



تبدیل و پاکسازی داده ها با کتابخانه dplyr و tidyr در R – راهنمای کاربردی
در بیشتر زمینههای «تحلیل دادهها» (Data Analysis)، کارهای اولیه به سه بخش تقسیم میشوند. بخش اول «استخراج» (Extraction) دادهها است. بخش دوم «تبدیل» (Transformation) و «پاکسازی» (Cleaning) و بخش سوم نیز «بصری سازی» یا «نمایش» (Visualization) دادهها نامیده میشود. توابع موجود در کتابخانه dplyr و tidyr در زبان برنامهنویسی R، به منظور انجام بخش دوم یعنی تبدیل و پاکسازی دادهها به کار گرفته میشوند. در این نوشتار توابعی از کتابخانه dplyr و tidyr را مورد بررسی قرار می دهیم که عمل «ادغام» (Merge) و همچنین پاکسازی دادهها را انجام میدهند. برای اجرای کدهای نوشته شده در R از پوسته Rstudio کمک میگیریم.


تبدیل و پاکسازی دادهها با کتابخانه dplyr و tidyr در R
یکی از مشکلاتی که یک تحلیلگر داده (Data Scientist) با آن مواجه است، تبدیل (Transformation) بر روی دادهها است زیرا آنها با قالب و شکلی که انتظار دارد، جمعآوری نشدهاند. یک تحلیلگر داده باید نیمی از وقت خود را صرف پاکسازی و تبدیل کردن داده بکند.
به این ترتیب مشخص است که این وظایف یکی از حساسترین قسمتهای کار تحلیل دادهها است. اگر بخش مربوط به تبدیل و پاکسازی به درستی، دقت و بطور کامل صورت نگرفته باشد، مدلی که در مراحل بعدی تولید خواهد شد، مناسب نخواهد بود.

از کتابخانههای محبوب در زبان برنامهنویسی R، کتابخانه dplyr و tidyr است که بعضی از توابع آن وظایف تبدیل و پاکسازی دادهها را انجام میدهند. در این متن به بررسی توابع خانواده join از کتابخانه dplyr و همچنین توابع gather, spread, separate و unite از کتابخانه tidyr میپردازیم.
