



نمونه گیری و بازنمونه گیری آماری (Sampling and Resampling) – به زبان ساده
دادهها ابزار کار در «یادگیری ماشین» (Machine Learning) هستند، در نتیجه نحوه جمعآوری و بهکارگیری آنها مهم است. «نمونهگیری» (Sampling) روشی آماری برای جمعآوری مشاهدات از یک جامعه آماری است. یک نمونه یا به منظور برآورد پارامترهای مجهول به کار میرود و یا جهت شناخت بهتر جامعه آماری به کار گرفته میشود. برای آشنایی بیشتر با مفهوم جامعه آماری و نمونه آماری بهتر است مطلب جامعه آماری — انواع داده و مقیاسهای آنها را مطالعه کنید.




در مقابل نمونهگیری، روش «بازنمونهگیری» (Re-sampling) براساس نمونه موجود، سعی در برآورد بهتر پارامترهای جامعه آماری و یا محاسبه خطای برآوردگر میکند. هر دو روش نمونهگیری و بازنمونهگیری برای حل مسائل مدلسازی به کار گرفته میشوند. در این مطلب با این دو مفهوم بیشتر آشنا شده و کاربرد آنها را در یادگیری ماشین مرور میکنیم.
نمونهگیری آماری
خصوصیات یا ویژگیهای یک عضو از جامعه آماری را در نظر بگیرید. مقدارهای این خصوصیات را برای آن عضو، «مقدار مشاهده شده» (Observation) مینامیم. در صورتی که همه اعضای جامعه آماری قابل مشاهده و اندازهگیری باشند، میتوان از روش سرشماری برای جمعآوری دادهها استفاده کرد.
زمانی که هدف، بررسی جامعه آماری با استفاده از مشاهدات آن است، احتمال دارد امکان دسترسی به همه این مشاهدات برای اعضای جامعه آماری فراهم نباشد. دلیل چنین امری میتواند یکی از موارد زیر باشد:
- هزینه زیاد برای اندازهگیری خصوصیات یا ویژگیهای اعضای جامعه آماری
- زمان زیاد برای اندازهگیری همه ویژگیها برای جامعه آماری
- از بین رفتن اعضای جامعه آماری در زمان اندازهگیری ویژگی (تعیین زمان سوختن یک لامپ)
- نامتناهی بودن جامعه آماری
ممکن است تعداد زیادی مشاهدات از جامعه آماری به روشی ساده و ارزان در اختیارمان قرار داشته باشد ولی از آنجایی که به همه جامعه آماری دسترسی نداشتهایم، این مجموعه مشاهدات، یک نمونه از جامعه محسوب میشوند.

به کمک یک نمونه آماری مناسب، با صرف زمان و هزینه کم، قادر هستیم پارامترهای جامعه آماری را برآورد کرده و آن را بهتر بشناسیم.
نمونهگیری
روش نمونهگیری، فرآیندی است که به کمک آن زیرمجموعهای از جامعه آماری تهیه میشود. این کار به منظور شناخت یا برآورد پارامترهای جامعه آماری صورت میگیرد. قبل از تهیه نمونه از جامعه آماری بهتر است به نکات زیر توجه کنیم:
- هدف از نمونهگیری: برآورد خصوصیات جامعه آماری براساس نمونه
- جامعه آماری: دامنه و حوزهای که بررسی موضوع تحقیق را نشان میدهند.
- تعیین محدودیت: تعیین معیاری برای انتخاب اعضای جامعه آماری در نمونه
- حجم نمونه: تعداد اعضای انتخابی از جامعه آماری در نمونه
خطا در برآورد
از آنجایی که به جای استفاده از جامعه آماری، نمونه آماری به کار گرفته شده است، برآورد پارامتر جامعه با خطا همراه است. این خطا از دو دیدگاه بررسی میشود. «اُریبی» (Bias) و «خطای نمونهگیری» (Sampling Error).
- اُریبی: این خطا به علت تمایل نمونه به یک سمت از جامعه آماری است. این میزان خطا نشان میدهد که به طور متوسط برآوردگر با مقدار واقعی چقدر تفاوت دارد.
- خطای نمونهگیری: از آنجایی که نمونه به صورت تصادفی از جامعه آماری انتخاب شده است، با انتخاب نمونه دیگر نیز مقدار برای پارامتر جامعه با مقدار دیگری برآورد میشود. خطای نمونهگیری نشان میدهد که واریانس این برآوردگر چقدر است. یعنی اگر چندین بار نمونهگیری انجام شود، به طور متوسط پراکندگی این برآوردها چقدر خواهد بود.
در نتیجه باید شیوه نمونهگیری به شکلی باشد که این دو خطا در آن کمترین حالت خود را داشته باشند. بنابراین شیوههای نمونهگیری متنوعی مانند «نمونهگیری تصادفی ساده» (Simple Random Sampling)، «نمونهگیری سیستماتیک» (Systematic Random Sampling)، «نمونهگیری طبقهای» (Stratified Random Sampling) و «نمونهگیری خوشهای» (Clustering Sampling) بوجود آمدهاند تا الگویی صحیح برای انتخاب اعضای نمونه آماری ارائه دهند.
بازنمونهگیری
با استفاده از نمونه آماری، برآورد پارامتر جامعه امکان پذیر است. ولی این برآورد براساس یک نمونه تصادفی حاصل شده است و دقت آن اندازهگیری نشده. یک روش برای مشخص کردن دقت برآوردگر، بازنمونهگیری و برآورد پارامتر است. به این ترتیب چندین برآوردگر براساس هر نمونه تولید شده در روش بازنمونهگیری حاصل میشود و میتوان واریانس یا دقت این برآوردگرها را محاسبه کرد.

