شما در حال مطالعه نسخه آفلاین یکی از مطالب «مجله فرادرس» هستید. لطفاً توجه داشته باشید، ممکن است برخی از قابلیتهای تعاملی مطالب، مانند امکان پاسخ به پرسشهای چهار گزینهای و مشاهده جواب صحیح آنها، نمایش نتیجه آزمونها، پاسخ تشریحی سوالات، پخش فایلهای صوتی و تصویری و غیره، در این نسخه در دسترس نباشند. برای دسترسی به نسخه آنلاین مطلب، استفاده از کلیه امکانات آن و داشتن تجربه کاربری بهتر اینجا کلیک کنید.
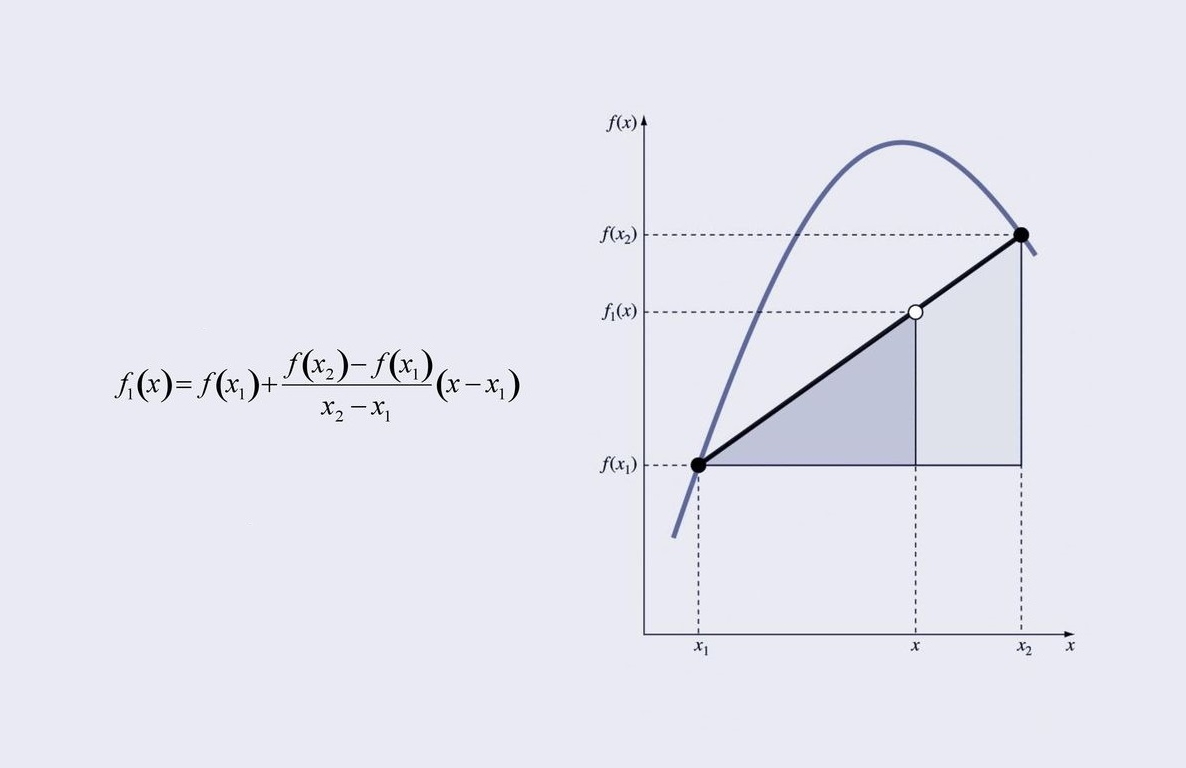
در آموزشهای قبلی مجله فرادرس، دیدیم که درونیابی لاگرانژ مبتنی بر n+1 نقطه درونیابی {xi,yi=f(xi),i=0,⋯,n} است. این همه چیزی بود که برای محاسبه هر یک از چندجملهایهای اساسی یا پایه li(x) نیاز داشتیم. اگر در صورت امکان بتوان از نقاط اضافهای استفاده کرد، باید همه چندجملهایهای پایه را در روش لاگرانژ تعویض کنیم. در مقایسه با روش لاگرانژ، در «درون یابی نیوتن» (Newton Interpolation)، وقتی نقاط بیشتری برای استفاده داشته باشیم، میتوانیم چندجملهایهای پایه بیشتر و ضرایب مربوط به آنها را محاسبه کنیم و چندجملهایهای پایه موجود و ضرایب آنها را بدون تغییر بگذاریم. بدین ترتیب، به دلیل وجود جملات اضافه، درجه چندجملهای درونیاب بزرگتر شده و ممکن است خطای تقریب کاهش پیدا کند (برای مثال، زمانی که چندجملهایهای مرتبه بالاتری را درونیابی کنیم).
