



تشخیص چهره در مرورگر با API جاوا اسکریپت – به زبان ساده
در این مطلب، روش تشخیص چهره در مرورگر با API جاوا اسکریپت و tensorflow.js آموزش داده شد. tensorflow.js در واقع «رابط برنامهنویسی کاربردی» (Application Programming Interface | API) «جاوا اسکریپت» (JavaScript | JS) برای «تشخیص چهره» (Face Detection)، «بازشناسی چهره» (Face Recognition) و «تشخیص ناحیه چهره» (Face Landmark Detection) است. برای مطالعه بیشتر در این رابطه، مطالب زیر پیشنهاد میشوند.




- آموزش یادگیری ماشین با مثالهای کاربردی ــ بخش چهارم
- تشخیص چهره در پایتون با OpenCV و Dlib — از صفر تا صد
- پیادهسازی سیستم تشخیص چهره در متلب — راهنمای کاربردی
- تشخیص چهره با فلاتر — راهنمای کاربردی
- API تشخیص چهره کروم — راهنمای کاربردی
- آموزش پایتون: مفاهیم OpenCV برای تشخیص چهره و حرکت — راهنمای مقدماتی
- بازشناسی چهره (Face Recognition) پیشرفته با استفاده از اکسل — به زبان ساده
- تشخیص لبخند در چهره — راهنمای کاربردی
فراهم آوردن امکانی که بتواند کار تشخیص چهره را در مرورگر انجام داد، برای بسیاری از افراد جالب توجه است. در این مطلب، face-api.js معرفی شده که یک ماژول جاوا اسکریپت ساخته شده بر فراز هسته tensorflow.js است و چندین پیادهسازی از «شبکههای عصبی پیچشی» (Convolutional Neural Networks | CNN) برای حل مسائل تشخیص چهره، تشخیص ناحیه چهره و بازشناسی تصویر دارد و برای کار در وب و دستگاههای موبایل بهینهسازی شده است.
در ادامه، یک نمونه کد ساده ارائه شده است که میتوان با استفاده از آن فورا کار را با تنها چند خط کد آغاز کرد. شایان توجه است که این پروژه در حال توسعه است و به روز رسانیهای جدیدی برای آن به مرور ارائه میشود. برای اطلاع از این به روز رسانیها بررسی این صفحه [+] توصیه میشود.
بسته تشخیص چهره face-recognition.js
بسته تشخیص چهره face-recognition.js برای تشخیص چهره در Node.js با استفاده از «یادگیری عمیق» (Deep Learning) ارائه شده است. در ابتدا به نظر نمیرسید که این ابزار در جامعه جاوا اسکریپت کارها این چنین با تقاضا و اقبال مواجه شود. برای بسیاری از افراد، face-recognition.js ابزاری رایگان و متنباز برای معادلهای پولی خودش که توسط مایکروسافت یا آمازون ارائه شدهاند، به منظور انجام بازشناسی چهره است. اگرچه این امکان وجود دارد که با بهرهگیری از این ابزار کل مراحل بازشناسی چهره را در مرورگر انجام داد.