در حقیقت بازنمونهگیری روشی مقرون به صرفه با استفاده از یک نمونه، برای محاسبه دقت برآوردهای حاصل شده است.
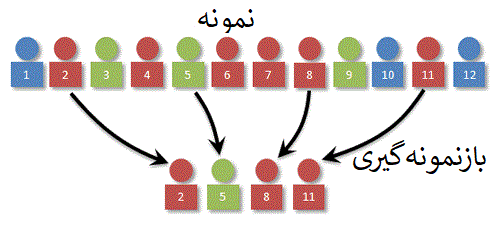
روشهای بازنمونهگیری ساده بوده و احتیاج به محاسبات طولانی ندارند. به عنوان مثال میتوان به روش «جکنایف» (Jackknife)، «بوتاسترپ» (Bootstrap) و همچنین «اعتبار سنجی متقابل» (K-fold Cross-validation) اشاره کرد.
- جکنایف: از یک نمونه با حجم n، چندین نمونه با استفاده از حذف یک به یک عناصر تولید شده و برآوردیابی انجام میشود. میانگین برآوردگرهای تولید شده میتواند به عنوان برآوردگر جدید معرفی شده و خطای آن محاسبه شود.
- بوتاسترپ: از یک نمونه با حجم n چندین نمونه با جایگذاری، تهیه میشود. از این نمونهها به عنوان مجموعه «داده آموزشی» (Learning Data) استفاده شده و برآورد پارامتر جامعه انجام میشود. از مابقی اعضایی که در بازنمونهگیری به کار نرفتهاند به عنوان مجموعه «دادههای آزمایشی» (Test Data) استفاده میشود.
- روش اعتبار سنجی متقابل: در این روش نمونه با حجم n به k زیر نمونه تقسیم شده بطوری که در هر بار برآورد پارامتر، یکی از این زیر نمونهها به عنوان داده آموزشی و مابقی به عنوان دادههای آزمایشی به کار میروند. این روش امروزه برای ارزیابی مدلهای پیشبینی به کمک آموزش ماشین به کار گرفته میشود.

اگر به فراگیری مباحث مشابه مطلب بالا علاقهمند هستید، آموزشهایی که در ادامه آمدهاند نیز به شما پیشنهاد میشوند:
- مجموعه آموزش های SPSS
- مجموعه آموزش های Minitab
- مجموعه آموزشهای آمار، احتمالات و دادهکاوی
- آموزش روش های نمونه برداری و بازرسی در کنترل کیفیت
- جامعه آماری — انواع داده و مقیاسهای آنها
- مفاهیم آماری – شاخصهای توصیفی
- توزیع فراوانی – به زبان ساده
- مفاهیم آماری – آمار و جامعه آماری – به زبان ساده
^^











سلام
سپاسگزارم استاد گرامی،مطلب برای من بسیار مفید بود،اگر ممکنه راههای ارتباطی باخودتون رو بفرمایید.