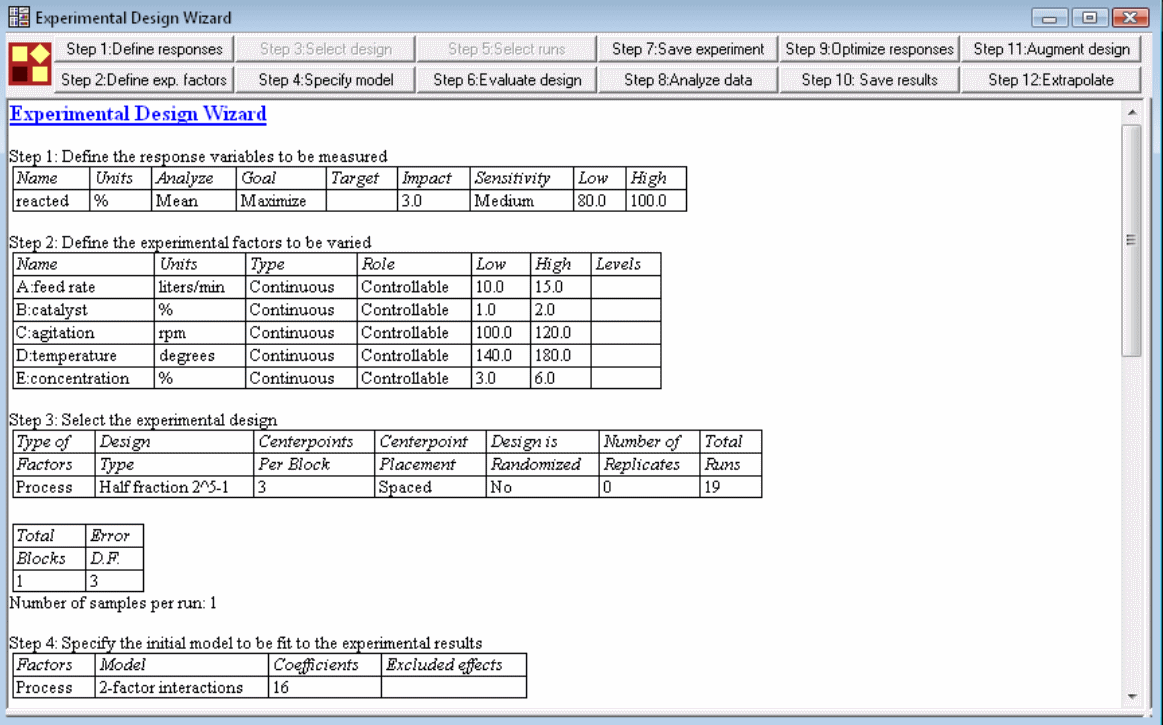
راهنمای طراحی آزمایش
نرمافزار Statgraphics شامل راهنمایی است که به کاربران در ساخت و تحلیل طراحی آزمایش یاری میرساند. راهنما این کار را طی ۱۲ مرحله مهم انجام میدهد. از این بین ۷ مرحله به پیش از راهاندازی آزمایش مربوط میشود. ۵ مرحله نهایی نیز برای بعد از انجام آموزش کاربرد دارند. این موارد را میتوانید در تصویر زیر مشاهده کنید.
بهینهسازی چند پاسخی
برای یافتن ترکیبی از عوامل آزمایشی که نتایج خوبی را برای پاسخ متغیرهای چندگانه به دست دهد، راهنمای طراحی آزمایش از مفهوم عوامل مطلوب استفاده میکند. عوامل مطلوب مسیری را محیا میکنند که طی آن الزامات رقابتی پاسخهای چند عاملی به تعادل میرسند. این موارد ممکن است در واحدهای متفاوتی اندازهگیری شوند. کاربر مقدار مورد انتظار یا بازه مورد قبول برای نتایج و اهمیت نسبی هر کدام را مشخص میکند. در ادامه نرمافزار بهترین ترکیب ممکن برای این عوامل آزمایشی را به دست میدهد.
طراحی بهینه مستعار
طراحی بهینه مستعاری که میتوان با این نرمافزار انجام داد، نه تنها دقت ضرایب مدلهای تخمینی، بلکه سوگیری بالقوه ناشی از اثرات فعال را نیز در نظر میگیرد. در تصویر زیر میتوانید تنظیمات مربوط به این طراحی را در نرمافزار Statgraphics مشاهده کنید.