ادغام دادهها در کتابخانه dplyr
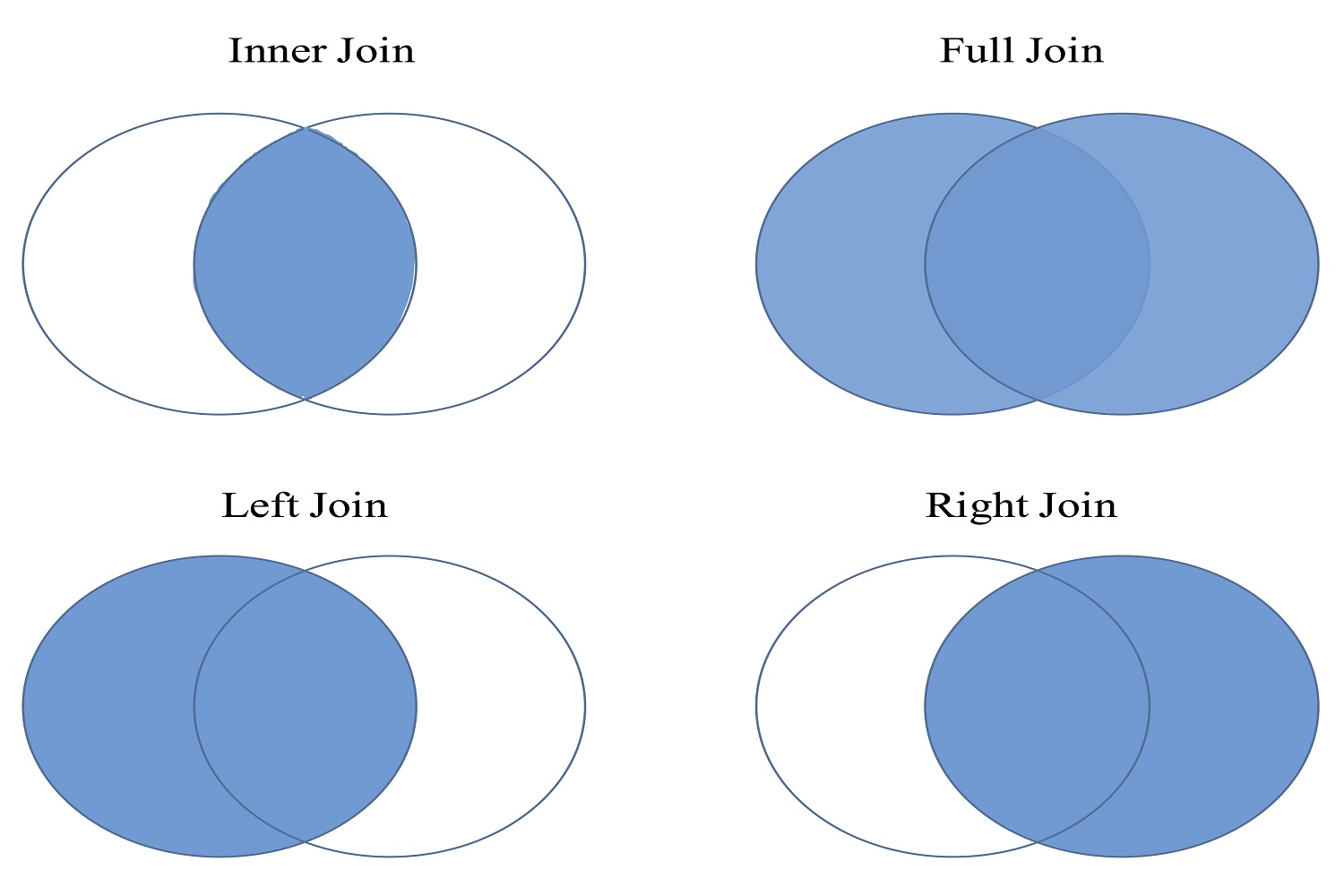
کتابخانه dplyr، توابعی دارد که عمل ترکیب و تبدیل «مجموعه داده» (Dataset) را در R به سادگی و راحتی انجام میدهند. ممکن است منابع اطلاعاتی ما مختلف باشند و نیاز است که در یک نقطه آنها را با یکدیگر ادغام کنیم. در این کتابخانه چهار روش مختلف برای ادغام منابع اطلاعاتی یا مجموعههای داده درست به مانند SQL وجود دارد. البته بعضی از توابع خانواده join مخصوص فیلتر کردن دادهها هستند که به آنها نیز خواهیم پرداخت.
- تابع ادغام از چپ -
- تابع ادغام از راست -
- تابع ادغام داخلی -
- تابع ادغام کامل -
- تابع فیلتر -
- تابع فیلتر -
در ادامه، براساس یک مثال به بررسی این توابع میپردازیم. ابتدا دو مجموعه داده میسازیم. جدولی با نام Table 1 که شامل دو فیلد (متغیر) ID و y است. به همین ترتیب نیز جدولی با نام Table 2 نیز ایجاد کردهایم که شامل متغیر ID و z است. در چنین حالتی، احتیاج به یک فیلد یا متغیر با مقدارهای مشترک در هر دو جدول داریم تا بتوانیم سطرهای متناظر را تشخیص و در عمل ادغام دخیل کنیم. در اینجا متغیر ID همان متغیر مشترک است که از این به بعد به آن متغیر کلید (key Variable) میگوییم.
در تصویر زیر اطلاعات ثبت شده در دو جدول Table 1 و Table 2دیده میشوند. مشخص است که مقدارهای مربوط به متغیر کلید (ID) برای سطرهای مرتبط یکسان هستند.

