



دستور Join و انواع آن در SQL – راهنمای جامع
در این مطلب از مجموعه مطالب کامپیوتر مجله فرادرس، به کارکرد دستور Join و انواع آن در SQL پرداخته شده است. دستور Join در SQL برای ترکیب کردن ستونهای یک یا چند جدول با یکدیگر در «پایگاه داده رابطهای» (Relational DataBase) مورد استفاده قرار میگیرد. میتوان گفت که دستور Join در SQL متناظر با عملیات Join در جبر رابطهای (Relational Algebra) است. دستور join در SQL یک مجموعه میسازد که امکان ذخیرهسازی یا استفاده از آن به عنوان جدول وجود دارد. دستور join در واقع ابزاری برای ترکیب ستونها از یک (join داخلی در یک جدول) یا تعداد بیشتری از جداول با یکدیگر، با استفاده از مقادیر مشترک آنها است. موسسه ملی استانداردهای آمریکا (ANSI)، پنج نوع از دستور join را تعریف میکند. این پنج نوع دستور join در SQL عبارتند از:

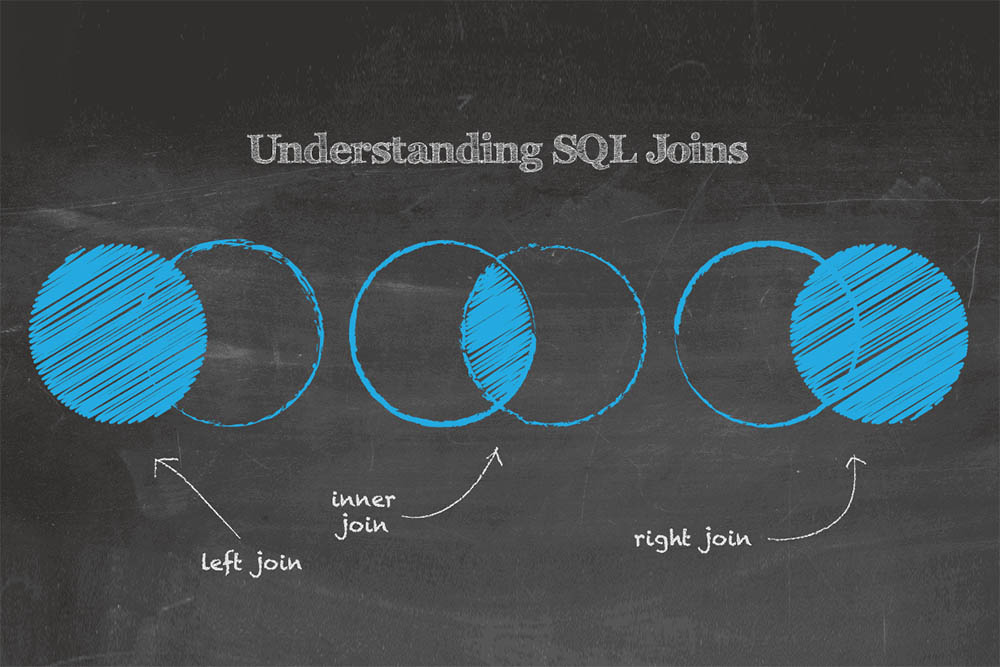


- inner join
- left join یا left outer join
- full join یا full outer join
- cross
به عنوان یک حالت خاص، یک جدول میتواند با خودش join شود که به این حالت، self join گفته میشود. برنامهنویس، از دستور join برای تعیین سطرهایی که باید با یکدیگر ترکیب شوند استفاده میکند. در صورتی که گزاره ارزیابی شده صحیح باشد، سطر ترکیب شده در قالب مورد انتظار برنامهنویس که یک سطر یا یک جدول موقت است، تولید میشود. در واقع، زمانی که بین دو جدول موجود در SQL عملیات join را انجام میدهیم، از هر جدول یک ستون را انتخاب و به یکدیگر الحاق کنیم. این دو ستون، شامل دادههای مشترک در میان دو جدول هستند. میتوان از چندین دستور join در یک دستور واحد SQL استفاده کرد؛ این قابلیت، این امکان را فراهم میکند تا ستونهای گوناگون از جداول مختلف، به یکدیگر ملحق شوند.
پیش از پرداختن به انواع دستور join در SQL، یک جدول ساده در SQL، به عنوان نمونه مورد بررسی قرار میگیرد و سپس، انواع دستور join در SQL روی این جدول اعمال و تشریح میشود. پایگاه دادههای رابطهای عموما به منظور حذف اطلاعات تکراری مانند موجودیتهای دارای روابط یک به چند، نرمال میشوند. برای مثال، جدول مربوط به دپارتمان (جدول مربوط به Department) ممکن است با تعدادی از کارکنان (در جدول Employee) مرتبط باشد. الحاق (join) جداول جداگانه برای دپارتمان و کارکنان، جدول دیگری را میسازد که اطلاعات از هر دو جدول را با یکدیگر ترکیب میکند.
برای درک بیشتر نحوه کارکرد این دستور، پیشنهاد میکنیم ویدیوی آموزشی رایگان زیر را تماشا کنید:
در بخش بعدی که انواع دستور join در SQL مورد بررسی قرار گرفته است، از جداول زیر استفاده شده است. در عین حال، مثالهایی نیز با جداول دیگر ارائه شده تا به درک هر چه بهتر و بیشتر مطلب دستور Join و انواع آن در SQL کمک کند. سطرهای جدولهای زیر برای نشان دادن هر چه بهتر تاثیرات انواع دستور join در sql به شکلی که مشاهده میشود طراحی شدهاند. در جدول Department، ستون DepartmentID، «کلید اصلی» (Primary Key) است که به صورت Department.DepartmentID تعیین میشود، در حالی که Employee.DepartmentID، کلید خارجی محسوب میشود.