در نهایت، به کمک tensorflow.js ابزار مشابهی با استفاده از tfjs-core پیادهسازی شد که نتایج مشابهی با face-recognition.js اما در مروگر وب دارد. علاوه بر آن، face-api.js مدلهایی فراهم میکند که برای وب کاربرد دارند و همچنین، روی منابع دستگاههای موبایل بهینهسازی شدهاند. اما همچنان بهترین قسمت پیرامون آن این است که نیاز به راهاندازی هیچ وابستگی خارجی نیست و این بسته به تنهایی فوقالعاده عمل میکند. به عنوان یک نقطه قوت دیگر باید گفت که این ابزار با GPU شتابهدهی شده و عملیات را روی بکاند WebGL اجرا میکند. همین دلایل متقاعد کننده بود که جامعه جاوااسکریپت نیاز به چنین بستهای برای مرورگر دارد.
حل مسائل بازشناسی چهره با یادگیری عمیق
افرادی که با مبحث یادگیری عمیق و چگونگی بازشناسی چهره با استفاده از یادگیری عمیق آشنایی دارند، نیازی به مطالعه این بخش ندارند و میتوانند مستقیما بخش بعدی را مطالعه کنند. هر چند برای درک بهتر مطلب مطالعه این بخش توصیه میشود.
کاری که قرار است در ادامه انجام شود، شناسایی یک شخص است که چهره آن در تصویر ورودی ارائه شده است. روش انجام این کار فراهم کردن یک یا تعداد بیشتری تصویر برچسبگذاری شده از هر فردی است که هدف، تشخیص چهره آن است. به این دادهها، «دادههای مرجع» (Reference Data) گفته میشود.
اگرچه، دو مسئله همچنان باقی است. اول آنکه اگر یک تصویر باشد که چند نفر در آن وجود داشته باشند، آیا هدف تشخیص چهره همه آنها است؟ دومین مسئله این است که نیازی برای به دست آوردن سنجههای مشابهت برای تصاویر دو چهره به منظور مقایسه تصاویر دو چهره وجود دارد.
تشخیص چهره در مرورگر با API جاوا اسکریپت
پاسخ اولین مسئله تشخیص چهره است. در ابتدا تنها کافی است تا موقعیت همه چهرهها در تصویر مشخص شود. Face-api.js چندین تشخیص دهنده چهره را برای بررسیهای موردی گوناگون پیادهسازی میکند. با دقتترین تشخیصدهنده چهره SSD است (Single Shot Multibox Detector)، که اساسا یک CNN بر پایه MobileNet V1 با تعدادی از لایههای پیشبینی جعبه قرار گرفته به صورت پشته در شبکه است.
علاوه بر آن، face-api.js یک تشخیصدهنده چهره کوچک بر پایه نسخه کوچکتر Tiny Yolo v2 است که پیچشهای جداشدنی عمیق را به جای پیچشهای معمولی به کار میگیرد که سریعتر هستند، اما کمی در مقایسه با SSD MobileNet V1 از صحت کمتری برخورد هستند.
در نهایت آنکه، یک پیادهسازی شبکه عصبی پیچشی آبشاری چند وظیفهای (Multi-task Cascaded Convolutional Neural Network | MTCNN) که این روزها بیشتر با انگیزههای پژوهشی مورد بررسی قرار میگیرد نیز که وجود دارد. شبکهها جعبههای محصورکنندهای را با امتیاز متناظر برای هر چهره باز میگردانند؛ برای مثال این امتیاز میتواند احتمال آن باشد که هر جعبه نشان دهنده یک چهره است. امتیازها برای فیلتر کردن جعبههای محصور کننده مورد استفاده قرار میگیرند، زیرا یک تصویر ممکن است به طور کلی فاقد هر گونه تصویر چهره باشد. شایان توجه است که این تشخیص چهره باید حتی در صورتی که تنها یک نفر در تصویر وجود دارد، انجام شود.
تشخیص ناحیه چهره و تراز چهره
اولین مسئله حل شد. اکنون، هدف تراز کردن جعبههای محصور کننده است.بدین شکل میتوان تصویری که در مرکز هر جعبه قرار دارد را پیش از انتقال دادن آن به شبکه تشخیص چهره شناسایی کرد، این کار موجب میشود بازشناسی چهره با صحت بیشتری انجام شود.
به همین دلیل، face-api.js یک CNN پیادهسازی میکند که ۶۸ نقطه ناحیه چهره را برای یک تصویر چهره داده شده پیدا میکند.

میتوان جعبه محصور کننده را به نوعی تنظیم کرد که چهره در مرکز آن قرار بگیرد. در ادامه میتوان نتایج تشخیص چهره (سمت چپ) را در مقایسه با تصاویر تراز شده (راست) مشاهده کرد.

بازشناسی چهره
اکنون میتوان تصاویر چهره استخراج و تراز شده را به شبکه بازشناسی چهره داد که بر پایه معماریهای مبتنی بر ResNet-34 و اساسا مطابق با معماری پیادهسازی شده در dlib است. شبکه به گونهای آموزش دیده است تا یاد بگیرد که مشخههای چهره انسان را به یک توصیفکننده چهره (یک بردار ویژگی با ۱۲۸ مقدار) نگاشت کند که گاهی به آن درونکارهای چهره نیز گفته میشود.