کدهای زیر به منظور بارگذاری کتابخانه dplyr و همچنین ایجاد جدولها نوشته شدهاند.
با اجرای این کد دو جدول به نامهای و ایجاد میشود که متغیر کلید آن دارای مقدارهای متنی (chr) از A تا F و متغیر دومی نیز مقدارهای عددی با ممیز شناور (dbl) هستند.
توجه دارید که در جدول اول سطری با ID برابر با F وجود دارد که در جدول دوم چنین سطری نیست. همچنین در جدول دوم نیز سطری با ID برابر با E هست که در جدول اول وجود ندارد.
ادغام از چپ -
یکی از معمولترین روشهای ادغام دو مجموعه داده، استفاده از تابع است. در این حالت براساس تصویری که در ادامه دیده میشود، با استفاده از متغیر کلید، سطرهای متناظر شناسایی شده و ستونهای هر دو جدول براساس سطرهای متناظر در کنار یکدیگر قرار میگیرند.

مشخص است که براساس متغیر ID مقدارهای سطرهای A,B,C,D در هر دو جدول مشترک هستند. بنابراین در جدول Table 3 حضور دارند. ولی از آنجایی که عمل ادغام از چپ است، جدول Table 1 اولویت دارد در نتیجه سطر F نیز اضافه شده ولی سطر E از جدول دوم اجازه ورود به جدول Table 3 را ندارد.
از آنجایی که برای سطر F در جدول دوم Table 2 مقداری برای متغیر z وجود ندارد، در جدول Table 3 مقدار NA برای متغیر z در سطر F ظاهر شده است. به این معنی که مقدار متغیر z برای سطر F ناموجود (Not Available) است.
نکته: اگر مقدار متغیری در مجموعه داده NA باشد، نرمافزار R آن را به عنوان داده ناموجود یا گمشده (Missing) در نظر میگیرد.
برای اجرای چنین ادغامی، از شکل دستوری زیر برای تابع استفاده میکنیم.
مشخص است که اولین پارامتر (df_primary)، جدول اصلی و دومین پارامتر (df_secondary) نیز جدولی را مشخص میکند که باید با جدول اصلی ادغام شود. پارامتر سوم نیز مشخص میکند که متغیر کلید در بین هر دو جدول ID در نظر گرفته شده است. از آنجایی که ادغام از چپ صورت گرفته، در جدول جدید (Table 3) سطرهای جدول اول (Table 1) حفظ شده و فقط ستون z براساس سطرهای متناظر، اضافه شده است. خروجی به صورت زیر در خواهد آمد.
ادغام از راست -
روش دیگر برای ادغام دو منبع اطلاعاتی، ادغام از راست است. به توجه به مفهوم ادغام از چپ، احتمالا روش ادغام از راست را نیز به راحتی درک خواهید کرد. تنها تفاوتی که در بین ادغام از چپ با ادغام از راست دو جدول مثال ما دیده میشود، وجود سطری با ID برابر با E است.

از انجایی که ادغام از راست صورت گرفته، اولویت با جدول دوم است. در نتیجه ستونهای مختلف این دو جدول براساس مقدارهای متغیر کلید شناسایی شده و در کنار یکدیگر قرار میگیرند و همچنین سطری از جدول دوم که در جدول اول دارای مقدار مشترکی نیست در جدول Table 3 دیده شده ولی مقدار متغیر y برایش به صورت NA ظاهر میشود. تصویر زیر شیوه ادغام این دو جدول را به خوبی نشان میدهد.

کد دستوری برای اجرای این عمل به صورت زیر است.
مشخص است که پارامترها درست به مانند پارامترهای است، ولی نحوه عمل تابع ادغام جدول معرفی شده در پارامتر اول به جدول مشخص شده در پارامتر دوم است. بطوری که اولویت با جدول دوم است. پارامتر by نیز درست به مانند قبل، متغیر مشترک در هر دو جدول را معرفی میکند. خروجی به صورت زیر خواهد بود.
