
الگوریتم های مهم پایتون که باید آنها را بدانید – راهنمای کاربردی
برخی الگوریتمهای خاص هستند که استفاده زیادی در زمان برنامهنویسی دارند. در این راهنما به بررسی چند الگوریتم مهم پایتون که جزء رایجترین انواع این الگوریتمها هستند به همراه مثال میپردازیم. این الگوریتمها شامل جستجو، مرتبسازی و افزودن/حذف کردن آیتم به لیست پیوندی هستند. ایدههای پیرامون این مثالها در مورد الگوریتمهای زیاد دیگری نیز صدق میکند. درک این سه مثال و الگوریتم به شما کمک میکنند تا اطلاعات خوبی در مورد روش برخورد با مسائل مرتبط با الگوریتمهای دیگر نیز کسب کنید و در این زمینه اعتماد به نفس داشته باشید.




جستجوی دودویی
«جستجوی دودویی» (Binary Search) یک الگوریتم ضروری جستجو است که روی آرایههای مرتب اجرا میشود و اندیس یک مقدار را که به دنبالش هستیم بازگشت میدهد. این کار به صورت زیر اجرا میشود:
- نقطه میانی آرایه مرتب را پیدا کنید.
- نقطه میانی را با مقدار مورد نظر مقایسه کنید.
- اگر نقطه میانی بزرگتر از مقدار مورد نظر باشد، جستجوی باینری در نیمه راست آرایه تکرار میشود.
- اگر نقطه میانی کوچکتر از مقدار مورد جستجو باشد، جستجوی باینری روی نیمه چپ آرایه تکرار میشود.
- این مراحل را تا زمانی که نقطه میانی برابر با مقدار مورد نظر باشد یا این که بدانیم مقدار مورد جستجو در آرایه وجود ندارد تکرار میکنیم.
از روی مراحل فوق مشخص است که راهحل ما میتواند به صورت «بازگشتی» (recursive) باشد. ما در هر تکرار یک آرایه کوچکتر را به متد خود ارسال میکنیم تا این که تنها یک مقدار که مورد نظر ما است باقی بماند. بخشهای دشوار این راهحل اندیسگذاری صحیح آرایه و ردگیری افست اندیس در هر تکرار است به طوری که بتوان اندیس مقدار مورد جستجو را در آرایه اصلی پیدا کرد. در کد زیر نسخهای از الگوریتم جستجوی دودویی را مشاهده میکنید:
جستجوی دودویی پیچیدگی زمانی برابر با (O(logn دارد. میدانیم که در این حالت وقتی اندازه آرایه ورودی را دو برابر کنیم، باید یک تکرار بیشتر برای یافتن مقدار مطلوب در الگوریتم خود اضافه کنیم. به همین دلیل است که جستجوی باینری چنین الگوریتم کارآمدی در علوم رایانه محسوب میشود.
مرتبسازی ادغامی
«مرتبسازی ادغامی» (Merge Sort) از روششناسی مشابه «تقسیم و حل» (divide and conquer) برای مرتبسازی کارآمد آرایهها بهره میگیرد. مراحل زیر در مورد شیوه پیادهسازی مرتبسازی ادغامی است.
- اگر آرایه تنها یک عنصر داشته باشد، بازگرد زیرا چنین آرایهای مرتب محسوب میشود.
- آرایه را به طور متوالی دو نیمه تقسیم کن، تا این که دیگر نتوان بیش از آن تقسیم کرد.
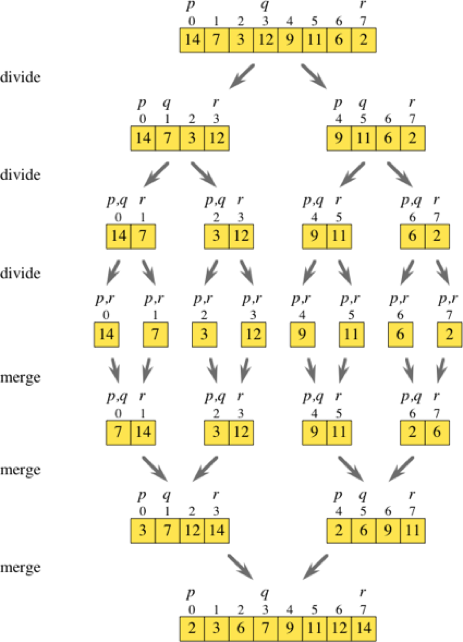
- آرایههای کوچکتر را به صورت مرتب با هم ادغام کن تا این که به آرایه اصلی مرتبسازی شده برسی.