و چندجملهای درونیاب نیوتن به صورت زیر تشکیل میشود:
$$ \large \begin {eqnarray}<br />
N _ n ( x ) & = & \sum _ { i = 0 } ^ n c _ i n _ i ( x ) = c _ 0 + \sum _{ i = 1 } ^ n c _ i \;<br />
\left ( \prod _ { j = 0 } ^ { i - 1 } ( x - x _ j ) \right )<br />
\nonumber \\<br />
& = & c _ 0 + c _ 1 ( x - x _ 0 ) + c _ 2 ( x - x _ 0 ) ( x -x _ 1 ) + \cdots + c _ n \prod _ { j = 0 } ^ { n - 1 } ( x - x _ j )<br />
\end {eqnarray} $$
لازم به ذکر است که آخرین نقطه (xn,yn) در هیچیک از چندجملهایهای پایه استفاده نمیشود، اما برای محاسبه آخرین ضریب cn به کار میرود. برای آنکه این چندجملهای Nn(x) مرتبه n از همه n+1 نقطه (xi,yi) برای i=0,⋯,n عبور کند، باید n+1 معادله زیر برقرار باشند:
به دلیل یکتایی درونیابی چندجملهای، این درون یابی نیوتن مانند درونیابیهای تابع توانی و لاگرانژ است: Vn(x)=Ln(x)=Pn(x). اینها چندجملهایهای مرتبه nاُم مشابهی هستند، اما با چندجملهایهای پایه وزندار مختلفی با ضرایب متفاوت تشکیل میشوند.
چند نکته مهم در مورد درون یابی نیوتن به شرح زیر است:
نکته ۱: وقتی یک نقطه اضافه (xn+1,yn+1) داشته باشیم و از آن استفاده کنیم، همه چندجملهایهای پایه قبلی و ضرایب متناظر با آنها بدون تغییر باقی میمانند و تنها لازم است یک چندجملهای پایه جدید با درجه n+1 به دست آوریم:
که دارای ضریب (n+1)اُمین تفاضل تقسیم شده cn+1=f[x0,⋯,xn,xn+1] است. چندجملهای درونیابی جدید با درجه n+1 را میتوان با در نظر گفتن جمله اضافه در مجموع بالا به دست آورد:
اما xn+1 یک نقطه دلخواه است و میتوانیم آن را با x جایگزین کنیم. در این صورت، میتوان نوشت:
f(x)=Nn(x)+f[x0,⋯,xn,x]ω(x)
با مقایسه این تابع با تابع خطا، داریم:
Rn(x)=f(x)−Nn(x)=(n+1)!f(n+1)(ξ)ω(x)
مشاهده میکنیم که تابع خطا را به صورت زیر نیز میتوان نوشت:
Rn(x)=f[x0,⋯,xn,x]ω(x)
که در آن:
f[x0,⋯,xn,x]=(n+1)!f(n+1)(ξ)
نکته ۲: اگر همه n+1 نقطه به یک موقعیت نزدیک باشند، یعنی xi→x0 (i=1,⋯,n)، در حالت حدی، به نقطه مشابه x0 تبدیل میشوند که n بار تکرار شده است. در نتیجه، داریم:
که در آن، ξ نقطهای بین x و x0 است. میبینیم که سری تیلور در واقع حالت خاصی از درون یابی نیوتن در شرایط حدی است، وقتی که n+1 نقطه به موقعیت مشابه x0 نزدیک میشوند.