همانظور که دیده میشود، در جدول ایجاد شده، سطر F وجود ندارد و همچنین در سطر مربوط به مقدار متغیر ID=E برای متغیر y مقدار NA ثبت شده است.
نکته: ترتیب قرارگیری متغیرها پس از ادغام، همان ترتیبی است که پارامترهای تابع نشان میدهد. یعنی ابتدا متغیرهای جدول df_primary و سپس متغیرهای جدول df_secondary قرار میگیرند. اگر میخواهید ترتیب قرارگیری متغیرها برعکس باشد باید جای پارامتر اول و دوم را تغییر دهید.
ادغام داخلی -
اگر میخواهید فقط سطرهای مشترک از دو جدول با یکدیگر ادغام شوند از تابع استفاده کنید. با این کار در جدول جدید، سطرهایی که دارای مقدار مشترک در متغیر کلید هستند ظاهر میشوند. نتیجه این کار جدولی است که دارای هیچ مقدار گمشدهای نیست. تصویر زیر به درک شیوه ادغام با تابع یاری میرساند.

همانطور که دیده میشود، در جدول Table 3 هیج سطری با مقدار NA دیده نمیشود. همچنین فقط سطرهایی از دو جدول Table 1 و Table 2 با یکدیگر ادغام شدهاند که در متغیر کلید دارای مقدار مشترک باشند. کد دستوری برای اجرای چنین ادغامی به صورت زیر است.
پارامترهای این تابع نیز درست به مانند پارامترهای توابع قبلی است. خروجی این دستور به صورت زیر خواهد بود.
ادغام کامل -
نوع دیگری که برای ادغام دو مجموعه داده باقی میماند، روش ادغام کامل است که به کمک تابع صورت میپذیرد. اگر میخواهید همه سطرهای مشترک و غیر مشتکر از دو جدول را در کنار یکدیگر ببینید از تابع استفاده کنید. به این ترتیب اگر در بین دو جدول، سطرهایی غیر مشترک وجود داشته باشند، دادههای گمشده با مقدار NA جایگزین خواهند شد. تصویر زیر به بررسی وضعیت چنین ادغامی پرداخته است.

برای اجرای این نوع ادغام از کد دستوری زیر استفاده میکنیم.
باز هم دیده میشود که پارامترهای این تابع درست به مانند هم خانوادههایش است. خروجی این کد در ادامه دیده میشود.
نکته: در خانواده توابع join، اگر جای پارامترهای اول و دوم را تعویض کنیم، جای قرارگیری متغیرها تغییر خواهد کرد. زیرا پارامتر اول جدول اصلی و پارامتر دوم جدولی است که باید به جدول اول اضافه شود. در زیر جای این پارامترها تغییر کرده و نتیجه قابل مشاهده است.
فیلتر کردن با توابع و
فرض کنید از جدول Table 1 میخواهید فقط مشاهداتی را جدا کنید که دارای مقدار مشترک با جدول Table 2 هستند. با تابع این کار به راحتی صورت میگیرد. کافی است برای مثال براساس مجموعه دادههای df_primary و df_secondary به صورت زیر کد نویسی کنیم.
مشخص است که پارامترها درست به مانند قبل است، با این تفاوت که این تابع عمل ادغام را انجام نمیدهد و فقط سطرها یا مشاهداتی از جدول اولیه (df_primary) را نشان میدهد که دارای مقدار مشترک براساس متغیر ID با جدول ثانویه (df_secondary) هستند. خروجی به صورت زیر خواهد بود.
همچنین اگر بخواهیم فقط سطرها یا مشاهداتی را از جدول اولیه نشان دهیم که دارای مقدار مشترکی برحسب ID با جدول ثانویه نیستند، از تابع استفاده خواهیم کرد. کد زیر نیز به این منظور تهیه شده است.