در جدول Employee، کارمندی به نام Williams هنوز به هیچ دپارتمانی تخصیص داده نشده است. همچنین، هیچ کارمندی به دپارتمان بازاریابی (Marketing) اختصاص پیدا نکرده است. برای ساخت جداول بالا، از دستورات زیر استفاده میشود.
انواع دستور join در SQL
چنانکه پیش از این نیز به آن اشاره شد، انواع گوناگونی از دستور join در SQL وجود دارد که کاربر بسته به نیاز خود میتواند از آنها استفاده کند. این دستورات با یکدیگر تفاوتهای ظریف اما بسیار مهمی دارند که موجب کاربردهای قابل توجه و متمایز آنها شده است. در ادامه، انواع دستور join در SQL همراه با ارائه مثال مورد بررسی قرار میگیرد.
cross join
Cross join حاصلضرب دکارتی (Cartesian Product) سطرهای تعیین شده در دستور join را در خروجی ارائه میکند. این دستور، سطرهایی را تولید میکند که ترکیبی از سطر جدول اول و دوم است. مثالی از دستور cross join در SQL و به صورت صریح (Explicit)، در ادامه آمده است.
مثالی از دستور cross join در SQL و به صورت ضمنی (Implicit)، در ادامه آمده است.

cross join به تنهایی هیچ گزارهای برای فیلتر کردن سطرها از جداول به یکدیگر ملحق شده اعمال نمیکند. نتایج cross join را میتوان با استفاده از دستور where فیلتر کرد که در این صورت، خروجی آن مشابه با خروجی inner join خواهد بود. در SQL:2011 استاندارد، cross join بخشی از بسته اختیاری برای F401 یعنی بسته «جدول الحاق توسعه یافته» (Extended Joined Table) است. معمولا از دستور cross join برای بررسی کارایی سرور استفاده میشود.
inner join
دستور inner join نیاز به آن دارد که سطرهای موجود در جدولهایی که قرار است به هم ملحق شوند، مقادیر ستون مشابهی داشته باشند. از دستور inner join به طور متداول در برنامههای کاربردی استفاده میشود؛ اما نباید چنین پنداشته شود که الزاما برای هر شرایطی مناسب است.
دستور inner join با ترکیب مقادیر ستونهای دو جدول (جدول A و B) بر مبنای گزاره join، یک جدول نتیجه جدید میسازد. این دستور هر سطر از A را با هر سطر از B مقایسه میکند تا همه جفتهایی که گزاره join را ارضا میکنند پیدا کند. هنگامی که گزاره Join با تطبیق مقادیری غیر از هیچ مقدار (non-NULL) ارضا میشود، مقادیر ستونها برای هر یک از سطرهای تطبیق داده شده A و B در یک سطر ننتیجه ترکیب میشوند.

نتایج دستور join را میتوان به عنوان خروجی اعمال ضرب دکارتی (یا cross join) بر همه سطرهای جدول (ترکیب همه سطرها در جدول A با هر سطری در جدول B) و سپس، بازگرداندن همه سطرهایی تعریف کرد که گزاره دستور join را ارضا میکنند. پیادهسازیهای SQL اساسا از رویکردهای دیگری مانند Hash Join یا join مرتبسازی ادغامی (Sort-Merge Join) استفاده میکنند. زیرا محاسبه ضرب دکارتی، کندتر است و معمولا، فضای حافظه زیادی را برای انجام ذخیرهسازی نیاز دارد.
SQL دو راهکار نحوی مختلف را برای بیان Join استفاده میکند؛ این دو راهکار عبارتند از «اعلان صریح الحاق» (Explicit Join Notation) و «اعلان ضمنی الحاق» (Implicit Join Notation). اعلان ضمنی join دیگر به عنوان بِهروشی برای دستور join در نظر گرفته نمیشود؛ هرچند که سیستمهای پایگاه داده همچنان از آن پشتیبانی میکنند. در اعلان صریح join، از کلیدواژه join استفاده میشود که به طور دلخواه پیش از کلیدواژه inner میآید تا جدول را برای join و کلیدواژه on را برای تعیین گزارش برای دستور join تعیین کند. آنچه بیان شد، در مثال زیر به خوبی قابل مشاهده است.

دستور ضمنی الحاق، جداول را در عبارت From از دستور Select برای join لیست و از ویرگول (Comma) برای جدا کردن آنها استفاده میکند. بنابراین، یک cross join تعریف میکند و عبارت where ممکن است فیلترهای گزاره اضافهای را اعمال کند. مثال زیر برابر با مثال پیشین است، با این تفاوت که این بار از اعلان ضمنی join استفاده شده است.
پرسش و پاسخ (کوئری | Query) داده شده در مثال بالا، جداول Employee و Department را با استفاده از ستون DepartmentID هر دو جدول ملحق (join) میکند.در جایی که DepartmentID این جدولها مطابقت دارد (گزاره join ارضا شده است)، کوئری، ستونهای DepartmentID ،LastName و DepartmentName از دو جدول را در سطر نتیجه ترکیب میکند. در جایی که DepartmentID تطابق ندارد، هیچ سطر نتیجهای تولید نمیشود. بنابراین، نتایج حاصل از اجرای کوئری بالا به صورت زیر است.

کارمند «Williams» و دپارتمان «Marketing» در نتایج حاصل از اجرای کوئری ظاهر نمیشوند. دلیل این امر آن است که هیچ یک از این دو، با هیچ سطر دیگری در جدول دیگر، مطابقت ندارند. «Williams» هیچ دپارتمان تخصیص یافتهای ندارد و به Marketing هیچ کارمندی تخصیص داده نشده است. با توجه به اینکه نیاز کاربر چیست، وقوع آنچه برای کارمند «Williams» و دپارتمان «Marketing» بیان شد، ممکن است یک اشکال ظریف محسوب شود که با اعمال outer join به جای inner join، قابل پیشگیری است.
inner join و مقادیر NULL
برنامهنویسها باید هنگام الحاق جداول بر اساس ستونهایی که مقادیر NULL دارند، دقت زیادی به خرج دهند. دلیل این امر آن است که NULL با هیچ مقدار دیگری (حتی با خود NULL) مطابقت ندارد؛ مگر اینکه شرط اتصال صراحتا از گزاره ترکیبی استفاده کند که ابتدا ستونهای join را، پیش از اعمال گزاره شرطی، از جهت NULL نبودن بررسی میکنند. inner join میتواند به صورت امنی در پایگاه دادهای مورد استفاده قرار بگیرد که «یکپارچگی مرجع» (Referential Integrity) را اعمال میکند و یا، ستونهای join به طور تضمینی NULL نباشند.