اکنون باید به مسئله اصلی مربوط به مقایسه دو چهره پرداخت. در اینجا از توصیفگر چهره هر یک از تصاویر چهره استخراج شده استفاده و آنها، با توصیفگرهای چهره دادههای ارجاع داده شده مقایسه میشوند. به بیان دقیقتر، میتوان «فاصله اقلیدسی» (Euclidean Distance) بین دو توصیفگر چهره را محاسبه و قضاوت کرد که آیا دو چهره بر پایه مقدار آستانه (برای چهره در ابعاد ۱۵۰×۱۵۰ مقدار ۰٫۶ آستانه خوبی است) مشابه هستند یا خیر. فاصله اقلیدسی در این زمینه عملکرد فوقالعاده ای دارد، اما میتوان از هر نوع دستهبندی که کاربر تمایل دارد استفاده کند. انیمیشن زیر مقایسه تصاویر دو چهره را با استفاده از فاصله اقلیدسی را بصریسازی کرده است.
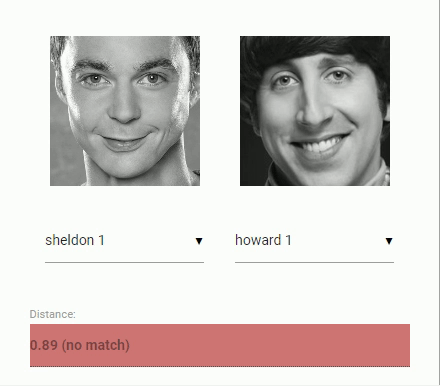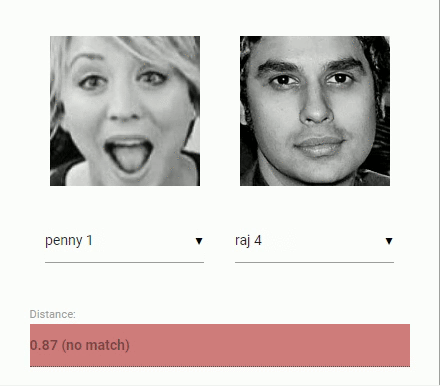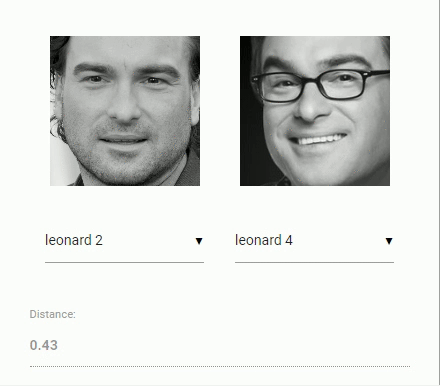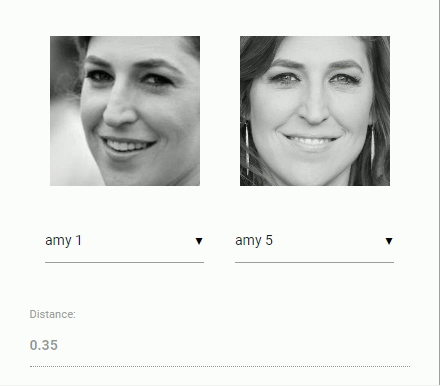
اکنون که مباحث نظری بازشناسی چهره به طور خلاصه بیان شدند، میتوان کدنویسی را آغاز کرد.
زمان کد نویسی
در این مثال، میتوان گام به گام مشاهده کرد که چگونه باید بازشناسی چهره روی تصاویر ورودی که افراد گوناگون را نشان میدهد پیادهسازی کرد.