به وضوح مشخص است که تنها مشاهدهای F است که از جدول اول، دارای مقدار مشترک با جدول دوم برحسب متغیر ID نیست. در نتیجه این سطر ID=F مشاهده خواهد شد.
نکته: اگر میخواهید سطرهایی از جدول df_secondary را مشاهده کنید که با جدول df_primary مشترک نیستند، کافی است جای پارامتر اول و دوم را در دستور قبلی عوض کنید. نتیجه دستور و خروجی به صورت زیر خواهد بود و فقط سطر ID=E مشاهده خواهد شد.
استفاده از چندین متغیر کلید
ممکن است برای ایجاد ارتباط بین دو جدول بیش از یک متغیر مبنا قرار گیرد. در این حالت برای مثال دو متغیر وجود دارد که بین دو جدول مشترک است. حال میخواهیم دو جدول را به کمک این دو متغیر ادغام کنیم. در تصویر زیر نحوه ادغام دو جدول نمایش داده شده است.

همانطور که در تصویر مشخص است، دو جدول دیده میشود که اولی (Table 1) شامل لیست مشتریانی است که از یک فروشگاه خرید کردهاند. متغیرهای ID, year, item نیز به ترتیب نشانگر کد مشتری، سال خرید و تعداد خریدها هستند. در جدول دوم (Table 2) نیز مشخصات مشترک مانند ID, year وجود دارد. همچنین میزان خرید مشتری نیز در متغیر price آورده شده است. قرار است این دو جدول با یکدیگر ادغام شوند تا تعداد و میزان خرید مشتریان در کنار یکدیگر قرار گیرند.
این اطلاعات توسط کد زیر در دو مجموعه داده df_primary و df_secondary قرار گرفته است.
برای ادغام از چپ این دو جدول از کد دستوری زیر استفاده میکنیم. مشخص است که برای معرفی دو متغیر به عنوان متغیر کلید، نام دو متغیر را در پارامتر by قرار دادهایم. کد و خروجی در زیر دیده میشود.
توابع مرتبط با پاکسازی دادهها
یکی دیگر از کتابخانههای مطرح برای عملیات پاکسازی داده (Data Cleaning) در R، کتابخانه است.

در ادامه به توابع از این کتابخانه اشاره خواهیم کرد که در انجام پاکسازی داده موثر هستند.
- تابع جمعآوری
- تایع گسترش
- تابع تفکیک
- تابع تجمیع
نکته: اگر این کتابخانه بر روی نرمافزار R، نصب نشده باشد، میتوانید از دستور زیر برای نصب آن اقدام کنید. البته این کار را برای کتابخانه dplyr نیز میتوانید انجام دهید. برای این کار باید به اینترنت متصل باشد.
تابع
گاهی نیاز است که شیوه نگهداری اطلاعات در یک مجموعه داده تغییر کند. فرض کنید اطلاعات به صورت تجمیعی در یک جدول مانند تصویر زیر قرار گرفتهاند. برای انجام تحلیل روی دادهها احتیاج داریم که ستونهای time و growth را در یک متغیرهای جداگانه ثبت کنیم. تابع این کار به خوبی انجام میدهد.

کدهای زیر به منظور ایجاد چنین مجموعه دادههای نوشته شدهاند. متغیر country کد کشور و q1_2017 تا q4_2017 نیز نشانگر فصلهای مختلف سال ۲۰۱۷ هستند. در داخل جدول زیر متغیر میزان رشد در هر مقطع و هر کشور ثبت شده است.
این مقدارهای در «چارچوب داده» (data.frame) به نام messy ثبت شده است. خروجی این دستورات به صورت زیر در خواهد آمد.