بسیاری از پایگاه دادههای رابطهای پردازش تراکنش، بر استانداردهای به روز رسانی داده «اسید» (ACID که سرنامی برای واژههای «تجزیهناپذیری» (Atomicity)، «هم خوانی» (Consistency)، «انزوا» (Isolation) و «پایایی» (Durability)) تکیه دارند تا از یکپارچگی دادهها اطمینان حاصل کنند و همین امر موجب میشود که inner join به گزینهای نامناسب مبدل شود.
اگرچه، پایگاهدادههای تراکنشی معمولا ستونهای قابل join مناسبی دارند که امکان NULL بودن آنها نیز وجود دارد. بسیاری از پایگاه دادههای رابطهای و انبارهای داده (Data Warehouse) از به روز رسانیهای ETL (سرنامی برای «استخراج» (Extract)، «تبدیل» (Transform) و «بارگذاری» (Load)) استفاده میکنندکه یکارچگی مرجع را دشوار و یا غیر ممکن میسازد که به نوبه خود منجر به ستونهای join از نوع NULL میشود که نویسنده کوئری SQL نمیتواند آنها را ویرایش کند و در نهایت منجر به آن میشود که inner join دادهها را بدون نمایش خطا حذف کند. انتخاب اینکه از inner join استفاده شود یا خیر، بستگی به طراحی پایگاه داده و مشخصههای داده دارد. left outer join معمولا میتواند به عنوان جایگزینی برای الحاق داخلی در نظر گرفته شود که در آن، ستونهای Join در یک جدول ممکن است حاوی مقادیر NULL باشند.
هر ستون دادهای که ممکن است NULL باشد، نباید هرگز به عنوان یک لینک در یک inner join در نظر گرفته شود، مگر آنکه نتیجه مورد نظر، حذف سطرهایی با مقدار NULL باشد. اگر ستونهای NULL برای join، تعمدا از مجموعه نتیجه جذف شوند، یک inner join سریعتر از یک outer join خواهد بود، زیرا که join جدو و فیلتر کردن در یک گام یکتا انجام میشود. متقابلا، یک inner join میتواند منجر به کند شدن کارایی به طور فاجعهباری شود و یا حتی، در هنگام استفاده در کوئری بزرگ در ترکیب با توابع پایگاه داده SQL در عبارت Where در پایگاه داده، منجر به خطای سرور شود.
یک تابع در دستور where در SQL، میتواند منجر به آن شود که پایگاه داده، شاخصهای جدول نسبتا فشرده را نادیده بگیرد. پایگاه داده ممکن است ستونهای انتخاب شده را از هر دو جدول بخواند و inner join را روی آنها انجام دهد، پیش از آنکه تعداد سطرها را با استفاده از فیلتری که وابسته به مقادیر محاسبه شده است کم کند و همین منجر به حجم قابل توجهی از پردازشهایی میشود که نیازی به آنها نبوده است.
هنگامی که مجموعه نتایج با الحاق چندین جدول شامل جدولهای اصلی (Master Tables) تولید شد که برای بررسی توصیفات کامل متنی کدهای شناساگرهای عددی (جدول Lookup) مورد استفاده قرار میگیرند، یک مقدار NULL در هر یک از کلیدهای خارجی میتواند منجر به آن شود که کل سطر از مجموعه نتایج بدون نمایش هیچ گونه پیام خطایی، حذف شود. یک کوئری SQL که شامل یک یا تعداد بیشتری inner join و outer join است، خطر مشابهی را برای مقادیر NULL در inner join دارد.
Equi-join
Equi-join نوع خاصی از join مبتنی بر مقایسه است که تنها از مقایسه برابری در گزاره join استفاده میکند. استفاده از دیگر عملگرهای مقایسهای (مانند <)، موجب میشود که join از نوع Equi-join محسوب نشود. کوئری مربوط به مثالی که پیشتر ارائه شد، در ادامه مجددا به عنوان مثالی از Equi-join آمده است.
دستور Equi-join را میتوان به صورت زیر نوشت.
اگر ستونها در یک Equi-join دارای نام مشابهی باشند، SQL-92 از یک اعلان کوتاه با استفاده از USING برای انجام equi-join بهره میبرد.
استفاده از USING، نقشی فراتر از تسهیل برنامهنویسی دارد؛ اگرچه، تا هنگامی که مجموعه نتایج متفاوت از مجموعه نتایج نسخه با گزاره صریح است، هر ستون معین شده در لیست USING تنها یک بار با یک اسم فاقد صلاحیت نمایش داده خواهد شد؛ به جای آنکه هر بار برای هر جدول در join نمایش داده شود.
Natural Join
Natural Join نوع خاصی از equi-join است. Natural Join (⋈) یک عملگر دودویی است که به صورت R ⋈ S نوشته میشود و در آن، R و S روابط هستند. نتایج Natural Join مجموعهای از ترکیبهای تاپلها در R و S است که در نام خصیصه مشترک خود با یکدیگر برابر هستند. برای درک بهتر موضوع و به عنوان مثالی، جداول Employee و Dept و همچنین، Natural Join آنها آمده است.