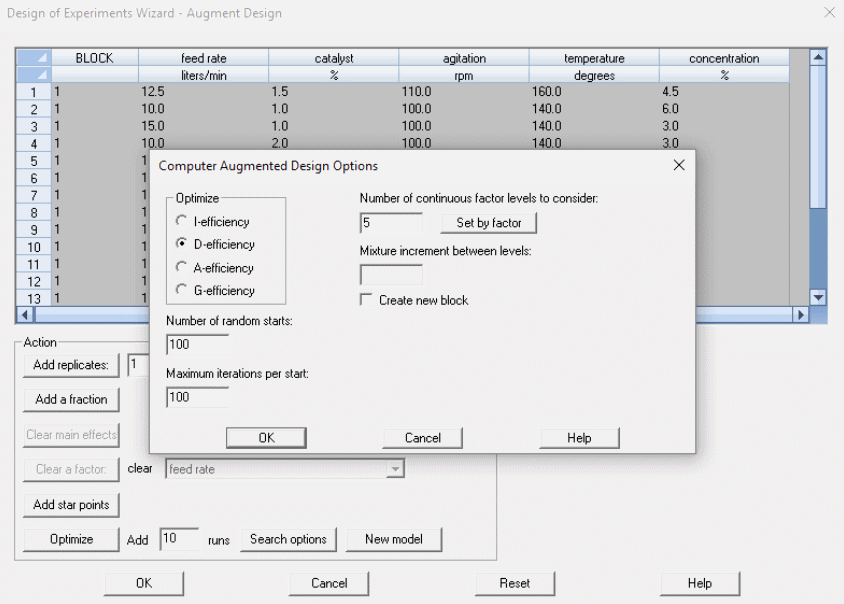
تقویت کامپیوتری طراحیهای موجود
با استفاده از نرم افزار Statgraphics میتوان روی آزمایشهای موجود تغییراتی را ایجاد کرد تا به بیشینه کارآیی خود برسند. در این مورد کاربر باید چرخههای عملیاتی بیشتری را به طراحی اضافه کند. در این صورت میتواند بهینهسازی را بیشینه کند. در تصویر زیر نمونهای از تنظیمات این طراحی را مشاهده میکنید.
طراحی آزمایش در شیمی و مهندسی شیمی
تا اینجا با مفهوم طراحی آزمایش آشنا شدیم. در ادامه میخواهیم بدانیم این مفهوم در دنیای علم شیمی چه کارکردی دارد و به چه طریقی مورد استفاده قرار میگیرد.

همانطور که میدانید تقاضا برای محصولات شیمیایی آلی و معدنی همواره رو به رشد است. این محصولات شیمیایی شامل مواد دارویی، مواد شیمیایی کشاورزی، پلیمرها، سوختها، شویندهها، لوازم آرایشی و بهداشتی، طعمدهندهها و مکملهای غذایی هستند. از همین رو استفاده از طراحی آزمایش برای سنتز محصولات جدید و بهینهسازی مواد موجود بسیار ضروری و پراهمیت است.
شناسایی، استخراج و سنتز محصولات شیمیایی جدید نیازمند این است که شیمیدانها بهطور پیوسته آزمایشهای موجود را بازطراحی کنند تا در محصول تغییراتی به وجود آورند. در فرآيند آزمایشها نیاز است که کنترل کیفیت صورت بگیرد تا طی آن دلیل به وجود آمدن محصولات جانبی در هر واکنش مشخص شود. این آزمایشها مقادیر قابل توجهی از زمان محققها را به خود اختصاص میدهند. همچنین در روند آنها مقادیر زیادی از مواد اولیه و منابع مصرف میشود و بهطور معمول رسیدن به پاسخ مناسب بلافاصله اتفاق نمیافتد.
شیمیدانها، زیستشیمیدانها و مهندسان شیمی اغلب به آزمایشهایی روی میآورند که در آنها از دستگاههایی استفاده میشود که باعث بهینهسازی میشوند و در نهایت مقدار بازده و خلوص بیشتری نیز به دست میدهند. این فرآیند نیازمند این است که محققان در روشهای خود بازنگری کنند. هرچه شیمی یک آزمایش پیشرفتهتر و پیچیدهتر باشد، طراحی آزمایش آن نیز پیچیدهتر خواهد بود. بهصورتی که خود میتواند تبدیل به یکی از زیرشاخههای آن شود.