حال میخواهیم مانند تصویر قبلی، مجموعه داده را به صورتی درآوریم که هر متغیرها بخصوص مقدارهای درون جدول به صورت یک متغیر جداگانه ثبت و نگهداری شوند. کد دستوری زیر به این منظور نوشته شده است. همانطور که مشخص است تابع از کتابخانه به کار رفته است.
در ادامه به بررسی بعضی از پارامترهای این دستور پرداختهایم. هر یک از این پارامترها در جدول زیر معرفی شدهاند.
| پارامتر | عملکرد |
| data | چارچوب داده که باید تغییر کند. |
| key | نام ستون یا ستونهایی که باید ایجاد شود. |
| value | نام ستونی از چارچوب داده که باید ستونهای جدید را مقدار دهی کند. |
| na.rm | مقدار منطقی به منظور حذف دادههای گمشده (پیشفرض FALSE) |
همانطور که مشخص است پارامتر اول این دستور مجموعه دادهای است که باید تغییر کند. همچنین پارامترهای دوم و سوم نیز بیانگر متغیرهایی است که باید ایجاد شوند. پارامتر آخر نیز مجموعه مقدارهایی است که باید پارامترهای دوم و سوم از آن استخراج شوند. در نتیجه خروجی دستور بالا به صورت زیر در خواهد آمد.
به این ترتیب به کمک تابع یک مجموعه داده جدید براساس اطلاعات قبلی ساخته شد که در آن متغیرهای رشد (growth) و فصل (quarter) موجود بوده و مقدار دهی شدهاند. همانطور که مشخص است به منظور ایجاد این متغیرها، مقدارهای متغیر country تکرار شدهاند تا یکپارچگی دادهها از بین نرود.
تابع
توابع و عکس یکدیگر عمل میکنند. بنابراین اگر میخواهید مجموعه داده را به صورت تجمیعی درآورید و ستونها گسترش یابند، از تابع استفاده کنید. پارامترهای این تابع نیز به مانند پارامترهای تابع است. در ادامه به معرفی بعضی از این پارامترها پرداختهایم.
| پارامتر | عملکرد |
| data | مجموعه دادهای که باید تغییر شکل یابد. |
| key | متغیری که مقدارش به منظور نامگذاری ستونها به کار میرود. |
| value | مقدارهایی که باید به منظور تشکیل جدول تجمیعی جدید درون جدول به کار روند. |
برای مثال فرض کنید که چارچوب داده tidier که در مثال قبل ایجاد شد را میخواهیم به صورت تجمیعی درآوریم بطوری که مقدارهای متغیر quarter در سطرهای جدول و مقدارهای growth نیز درون جدول جای گیرند. کد زیر به این منظور تهیه شده است.
با اجرای این کد، خروجی به صورت زیر خواهد بود.
مشخص است که چارچوب داده messy_again با messy یکی است.
تابع
فرض کنید مقدارهای یک متغیر یا ستون را باید به دو ستون یا دو متغیر مجزا تفکیک کنیم. همانطور که به یاد دارید در چارچوب اطلاعاتی tidier، متغیر quarter شامل سال و فصل بود. مثلا یکی از مقدارهای این متغیر به صورت نوشته شده است. اگر بخواهیم سال را از فصل جدا کنیم، تابع انتخاب خوب و مناسبی برای انجام این کار است.
پارامترهای این تابع به صورت زیر است. جدولی که در ادامه دیده میشود، به معرفی این پارامترها پرداخته است.
| پارامتر | عملکرد |
| data | چارچوب داده |
| col | ستونی که باید تفکیک شود |
| into | نام متغیرهای جدید |
| sep | علامت جدا کننده برای مقدارهای متغیر col |
| remove | مقدار منطقی به منظور حذف ستون col از مجموعه داده- پیشفرض TRUE |
برای جداسازی متغیر quarter و ایجاد دو متغیر Qrt و Year برای ثبت فصل و سال در چارچوب داده tidier از کد زیر استفاده میکنیم. مشخص است که علامت جداکننده در اینجا "_" است.