از Natural Join میتوان برای تعریف ترکیب روابط (Composition of Relations) استفاده کرد. برای مثال، ترکیب Employee و Dept همانطور که در بالا نمایش داده شده است، join آنها است که روی همه خصیصهها به جز خصیصه مشترک DeptName طرحریزی شده است. در «نظریه رسته» (Category Theory)، دستور join دقیقا «عقببَر» (Pullback | Fiber product) است. natural join احتمالا یکی از مهمترین عملگرها است، زیرا همتای رابطهای AND منطقی است.
شایان توجه است که اگر برخی از متغیرها در هر یک از دو گزارهای ظاهر شوند که توسط AND به یکدیگر مرتبط شدهاند، آن متغیر نیز بر مورد مشابهی دلالت خواهد داشت و هر دو وقوع باید همیشه با مقدار مشابهی جایگزین شوند. به طور خاص، natural join ترکیبی از روابط را فراهم میکند که به وسیله یک کلید خارجی مرتبط شدهاند. برای مثال، در مثال بالا، یک کلید خارجی احتمالا از Employee.DeptName تا Dept.DeptName را نگهداری میکند و سپس، الحاق طبیعی Employee و Dept همه کارکنان را با دپارتمانهای آنها ترکیب میکند. این مورد بدین دلیل مناسب است که کلید خصوصی بین خصیصههایی با نام مشابه نگه داشته میشود. اگر این مورد مانند آنچه در کلید خارجی برای Dept.manager تا Employee.Name صدق نمیکند، این ستونها باید پیش از اعمال natural join باید تغییر نام داده شوند. این نوع join گاهی با عنوان equi-join نیز نامیده میشود. به بیان دقیقتر، مفاهیم natural join به صورت زیر تعریف میشوند.

گزاره Fun برای رابطه r درست تشخیص داده میشود اگر و تنها اگر r یک تابع باشد. معمولا نیاز به آن است که R و S حداقل یک خصیصه مشترک داشته باشند، اما اگر این محدودیت حذف شود و R و S هیچ خصیصه مشترکی نداشته باشند، natural join دقیقا برابر با ضرب دکارتی خواهد بود. natural join را میتوان با استفاده از قانون اولیه :کاد» (Codd) به صورتی که در ادامه میآید شبیهسازی کرد. فرض میشود که c1, …, cm اسامی خصیصههای مشترک با R و S و r1, …, rn اسامی خصیصههای یکتا برای R و همچنین، s1, …, sk خصیصههای یکتا برای S است. علاوه بر آن، فرض میشود که خصیصههای x1, …, xm نه در R و نه در S وجود ندارند. در گام اول، اسامی خصیصههای مشترک در S را میتوان تغییر داد.

سپس، ضرب دکارتی انجام و تاپلهایی انتخاب میشوند که به یکدیگر ملحق شوند.

natural join نوعی از equi-join است که در آن، گزاره join به طور ضمنی و با مقایسه ستونهای موجود در هر دو جدولی که دارای اسامی ستونهای مشترک هستند در جدولهای Join، مشخص میشود. جدول join حاصل شده تنها دارای یک ستون برای هر جفت از ستونهای دارای نام مشترک است. در شرایطی که ستونهایی با اسامی مشابه پیدا نشوند، نتیجه در واقع یک Cross Join است.
اغلب کارشناسان بر این باور هستند که natural join خطرناک است و بنابراین، استفاده از آن را خیلی توصیه نمیکنند. خطر در پی استفاده ناخواسته یک ستون جدید که نام آن مشابه با دیگر ستون در جدول دیگر است میآید. یک natural join ممکن است «به طور طبیعی» از ستون جدید برای مقایسه استفاده کند و مقایسهها و تطبیقها را با استفاده از معیارهای جدیدی نسبت به قبل، انجام دهد.
بنابراین، یک کوئری میتواند نتایج متفاوتی را تولید کند، با اینکه داده در جدولها تغییر نکرده باشد و فقط تکمیل شده باشند. استفاده از اسامی ستونها برای تعیین خودکار لینک جداول در پایگاه دادههای بزرگی با هزاران جدول، یک گزینه نیست زیرا که یک محدودیت غیرواقعی را در مورد نامگذاریها ایجاد میکند.
پایگاه دادههای جهان واقعی عموما با یک داده کلید خارجی متناسب با قوانین و زمینه کسب و کار طراحی شدهاند که به طور مداوم شلوغ نیست (مقادیر NULL نیز پذیرفته هستند). ویرایش اسامی ستونها از دادههای مشابه در جدولهای متفاوت امری متداول نیست و این فقدان استحکام موجب میشود که natural joins صرفا به یک مبحث تئوری برای بحث تنزل پیدا کند. کوئری نمونه بالا برای inner joins را میتوان به عنوان natural join و به صورت زیر بیان کرد:
همچون عبارت USING صریح، تنها یک ستون DepartmentID در جدول join بدون هرگونه توصیفگری اتفاق میافتد.

PostgreSQL ،MySQL و Oracle از natural joins پشتیبانی میکنند. این در حالی است که Microsoft T-SQL و IBM DB2 از این دستور پشتیبانی نمیکنند. ستونهای استفاده شده در join صریح هستند، بنابراین، کد join نشان نمیدهد که کدام ستونها مورد انتظار هستند و یک تغییر در نام ستونها ممکن است کل نتایج را تغییر دهد. در استاندارد SQL:2011، الحاق طبیعی یا همان natural join بخشی از بسته «F401» است. در بسیاری از محیطهای پایگاه داده، اسامی ستونها به وسیله یک فروشنده خارجی و نه توسعهدهنده کوئری، کنترل میشود.
چند مثال دیگر از انواع inner join در SQL
عبارت نمونه SQL
SELECT * FROM Individual INNER JOIN Publisher ON Individual.IndividualId = Publisher.IndividualId WHERE Individual.IndividualId = '2';
جدول چپ