طراحی آزمایش سنتی
بهطور سنتی یک طراحی آزمایش معمولا با یک فرضیه یا هدفی برای دستیابی تعریف میشود. سپس شیمیدان با توجه به دانش خود پیشبینی میکند و در جهت رسیدن به آن آزمایشی را پی میگیرد. این شیمیدان با توجه به موارد گفته شده، برای این کار مراحل زیر را طی میکند.
- شناسایی متغیرها
- تنظیم شرایط
- تصمیمگیری در مورد متغیرها و مواردی که باعث دستکاری در آنها میشود.
- ارزیابی ریسک موجود
- انجام آزمایش و مشاهدات
- تغییر یک یا تعدادی بیشتر از متغیرهای آزمایش و سپس تکرار آن
بعد از این مرحله، آزمایشگر به دفعات روند انجام آزمایش را تکرار میکند تا به نتیجه دلخواه برسد. معمولا در این شرایط در هر بار تکرار آزمایش، تاثیر ناشی از تغییر یکی از متغیرها مورد بررسی قرار میگیرد.
طراحی آزمایش
پیشتر در مورد تاریخچه این مفهوم صحبت کردیم. پس از گسترش این روش در سال ۱۹۳۵، با استفاده از طراحی آزمایش، رابطه بین عوامل موثر میتواند تغییر کند. همچنین رابطه بین عوامل مختلف را میتوان به کمک تحلیل آماری به دست آورد. توجه داشته باشید که استفاده از این روش، نیاز به نیروی انسانی را افزایش میدهد، زیرا برای انجام آن علاوه بر یک شیمیدان، نیاز به یک ریاضیدان یا آماردان نیز خواهیم داشت.
«هوش مصنوعی» (Artificial Intelligence) و «یادگیری ماشین» (|Machine Learning) نیز میتواند برای پیشبینی ویژگیهای مولکول، ساختار مولکول و نتایج واکنشها به کار بروند. همچنین میتوان از آنها برای بهینهسازی شرایط آزمایش نیز بهره برد. استفاده از هوش مصنوعی در این مورد میتواند باعث کاهش زمان مورد نیاز برای انجام این فرآيند شود. همچنین میتوان از هوش مصنوعی برای انجام «سنتز برگشتی» (Retrosynthesis) نیز بهره برد. در این فرآیند تلاش بر این است تا از محصول به مواد اولیه برسیم و درواقع نحوه سنتز را بهصورت صحیح و کارآمد به دست آوریم. انجام این فرآیند با روشهای سنتی میتواند بسیار دشوار و وقتگیر باشد، بنابراین با کمک هوش مصنوعی تلاش میکنیم تا زمان مورد نیاز برای انجام آن را تا حد ممکن کاهش دهیم.
کنترل و نظارت
توانایی شناسایی و جداسازی محصولات یک فرآيند، حوزهای است که پیوسته در حال گسترش است. استفاده از روشهایی مانند «کروماتوگرافی» (Chromatography)، «طیفسنجی جرمی» (Mass Spectrometry) و «طیفسنجی رزونانس مغناطیسی هستهای» (NMR) باعث میشود توانایی تشخیص و جداسازی محصولات پیچیدهتری را داشته باشیم.
فرآیند شناسایی محصولات به مرور زمان پیچیدهتر میشود اما پیشرفت دستگاهها و روشها، امکان طراحی آزمایشهای مناسب را میدهند. ضبط دادهها بهصورت دیجیتالی به آزمایشگر کمک میکند تا دادههای بیشتری را با دقت بالاتری به دست آورد و به او این امکان را میدهد که به طراحی آزمایشهایی بپردازد که در آن به دادههای بیشتری دسترسی داشته باشد و با سرعت بیشتری آنها را تحلیل کند. در این صورت نتایج به دست آمده از این آزمایش نیز از دقت بالاتری برخوردار هستند.
مثال از طراحی آزمایش در مهندسی شیمی
حال که با مفهوم طراحی آزمایش و نحوه انجام آن آشنا شدیم، میخواهیم به بررسی تعدادی مثال بپردازیم که در حیطه شیمی و مهندسی شیمی از این مفهوم بهره میبرند.