نکته ۳: اگر همه n+1 نقطه x0=a≤x1≤⋯≤xn−1≤xn=b فواصل برابری داشته باشند، یعنی داشته باشیم:
xi+1−xi=h=nb−a,(i=0,⋯,n−1)
در نتیجه، درونیابی تفاضل تقسیم شده نیوتن را میتوان به فرم سادهتری نوشت. برای هر نقطه x∈(a,b)، مقدار c=(x−x0)/h را به گونهای در نظر میگیریم که بتوان آن را به صورت x=x0+ch و x−xi=(x0+ch)−(x0+ih)=(c−i)h نشان داد. اکنون چندجملهای نیوتن به صورت زیر نوشته میشود:
$$ \large \begin {eqnarray}<br />
N ( x ) & = & N( x _ 0 + c h ) = f [ x _ 0 ] + \sum _ { i = 1 } ^ n f [ x _ 0 , \cdots , x _ i ] \prod _ { j = 0 } ^ { i - 1 } ( x - x _ j )<br />
\nonumber \\<br />
& = & f [ x _ 0 ] + f [ x _ 0 , x _ 1 ] c h + f [ x _ 0 , x _ 1 , x _ 2 ] c ( c - 1 ) h ^ 2<br />
+ \cdots + f [ x _ 0 , \cdots , x _ n ] c ( c - 1 ) \cdots ( c -n + 1 ) h ^ n<br />
\nonumber \\<br />
& = & \sum _ { i = 0 } ^ n f [ x _ 0 , \cdots , x _ i ] c ( c - 1 ) ( c - 2 ) \cdots ( c - i + 1 ) h ^ i<br />
= \sum _ { i = 0 } ^ n f [ x _ 0 , \cdots , x _ i ] \left ( \begin {array} { c } c \\ i \end {array} \right ) i ! \; h ^ i<br />
\end {eqnarray} $$
که در آن:
(ci)=i!(c−i)!c!=i!c(c−1)(c−2)⋯(c−i+1)
مثال درون یابی نیوتن
تابع y=f(x)=xsin(2x+π/4)+1 را با یک چندجملهای درجه n=3، بر اساس n+1=4 نقطه زیر تقریب بزنید.
حل: بر اساس f[xi]=f(xi),(i=0,⋯,n)، میتوانیم همه تفاضلهای تقسیم شده دیگر را به صورت بازگشتی به فرم جدول زیر بنویسیم. در حالت کلی، f[xi,⋯,xj] را میتوان بر اساس همسایه سمت چپ f[xi+1,⋯,xj] و همسایه سمت چپ f[xi,⋯,xj−1] به دست آورد:
ضرایب، چهار تفاضل تقسیم شده روی قطر هستند: c0=f[x0]=f(x0)=y0=1.937، c1=f[x0,x1]=−0.937، c2=f[x0,x1,x2]=0.643 و c3=f[x0,x1,x2,x3]=−0.663. یک راه دیگر برای نشان دادن ضرایب، استفاده از فرم گسترش یافته است:
در نهایت، چندجملهای درونیاب نیوتن به صورت زیر به دست میآید:
$$ \large \begin {eqnarray}<br />
N _ 3 ( x ) & = & \sum _ { i = 0 } ^ 3 c _ i n _ i ( x )<br />
\nonumber \\<br />
& = & 1.937 - 0.937 ( x + 1 ) + 0.643 ( x + 1 ) ( x - 0 ) - 0.663 ( x + 1 ) ( x - 0 ) ( x - 1 )<br />
\nonumber \\<br />
& = & 1 + 0.369 \, x + 0.643 \, x ^ 2 - 0 . 663 \, x ^ 3<br />
\nonumber<br />
\end {eqnarray} $$
درونیابیهای چندجملهای با استفاده از روش سری توانی، لاگرانژ و نیوتن دقیقاً با هم برابرند: P3(x)=L3(x)=N3(x). این مورد یکتایی درونیابی چندجملهای را نشان میدهد که در شکلهای زیر برای y=f(x) نشان داده شده است.
پیادهسازی درون یابی نیوتن در متلب
کد متلب روش دون یابی نیوتن در ادامه ارائه شده است. ضرایب ci=f[x0,⋯,xn],(i=0,⋯,n) را میتوان با استفاده از فرم گسترش یافته یا فرم جدول به صورت بازگشتی تولید کرد.
سید سراج حمیدی دانشآموخته مهندسی برق است و به ریاضیات و زبان و ادبیات فارسی علاقه دارد. او آموزشهای مهندسی برق، ریاضیات و ادبیات مجله فرادرس را مینویسد.
شما در حال مطالعه نسخه آفلاین یکی از مطالب «مجله فرادرس» هستید. لطفاً توجه داشته باشید، ممکن است برخی از قابلیتهای تعاملی مطالب، مانند امکان پاسخ به پرسشهای چهار گزینهای و مشاهده جواب صحیح آنها، نمایش نتیجه آزمونها، پاسخ تشریحی سوالات، پخش فایلهای صوتی و تصویری و غیره، در این نسخه در دسترس نباشند. برای دسترسی به نسخه آنلاین مطلب، استفاده از کلیه امکانات آن و داشتن تجربه کاربری بهتر اینجا کلیک کنید.