جدول راست

نتیجه

در ادامه دستور Outer Join را بررسی میکنیم.
Outer join
جدول متصل شده هر سطری را حفظ میکند، حتی اگر هیچ سطر منطبق دیگری نیز وجود نداشته باشد. Outer join به انواع right outer join ،left outer join و full outer join تقسیم میشود. این تقسیمات بر اساس اینکه کدام سطر از جدول باقی میماند، سطر چپ، راست یا هر دو، انجام میشود (در این مورد، منظور از چپ و راست، دو سمت کلیدواژه join هستند). مانند inner join، میتوان انواع گوناگونی از Join شامل natural join ،equi-join و <ON <predicate (که به آن θ-join گفته میشود) و دیگر انواع را تعریف کرد.
Left outer join
نتیجه left outer join که به اختصار به آن left join گفته میشود، برای جداول A و B حاوی همه سطرهای جدول چپ (A) است، حتی اگر شرط join هیچ سطر مطابقی در جدول سمت راست (B) پیدا نکند. این یعنی، اگر عبارت ON با 0 (صفر) سطر در B مطابق باشد (برای یک سطر داده شده از A)، دستور join همچنان یک سطر را در نتیجه باز میگرداند (برای آن سطر) که ستونهای آن از B دارای مقدار NULL است. left outer join همه مقادیر از inner join به علاوه همه مقادیر در جدول سمت چپ را که با جدول سمت راست مطابقت ندارند، شامل سطرهایی با مقادیر NULL (خالی) در ستون پیوند را باز میگرداند.

برای مثال، این مورد امکان پیدا کردن دپارتمان یک کارمند را فراهم میکند، اما کارمندی که همچنان به یک دپارتمان تخصیص داده نشده است (بر خلاف inner-join مثال بالا، که در آن کارکنانی که به هیچ دپارتمانی تخصیص داده نشدهاند از نتایج حذف میشوند). مثالی از left outer join (کلیدواژه OUTER اختیاری است)، با سطرهای افزوده (در مقایسه با inner join) در ادامه آمده است و به صورت ایتالیک (خط مورب) در جدول نمایش داده شدهاند.

نحوهای جایگزین
اوراکل از دستور نحوی نسبتا منسوخ شده زیر نیز پشتیبانی میکند.
Sybase از نحو زیر پشتیبانی میکند (این نحو در مایکروسافت اسکیوال سرور از نسخه ۲۰۰۰ به بعد منسوخ شده است).
آیبیام اینفورمیکس (IBM Informix) از نحو زیر پشتیبانی نمیکند.
مثال تکمیلی از left outer join
دستور
SELECT * FROM Individual AS Ind LEFT JOIN Publisher AS Pub ON Ind.IndividualId = Pub.IndividualId;
جدول چپ

جدول راست

نتیجه

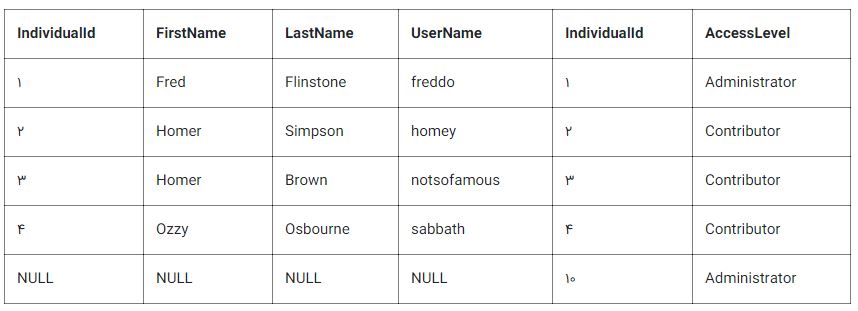
Right outer join
right outer join که به طور خلاصه به آن right join گفته میشود، شباهت زیادی به left outer join دارد، با این تفاوت که جدولهای برگردانده شده را نیز در نظر میگیرد. هر سطر از جدول سمت راست B دستکم یکبار در جدول الحاق شده نمایش داده میشود. اگر هیچ سطر مطابقی از جدول چپ (A) وجود نداشته باشد، در ستونهای جدول A برای آنهایی که هیچ مطابقی در B ندارند، مقدار NULL نمایش داده میشود.

right outer join همه مقادیر را از جدول سمت راست و مقادیر تطبیق یافته از جدول سمت چپ را باز میگرداند (در حالتی که هیچ گزاره join منطبقی وجود نداشته باشد، NULL بازگردانده میشود). برای مثال، این کار امکان آن را فراهم میکند که هر کارمندی و درپارتمان او پیدا شود؛ اما همچنان دپارتمانهایی که هیچ کارمندی به آنها تخصیص داده نشده است را نیز نمایش میدهد. در ادامه، مثالی از right outer join ارائه شده است (کلیدواژه OUTER اختیاری است). در جدول نتایج، مواردی که با خط مورب هستند نکات قابل توجه این نوع از Join را نمایش میدهند.
Left outer join و Right outer join به لحاظ کارکردی مشابه با یکدیگر هستند. هیچ یک از این دو دستور هیچ کارکردی را فراهم نمیکنند که دیگری نیز فراهم نمیکند، بنابراین، Left outer join و Right outer join در صورت تغییر ترتیب جدول، جایگزین یکدیگر میشوند.
مثال تکمیلی
دستور
SELECT * FROM Individual AS Ind RIGHT JOIN Publisher AS Pub ON Ind.IndividualId = Pub.IndividualId;
جدول چپ

جدول راست

نتیجه

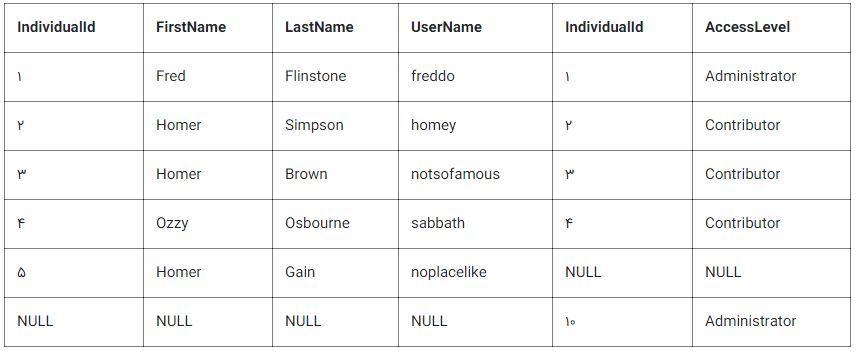
full outer join
به لحاظ مفهومی، دستور full outer join تاثیرات اعمال Left outer join و Right outer join را به طور همزمان دارد. هنگامی که سطرها در جداول full outer join شده تطبیق ندارند، کل مجموعه دارای مقادیر NULL برای هر ستون از جدول است که فاقد سطر دارای تطبیق است.