آزمایش اکسایش سیلیسیوم
واکنش اکسایش سیلیسیوم نیمههادی فراخالص باعث به وجود آمدن لایههایی از سیلیسیوم دیاکسید عایق با فرمول شیمیایی میشوند. این ماده میتواند در یک میکروالکترونیک نیمههادی اکسی فلز (MOS) مانند «ترانزیستور اثر میدان» (Field Effect Transistor) گنجانده شود. از دیگر کاربردهای سیلیسیوم دیاکسید در میکروالکترونیکها میتوان به گرفتن ناخالصی، عایق کردن دستگاه، مقاومت در برابر ناخالصی، غیرفعالسازی اتصال و ایجاد عایق در لایههای فلزی اشاره کرد.
تشکیل لایههای از واکنش بین سیلیسیوم و اکسیژن در محیطی مرطوب یا خشک است. در این آزمایش سینتیک اکسایش در اتمسفر خشک و با اکسیژن خالص اندازهگیری میشود. آزمایشگر سرعت مشاهده شده را به مدل سینتیکی ربط میدهد که در آن اکسیژن در سیلیسیوم دیاکسید منتشر میشود و واکنش شیمیایی متعاقب آن در سطح سیلیسیوم و سیلیسیوم دیاکسید رخ میدهد.
کنترل میزان ضخامت لایههای سیلیسیوم دیاکسید برای ساخت ترانزیستور اثر میدان ضروری است. ضخامت مورد نظر در طی زمان کاهش پیدا کرده است تا بتوان مدارهای الکتریکی کوچکتر و سریعتری داشت. در سال ۱۹۶۰ میلادی این مقدار در حد چند میکرون بود و با گذر زمان در سال ۲۰۰۱ به ۵ نانومتر رسید و هرچه پیش میرویم این اندازه کمتر نیز میشود. توجه داشته باشید که اندازهگیری دقیق ضخامت لایه سیلیسیوم دیاکسید ضروری است و به روش «الیپسومتری» (Ellipsometry) یا بیضیسنجی بررسی میشود.
تئوری تشکیل لایه سیلیسیوم دیاکسید
واکنش گاز جامد به تشکیل لایههای جامد سیلیسیوم دیاکسید میانجامد که در آن مراحل زیر بهصورت متوالی طی میشوند.
- انتشار در طول غشای یک گاز خارجی
- انحلال گاز اکسیژن در لایههای سیلیسیوم دیاکسید
- انتشار گاز اکسیژن در طول لایه سیلیسیوم دیاکسید
- واکنش اکسیژن در نقطه اتصال سیلیسیوم و سیلیسیوم دیاکسید
شار انتقال در طول مسیر باید در حالت ایستا باشد بهصورتی که برابر با سرعت واکنش در سطح باشد. این مورد را میتوان به شکل زیر نشان داد.
شار اکسیژن بر حسب مول بر سانتیمتر مکعب در ثانیه
غشای گاز خارجی
انتشار در اکسید
واکنش سطحی، با فرض درجه اول بودن
در ادامه میخواهیم بدانیم هر کدام اجزای این روابط به چه مولفهای اشاره دارند.
- : ضریب انتقال جرم
- : «پخشایی» (Diffusivity) اکسیژن در سیلیسیوم دیاکسید
- : ضخامت لحظهای اکسید
- : ثابت سرعت واکنش
غلظت فاز گازی که آن را با نشان میدهیم، در خارج از لایه سیلیسیوم دیاکسید با غلظت اکسید حل شده در سطح خارجی طبق «قانون هنری» (Henry's Law) ارتباط دارد. این رابطه را میتوان بهصورت زیر نشان داد.
حذف غلظتهای غیرقابل اندازهگیری ، و باعث به وجود آمدن عبارتی از غلظت فاز گازی میشود که قابل اندازهگیری است و آن را با نشان میدهیم. بنابراین میتوان مقدار سرعت واکنش را بهصورت زیر نوشت.
مقدار ثابت سرعت مشاهده شده را میتوان از جمع سه مقاومت در مجموعه به دست آورد که بهصورت زیر هستند.
- انتقال جرم:
- انتشار اکسید:
- واکنش شیمیایی:
در شرایط آزمایش و در حضور اکسیژن خالص، مقاومت انتقال جریان خارجی وجود ندارد. بنابراین رابطه زیر برابر با ۰ خواهد بود.
در ادامه نیز آن را از روابط حذف خواهیم کرد.