قرار دادن اسکریپت
پیش از هر چیز، باید آخرین بیلد موجود را از dist/face-api.js و یا نسخه کوچک شده را از dist/face-api.min.js دریافت و اسکریپت را استفاده کرد.
در شرایطی که با npm کار میشود:
بارگذاری دادههای مدل
بسته به نیازهای برنامه کاربردی، کاربر میتواند به طور خاص مدل مورد نیاز خودش را بارگذاری کند، اما برای اجرای مثالهای کاملا انتها به انتها، نیاز به بارگذاری مدل تشخیص چهره، نقاط برجسته چهره و بازشناسی چهره است. فایلهای مدل در مخزن موجود هستند و میتوان از اینجا [+] به آنها دسترسی داشت.
وزنهای مدل برای کاهش سایز فایل مدل کمیسازی شدهاند. این کار با مقایسه ٪۷۵ آنها با مدل واقعی به منظور فراهم کردن امکانی انجام شده است که حداقل نیازمندیهای لازم بارگذاری شوند. علاوه بر آن، وزنهای مدل به بخشهای حداکثر ۴ مگابایتی شکسته شده است تا به مرورگر امکان کش کردن این فایلها را بدهد، به این شکل تنها نیاز به یک بار بارگذاری آنها است.
فایلهای مدل را میتوان به سادگی به عنوان یک دارایی استاتیک در نرمافزار وب فراهم کرد یا میتوان میزبان آنها در جای دیگری بود و آنها را با تعیین مسیر یا URL برای فایلها بارگذاری کرد. فرض میشود که کاربر آنها را در پوشههای مدل همراه با داراییهای زیر public/models قرار داده است.
دریافت توصیفات کامل برای همه چهرهها از یک تصویر ورودی
شبکههای عصبی تصاویر HTML، نقاشی، عناصر ویدئو یا تانسورها را به عنوان ورودی میپذیرند. برای شناسایی همه جعبههای محصور کننده تصاویر ورودی، به سادگی میتوان گفت:
یک توصیف کامل چهره نتایج تشخیص را نگه میدارد (جعبه محصور کننده + امتیاز)، نقاط برجسته چهره و توصیفگر محاسبه شده. با حذف دومین پارامتر گزینهها از faceapi.detectAllFaces(input, options) در واقع SSD MobileNet V1 به طور پیشفرض برای تشخیص چهره به کار میرود. برای استفاده از Tiny Face Detector یا به جای آن از MTCNN، میتوان این کار را به سادگی با تعیین گزینههای متناظر انجام داد.
برای مستندسازی همراه با جزئیات پیرامون گزینههای تشخیص چهره، میتوان بخش مربوط به آن را در «گیتهاب» (Github) بررسی کرد. شایان ذکر است که باید مدل مربوطه را از قبل برای استفاده بررسی کرد، چنانکه با مدل SSD MobileNet V1 این کار انجام شد. جعبههای محصول کننده بازگردانده شده و موقعیت نقاط برجسته، وابسته به سایز تصویر/رسانه اصلی است. در شرایطی که سایز تصویر نمایش داده شده متناظر با سایز تصویر اصلی نباشد، میتوان به سادگی اندازه آن را تغییر داد.
میتوان نتایج تشخیص را با ترسیم جعبههای محصورکننده روی بوم بصریسازی کرد.

نقاط برجسته چهره را میتوان به صورت زیر نمایش داد.


تشخیص چهره
اکنون که روش بازیابی موقعیتها و توصیفگرها برای همه چهرههای داده شده در یک تصویر ورودی بیان شد، تصاویری به مدل داده میشود که هر یک، چهره یک نفر را نشان میدهند و توصیفگرهای چهره آنها محاسبه میشود. این توصیفگرها دادههای مرجع خواهند بود.
فرض میشود تعدادی تصویر نمونه برای فاعلهای تصاویر موجود است؛ ابتدا باید تصاویر را از URL واکشی کرد و عناصر تصویر HTML را از بافرهای داده آنها با استفاده از faceapi.fetchImage واکشی کرد. برای هر تصویر واکشی شده تصویر فاعلها موقعیتیابی و توصیفگرهای چهره آنها محاسبه میشود. این کار درست مانند آنچه پیش از این برای یک تصویر ورودی انجام شد، صورت میپذیرد.
شایان توجه است که این بار از faceapi.detectSingleFace استفاده میشود که تنها، چهره تشخیص داده شده را با بالاترین امتیاز باز میگرداند، زیرا فرض میشود که تنها کاراکتری برای برچسب داده شده در آن تصویر، نمایش داده میشود.

اکنون، تنها کار باقیمانده برای انجام، تطبیق دادن توصیفگرهای چهرههای شناخته شده از تصاویر ورودی با دادههای مرجع است. برای مثال، توصیفگرهای چهره برچسبگذاری شده. بدین منظور، میتوان از faceapi.FaceMatcher به صورت زیر استفاده کرد.
تطبیقدهنده چهره از فاصله اقلیدسی به عنوان سنجه مشابهت استفاده میکند. این سنجه برای چنین مسائلی عملکرد خیلی خوبی دارد. کار با تعیین شدن مطابقترین موارد برای هر چهره تشخیص داده شده در تصویر که حاوی برچسب به علاوه فاصله اقلیدسی مورد تطبیق یافته است به پایان میرسد.

در نهایت میتوان جعبههای محصورکننده را همراه با برچسبهای آنها در بوم ترسیم کرد تا نتایج را نشان دهند.

اگر مطلب بالا برای شما مفید بوده، آموزشهای زیر نیز به شما پیشنهاد میشود:
- مجموعه آموزشهای دادهکاوی و یادگیری ماشین
- مجموعه آموزشهای دادهکاوی یا Data Mining در متلب
- مجموعه آموزشهای هوش مصنوعی
- زبان برنامهنویسی پایتون (Python) — از صفر تا صد
- یادگیری ماشین با پایتون — به زبان ساده
- آموزش یادگیری ماشین با مثالهای کاربردی — مجموعه مقالات جامع وبلاگ فرادرس
^^