برای سطرهایی که تطابق دارند، یک سطر تنها در مجموعه نتیجه تولید میشود (حاوی ستونهایی که از هر دو جدول دارای مقدار هستند). برای مثال، این مورد امکان آن را فراهم میکند که کارکنانی که در دپارتمانها هستند و هر دپارتمانی که کارمندی دارد قابل مشاهده باشد، اما در عین حال، کارکنانی که در هیچ یک از دپارتمانها نیستند و دپارتمانهایی که هیچ کارمندی ندارند نیز نمایش داده شوند.

مثالی از یک full outer join (کلیدواژه OUTER اختیاری است) در ادامه آمده است.

برخی از سیستمهای پایگاه داده از کارکرد full outer join به طور مستقیم پشتیبانی نمیکنند؛ اما میتوانند این کار را با استفاده از دستورهای inner join و UNION ALL که «سطرهای یک جدول یکتا» را از جدولهای چپ و راست به ترتیب انتخاب میکند، شبیهسازی و تقلید کرد. مثال مشابهی در ادامه آمده است.
مثال تکمیلی
دستور
SELECT * FROM Individual AS Ind FULL JOIN Publisher AS Pub ON Ind.IndividualId = Pub.IndividualId;
جدول چپ

جدول راست

نتیجه

Self-join
این دستور موجب میشود که یک جدول با خودش join شود.
مثال
اگر دو جدول جداگانه برای کارکنان وجود داشته باشد و یک کوئری که که کارکنان را در اولین جدولی که کشورهای مشابهی با کارکنان در جدول دوم دارد درخواست کرده باشد، یک عملیات join نرمال برای پیدا کردن جدول پاسخ قابل استفاده است. اگرچه، اطلاعات همه کارکنان در یک جدول بزرگ یکتا موجود است. یک جدول ویرایش شده Employee به صورت زیر مفروض است.

یک کوئری نمونه به صورت زیر است:
در کد بالا از دستور order by در sql نیز استفاده شده است. نتایج کد بالا در جدول زیر ارائه شده است.

در ادامه، توضیحات مثال بالا ارائه شده است.
- F و S اسامی مستعار برای اولین و دومین کپی از جدول کارمندان است.
- شرط F.Country = S.Country مانع از جفت شدن بین کارکنان در کشورهای مختلف میشود. پرسش نمونه، صرفا جفت کارکنان در یک کشور را میخواهد.
- شرط F.EmployeeID < S.EmployeeID مانع از جفت شدن در جایی میشود که EmployeeID از اولین کارمند، بزرگتر یا مساوی EmployeeID دومین کارمند باشد. به بیان دیگر، تاثیر این شرایط برای اجتناب از جفتهای تکراری و خودالحاقی است. بدون این کار، جدول با ارزش کمتر تولید خواهد شد (جدول زیر تنها بخش Germany نتایج را نمایش میدهد).

تنها یکی از جفت کردنهای میانی برای ارضای پرسش اصلی مورد نیاز است و بالاترین و پایینترینها در این مثال اهمیتی ندارند.
جایگزین دستور join در SQL
اثر outer join به وسیله دستور UNION ALL بین یک INNER JOIN و SELECT سطرها در جدول اصلی (Main Table) که شرایط join را برآورده نمیکند قابل حصول است. برای مثال:
همچنین، کد بالا را به صورت زیر نیز میتوان نوشت.
منابع و فیلم آموزش پایگاه داده
در ادامه، منابع آموزشی و در واقع، فیلمهای آموزش پایگاه داده به زبان فارسی معرفی شدهاند.

فیلم آموزش پایگاه داده

طول مدت این دوره آموزشی هفت ساعت و پنجاه و هشت دقیقه و مدرس آن مهندس فرشید شیرافکن هستند. این آموزش برای کلیه علاقهمندان به علوم و مهندسی کامپیوتر، دانشجویان رشتههای حوزه فناوری اطلاعات، برنامهنویسان، فعالان حوزه دادهکاوی و علم داده، فعالان حوزه یادگیری ماشین، دانشجویان رشته علم اطلاعات و دانششناسی و سایر علاقهمندان و افرادی که نیاز به فراگیری مباحث پایگاه داده دارند، مناسب است. در فیلم آموزش پایگاه داده فرادرس، ابتدا مفاهیم و تعاریف اولیه سیستم پایگاه داده مورد بررسی قرار گرفته است. سپس، به ساختار دادهای رابطهای، مدل موجودیت-رابطه (Entity–Relationship Model)، جبر رابطهای، زبان SQL، وابستگی تابعی و نرمالترسازی پرداخته شده است. کلیه مباحث ارائه شده در این آموزش، همراه با مثالهای متعددی هستند تا به درک بهتر مطلب توسط مخاطب کمک کنند.
- برای دیدن فیلم آموزش فیلم آموزش پایگاه داده + اینجا کلیک کنید.
فیلم آموزش SQL Server مقدماتی