ضخامت اکسید با گذر زمان تغییر میکند و از طریق تعداد مولهای اکسیژن به شار مرتبط میشود.
- : تعدا مولهای اکسیژن به ازای واحد حجمی سیلیسیوم دیاکسید
با سادهسازی این رابطه میتوان آن را بهصورت زیر نیز نوشت.
در ادامه میخواهیم ببینیم دو عبارت و هر کدام به چه چیزی اشاره دارند.
با انتگرالگیری به رابطه زیر خواهیم رسید.
در این رابطه عبارتهای و را میتوان بهصورت زیر تعریف کرد.
همچنین منظور از مقدار ضخامت اولیه اکسید است.
راه حل کلی بهصورت ریشه درجه دوم است که آن را در زیر آوردهایم.
در اینجا دو محدودیت را در نظر میگیریم.
برای زمانهای کوتاه که برقرار است، اولین عبارت در «سری تیلور» (Taylor Series) برای بهصورت زیر است.
همچنین نشاندهنده ثابت خطی قانون سرعت است.
برای زمانهای بلند که برقرار است، رابطه زیر وجود دارد.
در این رابطه عبارت نشاندهنده «ثابت سهمی قانون سرعت» (Parabolic Law Rate Constant) است.
بنابراین دادههای مربوط به سرعت در ابتدا و انتهای زمان، ثابتهای اصلی سینتیک سرعت را به دست میدهند که توسط مراحل آهسته (واکنش در ابتدای زمان) و ( انتشار در زمان طولانی) کنترل میشوند. از آنجا که این دو اصل را نمیتوان به راحتی با دادههایی محدود از یکدیگر تشخیص داد، استفاده از رابطه کلی با ریشه دوم پیشنهاد میشود. این رابطه را میتوانید در زیر مشاهده کنید.
در این رابطه است.
در صورتی که مقدار و معلوم باشد، ضخامت اولیه اکسید را میتوان طبق تعریف به دست آورد.
آزمایش عملی
در این بخش میخواهیم نحوه انجام این آزمایش و به دست آوردن نتایج را بررسی کنیم. نمونه در دمای ۹۰۰ درجه سانتیگراد در کوره لولهای و با جریان میانگذر اکسیژن، اکسیده میشود. از روش الیپسومتری برای اندازهگیری ضخامت نمونه پس از سرد کردن آن، بهره میبریم. با دادن ضریب انکساری سیلیسیوم دیاکسید به الیپسومتر (۱٫۴۶۲ در طول موجی برابر با ۶۳۲٫۸ نانومتر) مقدار صخامت هر نمونه را خواهیم داشت. زمان کلی برای انجام آزمایش بین ۲ الی ۴ ساعت است.
طراحی آزمایش کشاورزی
طراحی آزمایش یکی از مواردی است که میتوان آن را در تمامی زمینههای تحقیقاتی به کار برد. در تحقیقات کشاورزی سوال اصلی که نیازمند پاسخ است، بهطور معمول بهصورت یک فرضیه مطرح میشود و آزمایشگر با انجام آزمایش میتواند آن را تایید یا رد کند. این فرضیات از تجربههای پیشین، مشاهدهها و با در نظر گرفتن مباحث نظری مطرح میشود. پس از مطرح شدن فرضیه و مشخص شدن چارچوبهای آن، باید آزمایش مورد نیاز برای بررسی آن، طراحی شود. این روند معمولا از ۴ فاز تشکیل میشود که در ادامه آنها را آوردهایم.
- انتخاب مواد مناسب برای انجام آزمایش روی آنها
- انتخاب مولفههایی که باید اندازهگیری شوند.
- انتخاب روندی که طی آن این مولفهها اندازهگیری میشوند.
- انتخاب روندی که بتوان به کمک آن تاثیرها را مورد بررسی قرار داد.
این مراحل چیزی است که در فرآيند طراحی یک آزمایش انجام میشود و باید در آن سه مورد بسیار مهم را در نظر داشت.