برای پیادهسازی مرتبسازی ادغامی، دو متد را تعریف خواهیم کرد. یکی از متدها اختصاص به افراز کردن آرایه دارد و دیگری وظیفه ادغام کردن مجدد دو آرایه مرتب را به صورت یک آرایه مرتبسازی شده بر عهده دارد. متد تقسیم کردن (merge_sort) به صورت بازگشتی فراخوانی میشود تا این که آرایه تنها یک عنصر طول داشته باشد. سپس این آرایههای فرعی با هم ترکیب میشوند تا نهایتاً یک آرایه مرتب بازگشت یابد. به مثال زیر توجه کنید:
مرتبسازی ادغامی دارای پیچیدگی زمانی (O(nlog n است که بهترین پیچیدگی زمانی برای یک الگوریتم مرتبسازی محسوب میشود. ما میتوانیم با بهرهگیری از تقسیم و حل کردن، کارآیی مرتبسازی را که اصولاً یک پردازش پرهزینه از نظر محاسباتی است به میزان زیادی افزایش دهیم.
الگوریتم نویسی شامل چند مرحله است که باید به صورت دقیق و منظم، پشت سر هم اجرا شوند. از آنجا که هدف این مطلب، آموزش الگوریتم نویسی نیست، دراینباره توضیحاتی ننوشتهایم. اما برای آموزش و درک روش صحیح نوشتن الگوریتم میتوانید مطلب مربوط به آن را در مجله فرادرس مطالعه کنید.
افزودن و حذف کردن آیتم از لیست پیوندی
لیست پیوندی یکی از ساختمانهای داده بنیادی در علوم کامپیوتر محسوب میشود که دلیل آن به خاطر زمان ثابت درج و حذف است. با استفاده از گرهها و اشارهگرها میتوانیم برخی پردازشها را به روشی کارآمدتر از زمانی که از آرایه استفاده میکردیم اجرا کنیم. به نمودار شماتیک زیر توجه کنید:

یک لیست پیوندی از گرههایی تشکیل یافته است که هر یک بخشی از دادهها و یک اشارهگر به گره بعدی دارند. این وضعیت در Ruby با یک struct به نام Node نمایش پیدا میکند که دو آرگومان به نامهای data: و:next_node دارد. اینک کافی است دو متد به نامهای insert_node و delete_node تعریف کنیم که یک گره head و یک location برای مکانی که حذف/درج رخ میدهد میپذیرد.
متد insert_node یک آرگومان دیگر به نام node نیز دارد که همان struct گرهی است که میخواهیم درج کنیم. سپس حلقهای تعریف میکنیم تا موقعیتی را که میخواهیم آیتمی را در آن درج یا حذف کنیم بیابیم. زمانی که به مکان مطلوب برسیم، اشارهگرها را طوری مجدداً چیدمان میکنیم تا عملیات درج/حذف ما را بازتاب دهند.
در یک لیست پیوندی میتوان آیتمها را از میانه یک مجموعه بدون نیاز به تغییر دادن بقیه ساختمان داده در حافظه حذف کرد و این وضعیت کارایی بیشتری نسبت به ساختمان داده آرایه ایجاد میکند. بدین ترتیب میبینیم که با انتخاب بهترین ساختمان داده بر اساس نیازها میتوان به کارایی مناسبی دست یافت.
سخن پایانی
سه نسخه الگوریتمی که در این مقاله معرفی کردیم، تنها جزء کوچکی از الگوریتمهای بنیادی هستند که باید برای خلق برنامههای کارآمد و موفقیت در مصاحبههای فنی بدانید. لیستی از الگوریتمهای دیگر که در این زمینه توصیه میشود مطالعه کنید به شرح زیر هستند:
- الگوریتم Quicksort
- پیمایش یک درخت جستجوی دودویی
- درخت کمینه پوشا
- الگوریتم Heapsort
- معکوس سازی یک رشته به صورت درجا
البته مفاهیم دیگری نیز وجود دارند که باید بیاموزید، بنابراین توصیه میکنیم به تمرین کردن و درک مثالهای بیشتری از الگوریتمها ادامه بدهید.
اگر این مطلب برای شما مفید بوده است، آموزشهای زیر نیز به شما پیشنهاد میشوند:
- مجموعه آموزشهای برنامهنویسی پایتون Python
- مجموعه آموزشهای برنامهنویسی
- گنجینه آموزش های برنامه نویسی پایتون (Python)
- زبان برنامه نویسی پایتون (Python) — از صفر تا صد
- آموزش الگوهای طراحی (Design Patterns) در پایتون (Python)
- نحوه نوشتن الگوریتم – آموزش کامل و به زبان ساده
==










جالب بود ولی کدهای نمونه برای زبان روبی هستند نه پایتون