طول مدت این دوره آموزشی نه ساعت و شش دقیقه است و مدرس آن، مهندس ضحی شبر هستند. این آموزش برای کلیه علاقهمندان به علوم و مهندسی کامپیوتر، دانشجویان رشتههای حوزه فناوری اطلاعات، برنامهنویسان و به طور خاص توسعهدهندگان وب، فعالان حوزه دادهکاوی و علم داده، فعالان حوزه یادگیری ماشین، دانشجویان رشته علم اطلاعات و دانششناسی و سایر علاقهمندان و افرادی که نیاز به فراگیری مباحث پایگاه داده دارند، مناسب است. از جمله مباحث مورد بررسی در فیلم آموزش SQL Server مقدماتی میتوان به آشنایی با محیط اسکیوال سرور، طراحی و مدیریت یک پایگاه داده، معرفی مدل رابطهای و تحلیل اولیه یک سیستم پایگاه داده (با استفاده از مثال سیستم انتخاب واحد)، تشریح دستورات درج، حذف، ویرایش و خواندن داده در جدول، معرفی قابلیت فایل استریم، معرفی Viewها و روش پیادهسازی آنها، آشنایی با دستورات مقدماتی برای برنامهنویسی در SQL Server، آشنایی با برنامهنویسی در SQL Server توسط Stored Procedureها، آشنایی با برنامهنویسی در SQL Server توسط Function، پشتیبانگیری به صورت دستی و خودکار، معرفی سرورهای متصل (Linked Server) و روش پیادهسازی آنها، آشنایی با مفهوم Synonym و پیادهسازی آن و معرفی Replication و روش پیادهسازی انواع آن اشاره کرد.
- برای دیدن فیلم آموزش SQL Server مقدماتی + اینجا کلیک کنید.
فیلم آموزش SQL Server تکمیلی

طول مدت این دوره آموزشی پنج ساعت و پنجاه و هشت دقیقه است و مدرس آن، مهندس یوسف مسعودی سبحانزاده هستند. این آموزش برای افرادی که فیلم آموزش SQL Server مقدماتی را مشاهده کردهاند و کلیه علاقهمندان به علوم و مهندسی کامپیوتر، دانشجویان رشتههای حوزه فناوری اطلاعات، برنامهنویسان و به طور خاص توسعهدهندگان وب، فعالان حوزه دادهکاوی و علم داده، فعالان حوزه یادگیری ماشین، دانشجویان رشته علم اطلاعات و دانششناسی و سایر علاقهمندانی که با مباحث مقدماتی پایگاه دادهها آشنایی دارند، مناسب است. از جمله سرفصلهای این دوره آموزشی میتوان به رویههای ذخیره شده، تریگرها، تراکنشها، مدیریت استثناها، امنیت و رمزگذاری در SQL، دستورات شرطی و کرسرها، معرفی مجموعهای از دستورات کلیدی و به کارگیری SQL در شبکههای محلی و وب اشاره کرد.
- برای دیدن فیلم آموزش SQL Server تکمیلی + اینجا کلیک کنید.
فیلم آموزش دستورهای پایگاه داده در SQL Server

طول مدت این دوره آموزشی سه ساعت و مدرس آن، مهندس سیدرضا هاشمیان است. این آموزش برای کلیه علاقهمندان به علوم و مهندسی کامپیوتر، دانشجویان رشتههای حوزه فناوری اطلاعات، برنامهنویسان و به طور خاص توسعهدهندگان وب، فعالان حوزه دادهکاوی و علم داده، فعالان حوزه یادگیری ماشین، دانشجویان رشته علم اطلاعات و دانششناسی و سایر علاقهمندان و افرادی که نیاز به فراگیری مباحث پایگاه داده و به خصوص دستورات پایگاه داده در SQL Server دارند، مناسب است. از جمله مباحث مورد بررسی در فیلم آموزش کار با دستورهای پایگاه داده در SQL Server میتوان به آشنایی با پرس و جو (کوئری)، معرفی دستورهای مدیریت پایگاه داده، معرفی دستورهای اولیه CRUD، آشنایی دقیقتر با دستورهای فراخوانی اطلاعات، انواع JOIN در SQL، کار با Viewها و آشنایی با توابع کاربردی اشاره کرد.
- برای دیدن فیلم آموزش کار با دستورهای پایگاه داده در SQL Server + اینجا کلیک کنید.
فیلم آموزش پایگاه داده اسکیولایت (SQLite) در سی شارپ (#C)

طول مدت این دوره آموزشی دو ساعت و چهل دقیقه و مدرس آن، مهندس محمد وفاییمقدم است. این آموزش برای علاقهمندان به فراگیری پایگاه داده اسکیولایت که با زبان «سیشارپ» (C#) به برنامهنویسی میپردازند، مناسب است. در عین حال، این آموزش برای کلیه علاقهمندان به علوم و مهندسی کامپیوتر، دانشجویان رشتههای حوزه فناوری اطلاعات، برنامهنویسان و به طور خاص توسعهدهندگان وب، فعالان حوزه دادهکاوی و علم داده، فعالان حوزه یادگیری ماشین، دانشجویان رشته علم اطلاعات و دانششناسی و سایر علاقهمندان و افرادی که نیاز به فراگیری مباحث پایگاه داده و به خصوص دستورات پایگاه داده اسکیولایت (SQLite) دارند مناسب است. از جمله مباحث مورد بررسی در فیلم آموزش پایگاه داده اسکیولایت (SQLite) در سی شارپ (#C) میتوان به معرفی پایگاه داده SQLite، روش شروع کار با SQLite و استفاده از پایگاه داده طراحی شده در زبان سی شارپ اشاره کرد.
- برای دیدن فیلم آموزش پایگاه داده اسکیولایت (SQLite) در سی شارپ (#C) + اینجا کلیک کنید.
فیلم آموزش پایگاه داده LocalDB پروژهمحور در سی شارپ (#C) - سیستم مدیریت کارمندان