- تخمین خطاها
- کنترل خطاها
- ارائه تفسیری مناسب از دادهها
کتاب آموزش طراحی آزمایش
فراگیری طراحی آزمایش برای دانشجویان و شاغلین بسیاری از رشتهها مفید و کاربردی است و میتواند به آنها در پیشبرد هرچه سریعتر آزمایشها کمک بهسزایی کند. از جمله این رشتهها میتوان به شیمی، مهندسی شیمی، ژنتیک، میکروبیولوژی، فیزیولوژی گیاهی و جانوری، مهندسی کشاورزی و مهندسی صنایع اشاره کرد. در ادامه میخواهیم به معرفی و بررسی تعدادی کتاب بپردازیم که میتوان از آنها برای فراگیری این مفهوم استفاده کرد.
کتاب Design and Analysis of Expriments
این کتاب راهنمایی قدم به قدم برای طراحی فرآیند یک آزمایش و تحلیل اطلاعات به دست آمده از آن با تمرکز بر ملاحظات عملی تضمینکننده این آزمایش، است. در این کتاب مثالهای متعددی آورده شده است که همگی از آزمایشهای واقعی گرفته شدهاند و بررسی این دادهها در نرمافزار ساس نیز مورد مطالعه قرار گرفته است. این کتاب را میتوان راهنمایی مدرن و جامع برای آموزش مفهوم طراحی آزمایش به حساب آورد.

این کتاب در سال ۲۰۱۷ میلادی و در ۸۶۵ صفحه، به زبان انگلیسی به چاپ رسید. این کتاب سه نویسنده دارد که همگی از اساتید ریاضیات و آمار در دانشگاههای آمریکا هستند.
کتاب A DOE Handbook
این کتاب، مرجعی جامع و مختصر برای انجام طراحی و تحلیلهای آماری با داشتن چند عامل است. این طراحیهای آزمایش در انواع صنایع و کسبوکارها به کار گرفته میشوند. مثالهای این کتاب بهصورتی انتخاب شدهاند که متاخر باشند تا بتوان همچنان در عمل نیز از آنها بهره برد. در این مثالها به وجود متخصصان علم آمار و نرمافزارهای پیچیده نیازی نیست. این کتاب برای افرادی که بدون پیشزمینه، تصمیم به یادگیری طراحی آزمایش دارند، بسیار مفید خواهد بود. همچنین به درک عمیقتر این مفهوم برای افرادی که با پایه و اساس آن آشنا هستند نیز کاربرد دارد.

این کتاب به نسبت کوتاه در سال ۲۰۱۴ میلادی، به زبان انگلیسی و در ۱۱۸ صفحه به چاپ رسید. نویسندگان این کتاب «دنیل کلمن» (Daniel Coleman) و «برت گانتر» (Bert Gunter) هستند.
کتاب Design of Expriments for 21st Century Engineers
استفاده از روش طراحی آزمایش سریعترین راه برای به دست آوردن انبوهی از اطلاعات در مورد سیستمی است که روی آن مشغول به کار هستیم. برای انجام هرچه بهتر این کار نیاز داریم تا بر برخی از مفاهیم آماری مانند رگرسیون و سایز نمونه تسلط داشته باشیم. در فصول ابتدایی این کتاب مفهوم طراحی آزمایش بهتفضیل مورد بررسی قرار گرفته است و برای تکمیل درک خواننده، در فصلهای ۷، ۸ و ۹ مفاهیم آماری مورد نیاز برای درک و تحلیل نتایج حاصل از طراحی آزمایش، پرداخته است.

نویسنده این کتاب «پاول الن» (Paul Allen) است و آن را در سال ۲۰۲۰ میلادی در ۲۱۲ صفحه به چاپ رسانده است.
کتاب Design of Expriments
آموزش طراحی آزمایش در این کتاب از پایه شروع میشود و به خواننده کمک میکند تا در این مسیر تبدیل به متخصص شود. همچنین برای درک بهتر مفاهیم آماری مورد استفاده در این طراحیها، به بررسی آمار به کار رفته در آن نیز پرداخته شده است. علاوه بر مثالهای متنوعی که در متن کتاب موجود است، در انتها ۸ تمرین بسیار مفید نیز قرار داده شده است که به فرد برای تکمیل و تثبیت دانستههای خود کمک فراوانی میکند.

این کتاب در سال ۲۰۱۳ میلادی و در ۲۳۸ صفحه به چاپ رسیده است. نویسنده این کتاب «مایک پرالتا» (Mike Peralta) است.