خروجی این دستور به صورت زیر خواهد بود. مشخص است که دو متغیر جدید اضافه و متغیر quarter نیز حذف شده است.
تابع
توابع و عکس یکدیگر عمل میکنند. به این ترتیب با تابع قادر هستیم مقدارهایی دو متغیر را در یک متغیر قرار دهیم.
شکل دستوری و بعضی از پارامترهای این تابع در ادامه دیده میشود.
| پارامتر | عملکرد |
| data | چارچوب داده |
| col | نام متغیر یا ستون جدید برای دادههای ترکیب شده |
| conc | اسامی متغیرهایی که مقدارهایشان باید ترکیب شوند |
| sep | علامت جداکننده برای مقدارهای ترکیب شده |
| remove | مقدار منطقی به منظور حذف ستون یا متغیرهای conc از مجموعه داده- پیشفرض TRUE |
همانطور که در قسمت قبل دیدید، متغیرهای Qrt و Year را ایجاد کردیم. حال قصد داریم این مقدارهای متغیرها را ترکیب کرده و در یک متغیر جدید به نام Quarter قرار دهیم. کد زیر به این منظور تهیه شده است.
با اجرای این دستور، خروجی به صورت زیر ساخته میشود. مشخص است از آنجایی که مقدار پیشفرض برای پارامتر remove مقدار TRUE است، متغیرهای اولیه که برای ترکیب به کار رفتهاند، در خروجی حذف شدهاند.
همانطور که دیده میشود، مجموعه داده اولیه که در قسمتهای قبلی با نام tidier داشتیم بازسازی شده است.
خلاصه
در انتها خلاصهای از توابع به کار رفته در این نوشتار به همراه پارامتر و کاربردهایشان دیده میشود. ابتدا توابع خانواده join معرفی میشوند.
| تابع | شرح | پارامترها | کلیدهای چندتایی |
| ادغام از چپ دو مجموعه داده- حفظ همه دادههای x |
x, y, by | دارد | |
| ادغام از راست دو مجموعه داده- حفظ همه دادههای y | x, y, by | دارد | |
| ادغام دو مجموعه داده با اعضای مشترک | x, y, by | دارد | |
| ادغام دو مجموعه داده با اعضای مشترک و غیر مشترک | x, y, by | دارد | |
| فیلتر مجموعه داده x برحسب مشاهدات مشترک با y | x, y, by | دارد | |
| فیلتر مجموعه داده x برحسب مشاهدات غیر مشترک با y | x, y, by | دارد |
همچنین جدول زیر نیز به معرفی توابع معروف کتابخانه tidyr پرداخته است.
| تابع | شرح | پارمتر |
| تبدیل دادههای جدول گسترده به ستونهای کمتر | data, key, value | |
| تبدیل دادههای جدول با ستونهای بیشتر | data, key, value | |
| تفکیک مقدارهای یک متغیر به چند متغیر | data, col, into, sep, remove | |
| ادغام مقدارهای چند متغیر در یک متغیر | data, col, conc, into, sep, remove |
اگر مطلب بالا برای شما مفید بوده، آموزشها و مطالب زیر نیز که در زمینه به کارگیری آمار و محاسبات در نرمافزار R هستند، به شما پیشنهاد میشوند:
- مجموعه آموزشهای آمار، احتمالات و دادهکاوی
- مجموعه آموزشهای یادگیری ماشین و بازشناسی الگو
- مجموعه آموزشهای هوش محاسباتی
- آموزش برنامهنویسی R و نرمافزار R Studio
- آموزش تکمیلی برنامهنویسی R و نرمافزار RStudio
- توابع Apply در زبان برنامه نویسی R — راهنمای کاربردی
- ضریب همبستگی و ماتریس همبستگی در R — کاربرد در یادگیری ماشین
^^