طول مدت این دوره آموزشی دوازده ساعت و هجده دقیقه و مدرس آن، مهندس عبداله اسکندری است. این آموزش برای علاقهمندان به فراگیری پایگاه داده LocalDB که با زبان «سیشارپ» (C#) به برنامهنویسی میپردازند، مناسب است. در عین حال، این آموزش برای کلیه علاقهمندان به علوم و مهندسی کامپیوتر، دانشجویان رشتههای حوزه فناوری اطلاعات، برنامهنویسان و به طور خاص توسعهدهندگان وب، فعالان حوزه دادهکاوی و علم داده، فعالان حوزه یادگیری ماشین، دانشجویان رشته علم اطلاعات و دانششناسی و سایر علاقهمندان و افرادی که نیاز به فراگیری مباحث پایگاه داده و به خصوص دستورات پایگاه داده LocalDB دارند مناسب است. از جمله مباحث مورد بررسی در فیلم آموزش پایگاه داده LocalDB پروژهمحور در سی شارپ (#C) میتوان به تحلیل نرمافزار پایگاه داده LocalDB، طراحی دیتابیس و پیادهسازی یک پروژه برای کار با پایگاه داده LocalDB با نام مدیریت کارمندان اشاره کرد.
- برای دیدن فیلم آموزش پایگاه داده LocalDB پروژهمحور در سی شارپ (#C) + اینجا کلیک کنید.
فیلم آموزش مدیریت بانک اطلاعات اوراکل

طول مدت این دوره آموزشی نه ساعت و دوازده دقیقه و مدرس آن، مهندس حمیدرضا پاکپور حاجیها است. این آموزش برای کلیه علاقهمندان به علوم و مهندسی کامپیوتر، دانشجویان رشتههای حوزه فناوری اطلاعات، برنامهنویسان، فعالان حوزه دادهکاوی و علم داده، فعالان حوزه یادگیری ماشین، دانشجویان رشته علم اطلاعات و دانششناسی و سایر علاقهمندان و افرادی که نیاز به فراگیری مباحث پایگاه داده و به خصوص مدیریت بانک اطلاعاتی اوراکل دارند مناسب است. از جمله مباحث مورد بررسی در این دوره آموزشی میتوان به معماری دیتابیس اوراکل، آمادهسازی محیط بانک اطلاعاتی، ایجاد دیتابیس اوراکل، مدیریت بخش حافظهای اوراکل، پیکربندی محیط شبکه در اوراکل، مدیریت ساختار ذخیرهسازی دیتابیس، مدیریت امنیت کاربران، مدیریت Schema اشیا، مدیریت داده و تضمین آن، مدیریت دادههای Undo شده، پیادهسازی امنیت در پایگاه داده اوراکل، نگهداری از پایگاه داده، مدیریت کارایی دیتابیس، مدیریت پشتیبانگیری و بازیابی و برخی از دیگر مباحث اشاره کرد.
- برای دیدن فیلم آموزش مدیریت بانک اطلاعاتی اوراکل + اینجا کلیک کنید.
فیلم آموزش مدیریت بانک اطلاعاتی اوراکل پیشرفته

طول مدت این دوره آموزشی شش ساعت و پنجاه و شش دقیقه و مدرس آن، مهندس حمیدرضا پاکپور حاجیها است. این آموزش برای افرادی که فیلم آموزش مدیریت بانک اطلاعات اوراکل را مشاهده کردهاند و همچنین، کلیه علاقهمندان به علوم و مهندسی کامپیوتر، دانشجویان رشتههای حوزه فناوری اطلاعات، برنامهنویسان، فعالان حوزه دادهکاوی و علم داده، فعالان حوزه یادگیری ماشین، دانشجویان رشته علم اطلاعات و دانششناسی و سایر علاقهمندان و افرادی که با مباحث مقدماتی مدیریت بانک اطلاعاتی اوراکل آشنایی دارند و در صدد فراگیری مباحث پیشرفته مدیریت بانک اطلاعاتی اوراکل هستند مناسب است. از جمله مباحث مورد بررسی در آموزش مدیریت بانک اطلاعاتی اوراکل پیشرفته میتوان به معماری دیتابیس اوراکل و ASM، پیکربندی برای بکاپ و بازیابی، پیکربندی محیط برای بکاپ، ایجاد بکاپها با ابزار RMAN، وظایف بکاپ و بازیابی، استفاده از ابزار RMAN برای Duplicate دیتابیس، استفاده از ابزار RMAN برای Duplicate دیتابیس، Flashback و نکاتی در مورد کارایی دیتابیس اشاره کرد.
- برای دیدن فیلم آموزش مدیریت بانک اطلاعاتی اوراکل پیشرفته + اینجا کلیک کنید.
فیلم آموزش مقدماتی PostgreSQL برای مدیریت پایگاه داده

طول مدت این دوره آموزشی دو ساعت و چهل و دو دقیقه و مدرس آن مهندس محمد وفایی مقدم است. این آموزش برای کلیه علاقهمندان به علوم و مهندسی کامپیوتر، دانشجویان رشتههای حوزه فناوری اطلاعات، برنامهنویسان، فعالان حوزه دادهکاوی و علم داده، فعالان حوزه یادگیری ماشین، دانشجویان رشته علم اطلاعات و دانششناسی و سایر علاقهمندان و افرادی که نیاز به فراگیری مباحث پایگاه داده و به خصوص PostgreSQL برای مدیریت پایگاه داده دارند مناسب است. از جمله مباحث مورد بررسی در آموزش مقدماتی PostgreSQL برای مدیریت پایگاه داده میتوان به معرفی و آشنایی با پایگاه داده و موارد مربوط به آن، نصب PostgreSQL و pgAdmin و تنظیمات مربوط به دیتابیس و سرور و کوئری ها و مدیریت دستورات مربوط به دیتابیس اشاره کرد.
- برای دیدن فیلم آموزش مقدماتی PostgreSQL برای مدیریت پایگاه داده + اینجا کلیک کنید.











ولی بازم نفهمیدم کاربرد inner Join و cross join چیه؟
سلام
همه سایت ها از هم کپی کردن فقط سایت شما نمونه ی جدید داشت که تونستم متوجه بشم مفهوم self join رو . دم شما گرم ??
سلام . وقت بخیر . میشه مثالی بزنید که right over join برابر با inner join (داخلی) بشه . /با order و customer/
و یدونم left over join برابر با inner join باشه
خیلی ممنون