کتاب Practical Design of Expriments
تمرکز این کتاب در آموزش به مهندسان و دانشمندان است و برای متخصصان آمار، چندان کارآمد نیست. در این کتاب که بهطور عمده از آموزش تصویری استفاده شده است، از نرمافزار متلب برای طراحی آزمایش کمک گرفته میشود. نحوه انجام یک طراحی آزمایش مرحله به مرحله توضیح داده شده است و میتوان طی آن از تصاویر موجود برای درک بهتر مسیر، بهره برد.

این کتاب بسیار کوتاه است و تنها ۵۰ صفحه دارد. نویسنده این کتاب «کالین هاردویک» (Colin Hardwick) است که پس از کسب سالها تجربه، شرکت مشاورهای خود را در سال ۲۰۱۳ میلادی و همزمان با انتشار این کتاب راهاندازی کرد. این شرکت به کسبوکارهای مختلف برای بهیتهسازی و ارتقای کیفیت مشاوره میدهد.
کتاب Design and Analysis of Expriments with R
در این کتاب با توجه به هدف هر تحقیق، طراحی آزمایش مناسب با آن ارائه شده است. همچنین روند ایجاد آزمایش و جمعاوری اطلاعات نیز مورد بررسی قرار گرفته است. در این کتاب از زبان برنامهنویسی R برای ایجاد و تحلیل طراحی آزمایشهای مثال استفاده شده است. از مزیتهای این کتاب میتوان به این مورد اشاره کرد که کدهای مربوط به زبان R، در وبسایت نویسنده در دسترس هستند و خواننده در صورت نیاز میتواند به آنها دسترسی داشته باشد. مثالهای این کتاب از گستردگی خوبی برخوردار هستند و از پایه تا پیشرفته را پوشش میدهند.

این کتاب قطور در سال ۲۰۱۴ میلادی و در ۶۲۸ صفحه، به زبان انگلیسی به چاپ رسید. نویسنده این کتاب، «جان لاوسن» (John Lawson) استاد دانشکده آمار در دانشگاه «بریگم یانگ» (Brigham Young) آمریکا است.
کتاب Design and Analysis of Expriments
این کتاب مقدمهای بر طراحی فرآیند و محصول است به گونهای که باعث بهینهسازی کیفیت و عملکرد آنها شود. در این کتاب روشهای پرکاربرد بهصورت ساده و واضح مورد بررسی قرار گرفتهاند و این به خواننده کمک میکند تا بر مفاهیم پایهای تسلط کافی پیدا کند و بتواند از آنها در آزمایشهای واقعی بهره ببرد. از مزیتهای این کتاب میتوان به این مورد اشاره کرد که در آن تعادل خوبی بین مفاهیم نظری و کاربردها وجود دارد.

دهمین ویرایش این کتاب در سال ۲۰۲۰ میلادی و در ۶۸۸ صفحه روانه بازار شد و در دسترسی علاقمندان قرار گرفت.
کتاب Design and Analysis of Expriments by Douglas Montgomery
با گسترش استفاده از نرمافزار JMP برای انجام طراحیهای آزمایش، نیاز به کتابی در این حوزه احساس میشد. این کتاب برای برطرف کردن این نیاز دانشجویان و شاغلان نوشته شده است. در وهله اول نیاز به آموزش و درک مفاهیم بهصورت نظری وجود دارد و سپس خواننده باید توانایی به کارگیری این آموختهها را در مثالهای واقعی پیدا کند. نویسنده در این کتاب نحوه طراحی و تحلیل آزمایش را بهصورتی که باعث افزایش کیفیت، کارآمدی و عملکرد شود، به خواننده میآموزد.

نویسنده این کتاب «اندرو کارل» (Andrew Karl) است که در زمینههای متنوعی از جمله داروسازی و تولید فعالیت داشته است. او دارای مدرک دکترای آمار از دانشگاه «ایالتی آریزونا» (Arizona State) است. آقای کارل این کتاب را در سال ۲۰۱۳ میلادی و در ۳۰۲ صفحه به چاپ رساند.
کتاب Optimal Design of Expriments
این کتاب اطلاعات بسیار سودمندی در مورد طراحی آزمایش مدرن در اختیار خواننده قرار میدهد. نثر نویسنده جذاب است و راهنماییهای بسیار خوبی برای پاسخ به مثالها در آن آورده است.

این کتاب در سال ۲۰۱۱ میلادی و در ۳۰۴ صفحه به چاپ رسید. نویسنده این کتاب «پیتر گوس» (Peter Goss) و «بردلی جونز» (Bradley Jones) هستند.
مثالهای عمومی از طراحی آزمایش
تا اینجا میدانیم طراحی آزمایش چیست و به چه روشهایی قابل انجام است. از طراحی آزمایشهای جالب در زمینههای گوناگونی، بنا به نیاز، استفاده میشود. در این بخش میخواهیم با تعدادی از مثالهای کاربردی در انواع حوزهها، آشنا شویم.
مثال اول
این مثال از نوع طراحی پیش از آزمایش است. کشاورزی به دنبال بهترین ماده مغذی است تا رشد محصولات خود را افزایش دهد. او برای این کار روش زیر را پی میگیرد.
طراحی آزمایش
در حالت عادی این کار از کشاورز زمان زیادی میگرفت. زیرا باید هکتارها زمین را با ماده مغذی مورد نظر کود میداد و سپس برای مشاهده نتیجه حاصل ماهها صبر میکرد. به جای این کار او ترکیبهای مختلف کود را روی نمونههای کوچک در آزمایشگاه اعمال میکند.
بعد از گذشت چند هفته، مقدار رشد نمونههای مختلف را با کودهای مختلف بررسی میکند و میتواند بهترین ماده مغذی را برای گیاهان زمین خود انتخاب کند.
مثال دوم
محققان حوزه پزشکی بهطور معمول از آزمایشهای واقعی برای بررسی تاثیرگذاری روشهای مختلف تیمار استفاده میکنند. در این بخش میخواهیم مثالی ساده از این مورد را بررسی کنیم. از یک جمعیت انسانی تعدادی از افراد برای شرکت در مطالعهای برای سنجش میزان تاثیر یک دارو روی قلب انتخاب میشوند.
طراحی آزمایش
شرکتکنندگان این آزمایش به دو گروه دستهبندی میشوند. افراد در گروه اول دارو را دریافت میکنند و در گروه دوم خیر. بعد از گذشت ۳ ماه از شروع درمان، آزمایشهای مختلفی روی آنها صورت میگیرد تا بتوان وضعیت سلامتی آنها را ارزیابی کرد. نتایج نشان میدهد که گروه دریافتکننده دارو از نظر سلامت قلب در وضعیت بهتری به سر میبرند.
سوالات متداول
حال که میدانیم طراحی آزمایش چیست و چگونه قابل انجام است، میخواهیم به برخی از مهمترین سوالهای پیرامون آن در این بخش پاسخ دهیم.
طراحی آزمایش میان موضوعی چیست؟
در «طراحی میان موضوعی» گروههای جداگانهای تشکیل میشود تا تیمارهای متفاوت روی آنها آزمایش شود.
طراحی آزمایش فاکتوریال چیست؟
طراحی فاکتوریال برای بررسی تاثیر دو یا تعداد بیشتری متغیر مستقل روی یک متغیر وابسته به کار گرفته میشود.
طراحی آزمایش تصادفی چیست؟
«طراحی کاملا تصادفی» نوعی از آزمایش است که در آن تیمارها بهصورت تصادفی به نمونهها نسبت داده میشوند.
نرم افزارهای طراحی آزمایش چیست؟
برای تسهیل طراحی آزمایش، نرمافزارهای آماری طراحی شده است که بتوان به کمک آنها طراحی آزمایش را با سرعت هرچه بیشتر و دقت و جزئیات بهتر، به انجام رساند. نرمافزار NCSS و Statgraphics نمونهای از این نرمافزارها هستند.
کاربرد طراحی آزمایش چیست؟
از مفهوم طراحی آزمایش در مهندسی، علوم پایه و علوم اجتماعی استفاده میشود. از جمله میتوان به برآورد ساختارهای فیزیکی، مواد و اجزای سازنده، فرمولاسیون شیمیایی، برنامههای کامپیوتری، نظرسنجیها، آزمایشهای طبیعی و بررسیهای آماری اشاره کرد.
جمعبندی
هدف از این مطلب از مجله فرادرس این بود که بدانیم طراحی آزمایش چیست و برای انجام آن باید چه مورادی را در نظر داشت. همچنین به انواع روشهایی که میتوان آن را انجام داد پرداختیم. در ادامه نرمافزارهایی را معرفی کردیم که برای طراحی آزمایش طراحی شدهاند. در نهایت نیز به بررسی مثالهایی پرداختیم.